mirror of
https://github.com/donnemartin/data-science-ipython-notebooks.git
synced 2024-03-22 13:30:56 +08:00
1217 lines
39 KiB
Plaintext
1217 lines
39 KiB
Plaintext
{
|
|
"metadata": {
|
|
"name": "",
|
|
"signature": "sha256:71af98f7155af43ed0d04aeee32dfc65b677bd43e2000e52770d010c81b0095a"
|
|
},
|
|
"nbformat": 3,
|
|
"nbformat_minor": 0,
|
|
"worksheets": [
|
|
{
|
|
"cells": [
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"# AWS Command Lines\n",
|
|
"\n",
|
|
"* SSH to EC2\n",
|
|
"* S3cmd\n",
|
|
"* s3-parallel-put\n",
|
|
"* S3DistCp\n",
|
|
"* mrjob\n",
|
|
"* Redshift\n",
|
|
"* Kinesis\n",
|
|
"* Lambda"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"<h2 id=\"ssh-to-ec2\">SSH to EC2</h2>"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"Connect to an Ubuntu EC2 instance through SSH with the given key:"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"collapsed": false,
|
|
"input": [
|
|
"!ssh -i key.pem ubuntu@ipaddress"
|
|
],
|
|
"language": "python",
|
|
"metadata": {},
|
|
"outputs": []
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"Connect to an Amazon Linux EC2 instance through SSH with the given key:"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"collapsed": false,
|
|
"input": [
|
|
"!ssh -i key.pem ec2-user@ipaddress"
|
|
],
|
|
"language": "python",
|
|
"metadata": {},
|
|
"outputs": []
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"<h2 id=\"s3cmd\">S3cmd</h2>\n",
|
|
"\n",
|
|
"Before I discovered [S3cmd](http://s3tools.org/s3cmd), I had been using the [S3 console](http://aws.amazon.com/console/) to do basic operations and [boto](https://boto.readthedocs.org/en/latest/) to do more of the heavy lifting. However, sometimes I just want to hack away at a command line to do my work.\n",
|
|
"\n",
|
|
"I've found S3cmd to be a great command line tool for interacting with S3 on AWS. S3cmd is written in Python, is open source, and is free even for commercial use. It offers more advanced features than those found in the [AWS CLI](http://aws.amazon.com/cli/)."
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"Install s3cmd:"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"collapsed": false,
|
|
"input": [
|
|
"!sudo apt-get install s3cmd"
|
|
],
|
|
"language": "python",
|
|
"metadata": {},
|
|
"outputs": []
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"Running the following command will prompt you to enter your AWS access and AWS secret keys. To follow security best practices, make sure you are using an IAM account as opposed to using the root account.\n",
|
|
"\n",
|
|
"I also suggest enabling GPG encryption which will encrypt your data at rest, and enabling HTTPS to encrypt your data in transit. Note this might impact performance."
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"collapsed": false,
|
|
"input": [
|
|
"!s3cmd --configure"
|
|
],
|
|
"language": "python",
|
|
"metadata": {},
|
|
"outputs": []
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"Frequently used S3cmds:"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"collapsed": false,
|
|
"input": [
|
|
"# List all buckets\n",
|
|
"!s3cmd ls\n",
|
|
"\n",
|
|
"# List the contents of the bucket\n",
|
|
"!s3cmd ls s3://my-bucket-name\n",
|
|
"\n",
|
|
"# Upload a file into the bucket (private)\n",
|
|
"!s3cmd put myfile.txt s3://my-bucket-name/myfile.txt\n",
|
|
"\n",
|
|
"# Upload a file into the bucket (public)\n",
|
|
"!s3cmd put --acl-public --guess-mime-type myfile.txt s3://my-bucket-name/myfile.txt\n",
|
|
"\n",
|
|
"# Recursively upload a directory to s3\n",
|
|
"!s3cmd put --recursive my-local-folder-path/ s3://my-bucket-name/mydir/\n",
|
|
"\n",
|
|
"# Download a file\n",
|
|
"!s3cmd get s3://my-bucket-name/myfile.txt myfile.txt\n",
|
|
"\n",
|
|
"# Recursively download files that start with myfile\n",
|
|
"!s3cmd --recursive get s3://my-bucket-name/myfile\n",
|
|
"\n",
|
|
"# Delete a file\n",
|
|
"!s3cmd del s3://my-bucket-name/myfile.txt\n",
|
|
"\n",
|
|
"# Delete a bucket\n",
|
|
"!s3cmd del --recursive s3://my-bucket-name/\n",
|
|
"\n",
|
|
"# Create a bucket\n",
|
|
"!s3cmd mb s3://my-bucket-name\n",
|
|
"\n",
|
|
"# List bucket disk usage (human readable)\n",
|
|
"!s3cmd du -H s3://my-bucket-name/\n",
|
|
"\n",
|
|
"# Sync local (source) to s3 bucket (destination)\n",
|
|
"!s3cmd sync my-local-folder-path/ s3://my-bucket-name/\n",
|
|
"\n",
|
|
"# Sync s3 bucket (source) to local (destination)\n",
|
|
"!s3cmd sync s3://my-bucket-name/ my-local-folder-path/\n",
|
|
"\n",
|
|
"# Do a dry-run (do not perform actual sync, but get information about what would happen)\n",
|
|
"!s3cmd --dry-run sync s3://my-bucket-name/ my-local-folder-path/\n",
|
|
"\n",
|
|
"# Apply a standard shell wildcard include to sync s3 bucket (source) to local (destination)\n",
|
|
"!s3cmd --include '2014-05-01*' sync s3://my-bucket-name/ my-local-folder-path/"
|
|
],
|
|
"language": "python",
|
|
"metadata": {},
|
|
"outputs": []
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"<h2 id=\"s3-parallel-put\">s3-parallel-put</h2>\n",
|
|
"\n",
|
|
"[s3-parallel-put](https://github.com/twpayne/s3-parallel-put.git) is a great tool for uploading multiple files to S3 in parallel."
