Vega
b617a87ee4
Init ppg extractor and ppg2mel ( #375 )
...
* Init ppg extractor and ppg2mel
* add preprocess and training
* FIx known issues
* Update __init__.py
Allow to gen audio
* Fix length issue
* Fix bug of preparing fid
* Fix sample issues
* Add UI usage of PPG-vc
2022-03-03 23:38:12 +08:00
AyahaShirane
ad22997614
fixed the issues #372 ( #379 )
...
修复了一些参数传递造成的问题,把过时的torch.nn.functional.tanh()改成了torch.tanh()
2022-02-27 11:02:01 +08:00
hertz
9e072c2619
Hifigan Support train from existed checkpoint. ( #389 )
...
* 1k steps to save tmp hifigan model
* hifigan support train from existed ckpt
2022-02-27 11:01:47 +08:00
Alex Newton
b79e9d68e4
连续换行造成的多了个None ( #405 )
...
小问题,gui好像没有这个问题,自己测试web的时候直接调用的函数发现的这个情况
2022-02-27 10:55:00 +08:00
babysor00
0536874dec
Add config file for pretrained
2022-02-23 09:37:39 +08:00
李子
4529479091
指定librosa版本 ( #378 )
...
* 支持data_aishell(SLR33)数据集
* 更新readme
* 指定librosa版本
2022-02-10 20:47:26 +08:00
babysor00
8ad9ba2b60
change naming logic of saving trained file for synthesizer to allow shorter interval
2022-01-15 17:56:14 +08:00
D-Blue
b56ec5ee1b
Fix a UserWarning ( #273 )
...
Fix a UserWarning in synthesizer/synthesizer_dataset.py, because of converting list of numpy array to torch tensor at Ln.85.
2021-12-20 20:33:12 +08:00
CrystalRays
0bc34a5bc9
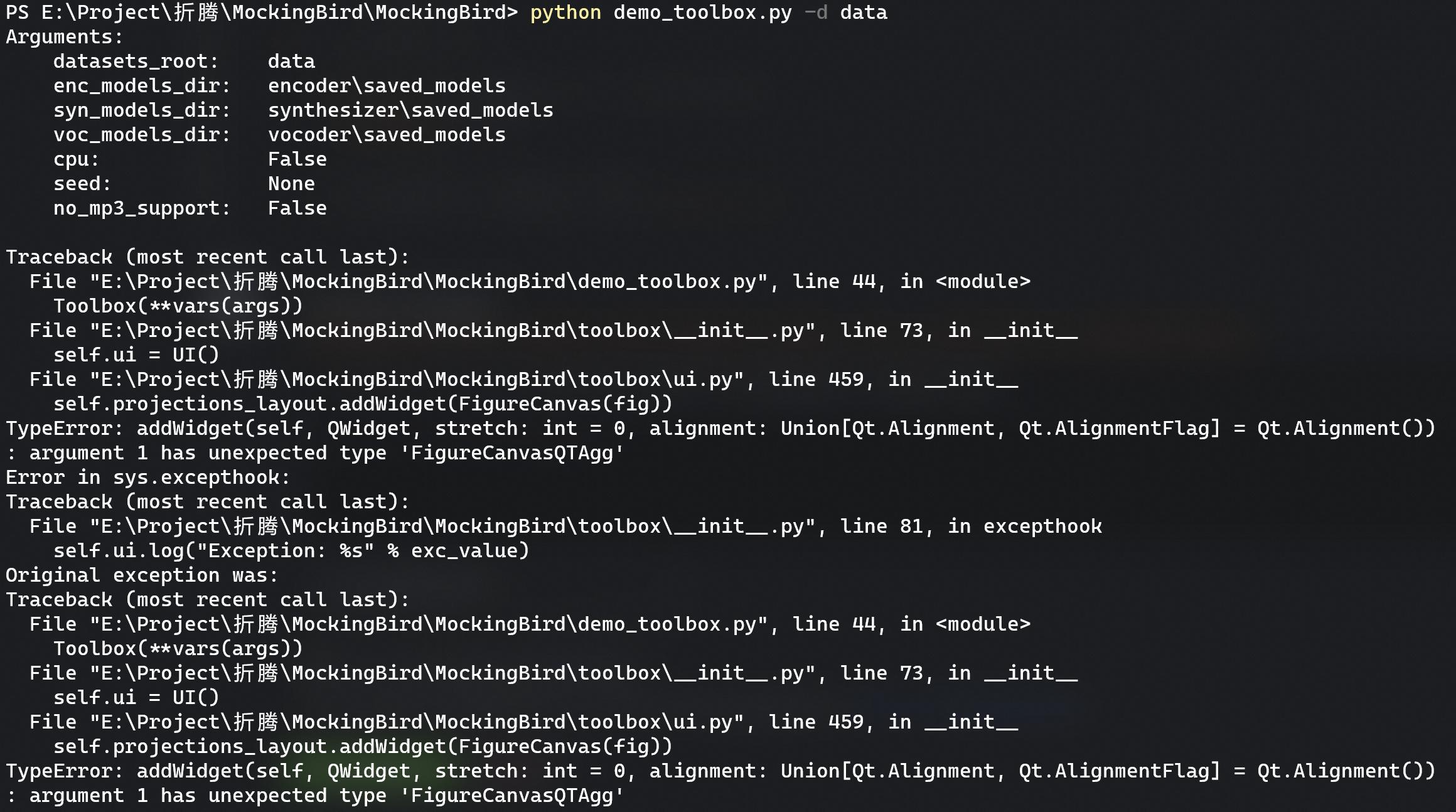
Fix TypeError at line 459 in toolbox/ui.py when both PySide6(PyQt6) and PyQt5 installed ( #255 )
...
