|
|
||
|---|---|---|
| analyses | ||
| aws | ||
| commands | ||
| data | ||
| images | ||
| kaggle | ||
| mapreduce | ||
| matplotlib | ||
| misc | ||
| numpy | ||
| pandas | ||
| python-data | ||
| scikit-learn | ||
| scipy | ||
| spark | ||
| __init__.py | ||
| .gitignore | ||
| LICENSE | ||
| README.md | ||
| requirements.txt | ||
data-science-ipython-notebooks
Continually updated Data Science IPython Notebooks.
This repo is a collection of IPython Notebooks I reference while working with data. Although I developed and maintain most notebooks, some notebooks I reference were created by other authors, who are credited within their notebook(s) by providing their names and/or a link to their source.
For detailed instructions, scripts, and tools to more optimally set up your development environment for data analysis, check out the dev-setup repo.
Index
- spark
- mapreduce-python
- amazon web services
- kaggle-and-business-analyses
- scikit-learn
- statistical-inference-scipy
- pandas
- matplotlib
- numpy
- python-data
- command lines
- misc
- notebook-installation
- credits
- contributing
- contact-info
- license

spark
IPython Notebook(s) demonstrating spark and HDFS functionality.
| Notebook | Description |
|---|---|
| spark | In-memory cluster computing framework, up to 100 times faster for certain applications and is well suited for machine learning algorithms. |
| hdfs | Reliably stores very large files across machines in a large cluster. |

mapreduce-python
IPython Notebook(s) demonstrating Hadoop MapReduce with mrjob functionality.
| Notebook | Description |
|---|---|
| mapreduce-python | Supports MapReduce jobs in Python with mrjob, running them locally or on Hadoop clusters. Demonstrates mrjob code, unit test, and config file to analyze Amazon S3 bucket logs on Elastic MapReduce. Disco is another python-based alternative. |

aws
IPython Notebook(s) demonstrating Amazon Web Services (AWS) and AWS tools functionality.
| Notebook | Description |
|---|---|
| boto | Official AWS SDK for Python. |
| s3cmd | Interacts with S3 through the command line. |
| s3distcp | Combines smaller files and aggregates them together by taking in a pattern and target file. S3DistCp can also be used to transfer large volumes of data from S3 to your Hadoop cluster. |
