---
title: 『数据结构』树
date: 2018-7-11 18:56
categories: 数据结构与算法
tags: [数据结构,树]
keywords:
mathjax: true
description:
---
- [1. 概念](#1-概念)
- [2. 二叉查找树](#2-二叉查找树)
- [2.1. 随机构造的二叉查找树](#21-随机构造的二叉查找树)
- [2.2. 平均结点深度](#22-平均结点深度)
- [2.3. 不同的二叉树数目(Catalan num)](#23-不同的二叉树数目catalan-num)
- [2.4. 好括号列](#24-好括号列)
- [3. 基数树(radixTree)](#3-基数树radixtree)
- [4. 字典树(trie)](#4-字典树trie)
- [4.1. AC 自动机](#41-ac-自动机)
- [5. 平衡二叉树](#5-平衡二叉树)
- [5.1. AVL Tree](#51-avl-tree)
- [5.2. splayTree](#52-splaytree)
- [5.2.1. Zig-step](#521-zig-step)
- [5.2.2. Zig-zig step](#522-zig-zig-step)
- [5.2.3. Zig-zag step](#523-zig-zag-step)
- [5.3. read-black Tree](#53-read-black-tree)
- [5.4. treap](#54-treap)
- [6. 总结](#6-总结)
- [7. 附代码](#7-附代码)
- [7.1. 二叉树(binaryTree)](#71-二叉树binarytree)
- [7.2. 前缀树(Trie)](#72-前缀树trie)
- [7.3. 赢者树(winnerTree)](#73-赢者树winnertree)
- [7.4. 左斜堆](#74-左斜堆)
# 1. 概念
* 双亲
* 左右孩子
* 左右子树
* 森林
* 结点,叶子,边,路径
* 高度 h
* 遍历(前中后层)
* 结点数 n
# 2. 二叉查找树
又名排序二叉树,对于每个结点, 如果有,其左孩子不大于它,右孩子不小于它
通过前序遍历或者后序遍历就可以得到有序序列(升序,降序)
常用三种操作, 插入,删除,查找,时间复杂度是 )
h是树高, 但是由于插入,删除而导致树不平衡, 即可能 
## 2.1. 随机构造的二叉查找树
下面可以证明,随机构造,即输入序列有 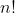中, 每种概率相同的情况下, 期望的树高 )
(直接搬运算法导论上面的啦>_<)

## 2.2. 平均结点深度
一个较 上面定理 弱的结论:
>一棵随机构造的二叉查找树,n 个结点的平均深度为 )
类似 RANDOMIZED-QUICKSORT 的证明过程, 因为快排 递归的过程就是一个递归 二叉树.
随机选择枢纽元就相当于这里的某个子树的根结点 在所有结点的大小随机排名, 如 i. 然后根结点将剩下的结点划分为左子树(i-1)个结点, 右子树(n-i)个结点.

## 2.3. 不同的二叉树数目(Catalan num)
给定,组成二叉查找树的数目.
由上面的证明过程, 可以容易地分析得出, 任选第 i 个数作为根, 由于二叉查找树的性质, 其左子树
应该有 i-1个结点, 右子树有 n-i个结点.
如果记 n 个结点 的二叉查找树的数目为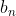
则有递推公式

然后我们来看`<<算法导论>>`(p162,思考题12-4)上怎么求的吧( •̀ ω •́ )y
设生成函数
=\sum_{n=0}^{\infty}b_n&space;x^n)
下面证明=xB(x)^2+1)
易得^2=\sum_{i=1}^{\infty}\sum_{n=i}^{\infty}b_{i-1}b_{n-i}x^n)
对比,&space;xB(x)^2+1)的 x 的各次系数,分别是 
当 k=0, 
当 k>0