### Error Info Screenshot

### Error Reason
Matplotlib.backends.qt_compat.py decide the version of qt library according to sys.modules firstly, os.environ secondly and the sequence of PyQt6, PySide6, PyQt5, PySide 2 and etc finally. Import PyQt5 after matplotlib make that there is no PyQt5 in sys.modules so that it choose PyQt6 or PySide6 before PyQt5 if it installed.
因为Matplotlib.backends.qt_compat.py优先根据导入的库决定要使用的Python Qt的库,如果没有导入则根据环境变量PYQT_APT决定,再不济就按照PyQt6, PySide6, PyQt5, PySide 2的顺序导入已经安装的库。因为ui.py先导入matplotlib而不是PYQT5导致matplotlib在导入的库里找不到Qt的库,又没有指定环境变量,然后用户安装了Qt6的库的话就导入Qt6的库去了
2021-12-15 12:41:10 +08:00
Wings Music
875fe15069
Update readme for training encoder ( #250 )
2021-12-07 19:10:29 +08:00
zzxiang
4728863f9d
Fix inference on cpu device ( #241 )
2021-11-29 21:10:07 +08:00
hertz
a4daf42868
1k steps to save tmp hifigan model ( #240 )
2021-11-29 21:09:54 +08:00
harian
b50c7984ab
tacotron.py-Multi GPU with DataParallel ( #231 )
2021-11-27 20:53:08 +08:00
babysor00
26fe4a047d
Differentiate GST token
2021-11-18 22:55:13 +08:00
babysor00
aff1b5313b
Order of declared pytorch module matters
2021-11-17 00:12:27 +08:00
babysor
7dca74e032
Change default to use speaker embed for reference
2021-11-13 10:57:45 +08:00
babysor00
a37b26a89c
模型兼容问题加强 Compatibility Enhance of Pretrained Models and code base #209
2021-11-10 23:23:13 +08:00
babysor00
902e1eb537
Merge branch 'main' of https://github.com/babysor/Realtime-Voice-Clone-Chinese
2021-11-09 21:08:33 +08:00
babysor00
5c0e53a29a
Fix #205
2021-11-09 21:08:28 +08:00
DragonDreamer
4edebdfeba
修复synthesizer/models/tacotron.Encoder注释错误 ( #203 )
...