| s3-parallel-put | Uploads multiple files to S3 in parallel. |
| redshift | Acts as a fast data warehouse built on top of technology from massive parallel processing (MPP). |
| kinesis | Streams data in real time with the ability to process thousands of data streams per second. |
| lambda | Runs code in response to events, automatically managing compute resources. |

kaggle-and-business-analyses
IPython Notebook(s) used in kaggle competitions and business analyses.
| Notebook | Description |
|---|---|
| titanic | Predicts survival on the Titanic. Demonstrates data cleaning, exploratory data analysis, and machine learning. |
| churn-analysis | Predicts customer churn. Exercises logistic regression, gradient boosting classifers, support vector machines, random forests, and k-nearest-neighbors. Discussion of confusion matrices, ROC plots, feature importances, prediction probabilities, and calibration/descrimination. |

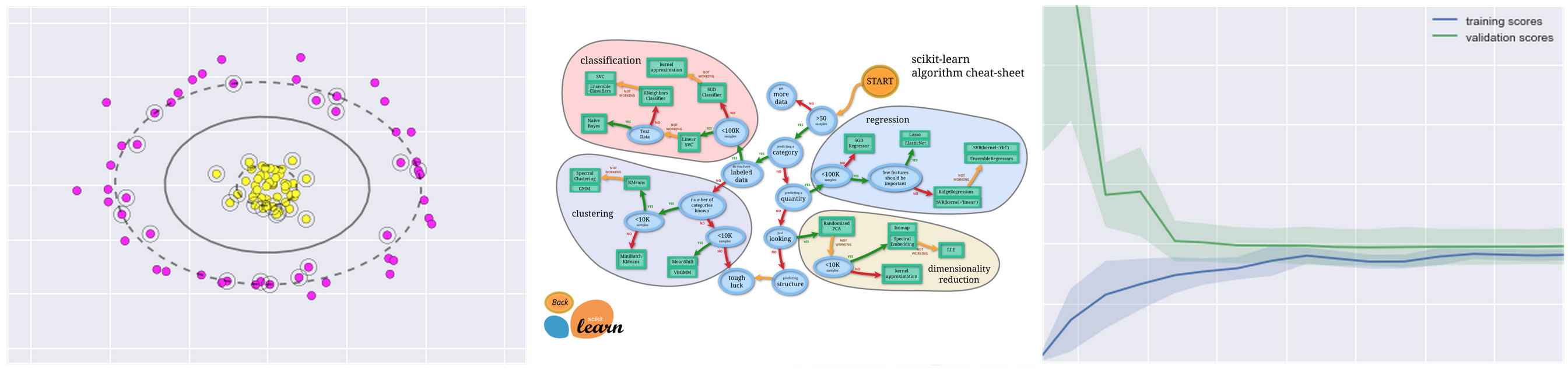
scikit-learn
IPython Notebook(s) demonstrating scikit-learn functionality.
| Notebook | Description |
|---|---|
