2018-07-08 23:28:29 +08:00
|
|
|
---
|
|
|
|
|
title: 『数据结构』散列表
|
|
|
|
|
date: 2018-07-08 23:25
|
2018-07-13 23:42:46 +08:00
|
|
|
categories: 数据结构与算法
|
2018-07-08 23:28:29 +08:00
|
|
|
tags: [数据结构,散列表]
|
|
|
|
|
keywords:
|
|
|
|
|
mathjax: true
|
|
|
|
|
description:
|
|
|
|
|
---
|
2018-07-11 19:26:24 +08:00
|
|
|
<!-- TOC -->
|
|
|
|
|
|
|
|
|
|
- [1. 关键字](#1-关键字)
|
|
|
|
|
- [2. 映射](#2-映射)
|
|
|
|
|
- [2.1. 散列函数(hash)](#21-散列函数hash)
|
|
|
|
|
- [2.1.1. 简单一致散列](#211-简单一致散列)
|
|
|
|
|
- [2.1.2. 碰撞(collision)](#212-碰撞collision)
|
|
|
|
|
- [2.1.3. str2int 的方法](#213-str2int-的方法)
|
|
|
|
|
- [2.2. 直接寻址法](#22-直接寻址法)
|
|
|
|
|
- [2.3. 链接法](#23-链接法)
|
|
|
|
|
- [2.3.1. 全域散列(universal hashing)](#231-全域散列universal-hashing)
|
|
|
|
|
- [2.3.1.1. 定义](#2311-定义)
|
|
|
|
|
- [2.3.1.2. 性质](#2312-性质)
|
|
|
|
|
- [2.3.1.3. 实现](#2313-实现)
|
|
|
|
|
- [2.4. 开放寻址法](#24-开放寻址法)
|
|
|
|
|
- [2.4.1. 不成功查找的探查数的期望](#241-不成功查找的探查数的期望)
|
|
|
|
|
- [2.4.1.1. 插入探查数的期望](#2411-插入探查数的期望)
|
|
|
|
|
- [2.4.1.2. 成功查找的探查数的期望](#2412-成功查找的探查数的期望)
|
|
|
|
|
|
|
|
|
|
<!-- /TOC -->
|
|
|
|
|
|
2018-07-08 23:28:29 +08:00
|
|
|
|
2019-03-18 00:46:56 +08:00
|
|
|
哈希表 (hash table) , 可以实现 ) 的 read, write, update
|
2018-07-08 23:28:29 +08:00
|
|
|
相对应 python 中的 dict, c语言中的 map
|
|
|
|
|
|
|
|
|
|
其实数组也能实现, 只是数组用来索引的关键字是下标, 是整数.
|
|
|
|
|
而哈希表就是将各种关键字映射到数组下标的一种"数组"
|
|
|
|
|
|
2018-07-11 19:26:24 +08:00
|
|
|
<a id="markdown-1-关键字" name="1-关键字"></a>
|
|
|
|
|
# 1. 关键字
|
2018-11-07 16:52:55 +08:00
|
|
|
由于关键字是用来索引数据的, 所以要求它不能变动(如果变动,实际上就是一个新的关键字插入了), 在python 中表现为 immutable. 常为字符串.
|
2018-07-08 23:28:29 +08:00
|
|
|
|
2018-07-11 19:26:24 +08:00
|
|
|
<a id="markdown-2-映射" name="2-映射"></a>
|
|
|
|
|
# 2. 映射
|
|
|
|
|
<a id="markdown-21-散列函数hash" name="21-散列函数hash"></a>
|
|
|
|
|
## 2.1. 散列函数(hash)
|
2019-03-18 00:46:56 +08:00
|
|
|
将关键字 k 进行映射, 映射函数 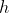, 映射后的数组地址 ).
|
2018-07-08 23:28:29 +08:00
|
|
|
|
2018-07-11 19:26:24 +08:00
|
|
|
<a id="markdown-211-简单一致散列" name="211-简单一致散列"></a>
|
|
|
|
|
### 2.1.1. 简单一致散列
|
2018-07-08 23:28:29 +08:00
|
|
|
|
|
|
|
|
>* 简单一致假设:元素散列到每个链表的可能性是相同的, 且与其他已被散列的元素独立无关.