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"Install package dependencies:"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"collapsed": false,
|
|
"input": [
|
|
"!sudo apt-get install boto\n",
|
|
"!sudo apt-get install git"
|
|
],
|
|
"language": "python",
|
|
"metadata": {},
|
|
"outputs": []
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"Clone the s3-parallel-put repo:"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"collapsed": false,
|
|
"input": [
|
|
"!git clone https://github.com/twpayne/s3-parallel-put.git"
|
|
],
|
|
"language": "python",
|
|
"metadata": {},
|
|
"outputs": []
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"Setup AWS keys for s3-parallel-put:"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"collapsed": false,
|
|
"input": [
|
|
"!export AWS_ACCESS_KEY_ID=XXX\n",
|
|
"!export AWS_SECRET_ACCESS_KEY=XXX"
|
|
],
|
|
"language": "python",
|
|
"metadata": {},
|
|
"outputs": []
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"Sample usage:"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"collapsed": false,
|
|
"input": [
|
|
"!s3-parallel-put --bucket=bucket --prefix=PREFIX SOURCE"
|
|
],
|
|
"language": "python",
|
|
"metadata": {},
|
|
"outputs": []
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"Dry run of putting files in the current directory on S3 with the given S3 prefix, do not check first if they exist:"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"collapsed": false,
|
|
"input": [
|
|
"!s3-parallel-put --bucket=bucket --host=s3.amazonaws.com --put=stupid --dry-run --prefix=prefix/ ./"
|
|
],
|
|
"language": "python",
|
|
"metadata": {},
|
|
"outputs": []
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"<h2 id=\"s3distcp\">S3DistCp</h2>\n",
|
|
"\n",
|
|
"[S3DistCp](http://docs.aws.amazon.com/ElasticMapReduce/latest/DeveloperGuide/UsingEMR_s3distcp.html) is an extension of DistCp that is optimized to work with Amazon S3. S3DistCp is useful for combining smaller files and aggregate them together, taking in a pattern and target file to combine smaller input files to larger ones. S3DistCp can also be used to transfer large volumes of data from S3 to your Hadoop cluster."
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"To run S3DistCp with the EMR command line, ensure you are using the proper version of Ruby:"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"collapsed": false,
|
|
"input": [
|
|
"!rvm --default ruby-1.8.7-p374"
|
|
],
|
|
"language": "python",
|
|
"metadata": {},
|
|
"outputs": []
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"The EMR command line below executes the following:\n",
|
|
"* Create a master node and slave nodes of type m1.small\n",
|
|
"* Runs S3DistCp on the source bucket location and concatenates files that match the date regular expression, resulting in files that are roughly 1024 MB or 1 GB\n",
|
|
"* Places the results in the destination bucket"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"collapsed": false,
|
|
"input": [
|
|
"!./elastic-mapreduce --create --instance-group master --instance-count 1 \\\n",
|
|
"--instance-type m1.small --instance-group core --instance-count 4 \\\n",
|
|
"--instance-type m1.small --jar /home/hadoop/lib/emr-s3distcp-1.0.jar \\\n",
|
|
"--args \"--src,s3://my-bucket-source/,--groupBy,.*([0-9]{4}-01).*,\\\n",
|
|
"--dest,s3://my-bucket-dest/,--targetSize,1024\""
|
|
],
|
|
"language": "python",
|
|
"metadata": {},
|
|
"outputs": []
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"For further optimization, compression can be helpful to save on AWS storage and bandwidth costs, to speed up the S3 to/from EMR transfer, and to reduce disk I/O. Note that compressed files are not easy to split for Hadoop. For example, Hadoop uses a single mapper per GZIP file, as it does not know about file boundaries.\n",
|
|
"\n",
|
|
"What type of compression should you use?\n",
|
|
"\n",
|
|