| intro | Intro notebook to scikit-learn. Scikit-learn adds Python support for large, multi-dimensional arrays and matrices, along with a large library of high-level mathematical functions to operate on these arrays. |
| knn | K-nearest neighbors. |
| linear-reg | Linear regression. |
| svm | Support vector machine classifier, with and without kernels. |
| random-forest | Random forest classifier and regressor. |
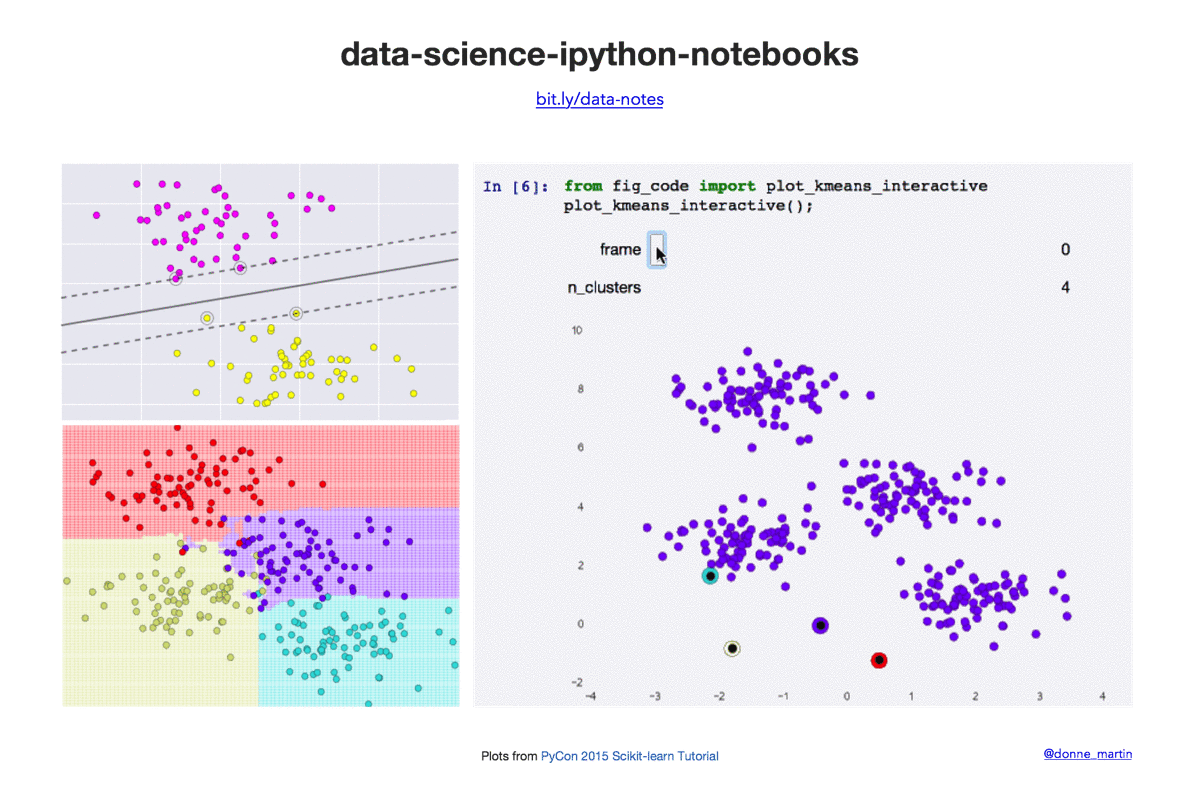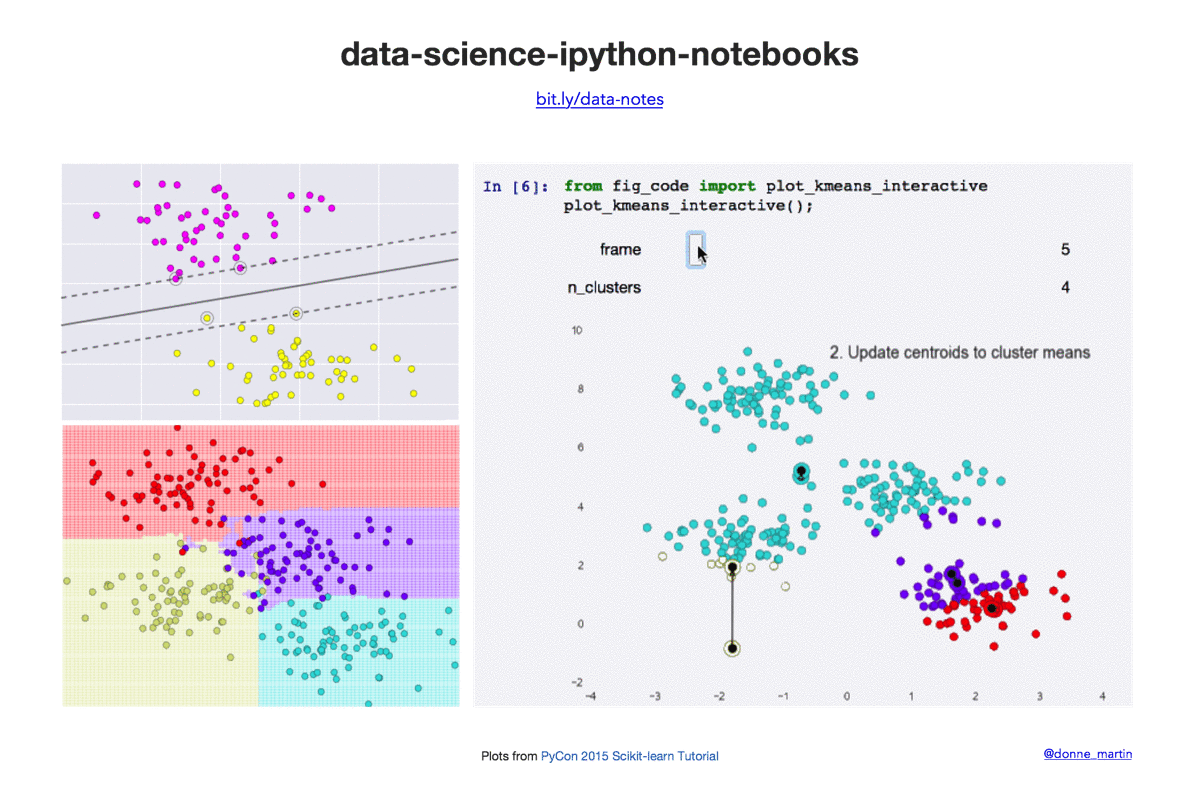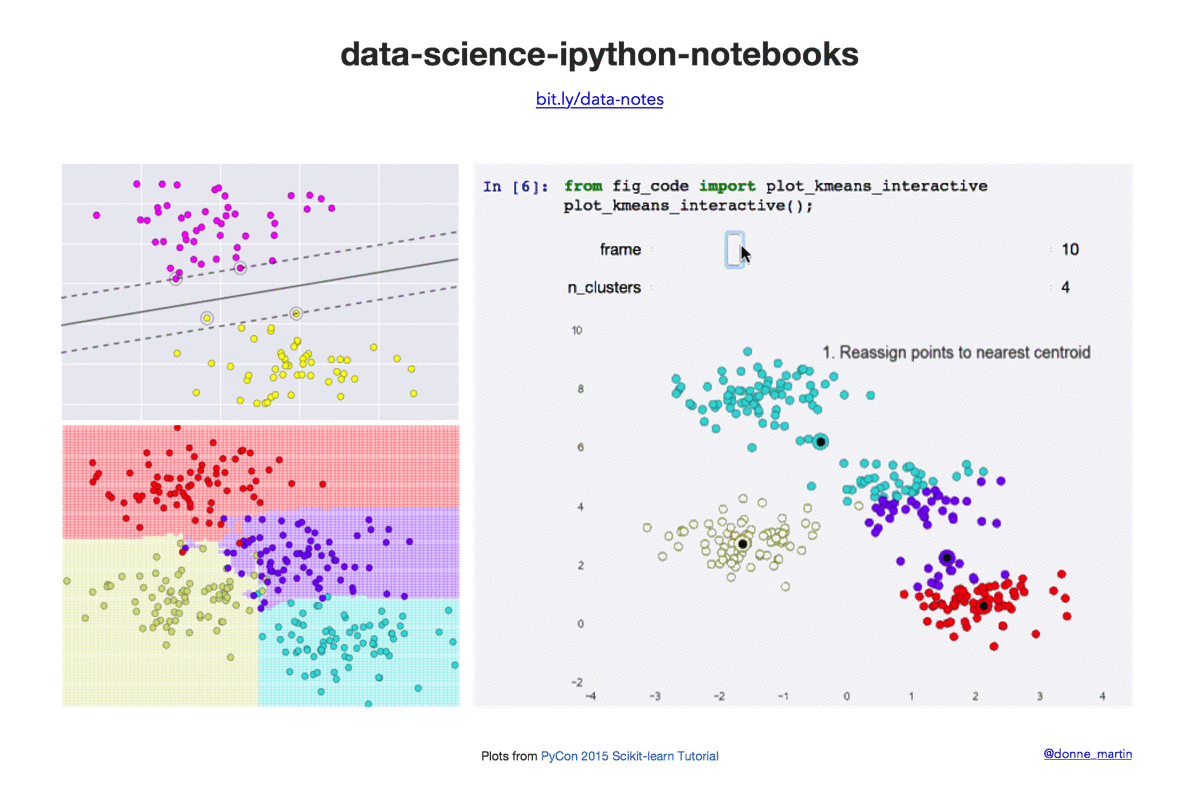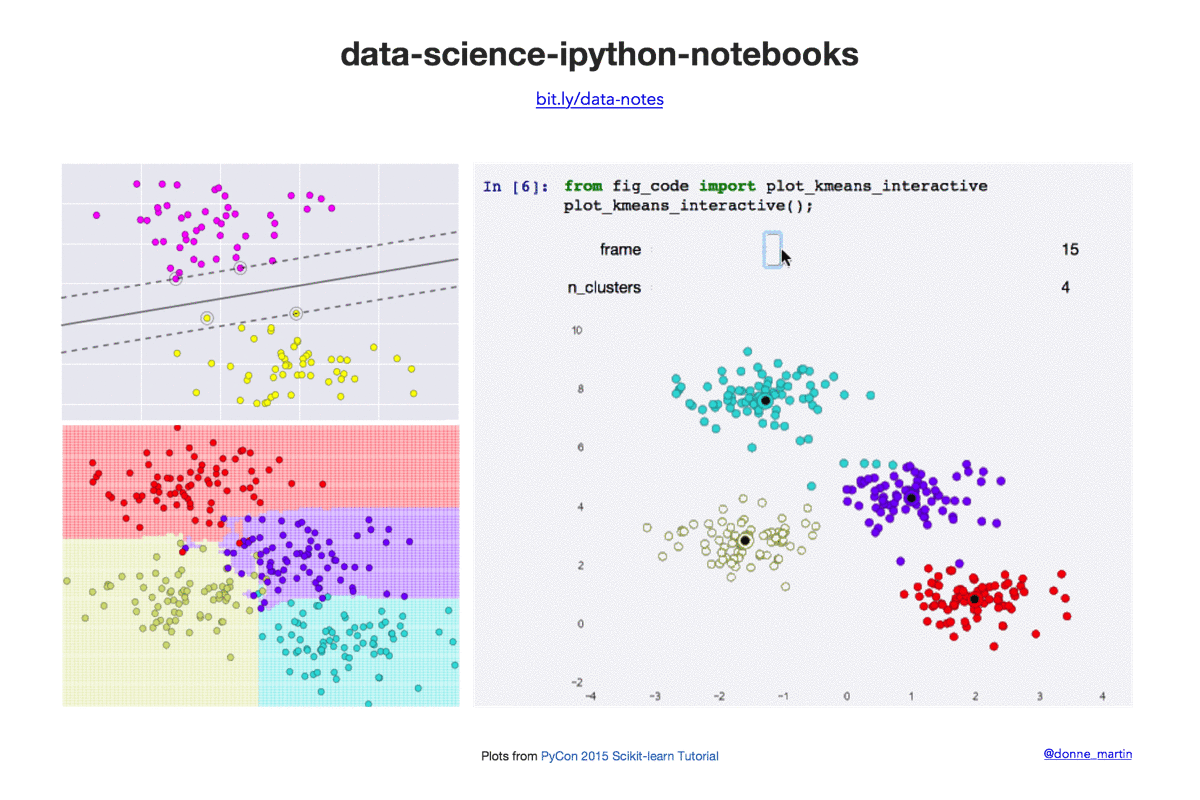
| k-means | K-means clustering. |
| pca | Principal component analysis. |
| gmm | Gaussian mixture models. |
| validation | Validation and model selection. |

statistical-inference-scipy
| Notebook | Description |
|---|---|
| scipy | SciPy is a collection of mathematical algorithms and convenience functions built on the Numpy extension of Python. It adds significant power to the interactive Python session by providing the user with high-level commands and classes for manipulating and visualizing data. |
| effect_size | Effect size. |
| sampling | Random sampling. |
| hypothesis | Hypothesis testing. |

pandas
IPython Notebook(s) demonstrating pandas functionality.
| Notebook | Description |
|---|---|
| pandas | Software library written for data manipulation and analysis in Python. Offers data structures and operations for manipulating numerical tables and time series. |
matplotlib
IPython Notebook(s) demonstrating matplotlib functionality.
| Notebook | Description |
|---|---|
| matplotlib | Python 2D plotting library which produces publication quality figures in a variety of hardcopy formats and interactive environments across platforms. |
| matplotlib-applied | Matplotlib visualizations appied to Kaggle competitions for exploratory data analysis. Examples of bar plots, histograms, subplot2grid, normalized plots, scatter plots, subplots, and kernel density estimation plots. |

numpy
IPython Notebook(s) demonstrating NumPy functionality.
| Notebook | Description |
|---|---|
| numpy | Adds Python support for large, multi-dimensional arrays and matrices, along with a large library of high-level mathematical functions to operate on these arrays. |

python-data
IPython Notebook(s) demonstrating Python functionality geared towards data analysis.