|
|
|
|
|
>* 简单一致散列(simple uniform hashing): 满足简单一致假设的散列
|
|
|
|
|
|
|
|
|
|
好的散列函数应 满足简单一致假设
|
|
|
|
|
例如
|
2019-03-18 00:46:56 +08:00
|
|
|
\quad&space;h(k)&space;=&space;k&space;\&space;mod\&space;m&space;\\&space;&(2)\quad&space;h(k)&space;=&space;\lfloor&space;{m(kA&space;\&space;mod\&space;1)\rfloor}&space;=&space;kA-\lfloor&space;kA&space;\rfloor&space;\text{,\&space;x(0<&space;A<&space;1)}\\&space;&\quad\text{Any-All-Access-Pass&space;A&space;Use,The-best-choice-is-related-to-the-hashed-data-characteristics.}\\&space;&\quad\text{&space;Knuth&space;Holding:,The-most-ideal-is-the-number-of-golden-sections.}\frac{\sqrt{5}&space;-1}{2}&space;\approx&space;0.618&space;\end{aligned}&space;)
|
2018-07-08 23:28:29 +08:00
|
|
|
|
2018-07-11 19:26:24 +08:00
|
|
|
<a id="markdown-212-碰撞collision" name="212-碰撞collision"></a>
|
|
|
|
|
### 2.1.2. 碰撞(collision)
|
2018-07-08 23:28:29 +08:00
|
|
|
由于关键字值域大于映射后的地址值域, 所以可能出现两个关键字有相同的映射地址
|
|
|
|
|
|
2018-07-11 19:26:24 +08:00
|
|
|
<a id="markdown-213-str2int-的方法" name="213-str2int-的方法"></a>
|
|
|
|
|
### 2.1.3. str2int 的方法
|
2018-07-08 23:28:29 +08:00
|
|
|
可以先用 ascii 值,然后
|
|
|
|
|
* 各位相加
|
|
|
|
|
* 两位叠加
|
|
|
|
|
* 循环移位
|
|
|
|
|
* ...
|
|
|
|
|
|
|
|
|
|
|
2018-08-29 15:52:02 +08:00
|
|
|
|
2018-07-11 19:26:24 +08:00
|
|
|
<a id="markdown-22-直接寻址法" name="22-直接寻址法"></a>
|
|
|
|
|
## 2.2. 直接寻址法
|
2019-03-18 00:46:56 +08:00
|
|
|
将关键字直接对应到数组地址, 即 =k)
|
2018-07-08 23:28:29 +08:00
|
|
|
|
|
|
|
|
缺点: 如果关键字值域范围大, 但是数量小, 就会浪费空间, 有可能还不能储存这么大的值域范围.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2018-07-11 19:26:24 +08:00
|
|
|
<a id="markdown-23-链接法" name="23-链接法"></a>
|
|
|
|
|
## 2.3. 链接法
|
2018-07-08 23:28:29 +08:00
|
|
|
通过链接法来解决碰撞
|
|
|
|
|
|
|
|
|
|

|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2019-03-18 00:46:56 +08:00
|
|
|
记有 m 个链表, n 个元素  为每个链表的期望元素个数(长度)
|
2018-07-08 23:28:29 +08:00
|
|
|
|
2019-03-18 00:46:56 +08:00
|
|
|
则查找成功,或者不成功的时间复杂度为 )
|
|
|
|
|
如果 ,&space;namely&space;\quad&space;\alpha=\frac{O(m)}{m}=O(1)), 则上面的链接法满足 )的速度
|
2018-07-08 23:28:29 +08:00
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2018-07-11 19:26:24 +08:00
|
|
|
<a id="markdown-231-全域散列universal-hashing" name="231-全域散列universal-hashing"></a>
|
|
|
|
|
### 2.3.1. 全域散列(universal hashing)
|
2018-07-08 23:28:29 +08:00
|
|
|
随机地选择散列函数, 使之独立于要存储的关键字
|
2018-07-11 19:26:24 +08:00
|
|
|
<a id="markdown-2311-定义" name="2311-定义"></a>
|
|
|
|
|
#### 2.3.1.1. 定义
|
2019-03-18 00:46:56 +08:00
|
|
|
设一组散列函数 , 将 关键字域 U 映射到  , 全域的函数组, 满足
|
|
|
|
|
&space;=&space;h(l),&space;\text{Such&space;h&space;The-number-does-not-exceed}\frac{|H|}{m}&space;)
|
|
|
|
|
即从 H 中任选一个散列函数, 当关键字不相等时, 发生碰撞的概率不超过 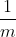
|
2018-07-08 23:28:29 +08:00
|
|
|
|
2018-07-11 19:26:24 +08:00
|
|
|
<a id="markdown-2312-性质" name="2312-性质"></a>
|
|
|
|
|
#### 2.3.1.2. 性质
|
2019-03-18 00:46:56 +08:00
|
|
|
对于 m 个槽位的表, 只需 )的期望时间来处理 n 个元素的 insert, search, delete,其中 有)个insert 操作
|
2018-07-11 19:26:24 +08:00
|
|
|
<a id="markdown-2313-实现" name="2313-实现"></a>
|
|
|
|
|
#### 2.3.1.3. 实现
|
2019-03-18 00:46:56 +08:00
|
|
|
选择足够大的 prime p, 记
|
|
|
|
|
令&space;=&space;((ak+b)mod\&space;p)&space;mod\&space;m)
|
|
|
|
|
则 
|
2018-07-11 19:26:24 +08:00
|
|
|
<a id="markdown-24-开放寻址法" name="24-开放寻址法"></a>
|
|
|
|
|
## 2.4. 开放寻址法
|
2018-07-08 23:28:29 +08:00
|
|
|
所有表项都在散列表中, 没有链表.
