目录
C/C++
- 封装
- 继承
- 多态
- 虚函数
- 内存分配和管理
- extern"C"
- const作用
- 什么是面向对象(OOP)
- new、malloc、alloca的区别
- 运行时类型识别(RTTI)
- 友元类和友元函数
- struct和class的区别
- this指针
const
// 类
class A
{
private:
const int a; // 常对象成员,只能在初始化列表赋值
public:
// 构造函数
A() { };
A(int x) : a(x) { }; // 初始化列表
// const可用于对重载函数的区分
int getValue(); // 普通成员函数
int getValue() const; // 常成员函数
};
void function()
{
// 对象
A b; // 普通对象,可以调用全部成员函数
const A a; // 常对象,只能调用常成员函数、更新常成员变量
canst A *p = &a; // 常指针
canst A &q = a; // 常引用
// 指针
char greeting[] = "Hello";
char* p1 = greeting; // 指针变量,指向字符数组变量
const char* p2 = greeting; // 指针变量,指向字符数组常量
char* const p3 = greeting; // 常指针,指向字符数组变量
const char* const p4 = greeting; // 常指针,指向字符数组常量
}
// 函数
void function1(const int Var); // 传递过来的参数在函数内不可变
void function2(const char* Var); // 参数指针所指内容为常量
void function3(char* const Var); // 参数指针为常指针
void function4(const int& Var); // 引用参数在函数内为常量
// 函数返回值
const int function5(); // 返回一个常数
const int* function6(); // 返回一个指向常量的指针变量,使用:const int *p = function6();
int* const function7(); // 返回一个指向变量的常指针,使用:int* const p = function7();
inline 内联函数
特征
- 相当于把内联函数里面的内容写在调用内联函数处;
- 相当于不用执行进入函数的步骤,直接执行函数体;
- 相当于宏,却比宏多了类型检查,真正具有函数特性;
- 不能包含循环、递归、switch等复杂操作。
使用
// 声明1(加inline,建议使用)
inline int functionName(int first, int secend,...);
// 声明2(不加inline)
int functionName(int first, int secend,...);
// 定义
inline int functionName(int first, int secend,...) {/****/};
编译器对inline函数的处理步骤
- 将inline函数体复制到inline函数调用点处;
- 为所用inline函数中的局部变量分配内存空间;
- 将inline函数的的输入参数和返回值映射到调用方法的局部变量空间中;
- 如果inline函数有多个返回点,将其转变为inline函数代码块末尾的分支(使用GOTO)。
优缺点
优点
- 内联函数同宏函数一样将在被调用处进行代码展开,省去了参数压栈、栈帧开辟与回收,结果返回等,从而提高程序运行速度。
- 内联函数相比宏函数来说,在代码展开时,会做安全检查或自动类型转换(同普通函数),而宏定义则不会。
- 在类中声明同时定义的成员函数,自动转化为内联函数,因此内联函数可以访问类的成员变量,宏定义则不能。
- 内联函数在运行时可调试,而宏定义不可以。
缺点
- 代码膨胀。内联是以代码膨胀(复制)为代价,消除函数调用带来的开销。如果执行函数体内代码的时间,相比于函数调用的开销较大,那么效率的收获会很少。另一方面,每一处内联函数的调用都要复制代码,将使程序的总代码量增大,消耗更多的内存空间。
