---
title: 『算法』排序
date: 2018-7-6
categories: 数据结构与算法
tags: [算法,排序]
keywords:
mathjax: true
description:
---
- [1. 希尔排序(shellSort)](#1-希尔排序shellsort)
- [2. 堆排序(heapSort)](#2-堆排序heapsort)
- [2.1. 建堆](#21-建堆)
- [2.2. 访问最元](#22-访问最元)
- [2.3. 取出最元](#23-取出最元)
- [2.4. 堆排序](#24-堆排序)
- [3. 快速排序(quickSort)](#3-快速排序quicksort)
- [3.1. partition的实现](#31-partition的实现)
- [3.2. 选择枢纽元](#32-选择枢纽元)
- [3.3. 快速排序的性能](#33-快速排序的性能)
- [3.3.1. 最坏情况](#331-最坏情况)
- [3.3.2. 最佳情况](#332-最佳情况)
- [3.3.3. 平衡的划分](#333-平衡的划分)
- [3.4. 期望运行时间](#34-期望运行时间)
- [3.5. 堆栈深度](#35-堆栈深度)
- [3.6. 测试](#36-测试)
- [4. 计数排序(countSort)](#4-计数排序countsort)
- [5. 基数排序(radixSort)](#5-基数排序radixsort)
- [5.1. 原理](#51-原理)
- [5.2. 实现](#52-实现)
- [5.3. 扩展](#53-扩展)
- [5.4. 测试](#54-测试)
- [6. 桶排序(bucketSort)](#6-桶排序bucketsort)
- [7. 选择问题(select)](#7-选择问题select)
排序的本质就是减少逆序数, 根据是否进行比较,可以分为如下两类.
* 比较排序
如希尔排序,堆排序, 快速排序, 合并排序等
可以证明 比较排序的下界 是 )
* 非比较排序
如 计数排序, 桶排序, 基数排序 不依靠比较来进行排序的, 可以达到 线性时间的复杂度
# 1. 希尔排序(shellSort)
希尔排序是选择排序的改进, 通过在较远的距离进行交换, 可以更快的减少逆序数. 这个距离即增量, 由自己选择一组, 从大到小进行, 而且最后一个增量必须是 1. 要选得到好的性能, 一般选择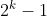
```pythonn
def shellSort(s,inc = None):
if inc is None: inc = [1,3,5,7,11,13,17,19]
num = len(s)
inc.sort(reverse=True)
for i in inc:
for j in range(i,num):
cur = j
while cur>=i and s[j] > s[cur-i]:
s[cur] = s[cur-i]
cur-=i
s[cur] = s[j]
return s
```
可以证明 希尔排序时间复杂度可以达到)
# 2. 堆排序(heapSort)
## 2.1. 建堆
是将一个数组(列表) heapify 的过程. 方法就是对每一个结点, 都自底向上的比较,然后操作,这个过程称为 上浮.
粗略的计算, 每个结点上浮的比较次数的上界是 层数, 即 logn, 则 n 个结点, 总的比较次数为 nlogn
但是可以发现, 不同高度 h 的结点比较的次数不同, 上界实际上应该是 ),每层结点数上界 
则 总比较次数为
\lceil&space;2^{h}&space;\rceil&space;&&space;=&space;\sum_{h=0}^{&space;{log_2&space;n}-1}&space;O(h\frac{n}{2^h})\\&space;&&space;=&space;n*O(\sum_{h=0}^{log_2&space;n}\frac{h}{2^h})&space;\\&space;&&space;=&space;n*O(1)&space;\\&space;&&space;=&space;O(n)&space;\end{aligned}&space;)
## 2.2. 访问最元
最大堆对应最大元,最小堆对于最小元, 可以 ) 内实现
## 2.3. 取出最元
最大堆取最大元,最小堆取最小元,由于元素取出了, 要进行调整.
从堆顶开始, 依次和其两个孩子比较, 如果是最大堆, 就将此结点(父亲)的值赋为较大的孩子的值,最小堆反之.
然后对那个孩子进行同样的操作,一直到达堆底,即最下面的一层. 这个过程称为 下滤.
最后将最后一个元素与最下面一层那个元素(与上一层交换的)交换, 再删除最后一个元素.