|
2019-03-18 00:46:56 +08:00
|
|
|
且散列表装载因子
|
2018-07-08 23:28:29 +08:00
|
|
|
这里散列函数再接受一个参数, 作为探测序号
|
2019-03-18 00:46:56 +08:00
|
|
|
逐一试探 ,h(k,1),\ldots,h(k,m-1)),这要有满足的,就插入, 不再计算后面的 hash值
|
2018-07-08 23:28:29 +08:00
|
|
|
|
|
|
|
|
探测序列一般分有三种
|
2019-03-18 00:46:56 +08:00
|
|
|
* 线性
|
2018-08-29 15:52:02 +08:00
|
|
|
|
2018-07-08 23:28:29 +08:00
|
|
|
存在一次聚集问题
|
2019-03-18 00:46:56 +08:00
|
|
|
* 二次^2)
|
2018-08-29 15:52:02 +08:00
|
|
|
|
2018-07-08 23:28:29 +08:00
|
|
|
存在二次聚集问题
|
|
|
|
|
* 双重探查
|
2018-08-29 15:52:02 +08:00
|
|
|
|
2019-03-18 00:46:56 +08:00
|
|
|
&space;=&space;(h_1(k)+i*h_2(k))mod\&space;m)
|
2018-07-08 23:28:29 +08:00
|
|
|
为了能查找整个表, 即要为模 m 的完系, 则 h_2(k)要与 m 互质.
|
2019-03-18 00:46:56 +08:00
|
|
|
如可以取 &space;=&space;k\&space;mod&space;\&space;m,h_2(k)&space;=&space;1+(k\&space;mod\&space;{m-1}))
|
2018-07-08 23:28:29 +08:00
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
注意删除时, 不能直接删除掉(如果有元素插入在其后插入时探测过此地址,删除后就不能访问到那个元素了), 应该 只是做个标记为删除
|
|
|
|
|
|
2018-07-11 19:26:24 +08:00
|
|
|
<a id="markdown-241-不成功查找的探查数的期望" name="241-不成功查找的探查数的期望"></a>
|
|
|
|
|
### 2.4.1. 不成功查找的探查数的期望
|
2019-03-18 00:46:56 +08:00
|
|
|
对于开放寻址散列表,且 ,一次不成功的查找,是这样的: 已经装填了 n 个, 总共有m 个,则空槽有 m-n 个.
|
2018-07-13 23:42:46 +08:00
|
|
|
不成功的探查是这样的: 一直探查到已经装填的元素(但是不是要找的元素), 直到遇到没有装填的空槽. 所以这服从几何分布, 即
|
2019-03-18 00:46:56 +08:00
|
|
|
=p(\text{Find-the-empty-slot-for-the-first-time})=\frac{m-n}{m}&space;)
|
2018-07-13 23:42:46 +08:00
|
|
|
有
|
2019-03-18 00:46:56 +08:00
|
|
|
=\frac{1}{p}\leqslant&space;\frac{1}{1-\alpha})
|
2018-07-13 23:42:46 +08:00
|
|
|
|
2018-07-08 23:28:29 +08:00
|
|
|

|
2018-07-13 23:42:46 +08:00
|
|
|
|
2018-07-11 19:26:24 +08:00
|
|
|
<a id="markdown-2411-插入探查数的期望" name="2411-插入探查数的期望"></a>
|
|
|
|
|
#### 2.4.1.1. 插入探查数的期望
|
2019-03-18 00:46:56 +08:00
|
|
|
所以, 插入一个关键字, 也最多需要 次, 因为插入过程就是前面都是被占用了的槽, 最后遇到一个空槽.与探查不成功是一样的过程
|
2018-07-11 19:26:24 +08:00
|
|
|
<a id="markdown-2412-成功查找的探查数的期望" name="2412-成功查找的探查数的期望"></a>
|
|
|
|
|
#### 2.4.1.2. 成功查找的探查数的期望
|
2019-03-18 00:46:56 +08:00
|
|
|
成功查找的探查过程与插入是一样的. 所以查找关键字 k 相当于 插入它, 设为第 i+1 个插入的(前面插入了i个,装载因子. 那么期望探查数就是
|
|
|
|
|

|
2018-07-08 23:28:29 +08:00
|
|
|
|
|
|
|
|
则成功查找的期望探查数为
|
2019-03-18 00:46:56 +08:00
|
|
|

|
2018-07-11 19:26:24 +08:00
|
|
|
|
|
|
|
|
代码
|
2018-07-13 23:42:46 +08:00
|
|
|
|
|
|
|
|
**[github地址](https://github.com/mbinary/algorithm-and-data-structure.git)**
|
2018-07-11 19:26:24 +08:00
|
|
|
```python
|
|
|
|
|
class item:
|
|
|
|
|
def __init__(self,key,val,nextItem=None):
|
|
|
|
|
self.key = key
|
|
|
|
|
self.val = val
|
|
|
|
|
self.next = nextItem
|
|
|
|
|