- inline函数无法随着函数库升级而升级。inline函数的改变需要重新编译,不像non-inline可以直接链接。
- 是否内联,程序员不可控。内联函数只是对编译器的建议,是否对函数内联,决定权在于编译器。
Effective C++
- 视C++为一个语言联邦(C、Object-Oriented C++、Template C++、STL)
- 尽量以
const、enum、inline替换#define(宁可以编译器替换预处理器) - 尽可能使用const
- 确定对象被使用前已先被初始化
- 了解C++默默编写并调用哪些函数(编译器暗自为class创建default构造函数、copy构造函数、copy assignment操作符、析构函数)
STL
数据结构
顺序结构
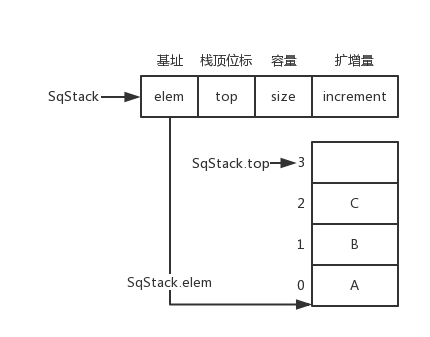
顺序栈(Sequence Stack)
typedef struct {
ElemType *elem;
int top;
int size;
int increment;
} SqSrack;
队列(Sequence Queue)
typedef struct {
ElemType * elem;
int front;
int rear;
int maxSize;
}SqQueue;
非循环队列
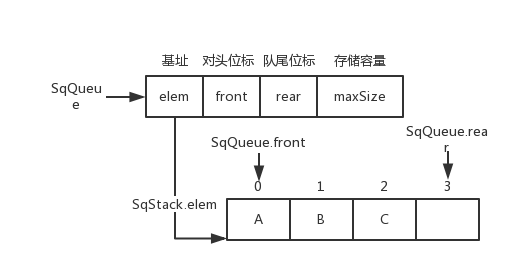
SqQueue.rear++
循环队列

SqQueue.rear = (SqQueue.rear + 1) % SqQueue.maxSize
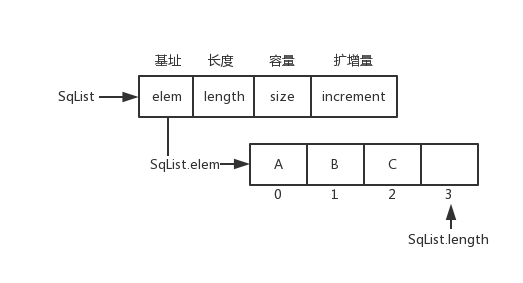
顺序表(Sequence List)
typedef struct {
ElemType *elem;
int length;
int size;
int increment;
} SqList;
链式结构
typedef struct LNode {
ElemType data;
struct LNode *next;
} LNode, *LinkList;
链队列(Link Queue)

线性表的链式表示
单链表(Link List)

双向链表(Du-Link-List)

循环链表(Cir-Link-List)

哈希表
概念
哈希函数:H(key): K -> D , key ∈ K
构造方法
- 直接定址法
- 除留余数法
- 数字分析法
- 折叠法
- 平方取中法
冲突处理方法
- 链地址法:key相同的用单链表链接
- 开放定址法
- 线性探测法:key相同 -> 放到key的下一个位置,
Hi = (H(key) + i) % m - 二次探测法:key相同 -> 放到
Di = 1^2, -1^2, ..., ±(k)^2,(k<=m/2) - 随机探测法:
H = (H(key) + 伪随机数) % m
- 线性探测法:key相同 -> 放到key的下一个位置,
线性探测的哈希表数据结构
typedef char KeyType;
typedef struct {
KeyType key;
}RcdType;
typedef struct {
RcdType *rcd;
int size;
int count;
bool *tag;
}HashTable;

递归
概念
函数直接或间接地调用自身
递归与分治
- 分治法
- 问题的分解
- 问题规模的分解
- 折半查找(递归)
- 归并查找(递归)
- 快速排序(递归)
递归与迭代
- 迭代:反复利用变量旧值推出新值
- 折半查找(迭代)
- 归并查找(迭代)
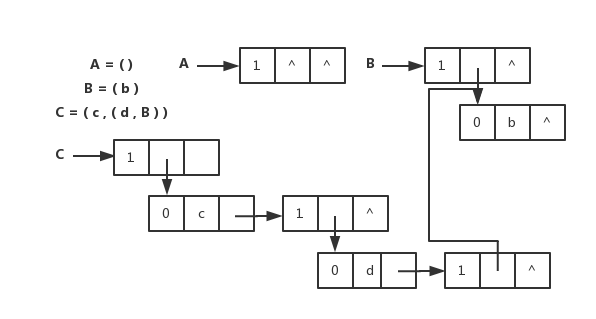
广义表
头尾链表存储表示
// 广义表的头尾链表存储表示
typedef enum {ATOM, LIST} ElemTag;
// ATOM==0:原子,LIST==1:子表
typedef struct GLNode {
ElemTag tag;
// 公共部分,用于区分原子结点和表结点
union {
// 原子结点和表结点的联合部分
AtomType atom;