fix Issue#202
2021-11-09 13:59:19 +08:00
babysor00
6c8f3f4515
Allow to select vocoder in web
2021-11-08 23:55:16 +08:00
babysor00
2bd323b7df
Update readme
2021-11-07 21:59:03 +08:00
babysor00
3674d8b5c6
Use speaker embedding anyway even with default style
2021-11-07 21:48:15 +08:00
babysor00
80aaf32164
Add max steps control in toolbox
2021-11-06 13:27:11 +08:00
babysor00
c396792b22
Upload new models
2021-10-27 20:19:50 +08:00
babysor00
7c58fe01d1
Concat GST output instead of adding directly with original output
2021-10-23 10:28:32 +08:00
Vega
724194a4de
Add code to control finetune layers ( #154 )
2021-10-23 10:25:43 +08:00
babysor00
31bc6656c3
Fix bug of importing GST and add more parameters in toolbox
2021-10-21 00:40:00 +08:00
洛竹
aa35fb3139
docs: this repo -> 本代码库 ( #157 )
...
Co-authored-by: 洛竹 <youngjuning@aliyun.com>
2021-10-20 22:54:31 +08:00
babysor00
727eafc51b
Merge branch 'main' of https://github.com/babysor/Realtime-Voice-Clone-Chinese
2021-10-20 00:27:19 +08:00
babysor00
d328ecba81
Reconstruct UI of toolbox
2021-10-20 00:27:13 +08:00
Vega
fad574118c
Update README-CN.md
2021-10-18 13:50:19 +08:00
babysor00
b0c156a537
Add new dataset support to preprocess parameter
2021-10-17 17:21:49 +08:00
Vega
724809abf4
Update README.md
2021-10-15 14:34:29 +08:00
Vega
05cd1a54ea
Add new pretrain model with gst
2021-10-14 01:26:23 +08:00
李子
245099c740
支持data_aishell(SLR33)数据集 ( #141 )
...
* 支持data_aishell(SLR33)数据集
* 更新readme
2021-10-12 23:40:27 +08:00
babysor00
6dd2af49fe
Merge branch 'main' of https://github.com/babysor/Realtime-Voice-Clone-Chinese
2021-10-12 20:02:05 +08:00
babysor00
8b43ec9a64
Fix bug pre-processing magicdata
2021-10-12 20:01:37 +08:00
Vega
2a99f0ff05
Add gst ( #137 )
...
* Commit with working GST
* Make it backward compatible
* Add readme
2021-10-12 19:43:29 +08:00
babysor00
a824b54122
补充预处理文档
2021-10-12 09:22:10 +08:00
weida wang
81befb91b0
Update ui.py ( #136 )
...
Add minimize and maximize button of window
2021-10-11 17:17:36 +08:00
babysor00
e2017d0314
Merge branch 'main' of https://github.com/babysor/Realtime-Voice-Clone-Chinese into main
2021-10-05 10:48:58 +08:00
babysor00
547ac816df
Update demo and training param
...
A
2021-10-05 10:48:54 +08:00
Ji Zhang
6b4ab39601
add alternative download source for dataset (google drive) ( #112 )
2021-10-03 10:10:40 +08:00
babysor00
b46e7a7866
New web with selecting wav files
2021-10-01 22:13:39 +08:00
babysor00
8a384a1191
Merge branch 'main' of https://github.com/babysor/Realtime-Voice-Clone-Chinese into main
2021-10-01 09:33:31 +08:00
Nemo
11154783d8
web tool box update UI ( #111 )
...
* web tool box update UI
* update img
2021-10-01 00:32:29 +08:00
AkifSaeed20
d52db0444e
Update launch.json ( #109 )
2021-10-01 00:22:43 +08:00
babysor00
790d11a58b
Allow to train encoder
2021-10-01 00:01:33 +08:00
babysor00
cb82fcfe58
Add Zhihu link (chinese Quora) to readme
2021-09-27 21:59:44 +08:00
{kind=link}