"* Time sensitive job: Snappy or LZO\n",
|
|
"* Large amounts of data: GZIP\n",
|
|
"* General purpose: GZIP, as it\u2019s supported by most platforms\n",
|
|
"\n",
|
|
"You can specify the compression codec (gzip, lzo, snappy, or none) to use for copied files with S3DistCp with \u2013outputCodec. If no value is specified, files are copied with no compression change. The code below sets the compression to lzo:"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"collapsed": false,
|
|
"input": [
|
|
"--outputCodec,lzo"
|
|
],
|
|
"language": "python",
|
|
"metadata": {},
|
|
"outputs": []
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"<h2 id=\"mrjob\">mrjob</h2>\n",
|
|
"\n",
|
|
"[mrjob](https://pythonhosted.org/mrjob/) lets you write MapReduce jobs in Python 2.5+ and run them on several platforms. You can:\n",
|
|
"\n",
|
|
"* Write multi-step MapReduce jobs in pure Python\n",
|
|
"* Test on your local machine\n",
|
|
"* Run on a Hadoop cluster\n",
|
|
"* Run in the cloud using Amazon Elastic MapReduce (EMR)"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"Run an Amazon EMR job on the given input (must be a flat file hierarchy), placing the results in the output (output directory must not exist):"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"collapsed": false,
|
|
"input": [
|
|
"!python mr-script.py -r emr s3://bucket-source/ --output-dir=s3://bucket-dest/"
|
|
],
|
|
"language": "python",
|
|
"metadata": {},
|
|
"outputs": []
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"Run a MapReduce job locally on the specified input file, sending the results to the specified output file:"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"collapsed": false,
|
|
"input": [
|
|
"!python mrjob_script.py input_data.txt > output_data.txt"
|
|
],
|
|
"language": "python",
|
|
"metadata": {},
|
|
"outputs": []
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"Sample mrjob code that processes log files on Amazon S3 based on the [S3 logging format](http://docs.aws.amazon.com/AmazonS3/latest/dev/LogFormat.html):"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"collapsed": false,
|
|
"input": [
|
|
"%%file mr_s3_log_parser.py\n",
|
|
"\n",
|
|
"import time\n",
|
|
"from mrjob.job import MRJob\n",
|
|
"from mrjob.protocol import RawValueProtocol, ReprProtocol\n",
|
|
"import re\n",
|
|
"\n",
|
|
"\n",
|
|
"class MrS3LogParser(MRJob):\n",
|
|
" \"\"\"Parses the logs from S3 based on the S3 logging format:\n",
|
|
" http://docs.aws.amazon.com/AmazonS3/latest/dev/LogFormat.html\n",
|
|
" \n",
|
|
" Aggregates a user's daily requests by user agent and operation\n",
|
|
" \n",
|
|
" Outputs date_time, requester, user_agent, operation, count\n",
|
|
" \"\"\"\n",
|
|
"\n",
|
|
" LOGPATS = r'(\\S+) (\\S+) \\[(.*?)\\] (\\S+) (\\S+) ' \\\n",
|
|
" r'(\\S+) (\\S+) (\\S+) (\"([^\"]+)\"|-) ' \\\n",
|
|
" r'(\\S+) (\\S+) (\\S+) (\\S+) (\\S+) (\\S+) ' \\\n",
|
|
" r'(\"([^\"]+)\"|-) (\"([^\"]+)\"|-)'\n",
|
|
" NUM_ENTRIES_PER_LINE = 17\n",
|
|
" logpat = re.compile(LOGPATS)\n",
|
|
"\n",
|
|
" (S3_LOG_BUCKET_OWNER, \n",
|
|
" S3_LOG_BUCKET, \n",
|
|
" S3_LOG_DATE_TIME,\n",
|
|
" S3_LOG_IP, \n",
|
|
" S3_LOG_REQUESTER_ID, \n",
|
|
" S3_LOG_REQUEST_ID,\n",
|
|
" S3_LOG_OPERATION, \n",
|
|
" S3_LOG_KEY, \n",
|
|
" S3_LOG_HTTP_METHOD,\n",
|
|
" S3_LOG_HTTP_STATUS, \n",
|
|
" S3_LOG_S3_ERROR, \n",
|
|
" S3_LOG_BYTES_SENT,\n",
|
|
" S3_LOG_OBJECT_SIZE, \n",
|
|
" S3_LOG_TOTAL_TIME, \n",
|
|
" S3_LOG_TURN_AROUND_TIME,\n",
|
|
" S3_LOG_REFERER, \n",
|
|
" S3_LOG_USER_AGENT) = range(NUM_ENTRIES_PER_LINE)\n",
|
|
"\n",
|
|
" DELIMITER = '\\t'\n",
|
|
"\n",
|
|
" # We use RawValueProtocol for input to be format agnostic\n",
|
|
" # and avoid any type of parsing errors\n",
|
|
" INPUT_PROTOCOL = RawValueProtocol\n",
|
|
"\n",
|
|
" # We use RawValueProtocol for output so we can output raw lines\n",
|
|
" # instead of (k, v) pairs\n",
|
|
" OUTPUT_PROTOCOL = RawValueProtocol\n",
|
|
"\n",
|
|