// atom是原子结点的值域,AtomType由用户定义
struct {
struct GLNode *hp, *tp;
} ptr;
// ptr是表结点的指针域,prt.hp和ptr.tp分别指向表头和表尾
} a;
} *GList, GLNode;

扩展线性链表存储表示
// 广义表的扩展线性链表存储表示
typedef enum {ATOM, LIST} ElemTag;
// ATOM==0:原子,LIST==1:子表
typedef struct GLNode1 {
ElemTag tag;
// 公共部分,用于区分原子结点和表结点
union {
// 原子结点和表结点的联合部分
AtomType atom; // 原子结点的值域
struct GLNode1 *hp; // 表结点的表头指针
} a;
struct GLNode1 *tp;
// 相当于线性链表的next,指向下一个元素结点
} *GList1, GLNode1;
二叉树
性质
- 非空二叉树第 i 层最多 2^(i-1) 个结点 (i >= 1)
- 深度为 k 的二叉树最多 2^k - 1 个结点 (k >= 1)
- 度为 0 的结点数为 n0,度为 2 的结点数为 n2,则 n0 = n2 + 1
- 有 n 个结点的完全二叉树深度 k = ⌊ log2(n) ⌋ + 1
- 对于含 n 个结点的完全二叉树中编号为 i (1 <= i <= n) 的结点
- 若 i = 1,为根,否则双亲为 ⌊ i / 2 ⌋
- 若 2i > n,则 i 结点没有左孩子,否则孩子编号为 2i + 1
- 若 2i + 1 > n,则 i 结点没有右孩子,否则孩子编号为 2i + 1
存储结构
typedef struct BiTNode
{
TElemType data;
struct BiTNode *lchild, *rchild;
}BiTNode, *BiTree;
顺序存储

链式存储

遍历方式
- 先序遍历
- 中序遍历
- 后续遍历
- 层次遍历
分类
- 满二叉树
- 完全二叉树(堆)
- 大顶堆:根 >= 左 && 根 >= 右
- 小顶堆:根 <= 左 && 根 <= 右
- 二叉查找树(二叉排序树):左 < 根 < 右
- 平衡二叉树(AVL树):| 左子树树高 - 右子树树高 | <= 1
- 最小失衡树:平衡二叉树插入新结点导致失衡的子树:调整:
- LL型:根的左孩子右旋
- RR型:根的右孩子左旋
- LR型:根的左孩子左旋,再右旋
- RL型:右孩子的左子树,先右旋,再左旋
其他树及森林
树的存储结构
- 双亲表示法
- 双亲孩子表示法
- 孩子兄弟表示法
并查集
一种不相交的子集所构成的集合 S = {S1, S2, ..., Sn}
平衡二叉树(AVL树)
性质
- | 左子树树高 - 右子树树高 | <= 1
- 平衡二叉树必定是二叉搜索树,反之则不一定
- 最小二叉平衡树的节点的公式:
F(n)=F(n-1)+F(n-2)+1(1是根节点,F(n-1)是左子树的节点数量,F(n-2)是右子树的节点数量)

最小失衡树
平衡二叉树插入新结点导致失衡的子树
调整:
- LL型:根的左孩子右旋
- RR型:根的右孩子左旋
- LR型:根的左孩子左旋,再右旋
- RL型:右孩子的左子树,先右旋,再左旋
红黑树
应用
- 关联数组:如STL中的map、set
B树
B+树
八叉树
图
算法
排序
查找
Problems
Single Problem
Leetcode Problems
Array
- 1. Two Sum
- 4. Median of Two Sorted Arrays
- 11. Container With Most Water
- 26. Remove Duplicates from Sorted Array
- 53. Maximum Subarray
- 66. Plus One
- 88. Merge Sorted Array
- 118. Pascal's Triangle
- 119. Pascal's Triangle II
- 121. Best Time to Buy and Sell Stock
- 122. Best Time to Buy and Sell Stock II