时间复杂度为 )
## 2.4. 堆排序
建立堆之后, 一直进行 `取出最元`操作, 即得有序序列
代码
```python
from functools import partial
class heap:
def __init__(self,lst,reverse = False):
self.data= heapify(lst,reverse)
self.cmp = partial(lambda i,j,r:cmp(self.data[i],self.data[j],r),r= reverse)
def getTop(self):
return self.data[0]
def __getitem__(self,idx):
return self.data[idx]
def __bool__(self):
return self.data != []
def popTop(self):
ret = self.data[0]
n = len(self.data)
cur = 1
while cur * 2<=n:
chd = cur-1
r_idx = cur*2
l_idx = r_idx-1
if r_idx==n:
self.data[chd] = self.data[l_idx]
break
j = l_idx if self.cmp(l_idx,r_idx)<0 else r_idx
self.data[chd] = self.data[j]
cur = j+1
self.data[cur-1] = self.data[-1]
self.data.pop()
return ret
def addNode(self,val):
self.data.append(val)
self.data = one_heapify(len(self.data)-1)
def cmp(n1,n2,reverse=False):
fac = -1 if reverse else 1
if n1 < n2: return -fac
elif n1 > n2: return fac
return 0
def heapify(lst,reverse = False):
for i in range(len(lst)):
lst = one_heapify(lst,i,reverse)
return lst
def one_heapify(lst,cur,reverse = False):
cur +=1
while cur>1:
chd = cur-1
prt = cur//2-1
if cmp(lst[prt],lst[chd],reverse)<0:
break
lst[prt],lst[chd] = lst[chd], lst[prt]
cur = prt+1
return lst
def heapSort(lst,reverse = False):
lst = lst.copy()
hp = heap(lst,reverse)
ret = []
while hp:
ret.append(hp.popTop())
return ret
if __name__ == '__main__':
from random import randint
n = randint(10,20)
lst = [randint(0,100) for i in range(n)]
print('random : ', lst)
print('small-heap: ', heapify(lst))
print('big-heap : ', heapify(lst,True))
print('ascend : ', heapSort(lst))
print('descend : ', heapSort(lst,True))
```
# 3. 快速排序(quickSort)
```python
def quickSort(lst):
def _sort(a,b):
if a>=b:return
CHOOSE PIVOT #选取适当的枢纽元, 一般是三数取中值
pos = partition(a,b)
_sort(a,pos-1)
_sort(pos+1,b)
_sort(0,len(lst))
```
快排大体结构就是这样,使用分治的思想, 在原地进行排列.
关键就在于选择枢纽元.
这里的 partition 就是根据枢纽元,分别将 大于,小于或等于的枢纽元的元素放在列表两边, 分割开.
## 3.1. partition的实现
partition 有不同的实现. 下面列出两种
* 第一种实现
```python
def partition(a,b):
pivot = lst[a]
while a!=b:
while apivot: b-=1
if apivot: b-=1
if a=b:return
mid = (a+b)//2
# 三数取中值置于第一个作为 pivot
if (lst[a]lst[mid]): lst[a],lst[b] = lst[b],lst[a] # lst[b] 为中值
i = partition(a,b)
_sort(a,i-1)
_sort(i+1,b)
_sort(0,len(lst)-1)
return lst
```
## 3.2. 选择枢纽元
* 端点或中点
* 随机
* 三数取中(两端点以及中点)
* 五数取中
## 3.3. 快速排序的性能
快速排序性能取决于划分的对称性(即枢纽元的选择), 以及partition 的实现. 如果每次划分很对称(大概在当前序列的中位数为枢纽元), 则与合并算法一样快, 但是如果不对称,在渐近上就和插入算法一样慢
### 3.3.1. 最坏情况
试想,如果每次划分两个区域分别包含 n-1, 1则易知时间复杂度为 ), 此外, 如果输入序序列已经排好序,且枢纽元没选好, 比如选的端点, 则同样是这样复杂, 而此时插入排序只需 ).
### 3.3.2. 最佳情况
有 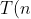&space;=&space;2T(\frac{n}{2})+\Theta(n))
则由主方法为)
### 3.3.3. 平衡的划分
如果每次 9:1, 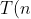&space;=&space;T(\frac{9n}{10})+T(\frac{n}{10})+\Theta(n))
用递归树求得在渐近上仍然是 )
所以任何比值 k:1, 都有如上的渐近时间复杂度
然而每次划分是不可能完全相同的
## 3.4. 期望运行时间
对于 randomized-quicksort, 即随机选择枢纽元
设 n 个元素, 从小到大记为 ,指示器变量 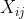表示 是否进行比较
即

考察比较次数, 可以发现两个元素进行比较, 一定是一个是枢纽元的情况, 两个元素间不可能进行两次比较.