" # Encode the intermediate records using repr() instead of JSON, so the\n",
|
|
" # record doesn't get Unicode-encoded\n",
|
|
" INTERNAL_PROTOCOL = ReprProtocol\n",
|
|
"\n",
|
|
" def clean_date_time_zone(self, raw_date_time_zone):\n",
|
|
" \"\"\"Converts entry 22/Jul/2013:21:04:17 +0000 to the format\n",
|
|
" 'YYYY-MM-DD HH:MM:SS' which is more suitable for loading into\n",
|
|
" a database such as Redshift or RDS\n",
|
|
"\n",
|
|
" Note: requires the chars \"[ ]\" to be stripped prior to input\n",
|
|
" Returns the converted datetime annd timezone\n",
|
|
" or None for both values if failed\n",
|
|
"\n",
|
|
" TODO: Needs to combine timezone with date as one field\n",
|
|
" \"\"\"\n",
|
|
" date_time = None\n",
|
|
" time_zone_parsed = None\n",
|
|
"\n",
|
|
" # TODO: Probably cleaner to parse this with a regex\n",
|
|
" date_parsed = raw_date_time_zone[:raw_date_time_zone.find(\":\")]\n",
|
|
" time_parsed = raw_date_time_zone[raw_date_time_zone.find(\":\") + 1:\n",
|
|
" raw_date_time_zone.find(\"+\") - 1]\n",
|
|
" time_zone_parsed = raw_date_time_zone[raw_date_time_zone.find(\"+\"):]\n",
|
|
"\n",
|
|
" try:\n",
|
|
" date_struct = time.strptime(date_parsed, \"%d/%b/%Y\")\n",
|
|
" converted_date = time.strftime(\"%Y-%m-%d\", date_struct)\n",
|
|
" date_time = converted_date + \" \" + time_parsed\n",
|
|
"\n",
|
|
" # Throws a ValueError exception if the operation fails that is\n",
|
|
" # caught by the calling function and is handled appropriately\n",
|
|
" except ValueError as error:\n",
|
|
" raise ValueError(error)\n",
|
|
" else:\n",
|
|
" return converted_date, date_time, time_zone_parsed\n",
|
|
"\n",
|
|
" def mapper(self, _, line):\n",
|
|
" line = line.strip()\n",
|
|
" match = self.logpat.search(line)\n",
|
|
"\n",
|
|
" date_time = None\n",
|
|
" requester = None\n",
|
|
" user_agent = None\n",
|
|
" operation = None\n",
|
|
"\n",
|
|
" try:\n",
|
|
" for n in range(self.NUM_ENTRIES_PER_LINE):\n",
|
|
" group = match.group(1 + n)\n",
|
|
"\n",
|
|
" if n == self.S3_LOG_DATE_TIME:\n",
|
|
" date, date_time, time_zone_parsed = \\\n",
|
|
" self.clean_date_time_zone(group)\n",
|
|
" # Leave the following line of code if \n",
|
|
" # you want to aggregate by date\n",
|
|
" date_time = date + \" 00:00:00\"\n",
|
|
" elif n == self.S3_LOG_REQUESTER_ID:\n",
|
|
" requester = group\n",
|
|
" elif n == self.S3_LOG_USER_AGENT:\n",
|
|
" user_agent = group\n",
|
|
" elif n == self.S3_LOG_OPERATION:\n",
|
|
" operation = group\n",
|
|
" else:\n",
|
|
" pass\n",
|
|
"\n",
|
|
" except Exception:\n",
|
|
" yield ((\"Error while parsing line: %s\", line), 1)\n",
|
|
" else:\n",
|
|
" yield ((date_time, requester, user_agent, operation), 1)\n",
|
|
"\n",
|
|
" def reducer(self, key, values):\n",
|
|
" output = list(key)\n",
|
|
" output = self.DELIMITER.join(output) + \\\n",
|
|
" self.DELIMITER + \\\n",
|
|
" str(sum(values))\n",
|
|
"\n",
|
|
" yield None, output\n",
|
|
"\n",
|
|
" def steps(self):\n",
|
|
" return [\n",
|
|
" self.mr(mapper=self.mapper,\n",
|
|
" reducer=self.reducer)\n",
|
|
" ]\n",
|
|
"\n",
|
|
"\n",
|
|
"if __name__ == '__main__':\n",
|
|
" MrS3LogParser.run()"
|
|
],
|
|
"language": "python",
|
|
"metadata": {},
|
|
"outputs": []
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"Accompanying unit test:"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"collapsed": false,
|
|
"input": [
|
|
"%%file test_mr_s3_log_parser.py\n",
|
|
"\n",
|
|
"from StringIO import StringIO\n",
|
|
"import unittest2 as unittest\n",
|
|
"from mr_s3_log_parser import MrS3LogParser\n",
|
|
"\n",
|
|
"\n",
|
|
"class MrTestsUtil:\n",
|
|
"\n",
|
|
" def run_mr_sandbox(self, mr_job, stdin):\n",
|
|
" # inline runs the job in the same process so small jobs tend to\n",
|
|
" # run faster and stack traces are simpler\n",
|
|
" # --no-conf prevents options from local mrjob.conf from polluting\n",
|
|
" # the testing environment\n",
|
|
" # \"-\" reads from standard in\n",