- 169. Majority Element
- 283. Move Zeroes
操作系统
- 进程间的通信方式(管道、有名管道、信号、共享内存、消息队列、信号量、套接字、文件)
计算机网络
- TCP/IP
- TCP协议
- TCP三次握手
- TCP和UDP的区别
- socket套接字
- HTTP返回码
概念
- TCP(Transmission Control Protocol,传输控制协议,在运输层)是一种面向连接的、可靠的、基于字节流的传输层通信协议。
- UDP(User Datagram Protocol,用户数据报协议,在运输层)是OSI(Open System Interconnection 开放式系统互联) 参考模型中一种无连接的传输层协议,提供面向事务的简单不可靠信息传送服务。
- IP(Internet Protocol,网际协议,在网络层)是为计算机网络相互连接进行通信而设计的协议。
- Socket 建立网络通信连接至少要一对端口号(socket)。socket本质是编程接口(API),对TCP/IP的封装,TCP/IP也要提供可供程序员做网络开发所用的接口,这就是Socket编程接口。
linux网络编程之TCP/IP基础(一):TCP/IP协议栈与数据报封装
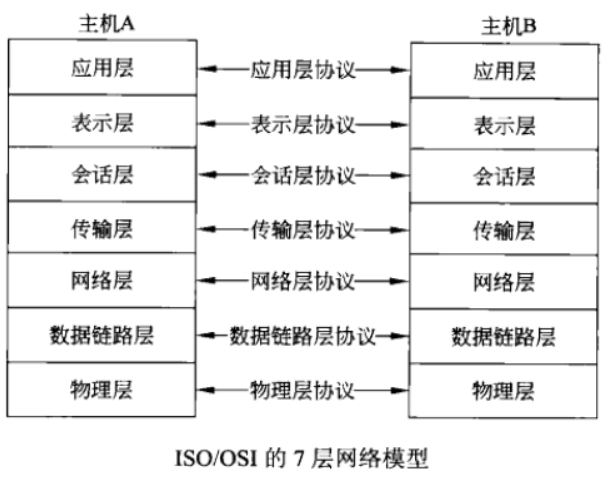
ISO/OSI参考模型
OSI(open system interconnection)开放系统互联模型是由ISO(International Organization for Standardization)国际标准化组织定义的网络分层模型,共七层,如下图
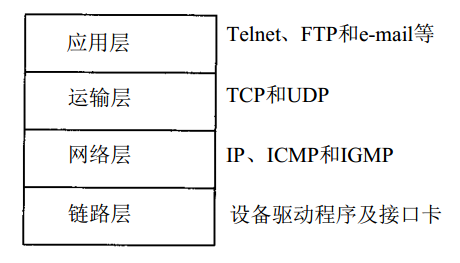
TCP/IP协议四层模型
TCP/IP网络协议栈分为应用层(Application)、传输层(Transport)、网络层(Network)和链路层(Link)四层。如下图所示
HTTP
HTTP 请求方法
- GET:请求指定的页面信息,并返回实体主体
- HEAD:类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头
- POST:向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。
- PUT:从客户端向服务器传送的数据取代指定的文档的内容。
- DELETE:请求服务器删除指定的页面
- CONNECT:HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器
- OPTIONS:允许客户端查看服务器的性能
- TRACE:回显服务器收到的请求,主要用于测试或诊断
HTTP 状态码
- 200 OK: 请求成功
- 301 Moved Permanently: 永久移动。请求的资源已被永久的移动到新URI,返回信息会包括新的URI,浏览器会自动定向到新URI。今后任何新的请求都应使用新的URI代替
- 400 Bad Request: 客户端请求的语法错误,服务器无法理解
- 401 Unauthorized: 请求要求用户的身份认证
- 403 Forbidden: 服务器理解请求客户端的请求,但是拒绝执行此请求
- 404 Not Found: 服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站设计人员可设置"您所请求的资源无法找到"的个性页面
- 408 Request Timeout: 服务器等待客户端发送的请求时间过长,超时
- 500 Internal Server Error: 服务器内部错误,无法完成请求
- 503 Service Unavailable: 由于超载或系统维护,服务器暂时的无法处理客户端的请求。延时的长度可包含在服务器的Retry-After头信息中
- 504 Gateway Timeout: 充当网关或代理的服务器,未及时从远端服务器获取请求
网络编程
Socket
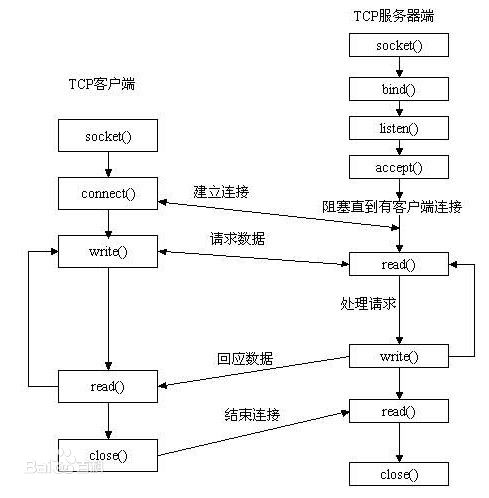
Socket 中的 read()、write() 函数
ssize_t read(int fd, void *buf, size_t count);
