mirror of https://github.com/OI-wiki/OI-wiki
style: format markdown files with remark-lint
parent
117e235e0c
commit
078f2df7c4
|
|
@ -24,7 +24,7 @@ RMQ 是 Range Maximum/Minimum Query 的缩写,表示区间最大(最小)
|
|||
|
||||
### 题 1
|
||||
|
||||
???+note "例题"
|
||||
???+ note "例题"
|
||||
如何用尽可能少的砝码称量出 $[0,31]$ 之间的所有重量?(只能在天平的一端放砝码)
|
||||
|
||||
??? note "解题思路"
|
||||
|
|
@ -34,7 +34,7 @@ RMQ 是 Range Maximum/Minimum Query 的缩写,表示区间最大(最小)
|
|||
|
||||
### 题 2
|
||||
|
||||
???+note "例题"
|
||||
???+ note "例题"
|
||||
给出一个长度为 $n$ 的环和一个常数 $k$,每次会从第 $i$ 个点跳到第 $(i+k)\bmod n+1$ 个点,总共跳了 $m$ 次。每个点都有一个权值,记为 $a_i$,求 $m$ 次跳跃的起点的权值之和对 $10^9+7$ 取模的结果。
|
||||
|
||||
数据范围:$1\leq n\leq 10^6$,$1\leq m\leq 10^{18}$,$1\leq k\leq n$,$0\le a_i\le 10^9$。
|
||||
|
|
|
|||
|
|
@ -47,7 +47,7 @@ int binary_search(int start, int end, int key) {
|
|||
}
|
||||
```
|
||||
|
||||
???+note
|
||||
???+ note
|
||||
参考 [编译优化 #位运算代替乘法](/lang/optimizations/#%E4%BD%8D%E8%BF%90%E7%AE%97%E4%BB%A3%E6%9B%BF%E4%B9%98%E6%B3%95),对于 $n$ 是有符号数的情况,当你可以保证 $n\ge 0$ 时,`n >> 1` 比 `n / 2` 指令数更少。
|
||||
|
||||
### 最大值最小化
|
||||
|
|
@ -56,9 +56,9 @@ int binary_search(int start, int end, int key) {
|
|||
|
||||
要求满足某种条件的最大值的最小可能情况(最大值最小化),首先的想法是从小到大枚举这个作为答案的「最大值」,然后去判断是否合法。若答案单调,就可以使用二分搜索法来更快地找到答案。因此,要想使用二分搜索法来解这种「最大值最小化」的题目,需要满足以下三个条件:
|
||||
|
||||
1. 答案在一个固定区间内;
|
||||
2. 可能查找一个符合条件的值不是很容易,但是要求能比较容易地判断某个值是否是符合条件的;
|
||||
3. 可行解对于区间满足一定的单调性。换言之,如果 $x$ 是符合条件的,那么有 $x + 1$ 或者 $x - 1$ 也符合条件。(这样下来就满足了上面提到的单调性)
|
||||
1. 答案在一个固定区间内;
|
||||
2. 可能查找一个符合条件的值不是很容易,但是要求能比较容易地判断某个值是否是符合条件的;
|
||||
3. 可行解对于区间满足一定的单调性。换言之,如果 $x$ 是符合条件的,那么有 $x + 1$ 或者 $x - 1$ 也符合条件。(这样下来就满足了上面提到的单调性)
|
||||
|
||||
当然,最小值最大化是同理的。
|
||||
|
||||
|
|
@ -78,14 +78,14 @@ bsearch 函数相比 qsort([排序相关 STL](./stl-sort.md))的四个参数
|
|||
|
||||
bsearch 函数的返回值是查找到的元素的地址,该地址为 void 类型。
|
||||
|
||||
注意:bsearch 与上文的 lower_bound 和 upper_bound 有两点不同:
|
||||
注意:bsearch 与上文的 lower\_bound 和 upper\_bound 有两点不同:
|
||||
|
||||
- 当符合条件的元素有重复多个的时候,会返回执行二分查找时第一个符合条件的元素,从而这个元素可能位于重复多个元素的中间部分。
|
||||
- 当查找不到相应的元素时,会返回 NULL。
|
||||
- 当符合条件的元素有重复多个的时候,会返回执行二分查找时第一个符合条件的元素,从而这个元素可能位于重复多个元素的中间部分。
|
||||
- 当查找不到相应的元素时,会返回 NULL。
|
||||
|
||||
用 lower_bound 可以实现与 bsearch 完全相同的功能,所以可以使用 bsearch 通过的题目,直接改写成 lower_bound 同样可以实现。但是鉴于上述不同之处的第二点,例如,在序列 1、2、4、5、6 中查找 3,bsearch 实现 lower_bound 的功能会变得困难。
|
||||
用 lower\_bound 可以实现与 bsearch 完全相同的功能,所以可以使用 bsearch 通过的题目,直接改写成 lower\_bound 同样可以实现。但是鉴于上述不同之处的第二点,例如,在序列 1、2、4、5、6 中查找 3,bsearch 实现 lower\_bound 的功能会变得困难。
|
||||
|
||||
利用 bsearch 实现 lower_bound 的功能比较困难,是否一定就不能实现?答案是否定的,存在比较 tricky 的技巧。借助编译器处理比较函数的特性:总是将第一个参数指向待查元素,将第二个参数指向待查数组中的元素,也可以用 bsearch 实现 lower_bound 和 upper_bound,如下文示例。只是,这要求待查数组必须是全局数组,从而可以直接传入首地址。
|
||||
利用 bsearch 实现 lower\_bound 的功能比较困难,是否一定就不能实现?答案是否定的,存在比较 tricky 的技巧。借助编译器处理比较函数的特性:总是将第一个参数指向待查元素,将第二个参数指向待查数组中的元素,也可以用 bsearch 实现 lower\_bound 和 upper\_bound,如下文示例。只是,这要求待查数组必须是全局数组,从而可以直接传入首地址。
|
||||
|
||||
```cpp
|
||||
int A[100005]; // 示例全局数组
|
||||
|
|
@ -115,13 +115,13 @@ int upper(const void *p1, const void *p2) {
|
|||
}
|
||||
```
|
||||
|
||||
因为现在的 OI 选手很少写纯 C,并且此方法作用有限,所以不是重点。对于新手而言,建议老老实实地使用 C++ 中的 lower_bound 和 upper_bound 函数。
|
||||
因为现在的 OI 选手很少写纯 C,并且此方法作用有限,所以不是重点。对于新手而言,建议老老实实地使用 C++ 中的 lower\_bound 和 upper\_bound 函数。
|
||||
|
||||
### 二分答案
|
||||
|
||||
解题的时候往往会考虑枚举答案然后检验枚举的值是否正确。若满足单调性,则满足使用二分法的条件。把这里的枚举换成二分,就变成了「二分答案」。
|
||||
|
||||
???+note "[Luogu P1873 砍树](https://www.luogu.com.cn/problem/P1873)"
|
||||
???+ note "[Luogu P1873 砍树](https://www.luogu.com.cn/problem/P1873)"
|
||||
伐木工人米尔科需要砍倒 $M$ 米长的木材。这是一个对米尔科来说很容易的工作,因为他有一个漂亮的新伐木机,可以像野火一样砍倒森林。不过,米尔科只被允许砍倒单行树木。
|
||||
|
||||
米尔科的伐木机工作过程如下:米尔科设置一个高度参数 $H$(米),伐木机升起一个巨大的锯片到高度 $H$,并锯掉所有的树比 $H$ 高的部分(当然,树木不高于 $H$ 米的部分保持不变)。米尔科就得到树木被锯下的部分。
|
||||
|
|
@ -179,7 +179,6 @@ int upper(const void *p1, const void *p2) {
|
|||

|
||||
|
||||
合法的最小值恰恰相反。
|
||||
|
||||
2. 为何返回左边值?
|
||||
|
||||
同上。
|
||||
|
|
@ -197,7 +196,7 @@ int upper(const void *p1, const void *p2) {
|
|||
|
||||
其次,某些题中需要求极值点的单峰函数并非一个单独的函数,而是多个函数进行特殊运算得到的函数(如求多个单调性不完全相同的一次函数的最小值的最大值)。此时函数的导函数可能是分段函数,且在函数某些点上可能不可导。
|
||||
|
||||
???+warning "注意"
|
||||
???+ warning "注意"
|
||||
只要函数是单峰函数,三分法既可以求出其最大值,也可以求出其最小值。为行文方便,除特殊说明外,下文中均以求单峰函数的最小值为例。
|
||||
|
||||
三分法与二分法的基本思想类似,但每次操作需在当前区间 $[l,r]$(下图中除去虚线范围内的部分)内任取两点 $lmid,rmid(lmid < rmid)$(下图中的两蓝点)。如下图,如果 $f(lmid)<f(rmid)$,则在 $[rmid,r]$(下图中的红色部分)中函数必然单调递增,最小值所在点(下图中的绿点)必然不在这一区间内,可舍去这一区间。反之亦然。
|
||||
|
|
@ -245,7 +244,7 @@ while (r - l > eps) {
|
|||
|
||||
### 例题
|
||||
|
||||
???+note "[洛谷 P3382 - 【模板】三分法](https://www.luogu.com.cn/problem/P3382)"
|
||||
???+ note "[洛谷 P3382 -【模板】三分法](https://www.luogu.com.cn/problem/P3382)"
|
||||
给定一个 $N$ 次函数和范围 $[l, r]$,求出使函数在 $[l, x]$ 上单调递增且在 $[x, r]$ 上单调递减的唯一的 $x$ 的值。
|
||||
|
||||
??? note "解题思路"
|
||||
|
|
@ -258,10 +257,10 @@ while (r - l > eps) {
|
|||
|
||||
### 习题
|
||||
|
||||
- [Uva 1476 - Error Curves](https://onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&category=447&page=show_problem&problem=4222)
|
||||
- [Uva 10385 - Duathlon](https://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&category=15&page=show_problem&problem=1326)
|
||||
- [UOJ 162 -【清华集训 2015】灯泡测试](https://uoj.ac/problem/162)
|
||||
- [洛谷 P7579 -「RdOI R2」称重(weigh)](https://www.luogu.com.cn/problem/P7579)
|
||||
- [Uva 1476 - Error Curves](https://onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&category=447&page=show_problem&problem=4222)
|
||||
- [Uva 10385 - Duathlon](https://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&category=15&page=show_problem&problem=1326)
|
||||
- [UOJ 162 -【清华集训 2015】灯泡测试](https://uoj.ac/problem/162)
|
||||
- [洛谷 P7579 -「RdOI R2」称重(weigh)](https://www.luogu.com.cn/problem/P7579)
|
||||
|
||||
## 分数规划
|
||||
|
||||
|
|
|
|||
|
|
@ -8,10 +8,10 @@
|
|||
|
||||
桶排序按下列步骤进行:
|
||||
|
||||
1. 设置一个定量的数组当作空桶;
|
||||
2. 遍历序列,并将元素一个个放到对应的桶中;
|
||||
3. 对每个不是空的桶进行排序;
|
||||
4. 从不是空的桶里把元素再放回原来的序列中。
|
||||
1. 设置一个定量的数组当作空桶;
|
||||
2. 遍历序列,并将元素一个个放到对应的桶中;
|
||||
3. 对每个不是空的桶进行排序;
|
||||
4. 从不是空的桶里把元素再放回原来的序列中。
|
||||
|
||||
## 性质
|
||||
|
||||
|
|
|
|||
|
|
@ -20,13 +20,13 @@ author: linehk, persdre
|
|||
|
||||
考虑用时随数据规模变化的趋势的主要原因有以下几点:
|
||||
|
||||
1. 现代计算机每秒可以处理数亿乃至更多次基本运算,因此我们处理的数据规模通常很大。如果算法 A 在规模为 $n$ 的数据上用时为 $100n$ 而算法 B 在规模为 $n$ 的数据上用时为 $n^2$,在数据规模小于 $100$ 时算法 B 用时更短,但在一秒钟内算法 A 可以处理数百万规模的数据,而算法 B 只能处理数万规模的数据。在允许算法执行时间更久时,时间复杂度对可处理数据规模的影响就会更加明显,远大于同一数据规模下用时的影响。
|
||||
2. 我们采用基本操作数来表示算法的用时,而不同的基本操作实际用时是不同的,例如加减法的用时远小于除法的用时。计算时间复杂度而忽略不同基本操作之间的区别以及一次基本操作与十次基本操作之间的区别,可以消除基本操作间用时不同的影响。
|
||||
1. 现代计算机每秒可以处理数亿乃至更多次基本运算,因此我们处理的数据规模通常很大。如果算法 A 在规模为 $n$ 的数据上用时为 $100n$ 而算法 B 在规模为 $n$ 的数据上用时为 $n^2$,在数据规模小于 $100$ 时算法 B 用时更短,但在一秒钟内算法 A 可以处理数百万规模的数据,而算法 B 只能处理数万规模的数据。在允许算法执行时间更久时,时间复杂度对可处理数据规模的影响就会更加明显,远大于同一数据规模下用时的影响。
|
||||
2. 我们采用基本操作数来表示算法的用时,而不同的基本操作实际用时是不同的,例如加减法的用时远小于除法的用时。计算时间复杂度而忽略不同基本操作之间的区别以及一次基本操作与十次基本操作之间的区别,可以消除基本操作间用时不同的影响。
|
||||
|
||||
当然,算法的运行用时并非完全由输入规模决定,而是也与输入的内容相关。所以,时间复杂度又分为几种,例如:
|
||||
|
||||
1. 最坏时间复杂度,即每个输入规模下用时最长的输入对应的时间复杂度。在算法竞赛中,由于输入可以在给定的数据范围内任意给定,我们为保证算法能够通过某个数据范围内的任何数据,一般考虑最坏时间复杂度。
|
||||
2. 平均(期望)时间复杂度,即每个输入规模下所有可能输入对应用时的平均值的复杂度(随机输入下期望用时的复杂度)。
|
||||
1. 最坏时间复杂度,即每个输入规模下用时最长的输入对应的时间复杂度。在算法竞赛中,由于输入可以在给定的数据范围内任意给定,我们为保证算法能够通过某个数据范围内的任何数据,一般考虑最坏时间复杂度。
|
||||
2. 平均(期望)时间复杂度,即每个输入规模下所有可能输入对应用时的平均值的复杂度(随机输入下期望用时的复杂度)。
|
||||
|
||||
所谓「用时随数据规模而增长的趋势」是一个模糊的概念,我们需要借助下文所介绍的 **渐进符号** 来形式化地表示时间复杂度。
|
||||
|
||||
|
|
@ -76,10 +76,10 @@ $f(n)=\omega(g(n))$,当且仅当对于任意给定的正数 $c$,$\exists n_0
|
|||
|
||||
### 常见性质
|
||||
|
||||
- $f(n) = \Theta(g(n))\iff f(n)=O(g(n))\land f(n)=\Omega(g(n))$
|
||||
- $f_1(n) + f_2(n) = O(\max(f_1(n), f_2(n)))$
|
||||
- $f_1(n) \times f_2(n) = O(f_1(n) \times f_2(n))$
|
||||
- $\forall a \neq 1, \log_a{n} = O(\log_2 n)$。由换底公式可以得知,任何对数函数无论底数为何,都具有相同的增长率,因此渐进时间复杂度中对数的底数一般省略不写。
|
||||
- $f(n) = \Theta(g(n))\iff f(n)=O(g(n))\land f(n)=\Omega(g(n))$
|
||||
- $f_1(n) + f_2(n) = O(\max(f_1(n), f_2(n)))$
|
||||
- $f_1(n) \times f_2(n) = O(f_1(n) \times f_2(n))$
|
||||
- $\forall a \neq 1, \log_a{n} = O(\log_2 n)$。由换底公式可以得知,任何对数函数无论底数为何,都具有相同的增长率,因此渐进时间复杂度中对数的底数一般省略不写。
|
||||
|
||||
## 简单的时间复杂度计算的例子
|
||||
|
||||
|
|
@ -146,7 +146,7 @@ $f(n)=\omega(g(n))$,当且仅当对于任意给定的正数 $c$,$\exists n_0
|
|||
## 主定理 (Master Theorem)
|
||||
|
||||
我们可以使用 Master Theorem 来快速求得关于递归算法的复杂度。
|
||||
Master Theorem 递推关系式如下
|
||||
Master Theorem 递推关系式如下
|
||||
|
||||
$$
|
||||
T(n) = a T\left(\frac{n}{b}\right)+f(n)\qquad \forall n > b
|
||||
|
|
|
|||
|
|
@ -22,7 +22,7 @@ author: leoleoasd, yzxoi
|
|||
|
||||
### 例题 1
|
||||
|
||||
???+note "[Codeforces Round #384 (Div. 2) C.Vladik and fractions](http://codeforces.com/problemset/problem/743/C)"
|
||||
???+ note "[Codeforces Round #384 (Div. 2) C.Vladik and fractions](http://codeforces.com/problemset/problem/743/C)"
|
||||
构造一组 $x,y,z$,使得对于给定的 $n$,满足 $\dfrac{1}{x}+\dfrac{1}{y}+\dfrac{1}{z}=\dfrac{2}{n}$
|
||||
|
||||
??? note "解题思路"
|
||||
|
|
@ -34,7 +34,7 @@ author: leoleoasd, yzxoi
|
|||
|
||||
### 例题 2
|
||||
|
||||
???+note "[Luogu P3599 Koishi Loves Construction](https://www.luogu.com.cn/problem/P3599)"
|
||||
???+ note "[Luogu P3599 Koishi Loves Construction](https://www.luogu.com.cn/problem/P3599)"
|
||||
Task1:试判断能否构造并构造一个长度为 $n$ 的 $1\dots n$ 的排列,满足其 $n$ 个前缀和在模 $n$ 的意义下互不相同
|
||||
|
||||
Taks2:试判断能否构造并构造一个长度为 $n$ 的 $1\dots n$ 的排列,满足其 $n$ 个前缀积在模 $n$ 的意义下互不相同
|
||||
|
|
@ -78,11 +78,11 @@ author: leoleoasd, yzxoi
|
|||
|
||||
### 例题 3
|
||||
|
||||
???+note "[AtCoder Grand Contest 032 B](https://atcoder.jp/contests/agc032/tasks/agc032_b)"
|
||||
???+ note "[AtCoder Grand Contest 032 B](https://atcoder.jp/contests/agc032/tasks/agc032_b)"
|
||||
给定一个整数 $N$,试构造一个节点数为 $N$ 无向图。令节点编号为 $1\ldots N$,要求其满足以下条件:
|
||||
|
||||
- 这是一个简单连通图。
|
||||
- 存在一个整数 $S$ 使得对于任意节点,与其相邻节点的下标和为 $S$。
|
||||
- 这是一个简单连通图。
|
||||
- 存在一个整数 $S$ 使得对于任意节点,与其相邻节点的下标和为 $S$。
|
||||
|
||||
保证输入数据有解。
|
||||
|
||||
|
|
@ -101,7 +101,7 @@ author: leoleoasd, yzxoi
|
|||
|
||||
### 例题 4
|
||||
|
||||
???+note "BZOJ 4971「Lydsy1708 月赛」记忆中的背包"
|
||||
???+ note "BZOJ 4971「Lydsy1708 月赛」记忆中的背包"
|
||||
经过一天辛苦的工作,小 Q 进入了梦乡。他脑海中浮现出了刚进大学时学 01 背包的情景,那时还是大一萌新的小 Q 解决了一道简单的 01 背包问题。这个问题是这样的:
|
||||
|
||||
给定 $n$ 个物品,每个物品的体积分别为 $v_1,v_2,…,v_n$,请计算从中选择一些物品(也可以不选),使得总体积恰好为 $w$ 的方案数。因为答案可能非常大,你只需要输出答案对 $P$ 取模的结果。
|
||||
|
|
|
|||
|
|
@ -13,9 +13,9 @@
|
|||
|
||||
它的工作过程分为三个步骤:
|
||||
|
||||
1. 计算每个数出现了几次;
|
||||
2. 求出每个数出现次数的 [前缀和](./prefix-sum.md);
|
||||
3. 利用出现次数的前缀和,从右至左计算每个数的排名。
|
||||
1. 计算每个数出现了几次;
|
||||
2. 求出每个数出现次数的 [前缀和](./prefix-sum.md);
|
||||
3. 利用出现次数的前缀和,从右至左计算每个数的排名。
|
||||
|
||||
### 计算前缀和的原因
|
||||
|
||||
|
|
|
|||
|
|
@ -16,10 +16,10 @@ author: fudonglai, AngelKitty, labuladong
|
|||
|
||||
以下是一些有助于理解递归的例子:
|
||||
|
||||
1. [什么是递归?](./divide-and-conquer.md)
|
||||
2. 如何给一堆数字排序?答:分成两半,先排左半边再排右半边,最后合并就行了,至于怎么排左边和右边,请重新阅读这句话。
|
||||
3. 你今年几岁?答:去年的岁数加一岁,1999 年我出生。
|
||||
4. 
|
||||
1. [什么是递归?](./divide-and-conquer.md)
|
||||
2. 如何给一堆数字排序?答:分成两半,先排左半边再排右半边,最后合并就行了,至于怎么排左边和右边,请重新阅读这句话。
|
||||
3. 你今年几岁?答:去年的岁数加一岁,1999 年我出生。
|
||||
4. 
|
||||
|
||||
递归在数学中非常常见。例如,集合论对自然数的正式定义是:1 是一个自然数,每个自然数都有一个后继,这一个后继也是自然数。
|
||||
|
||||
|
|
@ -84,7 +84,7 @@ int func(传入数值) {
|
|||
|
||||
显然,递归版本比非递归版本更易理解。递归版本的做法一目了然:把左半边排序,把右半边排序,最后合并两边。而非递归版本看起来不知所云,充斥着各种难以理解的边界计算细节,特别容易出 bug,且难以调试。
|
||||
|
||||
2. 练习分析问题的结构。当发现问题可以被分解成相同结构的小问题时,递归写多了就能敏锐发现这个特点,进而高效解决问题。
|
||||
2. 练习分析问题的结构。当发现问题可以被分解成相同结构的小问题时,递归写多了就能敏锐发现这个特点,进而高效解决问题。
|
||||
|
||||
### 递归的缺点
|
||||
|
||||
|
|
@ -107,7 +107,7 @@ int size_recursion(Node *head) {
|
|||
}
|
||||
```
|
||||
|
||||
](images/divide-and-conquer-2.png "[二者的对比,compiler 设为 Clang 10.0,优化设为 O1](https://quick-bench.com/q/rZ7jWPmSdltparOO5ndLgmS9BVc)")
|
||||
](images/divide-and-conquer-2.png "\[二者的对比,compiler 设为 Clang 10.0,优化设为 O1](https://quick-bench.com/q/rZ7jWPmSdltparOO5ndLgmS9BVc)")
|
||||
|
||||
### 递归的优化
|
||||
|
||||
|
|
@ -127,17 +127,17 @@ int size_recursion(Node *head) {
|
|||
|
||||
大概的流程可以分为三步:分解 -> 解决 -> 合并。
|
||||
|
||||
1. 分解原问题为结构相同的子问题。
|
||||
2. 分解到某个容易求解的边界之后,进行递归求解。
|
||||
3. 将子问题的解合并成原问题的解。
|
||||
1. 分解原问题为结构相同的子问题。
|
||||
2. 分解到某个容易求解的边界之后,进行递归求解。
|
||||
3. 将子问题的解合并成原问题的解。
|
||||
|
||||
分治法能解决的问题一般有如下特征:
|
||||
|
||||
- 该问题的规模缩小到一定的程度就可以容易地解决。
|
||||
- 该问题可以分解为若干个规模较小的相同问题,即该问题具有最优子结构性质,利用该问题分解出的子问题的解可以合并为该问题的解。
|
||||
- 该问题所分解出的各个子问题是相互独立的,即子问题之间不包含公共的子问题。
|
||||
- 该问题的规模缩小到一定的程度就可以容易地解决。
|
||||
- 该问题可以分解为若干个规模较小的相同问题,即该问题具有最优子结构性质,利用该问题分解出的子问题的解可以合并为该问题的解。
|
||||
- 该问题所分解出的各个子问题是相互独立的,即子问题之间不包含公共的子问题。
|
||||
|
||||
???+warning "注意"
|
||||
???+ warning "注意"
|
||||
如果各子问题是不独立的,则分治法要重复地解公共的子问题,也就做了许多不必要的工作。此时虽然也可用分治法,但一般用 [动态规划](../dp/basic.md) 较好。
|
||||
|
||||
以归并排序为例。假设实现归并排序的函数名为 `merge_sort`。明确该函数的职责,即 **对传入的一个数组排序**。这个问题显然可以分解。给一个数组排序等于给该数组的左右两半分别排序,然后合并成一个数组。
|
||||
|
|
@ -194,14 +194,14 @@ void traverse(TreeNode* root) {
|
|||
|
||||
## 例题详解
|
||||
|
||||
???+note "[437. 路径总和 III](https://leetcode-cn.com/problems/path-sum-iii/)"
|
||||
???+ note "[437. 路径总和 III](https://leetcode-cn.com/problems/path-sum-iii/)"
|
||||
给定一个二叉树,它的每个结点都存放着一个整数值。
|
||||
|
||||
找出路径和等于给定数值的路径总数。
|
||||
|
||||
路径不需要从根节点开始,也不需要在叶子节点结束,但是路径方向必须是向下的(只能从父节点到子节点)。
|
||||
|
||||
二叉树不超过 1000 个节点,且节点数值范围是[-1000000,1000000]的整数。
|
||||
二叉树不超过 1000 个节点,且节点数值范围是 \[-1000000,1000000] 的整数。
|
||||
|
||||
示例:
|
||||
|
||||
|
|
@ -290,8 +290,8 @@ void traverse(TreeNode* root) {
|
|||
|
||||
## 习题
|
||||
|
||||
- [LeetCode 上的递归专题练习](https://leetcode.com/explore/learn/card/recursion-i/)
|
||||
- [LeetCode 上的分治算法专项练习](https://leetcode.com/tag/divide-and-conquer/)
|
||||
- [LeetCode 上的递归专题练习](https://leetcode.com/explore/learn/card/recursion-i/)
|
||||
- [LeetCode 上的分治算法专项练习](https://leetcode.com/tag/divide-and-conquer/)
|
||||
|
||||
## 参考资料与注释
|
||||
|
||||
|
|
|
|||
|
|
@ -30,7 +30,7 @@ author: frank-xjh
|
|||
|
||||
以下是一个使用枚举解题与优化枚举范围的例子。
|
||||
|
||||
!!! 例题
|
||||
??? 例题
|
||||
一个数组中的数互不相同,求其中和为 $0$ 的数对的个数。
|
||||
|
||||
??? note "解题思路"
|
||||
|
|
@ -103,7 +103,7 @@ author: frank-xjh
|
|||
|
||||
## 习题
|
||||
|
||||
- [2811: 熄灯问题 - OpenJudge](http://bailian.openjudge.cn/practice/2811/)
|
||||
- [2811: 熄灯问题 - OpenJudge](http://bailian.openjudge.cn/practice/2811/)
|
||||
|
||||
## 脚注
|
||||
|
||||
|
|
|
|||
|
|
@ -16,8 +16,8 @@
|
|||
|
||||
贪心算法有两种证明方法:反证法和归纳法。一般情况下,一道题只会用到其中的一种方法来证明。
|
||||
|
||||
1. 反证法:如果交换方案中任意两个元素/相邻的两个元素后,答案不会变得更好,那么可以推定目前的解已经是最优解了。
|
||||
2. 归纳法:先算得出边界情况(例如 $n = 1$)的最优解 $F_1$,然后再证明:对于每个 $n$,$F_{n+1}$ 都可以由 $F_{n}$ 推导出结果。
|
||||
1. 反证法:如果交换方案中任意两个元素/相邻的两个元素后,答案不会变得更好,那么可以推定目前的解已经是最优解了。
|
||||
2. 归纳法:先算得出边界情况(例如 $n = 1$)的最优解 $F_1$,然后再证明:对于每个 $n$,$F_{n+1}$ 都可以由 $F_{n}$ 推导出结果。
|
||||
|
||||
## 要点
|
||||
|
||||
|
|
@ -25,8 +25,8 @@
|
|||
|
||||
在提高组难度以下的题目中,最常见的贪心有两种。
|
||||
|
||||
- 「我们将 XXX 按照某某顺序排序,然后按某种顺序(例如从小到大)选择。」。
|
||||
- 「我们每次都取 XXX 中最大/小的东西,并更新 XXX。」(有时「XXX 中最大/小的东西」可以优化,比如用优先队列维护)
|
||||
- 「我们将 XXX 按照某某顺序排序,然后按某种顺序(例如从小到大)选择。」。
|
||||
- 「我们每次都取 XXX 中最大/小的东西,并更新 XXX。」(有时「XXX 中最大/小的东西」可以优化,比如用优先队列维护)
|
||||
|
||||
二者的区别在于一种是离线的,先处理后选择;一种是在线的,边处理边选择。
|
||||
|
||||
|
|
@ -48,7 +48,7 @@
|
|||
|
||||
### 邻项交换法的例题
|
||||
|
||||
???+note "[NOIP 2012 国王游戏](https://vijos.org/p/1779)"
|
||||
???+ note "[NOIP 2012 国王游戏](https://vijos.org/p/1779)"
|
||||
恰逢 H 国国庆,国王邀请 n 位大臣来玩一个有奖游戏。首先,他让每个大臣在左、右手上面分别写下一个整数,国王自己也在左、右手上各写一个整数。然后,让这 n 位大臣排成一排,国王站在队伍的最前面。排好队后,所有的大臣都会获得国王奖赏的若干金币,每位大臣获得的金币数分别是:排在该大臣前面的所有人的左手上的数的乘积除以他自己右手上的数,然后向下取整得到的结果。
|
||||
|
||||
国王不希望某一个大臣获得特别多的奖赏,所以他想请你帮他重新安排一下队伍的顺序,使得获得奖赏最多的大臣,所获奖赏尽可能的少。注意,国王的位置始终在队伍的最前面。
|
||||
|
|
@ -92,14 +92,14 @@
|
|||
|
||||
### 后悔法的例题
|
||||
|
||||
???+note "[「USACO09OPEN」工作调度 Work Scheduling](https://www.luogu.com.cn/problem/P2949)"
|
||||
???+ note "[「USACO09OPEN」工作调度 Work Scheduling](https://www.luogu.com.cn/problem/P2949)"
|
||||
约翰的工作日从 $0$ 时刻开始,有 $10^9$ 个单位时间。在任一单位时间,他都可以选择编号 $1$ 到 $N$ 的 $N(1 \leq N \leq 10^5)$ 项工作中的任意一项工作来完成。工作 $i$ 的截止时间是 $D_i(1 \leq D_i \leq 10^9)$,完成后获利是 $P_i( 1\leq P_i\leq 10^9 )$。在给定的工作利润和截止时间下,求约翰能够获得的利润最大为多少。
|
||||
|
||||
??? note "解题思路"
|
||||
1. 先假设每一项工作都做,将各项工作按截止时间排序后入队;
|
||||
1. 先假设每一项工作都做,将各项工作按截止时间排序后入队;
|
||||
2. 在判断第 `i` 项工作做与不做时,若其截至时间符合条件,则将其与队中报酬最小的元素比较,若第 `i` 项工作报酬较高(后悔),则 `ans += a[i].p - q.top()`。
|
||||
用优先队列(小根堆)来维护队首元素最小。
|
||||
3. 当 `a[i].d<=q.size()` 可以这么理解从 0 开始到 `a[i].d` 这个时间段只能做 `a[i].d` 个任务,而若 `q.size()>=a[i].d` 说明完成 `q.size()` 个任务时间大于等于 `a[i].d` 的时间,所以当第 `i` 个任务获利比较大的时候应该把最小的任务从优先级队列中换出。
|
||||
3. 当 `a[i].d<=q.size()` 可以这么理解从 0 开始到 `a[i].d` 这个时间段只能做 `a[i].d` 个任务,而若 `q.size()>=a[i].d` 说明完成 `q.size()` 个任务时间大于等于 `a[i].d` 的时间,所以当第 `i` 个任务获利比较大的时候应该把最小的任务从优先级队列中换出。
|
||||
|
||||
??? note "参考代码"
|
||||
```cpp
|
||||
|
|
@ -108,15 +108,15 @@
|
|||
|
||||
##### 复杂度分析
|
||||
|
||||
- 空间复杂度:当输入 $n$ 个任务时使用 $n$ 个 $a$ 数组元素,优先队列中最差情况下会储存 $n$ 个元素,则空间复杂度为 $O(n)$。
|
||||
- 空间复杂度:当输入 $n$ 个任务时使用 $n$ 个 $a$ 数组元素,优先队列中最差情况下会储存 $n$ 个元素,则空间复杂度为 $O(n)$。
|
||||
|
||||
- 时间复杂度:`std::sort` 的时间复杂度为 $O(n\log n)$,维护优先队列的时间复杂度为 $O(n\log n)$,综上所述,时间复杂度为 $O(n\log n)$。
|
||||
- 时间复杂度:`std::sort` 的时间复杂度为 $O(n\log n)$,维护优先队列的时间复杂度为 $O(n\log n)$,综上所述,时间复杂度为 $O(n\log n)$。
|
||||
|
||||
## 习题
|
||||
|
||||
- [P1209\[USACO1.3\]修理牛棚 Barn Repair - 洛谷](https://www.luogu.com.cn/problem/P1209)
|
||||
- [P2123 皇后游戏 - 洛谷](https://www.luogu.com.cn/problem/P2123)
|
||||
- [LeetCode 上标签为贪心算法的题目](https://leetcode-cn.com/tag/greedy/)
|
||||
- [P1209\[USACO1.3\] 修理牛棚 Barn Repair - 洛谷](https://www.luogu.com.cn/problem/P1209)
|
||||
- [P2123 皇后游戏 - 洛谷](https://www.luogu.com.cn/problem/P2123)
|
||||
- [LeetCode 上标签为贪心算法的题目](https://leetcode-cn.com/tag/greedy/)
|
||||
|
||||
## 参考资料与注释
|
||||
|
||||
|
|
|
|||
|
|
@ -111,4 +111,4 @@ iRightChild(i) = 2 * i + 2;
|
|||
|
||||
## 外部链接
|
||||
|
||||
- [堆排序 - 维基百科,自由的百科全书](https://zh.wikipedia.org/wiki/%E5%A0%86%E6%8E%92%E5%BA%8F)
|
||||
- [堆排序 - 维基百科,自由的百科全书](https://zh.wikipedia.org/wiki/%E5%A0%86%E6%8E%92%E5%BA%8F)
|
||||
|
|
|
|||
|
|
@ -86,9 +86,9 @@
|
|||
|
||||
### 分治法实现归并排序
|
||||
|
||||
1. 当数组长度为 $1$ 时,该数组就已经是有序的,不用再分解。
|
||||
1. 当数组长度为 $1$ 时,该数组就已经是有序的,不用再分解。
|
||||
|
||||
2. 当数组长度大于 $1$ 时,该数组很可能不是有序的。此时将该数组分为两段,再分别检查两个数组是否有序(用第 1 条)。如果有序,则将它们合并为一个有序数组;否则对不有序的数组重复第 2 条,再合并。
|
||||
2. 当数组长度大于 $1$ 时,该数组很可能不是有序的。此时将该数组分为两段,再分别检查两个数组是否有序(用第 1 条)。如果有序,则将它们合并为一个有序数组;否则对不有序的数组重复第 2 条,再合并。
|
||||
|
||||
用数学归纳法可以证明该流程可以将一个数组转变为有序数组。
|
||||
|
||||
|
|
@ -144,7 +144,7 @@
|
|||
|
||||
重复上述过程直至数组只剩一个有序段,该段就是排好序的原数组。
|
||||
|
||||
???+note "为什么是 $\le n$ 而不是 $= n$"
|
||||
???+ note " 为什么是 $\le n$ 而不是 $= n$"
|
||||
数组的长度很可能不是 $2^x$,此时在最后就可能出现长度不完整的段,可能出现最后一个段是独立的情况。
|
||||
|
||||
#### 实现
|
||||
|
|
@ -193,6 +193,6 @@
|
|||
|
||||
## 外部链接
|
||||
|
||||
- [Merge Sort - GeeksforGeeks](https://www.geeksforgeeks.org/merge-sort/)
|
||||
- [归并排序 - 维基百科,自由的百科全书](https://zh.wikipedia.org/wiki/%E5%BD%92%E5%B9%B6%E6%8E%92%E5%BA%8F)
|
||||
- [逆序对 - 维基百科,自由的百科全书](https://zh.wikipedia.org/wiki/%E9%80%86%E5%BA%8F%E5%AF%B9)
|
||||
- [Merge Sort - GeeksforGeeks](https://www.geeksforgeeks.org/merge-sort/)
|
||||
- [归并排序 - 维基百科,自由的百科全书](https://zh.wikipedia.org/wiki/%E5%BD%92%E5%B9%B6%E6%8E%92%E5%BA%8F)
|
||||
- [逆序对 - 维基百科,自由的百科全书](https://zh.wikipedia.org/wiki/%E9%80%86%E5%BA%8F%E5%AF%B9)
|
||||
|
|
|
|||
|
|
@ -8,7 +8,7 @@ C++ 标准库中实现了前缀和函数 [`std::partial_sum`](https://zh.cpprefe