def to(self,it):
|
|
|
|
|
self.next = it
|
|
|
|
|
def __eq__(self,it):
|
|
|
|
|
'''using keyword <in> '''
|
|
|
|
|
return self.key == it.key
|
|
|
|
|
def __bool__(self):
|
|
|
|
|
return self.key is not None
|
|
|
|
|
def __str__(self):
|
|
|
|
|
li = []
|
|
|
|
|
nd = self
|
|
|
|
|
while nd:
|
|
|
|
|
li.append(f'({nd.key}:{nd.val})')
|
|
|
|
|
nd = nd.next
|
|
|
|
|
return ' -> '.join(li)
|
|
|
|
|
def __repr__(self):
|
|
|
|
|
return f'item({self.key},{self.val})'
|
|
|
|
|
class hashTable:
|
|
|
|
|
def __init__(self,size=100):
|
|
|
|
|
self.size = size
|
|
|
|
|
self.slots=[item(None,None) for i in range(self.size)]
|
|
|
|
|
def __setitem__(self,key,val):
|
|
|
|
|
nd = self.slots[self.myhash(key)]
|
|
|
|
|
while nd.next:
|
|
|
|
|
if nd.key ==key:
|
|
|
|
|
if nd.val!=val: nd.val=val
|
|
|
|
|
return
|
|
|
|
|
nd = nd.next
|
|
|
|
|
nd.next = item(key,val)
|
|
|
|
|
|
|
|
|
|
def myhash(self,key):
|
|
|
|
|
if isinstance(key,str):
|
|
|
|
|
key = sum(ord(i) for i in key)
|
|
|
|
|
if not isinstance(key,int):
|
|
|
|
|
key = hash(key)
|
|
|
|
|
return key % self.size
|
|
|
|
|
def __iter__(self):
|
|
|
|
|
'''when using keyword <in>, such as ' if key in dic',
|
|
|
|
|
the dic's __iter__ method will be called,(if hasn't, calls __getitem__
|
|
|
|
|
then ~iterate~ dic's keys to compare whether one equls to the key
|
|
|
|
|
'''
|
|
|
|
|
for nd in self.slots:
|
|
|
|
|
nd = nd.next
|
|
|
|
|
while nd :
|
|
|
|
|
yield nd.key
|
|
|
|
|
nd = nd.next
|
|
|
|
|
def __getitem__(self,key):
|
|
|
|
|
nd =self.slots[ self.myhash(key)].next
|
|
|
|
|
while nd:
|
|
|
|
|
if nd.key==key:
|
|
|
|
|
return nd.val
|
|
|
|
|
nd = nd.next
|
|
|
|
|
raise Exception(f'[KeyError]: {self.__class__.__name__} has no key {key}')
|
|
|
|
|
|
|
|
|
|
def __delitem__(self,key):
|
|
|
|
|
'''note that None item and item(None,None) differ with each other,
|
|
|
|
|
which means you should take care of them and correctly cop with None item
|
|
|
|
|
especially when deleting items
|
|
|
|
|
'''
|
|
|
|
|
n = self.myhash(key)
|
|
|
|
|
nd = self.slots[n].next
|
|
|
|
|
if nd.key == key:
|
|
|
|
|
if nd.next is None:
|
|
|
|
|
self.slots[n] = item(None,None) # be careful
|
|
|
|
|
else:self.slots[n] = nd.next
|
|
|
|
|
return
|
|
|
|
|
while nd:
|
|
|
|
|
if nd.next is None: break # necessary
|
|
|
|
|
if nd.next.key ==key:
|
|
|
|
|
nd.next = nd.next.next
|
|
|
|
|
nd = nd.next
|
|
|
|
|
def __str__(self):
|
|
|
|
|
li = ['\n\n'+'-'*5+'hashTable'+'-'*5]
|
|
|
|
|
for i,nd in enumerate(self.slots):
|
|
|
|
|
li.append(f'{i}: '+str(nd.next))
|
|
|
|
|
return '\n'.join(li)
|
|
|
|
|
```
|