ssize_t write(int fd, const void *buf, size_t count);
- read函数是负责从fd中读取内容.当读成功时,read返回实际所读的字节数。如果返回的值是0表示已经读到文件的结束了,小于0表示出现了错误。如果错误为EINTR说明读是由中断引起的,如果是ECONNREST表示网络连接出了问题。
- write函数将buf中的nbytes字节内容写入文件描述符fd。成功时返回写的字节数。失败时返回-1,并设置errno变量。在网络程序中,当我们向套接字文件描述符写时有俩种可能。(1)write的返回值大于0,表示写了部分或者是全部的数据。(2)返回的值小于0,此时出现了错误。我们要根据错误类型来处理。如果错误为EINTR表示在写的时候出现了中断错误。如果为EPIPE表示网络连接出现了问题(对方已经关闭了连接)。
socket中TCP的三次握手建立连接
我们知道tcp建立连接要进行“三次握手”,即交换三个分组。大致流程如下:
- 客户端向服务器发送一个SYN J
- 服务器向客户端响应一个SYN K,并对SYN J进行确认ACK J+1
- 客户端再想服务器发一个确认ACK K+1
只有就完了三次握手,但是这个三次握手发生在socket的那几个函数中呢?请看下图:

从图中可以看出:
- 当客户端调用connect时,触发了连接请求,向服务器发送了SYN J包,这时connect进入阻塞状态;
- 服务器监听到连接请求,即收到SYN J包,调用accept函数接收请求向客户端发送SYN K ,ACK J+1,这时accept进入阻塞状态;
- 客户端收到服务器的SYN K ,ACK J+1之后,这时connect返回,并对SYN K进行确认;
- 服务器收到ACK K+1时,accept返回,至此三次握手完毕,连接建立。
socket中TCP的四次握手释放连接
上面介绍了socket中TCP的三次握手建立过程,及其涉及的socket函数。现在我们介绍socket中的四次握手释放连接的过程,请看下图:

图示过程如下:
- 某个应用进程首先调用close主动关闭连接,这时TCP发送一个FIN M;
- 另一端接收到FIN M之后,执行被动关闭,对这个FIN进行确认。它的接收也作为文件结束符传递给应用进程,因为FIN的接收意味着应用进程在相应的连接上再也接收不到额外数据;
- 一段时间之后,接收到文件结束符的应用进程调用close关闭它的socket。这导致它的TCP也发送一个FIN N;
- 接收到这个FIN的源发送端TCP对它进行确认。
这样每个方向上都有一个FIN和ACK。
数据库
- 数据库事务四大特性:原子性、一致性、分离性、持久性
- 数据库索引:顺序索引 B+树索引 hash索引 MySQL索引背后的数据结构及算法原理
- SQL 约束 (Constraints)
设计模式
链接装载库
内存、栈、堆
一般应用程序内存空间有如下区域:
- 栈:由操作系统自动分配释放,存放函数的参数值、局部变量等的值,用于维护函数调用的上下文
- 堆:一般由程序员分配释放,若程序员不释放,程序结束时可能由操作系统回收,用来容纳应用程序动态分配的内存区域
- 可执行文件映像:存储着可执行文件在内存中的映像,由装载器装载是将可执行文件的内存读取或映射到这里
- 保留区:保留区并不是一个单一的内存区域,而是对内存中受到保护而禁止访问的内存区域的总称,如通常C语言讲无效指针赋值为0(NULL),因此0地址正常情况下不可能有效的访问数据
栈
栈保存了一个函数调用所需要的维护信息,常被称为堆栈帧(Stack Frame)或活动记录(Activate Record),一般包含以下几方面:
- 函数的返回地址和参数
- 临时变量:包括函数的非静态局部变量以及编译器自动生成的其他临时变量
- 保存上下文:包括函数调用前后需要保持不变的寄存器
堆
堆分配算法:
- 空闲链表(Free List)
- 位图(Bitmap)
- 对象池
“段错误(segment fault)” 或 “非法操作,该内存地址不能read/write”
典型的非法指针解引用造成的错误。当指针指向一个不允许读写的内存地址,而程序却试图利用指针来读或写该地址时,会出现这个错误。
普遍原因:
