mirror of
https://github.com/donnemartin/data-science-ipython-notebooks.git
synced 2024-03-22 13:30:56 +08:00
Added Redshift reference tables for create, sort key, dist key, and discussions on how to choose the appropriate keys.
This commit is contained in:
parent
17e7736974
commit
14ea9025c1
152
aws/aws.ipynb
152
aws/aws.ipynb
|
|
@ -1,7 +1,7 @@
|
|||
{
|
||||
"metadata": {
|
||||
"name": "",
|
||||
"signature": "sha256:db6ce15c2920169c4db02cf87f3c86fba56a73d96b8b710f037c3304434f9071"
|
||||
"signature": "sha256:bcaf53e50215c57cb4a91ea44895e0e87bc885288dd093cddf3777133df410f1"
|
||||
},
|
||||
"nbformat": 3,
|
||||
"nbformat_minor": 0,
|
||||
|
|
@ -345,7 +345,7 @@
|
|||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Run an mrjob on the given input (must be a flat file hierarchy), placing the results in the output (output directory must not exist):"
|
||||
"Run a MapReduce job on the given input (must be a flat file hierarchy), placing the results in the output (output directory must not exist):"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
|
@ -362,7 +362,7 @@
|
|||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Run an mrjob locally on the specified input file, sending the results to the specified output file:"
|
||||
"Run a MapReduce job locally on the specified input file, sending the results to the specified output file:"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
|
@ -506,6 +506,152 @@
|
|||
"language": "python",
|
||||
"metadata": {},
|
||||
"outputs": []
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Reference table creation and setup:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"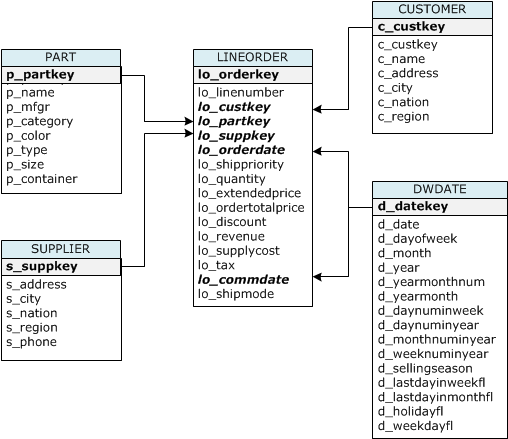"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"collapsed": false,
|
||||
"input": [
|
||||
"CREATE TABLE part (\n",
|
||||
" p_partkey integer not null sortkey distkey,\n",
|
||||
" p_name varchar(22) not null,\n",
|
||||
" p_mfgr varchar(6) not null,\n",
|
||||
" p_category varchar(7) not null,\n",
|
||||
" p_brand1 varchar(9) not null,\n",
|
||||
" p_color varchar(11) not null,\n",
|
||||
" p_type varchar(25) not null,\n",
|
||||
" p_size integer not null,\n",
|
||||
" p_container varchar(10) not null\n",
|
||||
");\n",
|
||||
"\n",
|
||||
"CREATE TABLE supplier (\n",
|
||||
" s_suppkey integer not null sortkey,\n",
|
||||
" s_name varchar(25) not null,\n",
|
||||
" s_address varchar(25) not null,\n",
|
||||
" s_city varchar(10) not null,\n",
|
||||
" s_nation varchar(15) not null,\n",
|
||||
" s_region varchar(12) not null,\n",
|
||||
" s_phone varchar(15) not null)\n",
|
||||
"diststyle all;\n",
|
||||
"\n",
|
||||
"CREATE TABLE customer (\n",
|
||||
" c_custkey integer not null sortkey,\n",
|
||||
" c_name varchar(25) not null,\n",
|
||||
" c_address varchar(25) not null,\n",
|
||||
" c_city varchar(10) not null,\n",
|
||||
" c_nation varchar(15) not null,\n",
|
||||
" c_region varchar(12) not null,\n",
|
||||
" c_phone varchar(15) not null,\n",
|
||||
" c_mktsegment varchar(10) not null)\n",
|
||||
"diststyle all;\n",
|
||||
"\n",
|
||||
"CREATE TABLE dwdate (\n",
|
||||
" d_datekey integer not null sortkey,\n",
|
||||
" d_date varchar(19) not null,\n",
|
||||
" d_dayofweek varchar(10) not null,\n",
|
||||
" d_month varchar(10) not null,\n",
|
||||
" d_year integer not null,\n",
|
||||
" d_yearmonthnum integer not null,\n",
|
||||
" d_yearmonth varchar(8) not null,\n",
|
||||
" d_daynuminweek integer not null,\n",
|
||||
" d_daynuminmonth integer not null,\n",
|
||||
" d_daynuminyear integer not null,\n",
|
||||
" d_monthnuminyear integer not null,\n",
|
||||
" d_weeknuminyear integer not null,\n",
|
||||
" d_sellingseason varchar(13) not null,\n",
|
||||
" d_lastdayinweekfl varchar(1) not null,\n",
|
||||
" d_lastdayinmonthfl varchar(1) not null,\n",
|
||||
" d_holidayfl varchar(1) not null,\n",