|
|
" mr_job.sandbox(stdin=stdin)\n",
|
|
"\n",
|
|
" # make_runner ensures job cleanup is performed regardless of\n",
|
|
" # success or failure\n",
|
|
" with mr_job.make_runner() as runner:\n",
|
|
" runner.run()\n",
|
|
" for line in runner.stream_output():\n",
|
|
" key, value = mr_job.parse_output_line(line)\n",
|
|
" yield value\n",
|
|
"\n",
|
|
" \n",
|
|
"class TestMrS3LogParser(unittest.TestCase):\n",
|
|
"\n",
|
|
" mr_job = None\n",
|
|
" mr_tests_util = None\n",
|
|
"\n",
|
|
" RAW_LOG_LINE_INVALID = \\\n",
|
|
" '00000fe9688b6e57f75bd2b7f7c1610689e8f01000000' \\\n",
|
|
" '00000388225bcc00000 ' \\\n",
|
|
" 's3-storage [22/Jul/2013:21:03:27 +0000] ' \\\n",
|
|
" '00.111.222.33 ' \\\n",
|
|
"\n",
|
|
" RAW_LOG_LINE_VALID = \\\n",
|
|
" '00000fe9688b6e57f75bd2b7f7c1610689e8f01000000' \\\n",
|
|
" '00000388225bcc00000 ' \\\n",
|
|
" 's3-storage [22/Jul/2013:21:03:27 +0000] ' \\\n",
|
|
" '00.111.222.33 ' \\\n",
|
|
" 'arn:aws:sts::000005646931:federated-user/user 00000AB825500000 ' \\\n",
|
|
" 'REST.HEAD.OBJECT user/file.pdf ' \\\n",
|
|
" '\"HEAD /user/file.pdf?versionId=00000XMHZJp6DjM9x500000' \\\n",
|
|
" '00000SDZk ' \\\n",
|
|
" 'HTTP/1.1\" 200 - - 4000272 18 - \"-\" ' \\\n",
|
|
" '\"Boto/2.5.1 (darwin) USER-AGENT/1.0.14.0\" ' \\\n",
|
|
" '00000XMHZJp6DjM9x5JVEAMo8MG00000'\n",
|
|
"\n",
|
|
" DATE_TIME_ZONE_INVALID = \"AB/Jul/2013:21:04:17 +0000\"\n",
|
|
" DATE_TIME_ZONE_VALID = \"22/Jul/2013:21:04:17 +0000\"\n",
|
|
" DATE_VALID = \"2013-07-22\"\n",
|
|
" DATE_TIME_VALID = \"2013-07-22 21:04:17\"\n",
|
|
" TIME_ZONE_VALID = \"+0000\"\n",
|
|
"\n",
|
|
" def __init__(self, *args, **kwargs):\n",
|
|
" super(TestMrS3LogParser, self).__init__(*args, **kwargs)\n",
|
|
" self.mr_job = MrS3LogParser(['-r', 'inline', '--no-conf', '-'])\n",
|
|
" self.mr_tests_util = MrTestsUtil()\n",
|
|
"\n",
|
|
" def test_invalid_log_lines(self):\n",
|
|
" stdin = StringIO(self.RAW_LOG_LINE_INVALID)\n",
|
|
"\n",
|
|
" for result in self.mr_tests_util.run_mr_sandbox(self.mr_job, stdin):\n",
|
|
" self.assertEqual(result.find(\"Error\"), 0)\n",
|
|
"\n",
|
|
" def test_valid_log_lines(self):\n",
|
|
" stdin = StringIO(self.RAW_LOG_LINE_VALID)\n",
|
|
"\n",
|
|
" for result in self.mr_tests_util.run_mr_sandbox(self.mr_job, stdin):\n",
|
|
" self.assertEqual(result.find(\"Error\"), -1)\n",
|
|
"\n",
|
|
" def test_clean_date_time_zone(self):\n",
|
|
" date, date_time, time_zone_parsed = \\\n",
|
|
" self.mr_job.clean_date_time_zone(self.DATE_TIME_ZONE_VALID)\n",
|
|
" self.assertEqual(date, self.DATE_VALID)\n",
|
|
" self.assertEqual(date_time, self.DATE_TIME_VALID)\n",
|
|
" self.assertEqual(time_zone_parsed, self.TIME_ZONE_VALID)\n",
|
|
"\n",
|
|
" # Use a lambda to delay the calling of clean_date_time_zone so that\n",
|
|
" # assertRaises has enough time to handle it properly\n",
|
|
" self.assertRaises(ValueError,\n",
|
|
" lambda: self.mr_job.clean_date_time_zone(\n",
|
|
" self.DATE_TIME_ZONE_INVALID))\n",
|
|
"\n",
|
|
"if __name__ == '__main__':\n",
|
|
" unittest.main()\n",
|
|
"\n"
|
|
],
|
|
"language": "python",
|
|
"metadata": {},
|
|
"outputs": []
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"Run the mrjob test:"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"collapsed": false,
|
|
"input": [
|
|
"!python test_mr_s3_log_parser.py -v"
|
|
],
|
|
"language": "python",
|
|
"metadata": {},
|
|
"outputs": []
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"<h2 id=\"redshift\">Redshift</h2>"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"Copy values from the given S3 location containing CSV files to a Redshift cluster:"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"collapsed": false,
|
|
"input": [
|
|
"copy table_name from 's3://source/part'\n",
|
|
"credentials 'aws_access_key_id=XXX;aws_secret_access_key=XXX'\n",
|
|
"csv;"
|
|
],
|
|
"language": "python",
|
|
"metadata": {},
|
|
"outputs": []