- 将指针初始化位NULL,之后没有给它一个合理的值就开始使用指针
- 没用初始化栈中的指针,指针的值一般会是随机数,之后就直接开始使用指针
编译链接
编译链接过程
- 预编译(预编译器处理如
#include、#define等预编译指令,生成.i或.ii文件) - 编译(编译器进行词法分析、语法分析、语义分析、中间代码生成、目标代码生成、优化,生成
.s文件) - 汇编(汇编器把汇编码翻译成机器码,生成
.o文件) - 链接(连接器进行地址和空间分配、符号决议、重定位,生成
.out文件)
现在版本GCC把预编译和编译合成一步,预编译编译程序cc1、汇编器as、连接器ld
MSVC编译环境,编译器cl、连接器link、可执行文件查看器dumpbin
目标文件
编译器编译源代码后生成的文件叫做目标文件。目标文件从结构上讲,它是已经编译后的可执行文件格式,只是还没有经过链接的过程,其中可能有些符号或有些地址还没有被调整。
可执行文件(Windows的
.exe和Linux的ELF)、动态链接库(Windows的.dll和Linux的.so)、静态链接库(Windows的.lib和Linux的.a)都是按照可执行文件格式存储(Windows按照PE-COFF,Linux按照ELF)
目标文件格式
- Windows的PE(Portable Executable),或称为PE-COFF,
.obj格式 - Linux的ELF(Executable Linkable Format),
.o格式 - Intel/Microsoft的OMF(Object Module Format)
- Unix的
a.out格式 - MS-DOS的
.COM格式
PE和ELF都是COFF(Common File Format)的变种
目标文件存储结构
| 段 | 功能 |
|---|---|
| File Header | 文件头,描述整个文件的文件属性(包括文件是否可执行、是静态链接或动态连接及入口地址、目标硬件、目标操作系统等) |
| .text section | 代码段,执行语句编译成的机器代码 |
| .data section | 数据段,已初始化的全局变量和局部静态变量 |
| .bss section | BBS段(Block Started by Symbol),未初始化的全局变量和局部静态变量(因为默认值为0,所以只是在此预留位置,不占空间) |
| .rodate section | 只读数据段,存放只读数据,一般是程序里面的只读变量(如const修饰的变量)和字符串常量 |
| .comment section | 注释信息段,存放编译器版本信息 |
| .note.GNU-stack section | 堆栈提示段 |
其他段略
链接的接口————符号
在链接中,目标文件之间相互拼合实际上是目标文件之间对地址的引用,即对函数和变量的地址的引用。我们将函数和变量统称为符号(Symbol),函数名或变量名就是符号名(Symbol Name)。
如下符号表(Symbol Table):
| Symbol(符号名) | Symbol Value (地址) |
|---|---|
| main | 0x100 |
| Add | 0x123 |
| ... | ... |
extern "C"
extern "C" 的作用是让C++编译器将 extern "C" 声明的代码当作C语言代码处理,可以避免C++因符号修饰导致代码不能和C语言库中的符号进行链接的问题。
#ifdef __cplusplus
extern "C" {
#endif
void *memset(void *, int, size_t);
#ifdef __cplusplus
}
#endif
Linux的共享库(Shared Library)
Linux下的共享库就是普通的ELF共享对象。
共享库版本更新应该保证二进制接口ABI(Application Binary Interface)的兼容
命名
libname.so.x.y.z
- x:主版本号,不同主版本号的库之间不兼容,需要重新编译
- y:次版本号,高版本号向后兼容低版本号
- z:发布版本号,不对接口进行更改,完全兼容
路径