所以=xB(x)^2+1)
由此解得
=\frac{1-\sqrt{1-4x}&space;}{2x})
在点 x=0 处,
用泰勒公式得
}^nx^n&space;\\&space;&=1+\sum_{n=1}^{\infty}\frac{(2n-3)!!{(-4x)}^n}{n!}&space;\end{aligned}&space;)
所以对应系数
!!}{2^{n+1}n!}&space;\\&space;&=\frac{C_{2n}^{n}}{n+1}&space;\end{aligned}&space;)
这个数叫做 `Catalan 数`
## 2.4. 好括号列
王树禾的`<<图论>>`(p42)上用另外的方法给出Catalan数, 并求出n结点 二叉查找数的个数
首先定义好括号列,有:
* 空列,即没有括号叫做好括号列
* 若A,B都是好括号列, 则串联后 AB是好括号列
* 若A是好括号列, 则 (A)是好括号列
>充要条件: 好括号列  左右括号数相等, 且从左向右看, 看到的右括号数不超过左括号数
>定理: 由 n个左括号,n个右括号组成的好括号列个数为=\frac{C_{2n}^{n}}{n+1})
证明:
由 n左n右组成的括号列有 个.
设括号列为坏括号列,
由充要条件, 存在最小的 j, 使得中右括号比左括号多一个,
由于是最小的 j, 所以 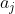为右括号, 为右括号
把中的左括号变为右括号, 右变左,记为
则括号列为好括号列
可好可坏,且有n-1个右,n+1个左, 共有!(n-1)!}=C_{2n}^{n+1})个.
所以坏括号列 与括号列 , 有!(n-1)!}=C_{2n}^{n+1})个
那么好括号列有
=C_{2n}^{n}&space;-&space;C_{2n}^{n+1}&space;=\frac{C_{2n}^{n}}{n+1}&space;)
>推论: n个字符,进栈出栈(出栈可以在栈不为空的时候随时进行), 则出栈序列有 c(n)种
这种先入后出的情形都是这样

# 3. 基数树(radixTree)

# 4. 字典树(trie)
又叫`前缀树`(preifx tree).适用于储存有公共前缀的字符串集合. 如果直接储存, 而很多字符串有公共前缀, 会浪费掉存储空间.
字典树可以看成是基数树的变形, 每个结点可以有多个孩子, 每个结点存储的是一个字符, 从根沿着结点走到一个结点,走过的路径形成字符序列, 如果有合适的单词就可以输出.
当然,也可以同理得出后缀树
## 4.1. AC 自动机
Aho-Corasick automation,是在字典树上添加匹配失败边(失配指针), 实现字符串搜索匹配的算法.

图中蓝色结点 表示存在字符串, 灰色表示不存在.
黑色边是父亲到子结点的边, 蓝色边就是`失配指针`.
蓝色边(终点称为起点的后缀结点): 连接字符串**终点**到在**图中存在的**, **最长**严格后缀的结点. 如 caa 的严格后缀为 aa,a, 空. 而在图中存在, 且最长的是字符串 a, 则连接到这个字符串的终点 a.
绿色边(字典后缀结点): 终点是起点经过蓝色有向边到达的第一个蓝色结点.
下面摘自 `wiki`
>在每一步中,算法先查找当前节点的 “孩子节点”,如果没有找到匹配,查找它的后缀节点(suffix) 的孩子,如果仍然没有,接着查找后缀节点的后缀节点的孩子, 如此循环, 直到根结点,如果到达根节点仍没有找到匹配则结束。
>
>当算法查找到一个节点,则输出所有结束在当前位置的字典项。输出步骤为首先找到该节点的字典后缀,然后用递归的方式一直执行到节点没有字典前缀为止。同时,如果该节点为一个字典节点,则输出该节点本身。
>
>输入 abccab 后算法的执行步骤如下:
>
# 5. 平衡二叉树
上面的二叉查找树不平衡,即经过多次插入,删除后, 其高度变化大, 不能保持)的性能
而平衡二叉树就能.
平衡二叉树都是经过一些旋转操作, 使左右子树的结点高度相差不大,达到平衡
有如下几种
## 5.1. AVL Tree
`平衡因子`: 右子树高度 - 左子树高度
定义: 每个结点的平衡因子属于{0,-1,1}


## 5.2. splayTree
伸展树, 它的特点是每次将访问的结点通过旋转旋转到根结点.
其实它并不平衡. 但是插入,查找,删除操作 的平摊时间是)
有三种旋转,下面都是将访问过的 x 旋转到 根部
### 5.2.1. Zig-step

### 5.2.2. Zig-zig step

### 5.2.3. Zig-zag step

## 5.3. read-black Tree
同样是平衡的二叉树, 以后单独写一篇关于红黑树的.
## 5.4. treap
[前面提到](#21-随机构造的二叉查找树), 随机构造的二叉查找树高度为 ),以及在[算法 general](https://mbinary.xyz/alg-genral.html) 中说明了怎样 随机化(shuffle)一个给定的序列.
所以,为了得到一个平衡的二叉排序树,我们可以将给定的序列随机化, 然后再进行构造二叉排序树.
但是如果不能一次得到全部的数据,也就是可能插入新的数据的时候,该怎么办呢? 可以证明,满足下面的条件构造的结构相当于同时得到全部数据, 也就是随机化的二叉查找树.