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"Copy values from the given location containing TSV files to a Redshift cluster:"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"collapsed": false,
|
|
"input": [
|
|
"copy table_name from 's3://source/part'\n",
|
|
"credentials 'aws_access_key_id=XXX;aws_secret_access_key=XXX'\n",
|
|
"csv delimiter '\\t';"
|
|
],
|
|
"language": "python",
|
|
"metadata": {},
|
|
"outputs": []
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"View Redshift errors:"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"collapsed": false,
|
|
"input": [
|
|
"select * from stl_load_errors;"
|
|
],
|
|
"language": "python",
|
|
"metadata": {},
|
|
"outputs": []
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"Vacuum Redshift in full:"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"collapsed": false,
|
|
"input": [
|
|
"VACUUM FULL;"
|
|
],
|
|
"language": "python",
|
|
"metadata": {},
|
|
"outputs": []
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"Analyze the compression of a table:"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"collapsed": false,
|
|
"input": [
|
|
"analyze compression table_name;"
|
|
],
|
|
"language": "python",
|
|
"metadata": {},
|
|
"outputs": []
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"Cancel the query with the specified id:"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"collapsed": false,
|
|
"input": [
|
|
"cancel 18764;"
|
|
],
|
|
"language": "python",
|
|
"metadata": {},
|
|
"outputs": []
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"The CANCEL command will not abort a transaction. To abort or roll back a transaction, you must use the ABORT or ROLLBACK command. To cancel a query associated with a transaction, first cancel the query then abort the transaction.\n",
|
|
"\n",
|
|
"If the query that you canceled is associated with a transaction, use the ABORT or ROLLBACK. command to cancel the transaction and discard any changes made to the data:"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"collapsed": false,
|
|
"input": [
|
|
"abort;"
|
|
],
|
|
"language": "python",
|
|
"metadata": {},
|
|
"outputs": []
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"Reference table creation and setup:"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"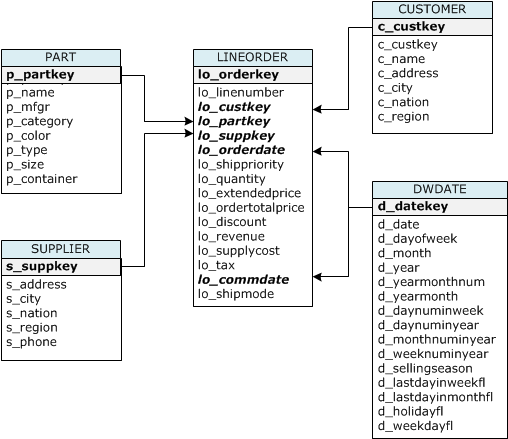"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"collapsed": false,
|
|
"input": [
|
|
"CREATE TABLE part (\n",
|
|
" p_partkey integer not null sortkey distkey,\n",
|
|
" p_name varchar(22) not null,\n",
|
|
" p_mfgr varchar(6) not null,\n",
|
|
" p_category varchar(7) not null,\n",
|
|
" p_brand1 varchar(9) not null,\n",
|
|
" p_color varchar(11) not null,\n",
|
|
" p_type varchar(25) not null,\n",
|
|
" p_size integer not null,\n",
|
|
" p_container varchar(10) not null\n",
|
|
");\n",
|
|
"\n",
|
|
"CREATE TABLE supplier (\n",
|
|
" s_suppkey integer not null sortkey,\n",
|
|
" s_name varchar(25) not null,\n",
|
|
" s_address varchar(25) not null,\n",
|
|
" s_city varchar(10) not null,\n",
|
|
" s_nation varchar(15) not null,\n",
|
|
" s_region varchar(12) not null,\n",
|
|
" s_phone varchar(15) not null)\n",
|
|
"diststyle all;\n",
|
|
"\n",
|
|
"CREATE TABLE customer (\n",
|
|
" c_custkey integer not null sortkey,\n",
|
|
" c_name varchar(25) not null,\n",
|
|
" c_address varchar(25) not null,\n",
|
|
" c_city varchar(10) not null,\n",
|
|
" c_nation varchar(15) not null,\n",
|
|
" c_region varchar(12) not null,\n",
|
|
" c_phone varchar(15) not null,\n",
|
|
" c_mktsegment varchar(10) not null)\n",
|
|
"diststyle all;\n",
|
|
"\n",
|
|
"CREATE TABLE dwdate (\n",
|
|
" d_datekey integer not null sortkey,\n",
|
|
" d_date varchar(19) not null,\n",
|
|
" d_dayofweek varchar(10) not null,\n",
|
|
" d_month varchar(10) not null,\n",
|
|
" d_year integer not null,\n",
|
|
" d_yearmonthnum integer not null,\n",
|
|
" d_yearmonth varchar(8) not null,\n",
|
|
" d_daynuminweek integer not null,\n",