|
|||
|
||||
### 例题
|
||||
|
||||
!!! 例题
|
||||
??? 例题
|
||||
有 $N$ 个的正整数放到数组 $A$ 里,现在要求一个新的数组 $B$,新数组的第 $i$ 个数 $B[i]$ 是原数组 $A$ 第 $0$ 到第 $i$ 个数的和。
|
||||
|
||||
输入:
|
||||
|
|
@ -36,7 +36,7 @@ C++ 标准库中实现了前缀和函数 [`std::partial_sum`](https://zh.cpprefe
|
|||
|
||||
多维前缀和的普通求解方法几乎都是基于容斥原理。
|
||||
|
||||
???+note "示例:一维前缀和扩展到二维前缀和"
|
||||
???+ note "示例:一维前缀和扩展到二维前缀和"
|
||||
比如我们有这样一个矩阵 $a$,可以视为二维数组:
|
||||
|
||||
```text
|
||||
|
|
@ -64,7 +64,7 @@ C++ 标准库中实现了前缀和函数 [`std::partial_sum`](https://zh.cpprefe
|
|||
|
||||
#### 例题
|
||||
|
||||
???+note "[洛谷 P1387 最大正方形](https://www.luogu.com.cn/problem/P1387)"
|
||||
???+ note "[洛谷 P1387 最大正方形](https://www.luogu.com.cn/problem/P1387)"
|
||||
在一个 $n\times m$ 的只包含 $0$ 和 $1$ 的矩阵里找出一个不包含 $0$ 的最大正方形,输出边长。
|
||||
|
||||
??? note "参考代码"
|
||||
|
|
@ -93,7 +93,7 @@ C++ 标准库中实现了前缀和函数 [`std::partial_sum`](https://zh.cpprefe
|
|||
设 $\textit{sum}_i$ 表示结点 $i$ 到根节点的权值总和。
|
||||
然后:
|
||||
|
||||
- 若是点权,$x,y$ 路径上的和为 $\textit{sum}_x + \textit{sum}_y - \textit{sum}_\textit{lca} - \textit{sum}_{\textit{fa}_\textit{lca}}$。
|
||||
- 若是点权,$x,y$ 路径上的和为 $\textit{sum}_x + \textit{sum}_y - \textit{sum}_\textit{lca} - \textit{sum}_{\textit{fa}_\textit{lca}}$。
|
||||
- 若是边权,$x,y$ 路径上的和为 $\textit{sum}_x + \textit{sum}_y - 2\cdot\textit{sum}_{lca}$。
|
||||
|
||||
LCA 的求法参见 [最近公共祖先](../graph/lca.md)。
|
||||
|
|
@ -108,12 +108,12 @@ C++ 标准库中实现了前缀和函数 [`std::partial_sum`](https://zh.cpprefe
|
|||
|
||||
### 性质
|
||||
|
||||
- $a_i$ 的值是 $b_i$ 的前缀和,即 $a_n=\sum\limits_{i=1}^nb_i$
|
||||
- 计算 $a_i$ 的前缀和 $sum=\sum\limits_{i=1}^na_i=\sum\limits_{i=1}^n\sum\limits_{j=1}^{i}b_j=\sum\limits_{i}^n(n-i+1)b_i$
|
||||
- $a_i$ 的值是 $b_i$ 的前缀和,即 $a_n=\sum\limits_{i=1}^nb_i$
|
||||
- 计算 $a_i$ 的前缀和 $sum=\sum\limits_{i=1}^na_i=\sum\limits_{i=1}^n\sum\limits_{j=1}^{i}b_j=\sum\limits_{i}^n(n-i+1)b_i$
|
||||
|
||||
它可以维护多次对序列的一个区间加上一个数,并在最后询问某一位的数或是多次询问某一位的数。注意修改操作一定要在查询操作之前。
|
||||
|
||||
???+note "示例"
|
||||
???+ note "示例"
|
||||
譬如使 $[l,r]$ 中的每个数加上一个 $k$,即
|
||||
|
||||
$$
|
||||
|
|
@ -171,7 +171,7 @@ $$
|
|||
|
||||
### 例题
|
||||
|
||||
???+note "[洛谷 3128 最大流](https://www.luogu.com.cn/problem/P3128)"
|
||||
???+ note "[洛谷 3128 最大流](https://www.luogu.com.cn/problem/P3128)"
|
||||
FJ 给他的牛棚的 $N(2 \le N \le 50,000)$ 个隔间之间安装了 $N-1$ 根管道,隔间编号从 $1$ 到 $N$。所有隔间都被管道连通了。
|
||||
|
||||
FJ 有 $K(1 \le K \le 100,000)$ 条运输牛奶的路线,第 $i$ 条路线从隔间 $s_i$ 运输到隔间 $t_i$。一条运输路线会给它的两个端点处的隔间以及中间途径的所有隔间带来一个单位的运输压力,你需要计算压力最大的隔间的压力是多少。
|
||||
|
|
@ -188,53 +188,53 @@ $$
|
|||
|
||||
前缀和:
|
||||
|
||||
- [洛谷 B3612【深进 1. 例 1】求区间和](https://www.luogu.com.cn/problem/B3612)
|
||||
- [洛谷 U69096 前缀和的逆](https://www.luogu.com.cn/problem/U69096)
|
||||
- [AT2412 最大の和](https://vjudge.net/problem/AtCoder-joi2007ho_a#author=wuyudi)
|
||||
- [「USACO16JAN」子共七 Subsequences Summing to Sevens](https://www.luogu.com.cn/problem/P3131)
|
||||
- [「USACO05JAN」Moo Volume S](https://www.luogu.com.cn/problem/P6067)
|
||||
- [洛谷 B3612【深进 1. 例 1】求区间和](https://www.luogu.com.cn/problem/B3612)
|
||||
- [洛谷 U69096 前缀和的逆](https://www.luogu.com.cn/problem/U69096)
|
||||
- [AT2412 最大の和](https://vjudge.net/problem/AtCoder-joi2007ho_a#author=wuyudi)
|
||||
- [「USACO16JAN」子共七 Subsequences Summing to Sevens](https://www.luogu.com.cn/problem/P3131)
|
||||
- [「USACO05JAN」Moo Volume S](https://www.luogu.com.cn/problem/P6067)
|
||||
|
||||
* * *
|
||||
***
|
||||
|
||||
二维/多维前缀和:
|
||||
|
||||
- [HDU 6514 Monitor](https://vjudge.net/problem/HDU-6514)
|
||||
- [洛谷 P1387 最大正方形](https://www.luogu.com.cn/problem/P1387)
|
||||
- [「HNOI2003」激光炸弹](https://www.luogu.com.cn/problem/P2280)
|
||||
- [HDU 6514 Monitor](https://vjudge.net/problem/HDU-6514)
|
||||
- [洛谷 P1387 最大正方形](https://www.luogu.com.cn/problem/P1387)
|
||||
- [「HNOI2003」激光炸弹](https://www.luogu.com.cn/problem/P2280)
|
||||
|
||||
* * *
|
||||
***
|
||||
|
||||
基于 DP 计算高维前缀和:
|
||||
|
||||
- [CF 165E Compatible Numbers](https://codeforces.com/contest/165/problem/E)
|
||||
- [CF 383E Vowels](https://codeforces.com/problemset/problem/383/E)
|
||||
- [ARC 100C Or Plus Max](https://atcoder.jp/contests/arc100/tasks/arc100_c)
|
||||
- [CF 165E Compatible Numbers](https://codeforces.com/contest/165/problem/E)
|
||||
- [CF 383E Vowels](https://codeforces.com/problemset/problem/383/E)
|
||||
- [ARC 100C Or Plus Max](https://atcoder.jp/contests/arc100/tasks/arc100_c)
|
||||
|
||||
* * *
|
||||
***
|
||||
|
||||
树上前缀和:
|
||||
|
||||
- [LOJ 10134.Dis](https://loj.ac/problem/10134)
|
||||
- [LOJ 2491. 求和](https://loj.ac/problem/2491)
|
||||
- [LOJ 10134.Dis](https://loj.ac/problem/10134)
|
||||
- [LOJ 2491. 求和](https://loj.ac/problem/2491)
|
||||
|
||||
* * *
|
||||
***
|
||||
|
||||
差分:
|
||||
|
||||
- [树状数组 3:区间修改,区间查询](https://loj.ac/problem/132)
|
||||
- [P3397 地毯](https://www.luogu.com.cn/problem/P3397)
|
||||
- [「Poetize6」IncDec Sequence](https://www.luogu.com.cn/problem/P4552)
|
||||
- [树状数组 3:区间修改,区间查询](https://loj.ac/problem/132)
|
||||
- [P3397 地毯](https://www.luogu.com.cn/problem/P3397)
|
||||
- [「Poetize6」IncDec Sequence](https://www.luogu.com.cn/problem/P4552)
|
||||
|
||||
* * *
|
||||
***
|
||||
|
||||
树上差分:
|
||||
|
||||
- [洛谷 3128 最大流](https://www.luogu.com.cn/problem/P3128)
|
||||
- [JLOI2014 松鼠的新家](https://loj.ac/problem/2236)
|
||||
- [NOIP2015 运输计划](http://uoj.ac/problem/150)
|
||||
- [NOIP2016 天天爱跑步](http://uoj.ac/problem/261)
|
||||
- [洛谷 3128 最大流](https://www.luogu.com.cn/problem/P3128)
|
||||
- [JLOI2014 松鼠的新家](https://loj.ac/problem/2236)
|
||||
- [NOIP2015 运输计划](http://uoj.ac/problem/150)
|
||||
- [NOIP2016 天天爱跑步](http://uoj.ac/problem/261)
|
||||
|
||||
* * *
|
||||
***
|
||||
|
||||
## 参考资料与注释
|
||||
|
||||
|
|
|
|||
|
|
@ -12,9 +12,9 @@
|
|||
|
||||
快速排序分为三个过程:
|
||||
|
||||
1. 将数列划分为两部分(要求保证相对大小关系);
|
||||
2. 递归到两个子序列中分别进行快速排序;
|
||||
3. 不用合并,因为此时数列已经完全有序。
|
||||
1. 将数列划分为两部分(要求保证相对大小关系);
|
||||
2. 递归到两个子序列中分别进行快速排序;
|
||||
3. 不用合并,因为此时数列已经完全有序。
|
||||
|
||||
和归并排序不同,第一步并不是直接分成前后两个序列,而是在分的过程中要保证相对大小关系。具体来说,第一步要是要把数列分成两个部分,然后保证前一个子数列中的数都小于后一个子数列中的数。为了保证平均时间复杂度,一般是随机选择一个数 $m$ 来当做两个子数列的分界。
|
||||
|
||||
|
|
@ -151,9 +151,9 @@
|
|||
|
||||
所以,我们需要对朴素快速排序思想加以优化。较为常见的优化思路有以下三种[^ref3]。
|
||||
|
||||
- 通过 **三数取中(即选取第一个、最后一个以及中间的元素中的中位数)** 的方法来选择两个子序列的分界元素(即比较基准)。这样可以避免极端数据(如升序序列或降序序列)带来的退化;
|
||||
- 当序列较短时,使用 **插入排序** 的效率更高;
|
||||
- 每趟排序后,**将与分界元素相等的元素聚集在分界元素周围**,这样可以避免极端数据(如序列中大部分元素都相等)带来的退化。
|
||||
- 通过 **三数取中(即选取第一个、最后一个以及中间的元素中的中位数)** 的方法来选择两个子序列的分界元素(即比较基准)。这样可以避免极端数据(如升序序列或降序序列)带来的退化;
|
||||
- 当序列较短时,使用 **插入排序** 的效率更高;
|
||||
- 每趟排序后,**将与分界元素相等的元素聚集在分界元素周围**,这样可以避免极端数据(如序列中大部分元素都相等)带来的退化。
|
||||
|
||||
下面列举了几种较为成熟的快速排序优化方式。
|
||||
|
||||
|
|
@ -298,9 +298,9 @@ T find_kth_element(T arr[], int rk, const int len) {
|
|||
|
||||
该算法的流程如下:
|
||||
|
||||
1. 将整个序列划分为 $\left \lfloor \dfrac{n}{5} \right \rfloor$ 组,每组元素数不超过 5 个;
|
||||
2. 寻找每组元素的中位数(因为元素个数较少,可以直接使用 [插入排序](./insertion-sort.md) 等算法)。
|
||||
3. 找出这 $\left \lfloor \dfrac{n}{5} \right \rfloor$ 组元素中位数中的中位数。将该元素作为前述算法中每次划分时的分界值即可。
|
||||
1. 将整个序列划分为 $\left \lfloor \dfrac{n}{5} \right \rfloor$ 组,每组元素数不超过 5 个;
|
||||
2. 寻找每组元素的中位数(因为元素个数较少,可以直接使用 [插入排序](./insertion-sort.md) 等算法)。
|
||||
3. 找出这 $\left \lfloor \dfrac{n}{5} \right \rfloor$ 组元素中位数中的中位数。将该元素作为前述算法中每次划分时的分界值即可。
|
||||
|
||||
#### 时间复杂度证明
|
||||
|
||||
|
|
|
|||
|
|
@ -89,7 +89,7 @@ void radix_sort() {
|
|||
|
||||
实际上并非必须从后往前枚举才是稳定排序,只需对 `cnt` 数组进行等价于 `std::exclusive_scan` 的操作即可。
|
||||
|
||||
???+ note "例题 [洛谷 P1177 【模板】快速排序](https://www.luogu.com.cn/problem/P1177)"
|
||||
???+ note " 例题 [洛谷 P1177【模板】快速排序](https://www.luogu.com.cn/problem/P1177)"
|
||||
给出 $n$ 个正整数,从小到大输出。
|
||||
|
||||
```cpp
|
||||
|
|
|
|||
|
|
@ -8,9 +8,9 @@
|
|||
|
||||
排序对不相邻的记录进行比较和移动:
|
||||
|
||||
1. 将待排序序列分为若干子序列(每个子序列的元素在原始数组中间距相同);
|
||||
2. 对这些子序列进行插入排序;
|
||||
3. 减小每个子序列中元素之间的间距,重复上述过程直至间距减少为 1。
|
||||
1. 将待排序序列分为若干子序列(每个子序列的元素在原始数组中间距相同);
|
||||
2. 对这些子序列进行插入排序;
|
||||
3. 减小每个子序列中元素之间的间距,重复上述过程直至间距减少为 1。
|
||||
|
||||
## 性质
|
||||
|
||||
|
|
|
|||
|
|
@ -10,17 +10,17 @@
|
|||
|
||||
写模拟题时,遵循以下的建议有可能会提升做题速度:
|
||||
|
||||
- 在动手写代码之前,在草纸上尽可能地写好要实现的流程。
|
||||
- 在代码中,尽量把每个部分模块化,写成函数、结构体或类。
|
||||
- 对于一些可能重复用到的概念,可以统一转化,方便处理:如,某题给你 "YY-MM-DD 时:分" 把它抽取到一个函数,处理成秒,会减少概念混淆。
|
||||
- 调试时分块调试。模块化的好处就是可以方便的单独调某一部分。
|
||||
- 写代码的时候一定要思路清晰,不要想到什么写什么,要按照落在纸上的步骤写。
|
||||
- 在动手写代码之前,在草纸上尽可能地写好要实现的流程。
|
||||
- 在代码中,尽量把每个部分模块化,写成函数、结构体或类。
|
||||
- 对于一些可能重复用到的概念,可以统一转化,方便处理:如,某题给你 "YY-MM-DD 时:分" 把它抽取到一个函数,处理成秒,会减少概念混淆。
|
||||
- 调试时分块调试。模块化的好处就是可以方便的单独调某一部分。
|
||||
- 写代码的时候一定要思路清晰,不要想到什么写什么,要按照落在纸上的步骤写。
|
||||
|
||||
实际上,上述步骤在解决其它类型的题目时也是很有帮助的。
|
||||
|
||||
## 例题详解
|
||||
|
||||
???+note " [Climbing Worm](https://vjudge.net/problem/Kattis-climbingworm)"
|
||||
???+ note "[Climbing Worm](https://vjudge.net/problem/Kattis-climbingworm)"
|
||||
一只长度不计的蠕虫位于 $n$ 英寸深的井的底部。它每次向上爬 $u$ 英寸,但是必须休息一次才能再次向上爬。在休息的时候,它滑落了 $d$ 英寸。之后它将重复向上爬和休息的过程。蠕虫爬出井口需要至少爬多少次?如果蠕虫爬完后刚好到达井的顶部,我们也设作蠕虫已经爬出井口。
|
||||
|
||||
??? note "解题思路"
|
||||
|
|
@ -33,6 +33,6 @@
|
|||
|
||||
## 习题
|
||||
|
||||
- [「NOIP2014」生活大爆炸版石头剪刀布 - Universal Online Judge](https://uoj.ac/problem/15)
|
||||
- [「OpenJudge 3750」魔兽世界](http://bailian.openjudge.cn/practice/3750/)
|
||||
- [「SDOI2010」猪国杀 - LibreOJ](https://loj.ac/problem/2885)
|
||||
- [「NOIP2014」生活大爆炸版石头剪刀布 - Universal Online Judge](https://uoj.ac/problem/15)
|
||||
- [「OpenJudge 3750」魔兽世界](http://bailian.openjudge.cn/practice/3750/)
|
||||
- [「SDOI2010」猪国杀 - LibreOJ](https://loj.ac/problem/2885)
|
||||
|
|
|
|||
|
|
@ -40,4 +40,4 @@
|
|||
|
||||
## 外部链接
|
||||
|
||||
- [排序算法 - 维基百科,自由的百科全书](https://zh.wikipedia.org/wiki/%E6%8E%92%E5%BA%8F%E7%AE%97%E6%B3%95)
|
||||
- [排序算法 - 维基百科,自由的百科全书](https://zh.wikipedia.org/wiki/%E6%8E%92%E5%BA%8F%E7%AE%97%E6%B3%95)
|
||||
|
|
|
|||
|
|
@ -82,7 +82,7 @@ std::sort(a, a + n, cmp);
|
|||
|
||||
C++ 标准并未严格要求此函数的实现算法,具体实现取决于编译器。[libstdc++](https://github.com/mirrors/gcc/blob/master/libstdc++-v3/include/bits/stl_algo.h) 和 [libc++](http://llvm.org/svn/llvm-project/libcxx/trunk/include/algorithm) 中的实现都使用了 [内省排序](./quick-sort.md#内省排序)。
|
||||
|
||||
## std::nth_element
|
||||
## std::nth\_element
|
||||
|
||||
参见:[`std::nth_element`](https://zh.cppreference.com/w/cpp/algorithm/nth_element)
|
||||
|
||||
|
|
@ -101,7 +101,7 @@ std::nth_element(first, nth, last, cmp);
|
|||
|
||||
它常用于构建 [K-D Tree](../ds/kdt.md)。
|
||||
|
||||
## std::stable_sort
|
||||
## std::stable\_sort
|
||||
|
||||
参见:[`std::stable_sort`](https://zh.cppreference.com/w/cpp/algorithm/stable_sort)
|
||||
|
||||
|
|
@ -116,7 +116,7 @@ std::stable_sort(first, last, cmp);
|
|||
|
||||
时间复杂度为 $O(n\log (n)^2)$,当额外内存可用时,复杂度为 $O(n\log n)$。
|
||||
|
||||
## std::partial_sort
|
||||
## std::partial\_sort
|
||||
|
||||
参见:[`std::partial_sort`](https://zh.cppreference.com/w/cpp/algorithm/partial_sort)
|
||||
|
||||
|
|
@ -179,20 +179,20 @@ std::sort(da + 1, da + 1 + 10, cmp); // 使用 cmp 函数进行比较,从大
|
|||
|
||||
严格弱序的要求:
|
||||
|
||||
1. $x \not< x$(非自反性)
|
||||
2. 若 $x < y$,则 $y \not< x$(非对称性)
|
||||
3. 若 $x < y, y < z$,则 $x < z$(传递性)
|
||||
4. 若 $x \not< y, y \not< x, y \not< z, z \not< y$,则 $x \not< z, z \not< x$(不可比性的传递性)
|
||||
1. $x \not< x$(非自反性)
|
||||
2. 若 $x < y$,则 $y \not< x$(非对称性)
|
||||
3. 若 $x < y, y < z$,则 $x < z$(传递性)
|
||||
4. 若 $x \not< y, y \not< x, y \not< z, z \not< y$,则 $x \not< z, z \not< x$(不可比性的传递性)
|
||||
|
||||
常见的错误做法:
|
||||
|
||||
- 使用 `<=` 来定义排序中的小于运算符。
|
||||
- 在调用排序运算符时,读取外部数值可能会改变的数组(常见于最短路算法)。
|
||||
- 将多个数的最大最小值进行比较的结果作为排序运算符(如皇后游戏/加工生产调度 中的经典错误)。
|
||||
- 使用 `<=` 来定义排序中的小于运算符。
|
||||
- 在调用排序运算符时,读取外部数值可能会改变的数组(常见于最短路算法)。
|
||||
- 将多个数的最大最小值进行比较的结果作为排序运算符(如皇后游戏/加工生产调度 中的经典错误)。
|
||||
|
||||
## 外部链接
|
||||
|
||||
- [浅谈邻项交换排序的应用以及需要注意的问题](https://ouuan.github.io/浅谈邻项交换排序的应用以及需要注意的问题/)
|
||||
- [浅谈邻项交换排序的应用以及需要注意的问题](https://ouuan.github.io/浅谈邻项交换排序的应用以及需要注意的问题/)
|
||||
|
||||
## 参考资料与注释
|
||||
|
||||
|
|
|
|||
|
|
@ -10,8 +10,8 @@ tim 排序在最好情况下的时间复杂度为 $O(n)$,最差情况下的时
|
|||
|
||||
tim 排序为了利用数组中本身就存在的连续且有序的子数组,以 RUN 作为合并操作的最小单位。其中,RUN 是一个满足以下性质的子数组:
|
||||
|
||||
- 一个 RUN 要么是非降序的,要么是严格升序的。
|
||||
- 一个 RUN 存在一个长度的下限。
|
||||
- 一个 RUN 要么是非降序的,要么是严格升序的。
|
||||
- 一个 RUN 存在一个长度的下限。
|
||||
|
||||
tim 排序的过程就是一个类似归并排序的过程,将数组划分为多个 RUN,然后以某种规则不断地合并两个 RUN,直到数组有序。具体过程如下:
|
||||
|
||||
|
|
@ -44,8 +44,8 @@ $$
|
|||
|
||||
## 参考资料
|
||||
|
||||
1. [Timsort](https://en.wikipedia.org/wiki/Timsort)
|
||||
2. [On the Worst-Case Complexity of TimSort](https://drops.dagstuhl.de/opus/volltexte/2018/9467/pdf/LIPIcs-ESA-2018-4.pdf)
|
||||
3. [original explanation by Tim Peters](https://bugs.python.org/file4451/timsort.txt)
|
||||
4. [java 实现](https://web.archive.org/web/20150716000631/https://android.googlesource.com/platform/libcore/+/gingerbread/luni/src/main/java/java/util/TimSort.java)
|
||||
5. [c 语言实现](http://svn.python.org/projects/python/trunk/Objects/listobject.c)
|
||||
1. [Timsort](https://en.wikipedia.org/wiki/Timsort)
|
||||
2. [On the Worst-Case Complexity of TimSort](https://drops.dagstuhl.de/opus/volltexte/2018/9467/pdf/LIPIcs-ESA-2018-4.pdf)
|
||||
3. [original explanation by Tim Peters](https://bugs.python.org/file4451/timsort.txt)
|
||||
4. [java 实现](https://web.archive.org/web/20150716000631/https://android.googlesource.com/platform/libcore/+/gingerbread/luni/src/main/java/java/util/TimSort.java)
|
||||
5. [c 语言实现](http://svn.python.org/projects/python/trunk/Objects/listobject.c)
|
||||
|
|
|
|||
|
|
@ -135,4 +135,4 @@
|
|||
|
||||
## 外部链接
|
||||
|
||||
- [Tournament sort - Wikipedia](https://en.wikipedia.org/wiki/Tournament_sort)
|
||||
- [Tournament sort - Wikipedia](https://en.wikipedia.org/wiki/Tournament_sort)
|
||||
|
|
|
|||
|
|
@ -10,7 +10,7 @@
|
|||
|
||||
使用排序预处理可以降低求解问题所需要的时间复杂度,通常是一个以空间换取时间的平衡。如果一个排序好的列表需要被多次分析的话,只需要耗费一次排序所需要的资源是很划算的,因为之后的每次分析都可以减少很多时间。
|
||||
|
||||
???+note "示例:检查给定数列中是否有相等的元素"
|
||||
???+ note "示例:检查给定数列中是否有相等的元素"
|
||||
考虑一个数列,你需要检查其中是否有元素相等。
|
||||
|
||||
一个朴素的做法是检查每一个数对,并判断这一对数是否相等。时间复杂度是 $O(n^2)$。
|
||||
|
|
|
|||
|
|
@ -8,11 +8,11 @@ author: H-J-Granger, orzAtalod, ksyx, Ir1d, Chrogeek, Enter-tainer, yiyangit, sh
|
|||
|
||||
例:
|
||||
|
||||
- `int main()` 写为 `int mian()` 之类的拼写错误。
|
||||
- `int main()` 写为 `int mian()` 之类的拼写错误。
|
||||
|
||||
- 写完 `struct` 或 `class` 忘记写分号。
|
||||
- 写完 `struct` 或 `class` 忘记写分号。
|
||||
|
||||
- 数组开太大,(在 OJ 上)使用了不合法的函数(例如多线程),或者函数声明但未定义,会引起链接错误。
|
||||
- 数组开太大,(在 OJ 上)使用了不合法的函数(例如多线程),或者函数声明但未定义,会引起链接错误。
|
||||
|
||||
- 函数参数类型不匹配。
|
||||
|
||||
|
|
@ -25,7 +25,7 @@ author: H-J-Granger, orzAtalod, ksyx, Ir1d, Chrogeek, Enter-tainer, yiyangit, sh
|
|||
//错误 没有与参数列表匹配的 重载函数 "std::max" 实例
|
||||
```
|
||||
|
||||
- 使用 `goto` 和 `switch-case` 的时候跳过了一些局部变量的初始化。
|
||||
- 使用 `goto` 和 `switch-case` 的时候跳过了一些局部变量的初始化。
|
||||
|
||||
## 不会引起 CE 但会引起 Warning 的错误
|
||||
|
||||
|
|
@ -47,7 +47,7 @@ author: H-J-Granger, orzAtalod, ksyx, Ir1d, Chrogeek, Enter-tainer, yiyangit, sh
|
|||
// 警告 运算符不正确: 在 Boolean 上下文中执行了常量赋值。应考虑改用“==”。
|
||||
```
|
||||
|
||||
- 如果确实想在原应使用 `==` 的语句里使用 `=`(比如 `while (foo = bar)`),又不想收到 Warning,可以使用 **双括号**:`while ((foo = bar))`。
|
||||
- 如果确实想在原应使用 `==` 的语句里使用 `=`(比如 `while (foo = bar)`),又不想收到 Warning,可以使用 **双括号**:`while ((foo = bar))`。
|
||||
|
||||
- 由于运算符优先级产生的错误。
|
||||
|
||||
|
|
@ -62,18 +62,18 @@ author: H-J-Granger, orzAtalod, ksyx, Ir1d, Chrogeek, Enter-tainer, yiyangit, sh
|
|||
// 警告 “<<”: 检查运算符优先级是否有可能的错误;使用括号阐明优先级
|
||||
```
|
||||
|
||||
- 不正确地使用 `static` 修饰符。
|
||||
- 不正确地使用 `static` 修饰符。
|
||||
|
||||
- 使用 `scanf` 读入的时候没加取地址符 `&`。
|
||||
- 使用 `scanf` 读入的时候没加取地址符 `&`。
|
||||
|
||||
- 使用 `scanf` 或 `printf` 的时候参数类型与格式指定符不符。
|
||||
- 使用 `scanf` 或 `printf` 的时候参数类型与格式指定符不符。
|
||||
|
||||
- 同时使用位运算和逻辑运算符 `==` 并且未加括号。
|
||||
- 示例:`(x >> j) & 3 == 2`
|
||||
- 示例:`(x >> j) & 3 == 2`
|
||||
|
||||
- `int` 字面量溢出。
|
||||
|
||||
- 示例:`long long x = 0x7f7f7f7f7f7f7f7f`,`1<<62`。
|
||||
- 示例:`long long x = 0x7f7f7f7f7f7f7f7f`,`1<<62`。
|
||||
|
||||
- 未初始化局部变量。
|
||||
|
||||
|
|
@ -102,7 +102,7 @@ author: H-J-Granger, orzAtalod, ksyx, Ir1d, Chrogeek, Enter-tainer, yiyangit, sh
|
|||
|
||||
有兴趣的话可以看 <https://www.ralfj.de/blog/2019/07/14/uninit.html>,尽管其是用 Rust 做的实验,但是本质是一样的。
|
||||
|
||||
- 局部变量与全局变量重名,导致全局变量被意外覆盖。(开 `-Wshadow` 就可检查此类错误。)
|
||||
- 局部变量与全局变量重名,导致全局变量被意外覆盖。(开 `-Wshadow` 就可检查此类错误。)
|
||||
|
||||
- 运算符重载后引发的输出错误。
|
||||
- 示例:
|
||||
|
|
@ -119,16 +119,16 @@ author: H-J-Granger, orzAtalod, ksyx, Ir1d, Chrogeek, Enter-tainer, yiyangit, sh
|
|||
|
||||
### 会导致 WA 的错误
|
||||
|
||||
- 上一组数据处理完毕,读入下一组数据前,未清空数组。
|
||||
- 上一组数据处理完毕,读入下一组数据前,未清空数组。
|
||||
|
||||
- 读入优化未判断负数。
|
||||
- 读入优化未判断负数。
|
||||
|
||||
- 所用数据类型位宽不足,导致溢出。
|
||||
- 如习语“三年 OI 一场空,不开 `long long` 见祖宗”所描述的场景。选手因为没有在正确的地方开 `long long`(将整数定义为 `long long` 类型),导致得出错误的答案而失分。
|
||||
- 如习语“三年 OI 一场空,不开 `long long` 见祖宗”所描述的场景。选手因为没有在正确的地方开 `long long`(将整数定义为 `long long` 类型),导致得出错误的答案而失分。
|
||||
|
||||
- 存图时,节点编号 0 开始,而题目给的边中两个端点的编号从 1 开始,读入的时候忘记 -1。
|
||||
- 存图时,节点编号 0 开始,而题目给的边中两个端点的编号从 1 开始,读入的时候忘记 -1。
|
||||
|
||||
- 大/小于号打错或打反。
|
||||
- 大/小于号打错或打反。
|
||||
|
||||
- 在执行 `ios::sync_with_stdio(false);` 后混用 `scanf/printf` 和 `std::cin/std::cout` 两种 IO,导致输入/输出错乱。
|
||||
|
||||
|
|
@ -154,7 +154,7 @@ author: H-J-Granger, orzAtalod, ksyx, Ir1d, Chrogeek, Enter-tainer, yiyangit, sh
|
|||
}
|
||||
```
|
||||
|
||||
- 特别的,也不能在执行 `ios::sync_with_stdio(false);` 后使用 `freopen`。
|
||||
- 特别的,也不能在执行 `ios::sync_with_stdio(false);` 后使用 `freopen`。
|
||||
|
||||
- 由于宏的展开,且未加括号导致的错误。
|
||||
|
||||
|
|
@ -166,9 +166,9 @@ author: H-J-Granger, orzAtalod, ksyx, Ir1d, Chrogeek, Enter-tainer, yiyangit, sh
|
|||
```
|
||||
|
||||
- 哈希的时候没有使用 `unsigned` 导致的运算错误。
|
||||
- 对负数的右移运算会在最高位补 1。参见:[位运算](../math/bit.md)
|
||||
- 对负数的右移运算会在最高位补 1。参见:[位运算](../math/bit.md)
|
||||
|
||||
- 没有删除或注释掉调试输出语句。
|
||||
- 没有删除或注释掉调试输出语句。
|
||||
|
||||
- 误加了 `;`。
|
||||
|
||||
|
|
@ -180,11 +180,11 @@ author: H-J-Granger, orzAtalod, ksyx, Ir1d, Chrogeek, Enter-tainer, yiyangit, sh
|
|||
printf("OI Wiki!\n");
|
||||
```
|
||||
|
||||
- 哨兵值设置错误。例如,平衡树的 `0` 节点。
|
||||
- 哨兵值设置错误。例如,平衡树的 `0` 节点。
|
||||
|
||||
- 在类或结构体的构造函数中使用 `:` 初始化变量时,变量声明顺序不符合初始化时候的依赖关系。
|
||||
|
||||
- 成员变量的初始化顺序与它们在类中声明的顺序有关,而与初始化列表中的顺序无关。参见:[构造函数与成员初始化器列表](https://zh.cppreference.com/w/cpp/language/constructor) 的“初始化顺序”
|
||||
- 成员变量的初始化顺序与它们在类中声明的顺序有关,而与初始化列表中的顺序无关。参见:[构造函数与成员初始化器列表](https://zh.cppreference.com/w/cpp/language/constructor) 的“初始化顺序”
|
||||
- 示例:
|
||||
|
||||
```cpp
|
||||
|
|
@ -224,23 +224,23 @@ author: H-J-Granger, orzAtalod, ksyx, Ir1d, Chrogeek, Enter-tainer, yiyangit, sh
|
|||
|
||||
不同的操作系统使用不同的符号来标记换行,以下为几种常用系统的换行符:
|
||||
|
||||
- LF(用 `\n` 表示):`Unix` 或 `Unix` 兼容系统
|
||||
- LF(用 `\n` 表示):`Unix` 或 `Unix` 兼容系统
|
||||
|
||||
- CR+LF(用 `\r\n` 表示):`Windows`
|
||||
- CR+LF(用 `\r\n` 表示):`Windows`
|
||||
|
||||
- CR(用 `\r` 表示):`Mac OS` 至版本 9
|
||||
- CR(用 `\r` 表示):`Mac OS` 至版本 9
|
||||
|
||||
而 C/C++ 利用转义序列 `\n` 来换行,这可能会导致我们认为输入中的换行符也一定是由 `\n` 来表示,而只读入了一个字符来代表换行符,这就会导致我们没有完全读入输入文件。
|
||||
|
||||
以下为解决方案:
|
||||
|
||||
- 多次 `getchar()`,直到读到想要的字符为止。
|
||||
- 多次 `getchar()`,直到读到想要的字符为止。
|
||||
|
||||
- 使用 `cin` 读入,**这可能会增大代码常数**。
|
||||
- 使用 `cin` 读入,**这可能会增大代码常数**。
|
||||
|
||||