所有总的比较次数不超过,
求均值
=\sum_{i=1}^{n-1}\sum_{j=i+1}^{n}E(X_{ij})=\sum_{i=1}^{n-1}\sum_{j=i+1}^{n}P(z_i,z_j\text{Making-Comparisons}))
再分析, 在中, 如果集合中的非此两元素,作为了枢纽元, 则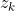将集合划分, 这两个集合中的元素都不会再和对方中的元素进行比较,
所以要使 进行比较, 则两者之一(只能是一个,即互斥)是 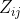上的枢纽元
则
&space;&&space;=&space;P(z_i,z_j\text{As}Z_{ij}\text{Hub-element})&space;\\&space;&&space;=&space;P(z_j\text{As}Z_{ij}\text{Hub-element})+P(z_i\text{As}Z_{ij}\text{Hub-element})\\&space;&&space;=&space;\frac{1}{j-i+1}+\frac{1}{j-i+1}&space;\\&space;&&space;=&space;\frac{2}{j-i+1}\\&space;\end{aligned}&space;)
注意第二步是因为两事件互斥才可以直接概率相加
然后就可以将次概率代入求期望比较次数了,
为 ) (由于是 O, 放缩一下就行)
## 3.5. 堆栈深度
考察快速排序的堆栈深度,可以从递归树思考,实际上的堆栈变化过程就是前序访问二叉树, 所以深度为 )
为了减少深度, 可以进行 尾递归优化, 将函数返回前的递归通过迭代完成
```python
QUICKSORT(A,a,b)
while a
## 3.6. 测试
这是上面三个版本的简单测试结果,
前面测试的是各函数用的时间, 后面打印出来的是体现正确性,用的另外的序列了

# 4. 计数排序(countSort)
需要知道元素的取值范围, 而且应该是有限的, 最好范围不大
不过需要额外的存储空间.
计算排序是稳定的: 具有相同值的元素在输出中是原来的相对顺序.
```python
def countSort(lst,mn,mx):
mark = [0]*(mx-mn+1)
for i in lst:
mark[i-mn]+=1
ret =[]
for n,i in enumerate(mark):
for j in range(i):
ret.append(n+mn)
return ret
```
# 5. 基数排序(radixSort)
## 5.1. 原理
由我们平时的直觉, 我们比较两个数时, 是从最高位比较起, 一位一位比较, 直到不相等时就能判断大小,或者相等(位数比完了).
基数排序有点不一样, 它是从低位比到高位, 这样才能把相同位有相同值的不同数排序.
对于 n 个数, 最高 d 位, 用下面的实现, 可时间复杂度为 *d))
## 5.2. 实现
下面是一个整数版本的基数排序,比较容易实现
```python
def radixSort(lst,radix=10):
ls = [[] for i in range(radix)]
mx = max(lst)
weight = 1
while mx >= weight:
for i in lst:
ls[(i // weight)%radix].append(i)
weight *= radix
lst = sum(ls,[])
ls = [[] for i in range(radix)]
return lst
```
## 5.3. 扩展
注意到如果有负数,要使用计数排序或者 基数排序,每个数需要加上最小值的相反数, 再排序, 最后再减去, 如果有浮点数, 就需要先乘以一个数, 使所有数变为整数.
我想过用 str 得到一个数的各位, 不过 str 可能比较慢. str 的实现应该也是先算术计算, 再生成 str 对象, 对于基数排序, 生成str 对象是多余的.
## 5.4. 测试
下面是 基数排序与快速排序的比较,测试代码
```python
from time import time
from random import randint
def timer(funcs,span,num=1000000):
lst = [randint(0,span) for i in range(num)]
print('range({}), {} items'.format(span,num))
for func in funcs:
data = lst.copy()
t = time()
func(data)
t = time()-t
print('{}: {}s'.format(func.__name__,t))
if __name__ == '__main__':
timer([quickSort,radixSort],1000000000,100000)
timer([quickSort,radixSort],1000000000000,10000)
timer([quickSort,radixSort],10000,100000)
```

# 6. 桶排序(bucketSort)
适用于均匀分布的序列
设有 n 个元素, 则设立 n 个桶
将各元素通过数值线性映射到桶地址,
类似 hash 链表.
然后在每个桶内, 进行插入排序())
最后合并所有桶.
这里的特点是 n 个桶实现了 )的时间复杂度, 但是耗费的空间 为 )
证明
* 线性映射部分: )
* 桶合并部分: )
* 桶内插入排序部分: 设每个桶内的元素数为随机变量 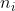, 易知 ) 记 
&space;&=\sum_{i=1}^{n}E(n_i^2)&space;\\&space;&=\sum_{i=1}^{n}(&space;Var(n_i)+E^2(n_i)&space;)&space;\\&space;&=&space;\sum_{i=1}^{n}(&space;np(1-p)+&space;(np)^2&space;)\\&space;&=&space;\sum_{i=1}^{n}(&space;2-\frac{1}{n}&space;)\\&space;&=&space;2n-1&space;\end{aligned}&space;)
将以上各部分加起来即得时间复杂度 )
# 7. 选择问题(select)
输入个序列 lst, 以及一个数 i, 输出 lst 中 第 i 小的数,即从小到大排列第 i
解决方法
* 全部排序, 取第 i 个, )
* 长度为 i 的队列(这是得到 lst 中 前
i 个元素的方法) 仍然 )
* randomized-select(仿造快排) 平均情况),最坏情况同上(快排), )
```python
from random import randint
def select(lst,i):
lst = lst.copy()
def partition(a,b):
pivot = lst[a]
while apivot: b-=1
if a=b: return lst[a]
# randomized select
n = randint(a,b)
lst[a],lst[n] = lst[n],lst[a]
pos = partition(a,b)
if pos>i:
return _select(a,pos-1)
elif pos