|
|
" d_daynuminmonth integer not null,\n",
|
|
" d_daynuminyear integer not null,\n",
|
|
" d_monthnuminyear integer not null,\n",
|
|
" d_weeknuminyear integer not null,\n",
|
|
" d_sellingseason varchar(13) not null,\n",
|
|
" d_lastdayinweekfl varchar(1) not null,\n",
|
|
" d_lastdayinmonthfl varchar(1) not null,\n",
|
|
" d_holidayfl varchar(1) not null,\n",
|
|
" d_weekdayfl varchar(1) not null)\n",
|
|
"diststyle all;\n",
|
|
"\n",
|
|
"CREATE TABLE lineorder (\n",
|
|
" lo_orderkey integer not null,\n",
|
|
" lo_linenumber integer not null,\n",
|
|
" lo_custkey integer not null,\n",
|
|
" lo_partkey integer not null distkey,\n",
|
|
" lo_suppkey integer not null,\n",
|
|
" lo_orderdate integer not null sortkey,\n",
|
|
" lo_orderpriority varchar(15) not null,\n",
|
|
" lo_shippriority varchar(1) not null,\n",
|
|
" lo_quantity integer not null,\n",
|
|
" lo_extendedprice integer not null,\n",
|
|
" lo_ordertotalprice integer not null,\n",
|
|
" lo_discount integer not null,\n",
|
|
" lo_revenue integer not null,\n",
|
|
" lo_supplycost integer not null,\n",
|
|
" lo_tax integer not null,\n",
|
|
" lo_commitdate integer not null,\n",
|
|
" lo_shipmode varchar(10) not null\n",
|
|
");"
|
|
],
|
|
"language": "python",
|
|
"metadata": {},
|
|
"outputs": []
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"| Table name | Sort Key | Distribution Style |\n",
|
|
"|------------|--------------|--------------------|\n",
|
|
"| LINEORDER | lo_orderdate | lo_partkey |\n",
|
|
"| PART | p_partkey | p_partkey |\n",
|
|
"| CUSTOMER | c_custkey | ALL |\n",
|
|
"| SUPPLIER | s_suppkey | ALL |\n",
|
|
"| DWDATE | d_datekey | ALL |"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"[Sort Keys](http://docs.aws.amazon.com/redshift/latest/dg/tutorial-tuning-tables-sort-keys.html)\n",
|
|
"\n",
|
|
"When you create a table, you can specify one or more columns as the sort key. Amazon Redshift stores your data on disk in sorted order according to the sort key. How your data is sorted has an important effect on disk I/O, columnar compression, and query performance.\n",
|
|
"\n",
|
|
"Choose sort keys for based on these best practices:\n",
|
|
"\n",
|
|
"If recent data is queried most frequently, specify the timestamp column as the leading column for the sort key.\n",
|
|
"\n",
|
|
"If you do frequent range filtering or equality filtering on one column, specify that column as the sort key.\n",
|
|
"\n",
|
|
"If you frequently join a (dimension) table, specify the join column as the sort key."
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"[Distribution Styles](http://docs.aws.amazon.com/redshift/latest/dg/c_choosing_dist_sort.html)\n",
|
|
"\n",
|
|
"When you create a table, you designate one of three distribution styles: KEY, ALL, or EVEN.\n",
|
|
"\n",
|
|
"**KEY distribution**\n",
|
|
"\n",
|
|
"The rows are distributed according to the values in one column. The leader node will attempt to place matching values on the same node slice. If you distribute a pair of tables on the joining keys, the leader node collocates the rows on the slices according to the values in the joining columns so that matching values from the common columns are physically stored together.\n",
|
|
"\n",
|
|
"**ALL distribution**\n",
|
|
"\n",
|
|
"A copy of the entire table is distributed to every node. Where EVEN distribution or KEY distribution place only a portion of a table's rows on each node, ALL distribution ensures that every row is collocated for every join that the table participates in.\n",
|
|
"\n",
|
|
"**EVEN distribution**\n",
|
|
"\n",
|
|
"The rows are distributed across the slices in a round-robin fashion, regardless of the values in any particular column. EVEN distribution is appropriate when a table does not participate in joins or when there is not a clear choice between KEY distribution and ALL distribution. EVEN distribution is the default distribution style."