- 使用 `scanf("%s",str)` 读入一个字符串,然后取 `str[0]` 作为读入的字符。
|
||||
- 使用 `scanf("%s",str)` 读入一个字符串,然后取 `str[0]` 作为读入的字符。
|
||||
|
||||
- 使用 `scanf(" %c",&c)` 过滤掉所有空白字符。
|
||||
- 使用 `scanf(" %c",&c)` 过滤掉所有空白字符。
|
||||
|
||||
### 会导致未知的结果
|
||||
|
||||
|
|
@ -257,15 +257,15 @@ author: H-J-Granger, orzAtalod, ksyx, Ir1d, Chrogeek, Enter-tainer, yiyangit, sh
|
|||
|
||||
例如:
|
||||
|
||||
- 未正确设置循环的初值导致访问了下标为 -1 的值。
|
||||
- 未正确设置循环的初值导致访问了下标为 -1 的值。
|
||||
|
||||
- 无向图边表未开 2 倍。
|
||||
- 无向图边表未开 2 倍。
|
||||
|
||||
- 线段树未开 4 倍空间。
|
||||
- 线段树未开 4 倍空间。
|
||||
|
||||
- 看错数据范围,少打一个零。
|
||||
- 看错数据范围,少打一个零。
|
||||
|
||||
- 错误预估了算法的空间复杂度。
|
||||
- 错误预估了算法的空间复杂度。
|
||||
|
||||
- 写线段树的时候,`pushup` 或 `pushdown` 叶节点。
|
||||
|
||||
|
|
@ -292,7 +292,7 @@ author: H-J-Granger, orzAtalod, ksyx, Ir1d, Chrogeek, Enter-tainer, yiyangit, sh
|
|||
|
||||
例如:
|
||||
|
||||
- 未初始化就解引用指针。
|
||||
- 未初始化就解引用指针。
|
||||
|
||||
- 指针指向的内存区域已经释放。
|
||||
|
||||
|
|
@ -342,7 +342,7 @@ author: H-J-Granger, orzAtalod, ksyx, Ir1d, Chrogeek, Enter-tainer, yiyangit, sh
|
|||
|
||||
### 会导致 RE
|
||||
|
||||
- 没删文件操作(某些 OJ)。
|
||||
- 没删文件操作(某些 OJ)。
|
||||
|
||||
- 排序时比较函数的错误 `std::sort` 要求比较函数是严格弱序:`a<a` 为 `false`;若 `a<b` 为 `true`,则 `b<a` 为 `false`;若 `a<b` 为 `true` 且 `b<c` 为 `true`,则 `a<c` 为 `true`。其中要特别注意第二点。
|
||||
如果不满足上述要求,排序时很可能会 RE。
|
||||
|
|
@ -371,15 +371,15 @@ author: H-J-Granger, orzAtalod, ksyx, Ir1d, Chrogeek, Enter-tainer, yiyangit, sh
|
|||
|
||||
### 会导致 TLE
|
||||
|
||||
- 分治未判边界导致死递归。
|
||||
- 分治未判边界导致死递归。
|
||||
|
||||
- 死循环。
|
||||
|
||||
- 循环变量重名。
|
||||
- 循环变量重名。
|
||||
|
||||
- 循环方向反了。
|
||||
- 循环方向反了。
|
||||
|
||||
- BFS 时不标记某个状态是否已访问过。
|
||||
- BFS 时不标记某个状态是否已访问过。
|
||||
|
||||
- 使用宏展开编写 min/max
|
||||
|
||||
|
|
@ -412,19 +412,19 @@ author: H-J-Granger, orzAtalod, ksyx, Ir1d, Chrogeek, Enter-tainer, yiyangit, sh
|
|||
}
|
||||
```
|
||||
|
||||
- 没删文件操作(某些 OJ)。
|
||||
- 没删文件操作(某些 OJ)。
|
||||
|
||||
- 在 `for/while` 循环中重复执行复杂度非 $O(1)$ 的函数。严格来说,这可能会引起时间复杂度的改变。
|
||||
- 在 `for/while` 循环中重复执行复杂度非 $O(1)$ 的函数。严格来说,这可能会引起时间复杂度的改变。
|
||||
|
||||
### 会导致 MLE
|
||||
|
||||
- 数组过大。
|
||||
- 数组过大。
|
||||
|
||||
- STL 容器中插入了过多的元素。
|
||||
|
||||
- 经常是在一个会向 STL 插入元素的循环中死循环了。
|
||||
- 经常是在一个会向 STL 插入元素的循环中死循环了。
|
||||
|
||||
- 也有可能被卡了。
|
||||
- 也有可能被卡了。
|
||||
|
||||
### 会导致常数过大
|
||||
|
||||
|
|
@ -437,16 +437,16 @@ author: H-J-Granger, orzAtalod, ksyx, Ir1d, Chrogeek, Enter-tainer, yiyangit, sh
|
|||
const int mod = 998244353; // 正确,方便编译器按常量处理
|
||||
```
|
||||
|
||||
- 使用了不必要的递归(尾递归不在此列)。
|
||||
- 使用了不必要的递归(尾递归不在此列)。
|
||||
|
||||
- 将递归转化成迭代的时候,引入了大量额外运算。
|
||||
- 将递归转化成迭代的时候,引入了大量额外运算。
|
||||
|
||||
### 只在程序在本地运行的时候造成影响的错误
|
||||
|
||||
- 文件操作有可能会发生的错误:
|
||||
|
||||
- 对拍时未关闭文件指针 `fclose(fp)` 就又令 `fp = fopen()`。这会使得进程出现大量的文件野指针。
|
||||
- 对拍时未关闭文件指针 `fclose(fp)` 就又令 `fp = fopen()`。这会使得进程出现大量的文件野指针。
|
||||
|
||||
- `freopen()` 中的文件名未加 `.in`/`.out`。
|
||||
- `freopen()` 中的文件名未加 `.in`/`.out`。
|
||||
|
||||
- 使用堆空间后忘记 `delete` 或 `free`。
|
||||
- 使用堆空间后忘记 `delete` 或 `free`。
|
||||
|
|
|
|||
|
|
@ -4,7 +4,7 @@
|
|||
|
||||
注意这个技巧只适用于输入的值域不大(如,输入只有一个数,而且范围很小)的问题,否则可能会导致代码过长、MLE、打表需要的时间过长等问题。
|
||||
|
||||
???+note "例题"
|
||||
???+ note "例题"
|
||||
规定 $f(x)$ 为整数 $x$ 的二进制表示中 $1$ 的个数。输入一个正整数 $n$($n\leq 10^9$),输出 $\sum_{i=1}^n f^2(i)$。
|
||||
|
||||
如果对于每一个 $n$,都输出 $f(n)$ 的话,除了可能会 MLE 外,还有可能代码超过最大代码长度限制,导致编译不通过。
|
||||
|
|
@ -21,7 +21,7 @@ $$
|
|||
|
||||
一般来说,这样的问题对于处理单个函数值 $f(x)$ 很快,但是需要大量函数值求和(求积或某些可以快速合并的操作),枚举会超出时间限制,在找不到标准做法的情况下,分段打表是一个不错的选择。
|
||||
|
||||
???+note "注意事项"
|
||||
???+ note "注意事项"
|
||||
当上题中指数不是定值,但是范围较小,也可以考虑打表。
|
||||
|
||||
### 例题
|
||||
|
|
|
|||
|
|
@ -30,10 +30,10 @@ ICPC 主要分为区域赛(Regionals)和总决赛(World Finals)两部分
|
|||
|
||||
## 赛季赛程
|
||||
|
||||
- ICPC/CCPC 网络赛(8 月底至 9 月初)
|
||||
- ICPC/CCPC 区域赛(9 月底至 11 月底)
|
||||
- ICPC EC Final/CCPC Final(12 月中旬)
|
||||
- ICPC World Finals(次年 4 月至 6 月)
|
||||
- ICPC/CCPC 网络赛(8 月底至 9 月初)
|
||||
- ICPC/CCPC 区域赛(9 月底至 11 月底)
|
||||
- ICPC EC Final/CCPC Final(12 月中旬)
|
||||
- ICPC World Finals(次年 4 月至 6 月)
|
||||
|
||||
## 训练指南
|
||||
|
||||
|
|
@ -49,10 +49,10 @@ OJ 里查询用的关键词:`Multi-University Training Contest`。
|
|||
|
||||
### 训练营
|
||||
|
||||
- 寒假的时候头条/清华/CCPC (Wannafly Camp) 举办的 Camp
|
||||
- Wannafly Camp
|
||||
- 寒假的时候头条/清华/CCPC (Wannafly Camp) 举办的 Camp
|
||||
- Wannafly Camp
|
||||
|
||||
## 训练资源
|
||||
|
||||
- **OI Wiki:<https://oi-wiki.org>**
|
||||
- Codeforces Gym:<https://codeforces.com/gyms>
|
||||
- **OI Wiki:<https://oi-wiki.org>**
|
||||
- Codeforces Gym:<https://codeforces.com/gyms>
|
||||
|
|
|
|||
|
|
@ -1,14 +1,14 @@
|
|||
author: countercurrent-time, StudyingFather
|
||||
|
||||
上个世纪的 IOI 就已涉及交互题。虽然交互题近年来没有在省选以下的比赛中出现,不过 2019 年里 NOI 系列比赛中连续出现《P5208[WC2019]I 君的商店》、《P5473[NOI2019]I 君的探险》两道交互题,这可能代表着交互题重新回到 NOI 系列比赛中。
|
||||
上个世纪的 IOI 就已涉及交互题。虽然交互题近年来没有在省选以下的比赛中出现,不过 2019 年里 NOI 系列比赛中连续出现《P5208\[WC2019]I 君的商店》、《P5473\[NOI2019]I 君的探险》两道交互题,这可能代表着交互题重新回到 NOI 系列比赛中。
|
||||
|
||||
交互题没有很高的前置算法要求,一般也没有严格的时间限制,程序的优秀程度往往仅取决于交互次数限制。所以学习交互题时,建议按照难度循序渐进。要是有意锻炼算法思维而不只是单纯地学习算法,那么完成交互题是很不错的方法。虽然交互题对选手已掌握算法的要求通常较低,但仍建议掌握一定提高和省选算法后再尝试做交互题,因为此时自己的算法思维水平和知识面已经达到了一定水平。基础的交互题介绍可以参考 OI wiki 的 [题型介绍 - 交互题](./problems.md#交互题)。
|
||||
|
||||
交互题的特殊错误:
|
||||
|
||||
- 选手每一次输出后都需要刷新缓冲区,否则会引起 Idleness limit exceeded 错误。另外,如果题目含多组数据并且程序可以在未读入所有数据前就知道答案,也仍然要读入所有数据,否则同样会因为读入混乱引起 ILE(可以一次提出多次询问,一次接收所有询问的回答)。同时尽量不要使用快读。
|
||||
- 如果程序查询次数过多,则在 Codeforces 上会给出 Wrong Answer 的评测结果(不过评测系统会说明 Wrong Answer 的原因),而 UVA 会给出 Protocol Limit Exceeded (PLE) 的评测结果。
|
||||
- 如果程序交互格式错误,UVa 会给出 Protocol Violation (PV) 的评测结果。
|
||||
- 选手每一次输出后都需要刷新缓冲区,否则会引起 Idleness limit exceeded 错误。另外,如果题目含多组数据并且程序可以在未读入所有数据前就知道答案,也仍然要读入所有数据,否则同样会因为读入混乱引起 ILE(可以一次提出多次询问,一次接收所有询问的回答)。同时尽量不要使用快读。
|
||||
- 如果程序查询次数过多,则在 Codeforces 上会给出 Wrong Answer 的评测结果(不过评测系统会说明 Wrong Answer 的原因),而 UVA 会给出 Protocol Limit Exceeded (PLE) 的评测结果。
|
||||
- 如果程序交互格式错误,UVa 会给出 Protocol Violation (PV) 的评测结果。
|
||||
|
||||
由于交互题输入输出较为繁琐,所以建议分别封装输入和输出函数。
|
||||
|
||||
|
|
@ -16,11 +16,11 @@ author: countercurrent-time, StudyingFather
|
|||
|
||||
例题:
|
||||
|
||||
- [CF679A Bear and Prime 100](https://www.luogu.com.cn/problem/CF679A)
|
||||
- [CF843B Interactive LowerBound](https://www.luogu.com.cn/problem/CF843B)
|
||||
- [UOJ206\[APIO2016\]Gap](http://uoj.ac/problem/206)
|
||||
- [CF750F New Year and Finding Roots](https://www.luogu.com.cn/problem/CF750F)
|
||||
- [UVA12731 太空站之谜 Mysterious Space Station](https://www.luogu.com.cn/problem/UVA12731)
|
||||
- [CF679A Bear and Prime 100](https://www.luogu.com.cn/problem/CF679A)
|
||||
- [CF843B Interactive LowerBound](https://www.luogu.com.cn/problem/CF843B)
|
||||
- [UOJ206\[APIO2016\]Gap](http://uoj.ac/problem/206)
|
||||
- [CF750F New Year and Finding Roots](https://www.luogu.com.cn/problem/CF750F)
|
||||
- [UVA12731 太空站之谜 Mysterious Space Station](https://www.luogu.com.cn/problem/UVA12731)
|
||||
|
||||
## CF679A Bear and Prime 100
|
||||
|
||||
|
|
@ -104,7 +104,7 @@ author: countercurrent-time, StudyingFather
|
|||
}
|
||||
```
|
||||
|
||||
## UOJ206[APIO2016]Gap
|
||||
## UOJ206\[APIO2016]Gap
|
||||
|
||||
分两个子任务讨论:
|
||||
|
||||
|
|
@ -282,8 +282,8 @@ $h \le 4$ 时可以直接暴力枚举。然而 $h > 4$ 时需要很高效的遍
|
|||
|
||||
由于唯一的反馈是移动时是否撞墙,所以我们应该考虑在机器人不走丢的情况下,尽量接近墙边走路,这样有几个好处:
|
||||
|
||||
- 靠近墙边走路时,很容易知道自己会不会撞墙,获取到尽量多的信息。
|
||||
- 墙边都是不会出现传送门的格子,可以避免机器人走丢。
|
||||
- 靠近墙边走路时,很容易知道自己会不会撞墙,获取到尽量多的信息。
|
||||
- 墙边都是不会出现传送门的格子,可以避免机器人走丢。
|
||||
|
||||
所以,我们如果已知机器人可能在墙边的某个位置,要确定机器人是不是真的在这个位置,就可以通过 [“单手扶墙法”](https://en.wikipedia.org/wiki/Maze_solving_algorithm) 确定自己是不是真的在这个位置。根据拓扑学原理,在两边都是墙的迷宫中,如果从入口进入,并且总是用一只手扶着同一边墙,就可以保证找到出口。由于本题中的墙是闭合的,所以只需要沿着墙边的道路走,就可以保证可以回到原点而不会撞墙。另外,由于墙边的道路是地图上的最大闭合回路,所以实际代码中并不需要特意撞墙以保证机器人在墙边,可以使用标记在地图中标明墙边道路。而且一旦撞了墙,就需要赶快沿着原路返回,可以在避免机器人走丢的同时减少步数。
|
||||
|
||||
|
|
@ -566,10 +566,10 @@ $h \le 4$ 时可以直接暴力枚举。然而 $h > 4$ 时需要很高效的遍
|
|||
|
||||
## 习题
|
||||
|
||||
- [刘汝佳的交互题专场比赛 Rujia Liu's Present 7 质量非常高,推荐一做。](https://onlinejudge.org/contests/328-9976a2e2/)
|
||||
- [P5473\[NOI2019\]I 君的探险](https://www.luogu.com.cn/problem/P5473)
|
||||
- [P5208\[WC2019\]I 君的商店](https://www.luogu.com.cn/problem/P5208)
|
||||
- [刘汝佳的交互题专场比赛 Rujia Liu's Present 7 质量非常高,推荐一做。](https://onlinejudge.org/contests/328-9976a2e2/)
|
||||
- [P5473\[NOI2019\]I 君的探险](https://www.luogu.com.cn/problem/P5473)
|
||||
- [P5208\[WC2019\]I 君的商店](https://www.luogu.com.cn/problem/P5208)
|
||||
|
||||
## 参考资料与拓展阅读
|
||||
|
||||
- [用 Linux 管道实现 online judge 的交互题功能](https://www.cnblogs.com/tsreaper/p/pipe-interactive.html)
|
||||
- [用 Linux 管道实现 online judge 的交互题功能](https://www.cnblogs.com/tsreaper/p/pipe-interactive.html)
|
||||
|
|
|
|||
|
|
@ -2,7 +2,7 @@ author: Marcythm, yizr-cnyali, Chaigidel, Tiger3018, voidge, H-J-Granger, ouuan,
|
|||
|
||||
在默认情况下,`std::cin/std::cout` 是极为迟缓的读入/输出方式,而 `scanf/printf` 比 `std::cin/std::cout` 快得多。
|
||||
|
||||
???+note "注意"
|
||||
???+ note "注意"
|
||||
`cin`/`cout` 与 `scanf`/`printf` 的实际速度差会随编译器和操作系统的不同发生一定的改变。如果想要进行详细对比,请以实际测试结果为准。
|
||||
|
||||
下文将详细介绍读入输出的优化方法。
|
||||
|
|
@ -44,7 +44,7 @@ std::cin.tie(0);
|
|||
|
||||
`scanf` 和 `printf` 依然有优化的空间,这就是本章所介绍的内容——读入和输出优化。
|
||||
|
||||
- 注意,本页面中介绍的读入和输出优化均针对整型数据,若要支持其他类型的数据(如浮点数),可自行按照本页面介绍的优化原理来编写代码。
|
||||
- 注意,本页面中介绍的读入和输出优化均针对整型数据,若要支持其他类型的数据(如浮点数),可自行按照本页面介绍的优化原理来编写代码。
|
||||
|
||||
### 原理
|
||||
|
||||
|
|
@ -54,7 +54,7 @@ std::cin.tie(0);
|
|||
|
||||
整数的 '+' 通常是省略的,且不会对后面数字所代表的值产生影响,而 '-' 不可省略,因此要进行判定
|
||||
|
||||
10 进制整数中是不含空格或除 0~9 和正负号外的其他字符的,因此在读入不应存在于整数中的字符(通常为空格)时,就可以判定已经读入结束
|
||||
10 进制整数中是不含空格或除 0\~9 和正负号外的其他字符的,因此在读入不应存在于整数中的字符(通常为空格)时,就可以判定已经读入结束
|
||||
|
||||
C 和 C++ 语言分别在 ctype.h 和 cctype 头文件中,提供了函数 `isdigit`, 这个函数会检查传入的参数是否为十进制数字字符,是则返回 **true**,否则返回 **false**。对应的,在下面的代码中,可以使用 `isdigit(ch)` 代替 `ch >= '0' && ch <= '9'`,而可以使用 `!isdigit(ch)` 代替 `ch <'0' || ch> '9'`
|
||||
|
||||
|
|
@ -79,7 +79,7 @@ int read() {
|
|||
}
|
||||
```
|
||||
|
||||
- 举例
|
||||
- 举例
|
||||
|
||||
读入 num 可写为 `num=read();`
|
||||
|
||||
|
|
@ -119,7 +119,7 @@ inline void write(int x) {
|
|||
}
|
||||
```
|
||||
|
||||
- 举例
|
||||
- 举例
|
||||
|
||||
输出 num 可写为 `write(num);`
|
||||
|
||||
|
|
@ -204,12 +204,12 @@ inline void write(int x) {
|
|||
|
||||
### 刷新缓冲区
|
||||
|
||||
1. 程序结束
|
||||
2. 关闭文件
|
||||
3. `printf` 输出 `\r` 或者 `\n` 到终端的时候(注:如果是输出到文件,则不会刷新缓冲区)
|
||||
4. 手动 `fflush()`
|
||||
5. 缓冲区满自动刷新
|
||||
6. `cout` 输出 `endl`
|
||||
1. 程序结束
|
||||
2. 关闭文件
|
||||
3. `printf` 输出 `\r` 或者 `\n` 到终端的时候(注:如果是输出到文件,则不会刷新缓冲区)
|
||||
4. 手动 `fflush()`
|
||||
5. 缓冲区满自动刷新
|
||||
6. `cout` 输出 `endl`
|
||||
|
||||
## 使输入输出优化更为通用
|
||||
|
||||
|
|
|
|||
|
|
@ -6,16 +6,16 @@ author: Ir1d, Planet6174, abc1763613206, StudyingFather, cjsoft, Marcythm, luogu
|
|||
|
||||
OI 竞赛种类繁多,仅中国就包括:
|
||||
|
||||
- 全国青少年信息学奥林匹克联赛(NOIP)
|
||||
- 全国青少年信息学奥林匹克竞赛(NOI)
|
||||
- 全国青少年信息学奥林匹克竞赛冬令营(WC)
|
||||
- 国际信息学奥林匹克竞赛中国队选拔赛(CTSC)
|
||||
- 全国青少年信息学奥林匹克联赛(NOIP)
|
||||
- 全国青少年信息学奥林匹克竞赛(NOI)
|
||||
- 全国青少年信息学奥林匹克竞赛冬令营(WC)
|
||||
- 国际信息学奥林匹克竞赛中国队选拔赛(CTSC)
|
||||
|
||||
国际性的 OI 竞赛包括:
|
||||
|
||||
- 国际信息学奥林匹克(IOI)
|
||||
- 美国计算机奥林匹克竞赛(USACO)
|
||||
- 日本信息学奥林匹克(JOI)
|
||||
- 国际信息学奥林匹克(IOI)
|
||||
- 美国计算机奥林匹克竞赛(USACO)
|
||||
- 日本信息学奥林匹克(JOI)
|
||||
- 亚太地区信息学奥林匹克(APIO)
|
||||
|
||||
……
|
||||
|
|
@ -111,9 +111,9 @@ APIO 和 CTS 都以省为单位报名,一般按照 NOIP 的成绩排序来确
|
|||
|
||||
#### PKU
|
||||
|
||||
- 北京大学信息学冬季体验营(PKUWC):在冬令营前后举行。
|
||||
- 北京大学信息学体验营(PKUSC):一般在六月份在校内举行。由于在学校机房比赛,机房环境是 Windows,比赛系统是 OpenJudge。
|
||||
- 北京大学中学生暑期课堂(信息学):在暑假举行,面向高二年级理科学生。
|
||||
- 北京大学信息学冬季体验营(PKUWC):在冬令营前后举行。
|
||||
- 北京大学信息学体验营(PKUSC):一般在六月份在校内举行。由于在学校机房比赛,机房环境是 Windows,比赛系统是 OpenJudge。
|
||||
- 北京大学中学生暑期课堂(信息学):在暑假举行,面向高二年级理科学生。
|
||||
|
||||
## 其他国家和地区的 OI 竞赛
|
||||
|
||||
|
|
@ -123,14 +123,14 @@ APIO 和 CTS 都以省为单位报名,一般按照 NOIP 的成绩排序来确
|
|||
|
||||
USACO 或许是国内选手最熟悉的外国 OI 竞赛(可能也是中文题解最多的外国 OI 竞赛)。
|
||||
|
||||
每年冬季到初春,USACO 会每月举办一场网络赛。一场比赛持续 3~5 个小时。
|
||||
每年冬季到初春,USACO 会每月举办一场网络赛。一场比赛持续 3\~5 个小时。
|
||||
|
||||
根据官网的介绍,USACO 的比赛分成这 4 档难度(2015~2016 学年之前为 3 档):
|
||||
根据官网的介绍,USACO 的比赛分成这 4 档难度(2015\~2016 学年之前为 3 档):
|
||||
|
||||
- 铜牌组,适合编程初学者,尤其是只学了最最基础的算法(如:排序,二分查找)的学生;
|
||||
- 银牌组,适合开始学习基本的算法技巧(如:递归,搜索,贪心算法)和基础数据结构的学生;
|
||||
- 金牌组,学生会遇到更复杂的算法(如:最短路径,DP)和更高级的数据结构;
|
||||
- 铂金组,适合有着扎实的算法设计能力的选手,铂金组可以帮助他们以复杂且更开放的问题来挑战自我。
|
||||
- 铜牌组,适合编程初学者,尤其是只学了最最基础的算法(如:排序,二分查找)的学生;
|
||||
- 银牌组,适合开始学习基本的算法技巧(如:递归,搜索,贪心算法)和基础数据结构的学生;
|
||||
- 金牌组,学生会遇到更复杂的算法(如:最短路径,DP)和更高级的数据结构;
|
||||
- 铂金组,适合有着扎实的算法设计能力的选手,铂金组可以帮助他们以复杂且更开放的问题来挑战自我。
|
||||
|
||||
在国内,目前 USACO 题目最齐全的是洛谷。
|
||||
|
||||
|
|
@ -144,10 +144,10 @@ POI 是不少省选选手最常刷的外国 OI 比赛。
|
|||
|
||||
根据 <http://main.edu.pl/en/> 的描述,POI 的流程如下:
|
||||
|
||||
- 第一轮:五题,网络赛,公开赛;
|
||||
- 第二轮:包含一场练习赛,和两场正式比赛;
|
||||
- 第三轮:赛制同上。
|
||||
- ONTAK:POI 训练营(类似国内的集训队)。
|
||||
- 第一轮:五题,网络赛,公开赛;
|
||||
- 第二轮:包含一场练习赛,和两场正式比赛;
|
||||
- 第三轮:赛制同上。
|
||||
- ONTAK:POI 训练营(类似国内的集训队)。
|
||||
|
||||
另有 PA,大意为“算法大战”。
|
||||
|
||||
|
|
@ -173,10 +173,10 @@ JOI(日文:日本情報オリンピック,中文:日本信息学奥赛
|
|||
|
||||
JOI 的流程:
|
||||
|
||||
- 预赛(予選)
|
||||
- 决赛(本選/JOI Final)
|
||||
- 春训营(春季トレーニング合宿/JOI Spring Camp/JOISC)
|
||||
- 公开赛(通信教育/JOI Open Contest)
|
||||
- 预赛(予選)
|
||||
- 决赛(本選/JOI Final)
|
||||
- 春训营(春季トレーニング合宿/JOI Spring Camp/JOISC)
|
||||
- 公开赛(通信教育/JOI Open Contest)
|
||||
|
||||
预赛难度较低,自 2019/2020 赛季起,预赛分为多轮。JOI Final 的难度从提高 - 到 提高 + 左右。JOISC 和 JOI Open 的题目的难度从提高到 NOI - 不等。
|
||||
|
||||
|
|
@ -194,25 +194,25 @@ ROI(俄文:олимпиадная информатика,中文:俄罗
|
|||
|
||||
流程:
|
||||
|
||||
- 市级比赛(Municipal stage/Муниципальный этап)
|
||||
- 州级比赛(Regional Stage/Региональный этап)
|
||||
- 决赛(Final Stage/Заключительный этап)
|
||||
- 市级比赛(Municipal stage/Муниципальный этап)
|
||||
- 州级比赛(Regional Stage/Региональный этап)
|
||||
- 决赛(Final Stage/Заключительный этап)
|
||||
|
||||
目前 LibreOJ 有近几年的 ROI 决赛题的译文。
|
||||
|
||||
除此之外,俄罗斯较大型的、面向中学生的比赛还有:
|
||||
|
||||
- 信息学网络奥赛(俄文:Интернет-олимпиады по информатике)
|
||||
- 官网地址:<http://neerc.ifmo.ru/school/io/index.html>
|
||||
- 该比赛由 ROI 出题人举办。
|
||||
- 官网地址:<http://neerc.ifmo.ru/school/io/index.html>
|
||||
- 该比赛由 ROI 出题人举办。
|
||||
- 全国中学生团队信息学竞赛(俄文:Всероссийской командной олимпиады школьников)
|
||||
- 官网地址:<http://neerc.ifmo.ru/school/russia-team/index.html>
|
||||
- 该比赛的预选赛 Moscow Team Olympiad 可以在 Codeforces 上提交。
|
||||
- 官网地址:<http://neerc.ifmo.ru/school/russia-team/index.html>
|
||||
- 该比赛的预选赛 Moscow Team Olympiad 可以在 Codeforces 上提交。
|
||||
- Innopolis Open
|
||||
- 官网地址 <https://olymp.innopolis.ru/en/ooui/information/>
|
||||
- 官网地址 <https://olymp.innopolis.ru/en/ooui/information/>
|
||||
- 中学生编程公开赛(Открытая олимпиада школьников по программированию)
|
||||
- 官网地址:<https://olympiads.ru/zaoch/>
|
||||
- 官网称该比赛对标 ROI。
|
||||
- 官网地址:<https://olympiads.ru/zaoch/>
|
||||
- 官网称该比赛对标 ROI。
|
||||
|
||||
### 加拿大:CCC & CCO
|
||||
|
||||
|
|
@ -228,22 +228,22 @@ CCC Junior/Senior 贴近 NOIP 普及组/提高组难度。CCO 想要拿到金牌
|
|||
|
||||
台湾地区的选手如果想参加 IOI,需要经过这几轮比赛:
|
||||
|
||||
- 區域資訊學科能力競賽
|
||||
- 全國資訊學科能力競賽
|
||||
- 資訊研習營(TOI)
|
||||
- 區域資訊學科能力競賽
|
||||
- 全國資訊學科能力競賽
|
||||
- 資訊研習營(TOI)
|
||||
|
||||
### 其他国家
|
||||
|
||||
- 法国与澳大利亚:FARIO:<http://orac.amt.edu.au/cgi-bin/train/hub.pl>
|
||||
- 难度与 NOI 类似。
|
||||
- 难度与 NOI 类似。
|
||||
|
||||
- 英国:British Informatics Olympiad:<https://www.olympiad.org.uk/>
|
||||
- 难度太低。
|
||||
- 难度太低。
|
||||
|
||||
- 捷克:Matematická olympiáda–kategorie P:<http://mo.mff.cuni.cz/p/archiv.html>
|
||||
- 捷克:Matematická olympiáda–kategorie P:<http://mo.mff.cuni.cz/p/archiv.html>
|
||||
|
||||
- 罗马尼亚:Olimpiada Nationala de Informatica:<http://olimpiada.info/>
|
||||
- 题面、测试数据、题解请在含有 Subiecte 字样的标签页中寻找。
|
||||
- 题面、测试数据、题解请在含有 Subiecte 字样的标签页中寻找。
|
||||
|
||||
## 其它国际 OI 竞赛
|
||||
|
||||
|
|
|
|||
|
|
@ -18,14 +18,14 @@ author: StudyingFather, NachtgeistW, countercurrent-time, Ir1d, H-J-Granger, Chr
|
|||
|
||||
这一过程结束后,评测系统会根据程序的运行状态,给出不同的 **评测结果**[^note5]:
|
||||
|
||||
- Accepted(AC):选手程序被接受。
|
||||
- Compile Error(CE):选手程序无法正常编译。
|
||||
- Wrong Answer(WA):选手程序正常结束,但是选手程序的输出与测试点输出不符。
|
||||
- Presentation Error(PE):选手程序正常结束,但是格式不符合要求[^note6]。
|
||||
- Runtime Error(RE):选手程序非正常结束(选手程序结束时的返回值不为零)。
|
||||
- Time Limit Exceeded(TLE):选手程序运行的时间超过了给定的时间限制。
|
||||
- Memory Limit Exceeded(MLE):选手程序占用的最大空间超过了给定的空间限制。
|
||||
- Output Limit Exceeded(OLE):选手程序输出的内容的量超过了最大限制。
|
||||
- Accepted(AC):选手程序被接受。
|
||||
- Compile Error(CE):选手程序无法正常编译。
|
||||
- Wrong Answer(WA):选手程序正常结束,但是选手程序的输出与测试点输出不符。
|
||||
- Presentation Error(PE):选手程序正常结束,但是格式不符合要求[^note6]。
|
||||
- Runtime Error(RE):选手程序非正常结束(选手程序结束时的返回值不为零)。
|
||||
- Time Limit Exceeded(TLE):选手程序运行的时间超过了给定的时间限制。
|
||||
- Memory Limit Exceeded(MLE):选手程序占用的最大空间超过了给定的空间限制。
|
||||
- Output Limit Exceeded(OLE):选手程序输出的内容的量超过了最大限制。
|
||||
|
||||
在 ICPC 赛事中,你的程序需要在一道题目的所有测试点上都取得 AC 状态,才能视为通过相应的题目。在 OI 赛事中,在一个测试点中取得 AC 状态,即可拿到该测试点的分数[^note7]。
|
||||
|
||||
|
|
@ -39,8 +39,8 @@ author: StudyingFather, NachtgeistW, countercurrent-time, Ir1d, H-J-Granger, Chr
|
|||
|
||||
做这种题目一般有两种方法:
|
||||
|
||||
- 手玩。这种方法简单粗暴,但是遇到较大的数据就没辙了。
|
||||
- 编写一个程序来获得答案文件。
|
||||
- 手玩。这种方法简单粗暴,但是遇到较大的数据就没辙了。
|
||||
- 编写一个程序来获得答案文件。
|
||||
|
||||
## 交互题
|
||||
|
||||
|
|
@ -109,9 +109,9 @@ STDIO 交互的一个明显优势在于它可以支持任何编程语言,但
|
|||
|
||||
本地测试的方法由于题目设定的不同而多种多样,常用的形式如:
|
||||
|
||||
- 手工输入
|
||||
- 编写一个辅助程序,转换第一个程序的输出到第二个程序的输入
|
||||
- 用双向管道将两个程序的标准输入/输出连接起来
|
||||
- 手工输入
|
||||
- 编写一个辅助程序,转换第一个程序的输出到第二个程序的输入
|
||||
- 用双向管道将两个程序的标准输入/输出连接起来
|
||||
|
||||
由于评测平台对于通信题的支持有限,因而目前为止,通信题只常见于 IOI 系列赛和 UOJ 等少数在线平台举办的比赛。它仍是一个有待探索的领域。
|
||||
|
||||
|
|
@ -121,8 +121,8 @@ STDIO 交互的一个明显优势在于它可以支持任何编程语言,但
|
|||
|
||||
通常有以下几种形式:
|
||||
|
||||
- 给定一个程序,并告知要求补全的代码块将被嵌入在哪里。
|
||||
- 不给出程序,而将输入信息作为待提交函数的参数。
|
||||
- 给定一个程序,并告知要求补全的代码块将被嵌入在哪里。
|
||||
- 不给出程序,而将输入信息作为待提交函数的参数。
|
||||
|
||||
这种题在 [LeetCode](https://leetcode.com/) 和 [PTA - 拼题 A](https://pintia.cn/problem-sets) 上比较多见。
|
||||
|
||||
|
|
@ -136,7 +136,9 @@ STDIO 交互的一个明显优势在于它可以支持任何编程语言,但
|
|||
代码中必须至少包含十个可见字符。
|
||||
|
||||
题目很经典,但是在绝大多数 OJ 上都很难实现。
|
||||
|
||||
??? 参考代码
|
||||
|
||||
|
||||
```c++
|
||||
#include<cstdio>
|
||||
|
|
|
|||
|
|
@ -24,10 +24,10 @@ author: ouuan, Henry-ZHR, StudyingFather, ChungZH, xyf007
|
|||
|
||||
### idea 的来源
|
||||
|
||||
1. 受到已有题目的启发(但不能照搬或无意义地加强,如:序列题目搬到仙人掌上)。
|
||||
2. 受到学过的知识点的启发(但不能毫无联系地拼凑知识点)。
|
||||
3. 从生活/游戏中受到启发(但注意不要把游戏出成大模拟)。
|
||||
4. 不知道为什么,就是想到了一道题。
|
||||
1. 受到已有题目的启发(但不能照搬或无意义地加强,如:序列题目搬到仙人掌上)。
|
||||
2. 受到学过的知识点的启发(但不能毫无联系地拼凑知识点)。
|
||||
3. 从生活/游戏中受到启发(但注意不要把游戏出成大模拟)。
|
||||
4. 不知道为什么,就是想到了一道题。
|
||||
|
||||
### 什么样的 idea 是不好的
|
||||
|
||||
|
|
@ -35,30 +35,30 @@ author: ouuan, Henry-ZHR, StudyingFather, ChungZH, xyf007
|
|||
|
||||
原题大致可分为完全一致、几乎一致和做法一致三种。
|
||||
|
||||
- 完全一致:使用一题的 AC 代码可以 AC 另一题。
|
||||
- 几乎一致:由一题的 AC 代码改动至另一题的 AC 代码可以由一个不会该题的人完成。
|
||||
- 做法一致:核心思路、做法一致,但代码实现上、不那么关键的细节上有差异。
|
||||
- 完全一致:使用一题的 AC 代码可以 AC 另一题。
|
||||
- 几乎一致:由一题的 AC 代码改动至另一题的 AC 代码可以由一个不会该题的人完成。
|
||||
- 做法一致:核心思路、做法一致,但代码实现上、不那么关键的细节上有差异。
|
||||
|
||||
这三种原题自下而上为包含关系。
|
||||
|
||||
以下情况不应出现:
|
||||
|
||||
1. 在明知有“几乎一致”的原题的情况下出原题。
|
||||
2. 由于未使用搜索引擎查找导致自己不清楚有原题,从而出了“几乎一致”的原题。
|
||||
3. 在“做法一致”的原题广为人知(如:NOIP、NOI 原题)时出原题。
|
||||
4. 在带有选拔性的考试的非送分题中出现“做法一致”的原题。
|
||||
1. 在明知有“几乎一致”的原题的情况下出原题。
|
||||
2. 由于未使用搜索引擎查找导致自己不清楚有原题,从而出了“几乎一致”的原题。