大部分包括Linux在内的开源系统遵循FHS(File Hierarchy Standard)的标准,这标准规定了系统文件如何存放,包括各个目录结构、组织和作用。
/lib:存放系统最关键和最基础的共享库,如动态链接器、C语言运行库、数学库等/usr/lib:存放非系统运行时所需要的关键性的库,主要是开发库/usr/local/lib:存放跟操作系统本身并不十分相关的库,主要是一些第三方应用程序的库
动态链接器会在
/lib、/usr/lib和由/etc/ld.so.conf配置文件指定的,目录中查找共享库
环境变量
LD_LIBRARY_PATH:临时改变某个应用程序的共享库查找路径,而不会影响其他应用程序LD_PRELOAD:指定预先装载的一些共享库甚至是目标文件LD_DEBUG:打开动态链接器的调试功能
Windows的动态链接库(Dynamic-Link Library)
DLL头文件
#ifdef __cplusplus
extern "C" {
#endif
#ifdef _WIN32
# ifdef MODULE_API_EXPORTS
# define MODULE_API __declspec(dllexport)
# else
# define MODULE_API __declspec(dllimport)
# endif
#else
# define MODULE_API
#endif
MODULE_API int module_init();
#ifdef __cplusplus
}
#endif
DLL源文件
#define MODULE_API_EXPORTS
#include "module.h"
MODULE_API int module_init()
{
/* do something useful */
return 0;
}
运行库(Runtime Library)
典型程序运行步骤
- 操作系统创建进程,把控制权交给程序的入口(往往是运行库中的某个入口函数)
- 入口函数对运行库和程序运行环境进行初始化(包括堆、I/O、线程、全局变量构造等等)。
- 入口函数初始化后,调用main函数,正式开始执行程序主体部分。
- main函数执行完毕后,返回到入口函数进行清理工作(包括全局变量析构、堆销毁、关闭I/O等),然后进行系统调用结束进程。
一个程序的I/O指代程序与外界的交互,包括文件、管程、网络、命令行、信号等。更广义地讲,I/O指代操作系统理解为“文件”的事物。
glibc 入口
_start -> __libc_start_main -> exit -> _exit
其中main(argc, argv, __environ)函数在__libc_start_main里执行。
MSVC CRT 入口
int mainCRTStartup(void)
执行如下操作:
- 初始化和OS版本有关的全局变量。
- 初始化堆。
- 初始化I/O。
- 获取命令行参数和环境变量。
- 初始化C库的一些数据。
- 调用main并记录返回值。
- 检查错误并将main的返回值返回。
C语言运行库(CRT)
大致包含如下功能:
- 启动与退出:包括入口函数及入口函数所依赖的其他函数等。
- 标准函数:有C语言标准规定的C语言标准库所拥有的函数实现。
- I/O:I/O功能的封装和实现。
- 堆:堆的封装和实现。
- 语言实现:语言中一些特殊功能的实现。
- 调试:实现调试功能的代码。
C语言标准库(ANSI C)
包含:
- 标准输入输出(stdio.h)
- 文件操作(stdio.h)
- 字符操作(ctype.h)
- 字符串操作(string.h)
- 数学函数(math.h)
- 资源管理(stdlib.h)
- 格式转换(stdlib.h)
- 时间/日期(time.h)
- 断言(assert.h)
- 各种类型上的常数(limits.h & float.h)
- 变长参数(stdarg.h)
- 非局部跳转(setjmp.h)
海量数据处理
音视频
其他
书籍
- 《剑指Offer》
- 《编程珠玑》
- 《深度探索C++对象模型》
- 《Effective C++》
- 《More Effective C++》
- 《深入理解C++11》
- 《STL源码剖析》
- 《深入理解计算机系统》
- 《TCP/IP网络编程》
- 《程序员的自我修养》