| Notebook | Description |
|---|---|
| data structures | Tuples, lists, dicts, sets. |
| data structure utilities | Slice, range, xrange, bisect, sort, sorted, reversed, enumerate, zip, list comprehensions. |
| functions | Functions as objects, lambda functions, closures, *args, **kwargs currying, generators, generator expressions, itertools. |
| datetime | Datetime, strftime, strptime, timedelta. |
| logging | Logging with RotatingFileHandler and TimedRotatingFileHandler. |
| pdb | Interactive source code debugger. |
| unit tests | Nose unit tests. |

commands
IPython Notebook(s) demonstrating various command lines for Linux, Git, etc.
| Notebook | Description |
|---|---|
| linux | Unix-like and mostly POSIX-compliant computer operating system. Disk usage, splitting files, grep, sed, curl, viewing running processes, terminal syntax highlighting, and Vim. |
| anaconda | Distribution of the Python programming language for large-scale data processing, predictive analytics, and scientific computing, that aims to simplify package management and deployment. |
| ipython notebook | Web-based interactive computational environment where you can combine code execution, text, mathematics, plots and rich media into a single document. |
| git | Distributed revision control system with an emphasis on speed, data integrity, and support for distributed, non-linear workflows. |
| ruby | Used to interact with the AWS command line and for Jekyll, a blog framework that can be hosted on GitHub Pages. |
| jekyll | Simple, blog-aware, static site generator for personal, project, or organization sites. Renders Markdown or Textile and Liquid templates, and produces a complete, static website ready to be served by Apache HTTP Server, Nginx or another web server. Pelican is a python-based alternative. |
| django | High-level Python Web framework that encourages rapid development and clean, pragmatic design. It can be useful to share reports/analyses and for blogging. Lighter-weight alternatives include Pyramid, Flask, Tornado, and Bottle. |
misc
IPython Notebook(s) demonstrating miscellaneous functionality.
| Notebook | Description |
|---|---|
| regex | Regular expression cheat sheet useful in data wrangling. |
notebook-installation
anaconda
Anaconda is a free distribution of the Python programming language for large-scale data processing, predictive analytics, and scientific computing that aims to simplify package management and deployment.
Follow instructions to install Anaconda or the more lightweight miniconda.
pip-requirements
If you prefer to use a more lightweight installation procedure than Anaconda, first clone the repo then run the following pip command on the provided requirements.txt file:
$ pip install -r requirements.txt
running-notebooks
To view interactive content or to modify elements within the IPython notebooks, you must first clone or download the repository then run the ipython notebook. More information on IPython Notebooks can be found here.
$ git clone https://github.com/donnemartin/data-science-ipython-notebooks.git
$ cd data-science-ipython-notebooks
$ ipython notebook
Notebooks tested with Python 2.7.x.
credits
- Python for Data Analysis: Data Wrangling with Pandas, NumPy, and IPython by Wes McKinney
- PyCon 2015 Scikit-learn Tutorial by Jake VanderPlas
- Parallel Machine Learning with scikit-learn and IPython by Olivier Grisel
- Statistical Interference Using Computational Methods in Python by Allen Downey
- Yhat Blog by Yhat
- Kaggle by Kaggle
- Spark Docs by Apache Spark
- AWS Docs by Amazon Web Services
contributing
Contributions are welcome! For bug reports or requests please submit an issue.
contact-info
Feel free to contact me to discuss any issues, questions, or comments.
- Email: donne.martin@gmail.com
- Twitter: @donne_martin
- GitHub: donnemartin
- LinkedIn: donnemartin
- Website: donnemartin.com
license
This repository contains a variety of content; some developed by Donne Martin, and some from third-parties. The third-party content is distributed under the license provided by those parties.
The content developed by Donne Martin is distributed under the following license:
Copyright 2015 Donne Martin
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.