|
||||
3. 在“做法一致”的原题广为人知(如:NOIP、NOI 原题)时出原题。
|
||||
4. 在带有选拔性的考试的非送分题中出现“做法一致”的原题。
|
||||
|
||||
以下情况最好不要出现:
|
||||
|
||||
1. 在明知有至少为“做法一致”的原题的情况下出原题。
|
||||
2. 由于未使用搜索引擎查找导致自己不清楚有原题,从而出了“做法一致”的原题。
|
||||
3. 在任何情况下出“几乎一致”的原题。
|
||||
1. 在明知有至少为“做法一致”的原题的情况下出原题。
|
||||
2. 由于未使用搜索引擎查找导致自己不清楚有原题,从而出了“做法一致”的原题。
|
||||
3. 在任何情况下出“几乎一致”的原题。
|
||||
|
||||
可以放宽要求的例外情况:
|
||||
|
||||
1. 校内模拟赛。
|
||||
2. 以专题训练为目的的模拟赛。
|
||||
3. 难度较低的比赛,或是定位为送分题的题目。
|
||||
1. 校内模拟赛。
|
||||
2. 以专题训练为目的的模拟赛。
|
||||
3. 难度较低的比赛,或是定位为送分题的题目。
|
||||
|
||||
#### 关于毒瘤题
|
||||
|
||||
|
|
@ -104,9 +104,9 @@ OI 中的数学题与其它数学题的区别,也是体现 OI 本质的一个
|
|||
|
||||
网上有很多 LaTeX 的教程,如:
|
||||
|
||||
- [LaTeX 入门](../tools/latex.md#图表)
|
||||
- [LaTeX 数学公式大全](https://www.luogu.com.cn/blog/IowaBattleship/latex-gong-shi-tai-quan)
|
||||
- [LaTeX 各种命令,符号](https://blog.csdn.net/garfielder007/article/details/51646604)
|
||||
- [LaTeX 入门](../tools/latex.md#图表)
|
||||
- [LaTeX 数学公式大全](https://www.luogu.com.cn/blog/IowaBattleship/latex-gong-shi-tai-quan)
|
||||
- [LaTeX 各种命令,符号](https://blog.csdn.net/garfielder007/article/details/51646604)
|
||||
|
||||
使用时请注意 [LaTeX 公式的格式要求](../intro/format.md)。
|
||||
|
||||
|
|
@ -184,15 +184,15 @@ OI 中的数学题与其它数学题的区别,也是体现 OI 本质的一个
|
|||
如果有多组合法的答案,可以任意输出其中一组。
|
||||
```
|
||||
|
||||
???+note "在选手代码内由随机数生成器生成输入数据"
|
||||
???+ note "在选手代码内由随机数生成器生成输入数据"
|
||||
有的题目会因为输入数据过大,为了防止读入用时过长,而要求选手在代码内通过给定的数据生成器生成数据,代替通过标准输入或文件输入来读入数据。
|
||||
|
||||
采用这种做法需要谨慎考虑,因为它有很多缺点:
|
||||
|
||||
- 可能引入了正解所不需要的数据随机性,或者使得构造数据变得困难
|
||||
- 可能增大了理解输入格式的难度
|
||||
- 如果随机数生成器封装的不好,可能理解数据生成器本身的使用方法就有难度
|
||||
- 如果选手没有使用出题者推荐的语言,可能需要自己写一个数据生成器
|
||||
- 可能引入了正解所不需要的数据随机性,或者使得构造数据变得困难
|
||||
- 可能增大了理解输入格式的难度
|
||||
- 如果随机数生成器封装的不好,可能理解数据生成器本身的使用方法就有难度
|
||||
- 如果选手没有使用出题者推荐的语言,可能需要自己写一个数据生成器
|
||||
|
||||
采用这种做法一般是为了防止读入数据用时过长,所以一个可能的替代方案是下发一个性能足够好的 [读入、输出优化](./io.md) 模板,以尽量保证所有人的读入用时一致,这样的话即使读入用时很久也不会影响不同选手用时的差异。另一个解决方案是将题目包装成函数调用式(而非 IO 式)交互题,即使算法过程中没有交互,交互题也可以起到统一读入用时的作用,IOI 就采用了所有题目都是交互题的方案。但是,这两种方案都对选手使用的语言有限制,需要出题者手动支持每种允许选手使用的语言。
|
||||
|
||||
|
|
@ -206,15 +206,15 @@ OI 中的数学题与其它数学题的区别,也是体现 OI 本质的一个
|
|||
|
||||
数据范围的常见遗漏:
|
||||
|
||||
1. “整数”中的“整”。
|
||||
2. 题面中只说了是“整数”没说是“正整数”,并且数据范围中只有上限没有下限。
|
||||
3. 字符串没说字符集。
|
||||
4. 实数没说小数点后位数。
|
||||
5. 某些变量没有给范围。
|
||||
1. “整数”中的“整”。
|
||||
2. 题面中只说了是“整数”没说是“正整数”,并且数据范围中只有上限没有下限。
|
||||
3. 字符串没说字符集。
|
||||
4. 实数没说小数点后位数。
|
||||
5. 某些变量没有给范围。
|
||||
|
||||
你需要保证标程可以通过满足题面所述数据范围的 **任何一组数据**。
|
||||
|
||||
???+note "关于“保证数据随机生成”"
|
||||
???+ note "关于“保证数据随机生成”"
|
||||
有的题目中会“保证数据随机生成”,很多时候这样的限制并不是最优的解决方案,因为“随机生成”对数据的限制并不明确,会给判断具体数据范围、提供 hack 数据带来困难。
|
||||
|
||||
一般来说,“保证数据随机生成”可以换成解法所需要的数据性质。例如,随机生成一棵树往往可以换成限制树的高度。
|
||||
|
|
@ -251,9 +251,9 @@ OI 中的数学题与其它数学题的区别,也是体现 OI 本质的一个
|
|||
|
||||
一般地,时限应满足以下要求:
|
||||
|
||||
1. 至少为 std 在最坏情况下用时的两倍。
|
||||
2. 如果比赛允许使用 Java,应使 Java 能够通过。
|
||||
3. 不应使错误做法通过(实在卡不掉、想放某种错解过除外)。
|
||||
1. 至少为 std 在最坏情况下用时的两倍。
|
||||
2. 如果比赛允许使用 Java,应使 Java 能够通过。
|
||||
3. 不应使错误做法通过(实在卡不掉、想放某种错解过除外)。
|
||||
|
||||
为了更好地在放大常数做法过的同时卡掉错解,一般可以采用同时增大数据范围和时限的方法。但要注意,有时正解(由于缓存等玄学问题)会在数据范围增大时有极大的常数增加,此时增大数据范围不一定能够增大正解与错解之间用时的差距。
|
||||
|
||||
|
|
@ -335,13 +335,13 @@ OI 中的数学题与其它数学题的区别,也是体现 OI 本质的一个
|
|||
|
||||
常用构造:
|
||||
|
||||
- 链
|
||||
- 菊花
|
||||
- 完全二叉树
|
||||
- 将完全二叉树的每个节点替换为一条长为 $\sqrt n$ 的链
|
||||
- 菊花上挂一条链
|
||||
- 链上挂一些单点
|
||||
- 一棵高度为 $d$ 且 $d>1$ 的树的根节点有两个儿子,左子树是一条长为 $d-1$ 的链,右子树是一棵高度为 $d-1$ 的这样的树。
|
||||
- 链
|
||||
- 菊花
|
||||
- 完全二叉树
|
||||
- 将完全二叉树的每个节点替换为一条长为 $\sqrt n$ 的链
|
||||
- 菊花上挂一条链
|
||||
- 链上挂一些单点
|
||||
- 一棵高度为 $d$ 且 $d>1$ 的树的根节点有两个儿子,左子树是一条长为 $d-1$ 的链,右子树是一棵高度为 $d-1$ 的这样的树。
|
||||
|
||||
如果不是在考场上,还可以使用 [Tree-Generator](https://github.com/ouuan/Tree-Generator) 来生成各种各样的树。
|
||||
|
||||
|
|
@ -421,11 +421,11 @@ gen 100000 100000 > 5.in
|
|||
|
||||
这里引用 CodeChef 对题目输入数据的格式要求,可作为一般情况下的参考:
|
||||
|
||||
> 1. 不使用 Windows 格式的换行符,即 `\r\n`。
|
||||
> 2. 最后一行的末尾有换行符,即整个文件的最后一个字符需要是 `\n`。
|
||||
> 3. 没有空行。
|
||||
> 4. 任何一行的开头和末尾都没有空白字符。
|
||||
> 5. 连续的空格不超过 1 个。
|
||||
> 1. 不使用 Windows 格式的换行符,即 `\r\n`。
|
||||
> 2. 最后一行的末尾有换行符,即整个文件的最后一个字符需要是 `\n`。
|
||||
> 3. 没有空行。
|
||||
> 4. 任何一行的开头和末尾都没有空白字符。
|
||||
> 5. 连续的空格不超过 1 个。
|
||||
|
||||
## Special Judge
|
||||
|
||||
|
|
@ -437,8 +437,8 @@ checker 一般使用 testlib 编写。由于 checker 要应对各种各样的不
|
|||
|
||||
编写 checker 需要注意以下两点:
|
||||
|
||||
1. 你需要应对各种不合法的输出,因此,请检查读入的每个变量是否在合法范围中(`readInt(minvalue, maxvalue)`)。例如:读入一个在 check 过程中会作为数组下标的变量时必须检查其范围,否则可能引发数组越界,有时这会导致 RE,有时则可能判为 AC。
|
||||
2. 原则上 checker 中不应检查空白字符(即,不应使用 `readSpace()`、`readEoln()`、`readEof()`,值得一提的是,testlib 会自动检查是否有多余的输出)。
|
||||
1. 你需要应对各种不合法的输出,因此,请检查读入的每个变量是否在合法范围中(`readInt(minvalue, maxvalue)`)。例如:读入一个在 check 过程中会作为数组下标的变量时必须检查其范围,否则可能引发数组越界,有时这会导致 RE,有时则可能判为 AC。
|
||||
2. 原则上 checker 中不应检查空白字符(即,不应使用 `readSpace()`、`readEoln()`、`readEof()`,值得一提的是,testlib 会自动检查是否有多余的输出)。
|
||||
|
||||
## 题解
|
||||
|
||||
|
|
@ -484,10 +484,10 @@ checker 一般使用 testlib 编写。由于 checker 要应对各种各样的不
|
|||
|
||||
在类 CF/ATC 这种线上赛的比赛中,需要尽量保证难度的递增(虽然由于对难度的误估很多时候都并不能真正做到),并且尽量避免出现大的 difficulty gap。可以通过把一题分为难易两题(两个 subtask)来减少 difficulty gap,但是分 subtask 需要谨慎考虑,也有很多人不喜欢 CF 赛制中的 subtask([Are subtasks evil?](https://codeforces.com/blog/entry/71700)),原因包括但不限于:
|
||||
|
||||
- 由于赛制原因,可能先做 easy version 再做 hard version 罚时更少而总分更高
|
||||
- subtask 的赋分往往与题目难度不成正比
|
||||
- 很多时候 easy version 的题目并不是一道合格的题目(不有趣)
|
||||
- 很多时候 easy version 的解法对于思考 hard version 的正解没有帮助
|
||||
- 由于赛制原因,可能先做 easy version 再做 hard version 罚时更少而总分更高
|
||||
- subtask 的赋分往往与题目难度不成正比
|
||||
- 很多时候 easy version 的题目并不是一道合格的题目(不有趣)
|
||||
- 很多时候 easy version 的解法对于思考 hard version 的正解没有帮助
|
||||
|
||||
### 题目知识点的分配
|
||||
|
||||
|
|
@ -511,10 +511,10 @@ Codeforces 是全球最著名的算法竞赛网站之一,题目质量较高,
|
|||
|
||||
#### 出题资格
|
||||
|
||||
- 蓝名且参加过至少 25 场 rated 比赛;
|
||||
- 紫名且参加过至少 15 场 rated 比赛;
|
||||
- 橙名且参加过至少 5 场 rated 比赛;
|
||||
- 红名或黑红名。
|
||||
- 蓝名且参加过至少 25 场 rated 比赛;
|
||||
- 紫名且参加过至少 15 场 rated 比赛;
|
||||
- 橙名且参加过至少 5 场 rated 比赛;
|
||||
- 红名或黑红名。
|
||||
|
||||
#### 提交比赛申请
|
||||
|
||||
|
|
@ -532,8 +532,8 @@ Codeforces 是全球最著名的算法竞赛网站之一,题目质量较高,
|
|||
|
||||
与管理联系有两个作用:
|
||||
|
||||
1. 加快审核速度。
|
||||
2. 进入准备阶段后管理会提供建议和帮助。
|
||||
1. 加快审核速度。
|
||||
2. 进入准备阶段后管理会提供建议和帮助。
|
||||
|
||||
正规的联系方式是在 proposal system 中以 proposal 的形式提交申请,管理开始审核之后以 comment 的形式在 proposal 的下方进行讨论。
|
||||
|
||||
|
|
@ -557,7 +557,7 @@ Codeforces 是全球最著名的算法竞赛网站之一,题目质量较高,
|
|||
|
||||
### AtCoder
|
||||
|
||||
日本的算法竞赛平台,出题联系方式:[contest@atcoder.jp](mailto:contest@atcoder.jp)。
|
||||
日本的算法竞赛平台,出题联系方式:<contest@atcoder.jp>。
|
||||
|
||||
### UOJ & LOJ
|
||||
|
||||
|
|
@ -575,13 +575,13 @@ Codeforces 是全球最著名的算法竞赛网站之一,题目质量较高,
|
|||
|
||||
## 参考资料
|
||||
|
||||
1. [vfk《UOJ 精神之源流》][1]
|
||||
1. [vfk《UOJ 精神之源流》][1]
|
||||
|
||||
2. [王天懿《论偏题的危害》][2]
|
||||
2. [王天懿《论偏题的危害》][2]
|
||||
|
||||
3. [CF 出题人须知][3]([国内可访问的图片版](https://github.com/OI-wiki/libs/blob/master/topic/rules.jpg))
|
||||
3. [CF 出题人须知][3]([国内可访问的图片版](https://github.com/OI-wiki/libs/blob/master/topic/rules.jpg))
|
||||
|
||||
4. [CF 出题人的自我修养][4]
|
||||
4. [CF 出题人的自我修养][4]
|
||||
|
||||
本文由作者本人自 [ouuan 的出题规范](https://ouuan.github.io/post/ouuan-的出题规范/) 搬运而来并有所修改、补充。
|
||||
|
||||
|
|
|
|||
|
|
@ -12,64 +12,64 @@ author: Suyun514, ChungZH, Enter-tainer, StudyingFather, Konano, JulieSigtuna, G
|
|||
<!-- - [BZOJ](https://www.lydsy.com/JudgeOnline/) :因原属衡阳八中而得此简称,汇聚多种习题和真题,题目质量相对较高,但可能需要联系邮箱。BZOJ 上有大量只有付费用户才能提交的题目。2018 年 BZOJ 测试数据泄露,催生了 DarkBZOJ。 -->
|
||||
- [Comet OJ](https://www.cometoj.com):始于 2018 年,旨在为广大算法爱好者提供一个竞技、练习、交流的平台,经常举办原创性的高质量比赛,有丰富的题库。
|
||||
<!-- - [CodeVS](http://www.codevs.cn/) 面向 OI 选手的过气 OJ。 -->
|
||||
- [FZUOJ](http://acm.fzu.edu.cn/) 始于 2008 年,福州大学在线评测系统。
|
||||
- [HDU Online Judge](http://acm.hdu.edu.cn/) 始于 2005 年,杭州电子科技大学在线评测系统,有多校训练的题目。
|
||||
- [hihoCoder](https://hihocoder.com/) 始于 2012 年,面向企业招聘,有些题目来自于每周一题,涉及知识点的学习。(登录后方可查看题面)
|
||||
- [HydroOJ](https://hydro.ac/):始于 2021 年,为开源项目 [Hydro](https://hydro.js.org/) 的官方站。用户可以创建自己的 [域](https://hydro.ac/discuss/6087cc44e098b0cd7dde1a0c),域中可以使用题库、比赛、讨论等主站可以使用的功能。
|
||||
- [计蒜客](https://www.jisuanke.com/) 北京矩道优达网络科技有限公司旗下的核心产品,提供按知识点和难度筛选的信息学题库和 ICPC 题库。
|
||||
- [FZUOJ](http://acm.fzu.edu.cn/) 始于 2008 年,福州大学在线评测系统。
|
||||
- [HDU Online Judge](http://acm.hdu.edu.cn/) 始于 2005 年,杭州电子科技大学在线评测系统,有多校训练的题目。
|
||||
- [hihoCoder](https://hihocoder.com/) 始于 2012 年,面向企业招聘,有些题目来自于每周一题,涉及知识点的学习。(登录后方可查看题面)
|
||||
- [HydroOJ](https://hydro.ac/):始于 2021 年,为开源项目 [Hydro](https://hydro.js.org/) 的官方站。用户可以创建自己的 [域](https://hydro.ac/discuss/6087cc44e098b0cd7dde1a0c),域中可以使用题库、比赛、讨论等主站可以使用的功能。
|
||||
- [计蒜客](https://www.jisuanke.com/) 北京矩道优达网络科技有限公司旗下的核心产品,提供按知识点和难度筛选的信息学题库和 ICPC 题库。
|
||||
- [Judge Duck Online](https://duck.ac/) 基于 [松松松](https://github.com/wangyisong1996) 开发的开源项目 [JudgeDuck](https://github.com/JudgeDuck),可以将评测程序的运行时间精确到微秒。(题目较少)
|
||||
<!-- - [JoyOI](http://www.joyoi.cn/) 原 Tyvj, [项目开源](https://github.com/joyoi) 。-->
|
||||
- [LibreOJ](https://loj.ac/):始于 2017 年。基于开源项目 [Lyrio](https://github.com/lyrio-dev/lyrio),Libre 取自由之意。题目所有测试数据以及提交的代码均对所有用户开放。目前由 [Menci](https://github.com/Menci) 维护。
|
||||
- [Lutece](https://acm.uestc.edu.cn/home):电子科技大学在线评测系统,始于 2018 年,[项目开源](https://github.com/lutece-awesome)。
|
||||
- [洛谷](https://www.luogu.com.cn/):始于 2013 年,社区群体庞大,各类 OI 的真题和习题较全。提供有偿教育服务。
|
||||
- [牛客网](https://www.nowcoder.com/):始于 2014 年,提供技术类求职备考、社群交流、企业招聘等服务。
|
||||
- [NOJ](http://acm.njupt.edu.cn/):南京邮电大学在线评测系统,始于 2008 年,[项目开源](https://github.com/ZsgsDesign/NOJ)。自身拥有题目两千余道,同时支持对多个国内外 OJ 的提交,可以直接在 NOJ 提交别的 OJ 的题。
|
||||
- [NTUOJ](http://acm.csie.ntu.edu.tw):台湾大学在线评测系统,始于 2007 年,基于开源项目 [Judge Girl](http://judgegirl.github.io/)。
|
||||
- [OpenJudge](http://openjudge.cn/):始于 2005 年,由 POJ 团队开发的小组评测平台。
|
||||
- [POJ](http://poj.org/):北京大学在线评测系统,始于 2003 年,国内历史最悠久的 OJ 之一。内有很多英文题,既有基础题,也有值得一试的好题。
|
||||
- [PTA(拼题 A)](https://pintia.cn/):始于 2016 年,浙江大学衍生的杭州百腾教育科技有限公司产品。
|
||||
- [清澄](http://www.tsinsen.com/):始于 2005 年,由 [胡伟栋](http://www.hhwdd.com/) 开发。自 2019 年 9 月 1 日起不再对外提供服务。
|
||||
- [Universal Online Judge](https://uoj.ac/):始于 2014 年,Universal 取通用之意,[项目开源](https://github.com/UniversalOJ/UOJ-System);[VFK](https://github.com/vfleaking) 的 OJ:多原创比赛题和 CCF/THU 题,难度较高。
|
||||
- [Vijos](https://vijos.org/):始于 2005 年。[服务端](https://github.com/vijos/vj4) 和 [评测机](https://github.com/vijos/jd4) 等项目开源。
|
||||
- [WZOI](https://wzoi.cc):始于 2017 年,由浙江省温州中学维护的 [开源](https://github.com/massimodong/wzoj) 评测系统。
|
||||
- [ZOJ](https://zoj.pintia.cn/home):浙江大学在线评测系统,始于 2001 年。
|
||||
- [LibreOJ](https://loj.ac/):始于 2017 年。基于开源项目 [Lyrio](https://github.com/lyrio-dev/lyrio),Libre 取自由之意。题目所有测试数据以及提交的代码均对所有用户开放。目前由 [Menci](https://github.com/Menci) 维护。
|
||||
- [Lutece](https://acm.uestc.edu.cn/home):电子科技大学在线评测系统,始于 2018 年,[项目开源](https://github.com/lutece-awesome)。
|
||||
- [洛谷](https://www.luogu.com.cn/):始于 2013 年,社区群体庞大,各类 OI 的真题和习题较全。提供有偿教育服务。
|
||||
- [牛客网](https://www.nowcoder.com/):始于 2014 年,提供技术类求职备考、社群交流、企业招聘等服务。
|
||||
- [NOJ](http://acm.njupt.edu.cn/):南京邮电大学在线评测系统,始于 2008 年,[项目开源](https://github.com/ZsgsDesign/NOJ)。自身拥有题目两千余道,同时支持对多个国内外 OJ 的提交,可以直接在 NOJ 提交别的 OJ 的题。
|
||||
- [NTUOJ](http://acm.csie.ntu.edu.tw):台湾大学在线评测系统,始于 2007 年,基于开源项目 [Judge Girl](http://judgegirl.github.io/)。
|
||||
- [OpenJudge](http://openjudge.cn/):始于 2005 年,由 POJ 团队开发的小组评测平台。
|
||||
- [POJ](http://poj.org/):北京大学在线评测系统,始于 2003 年,国内历史最悠久的 OJ 之一。内有很多英文题,既有基础题,也有值得一试的好题。
|
||||
- [PTA(拼题 A)](https://pintia.cn/):始于 2016 年,浙江大学衍生的杭州百腾教育科技有限公司产品。
|
||||
- [清澄](http://www.tsinsen.com/):始于 2005 年,由 [胡伟栋](http://www.hhwdd.com/) 开发。自 2019 年 9 月 1 日起不再对外提供服务。
|
||||
- [Universal Online Judge](https://uoj.ac/):始于 2014 年,Universal 取通用之意,[项目开源](https://github.com/UniversalOJ/UOJ-System);[VFK](https://github.com/vfleaking) 的 OJ:多原创比赛题和 CCF/THU 题,难度较高。
|
||||
- [Vijos](https://vijos.org/):始于 2005 年。[服务端](https://github.com/vijos/vj4) 和 [评测机](https://github.com/vijos/jd4) 等项目开源。
|
||||
- [WZOI](https://wzoi.cc):始于 2017 年,由浙江省温州中学维护的 [开源](https://github.com/massimodong/wzoj) 评测系统。
|
||||
- [ZOJ](https://zoj.pintia.cn/home):浙江大学在线评测系统,始于 2001 年。
|
||||
|
||||
### 国外
|
||||
|
||||
- [AizuOJ](https://onlinejudge.u-aizu.ac.jp):日本会津大学在线评测系统,始于 2004 年。包含日本若干高中和大学编程比赛的题目,自带编程/数据结构/算法的入门课程。
|
||||
- [AtCoder](https://atcoder.jp/):日本 OJ,日文版里会有日本高校的比赛,英文内不会显示。题目有趣,质量较高。
|
||||
- [CodeChef](https://codechef.com/):印度 OJ,周期举办比赛。系统基于 SPOJ 的 Sphere Engine。
|
||||
- [Codeforces](https://codeforces.com/):俄罗斯 OJ,始于 2010 年,创始人是 [Mike Mirzayanov](https://www.linkedin.com/in/mike-mirzayanov-31772a93/)。有多种系列的比赛,并支持个人出题、申请组织比赛。题目质量较高。
|
||||
- [CSES](https://cses.fi/problemset/)(Code Submission Evaluation System),按专题划分的题库,[旨在](https://cses.fi/problemset/text/1810) 成为综合的高质量题库,目前只有 200 题,主要由 [Competitive Programmer’s Handbook](https://cses.fi/book/book.pdf) 作者 Antti Laaksonen 开发,始于 2013。
|
||||
- [CS Academy](https://csacademy.com/)
|
||||
- [DMOJ](https://dmoj.ca/) 加拿大开源的 OJ,语言支持广;题库是各大比赛的存档,也有定期自行举办的比赛。
|
||||
- [HackerRank](https://www.hackerrank.com/) 有很多比赛
|
||||
- [ICPC Live Archive](https://icpcarchive.ecs.baylor.edu/) 存档了 1990 年至今的 ICPC 区域赛和总决赛题目;但部分比赛的评测数据仅为样例数据,且对 Special Judge 的支持不完善。
|
||||
- [ICPC Problem Archive](https://judge.icpc.global) 基于 Kattis 系统;存档了 2012 年至今的 ICPC 全球总决赛题目,并且会在总决赛开赛时同步发放题目(但不会有同步赛)。
|
||||
- [Kattis](https://open.kattis.com/) 题库主要包含类似 ICPC 比赛的题目;根据用户解题情况评定用户等级,推荐适合该用户水平的 trivial/easy/medium/hard 四类难度的题目,其中题目难度采用类 [ELO 等级分](https://zh.wikipedia.org/wiki/%E7%AD%89%E7%BA%A7%E5%88%86) 系统来评估。
|
||||
- [LeetCode](https://leetcode.com/) 码农面试刷题网站,有中文分站:[LeetCode China](https://leetcode.cn)。
|
||||
- [Light OJ](http://lightoj.com) 一个快挂了的 OJ,`www` 域名无法访问,请使用 [根域名](http://lightoj.com) 访问
|
||||
- [opentrains](http://opentrains.snarknews.info/) 俄罗斯 [Open Cup](http://opencup.ru/) 比赛的训练平台,基于 [ejudge](https://ejudge.ru/) 开源系统搭建,支持虚拟比赛;题库包含历年 Open Cup 赛题以及 Petrozavodsk 训练营的题目。
|
||||
- [SPOJ](http://www.spoj.com) 始于 2003 年,其后台系统 [Sphere Engine](https://sphere-engine.com/) 于 2008 年商业化;支持题目点赞和标签功能。
|
||||
- [TopCoder](https://www.topcoder.com/) 始于 2001 年,其 [竞技编程社区](https://www.topcoder.com/community/competitive-programming/) 有很多比赛;目前主营业务是技术众包。
|
||||
- [TimusOJ](http://acm.timus.ru/) 始于 2000 年,由 Ural Federal University 开发,拥有俄罗斯最大的在线评测题库,题目主要来自乌拉尔联邦大学校赛、乌拉尔锦标赛、ICPC 乌拉尔区域赛、以及 Petrozavodsk 训练营。
|
||||
- Online Judge(前 [UVaOJ](https://uva.onlinejudge.org/))始于 1995 年,国际成名最早的 OJ,创始人是西班牙 University of Valladolid (UVa) 的 Miguel Ángel Revilla 教授;由于 [Revilla 教授于 2018 年不幸离世](https://www.elnortedecastilla.es/valladolid/muere-profesor-miguel-20180402225739-nt.html),且 Valladolid 大学终止维护,UVaOJ 自 2019 年 7 月起更名为 Online Judge。现在该平台的维护者 [正在 GitHub 上构建新的评测平台](https://github.com/TheOnlineJudge/ojudge)。
|
||||
- [Yandex](https://contest.yandex.ru/) 存档了近几年的全俄罗斯信息学奥赛。
|
||||
- [AizuOJ](https://onlinejudge.u-aizu.ac.jp):日本会津大学在线评测系统,始于 2004 年。包含日本若干高中和大学编程比赛的题目,自带编程/数据结构/算法的入门课程。
|
||||
- [AtCoder](https://atcoder.jp/):日本 OJ,日文版里会有日本高校的比赛,英文内不会显示。题目有趣,质量较高。
|
||||
- [CodeChef](https://codechef.com/):印度 OJ,周期举办比赛。系统基于 SPOJ 的 Sphere Engine。
|
||||
- [Codeforces](https://codeforces.com/):俄罗斯 OJ,始于 2010 年,创始人是 [Mike Mirzayanov](https://www.linkedin.com/in/mike-mirzayanov-31772a93/)。有多种系列的比赛,并支持个人出题、申请组织比赛。题目质量较高。
|
||||
- [CSES](https://cses.fi/problemset/)(Code Submission Evaluation System),按专题划分的题库,[旨在](https://cses.fi/problemset/text/1810) 成为综合的高质量题库,目前只有 200 题,主要由 [Competitive Programmer’s Handbook](https://cses.fi/book/book.pdf) 作者 Antti Laaksonen 开发,始于 2013。
|
||||
- [CS Academy](https://csacademy.com/)
|
||||
- [DMOJ](https://dmoj.ca/) 加拿大开源的 OJ,语言支持广;题库是各大比赛的存档,也有定期自行举办的比赛。
|
||||
- [HackerRank](https://www.hackerrank.com/) 有很多比赛
|
||||
- [ICPC Live Archive](https://icpcarchive.ecs.baylor.edu/) 存档了 1990 年至今的 ICPC 区域赛和总决赛题目;但部分比赛的评测数据仅为样例数据,且对 Special Judge 的支持不完善。
|
||||
- [ICPC Problem Archive](https://judge.icpc.global) 基于 Kattis 系统;存档了 2012 年至今的 ICPC 全球总决赛题目,并且会在总决赛开赛时同步发放题目(但不会有同步赛)。
|
||||
- [Kattis](https://open.kattis.com/) 题库主要包含类似 ICPC 比赛的题目;根据用户解题情况评定用户等级,推荐适合该用户水平的 trivial/easy/medium/hard 四类难度的题目,其中题目难度采用类 [ELO 等级分](https://zh.wikipedia.org/wiki/%E7%AD%89%E7%BA%A7%E5%88%86) 系统来评估。
|
||||
- [LeetCode](https://leetcode.com/) 码农面试刷题网站,有中文分站:[LeetCode China](https://leetcode.cn)。
|
||||
- [Light OJ](http://lightoj.com) 一个快挂了的 OJ,`www` 域名无法访问,请使用 [根域名](http://lightoj.com) 访问
|
||||
- [opentrains](http://opentrains.snarknews.info/) 俄罗斯 [Open Cup](http://opencup.ru/) 比赛的训练平台,基于 [ejudge](https://ejudge.ru/) 开源系统搭建,支持虚拟比赛;题库包含历年 Open Cup 赛题以及 Petrozavodsk 训练营的题目。
|
||||
- [SPOJ](http://www.spoj.com) 始于 2003 年,其后台系统 [Sphere Engine](https://sphere-engine.com/) 于 2008 年商业化;支持题目点赞和标签功能。
|
||||
- [TopCoder](https://www.topcoder.com/) 始于 2001 年,其 [竞技编程社区](https://www.topcoder.com/community/competitive-programming/) 有很多比赛;目前主营业务是技术众包。
|
||||
- [TimusOJ](http://acm.timus.ru/) 始于 2000 年,由 Ural Federal University 开发,拥有俄罗斯最大的在线评测题库,题目主要来自乌拉尔联邦大学校赛、乌拉尔锦标赛、ICPC 乌拉尔区域赛、以及 Petrozavodsk 训练营。
|
||||
- Online Judge(前 [UVaOJ](https://uva.onlinejudge.org/))始于 1995 年,国际成名最早的 OJ,创始人是西班牙 University of Valladolid (UVa) 的 Miguel Ángel Revilla 教授;由于 [Revilla 教授于 2018 年不幸离世](https://www.elnortedecastilla.es/valladolid/muere-profesor-miguel-20180402225739-nt.html),且 Valladolid 大学终止维护,UVaOJ 自 2019 年 7 月起更名为 Online Judge。现在该平台的维护者 [正在 GitHub 上构建新的评测平台](https://github.com/TheOnlineJudge/ojudge)。
|
||||
- [Yandex](https://contest.yandex.ru/) 存档了近几年的全俄罗斯信息学奥赛。
|
||||
|
||||
## 教程资料
|
||||
|
||||
- [**OI Wiki**](https://oi-wiki.org)
|
||||
- [Codeforces 上网友整理的一份教程合集](http://codeforces.com/blog/entry/57282)
|
||||
- [英文版 E-Maxx 算法教程](https://cp-algorithms.com/)
|
||||
- [演算法笔记](http://web.ntnu.edu.tw/~algo/):台湾师范大学总结的教程
|
||||
- [如何为 ACM-ICPC 做准备?- geeksforgeeks](https://www.geeksforgeeks.org/how-to-prepare-for-acm-icpc/)
|
||||
- [Topcoder 整理的教程](https://www.topcoder.com/community/competitive-programming/tutorials/)
|
||||
- [校招面试指南](https://github.com/jwasham/coding-interview-university)
|
||||
- [由 hzwer 收集整理自互联网的课件](https://github.com/hzwer/sharePPT)
|
||||
- [Trinkle23897 的课件](https://github.com/Trinkle23897/oi_slides)
|
||||
- [huzecong 的课件](https://github.com/huzecong/oi-slides)
|
||||
- [Open Data Structure](https://opendatastructures.org/):内含众多数据结构讲稿
|
||||
- [IOI Syllabus (2020)](https://www.cs.utexas.edu/users/utpc/courses/IOI.pdf)
|
||||
- [**OI Wiki**](https://oi-wiki.org)
|
||||
- [Codeforces 上网友整理的一份教程合集](http://codeforces.com/blog/entry/57282)
|
||||
- [英文版 E-Maxx 算法教程](https://cp-algorithms.com/)
|
||||
- [演算法笔记](http://web.ntnu.edu.tw/~algo/):台湾师范大学总结的教程
|
||||
- [如何为 ACM-ICPC 做准备?- geeksforgeeks](https://www.geeksforgeeks.org/how-to-prepare-for-acm-icpc/)
|
||||
- [Topcoder 整理的教程](https://www.topcoder.com/community/competitive-programming/tutorials/)
|
||||
- [校招面试指南](https://github.com/jwasham/coding-interview-university)
|
||||
- [由 hzwer 收集整理自互联网的课件](https://github.com/hzwer/sharePPT)
|
||||
- [Trinkle23897 的课件](https://github.com/Trinkle23897/oi_slides)
|
||||
- [huzecong 的课件](https://github.com/huzecong/oi-slides)
|
||||
- [Open Data Structure](https://opendatastructures.org/):内含众多数据结构讲稿
|
||||
- [IOI Syllabus (2020)](https://www.cs.utexas.edu/users/utpc/courses/IOI.pdf)