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"<h2 id=\"kinesis\">Kinesis</h2>"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"Create a stream:"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"collapsed": false,
|
|
"input": [
|
|
"!aws kinesis create-stream --stream-name Foo --shard-count 1 --profile adminuser"
|
|
],
|
|
"language": "python",
|
|
"metadata": {},
|
|
"outputs": []
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"List all streams:"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"collapsed": false,
|
|
"input": [
|
|
"!aws kinesis list-streams --profile adminuser"
|
|
],
|
|
"language": "python",
|
|
"metadata": {},
|
|
"outputs": []
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"Get info about the stream:"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"collapsed": false,
|
|
"input": [
|
|
"!aws kinesis describe-stream --stream-name Foo --profile adminuser"
|
|
],
|
|
"language": "python",
|
|
"metadata": {},
|
|
"outputs": []
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"Put a record to the stream:"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"collapsed": false,
|
|
"input": [
|
|
"!aws kinesis put-record --stream-name Foo --data \"SGVsbG8sIHRoaXMgaXMgYSB0ZXN0IDEyMy4=\" --partition-key shardId-000000000000 --region us-east-1 --profile adminuser"
|
|
],
|
|
"language": "python",
|
|
"metadata": {},
|
|
"outputs": []
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"Get records from a given shard:"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"collapsed": false,
|
|
"input": [
|
|
"!SHARD_ITERATOR=$(aws kinesis get-shard-iterator --shard-id shardId-000000000000 --shard-iterator-type TRIM_HORIZON --stream-name Foo --query 'ShardIterator' --profile adminuser)\n",
|
|
"aws kinesis get-records --shard-iterator $SHARD_ITERATOR"
|
|
],
|
|
"language": "python",
|
|
"metadata": {},
|
|
"outputs": []
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"Delete a stream:"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"collapsed": false,
|
|
"input": [
|
|
"!aws kinesis delete-stream --stream-name Foo --profile adminuser"
|
|
],
|
|
"language": "python",
|
|
"metadata": {},
|
|
"outputs": []
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"<h2 id=\"lambda\">Lambda</h2>"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"List lambda functions:"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"collapsed": false,
|
|
"input": [
|
|
"!aws lambda list-functions \\\n",
|
|
" --region us-east-1 \\\n",
|
|
" --max-items 10"
|
|
],
|
|
"language": "python",
|
|
"metadata": {},
|
|
"outputs": []
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"Upload a lambda function:"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"collapsed": false,
|
|
"input": [
|
|
"!aws lambda upload-function \\\n",
|
|
" --region us-east-1 \\\n",
|
|
" --function-name foo \\\n",
|
|
" --function-zip file-path/foo.zip \\\n",
|
|
" --role IAM-role-ARN \\\n",
|
|
" --mode event \\\n",
|
|
" --handler foo.handler \\\n",
|
|
" --runtime nodejs \\\n",
|
|
" --debug"
|
|
],
|
|
"language": "python",
|
|
"metadata": {},
|
|
"outputs": []
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"Invoke a lambda function:"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"collapsed": false,
|
|
"input": [
|
|
"!aws lambda invoke-async \\\n",
|
|
" --function-name foo \\\n",
|
|
" --region us-east-1 \\\n",
|
|
" --invoke-args foo.txt \\\n",
|
|
" --debug"
|
|
],
|
|
"language": "python",
|
|
"metadata": {},
|
|
"outputs": []
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"Return metadata for a specific function:"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"collapsed": false,
|
|
"input": [
|
|
"!aws lambda get-function-configuration \\\n",
|
|
" --function-name helloworld \\\n",
|
|
" --region us-east-1 \\\n",
|
|
" --debug"
|
|
],
|
|
"language": "python",
|
|
"metadata": {},
|
|
"outputs": []
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"Return metadata for a specific function along with a presigned URL that you can use to download the function's .zip file that you uploaded:"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"collapsed": false,
|
|
"input": [
|
|
"!aws lambda get-function \\\n",
|
|
" --function-name helloworld \\\n",
|
|
" --region us-east-1 \\\n",
|
|
" --debug"
|
|
],
|
|
"language": "python",
|
|
"metadata": {},
|
|
"outputs": []
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"Add an event source:"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"collapsed": false,
|
|
"input": [
|
|
"!aws lambda add-event-source \\\n",
|
|
" --region us-east-1 \\\n",
|
|
" --function-name ProcessKinesisRecords \\\n",
|
|
" --role invocation-role-arn \\\n",
|
|
" --event-source kinesis-stream-arn \\\n",
|
|
" --batch-size 100 \\\n",
|
|
" --profile adminuser"
|
|
],
|
|
"language": "python",
|
|
"metadata": {},
|
|
"outputs": []
|
|
},
|
|
{
|
|
"cell_type": "markdown",
|
|
"metadata": {},
|
|
"source": [
|
|
"Delete a lambda function:"
|
|
]
|
|
},
|
|
{
|
|
"cell_type": "code",
|
|
"collapsed": false,
|
|
"input": [
|
|
"!aws lambda delete-function \\\n",
|
|
" --function-name helloworld \\\n",
|
|
" --region us-east-1 \\\n",
|
|
" --debug"
|
|
],
|
|
"language": "python",
|
|
"metadata": {},
|
|
"outputs": []
|
|
}
|
|
],
|
|
"metadata": {}
|
|
}
|
|
]
|
|
} |