这种结构叫 `treap`, 不仅有要排序的关键字 key, 还有随机生成的,各不相等的关键字`priority`,代表插入的顺序.
* 二叉查找树的排序性质: 双亲结点的 key 大于左孩子,小于右孩子
* 最小(大)堆的堆序性质: 双亲的 prority小于(大于) 孩子的 prority
插入的实现: 先进行二叉查找树的插入,成为叶子结点, 再通过旋转 实现 `上浮`(堆中术语).
将先排序 key, 再排序 prority(排序prority 时通过旋转保持 key 的排序)
# 6. 总结
还有很多有趣的树结构,
比如斜堆, 竞赛树(赢者树,输者树,线段树, 索引树,B树, fingerTree(不知道是不是译为手指树233)...
这里就不详细介绍了, 如果以后有时间,可能挑几个单独写一篇文章
# 7. 附代码
**[github地址](https://github.com/mbinary/algorithm-and-data-structure.git)**
## 7.1. 二叉树(binaryTree)
```python
from functools import total_ordering
@total_ordering
class node:
def __init__(self,val,left=None,right=None,freq = 1):
self.val=val
self.left=left
self.right=right
self.freq = freq
def __lt__(self,nd):
return self.valnewNode:
if nd.left is None:nd.left = newNode
else : _add(nd.left,newNode)
else:nd.freq +=1
_add(self.root,node(val))
def find(self,val):
prt= self._findPrt(self.root,node(val),None)
if prt.left and prt.left.val==val:
return prt.left
elif prt.right and prt.right.val==val:return prt.right
else :return None
def _findPrt(self,nd,tgt,prt):
if nd==tgt or nd is None:return prt
elif nd
## 7.2. 前缀树(Trie)
```python
class node:
def __init__(self,val = None):
self.val = val
self.isKey = False
self.children = {}
def __getitem__(self,i):
return self.children[i]
def __iter__(self):
return iter(self.children.keys())
def __setitem__(self,i,x):
self.children[i] = x
def __bool__(self):
return self.children!={}
def __str__(self):
return 'val: '+str(self.val)+'\nchildren: '+' '.join(self.children.keys())
def __repr__(self):
return str(self)
class Trie(object):
def __init__(self):
self.root=node('')
self.dic ={'insert':self.insert,'startsWith':self.startsWith,'search':self.search}
def insert(self, word):
"""
Inserts a word into the trie.
:type word: str
:rtype: void
"""
if not word:return
nd = self.root
for i in word:
if i in nd:
nd = nd[i]
else:
newNode= node(i)
nd[i] = newNode
nd = newNode
else:nd.isKey = True
def search(self, word,matchAll='.'):
"""support matchall function eg, 'p.d' matchs 'pad' , 'pid'
"""
self.matchAll = '.'
return self._search(self.root,word)
def _search(self,nd,word):
for idx,i in enumerate(word):
if i==self.matchAll :
for j in nd:
bl =self._search(nd[j],word[idx+1:])
if bl:return True
else:return False
if i in nd:
nd = nd[i]
else:return False
else:return nd.isKey
def startsWith(self, prefix):
"""
Returns if there is any word in the trie that starts with the given prefix.
:type prefix: str
:rtype: bool
"""
nd = self.root
for i in prefix:
if i in nd:
nd= nd[i]
else:return False
return True
def display(self):
print('preOrderTraverse data of the Trie')
self.preOrder(self.root,'')
def preOrder(self,root,s):
s=s+root.val
if root.isKey:
print(s)
for i in root:
self.preOrder(root[i],s)
```
## 7.3. 赢者树(winnerTree)
```python
class winnerTree:
'''if iself.s else 2*p+self.lowExt-self.n+1
def arrayToTree(self,i):
return (i+self.offset)//2 if i<=self.lowExt else (i-self.lowExt+ self.n-1)//2
def win(self,a,b):
return ab
def initTree(self,p):
if p>=self.n:
delta = p%2 #!!! good job notice delta mark the lchild or rchlid
return self.players[self.treeToArray(p//2)+delta]
l = self.initTree(2*p)
r = self.initTree(2*p+1)
self.tree[p] = l if self.win(l,r) else r
return self.tree[p]
def winner(self):
idx = 1
while 2*idx
## 7.4. 左斜堆
```python
from functools import total_ordering
@total_ordering
class node:
def __init__(self,val,freq=1,s=1,left=None,right=None):
self.val=val
self.freq=freq
self.s=s
if left is None or right is None:
self.left = left if left is not None else right
self.right =None
else:
if left.s int
if root is None:return t
if t is None:return root
if root