|
||||
|
||||
## 书籍
|
||||
|
||||
|
|
@ -77,129 +77,129 @@ author: Suyun514, ChungZH, Enter-tainer, StudyingFather, Konano, JulieSigtuna, G
|
|||
|
||||
- 刘汝佳系列
|
||||
- 《算法竞赛入门经典》(紫)
|
||||
- [第一版 配套资源仓库(镜像)](https://github.com/sukhoeing/aoapc-book/)
|
||||
- [第二版 配套资源仓库](https://github.com/aoapc-book/aoapc-bac2nd)
|
||||
- [第二版 习题选解](https://github.com/sukhoeing/aoapc-bac2nd-keys)
|
||||
- 《算法竞赛入门经典 - 训练指南》(白/蓝)- 陈锋 合著
|
||||
- 《算法艺术与信息学竞赛》(蓝/黑)
|
||||
- [第一版 配套资源仓库(镜像)](https://github.com/sukhoeing/aoapc-book/)
|
||||
- [第二版 配套资源仓库](https://github.com/aoapc-book/aoapc-bac2nd)
|
||||
- [第二版 习题选解](https://github.com/sukhoeing/aoapc-bac2nd-keys)
|
||||
- 《算法竞赛入门经典 - 训练指南》(白/蓝)- 陈锋 合著
|
||||
- 《算法艺术与信息学竞赛》(蓝/黑)
|
||||
- 《算法竞赛进阶指南》- 李煜东
|
||||
- [配套资源仓库](https://github.com/lydrainbowcat/tedukuri)
|
||||
- [配套资源仓库](https://github.com/lydrainbowcat/tedukuri)
|
||||
- 《啊哈算法》- 纪磊
|
||||
- 面向初学者或有初步兴趣的人群,有幽默配图。
|
||||
- 面向初学者或有初步兴趣的人群,有幽默配图。
|
||||
- CCF 中学生计算机程序设计系列
|
||||
- 《CCF 中学生计算机程序设计 - 入门篇》- 陈颖,邱桂香,朱全民
|
||||
- [建议配合勘误使用。](https://zhuanlan.zhihu.com/p/85215961)
|
||||
- 《CCF 中学生计算机程序设计 - 基础篇》- 江涛,宋新波,朱全民
|
||||
- 《CCF 中学生计算机程序设计 - 提高篇》- 徐先友,朱全民
|
||||
- 《CCF 中学生计算机程序设计 - 专业篇》(未出)
|
||||
- [建议配合勘误使用。](https://zhuanlan.zhihu.com/p/85215961)
|
||||
- 《CCF 中学生计算机程序设计 - 基础篇》- 江涛,宋新波,朱全民
|
||||
- 《CCF 中学生计算机程序设计 - 提高篇》- 徐先友,朱全民
|
||||
- 《CCF 中学生计算机程序设计 - 专业篇》(未出)
|
||||
- 深入浅出系列
|
||||
- 《深入浅出程序设计竞赛 - 基础篇》- 洛谷网校教研组
|
||||
- 《深入浅出程序设计竞赛 - 基础篇》- 洛谷网校教研组
|
||||
- 一本通系列
|
||||
- 《信息学奥赛一本通》- 董永建
|
||||
- 《信息学奥赛一本通》- 董永建
|
||||
- 《信息学奥赛一本通 - 提高篇》- 黄新军,董永建
|
||||
- [建议选择性阅读。](https://www.zhihu.com/question/292926937)
|
||||
- 《信息学奥赛一本通 - 高手训练》- 黄新军,董永建
|
||||
- [建议选择性阅读。](https://www.zhihu.com/question/292926937)
|
||||
- 《信息学奥赛一本通 - 高手训练》- 黄新军,董永建
|
||||
- 其他由国内著名 OI 教练写的教材
|
||||
- 《信息学奥赛课课通》- 林厚从
|
||||
- 《聪明人的游戏:信息学探秘 - 提高篇》- 江涛,陈茂贤
|
||||
- 《计算概论:C++ 编程与信息学竞赛入门》- 金靖
|
||||
- 《算法竞赛宝典》- 张新华
|
||||
- 《信息学奥赛课课通》- 林厚从
|
||||
- 《聪明人的游戏:信息学探秘 - 提高篇》- 江涛,陈茂贤
|
||||
- 《计算概论:C++ 编程与信息学竞赛入门》- 金靖
|
||||
- 《算法竞赛宝典》- 张新华
|
||||
- ACM 国际大学生程序设计竞赛系列
|
||||
- 《ACM 国际大学生程序设计竞赛系列 知识与入门》- 俞勇
|
||||
- 《ACM 国际大学生程序设计竞赛系列 算法与实现》- 俞勇
|
||||
- 《ACM 国际大学生程序设计竞赛系列 题目与解读》- 俞勇
|
||||
- 《算法竞赛入门到进阶》- 罗勇军,郭卫斌
|
||||
- 《ACM 国际大学生程序设计竞赛系列 知识与入门》- 俞勇
|
||||
- 《ACM 国际大学生程序设计竞赛系列 算法与实现》- 俞勇
|
||||
- 《ACM 国际大学生程序设计竞赛系列 题目与解读》- 俞勇
|
||||
- 《算法竞赛入门到进阶》- 罗勇军,郭卫斌
|
||||
- 《算法导论》第三版 - Thomas H.Cormen/Charles E.Leiserson/Ronald L.Rivest/Clifford Stein
|
||||
黑书,大学经典教材。英文版原名*Introduction to Algorithms*
|
||||
- [答案解析 (English)](https://github.com/walkccc/CLRS)
|
||||
- [答案解析 (English)](https://github.com/walkccc/CLRS)
|
||||
- 《具体数学》第二版 - Ronald L. Graham/Donald E. Knuth/Oren Patashnik
|
||||
英文版原名*Concrete Mathematics*
|
||||
- 《组合数学》第五版 - Richard A.Brualdi
|
||||
英文版原名*Introductory Combinatorics*
|
||||
- 《挑战程序设计竞赛》全套 - 秋叶拓哉,岩田阳一,北川宜稔
|
||||
通俗易懂。
|
||||
- [译者博客的介绍页](http://blog.watashi.ws/2382/pccb-etc/)
|
||||
- [译者博客的介绍页](http://blog.watashi.ws/2382/pccb-etc/)
|
||||
- 《算法概论》- Sanjoy Dasgupta/Christos Papadimitriou/Umesh Vazirani
|
||||
- 提纲挚领,但内容较少。
|
||||
- [Legend-K 的数据结构与算法的笔记](http://web.archive.org/web/20180826111306/http://www.legend-k.com/Algorithm/Algorithm.pdf)
|
||||
- [acm-cheat-sheet](https://github.com/soulmachine/acm-cheat-sheet)
|
||||
- 提纲挚领,但内容较少。
|
||||
- [Legend-K 的数据结构与算法的笔记](http://web.archive.org/web/20180826111306/http://www.legend-k.com/Algorithm/Algorithm.pdf)
|
||||
- [acm-cheat-sheet](https://github.com/soulmachine/acm-cheat-sheet)
|
||||
- [Competitive Programmer’s Handbook](https://cses.fi/book/book.pdf)- Antti Laaksonen
|
||||
- 作者花了三年个人时间完成。面向算法竞赛,覆盖面广,详略得当。
|
||||
- 作者花了三年个人时间完成。面向算法竞赛,覆盖面广,详略得当。
|
||||
- [《挑战编程:程序设计竞赛训练手册》](http://acm.cs.buap.mx/downloads/Programming_Challenges.pdf)- Steven S. Skiena/Miguel A. Revilla
|
||||
- 由西班牙 University of Valladolid 的两位教授编写。
|
||||
- 阅读 [经过翻译的在线电子版图书](http://www.tup.com.cn/upload/books/yz/030502-01.pdf)
|
||||
- 购买 [纸质版图书](http://www.tup.tsinghua.edu.cn/booksCenter/book_03050201.html)
|
||||
- 由西班牙 University of Valladolid 的两位教授编写。
|
||||
- 阅读 [经过翻译的在线电子版图书](http://www.tup.com.cn/upload/books/yz/030502-01.pdf)
|
||||
- 购买 [纸质版图书](http://www.tup.tsinghua.edu.cn/booksCenter/book_03050201.html)
|
||||
- 《C++,挑战编程——程序设计竞赛进阶训练指南》- 邱秋
|
||||
- [作者博客的介绍页](https://blog.csdn.net/metaphysis/article/details/90288252)
|
||||
- [作者博客的介绍页](https://blog.csdn.net/metaphysis/article/details/90288252)
|
||||
- [《数据结构(C++ 语言版 第 3 版)》- 邓俊辉](https://dsa.cs.tsinghua.edu.cn/~deng/ds/dsacpp/index.htm)
|
||||
- 建议随配套课程、配套课件和习题解析一起使用。
|
||||
- 建议随配套课程、配套课件和习题解析一起使用。
|
||||
- 《计算几何:算法与应用》- 伯格(Berg,M.D.)著,邓俊辉 译
|
||||
英文版原名*Computational Geometry: Algorithms and Applications*
|
||||
- [《Handbook of Data Structures and Applications, 2nd Edition》](https://www.routledge.com/Handbook-of-Data-Structures-and-Applications/Mehta-Sahni/p/book/9780367572006)
|
||||
- 由许多著名教授如 Sartaj Sahni、Hanan Samet、Weiss 等合著,内容较多,建议有一定基础的数据结构爱好者阅读。
|
||||
- 由许多著名教授如 Sartaj Sahni、Hanan Samet、Weiss 等合著,内容较多,建议有一定基础的数据结构爱好者阅读。
|
||||
- [算法详解 系列](https://www.algorithmsilluminated.org/)
|
||||
- 面向有语言基础的初学者的教材,建议同配套课程一起使用
|
||||
- 《Algorithms Illuminated, Part 1: The Basics》- Tim Roughgarden
|
||||
- 《算法详解,卷 1:算法基础》- 徐波 译
|
||||
- 《Algorithms Illuminated, Part 2: Graph Algorithms and Data Structures》- Tim Roughgarden
|
||||
- 《算法详解,卷 2:图算法和数据结构》- 徐波 译
|
||||
- 《Algorithms Illuminated, Part 3: Greedy Algorithms and Dynamic Programming》- Tim Roughgarden
|
||||
- 《Algorithms Illuminated, Part 4: Algorithms for NP-Hard Problems》- Tim Roughgarden
|
||||
- 面向有语言基础的初学者的教材,建议同配套课程一起使用
|
||||
- 《Algorithms Illuminated, Part 1: The Basics》- Tim Roughgarden
|
||||
- 《算法详解,卷 1:算法基础》- 徐波 译
|
||||
- 《Algorithms Illuminated, Part 2: Graph Algorithms and Data Structures》- Tim Roughgarden
|
||||
- 《算法详解,卷 2:图算法和数据结构》- 徐波 译
|
||||
- 《Algorithms Illuminated, Part 3: Greedy Algorithms and Dynamic Programming》- Tim Roughgarden
|
||||
- 《Algorithms Illuminated, Part 4: Algorithms for NP-Hard Problems》- Tim Roughgarden
|
||||
|
||||
## 课程
|
||||
|
||||
- [Baylor: CSI 3144 (2006)](http://cs.baylor.edu/~contest/syllabus.txt)
|
||||
- [CMU 15-295 (2021)](https://contest.cs.cmu.edu/295/)
|
||||
- [Georgia Tech: CS 4540 (2020)](https://faculty.cc.gatech.edu/~rpeng/CS4540_F20/)
|
||||
- [Georgia Tech: CS 6550 (2021)](https://faculty.cc.gatech.edu/~rpeng/CS6550_S21/)
|
||||
- [LSU: CSC 2700 (2021)](http://isaac.lsu.edu/class/)
|
||||
- [NUS: CS 3233 (2021)](https://www.comp.nus.edu.sg/~stevenha/cs3233.html)
|
||||
- [Reykjavik: T-414-ÁFLV (2016)](https://algo.is/)
|
||||
- [SPSU: Coursera (2019)](https://www.coursera.org/learn/competitive-programming-core-skills/)
|
||||
- [Stanford: CS 97SI (2015)](https://web.stanford.edu/class/cs97si/)
|
||||
- [Stonybrook: CSE 392 (2012)](https://www3.cs.stonybrook.edu/~skiena/392/)
|
||||
- [TAMU: CSCE 430 (2021)](https://www.cs.utexas.edu/users/utpc/courses/TAMU-CSCE-430.pdf)
|
||||
- [UBC: CPSC 490 (2021)](https://www.students.cs.ubc.ca/~cs-490/2019W2/problem-solving/)
|
||||
- [UCF: COP 4516 (2021)](http://www.cs.ucf.edu/~dmarino/progcontests/cop4516/spr2021/)
|
||||
- [VT: CS 2984/4984 (2020)](https://www.cs.utexas.edu/users/utpc/courses/VT-CS-2984-4984.pdf)
|
||||
- [THU: 数据结构](https://www.xuetangx.com/course/THU08091000384/)
|
||||
- [THU: 计算几何](https://www.xuetangx.com/course/THU08091000327/)
|
||||
- [StanfordOnline: Algorithms: Design and Analysis](https://www.algorithmsilluminated.org/)
|
||||
- [Baylor: CSI 3144 (2006)](http://cs.baylor.edu/~contest/syllabus.txt)
|
||||
- [CMU 15-295 (2021)](https://contest.cs.cmu.edu/295/)
|
||||
- [Georgia Tech: CS 4540 (2020)](https://faculty.cc.gatech.edu/~rpeng/CS4540_F20/)
|
||||
- [Georgia Tech: CS 6550 (2021)](https://faculty.cc.gatech.edu/~rpeng/CS6550_S21/)
|
||||
- [LSU: CSC 2700 (2021)](http://isaac.lsu.edu/class/)
|
||||
- [NUS: CS 3233 (2021)](https://www.comp.nus.edu.sg/~stevenha/cs3233.html)
|
||||
- [Reykjavik: T-414-ÁFLV (2016)](https://algo.is/)
|
||||
- [SPSU: Coursera (2019)](https://www.coursera.org/learn/competitive-programming-core-skills/)
|
||||
- [Stanford: CS 97SI (2015)](https://web.stanford.edu/class/cs97si/)
|
||||
- [Stonybrook: CSE 392 (2012)](https://www3.cs.stonybrook.edu/~skiena/392/)
|
||||
- [TAMU: CSCE 430 (2021)](https://www.cs.utexas.edu/users/utpc/courses/TAMU-CSCE-430.pdf)
|
||||
- [UBC: CPSC 490 (2021)](https://www.students.cs.ubc.ca/~cs-490/2019W2/problem-solving/)
|
||||
- [UCF: COP 4516 (2021)](http://www.cs.ucf.edu/~dmarino/progcontests/cop4516/spr2021/)
|
||||
- [VT: CS 2984/4984 (2020)](https://www.cs.utexas.edu/users/utpc/courses/VT-CS-2984-4984.pdf)
|
||||
- [THU: 数据结构](https://www.xuetangx.com/course/THU08091000384/)
|
||||
- [THU: 计算几何](https://www.xuetangx.com/course/THU08091000327/)
|
||||
- [StanfordOnline: Algorithms: Design and Analysis](https://www.algorithmsilluminated.org/)
|
||||
|
||||
## 工具
|
||||
|
||||
- [《100 个 gdb 小技巧》](https://github.com/hellogcc/100-gdb-tips)
|
||||
- [Algorithm Visualizer](http://algorithm-visualizer.org)
|
||||
- [cppreference](https://zh.cppreference.com/w/):一个全面的 C 和 C++ 语言及其标准库的在线参考资料
|
||||
- [Compiler Explorer](https://godbolt.org):在线查看编译后代码块对应的汇编语句,支持选择不同的编译器
|
||||
- [C++ Insights](https://cppinsights.io/):以编译器的视角去查看你的 C++ 源码
|
||||
- [Inverse Symbolic Calculator](http://wayback.cecm.sfu.ca/projects/ISC/ISCmain.html):实数反查表达式,适用于反推常数
|
||||
- [$\rm\LaTeX$ 手写符号识别](http://detexify.kirelabs.org/classify.html)
|
||||
- [$\rm\LaTeX$ 数学公式参考](http://www.mohu.org/info/symbols/symbols.htm)
|
||||
- [Mathpix](https://mathpix.com/):截图转 $\rm\LaTeX{}$
|
||||
- [OEIS](https://oeis.org):整数数列搜索引擎
|
||||
- [Python Tutor](https://pythontutor.com/): 代码执行过程可视化
|
||||
- [Quick C++ Benchmark](https://quick-bench.com/):在线比较两个及以上函数的运行速度
|
||||
- [Try It Online](https://tio.run):在线运行 600+ 种语言的代码,支持 IO 交互,超时 60s,可以分享代码
|
||||
- [图论画板](https://csacademy.com/app/graph_editor/) 与 [GraphViz](http://www.graphviz.org/)
|
||||
- [Ubuntu Pastebin](https://paste.ubuntu.com):可用于分享代码
|
||||
- [uDebug](https://www.udebug.com):提供一些 OJ 题目的调试辅助
|
||||
- [USF](https://www.cs.usfca.edu/~galles/visualization/) 与 [VisuAlgo](https://visualgo.net/zh):算法可视化
|
||||
- [Wandbox](https://wandbox.org/): 在线代码运行,支持 30+ 种语言,可以分享代码,支持不同编译器版本
|
||||
- [Wolfram Alpha](https://www.wolframalpha.com/):可以计算包括数学、科学技术、社会文化……等多个主题的问题
|
||||
- [《100 个 gdb 小技巧》](https://github.com/hellogcc/100-gdb-tips)
|
||||
- [Algorithm Visualizer](http://algorithm-visualizer.org)
|
||||
- [cppreference](https://zh.cppreference.com/w/):一个全面的 C 和 C++ 语言及其标准库的在线参考资料
|
||||
- [Compiler Explorer](https://godbolt.org):在线查看编译后代码块对应的汇编语句,支持选择不同的编译器
|
||||
- [C++ Insights](https://cppinsights.io/):以编译器的视角去查看你的 C++ 源码
|
||||
- [Inverse Symbolic Calculator](http://wayback.cecm.sfu.ca/projects/ISC/ISCmain.html):实数反查表达式,适用于反推常数
|
||||
- [$\rm\LaTeX$ 手写符号识别](http://detexify.kirelabs.org/classify.html)
|
||||
- [$\rm\LaTeX$ 数学公式参考](http://www.mohu.org/info/symbols/symbols.htm)
|
||||
- [Mathpix](https://mathpix.com/):截图转 $\rm\LaTeX{}$
|
||||
- [OEIS](https://oeis.org):整数数列搜索引擎
|
||||
- [Python Tutor](https://pythontutor.com/): 代码执行过程可视化
|
||||
- [Quick C++ Benchmark](https://quick-bench.com/):在线比较两个及以上函数的运行速度
|
||||
- [Try It Online](https://tio.run):在线运行 600+ 种语言的代码,支持 IO 交互,超时 60s,可以分享代码
|
||||
- [图论画板](https://csacademy.com/app/graph_editor/) 与 [GraphViz](http://www.graphviz.org/)
|
||||
- [Ubuntu Pastebin](https://paste.ubuntu.com):可用于分享代码
|
||||
- [uDebug](https://www.udebug.com):提供一些 OJ 题目的调试辅助
|
||||
- [USF](https://www.cs.usfca.edu/~galles/visualization/) 与 [VisuAlgo](https://visualgo.net/zh):算法可视化
|
||||
- [Wandbox](https://wandbox.org/): 在线代码运行,支持 30+ 种语言,可以分享代码,支持不同编译器版本
|
||||
- [Wolfram Alpha](https://www.wolframalpha.com/):可以计算包括数学、科学技术、社会文化……等多个主题的问题
|
||||
|
||||
## 题集和资源
|
||||
|
||||
- [POJ 训练计划](http://blog.csdn.net/skywalkert/article/details/46594541)
|
||||
- [USACO](http://train.usaco.org/usacogate)
|
||||
- [洛谷题单](https://www.luogu.com.cn/training/list)
|
||||
- [-Morass- 贴在 Codeforces 上的一份题单](https://codeforces.com/blog/entry/55274)
|
||||
- Codeforces 社区高质量算法文章合集 [之一](https://codeforces.com/blog/entry/57282) [之二](https://codeforces.com/blog/entry/13529)
|
||||
- [北京大学 ICPC 暑期课课件例题](https://vjudge.net/article/446)
|
||||
- [北京大学 ICPC 暑期课课件](https://lib-pku.github.io/#acm-icpc%E6%9A%91%E6%9C%9F%E8%AF%BE)
|
||||
- [GitHub.com:OI-wiki/libs](https://github.com/OI-wiki/libs)
|
||||
- [多校联合训练](http://acm.hdu.edu.cn) 关键词:`Multi-University Training Contest`
|
||||
- [Vjudge](https://vjudge.net/)
|
||||
- [Project Euler](https://projecteuler.net/)
|
||||
- [Junior Training Sheet](https://goo.gl/unDETI):对新手友好的训练计划
|
||||
- [USACO Guide](https://usaco.guide/):针对 USACO 的各个级别分类的训练资源
|
||||
- [POJ 训练计划](http://blog.csdn.net/skywalkert/article/details/46594541)
|
||||
- [USACO](http://train.usaco.org/usacogate)
|
||||
- [洛谷题单](https://www.luogu.com.cn/training/list)
|
||||
- [-Morass- 贴在 Codeforces 上的一份题单](https://codeforces.com/blog/entry/55274)
|
||||
- Codeforces 社区高质量算法文章合集 [之一](https://codeforces.com/blog/entry/57282) [之二](https://codeforces.com/blog/entry/13529)
|
||||
- [北京大学 ICPC 暑期课课件例题](https://vjudge.net/article/446)
|
||||
- [北京大学 ICPC 暑期课课件](https://lib-pku.github.io/#acm-icpc%E6%9A%91%E6%9C%9F%E8%AF%BE)
|
||||
- [GitHub.com:OI-wiki/libs](https://github.com/OI-wiki/libs)
|
||||
- [多校联合训练](http://acm.hdu.edu.cn) 关键词:`Multi-University Training Contest`
|
||||
- [Vjudge](https://vjudge.net/)
|
||||
- [Project Euler](https://projecteuler.net/)
|
||||
- [Junior Training Sheet](https://goo.gl/unDETI):对新手友好的训练计划
|
||||
- [USACO Guide](https://usaco.guide/):针对 USACO 的各个级别分类的训练资源
|
||||
|
|
|
|||
|
|
@ -15,15 +15,15 @@
|
|||
|
||||
同时了解一下 C++ 的源程序的大致框架是什么样子的。
|
||||
|
||||
- [Hello, World!](../lang/helloworld.md)
|
||||
- [C++ 语法基础](../lang/basic.md)
|
||||
- [Hello, World!](../lang/helloworld.md)
|
||||
- [C++ 语法基础](../lang/basic.md)
|
||||
|
||||
### 1.2 变量与运算
|
||||
|
||||
计算机出现的最初目的就是计算。因此我们先学习如何完成一些简单的运算任务吧。
|
||||
|
||||
- [变量](../lang/var.md)
|
||||
- [运算](../lang/op.md)
|
||||
- [变量](../lang/var.md)
|
||||
- [运算](../lang/op.md)
|
||||
|
||||
### 1.3 流程控制
|
||||
|
||||
|
|
@ -31,33 +31,33 @@
|
|||
|
||||
有的时候,我们需要在不同的条件下,选择执行不同的语句,这时候我们就需要借助分支语句。
|
||||
|
||||
- [分支](../lang/branch.md)
|
||||
- [分支](../lang/branch.md)
|
||||
|
||||
分支语句包括下面几种:
|
||||
|
||||
- if 语句
|
||||
- if-else 语句
|
||||
- if-elif-else 语句
|
||||
- switch 语句
|
||||
- if 语句
|
||||
- if-else 语句
|
||||
- if-elif-else 语句
|
||||
- switch 语句
|
||||
|
||||
#### 1.3.2 循环结构
|
||||
|
||||
将若干条语句重复执行多次,就需要用到循环语句。
|
||||
|
||||
- [循环](../lang/loop.md)
|
||||
- [循环](../lang/loop.md)
|
||||
|
||||
循环语句包括下面几种:
|
||||
|
||||
- for 语句
|
||||
- while 语句
|
||||
- do-while 语句
|
||||
- for 语句
|
||||
- while 语句
|
||||
- do-while 语句
|
||||
|
||||
### 1.4 数组与结构体
|
||||
|
||||
数组用于存储大量相同类型的数据。而结构体则可以将若干变量捆绑起来。
|
||||
|
||||
- [数组](../lang/array.md)
|
||||
- [结构体](../lang/struct.md)
|
||||
- [数组](../lang/array.md)
|
||||
- [结构体](../lang/struct.md)
|
||||
|
||||
### 1.5 函数与递归
|
||||
|
||||
|
|
@ -65,8 +65,8 @@
|
|||
|
||||
递归则是新手入门的一道坎,「自己调用自己」听起来并不是那么容易理解,不过仔细深究根本,就会发现「自己调用自己」和「自己调用别人」并没有本质差别。
|
||||
|
||||
- [函数](../lang/func.md)
|
||||
- [递归 & 分治](../basic/divide-and-conquer.md)
|
||||
- [函数](../lang/func.md)
|
||||
- [递归 & 分治](../basic/divide-and-conquer.md)
|
||||
|
||||
## 2 CSP-J 入门级
|
||||
|
||||
|
|
@ -76,21 +76,21 @@
|
|||
|
||||
为了做对一些简单的题目,你需要学会通过枚举或模拟脑海中的逻辑,来实现代码。这看起来并不是很高效,但有的时候很管用。
|
||||
|
||||
- [枚举](../basic/enumerate.md)
|
||||
- [模拟](../basic/simulate.md)
|
||||
- [枚举](../basic/enumerate.md)
|
||||
- [模拟](../basic/simulate.md)
|
||||
|
||||
### 2.2 递归与分治
|
||||
|
||||
递归是指函数定义中不断调用自己的方法;而分治则是不断将这一个问题分解为若干子问题,求解后合并的操作。
|
||||
|
||||
- [递归 & 分治](../basic/divide-and-conquer.md)
|
||||
- [递归 & 分治](../basic/divide-and-conquer.md)
|
||||
|
||||
### 2.3 字符串
|
||||
|
||||
在做信息学题目时,经常会碰到的一个数据类型就是字符串,你需要学习一些用于操作字符串的 STL 函数。当然,模拟也是解决字符串问题的好方法。
|
||||
|
||||
- [字符串基础](../string/basic.md)
|
||||
- [STL 函数](../string/lib-func.md)
|
||||
- [字符串基础](../string/basic.md)
|
||||
- [STL 函数](../string/lib-func.md)
|
||||
|
||||
### 2.4 排序
|
||||
|
||||
|
|
@ -98,17 +98,17 @@
|
|||
|
||||
排序的方法有点多,但理解后记住它们并不难。
|
||||
|
||||
- [排序简介](../basic/sort-intro.md)
|
||||
- [选择排序](../basic/selection-sort.md)
|
||||
- [冒泡排序](../basic/bubble-sort.md)
|
||||
- [插入排序](../basic/insertion-sort.md)
|
||||
- [计数排序](../basic/counting-sort.md)
|
||||
- [基数排序](../basic/radix-sort.md)
|
||||
- [快速排序](../basic/quick-sort.md)
|
||||
- [归并排序](../basic/merge-sort.md)
|
||||
- [堆排序](../basic/heap-sort.md)
|
||||
- [桶排序](../basic/bucket-sort.md)
|
||||
- [排序相关 STL](../basic/stl-sort.md)
|
||||
- [排序简介](../basic/sort-intro.md)
|
||||
- [选择排序](../basic/selection-sort.md)
|
||||
- [冒泡排序](../basic/bubble-sort.md)
|
||||
- [插入排序](../basic/insertion-sort.md)
|
||||
- [计数排序](../basic/counting-sort.md)
|
||||
- [基数排序](../basic/radix-sort.md)
|
||||
- [快速排序](../basic/quick-sort.md)
|
||||
- [归并排序](../basic/merge-sort.md)
|
||||
- [堆排序](../basic/heap-sort.md)
|
||||
- [桶排序](../basic/bucket-sort.md)
|
||||
- [排序相关 STL](../basic/stl-sort.md)
|
||||
|
||||
NOI 大纲中入门级只要求学习选择、冒泡、插入排序,共三个排序算法,但是其余的难度也并不大,且初赛中可能涉及,故一并列出。
|
||||
|
||||
|
|
@ -116,11 +116,11 @@ NOI 大纲中入门级只要求学习选择、冒泡、插入排序,共三个
|
|||
|
||||
二分查找,本质上是运用分治的思想,不断减少查找范围的大小,直至找到答案。但是需要注意,这个查找方式必须应用在有序的数据结构中。
|
||||
|
||||
- [二分](../basic/binary.md)
|
||||
- [二分](../basic/binary.md)
|
||||
|
||||
而倍增则不同,它是不断翻倍,以把线性范畴内的处理转化为对数级,大大优化时间复杂度。(这个知识点需要一点数学基础,暂时跳过也问题不大)
|
||||
|
||||
- [倍增](../basic/binary-lifting.md)
|
||||
- [倍增](../basic/binary-lifting.md)
|
||||
|
||||
### 2.6 搜索
|
||||
|
||||
|
|
@ -130,19 +130,19 @@ NOI 大纲中入门级只要求学习选择、冒泡、插入排序,共三个
|
|||
|
||||
深度优先搜索指利用递归函数方便地实现暴力枚举的算法,与图论中的 DFS 算法有一定相似之处,但并不完全相同。
|
||||
|
||||
- [DFS(搜索)](../search/dfs.md)
|
||||
- [DFS(搜索)](../search/dfs.md)
|
||||
|
||||
#### 2.6.2 广度优先搜索(BFS)
|
||||
|
||||
将每一个状态设计为图中的一个点,可以展开地毯式搜索。
|
||||
|
||||
- [BFS(搜索)](../search/bfs.md)
|
||||
- [BFS(搜索)](../search/bfs.md)
|
||||
|
||||
#### 2.6.3 搜索优化
|
||||
|
||||
很多题目都可以用 DFS 来解决,而这个算法的复杂度显然是无法通过的。因此,需要一些优化使它跑得更快。这样的优化能够减少不可能成功的尝试,称为“剪枝”。BFS 相关的优化就要更加灵活了,但是基本思路和这里是一样的。
|
||||
|
||||
- [DFS 剪枝优化](../search/opt.md)
|
||||
- [DFS 剪枝优化](../search/opt.md)
|
||||
|
||||
### 2.7 数据结构入门
|
||||
|
||||
|
|
@ -150,15 +150,15 @@ NOI 大纲中入门级只要求学习选择、冒泡、插入排序,共三个
|
|||
|
||||
数组,链表,队列,栈,都是线性结构。巧用这些结构可以做出不少方便的事情。
|
||||
|
||||
- [栈](../ds/stack.md)
|
||||
- [队列](../ds/queue.md)
|
||||
- [链表](../ds/linked-list.md)
|
||||
- [栈](../ds/stack.md)
|
||||
- [队列](../ds/queue.md)
|
||||
- [链表](../ds/linked-list.md)
|
||||
|
||||
#### 2.7.2 复杂数据结构
|
||||
|
||||
- [树及二叉树](../graph/tree-basic.md)
|
||||
- [图的概念](../graph/concept.md)
|
||||
- [图的存储](../graph/save.md)
|
||||
- [树及二叉树](../graph/tree-basic.md)
|
||||
- [图的概念](../graph/concept.md)
|
||||
- [图的存储](../graph/save.md)
|
||||
|
||||
### 2.8 动态规划入门
|
||||
|
||||
|
|
@ -166,32 +166,32 @@ NOI 大纲中入门级只要求学习选择、冒泡、插入排序,共三个
|
|||
|
||||
由于动态规划并不是某种具体的算法,而是一种解决特定问题的方法,因此它会出现在各式各样的数据结构中,与之相关的题目种类也更为繁杂。
|
||||
|
||||