|
||||
" d_weekdayfl varchar(1) not null)\n",
|
||||
"diststyle all;\n",
|
||||
"\n",
|
||||
"CREATE TABLE lineorder (\n",
|
||||
" lo_orderkey integer not null,\n",
|
||||
" lo_linenumber integer not null,\n",
|
||||
" lo_custkey integer not null,\n",
|
||||
" lo_partkey integer not null distkey,\n",
|
||||
" lo_suppkey integer not null,\n",
|
||||
" lo_orderdate integer not null sortkey,\n",
|
||||
" lo_orderpriority varchar(15) not null,\n",
|
||||
" lo_shippriority varchar(1) not null,\n",
|
||||
" lo_quantity integer not null,\n",
|
||||
" lo_extendedprice integer not null,\n",
|
||||
" lo_ordertotalprice integer not null,\n",
|
||||
" lo_discount integer not null,\n",
|
||||
" lo_revenue integer not null,\n",
|
||||
" lo_supplycost integer not null,\n",
|
||||
" lo_tax integer not null,\n",
|
||||
" lo_commitdate integer not null,\n",
|
||||
" lo_shipmode varchar(10) not null\n",
|
||||
");"
|
||||
],
|
||||
"language": "python",
|
||||
"metadata": {},
|
||||
"outputs": []
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"| Table name | Sort Key | Distribution Style |\n",
|
||||
"|------------|--------------|--------------------|\n",
|
||||
"| LINEORDER | lo_orderdate | lo_partkey |\n",
|
||||
"| PART | p_partkey | p_partkey |\n",
|
||||
"| CUSTOMER | c_custkey | ALL |\n",
|
||||
"| SUPPLIER | s_suppkey | ALL |\n",
|
||||
"| DWDATE | d_datekey | ALL |"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"[Sort Keys](http://docs.aws.amazon.com/redshift/latest/dg/tutorial-tuning-tables-sort-keys.html)\n",
|
||||
"\n",
|
||||
"When you create a table, you can specify one or more columns as the sort key. Amazon Redshift stores your data on disk in sorted order according to the sort key. How your data is sorted has an important effect on disk I/O, columnar compression, and query performance.\n",
|
||||
"\n",
|
||||
"Choose sort keys for based on these best practices:\n",
|
||||
"\n",
|
||||
"If recent data is queried most frequently, specify the timestamp column as the leading column for the sort key.\n",
|
||||
"\n",
|
||||
"If you do frequent range filtering or equality filtering on one column, specify that column as the sort key.\n",
|
||||
"\n",
|
||||
"If you frequently join a (dimension) table, specify the join column as the sort key."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"[Distribution Styles](http://docs.aws.amazon.com/redshift/latest/dg/c_choosing_dist_sort.html)\n",
|
||||
"\n",
|
||||
"When you create a table, you designate one of three distribution styles: KEY, ALL, or EVEN.\n",
|
||||
"\n",
|
||||
"**KEY distribution**\n",
|
||||
"\n",
|
||||
"The rows are distributed according to the values in one column. The leader node will attempt to place matching values on the same node slice. If you distribute a pair of tables on the joining keys, the leader node collocates the rows on the slices according to the values in the joining columns so that matching values from the common columns are physically stored together.\n",
|
||||
"\n",
|
||||
"**ALL distribution**\n",
|
||||
"\n",
|
||||
"A copy of the entire table is distributed to every node. Where EVEN distribution or KEY distribution place only a portion of a table's rows on each node, ALL distribution ensures that every row is collocated for every join that the table participates in.\n",
|
||||
"\n",
|
||||
"**EVEN distribution**\n",
|
||||
"\n",
|
||||
"The rows are distributed across the slices in a round-robin fashion, regardless of the values in any particular column. EVEN distribution is appropriate when a table does not participate in joins or when there is not a clear choice between KEY distribution and ALL distribution. EVEN distribution is the default distribution style."
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {}
|
||||
|
|
|
|||
Loading…
Reference in New Issue
Block a user