- [动态规划简介](../dp/index.md)
|
||||
- [动态规划简介](../dp/index.md)
|
||||
|
||||
#### 2.8.1 背包问题
|
||||
|
||||
即给出一个有限制容量的背包,选择放入若干有容量和价值的物品,求解如何放置能使得价值总和最大。这是阻挡很多 OIer 的第一道坎,从这里开始,算法就有些难以理解。
|
||||
|
||||
- [背包 DP](../dp/knapsack.md)
|
||||
- [背包 DP](../dp/knapsack.md)
|
||||
|
||||
#### 2.8.2 线性动态规划
|
||||
|
||||
在动态规划中,最难的部分之一就是设计状态,需要用到构造相关技巧。当你写出了状态和状态转移方程之后,完成一道动态规划的题目就不难了。
|
||||
|
||||
- [构造](../basic/construction.md)
|
||||
- [动态规划基础](../dp/basic.md)
|
||||
- [构造](../basic/construction.md)
|
||||
- [动态规划基础](../dp/basic.md)
|
||||
|
||||
记忆化搜索是一种通过记录已经遍历过的状态的信息,从而避免对同一状态重复遍历的搜索实现方式。有的题目也可以使用记忆化搜索来降低思维难度。
|
||||
|
||||
因为记忆化搜索确保了每个状态只访问一次,它也是一种常见的动态规划实现方式。
|
||||
|
||||
- [记忆化搜索](../dp/memo.md)
|
||||
- [记忆化搜索](../dp/memo.md)
|
||||
|
||||
#### 2.8.3 复杂动态规划
|
||||
|
||||
区间类动态规划是线性动态规划的扩展,它在分阶段地划分问题时,与阶段中元素出现的顺序和由前一阶段的哪些元素合并而来有很大的关系。
|
||||
|
||||
- [区间 DP](../dp/interval.md)
|
||||
- [区间 DP](../dp/interval.md)
|
||||
|
||||
### 2.9 数学
|
||||
|
||||
|
|
@ -199,13 +199,13 @@ NOI 大纲中入门级只要求学习选择、冒泡、插入排序,共三个
|
|||
|
||||
就算是 long long(或 int64)还不够怎么办?用高精度算法。本质上就是模拟了四则运算。
|
||||
|
||||
- [高精度计算](../math/bignum.md)
|
||||
- [高精度计算](../math/bignum.md)
|
||||
|
||||
#### 2.9.2 进制转换
|
||||
|
||||
在计算机中,除了二进制,比较常用的还有八进制和十六进制。有的时候学会运用正确的进制对解题也有很大帮助。
|
||||
|
||||
- [进位制](../math/base.md)
|
||||
- [进位制](../math/base.md)
|
||||
|
||||
#### 2.9.3 位运算
|
||||
|
||||
|
|
@ -213,23 +213,23 @@ NOI 大纲中入门级只要求学习选择、冒泡、插入排序,共三个
|
|||
|
||||
基本的位运算共 6 种,分别为按位与、按位或、按位异或、按位取反、左移和右移。
|
||||
|
||||
- [位运算](../math/bit.md)
|
||||
- [位运算](../math/bit.md)
|
||||
|
||||
#### 2.9.4 数论
|
||||
|
||||
- [数论基础](../math/number-theory/basic.md)
|
||||
- [素数](../math/number-theory/prime.md)
|
||||
- [筛法](../math/number-theory/sieve.md)
|
||||
- [最大公因数](../math/number-theory/gcd.md)
|
||||
- [欧拉函数](../math/number-theory/euler.md)
|
||||
- [分解质因数](../math/number-theory/pollard-rho.md)
|
||||
- [数论基础](../math/number-theory/basic.md)
|
||||
- [素数](../math/number-theory/prime.md)
|
||||
- [筛法](../math/number-theory/sieve.md)
|
||||
- [最大公因数](../math/number-theory/gcd.md)
|
||||
- [欧拉函数](../math/number-theory/euler.md)
|
||||
- [分解质因数](../math/number-theory/pollard-rho.md)
|
||||
|
||||
#### 2.9.5 组合计数
|
||||
|
||||
- [排列组合](../math/combinatorics/combination.md)
|
||||
- [抽屉原理](../math/combinatorics/drawer-principle.md)
|
||||
- [容斥原理](../math/combinatorics/inclusion-exclusion-principle.md)
|
||||
- [排列组合](../math/combinatorics/combination.md)
|
||||
- [抽屉原理](../math/combinatorics/drawer-principle.md)
|
||||
- [容斥原理](../math/combinatorics/inclusion-exclusion-principle.md)
|
||||
|
||||
* * *
|
||||
***
|
||||
|
||||
至此,你就学习完了入门组范畴内的所有算法,但是想要掌握它们,你需要继续进行足够数量的刷题,以巩固你所学到的知识点。
|
||||
|
|
|
|||
|
|
@ -6,7 +6,7 @@ author: Ir1d, CBW2007, ChungZH, xhn16729, Xeonacid, tptpp, hsfzLZH1, ouuan, Marc
|
|||
|
||||
## 引入
|
||||
|
||||
???+note "[[IOI1994]数字三角形](https://www.luogu.com.cn/problem/P1216)"
|
||||
???+ note "[\[IOI1994\] 数字三角形](https://www.luogu.com.cn/problem/P1216)"
|
||||
给定一个 $r$ 行的数字三角形($r \leq 1000$),需要找到一条从最高点到底部任意处结束的路径,使路径经过数字的和最大。每一步可以走到当前点左下方的点或右下方的点。
|
||||
|
||||
```plain
|
||||
|
|
@ -43,17 +43,17 @@ author: Ir1d, CBW2007, ChungZH, xhn16729, Xeonacid, tptpp, hsfzLZH1, ouuan, Marc
|
|||
|
||||
注意要确保我们考察了最优解中用到的所有子问题。
|
||||
|
||||
1. 证明问题最优解的第一个组成部分是做出一个选择;
|
||||
2. 对于一个给定问题,在其可能的第一步选择中,假定你已经知道哪种选择才会得到最优解。你现在并不关心这种选择具体是如何得到的,只是假定已经知道了这种选择;
|
||||
3. 给定可获得的最优解的选择后,确定这次选择会产生哪些子问题,以及如何最好地刻画子问题空间;
|
||||
4. 证明作为构成原问题最优解的组成部分,每个子问题的解就是它本身的最优解。方法是反证法,考虑加入某个子问题的解不是其自身的最优解,那么就可以从原问题的解中用该子问题的最优解替换掉当前的非最优解,从而得到原问题的一个更优的解,从而与原问题最优解的假设矛盾。
|
||||
1. 证明问题最优解的第一个组成部分是做出一个选择;
|
||||
2. 对于一个给定问题,在其可能的第一步选择中,假定你已经知道哪种选择才会得到最优解。你现在并不关心这种选择具体是如何得到的,只是假定已经知道了这种选择;
|
||||
3. 给定可获得的最优解的选择后,确定这次选择会产生哪些子问题,以及如何最好地刻画子问题空间;
|
||||
4. 证明作为构成原问题最优解的组成部分,每个子问题的解就是它本身的最优解。方法是反证法,考虑加入某个子问题的解不是其自身的最优解,那么就可以从原问题的解中用该子问题的最优解替换掉当前的非最优解,从而得到原问题的一个更优的解,从而与原问题最优解的假设矛盾。
|
||||
|
||||
要保持子问题空间尽量简单,只在必要时扩展。
|
||||
|
||||
最优子结构的不同体现在两个方面:
|
||||
|
||||
1. 原问题的最优解中涉及多少个子问题;
|
||||
2. 确定最优解使用哪些子问题时,需要考察多少种选择。
|
||||
1. 原问题的最优解中涉及多少个子问题;
|
||||
2. 确定最优解使用哪些子问题时,需要考察多少种选择。
|
||||
|
||||
子问题图中每个定点对应一个子问题,而需要考察的选择对应关联至子问题顶点的边。
|
||||
|
||||
|
|
@ -69,15 +69,15 @@ author: Ir1d, CBW2007, ChungZH, xhn16729, Xeonacid, tptpp, hsfzLZH1, ouuan, Marc
|
|||
|
||||
对于一个能用动态规划解决的问题,一般采用如下思路解决:
|
||||
|
||||
1. 将原问题划分为若干 **阶段**,每个阶段对应若干个子问题,提取这些子问题的特征(称之为 **状态**);
|
||||
2. 寻找每一个状态的可能 **决策**,或者说是各状态间的相互转移方式(用数学的语言描述就是 **状态转移方程**)。
|
||||
3. 按顺序求解每一个阶段的问题。
|
||||
1. 将原问题划分为若干 **阶段**,每个阶段对应若干个子问题,提取这些子问题的特征(称之为 **状态**);
|
||||
2. 寻找每一个状态的可能 **决策**,或者说是各状态间的相互转移方式(用数学的语言描述就是 **状态转移方程**)。
|
||||
3. 按顺序求解每一个阶段的问题。
|
||||
|
||||
如果用图论的思想理解,我们建立一个 [有向无环图](../graph/dag.md),每个状态对应图上一个节点,决策对应节点间的连边。这样问题就转变为了一个在 DAG 上寻找最长(短)路的问题(参见:[DAG 上的 DP](./dag.md))。
|
||||
|
||||
## 最长公共子序列
|
||||
|
||||
???+note "最长公共子序列问题"
|
||||
???+ note "最长公共子序列问题"
|
||||
给定一个长度为 $n$ 的序列 $A$ 和一个 长度为 $m$ 的序列 $B$($n,m \leq 5000$),求出一个最长的序列,使得该序列既是 $A$ 的子序列,也是 $B$ 的子序列。
|
||||
|
||||
子序列的定义可以参考 [子序列](../string/basic.md)。一个简要的例子:字符串 `abcde` 与字符串 `acde` 的公共子序列有 `a`、`c`、`d`、`e`、`ac`、`ad`、`ae`、`cd`、`ce`、`de`、`ade`、`ace`、`cde`、`acde`,最长公共子序列的长度是 4。
|
||||
|
|
@ -112,7 +112,7 @@ int dp() {
|
|||
|
||||
## 最长不下降子序列
|
||||
|
||||
???+note "最长不下降子序列问题"
|
||||
???+ note "最长不下降子序列问题"
|
||||
给定一个长度为 $n$ 的序列 $A$($n \leq 5000$),求出一个最长的 $A$ 的子序列,满足该子序列的后一个元素不小于前一个元素。
|
||||
|
||||
### 算法一
|
||||
|
|
@ -171,8 +171,8 @@ int dp() {
|
|||
|
||||
考虑进来一个元素 $a_i$:
|
||||
|
||||
1. 元素大于等于 $d_{len}$,直接将该元素插入到 $d$ 序列的末尾。
|
||||
2. 元素小于 $d_{len}$,找到 **第一个** 大于它的元素,插入进去,丢弃在它之后的全部元素。
|
||||
1. 元素大于等于 $d_{len}$,直接将该元素插入到 $d$ 序列的末尾。
|
||||
2. 元素小于 $d_{len}$,找到 **第一个** 大于它的元素,插入进去,丢弃在它之后的全部元素。
|
||||
|
||||
参考代码如下:
|
||||
|
||||
|
|
|
|||
|
|
@ -1 +0,0 @@
|
|||
|
||||
|
|
@ -6,7 +6,7 @@ DAG 即 [有向无环图](../graph/dag.md),一些实际问题中的二元关
|
|||
|
||||
以这道题为例子,来分析一下 DAG 建模的过程。
|
||||
|
||||
???+note " 例题 [UVa 437 巴比伦塔 The Tower of Babylon](https://cn.vjudge.net/problem/UVA-437)"
|
||||
???+ note " 例题 [UVa 437 巴比伦塔 The Tower of Babylon](https://cn.vjudge.net/problem/UVA-437)"
|
||||
有 $n (n\leqslant 30)$ 种砖块,已知三条边长,每种都有无穷多个。要求选一些立方体摞成一根尽量高的柱子(每个砖块可以自行选择一条边作为高),使得每个砖块的底面长宽分别严格小于它下方砖块的底面长宽,求塔的最大高度。
|
||||
|
||||
## 过程
|
||||
|
|
|
|||
|
|
@ -6,7 +6,7 @@
|
|||
|
||||
以这道模板题为例子讲解一下动态 DP 的过程。
|
||||
|
||||
???+note " 例题 [洛谷 P4719 【模板】动态 DP](https://www.luogu.com.cn/problem/P4719) "
|
||||
???+ note " 例题 [洛谷 P4719【模板】动态 DP](https://www.luogu.com.cn/problem/P4719)"
|
||||
给定一棵 $n$ 个点的树,点带点权。有 $m$ 次操作,每次操作给定 $x,y$ 表示修改点 $x$ 的权值为 $y$。你需要在每次操作之后求出这棵树的最大权独立集的权值大小。
|
||||
|
||||
### 广义矩阵乘法
|
||||
|
|
@ -70,13 +70,13 @@ $$
|
|||
|
||||
### 具体思路
|
||||
|
||||
1. DFS 预处理求出 $f_{i,0/1}$ 和 $g_{i,0/1}$.
|
||||
1. DFS 预处理求出 $f_{i,0/1}$ 和 $g_{i,0/1}$.
|
||||
|
||||
2. 对这棵树进行树链剖分(注意,因为我们对一个点进行询问需要计算从该点到该点所在的重链末尾的区间矩阵乘,所以对于每一个点记录 $End_i$ 表示 $i$ 所在的重链末尾节点编号),每一条重链建立线段树,线段树维护 $g$ 矩阵和 $g$ 矩阵区间乘积。
|
||||
2. 对这棵树进行树链剖分(注意,因为我们对一个点进行询问需要计算从该点到该点所在的重链末尾的区间矩阵乘,所以对于每一个点记录 $End_i$ 表示 $i$ 所在的重链末尾节点编号),每一条重链建立线段树,线段树维护 $g$ 矩阵和 $g$ 矩阵区间乘积。
|
||||
|
||||
3. 修改时首先修改 $g_{i,1}$ 和线段树中 $i$ 节点的矩阵,计算 $top_i$ 矩阵的变化量,修改到 $fa_{top_i}$ 矩阵。
|
||||
3. 修改时首先修改 $g_{i,1}$ 和线段树中 $i$ 节点的矩阵,计算 $top_i$ 矩阵的变化量,修改到 $fa_{top_i}$ 矩阵。
|
||||
|
||||
4. 查询时就是 1 到其所在的重链末尾的区间乘,最后取一个 $\max$ 即可。
|
||||
4. 查询时就是 1 到其所在的重链末尾的区间乘,最后取一个 $\max$ 即可。
|
||||
|
||||
??? note "代码实现"
|
||||
```c++
|
||||
|
|
@ -85,6 +85,6 @@ $$
|
|||
|
||||
## 习题
|
||||
|
||||
- [SPOJ GSS3 - Can you answer these queries III](https://www.spoj.com/problems/GSS3/)
|
||||
- [「NOIP2018」保卫王国](https://loj.ac/p/2955)
|
||||
- [「SDOI2017」切树游戏](https://loj.ac/p/2269)
|
||||
- [SPOJ GSS3 - Can you answer these queries III](https://www.spoj.com/problems/GSS3/)
|
||||
- [「NOIP2018」保卫王国](https://loj.ac/p/2955)
|
||||
- [「SDOI2017」切树游戏](https://loj.ac/p/2269)
|
||||
|
|
|
|||
|
|
@ -18,7 +18,7 @@
|
|||
|
||||
### 例题
|
||||
|
||||
???+note "[「NOI1995」石子合并](https://loj.ac/problem/10147)"
|
||||
???+ note "[「NOI1995」石子合并](https://loj.ac/problem/10147)"
|
||||
题目大意:在一个环上有 $n$ 个数 $a_1,a_2,\dots,a_n$,进行 $n-1$ 次合并操作,每次操作将相邻的两堆合并成一堆,能获得新的一堆中的石子数量的和的得分。你需要最大化你的得分。
|
||||
|
||||
需要考虑不在环上,而在一条链上的情况。
|
||||
|
|
|
|||
|
|
@ -6,7 +6,7 @@ author: hydingsy, Link-cute, Ir1d, greyqz, LuoshuiTianyi, Odeinjul, xyf007, Good
|
|||
|
||||
在具体讲何为「背包 dp」前,先来看如下的例题:
|
||||
|
||||
???+note "[「USACO07 DEC」Charm Bracelet](https://www.luogu.com.cn/problem/P2871)"
|
||||
???+ note "[「USACO07 DEC」Charm Bracelet](https://www.luogu.com.cn/problem/P2871)"
|
||||
题意概要:有 $n$ 个物品和一个容量为 $W$ 的背包,每个物品有重量 $w_{i}$ 和价值 $v_{i}$ 两种属性,要求选若干物品放入背包使背包中物品的总价值最大且背包中物品的总重量不超过背包的容量。
|
||||
|
||||
在上述例题中,由于每个物体只有两种可能的状态(取与不取),对应二进制中的 $0$ 和 $1$,这类问题便被称为「0-1 背包问题」。
|
||||
|
|
@ -158,10 +158,10 @@ $$
|
|||
|
||||
举几个例子:
|
||||
|
||||
- $6=1+2+3$
|
||||
- $8=1+2+4+1$
|
||||
- $18=1+2+4+8+3$
|
||||
- $31=1+2+4+8+16$
|
||||
- $6=1+2+3$
|
||||
- $8=1+2+4+1$
|
||||
- $18=1+2+4+8+3$
|
||||
- $31=1+2+4+8+16$
|
||||
|
||||
显然,通过上述拆分方式,可以表示任意 $\le k_i$ 个物品的等效选择方式。将每种物品按照上述方式拆分后,使用 0-1 背包的方法解决即可。
|
||||
|
||||
|
|
@ -236,7 +236,7 @@ for (循环物品种类) {
|
|||
|
||||
## 二维费用背包
|
||||
|
||||
???+note "[「Luogu P1855」榨取 kkksc03](https://www.luogu.com.cn/problem/P1855)"
|
||||
???+ note "[「Luogu P1855」榨取 kkksc03](https://www.luogu.com.cn/problem/P1855)"
|
||||
有 $n$ 个任务需要完成,完成第 $i$ 个任务需要花费 $t_i$ 分钟,产生 $c_i$ 元的开支。
|
||||
|
||||
现在有 $T$ 分钟时间,$W$ 元钱来处理这些任务,求最多能完成多少任务。
|
||||
|
|
@ -267,7 +267,7 @@ for (循环物品种类) {
|
|||
|
||||
## 分组背包
|
||||
|
||||
???+note "[「Luogu P1757」通天之分组背包](https://www.luogu.com.cn/problem/P1757)"
|
||||
???+ note "[「Luogu P1757」通天之分组背包](https://www.luogu.com.cn/problem/P1757)"
|
||||
有 $n$ 件物品和一个大小为 $m$ 的背包,第 $i$ 个物品的价值为 $w_i$,体积为 $v_i$。同时,每个物品属于一个组,同组内最多只能选择一个物品。求背包能装载物品的最大总价值。
|
||||
|
||||
这种题怎么想呢?其实是从「在所有物品中选择一件」变成了「从当前组中选择一件」,于是就对每一组进行一次 0-1 背包就可以了。
|
||||
|
|
@ -298,7 +298,7 @@ for (循环物品种类) {
|
|||
|
||||
## 有依赖的背包
|
||||
|
||||
???+note "[「Luogu P1064」金明的预算方案](https://www.luogu.com.cn/problem/P1064)"
|
||||
???+ note "[「Luogu P1064」金明的预算方案](https://www.luogu.com.cn/problem/P1064)"
|
||||
金明有 $n$ 元钱,想要买 $m$ 个物品,第 $i$ 件物品的价格为 $v_i$,重要度为 $p_i$。有些物品是从属于某个主件物品的附件,要买这个物品,必须购买它的主件。
|
||||
|
||||
目标是让所有购买的物品的 $v_i \times p_i$ 之和最大。
|
||||
|
|
@ -383,7 +383,7 @@ g[0] = 1; // 什么都不装是一种方案
|
|||
|
||||
最后我们通过找到最优解的价值,把 $g_{j}$ 数组里取到最优解的所有方案数相加即可。
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
for (int i = 0; i < N; i++) {
|
||||
for (int j = V; j >= v[i]; j--) {
|
||||
|
|
@ -444,4 +444,4 @@ g[0] = 1; // 什么都不装是一种方案
|
|||
|
||||
### 参考资料与注释
|
||||
|
||||
- [背包问题九讲 - 崔添翼](https://github.com/tianyicui/pack)。
|
||||
- [背包问题九讲 - 崔添翼](https://github.com/tianyicui/pack)。
|
||||
|
|
|
|||
|
|
@ -6,7 +6,7 @@
|
|||
|
||||
## 引入
|
||||
|
||||
???+note "[[NOIP2005] 采药](https://www.luogu.com.cn/problem/P1048)"
|
||||
???+ note "[\[NOIP2005\] 采药](https://www.luogu.com.cn/problem/P1048)"
|
||||
山洞里有 $M$ 株不同的草药,采每一株都需要一些时间 $t_i$,每一株也有它自身的价值 $v_i$。给你一段时间 $T$,在这段时间里,你可以采到一些草药。让采到的草药的总价值最大。
|
||||
|
||||
$1 \leq T \leq 10^3$,$1 \leq t_i,v_i,M \leq 100$
|
||||
|
|
@ -15,7 +15,7 @@
|
|||
|
||||
很容易实现这样一个朴素的搜索做法:在搜索时记录下当前准备选第几个物品、剩余的时间是多少、已经获得的价值是多少这三个参数,然后枚举当前物品是否被选,转移到相应的状态。
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
=== "C++"
|
||||
|
||||
```cpp
|
||||
|
|
@ -76,7 +76,7 @@
|
|||
|
||||
通过这样的处理,我们确保了每个状态只会被访问一次,因此该算法的的时间复杂度为 $O(TM)$。
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
=== "C++"
|
||||
|
||||
```cpp
|
||||
|
|
@ -160,9 +160,9 @@ int main() {
|
|||
|
||||
### 方法一
|
||||
|
||||
1. 把这道题的 dp 状态和方程写出来
|
||||
2. 根据它们写出 dfs 函数
|
||||
3. 添加记忆化数组
|
||||
1. 把这道题的 dp 状态和方程写出来
|
||||
2. 根据它们写出 dfs 函数
|
||||
3. 添加记忆化数组
|
||||
|
||||
举例:
|
||||
|
||||
|
|
@ -208,8 +208,8 @@ $dp_{i} = \max\{dp_{j}+1\}\quad (1 \leq j < i \land a_{j}<a_{i})$(最长上升
|
|||
|
||||
### 方法二
|
||||
|
||||
1. 写出这道题的暴搜程序(最好是 [dfs](../search/dfs.md))
|
||||
2. 将这个 dfs 改成「无需外部变量」的 dfs
|
||||
3. 添加记忆化数组
|
||||
1. 写出这道题的暴搜程序(最好是 [dfs](../search/dfs.md))
|
||||
2. 将这个 dfs 改成「无需外部变量」的 dfs
|
||||
3. 添加记忆化数组
|
||||
|
||||
举例:本文中「采药」的例子
|
||||
|
|
|
|||
|
|
@ -1 +0,0 @@
|
|||
|
||||
|
|
@ -2,17 +2,17 @@
|
|||
|
||||
## 引入
|
||||
|
||||
数位是指把一个数字按照个、十、百、千等等一位一位地拆开,关注它每一位上的数字。如果拆的是十进制数,那么每一位数字都是 0~9,其他进制可类比十进制。
|
||||
数位是指把一个数字按照个、十、百、千等等一位一位地拆开,关注它每一位上的数字。如果拆的是十进制数,那么每一位数字都是 0\~9,其他进制可类比十进制。
|
||||
|
||||
数位 DP:用来解决一类特定问题,这种问题比较好辨认,一般具有这几个特征:
|
||||
|
||||
1. 要求统计满足一定条件的数的数量(即,最终目的为计数);
|
||||
1. 要求统计满足一定条件的数的数量(即,最终目的为计数);
|
||||
|
||||
2. 这些条件经过转化后可以使用「数位」的思想去理解和判断;
|
||||
2. 这些条件经过转化后可以使用「数位」的思想去理解和判断;
|
||||
|
||||
3. 输入会提供一个数字区间(有时也只提供上界)来作为统计的限制;
|
||||
3. 输入会提供一个数字区间(有时也只提供上界)来作为统计的限制;
|
||||
|
||||
4. 上界很大(比如 $10^{18}$),暴力枚举验证会超时。
|
||||
4. 上界很大(比如 $10^{18}$),暴力枚举验证会超时。
|
||||
|
||||
数位 DP 的基本原理:
|
||||
|
||||
|
|
@ -26,7 +26,7 @@
|
|||
|
||||
## 例题一
|
||||
|
||||
???+note " 例 1 [Luogu P2602 数字计数](https://www.luogu.com.cn/problem/P2602)"
|
||||
???+ note " 例 1 [Luogu P2602 数字计数](https://www.luogu.com.cn/problem/P2602)"
|
||||
题目大意:给定两个正整数 $a,b$,求在 $[a,b]$ 中的所有整数中,每个数码(digit)各出现了多少次。
|
||||
|
||||
### 方法一
|
||||
|
|
@ -84,7 +84,7 @@
|
|||
|
||||
#### 过程
|
||||
|
||||
???+note "参考代码"
|
||||
???+ note "参考代码"
|
||||
```c++
|
||||
#include <cstdio> //code by Alphnia
|
||||
#include <cstring>
|
||||
|
|
@ -143,7 +143,7 @@
|
|||
|
||||
## 例题二
|
||||
|
||||
???+note " 例 2 [hdu 2089 不要62](https://vjudge.net/problem/HDU-2089)"
|
||||
???+ note " 例 2 [hdu 2089 不要 62](https://vjudge.net/problem/HDU-2089)"
|
||||
题面大意:统计一个区间内数位上不能有 4 也不能有连续的 62 的数有多少。
|
||||
|
||||
### 解释
|
||||
|
|
@ -152,7 +152,7 @@
|
|||
|
||||
### 实现
|
||||
|
||||
???+note "参考代码"
|
||||
???+ note "参考代码"
|
||||
```c++
|
||||
#include <cstdio> //code by Alphnia
|
||||
#include <cstring>
|
||||
|
|
@ -205,7 +205,7 @@
|
|||
|
||||
## 例题三
|
||||
|
||||
???+note " 例 3 [SCOI2009 windy 数 ](https://loj.ac/problem/10165)"
|
||||
???+ note " 例 3 [SCOI2009 windy 数](https://loj.ac/problem/10165)"
|
||||
题目大意:给定一个区间 $[l,r]$,求其中满足条件 **不含前导 $0$ 且相邻两个数字相差至少为 $2$** 的数字个数。
|
||||
|
||||
### 解释
|
||||
|
|
@ -224,7 +224,7 @@
|
|||
|
||||
### 实现
|
||||
|
||||
???+note "参考代码"
|
||||
???+ note "参考代码"
|
||||
```cpp
|
||||
int dfs(int x, int st, int op) // op=1 =;op=0 <
|
||||
{
|
||||
|
|
@ -257,7 +257,7 @@
|
|||
|
||||
## 例题四
|
||||
|
||||
???+note "例 4.[SPOJMYQ10](https://www.spoj.com/problems/MYQ10/en/)"
|
||||
???+ note " 例 4.[SPOJMYQ10](https://www.spoj.com/problems/MYQ10/en/)"
|
||||
题面大意:假如手写下 $[n,m]$ 之间所有整数,会有多少数看起来和在镜子里看起来一模一样?($n,m<10^{44}, T<10^5$)
|
||||
|
||||
### 解释
|
||||
|
|
@ -276,7 +276,7 @@
|
|||
|
||||
### 实现
|
||||
|
||||
???+note "参考代码"
|
||||
???+ note "参考代码"
|
||||
```c++
|
||||
int check(char cc[]) { // n 的特判
|
||||
int strc = strlen(cc);
|
||||
|
|
@ -324,7 +324,7 @@
|
|||
|
||||
## 例题五
|
||||
|
||||
???+note "例 5. [P3311 数数](https://www.luogu.com.cn/problem/P3311)"
|
||||
???+ note " 例 5.[P3311 数数](https://www.luogu.com.cn/problem/P3311)"
|
||||
题面:我们称一个正整数 $x$ 是幸运数,当且仅当它的十进制表示中不包含数字串集合 $S$ 中任意一个元素作为其子串。例如当 $S = \{22, 333, 0233\}$ 时,$233233$ 是幸运数,$23332333$、$2023320233$、$32233223$ 不是幸运数。给定 $n$ 和 $S$,计算不大于 $n$ 的幸运数个数。答案对 $10^9 + 7$ 取模。
|
||||
|
||||
$1 \leq n<10^{1201},1 \leq m \leq 100,1 \leq \sum_{i = 1}^m |s_i| \leq 1500,\min_{i = 1}^m |s_i| \geq 1$,其中 $|s_i|$ 表示字符串 $s_i$ 的长度。$n$ 没有前导 $0$,但是 $s_i$ 可能有前导 $0$。
|
||||
|
|
@ -341,7 +341,7 @@
|
|||
|
||||
### 实现
|
||||
|
||||
???+note "参考代码"
|
||||
???+ note "参考代码"
|
||||
```c++
|
||||
#include <bits/stdc++.h> //code by Alphnia
|
||||
using namespace std;
|
||||
|
|
|
|||
|
|
@ -4,7 +4,7 @@ author: Marcythm, hsfzLZH1, Ir1d, greyqz, Anguei, billchenchina, Chrogeek, Chung
|
|||
|
||||
前置知识:[单调队列](../../ds/monotonous-queue.md)、[单调栈](../../ds/monotonous-stack.md)。
|
||||
|
||||
???+note " 例题 [CF372C Watching Fireworks is Fun](http://codeforces.com/problemset/problem/372/C)"
|
||||
???+ note " 例题 [CF372C Watching Fireworks is Fun](http://codeforces.com/problemset/problem/372/C)"
|
||||
题目大意:城镇中有 $n$ 个位置,有 $m$ 个烟花要放。第 $i$ 个烟花放出的时间记为 $t_i$,放出的位置记为 $a_i$。如果烟花放出的时候,你处在位置 $x$,那么你将收获 $b_i-|a_i-x|$ 点快乐值。
|
||||
|
||||
初始你可在任意位置,你每个单位时间可以移动不大于 $d$ 个单位距离。现在你需要最大化你能获得的快乐值。
|
||||
|
|
@ -38,7 +38,7 @@ $f_{i,j}=\max\{f_{i-1,k}+b_i-|a_i-j|\}=\max\{f_{i-1,k}-|a_i-j|\}+b_i$
|
|||
|
||||
## 单调队列优化多重背包
|
||||
|
||||
???+note "问题描述"
|
||||
???+ note "问题描述"
|
||||
你有 $n$ 个物品,每个物品重量为 $w_i$,价值为 $v_i$,数量为 $k_i$。你有一个承重上限为 $m$ 的背包,现在要求你在不超过重量上限的情况下选取价值和尽可能大的物品放入背包。求最大价值。
|
||||
|
||||
不了解背包 DP 的请先阅读 [背包 DP](../knapsack.md)。设 $f_{i,j}$ 表示前 $i$ 个物品装入承重为 $j$ 的背包的最大价值,朴素的转移方程为
|
||||
|
|
@ -65,6 +65,6 @@ $$
|
|||
|
||||
## 习题
|
||||
|
||||
- [「Luogu P1886」滑动窗口](https://loj.ac/problem/10175)
|
||||
- [「NOI2005」瑰丽华尔兹](https://www.luogu.com.cn/problem/P2254)
|
||||
- [「SCOI2010」股票交易](https://loj.ac/problem/10183)
|
||||
- [「Luogu P1886」滑动窗口](https://loj.ac/problem/10175)
|
||||
- [「NOI2005」瑰丽华尔兹](https://www.luogu.com.cn/problem/P2254)
|
||||
- [「SCOI2010」股票交易](https://loj.ac/problem/10183)
|
||||
|
|
|
|||
|
|
@ -10,8 +10,8 @@ $$
|
|||
|
||||
直接简单实现状态转移,总时间复杂度将会达到 $O(n^3)$,但当函数 $w(l,r)$ 满足一些特殊的性质时,我们可以利用决策的单调性进行优化。
|
||||
|
||||
- **区间包含单调性**:如果对于任意 $l \leq l' \leq r' \leq r$,均有 $w(l',r') \leq w(l,r)$ 成立,则称函数 $w$ 对于区间包含关系具有单调性。
|
||||
- **四边形不等式**:如果对于任意 $l_1\leq l_2 \leq r_1 \leq r_2$,均有 $w(l_1,r_1)+w(l_2,r_2) \leq w(l_1,r_2) + w(l_2,r_1)$ 成立,则称函数 $w$ 满足四边形不等式(简记为“交叉小于包含”)。若等号永远成立,则称函数 $w$ 满足 **四边形恒等式**。
|
||||
- **区间包含单调性**:如果对于任意 $l \leq l' \leq r' \leq r$,均有 $w(l',r') \leq w(l,r)$ 成立,则称函数 $w$ 对于区间包含关系具有单调性。
|
||||
- **四边形不等式**:如果对于任意 $l_1\leq l_2 \leq r_1 \leq r_2$,均有 $w(l_1,r_1)+w(l_2,r_2) \leq w(l_1,r_2) + w(l_2,r_1)$ 成立,则称函数 $w$ 满足四边形不等式(简记为“交叉小于包含”)。若等号永远成立,则称函数 $w$ 满足 **四边形恒等式**。
|
||||
|
||||
**引理 1**:若 $w(l, r)$ 满足区间包含单调性和四边形不等式,则状态 $f_{l,r}$ 满足四边形不等式。
|
||||
|
||||
|
|
@ -143,7 +143,7 @@ $$
|
|||
\sum_{1\leq l<r\leq n} m_{l+1,r} - m_{l,r-1} = \sum_{i=1}^n m_{i,n} - m_{1,i}\leq n^2
|
||||
$$
|
||||
|
||||
???+note "核心代码"
|
||||
???+ note "核心代码"
|
||||
=== "C++"
|
||||
|
||||
```cpp
|
||||
|
|
@ -261,7 +261,7 @@ $$
|
|||
|
||||
在这种情况下,我们定义过程 $\textsf{DP}(l, r, k_l, k_r)$ 表示求解 $f_{l}\sim f_{r}$ 的状态值,并且已知这些状态的最优决策点必定位于 $[k_l, k_r]$ 中,然后使用分治算法如下:
|
||||
|
||||
???+note "代码实现"
|
||||
???+ note "代码实现"
|
||||
=== "C++"
|
||||
|
||||
```cpp
|
||||
|
|
@ -299,7 +299,7 @@ $$
|
|||
|
||||
### [「POI2011」Lightning Conductor](https://loj.ac/problem/2157)
|
||||
|
||||
???+note "题目大意"
|
||||
???+ note "题目大意"
|
||||
给定一个长度为 $n$($n\leq 5\times 10^5$)的序列 $a_1, a_2, \cdots, a_n$,要求对于每一个 $1 \leq r \leq n$,找到最小的非负整数 $f_r$ 满足
|
||||
|
||||
$$
|
||||
|
|
@ -370,7 +370,7 @@ $$
|
|||
|
||||
### [「HNOI2008」玩具装箱 toy](https://loj.ac/problem/10188)
|
||||
|
||||
???+note "题目大意"
|
||||
???+ note "题目大意"
|
||||
有 $n$ 个玩具需要装箱,要求每个箱子中的玩具编号必须是连续的。每个玩具有一个长度 $C_i$,如果一个箱子中有多个玩具,那么每两个玩具之间要加入一个单位长度的分隔物。形式化地说,如果将编号在 $[l,r]$ 间的玩具装在一个箱子里,那么这个箱子的长度为 $r-l+\sum_{k=l}^r C_k$。现在需要制定一个装箱方案,使得所有容器的长度与 $K$ 差值的平方之和最小。
|
||||
|
||||
设 $f_{r}$ 表示将前 $r$ 个玩具装箱的最小代价,则枚举第 $r$ 个玩具与哪些玩具放在一个箱子中,可以得到状态转移方程为
|
||||
|
|
@ -383,19 +383,19 @@ $$
|
|||
|
||||
## 习题
|
||||
|
||||
- [「IOI2000」邮局](https://www.luogu.com.cn/problem/P4767)
|
||||
- [Codeforces - Ciel and Gondolas](https://codeforces.com/contest/321/problem/E)(Be careful with I/O!)
|
||||
- [SPOJ - LARMY](https://www.spoj.com/problems/LARMY/)
|
||||
- [Codechef - CHEFAOR](https://www.codechef.com/problems/CHEFAOR)
|
||||
- [Hackerrank - Guardians of the Lunatics](https://www.hackerrank.com/contests/ioi-2014-practice-contest-2/challenges/guardians-lunatics-ioi14)
|
||||
- [ACM ICPC World Finals 2017 - Money](https://open.kattis.com/problems/money)
|
||||
- [「IOI2000」邮局](https://www.luogu.com.cn/problem/P4767)
|
||||
- [Codeforces - Ciel and Gondolas](https://codeforces.com/contest/321/problem/E)(Be careful with I/O!)
|
||||
- [SPOJ - LARMY](https://www.spoj.com/problems/LARMY/)
|
||||
- [Codechef - CHEFAOR](https://www.codechef.com/problems/CHEFAOR)
|
||||
- [Hackerrank - Guardians of the Lunatics](https://www.hackerrank.com/contests/ioi-2014-practice-contest-2/challenges/guardians-lunatics-ioi14)
|
||||
- [ACM ICPC World Finals 2017 - Money](https://open.kattis.com/problems/money)
|
||||
|
||||
## 参考资料
|
||||
|
||||
- [noiau 的 CSDN 博客](https://blog.csdn.net/noiau/article/details/72514812)
|
||||
- [Quora Answer by Michael Levin](https://www.quora.com/What-is-divide-and-conquer-optimization-in-dynamic-programming)
|
||||
- [Video Tutorial by "Sothe" the Algorithm Wolf](https://www.youtube.com/watch?v=wLXEWuDWnzI)
|
||||
- [noiau 的 CSDN 博客](https://blog.csdn.net/noiau/article/details/72514812)
|
||||
- [Quora Answer by Michael Levin](https://www.quora.com/What-is-divide-and-conquer-optimization-in-dynamic-programming)
|
||||
- [Video Tutorial by "Sothe" the Algorithm Wolf](https://www.youtube.com/watch?v=wLXEWuDWnzI)
|
||||
|
||||
* * *
|
||||
***
|
||||
|
||||
**本页面主要译自英文版博文 [Divide and Conquer DP](https://cp-algorithms.com/dynamic_programming/divide-and-conquer-dp.html)。版权协议为 CC-BY-SA 4.0。**
|
||||
|
|
|
|||
|
|
@ -2,7 +2,7 @@ author: Marcythm, hsfzLZH1, abc1763613206, greyqz, Ir1d, billchenchina, Chrogeek
|
|||
|
||||
## 例题引入
|
||||
|
||||
???+note "[「HNOI2008」玩具装箱](https://loj.ac/problem/10188)"
|
||||
???+ note "[「HNOI2008」玩具装箱](https://loj.ac/problem/10188)"
|
||||
有 $n$ 个玩具,第 $i$ 个玩具价值为 $c_i$。要求将这 $n$ 个玩具排成一排,分成若干段。对于一段 $[l,r]$,它的代价为 $(r-l+\sum_{i=l}^r c_i-L)^2$。其中 $L$ 是一个常量,求分段的最小代价。
|
||||
|
||||
$1\le n\le 5\times 10^4, 1\le L, c_i\le 10^7$。
|
||||
|
|
@ -40,7 +40,7 @@ $$
|
|||
|
||||
则转移方程就写作 $b_i = \min_{j<i}\{ y_j-k_ix_j \}$。我们把 $(x_j,y_j)$ 看作二维平面上的点,则 $k_i$ 表示直线斜率,$b_i$ 表示一条过 $(x_j,y_j)$ 的斜率为 $k_i$ 的直线的截距。问题转化为了,选择合适的 $j$($1\le j<i$),最小化直线的截距。
|
||||
|
||||

|
||||

|
||||
|
||||
如图,我们将这个斜率为 $k_i$ 的直线从下往上平移,直到有一个点 $(x_p,y_p)$ 在这条直线上,则有 $b_i=y_p-k_ix_p$,这时 $b_i$ 取到最小值。算完 $f_i$,我们就把 $(x_i,y_i)$ 这个点加入点集中,以做为新的 DP 决策。那么,我们该如何维护点集?
|
||||
|
||||
|
|
@ -56,9 +56,9 @@ $$
|
|||
|
||||
概括一下上述斜率优化模板题的算法:
|
||||
|
||||
1. 将初始状态入队。
|
||||
2. 每次使用一条和 $i$ 相关的直线 $f(i)$ 去切维护的凸包,找到最优决策,更新 $dp_i$。
|
||||
3. 加入状态 $dp_i$。如果一个状态(即凸包上的一个点)在 $dp_i$ 加入后不再是凸包上的点,需要在 $dp_i$ 加入前将其剔除。
|
||||
1. 将初始状态入队。
|
||||
2. 每次使用一条和 $i$ 相关的直线 $f(i)$ 去切维护的凸包,找到最优决策,更新 $dp_i$。
|
||||
3. 加入状态 $dp_i$。如果一个状态(即凸包上的一个点)在 $dp_i$ 加入后不再是凸包上的点,需要在 $dp_i$ 加入前将其剔除。
|
||||
|
||||
接下来我们介绍斜率优化的进阶应用,将斜率优化与二分/分治/数据结构等结合,来维护性质不那么好(缺少一些单调性性质)的 DP 方程。
|
||||
|
||||
|
|
@ -68,7 +68,7 @@ $$
|
|||
|
||||
在上述例题中,直线的斜率随 $i$ 单调变化,但是对于有些问题,斜率并不是单调的。这时我们需要维护凸包上的每一个节点,然后每次用当前的直线去切这个凸包。这个过程可以使用二分解决,因为凸包上相邻两个点的斜率是有单调性的。
|
||||
|
||||
???+note "玩具装箱 改"
|
||||
???+ note "玩具装箱 改"
|
||||
有 $n$ 个玩具,第 $i$ 个玩具价值为 $c_i$。要求将这 $n$ 个玩具排成一排,分成若干段。对于一段 $[l,r]$,它的代价为 $(r-l+\sum_{i=l}^r c_i-L)^2$。其中 $L$ 是一个常量,求分段的最小代价。
|
||||
|
||||
$1\le n\le 5\times 10^4,1\le L\le 10^7,-10^7\le c_i\le 10^7$。
|
||||
|
|
@ -87,8 +87,8 @@ $$
|
|||
|
||||
然而这时有两个条件不成立了:
|
||||
|
||||
1. 直线的斜率不再单调;
|
||||
2. 每次加入的决策点的横坐标不再单调。
|
||||
1. 直线的斜率不再单调;
|
||||
2. 每次加入的决策点的横坐标不再单调。
|
||||
|
||||
仍然考虑凸壳的维护。
|
||||
|
||||
|
|
@ -102,16 +102,16 @@ $$
|
|||
|
||||
设 $\text{CDQ}(l,r)$ 代表计算 $f_i,i\in [l,r]$。考虑 $\text{CDQ}(1,n)$:
|
||||
|
||||
- 我们先调用 $\text{CDQ}(1,mid)$ 算出 $f_i,i\in[1,mid]$。然后我们对 $[1,mid]$ 这个区间内的决策点建凸壳,然后使用这个凸壳去更新 $f_i,i\in [mid+1,n]$。这时我们决策点集是固定的,不像之前那样边计算 DP 值边加入决策点,那么我们就可以把 $i \in [mid+1,n]$ 的 $f_i$ 先按照直线的斜率 $k_i$ 排序,然后就可以使用单调队列来计算 DP 值了。当然,也可以在静态凸壳上二分计算 DP 值。
|
||||
- 我们先调用 $\text{CDQ}(1,mid)$ 算出 $f_i,i\in[1,mid]$。然后我们对 $[1,mid]$ 这个区间内的决策点建凸壳,然后使用这个凸壳去更新 $f_i,i\in [mid+1,n]$。这时我们决策点集是固定的,不像之前那样边计算 DP 值边加入决策点,那么我们就可以把 $i \in [mid+1,n]$ 的 $f_i$ 先按照直线的斜率 $k_i$ 排序,然后就可以使用单调队列来计算 DP 值了。当然,也可以在静态凸壳上二分计算 DP 值。
|
||||
|
||||
- 对于 $[mid+1,n]$ 中的每个点,如果它的最优决策的位置是在 $[1,mid]$ 这个区间,在这一步操作中他就会被更新成最优答案。当执行完这一步操作时,我们发现 $[1,mid]$ 中的所有点已经发挥了全部的作用,凸壳中他们存不存在已经不影响之后的答案更新。因此我们可以直接舍弃这个区间的决策点,并使用 $\text{CDQ}(mid+1,n)$ 解决右区间剩下的问题。
|
||||
- 对于 $[mid+1,n]$ 中的每个点,如果它的最优决策的位置是在 $[1,mid]$ 这个区间,在这一步操作中他就会被更新成最优答案。当执行完这一步操作时,我们发现 $[1,mid]$ 中的所有点已经发挥了全部的作用,凸壳中他们存不存在已经不影响之后的答案更新。因此我们可以直接舍弃这个区间的决策点,并使用 $\text{CDQ}(mid+1,n)$ 解决右区间剩下的问题。
|
||||
|
||||
时间复杂度 $O(n\log^2 n)$。
|
||||
|
||||
对比「玩具装箱」和「玩具装箱 改」,可以总结出以下两点:
|
||||
|
||||
- 二分/CDQ/平衡树等能够优化 DP 方程的计算,于一定程度上降低复杂度,但不能改变这个方程本身。
|
||||
- DP 方程的性质会取决于数据的特征,但 DP 方程本身取决于题目中的数学模型。
|
||||
- 二分/CDQ/平衡树等能够优化 DP 方程的计算,于一定程度上降低复杂度,但不能改变这个方程本身。
|
||||
- DP 方程的性质会取决于数据的特征,但 DP 方程本身取决于题目中的数学模型。
|
||||
|
||||
## 小结
|
||||
|
||||
|
|
@ -119,12 +119,12 @@ $$
|
|||
|
||||
## 习题
|
||||
|
||||
- [「SDOI2016」征途](https://loj.ac/problem/2035)
|
||||
- [「ZJOI2007」仓库建设](https://loj.ac/problem/10189)
|
||||
- [「APIO2010」特别行动队](https://loj.ac/problem/10190)
|
||||
- [「JSOI2011」柠檬](https://www.luogu.com.cn/problem/P5504)
|
||||
- [「Codeforces 311B」Cats Transport](http://codeforces.com/problemset/problem/311/B)
|
||||
- [「NOI2007」货币兑换](https://loj.ac/problem/2353)
|
||||
- [「NOI2019」回家路线](https://loj.ac/problem/3156)
|
||||
- [「NOI2016」国王饮水记](https://uoj.ac/problem/223)
|
||||
- [「NOI2014」购票](https://uoj.ac/problem/7)
|
||||
- [「SDOI2016」征途](https://loj.ac/problem/2035)
|
||||
- [「ZJOI2007」仓库建设](https://loj.ac/problem/10189)
|
||||
- [「APIO2010」特别行动队](https://loj.ac/problem/10190)
|
||||
- [「JSOI2011」柠檬](https://www.luogu.com.cn/problem/P5504)
|
||||
- [「Codeforces 311B」Cats Transport](http://codeforces.com/problemset/problem/311/B)
|
||||
- [「NOI2007」货币兑换](https://loj.ac/problem/2353)
|
||||
- [「NOI2019」回家路线](https://loj.ac/problem/3156)
|
||||
- [「NOI2016」国王饮水记](https://uoj.ac/problem/223)
|
||||
- [「NOI2014」购票](https://uoj.ac/problem/7)
|
||||
|
|
|
|||
|
|
@ -8,7 +8,7 @@ author: Marcythm, partychicken, Xeonacid
|
|||
|
||||
## 例 1
|
||||
|
||||
???+note "题面"
|
||||
???+ note "题面"
|
||||
给定两个长度分别为 $n,m$ 且仅由小写字母构成的字符串 $A,B$, 求 $A,B$ 的最长公共子序列。$(n\le 10^6,m\le 10^3)$
|
||||
|
||||
### 朴素的解法
|
||||
|
|
@ -41,7 +41,7 @@ $$
|
|||
|
||||
## 例 2
|
||||
|
||||
???+note "题面"
|
||||
???+ note "题面"
|
||||
给定一个 $n$ 个点的无权有向图,判断该图是否存在哈密顿回路。$(2\le n\le 20)$
|
||||
|
||||
### 朴素的解法
|
||||
|
|
|
|||
|
|
@ -8,7 +8,7 @@
|
|||
|
||||
温故而知新,在开始学习插头 DP 之前,不妨先让我们回顾一个经典问题。
|
||||
|
||||
???+note " 例题 [「HDU 1400」Mondriaan’s Dream](https://vjudge.net/problem/HDU-1400)"
|
||||
???+ note " 例题 [「HDU 1400」Mondriaan’s Dream](https://vjudge.net/problem/HDU-1400)"
|
||||
题目大意:在 $N\times M$ 的棋盘内铺满 $1\times 2$ 或 $2\times 1$ 的多米诺骨牌,求方案数。
|
||||
|
||||
当 $n$ 或 $m$ 规模不大的时候,这类问题可以使用 [状压 DP](./state.md) 解决。逐行划分阶段,设 $dp(i,s)$ 表示当前已考虑过前 $i$ 行,且第 $i$ 行的状态为 $s$ 的方案数。这里的状态 $s$ 的每一位可以表示这个这个位置是否已被上一行覆盖。
|
||||
|
|
@ -88,7 +88,7 @@ if (s >> j & 1) { // 如果已被覆盖
|
|||
|
||||
#### 例题
|
||||
|
||||
???+note " 例题 [「HDU 1693」Eat the Trees](https://vjudge.net/problem/HDU-1693)"
|
||||
???+ note " 例题 [「HDU 1693」Eat the Trees](https://vjudge.net/problem/HDU-1693)"
|
||||
题目大意:求用若干条回路覆盖 $N\times M$ 棋盘的方案数,有些位置有障碍。
|
||||
|
||||
严格来说,多条回路问题并不属于插头 DP,因为我们只需要和上面的骨牌覆盖问题一样,记录插头是否存在,然后成对的合并和生成插头就可以了。
|
||||
|
|
@ -109,7 +109,7 @@ if (s >> j & 1) { // 如果已被覆盖
|
|||
|
||||
#### 例题
|
||||
|
||||
???+note " 例题 [「Andrew Stankevich Contest 16 - Problem F」Pipe Layout](https://codeforces.com/gym/100220)"
|
||||
???+ note " 例题 [「Andrew Stankevich Contest 16 - Problem F」Pipe Layout](https://codeforces.com/gym/100220)"
|
||||
题目大意:求用一条回路覆盖 $N\times M$ 棋盘的方案数。
|
||||
|
||||
在上面的状态表示中我们每合并一组连通的插头,就会生成一条独立的回路,因而在本题中,我们还需要区分插头之间的连通性(出现了!)。这需要我们对状态进行额外的编码。
|
||||
|
|
@ -120,8 +120,8 @@ if (s >> j & 1) { // 如果已被覆盖
|
|||
|
||||
那么下面两组编码方式表示的是相同的状态:
|
||||
|
||||
- `0 3 1 0 1 3`
|
||||
- `0 1 2 0 2 1`
|
||||
- `0 3 1 0 1 3`
|
||||
- `0 1 2 0 2 1`
|
||||
|
||||
我们将相同的状态都映射成字典序最小表示,例如在上例中的 `0 1 2 0 2 1` 就是一组最小表示。
|
||||
|
||||
|
|
@ -157,9 +157,9 @@ if (s >> j & 1) { // 如果已被覆盖
|
|||
|
||||
#### 手写哈希
|
||||
|
||||
在一些 [状压 DP](./state.md) 的问题中,合法的状态可能是稀疏的(例如本题),为了优化时空复杂度,我们可以使用哈希表存储合法的 DP 状态。对于 C++ 选手,我们可以使用 [std::unordered_map](http://www.cplusplus.com/reference/unordered_map/unordered_map/),当然也可以直接手写,这样可以灵活的将状态转移函数也封装于其中。
|
||||
在一些 [状压 DP](./state.md) 的问题中,合法的状态可能是稀疏的(例如本题),为了优化时空复杂度,我们可以使用哈希表存储合法的 DP 状态。对于 C++ 选手,我们可以使用 [std::unordered\_map](http://www.cplusplus.com/reference/unordered_map/unordered_map/),当然也可以直接手写,这样可以灵活的将状态转移函数也封装于其中。
|
||||
|
||||
???+note "代码实现"
|
||||
???+ note "代码实现"
|
||||
```cpp
|
||||
const int MaxSZ = 16796, Prime = 9973;
|
||||
|
||||
|
|
@ -192,21 +192,21 @@ if (s >> j & 1) { // 如果已被覆盖
|
|||
|
||||
上面的代码中:
|
||||
|
||||
- `MaxSZ` 表示合法状态的上界,可以估计,也可以预处理出较为精确的值。
|
||||
- `Prime` 一个小于 `MaxSZ` 的大素数。
|
||||
- `head[]` 表头节点的指针。
|
||||
- `next[]` 后续状态的指针。
|
||||
- `state[]` 节点的状态。
|
||||
- `key[]` 节点的关键字,在本题中是方案数。
|
||||
- `clear()` 初始化函数,和手写邻接表类似,我们只需要初始化表头节点的指针。
|
||||
- `push()` 状态转移函数,其中 `d` 是一个全局变量(偷懒),表示每次状态转移所带来的增量。如果找到的话就 `+=`,否则就创建一个状态为 `s`,关键字为 `d` 的新节点。
|
||||
- `roll()` 迭代完一整行之后,滚动轮廓线。
|
||||
- `MaxSZ` 表示合法状态的上界,可以估计,也可以预处理出较为精确的值。
|
||||
- `Prime` 一个小于 `MaxSZ` 的大素数。
|
||||
- `head[]` 表头节点的指针。
|
||||
- `next[]` 后续状态的指针。
|
||||
- `state[]` 节点的状态。
|
||||
- `key[]` 节点的关键字,在本题中是方案数。
|
||||
- `clear()` 初始化函数,和手写邻接表类似,我们只需要初始化表头节点的指针。
|
||||
- `push()` 状态转移函数,其中 `d` 是一个全局变量(偷懒),表示每次状态转移所带来的增量。如果找到的话就 `+=`,否则就创建一个状态为 `s`,关键字为 `d` 的新节点。
|
||||
- `roll()` 迭代完一整行之后,滚动轮廓线。
|
||||
|
||||
关于哈希表的复杂度分析,以及开哈希和闭哈希的不同,可以参见 [《算法导论》](../contest/resources.md#书籍) 中关于散列表的相关章节。
|
||||
|
||||
#### 状态转移
|
||||
|
||||
???+note "代码实现"
|
||||
???+ note "代码实现"
|
||||
```cpp
|
||||
REP(ii, H0->sz) {
|
||||
decode(H0->state[ii]); // 取出状态,并解码
|
||||
|
|
@ -265,7 +265,7 @@ if (s >> j & 1) { // 如果已被覆盖
|
|||
|
||||
#### 例题
|
||||
|
||||
???+note " 例题 [「ZOJ 3213」Beautiful Meadow](https://vjudge.net/problem/ZOJ-3213)"
|
||||
???+ note " 例题 [「ZOJ 3213」Beautiful Meadow](https://vjudge.net/problem/ZOJ-3213)"
|
||||
题目大意:一个 $N\times M$ 的方阵($N,M\le 8$),每个格点有一个权值,求一段路径,最大化路径覆盖的格点的权值和。
|
||||
|
||||
本题是标准的一条路径问题,在一条路径问题中,编码的状态中还会存在不能配对的独立插头。需要在状态转移函数中,额外讨论独立插头的生成、合并与消失的情况。独立插头的生成和消失对应着路径的一端,因而这类事件不会发生超过两次(一次生成一次消失,或者两次生成一次合并),否则最终结果一定会出现多个连通块。
|
||||
|
|
@ -274,7 +274,7 @@ if (s >> j & 1) { // 如果已被覆盖
|
|||
|
||||
#### 状态转移
|
||||
|
||||
???+note "代码实现"
|
||||
???+ note "代码实现"
|
||||
```cpp
|
||||
REP(i, n) {
|
||||
REP(j, m) {
|
||||
|
|
@ -338,10 +338,10 @@ if (s >> j & 1) { // 如果已被覆盖
|
|||
#### 习题
|
||||
|
||||
??? note " 习题 [「NOI 2010 Day2」旅行路线](https://www.luogu.com.cn/problem/P1933)"
|
||||
题目大意:$n\times m$ 的棋盘,棋盘的每个格子有一个 01 权值 T[x][y],要求寻找一个路径覆盖,满足:
|
||||
题目大意:$n\times m$ 的棋盘,棋盘的每个格子有一个 01 权值 T\[x]\[y],要求寻找一个路径覆盖,满足:
|
||||
|
||||
- 第 i 个参观的格点 (x, y),满足 T[x][y]= L[i]
|
||||
- 路径的一端在棋盘的边界上
|
||||
- 第 i 个参观的格点 (x, y),满足 T\[x]\[y]= L\[i]
|
||||
- 路径的一端在棋盘的边界上
|
||||
|
||||
求可行的方案数。
|
||||
|
||||
|
|
@ -351,10 +351,10 @@ if (s >> j & 1) { // 如果已被覆盖
|
|||
|
||||
### 例题「UVA 10572」Black & White
|
||||
|
||||
???+note " 例题 [「UVA 10572」Black & White](https://vjudge.net/problem/UVA-10572)"
|
||||
???+ note " 例题 [「UVA 10572」Black & White](https://vjudge.net/problem/UVA-10572)"
|
||||
题目大意:在 $N\times M$ 的棋盘内对未染色的格点进行黑白染色,要求所有黑色区域和白色区域连通,且任意一个 $2\times 2$ 的子矩形内的颜色不能完全相同(例如下图中的情况非法),求合法的方案数,并构造一组合法的方案。
|
||||
|
||||

|
||||

|
||||
|
||||
### 状态编码
|
||||
|
||||
|
|
@ -368,7 +368,7 @@ if (s >> j & 1) { // 如果已被覆盖
|
|||
|
||||
在最多情况下(例如第一行黑白相间),每个插头的连通性信息都不一样,因此我们需要 $4$ 位二进制位记录连通性,再加上颜色信息,本题的 `Offset` 为 $5$ 位。
|
||||
|
||||
???+note "代码实现"
|
||||
???+ note "代码实现"
|
||||
```cpp
|
||||
const int Offset = 5, Mask = (1 << Offset) - 1;
|
||||
int c[N + 2];
|
||||
|
|
@ -402,7 +402,7 @@ if (s >> j & 1) { // 如果已被覆盖
|
|||
|
||||
因为需要构造任意一组方案,这里的哈希表我们需要添加一组域 `pre[]` 来记录每个状态在上一阶段的任意一个前驱。
|
||||
|
||||
???+note "代码实现"
|
||||
???+ note "代码实现"
|
||||
```cpp
|
||||
const int Prime = 9979, MaxSZ = 1 << 20;
|
||||
|
||||
|
|
@ -441,7 +441,7 @@ if (s >> j & 1) { // 如果已被覆盖
|
|||
|
||||
有了上面的信息,我们就可以容易的构造方案了。首先遍历当前哈希表中的状态,如果连通块数目不超过 $2$,那么统计进方案数。如果方案数不为 $0$,我们倒序用 `pre` 数组构造出方案,注意每一行的末尾因为我们执行了 `Roll()` 操作,颜色需要取 `c[j+1]`。
|
||||
|
||||
???+note "代码实现"
|
||||
???+ note "代码实现"
|
||||
```cpp
|
||||
void print() {
|
||||
T_key z = 0;
|
||||
|
|
@ -474,14 +474,14 @@ if (s >> j & 1) { // 如果已被覆盖
|
|||
|
||||
我们记:
|
||||
|
||||
- `cc` 当前正在染色的格子的颜色
|
||||
- `lf` 左边格子的颜色
|
||||
- `up` 上边格子的颜色
|
||||
- `lu` 左上格子的颜色
|
||||
- `cc` 当前正在染色的格子的颜色
|
||||
- `lf` 左边格子的颜色
|
||||
- `up` 上边格子的颜色
|
||||
- `lu` 左上格子的颜色
|
||||
|
||||
我们用 $-1$ 表示颜色不存在。接下来讨论状态转移,一共有三种情况,合并,继承与生成:
|
||||
|
||||
???+note "状态转移-代码"
|
||||
???+ note "状态转移 - 代码"
|
||||
```cpp
|
||||
void trans(int i, int j, int u, int cc) {
|
||||
decode(H0->state[u]);
|
||||
|
|
@ -509,7 +509,7 @@ if (s >> j & 1) { // 如果已被覆盖
|
|||
|
||||
对于最后一种情况需要注意的是,如果已经生成了一个封闭的连通区域,那么我们不能再使用她的颜色染色,否则这种颜色会出现两个连通块。我们似乎需要额度记录这种事件,可以参考 [「ZOJ 3213」Beautiful Meadow](#例题_2) 中的做法,再开一维记录这个事件。不过利用本题的特殊性,我们也可以特判掉。
|
||||
|
||||
???+note "特判-代码"
|
||||
???+ note "特判 - 代码"
|
||||
```cpp
|
||||
bool ok(int i, int j, int cc) {
|
||||
if (cc == c[j + 1]) return true;
|
||||
|
|
@ -554,12 +554,12 @@ if (s >> j & 1) { // 如果已被覆盖
|
|||
|
||||
## 图论模型
|
||||
|
||||
???+note " 例题 [「NOI 2007 Day2」生成树计数](https://www.luogu.com.cn/problem/P2109)"
|
||||
???+ note " 例题 [「NOI 2007 Day2」生成树计数](https://www.luogu.com.cn/problem/P2109)"
|
||||
题目大意:某类特殊图的生成树计数,每个节点恰好与其前 $k$ 个节点之间有边相连。
|
||||
|
||||
???+note " 例题 [「2015 ACM-ICPC Asia Shenyang Regional Contest - Problem E」Efficient Tree](https://vjudge.net/problem/HDU-5513)"
|
||||
???+ note " 例题 [「2015 ACM-ICPC Asia Shenyang Regional Contest - Problem E」Efficient Tree](https://vjudge.net/problem/HDU-5513)"
|
||||
题目大意:给出一个 $N\times M$ 的网格图,以及相邻四连通格子之间的边权。
|
||||
对于一颗生成树,每个节点的得分为 1+[有一条连向上的边]+[有一条连向左的边]。
|
||||
对于一颗生成树,每个节点的得分为 1+\[有一条连向上的边]+\[有一条连向左的边]。
|
||||
生成树的得分为所有节点的得分之积。
|
||||
|
||||
你需要求出:最小生成树的边权和,以及所有最小生成树的得分之和。
|
||||
|
|
@ -569,7 +569,7 @@ if (s >> j & 1) { // 如果已被覆盖
|
|||
|
||||
### 例题
|
||||
|
||||
???+note " 例题 [「HDU 4113」Construct the Great Wall](https://vjudge.net/problem/HDU-4113)"
|
||||
???+ note " 例题 [「HDU 4113」Construct the Great Wall](https://vjudge.net/problem/HDU-4113)"
|
||||
题目大意:在 $N\times M$ 的棋盘内构造一组回路,分割所有的 `x` 和 `o`。
|
||||
|
||||
有一类插头 DP 问题要求我们在棋盘上构造一组墙,以分割棋盘上的某些元素。不妨称之为修墙问题,这类问题既可视作染色模型,也可视作路径模型。
|
||||
|
|
@ -754,9 +754,9 @@ if (s >> j & 1) { // 如果已被覆盖
|
|||
??? note " 习题 [「World Finals 2009/2010 Harbin」Channel](https://vjudge.net/problem/UVALive-4789)"
|
||||
题目大意:一张方格地图上用 `.` 表示空地、`#` 表示石头,找到最长的一条路径满足:
|
||||
|
||||
1. 起点在左上角,终点在右下角。
|
||||
2. 不能经过石头。
|
||||
3. 路径自身不能在八连通的意义下成环。(即包括拐角处也不能接触)
|
||||
1. 起点在左上角,终点在右下角。
|
||||
2. 不能经过石头。
|
||||
3. 路径自身不能在八连通的意义下成环。(即包括拐角处也不能接触)
|
||||
|
||||
??? note " 习题 [「HDU 3958」Tower Defence](https://vjudge.net/problem/HDU-3958)"
|
||||
题目大意:可以转化为求解一条从 $\mathit{S}$ 到 $\mathit{T}$ 的不能接触的最长路径,拐角处可以接触。
|
||||
|
|
@ -779,8 +779,8 @@ if (s >> j & 1) { // 如果已被覆盖
|
|||
|
||||
插头 DP 问题通常编码难度较大,讨论复杂,因而属于 OI/ACM 中相对较为 [偏门的领域](https://github.com/OI-wiki/libs/blob/master/topic/7-%E7%8E%8B%E5%A4%A9%E6%87%BF-%E8%AE%BA%E5%81%8F%E9%A2%98%E7%9A%84%E5%8D%B1%E5%AE%B3.ppt)。这方面最为经典的资料,当属 2008 年 [陈丹琦](https://www.cs.princeton.edu/~danqic/) 的集训队论文——[基于连通性状态压缩的动态规划问题](https://github.com/AngelKitty/review_the_national_post-graduate_entrance_examination/tree/master/books_and_notes/professional_courses/data_structures_and_algorithms/sources/%E5%9B%BD%E5%AE%B6%E9%9B%86%E8%AE%AD%E9%98%9F%E8%AE%BA%E6%96%87/%E5%9B%BD%E5%AE%B6%E9%9B%86%E8%AE%AD%E9%98%9F2008%E8%AE%BA%E6%96%87%E9%9B%86/%E9%99%88%E4%B8%B9%E7%90%A6%E3%80%8A%E5%9F%BA%E4%BA%8E%E8%BF%9E%E9%80%9A%E6%80%A7%E7%8A%B6%E6%80%81%E5%8E%8B%E7%BC%A9%E7%9A%84%E5%8A%A8%E6%80%81%E8%A7%84%E5%88%92%E9%97%AE%E9%A2%98%E3%80%8B)。其次,HDU 的 notonlysuccess 2011 年曾经在博客中连续写过两篇由浅入深的专题,也是不可多得的好资料,不过现在需要在 Web Archive 里考古。
|
||||
|
||||
- [notonlysuccess,【专辑】插头 DP](https://web.archive.org/web/20110815044829/http://www.notonlysuccess.com/?p=625)
|
||||
- [notonlysuccess,【完全版】插头 DP](https://web.archive.org/web/20111007185146/http://www.notonlysuccess.com/?p=931)
|
||||
- [notonlysuccess,【专辑】插头 DP](https://web.archive.org/web/20110815044829/http://www.notonlysuccess.com/?p=625)
|
||||
- [notonlysuccess,【完全版】插头 DP](https://web.archive.org/web/20111007185146/http://www.notonlysuccess.com/?p=931)
|
||||
|
||||
### 多米诺骨牌覆盖
|
||||
|
||||
|
|
@ -790,14 +790,14 @@ if (s >> j & 1) { // 如果已被覆盖
|
|||
|
||||
当 $m\le 10,n\le 10^9$ 时,可以将转移方程预处理成矩阵形式,并使用 [矩阵乘法进行加速](http://www.matrix67.com/blog/archives/276)。
|
||||
|
||||

|
||||

|
||||
|
||||
当 $n,m\le 100$,可以用 [FKT Algorithm](https://en.wikipedia.org/wiki/FKT_algorithm) 计算其所对应平面图的完美匹配数。
|
||||
|
||||
- [「51nod 1031」骨牌覆盖](http://www.51nod.com/Challenge/Problem.html#problemId=1031)
|
||||
- [「51nod 1033」骨牌覆盖 V2](http://www.51nod.com/Challenge/Problem.html#problemId=1033)\|[「Vijos 1194」Domino](https://vijos.org/p/1194)
|
||||
- [「51nod 1034」骨牌覆盖 V3](http://www.51nod.com/Challenge/Problem.html#problemId=1034)\|[「Ural 1594」Aztec Treasure](https://acm.timus.ru/problem.aspx?space=1&num=1594)
|
||||
- [Wolfram MathWorld, Chebyshev Polynomial of the Second Kind](https://mathworld.wolfram.com/ChebyshevPolynomialoftheSecondKind.html)
|
||||
- [「51nod 1031」骨牌覆盖](http://www.51nod.com/Challenge/Problem.html#problemId=1031)
|
||||
- [「51nod 1033」骨牌覆盖 V2](http://www.51nod.com/Challenge/Problem.html#problemId=1033)|[「Vijos 1194」Domino](https://vijos.org/p/1194)
|
||||
- [「51nod 1034」骨牌覆盖 V3](http://www.51nod.com/Challenge/Problem.html#problemId=1034)|[「Ural 1594」Aztec Treasure](https://acm.timus.ru/problem.aspx?space=1&num=1594)
|
||||
- [Wolfram MathWorld, Chebyshev Polynomial of the Second Kind](https://mathworld.wolfram.com/ChebyshevPolynomialoftheSecondKind.html)
|
||||
|
||||
### 一条路径
|
||||
|
||||
|
|
@ -805,4 +805,4 @@ if (s >> j & 1) { // 如果已被覆盖
|
|||
|
||||

|
||||
|
||||
- [【动画】从方格这头走向那头有多少种走法呢~【结尾迷之感动】](https://www.bilibili.com/video/BV1Cx411D74e)\|[Youtube](https://www.youtube.com/watch?v=Q4gTV4r0zRs)
|
||||
- [【动画】从方格这头走向那头有多少种走法呢~【结尾迷之感动】](https://www.bilibili.com/video/BV1Cx411D74e)|[Youtube](https://www.youtube.com/watch?v=Q4gTV4r0zRs)
|
||||
|
|
|
|||
|
|
@ -6,7 +6,7 @@
|
|||
|
||||
这类题目采用顺推,也就是从初始状态推向结果。同一般的 DP 类似的,难点依然是对状态转移方程的刻画,只是这类题目经过了概率论知识的包装。
|
||||
|
||||
???+note "例题 [Codeforces 148 D Bag of mice](https://codeforces.com/problemset/problem/148/D)"
|
||||
???+ note " 例题 [Codeforces 148 D Bag of mice](https://codeforces.com/problemset/problem/148/D)"
|
||||
题目大意:袋子里有 $w$ 只白鼠和 $b$ 只黑鼠,公主和龙轮流从袋子里抓老鼠。谁先抓到白色老鼠谁就赢,如果袋子里没有老鼠了并且没有谁抓到白色老鼠,那么算龙赢。公主每次抓一只老鼠,龙每次抓完一只老鼠之后会有一只老鼠跑出来。每次抓的老鼠和跑出来的老鼠都是随机的。公主先抓。问公主赢的概率。
|
||||
|
||||
### 过程
|
||||
|
|
@ -14,10 +14,10 @@
|
|||
设 $f_{i,j}$ 为轮到公主时袋子里有 $i$ 只白鼠,$j$ 只黑鼠,公主赢的概率。初始化边界,$f_{0,j}=0$ 因为没有白鼠了算龙赢,$f_{i,0}=1$ 因为抓一只就是白鼠,公主赢。
|
||||
考虑 $f_{i,j}$ 的转移:
|
||||
|
||||
- 公主抓到一只白鼠,公主赢了。概率为 $\frac{i}{i+j}$;
|
||||
- 公主抓到一只黑鼠,龙抓到一只白鼠,龙赢了。概率为 $\frac{j}{i+j}\cdot \frac{i}{i+j-1}$;
|
||||
- 公主抓到一只黑鼠,龙抓到一只黑鼠,跑出来一只黑鼠,转移到 $f_{i,j-3}$。概率为 $\frac{j}{i+j}\cdot\frac{j-1}{i+j-1}\cdot\frac{j-2}{i+j-2}$;
|
||||
- 公主抓到一只黑鼠,龙抓到一只黑鼠,跑出来一只白鼠,转移到 $f_{i-1,j-2}$。概率为 $\frac{j}{i+j}\cdot\frac{j-1}{i+j-1}\cdot\frac{i}{i+j-2}$;
|
||||
- 公主抓到一只白鼠,公主赢了。概率为 $\frac{i}{i+j}$;
|
||||
- 公主抓到一只黑鼠,龙抓到一只白鼠,龙赢了。概率为 $\frac{j}{i+j}\cdot \frac{i}{i+j-1}$;
|
||||
- 公主抓到一只黑鼠,龙抓到一只黑鼠,跑出来一只黑鼠,转移到 $f_{i,j-3}$。概率为 $\frac{j}{i+j}\cdot\frac{j-1}{i+j-1}\cdot\frac{j-2}{i+j-2}$;
|
||||
- 公主抓到一只黑鼠,龙抓到一只黑鼠,跑出来一只白鼠,转移到 $f_{i-1,j-2}$。概率为 $\frac{j}{i+j}\cdot\frac{j-1}{i+j-1}\cdot\frac{i}{i+j-2}$;
|
||||
|
||||
考虑公主赢的概率,第二种情况不参与计算。并且要保证后两种情况合法,所以还要判断 $i,j$ 的大小,满足第三种情况至少要有 3 只黑鼠,满足第四种情况要有 1 只白鼠和 2 只黑鼠。
|
||||
|
||||
|
|
@ -30,15 +30,15 @@
|
|||
|
||||
### 习题
|
||||
|
||||
- [CodeForces 148 D Bag of mice](https://codeforces.com/problemset/problem/148/D)
|
||||
- [POJ3071 Football](http://poj.org/problem?id=3071)
|
||||
- [CodeForces 768 D Jon and Orbs](https://codeforces.com/problemset/problem/768/D)
|
||||
- [CodeForces 148 D Bag of mice](https://codeforces.com/problemset/problem/148/D)
|
||||
- [POJ3071 Football](http://poj.org/problem?id=3071)
|
||||
- [CodeForces 768 D Jon and Orbs](https://codeforces.com/problemset/problem/768/D)
|
||||
|
||||
## DP 求期望
|
||||
|
||||
### 例一
|
||||
|
||||
???+note " 例题 [POJ2096 Collecting Bugs](http://poj.org/problem?id=2096)"
|
||||
???+ note " 例题 [POJ2096 Collecting Bugs](http://poj.org/problem?id=2096)"
|
||||
题目大意:一个软件有 $s$ 个子系统,会产生 $n$ 种 bug。某人一天发现一个 bug,这个 bug 属于某种 bug 分类,也属于某个子系统。每个 bug 属于某个子系统的概率是 $\frac{1}{s}$,属于某种 bug 分类的概率是 $\frac{1}{n}$。求发现 $n$ 种 bug,且 $s$ 个子系统都找到 bug 的期望天数。
|
||||
|
||||
#### 过程
|
||||
|
|
@ -47,10 +47,10 @@
|
|||
|
||||
考虑 $f_{i,j}$ 的状态转移:
|
||||
|
||||
- $f_{i,j}$,发现一个 bug 属于已经发现的 $i$ 种 bug 分类,$j$ 个子系统,概率为 $p_1=\frac{i}{n}\cdot\frac{j}{s}$
|
||||
- $f_{i,j+1}$,发现一个 bug 属于已经发现的 $i$ 种 bug 分类,不属于已经发现的子系统,概率为 $p_2=\frac{i}{n}\cdot(1-\frac{j}{s})$
|
||||
- $f_{i+1,j}$,发现一个 bug 不属于已经发现 bug 分类,属于 $j$ 个子系统,概率为 $p_3=(1-\frac{i}{n})\cdot\frac{j}{s}$
|
||||
- $f_{i+1,j+1}$,发现一个 bug 不属于已经发现 bug 分类,不属于已经发现的子系统,概率为 $p_4=(1-\frac{i}{n})\cdot(1-\frac{j}{s})$
|
||||
- $f_{i,j}$,发现一个 bug 属于已经发现的 $i$ 种 bug 分类,$j$ 个子系统,概率为 $p_1=\frac{i}{n}\cdot\frac{j}{s}$
|
||||
- $f_{i,j+1}$,发现一个 bug 属于已经发现的 $i$ 种 bug 分类,不属于已经发现的子系统,概率为 $p_2=\frac{i}{n}\cdot(1-\frac{j}{s})$
|
||||
- $f_{i+1,j}$,发现一个 bug 不属于已经发现 bug 分类,属于 $j$ 个子系统,概率为 $p_3=(1-\frac{i}{n})\cdot\frac{j}{s}$
|
||||
- $f_{i+1,j+1}$,发现一个 bug 不属于已经发现 bug 分类,不属于已经发现的子系统,概率为 $p_4=(1-\frac{i}{n})\cdot(1-\frac{j}{s})$
|
||||
|
||||
再根据期望的线性性质,就可以得到状态转移方程:
|
||||
|
||||
|
|
@ -70,7 +70,7 @@ $$
|
|||
|
||||
### 例二
|
||||
|
||||
???+note "例题 [「NOIP2016」换教室](http://uoj.ac/problem/262)"
|
||||
???+ note " 例题 [「NOIP2016」换教室](http://uoj.ac/problem/262)"
|
||||
题目大意:牛牛要上 $n$ 个时间段的课,第 $i$ 个时间段在 $c_i$ 号教室,可以申请换到 $d_i$ 号教室,申请成功的概率为 $p_i$,至多可以申请 $m$ 节课进行交换。第 $i$ 个时间段的课上完后要走到第 $i+1$ 个时间段的教室,给出一张图 $v$ 个教室 $e$ 条路,移动会消耗体力,申请哪几门课程可以使他因在教室间移动耗费的体力值的总和的期望值最小,也就是求出最小的期望路程和。
|
||||
|
||||
#### 过程
|
||||
|
|
@ -80,7 +80,7 @@ $$
|
|||
|
||||
考虑 $f_{i,j,0/1}$ 的状态转移:
|
||||
|
||||
- 如果这一阶段不换,即 $f_{i,j,0}$。可能是由上一次不换的状态转移来的,那么就是 $f_{i-1,j,0}+w_{c_{i-1},c_{i}}$, 也有可能是由上一次交换的状态转移来的,这里结合条件概率和全概率的知识分析可以得到 $f_{i-1,j,1}+w_{d_{i-1},c_{i}}\cdot p_{i-1}+w_{c_{i-1},c_{i}}\cdot (1-p_{i-1})$,状态转移方程就有
|
||||
- 如果这一阶段不换,即 $f_{i,j,0}$。可能是由上一次不换的状态转移来的,那么就是 $f_{i-1,j,0}+w_{c_{i-1},c_{i}}$, 也有可能是由上一次交换的状态转移来的,这里结合条件概率和全概率的知识分析可以得到 $f_{i-1,j,1}+w_{d_{i-1},c_{i}}\cdot p_{i-1}+w_{c_{i-1},c_{i}}\cdot (1-p_{i-1})$,状态转移方程就有
|
||||
|
||||
$$
|
||||
\begin{aligned}
|
||||
|
|
@ -88,7 +88,7 @@ f_{i,j,0}=min(f_{i-1,j,0}+w_{c_{i-1},c_{i}},f_{i-1,j,1}+w_{d_{i-1},c_{i}}\cdot p
|
|||
\end{aligned}
|
||||
$$
|
||||
|
||||
- 如果这一阶段交换,即 $f_{i,j,1}$。类似地,可能由上一次不换的状态转移来,也可能由上一次交换的状态转移来。那么遇到不换的就乘上 $(1-p_i)$,遇到交换的就乘上 $p_i$,将所有会出现的情况都枚举一遍出进行计算就好了。这里不再赘述各种转移情况,相信通过上一种阶段例子,这里的状态转移应该能够很容易写出来。
|
||||
- 如果这一阶段交换,即 $f_{i,j,1}$。类似地,可能由上一次不换的状态转移来,也可能由上一次交换的状态转移来。那么遇到不换的就乘上 $(1-p_i)$,遇到交换的就乘上 $p_i$,将所有会出现的情况都枚举一遍出进行计算就好了。这里不再赘述各种转移情况,相信通过上一种阶段例子,这里的状态转移应该能够很容易写出来。
|
||||
|
||||
#### 实现
|
||||
|
||||
|
|
@ -101,15 +101,15 @@ $$
|
|||
|
||||
### 习题
|
||||
|
||||
- [POJ2096 Collecting Bugs](http://poj.org/problem?id=2096)
|
||||
- [HDU3853 LOOPS](https://vjudge.net/problem/HDU-3853)
|
||||
- [HDU4035 Maze](https://vjudge.net/problem/HDU-4035)
|
||||
- [「NOIP2016」换教室](http://uoj.ac/problem/262)
|
||||
- [「SCOI2008」奖励关](https://www.luogu.com.cn/problem/P2473)
|
||||
- [POJ2096 Collecting Bugs](http://poj.org/problem?id=2096)
|
||||
- [HDU3853 LOOPS](https://vjudge.net/problem/HDU-3853)
|
||||
- [HDU4035 Maze](https://vjudge.net/problem/HDU-4035)
|
||||
- [「NOIP2016」换教室](http://uoj.ac/problem/262)
|
||||
- [「SCOI2008」奖励关](https://www.luogu.com.cn/problem/P2473)
|
||||
|
||||
## 有后效性 DP
|
||||
|
||||
???+note "[CodeForces 24 D Broken robot](https://codeforces.com/problemset/problem/24/D)"
|
||||
???+ note "[CodeForces 24 D Broken robot](https://codeforces.com/problemset/problem/24/D)"
|
||||
题目大意:给出一个 $n \times m$ 的矩阵区域,一个机器人初始在第 $x$ 行第 $y$ 列,每一步机器人会等概率地选择停在原地,左移一步,右移一步,下移一步,如果机器人在边界则不会往区域外移动,问机器人到达最后一行的期望步数。
|
||||
|
||||
### 过程
|
||||
|
|
@ -118,16 +118,16 @@ $$
|
|||
设 $f_{i,j}$ 为机器人机器人从第 i 行第 j 列出发到达第 $n$ 行的期望步数,最终状态为 $f_{n,j}=0$。
|
||||
由于机器人会等概率地选择停在原地,左移一步,右移一步,下移一步,考虑 $f_{i,j}$ 的状态转移:
|
||||
|
||||
- $f_{i,1}=\frac{1}{3}\cdot(f_{i+1,1}+f_{i,2}+f_{i,1})+1$
|
||||
- $f_{i,j}=\frac{1}{4}\cdot(f_{i,j}+f_{i,j-1}+f_{i,j+1}+f_{i+1,j})+1$
|
||||
- $f_{i,m}=\frac{1}{3}\cdot(f_{i,m}+f_{i,m-1}+f_{i+1,m})+1$
|
||||
- $f_{i,1}=\frac{1}{3}\cdot(f_{i+1,1}+f_{i,2}+f_{i,1})+1$
|
||||
- $f_{i,j}=\frac{1}{4}\cdot(f_{i,j}+f_{i,j-1}+f_{i,j+1}+f_{i+1,j})+1$
|
||||
- $f_{i,m}=\frac{1}{3}\cdot(f_{i,m}+f_{i,m-1}+f_{i+1,m})+1$
|
||||
|
||||
在行之间由于只能向下移动,是满足无后效性的。在列之间可以左右移动,在移动过程中可能产生环,不满足无后效性。
|
||||
将方程变换后可以得到:
|
||||
|
||||
- $2f_{i,1}-f_{i,2}=3+f_{i+1,1}$
|
||||
- $3f_{i,j}-f_{i,j-1}-f_{i,j+1}=4+f_{i+1,j}$
|
||||
- $2f_{i,m}-f_{i,m-1}=3+f_{i+1,m}$
|
||||
- $2f_{i,1}-f_{i,2}=3+f_{i+1,1}$
|
||||
- $3f_{i,j}-f_{i,j-1}-f_{i,j+1}=4+f_{i+1,j}$
|
||||
- $2f_{i,m}-f_{i,m-1}=3+f_{i+1,m}$
|
||||
|
||||
由于是逆序的递推,所以每一个 $f_{i+1,j}$ 是已知的。
|
||||
由于有 $m$ 列,所以右边相当于是一个 $m$ 行的列向量,那么左边就是 $m$ 行 $m$ 列的矩阵。使用增广矩阵,就变成了 m 行 m+1 列的矩阵,然后进行 [高斯消元](../math/linear-algebra/gauss.md) 即可解出答案。
|
||||
|
|
@ -194,9 +194,9 @@ $$
|
|||
|
||||
### 习题
|
||||
|
||||
- [CodeForce 24 D Broken robot](https://codeforces.com/problemset/problem/24/D)
|
||||
- [HDU Time Travel](https://vjudge.net/problem/HDU-4418)
|
||||
- [「HNOI2013」游走](https://loj.ac/problem/2383)
|
||||
- [CodeForce 24 D Broken robot](https://codeforces.com/problemset/problem/24/D)
|
||||
- [HDU Time Travel](https://vjudge.net/problem/HDU-4418)
|
||||
- [「HNOI2013」游走](https://loj.ac/problem/2383)
|
||||
|
||||
## 参考文献
|
||||
|
||||
|
|
|
|||
|
|
@ -4,7 +4,7 @@
|
|||
|
||||
## 例题
|
||||
|
||||
???+note "[「SCOI2005」互不侵犯](https://loj.ac/problem/2153)"
|
||||
???+ note "[「SCOI2005」互不侵犯](https://loj.ac/problem/2153)"
|
||||
在 $N\times N$ 的棋盘里面放 $K$ 个国王($1 \leq N \leq 9, 1 \leq K \leq N \times N$),使他们互不攻击,共有多少种摆放方案。
|
||||
|
||||
国王能攻击到它上下左右,以及左上左下右上右下八个方向上附近的各一个格子,共 $8$ 个格子。
|
||||
|
|
@ -34,7 +34,7 @@ $$
|
|||
|
||||
## 习题
|
||||
|
||||
- [「NOI2001」炮兵阵地](https://loj.ac/problem/10173)
|
||||
- [「USACO06NOV」玉米田 Corn Fields](https://www.luogu.com.cn/problem/P1879)
|
||||
- [「AHOI2009」中国象棋](https://www.luogu.com.cn/problem/P2051)
|
||||
- [「九省联考 2018」一双木棋](https://loj.ac/problem/2471)
|
||||
- [「NOI2001」炮兵阵地](https://loj.ac/problem/10173)
|
||||
- [「USACO06NOV」玉米田 Corn Fields](https://www.luogu.com.cn/problem/P1879)
|
||||
- [「AHOI2009」中国象棋](https://www.luogu.com.cn/problem/P2051)
|
||||
- [「九省联考 2018」一双木棋](https://loj.ac/problem/2471)
|
||||
|
|
|
|||
|
|
@ -4,15 +4,15 @@
|
|||
|
||||
以下面这道题为例,介绍一下树形 DP 的一般过程。
|
||||
|
||||
???+note " 例题 [洛谷 P1352 没有上司的舞会](https://www.luogu.com.cn/problem/P1352)"
|
||||
???+ note " 例题 [洛谷 P1352 没有上司的舞会](https://www.luogu.com.cn/problem/P1352)"
|
||||
某大学有 $n$ 个职员,编号为 $1 \sim N$。他们之间有从属关系,也就是说他们的关系就像一棵以校长为根的树,父结点就是子结点的直接上司。现在有个周年庆宴会,宴会每邀请来一个职员都会增加一定的快乐指数 $a_i$,但是呢,如果某个职员的直接上司来参加舞会了,那么这个职员就无论如何也不肯来参加舞会了。所以,请你编程计算,邀请哪些职员可以使快乐指数最大,求最大的快乐指数。
|
||||
|
||||
我们设 $f(i,0/1)$ 代表以 $i$ 为根的子树的最优解(第二维的值为 0 代表 $i$ 不参加舞会的情况,1 代表 $i$ 参加舞会的情况)。
|
||||
|
||||
对于每个状态,都存在两种决策(其中下面的 $x$ 都是 $i$ 的儿子):
|
||||
|
||||
- 上司不参加舞会时,下属可以参加,也可以不参加,此时有 $f(i,0) = \sum\max \{f(x,1),f(x,0)\}$;
|
||||
- 上司参加舞会时,下属都不会参加,此时有 $f(i,1) = \sum{f(x,0)} + a_i$。
|
||||
- 上司不参加舞会时,下属可以参加,也可以不参加,此时有 $f(i,0) = \sum\max \{f(x,1),f(x,0)\}$;
|
||||
- 上司参加舞会时,下属都不会参加,此时有 $f(i,1) = \sum{f(x,0)} + a_i$。
|
||||
|
||||
我们可以通过 DFS,在返回上一层时更新当前结点的最优解。
|
||||
|
||||
|
|
@ -22,17 +22,17 @@
|
|||
|
||||
### 习题
|
||||
|
||||
- [HDU 2196 Computer](https://vjudge.net/problem/HDU-2196)
|
||||
- [HDU 2196 Computer](https://vjudge.net/problem/HDU-2196)
|
||||
|
||||
- [POJ 1463 Strategic game](http://poj.org/problem?id=1463)
|
||||
- [POJ 1463 Strategic game](http://poj.org/problem?id=1463)
|
||||
|
||||
- [\[POI2014\]FAR-FarmCraft](https://www.luogu.com.cn/problem/P3574)
|
||||
- [\[POI2014\]FAR-FarmCraft](https://www.luogu.com.cn/problem/P3574)
|
||||
|
||||
## 树上背包
|
||||
|
||||
树上的背包问题,简单来说就是背包问题与树形 DP 的结合。
|
||||
|
||||
???+note "例题 [洛谷 P2014 CTSC1997 选课](https://www.luogu.com.cn/problem/P2014)"
|
||||
???+ note " 例题 [洛谷 P2014 CTSC1997 选课](https://www.luogu.com.cn/problem/P2014)"
|
||||
现在有 $n$ 门课程,第 $i$ 门课程的学分为 $a_i$,每门课程有零门或一门先修课,有先修课的课程需要先学完其先修课,才能学习该课程。
|
||||
|
||||
一位学生要学习 $m$ 门课程,求其能获得的最多学分数。
|
||||
|
|
@ -66,11 +66,11 @@ $f$ 的第二维可以很轻松地用滚动数组的方式省略掉,注意这
|
|||
|
||||
### 习题
|
||||
|
||||
- [「CTSC1997」选课](https://www.luogu.com.cn/problem/P2014)
|
||||
- [「CTSC1997」选课](https://www.luogu.com.cn/problem/P2014)
|
||||
|
||||
- [「JSOI2018」潜入行动](https://loj.ac/problem/2546)
|
||||
- [「JSOI2018」潜入行动](https://loj.ac/problem/2546)
|
||||
|
||||
- [「SDOI2017」苹果树](https://loj.ac/problem/2268)
|
||||
- [「SDOI2017」苹果树](https://loj.ac/problem/2268)
|
||||
|
||||
## 换根 DP
|
||||
|
||||
|
|
@ -80,7 +80,7 @@ $f$ 的第二维可以很轻松地用滚动数组的方式省略掉,注意这
|
|||
|
||||
接下来以一些例题来带大家熟悉这个内容。
|
||||
|
||||
???+note "例题 [[POI2008]STA-Station](https://www.luogu.com.cn/problem/P3478)"
|
||||
???+ note " 例题 [\[POI2008\]STA-Station](https://www.luogu.com.cn/problem/P3478)"
|
||||
给定一个 $n$ 个点的树,请求出一个结点,使得以这个结点为根时,所有结点的深度之和最大。
|
||||
|
||||
不妨令 $u$ 为当前结点,$v$ 为当前结点的子结点。首先需要用 $s_i$ 来表示以 $i$ 为根的子树中的结点个数,并且有 $s_u=1+\sum s_v$。显然需要一次 DFS 来计算所有的 $s_i$,这次的 DFS 就是预处理,我们得到了以某个结点为根时其子树中的结点总数。
|
||||
|
|
@ -89,9 +89,9 @@ $f$ 的第二维可以很轻松地用滚动数组的方式省略掉,注意这
|
|||
|
||||
$f_v\leftarrow f_u$ 可以体现换根,即以 $u$ 为根转移到以 $v$ 为根。显然在换根的转移过程中,以 $v$ 为根或以 $u$ 为根会导致其子树中的结点的深度产生改变。具体表现为:
|
||||
|
||||
- 所有在 $v$ 的子树上的结点深度都减少了一,那么总深度和就减少了 $s_v$;
|
||||
- 所有在 $v$ 的子树上的结点深度都减少了一,那么总深度和就减少了 $s_v$;
|
||||
|
||||
- 所有不在 $v$ 的子树上的结点深度都增加了一,那么总深度和就增加了 $n-s_v$;
|
||||
- 所有不在 $v$ 的子树上的结点深度都增加了一,那么总深度和就增加了 $n-s_v$;
|
||||
|
||||
根据这两个条件就可以推出状态转移方程 $f_v = f_u - s_v + n - s_v=f_u + n - 2 \times s_v$。
|
||||
|
||||
|
|
@ -104,13 +104,13 @@ $f_v\leftarrow f_u$ 可以体现换根,即以 $u$ 为根转移到以 $v$ 为
|
|||
|
||||
### 习题
|
||||
|
||||
- [POJ 3585 Accumulation Degree](http://poj.org/problem?id=3585)
|
||||
- [POJ 3585 Accumulation Degree](http://poj.org/problem?id=3585)
|
||||
|
||||
- [\[POI2008\]STA-Station](https://www.luogu.com.cn/problem/P3478)
|
||||
- [\[POI2008\]STA-Station](https://www.luogu.com.cn/problem/P3478)
|
||||
|
||||
- [\[USACO10MAR\]Great Cow Gathering G](https://www.luogu.com.cn/problem/P2986)
|
||||
- [\[USACO10MAR\]Great Cow Gathering G](https://www.luogu.com.cn/problem/P2986)
|
||||
|
||||
- [CodeForce 708C Centroids](http://codeforces.com/problemset/problem/708/C)
|
||||
- [CodeForce 708C Centroids](http://codeforces.com/problemset/problem/708/C)
|
||||
|
||||
## 参考资料与注释
|
||||
|
||||
|
|
|
|||
|
|
@ -2,13 +2,13 @@ AVL 树,是一种平衡的二叉搜索树。由于各种算法教材上对 AVL
|
|||
|
||||
## 性质
|
||||
|
||||
1. 空二叉树是一个 AVL 树
|
||||
2. 如果 T 是一棵 AVL 树,那么其左右子树也是 AVL 树,并且 $|h(ls) - h(rs)| \leq 1$,h 是其左右子树的高度
|
||||
3. 树高为 $O(\log n)$
|
||||
1. 空二叉树是一个 AVL 树
|
||||
2. 如果 T 是一棵 AVL 树,那么其左右子树也是 AVL 树,并且 $|h(ls) - h(rs)| \leq 1$,h 是其左右子树的高度
|
||||
3. 树高为 $O(\log n)$
|
||||
|
||||
平衡因子:右子树高度 - 左子树高度
|
||||
|
||||
???+note "树高的证明"
|
||||
???+ note "树高的证明"
|
||||
设 $f_n$ 为高度为 $n$ 的 AVL 树所包含的最少节点数,则有
|
||||
|
||||
$$
|
||||
|
|
@ -111,7 +111,7 @@ $$
|
|||
|
||||
因此旋转后的节点 B、C、D 也满足性质 2。最后给出对于一个节点维护平衡操作的伪代码。
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```text
|
||||
Maintain-Balanced(p)
|
||||
if h[ls[p]] - h[rs[p]] == 2
|
||||
|
|
|
|||
|
|
@ -6,8 +6,8 @@ author: Persdre
|
|||
|
||||
在 B 树中,有两种节点:
|
||||
|
||||
1. 内部节点(internal node):存储了数据以及指向其子节点的指针。
|
||||
2. 叶子节点(leaf node):与内部节点不同的是,叶子节点只存储数据,并没有子节点。
|
||||
1. 内部节点(internal node):存储了数据以及指向其子节点的指针。
|
||||
2. 叶子节点(leaf node):与内部节点不同的是,叶子节点只存储数据,并没有子节点。
|
||||
|
||||
树是一种数据结构。树用多个节点储存元素。某些节点存在一定的关系,用连线表示。二叉树是一种特殊的树,每个节点最多有两个子树。二叉树常用于实现二叉搜索树和二叉堆。
|
||||
而 [AVL 树](./avl.md) 是特殊的二叉树,是最早被发明的自平衡二叉查找树。B 树保留了自平衡的特点,但 B 树的每个节点可以拥有两个以上的子节点,因此 B 树是一种多路搜索树。
|
||||
|
|
@ -16,12 +16,12 @@ author: Persdre
|
|||
|
||||
首先介绍一下一棵 $m$ 阶的 B 树的特性。$m$ 表示这个树的每一个节点最多可以拥有的子节点个数。一棵 $m$ 阶的 B 树满足的性质如下:
|
||||
|
||||
1. 每个节点最多有 $m$ 个子节点。
|
||||
2. 每一个非叶子节点(除根节点)最少有 $\lceil \dfrac{m}{2} \rceil$ 个子节点。
|
||||
3. 如果根节点不是叶子节点,那么它至少有两个子节点。
|
||||
4. 有 $k$ 个子节点的非叶子节点拥有 $k−1$ 个键,且升序排列,满足 $k[i] < k[i+1]$。
|
||||
5. 每个节点至多包含 $2k-1$ 个键。
|
||||
6. 所有的叶子节点都在同一层。
|
||||
1. 每个节点最多有 $m$ 个子节点。
|
||||
2. 每一个非叶子节点(除根节点)最少有 $\lceil \dfrac{m}{2} \rceil$ 个子节点。
|
||||
3. 如果根节点不是叶子节点,那么它至少有两个子节点。
|
||||
4. 有 $k$ 个子节点的非叶子节点拥有 $k−1$ 个键,且升序排列,满足 $k[i] < k[i+1]$。
|
||||
5. 每个节点至多包含 $2k-1$ 个键。
|
||||
6. 所有的叶子节点都在同一层。
|
||||
|
||||
一个简单的图例如下:
|
||||
|
||||
|
|
@ -36,7 +36,7 @@ author: Persdre
|
|||
B 树中的节点包含有多个键。假设需要查找的是 $k$,那么从根节点开始,从上到下递归的遍历树。在每一层上,搜索的范围被减小到包含了搜索值的子树中。
|
||||
子树值的范围被它的父节点的键确定。因为是从根节点开始的二分法查找,所以查找一个键的代码如下:
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
BTreeNode *BTreeNode::search(int k) {
|
||||
// 找到第一个大于等于待查找键 k 的键
|
||||
|
|
@ -61,7 +61,7 @@ B 树的中序遍历与二叉搜索树的中序遍历也很相似,从最左边
|
|||
|
||||
遍历的代码如下:
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
void BTreeNode::traverse() {
|
||||
// 有 n 个键和 n+1 个孩子
|
||||
|
|
@ -88,11 +88,11 @@ B 树的中序遍历与二叉搜索树的中序遍历也很相似,从最左边
|
|||
|
||||
针对一棵高度为 $h$ 的 $m$ 阶 B 树,插入一个元素时,首先要验证该元素在 B 树中是否存在,如果不存在,那么就要在叶子节点中插入该新的元素,此时分 3 种情况:
|
||||
|
||||
1. 如果叶子节点空间足够,即该节点的关键字数小于 $m-1$,则直接插入在叶子节点的左边或右边;
|
||||
1. 如果叶子节点空间足够,即该节点的关键字数小于 $m-1$,则直接插入在叶子节点的左边或右边;
|
||||
2. 如果空间满了以至于没有足够的空间去添加新的元素,即该节点的关键字数已经有了 $m$ 个,则需要将该节点进行“分裂”,将一半数量的关键字元素分裂到新的其相邻右节点中,中间关键字元素上移到父节点中,而且当节点中关键元素向右移动了,相关的指针也需要向右移。
|
||||
1. 从该节点的原有元素和新的元素中选择出中位数
|
||||
2. 小于这一中位数的元素放入左边节点,大于这一中位数的元素放入右边节点,中位数作为分隔值。
|
||||
3. 分隔值被插入到父节点中,这可能会造成父节点分裂,分裂父节点时可能又会使它的父节点分裂,以此类推。如果没有父节点(这一节点是根节点),就创建一个新的根节点(增加了树的高度)。
|
||||
1. 从该节点的原有元素和新的元素中选择出中位数
|
||||
2. 小于这一中位数的元素放入左边节点,大于这一中位数的元素放入右边节点,中位数作为分隔值。
|
||||
3. 分隔值被插入到父节点中,这可能会造成父节点分裂,分裂父节点时可能又会使它的父节点分裂,以此类推。如果没有父节点(这一节点是根节点),就创建一个新的根节点(增加了树的高度)。
|
||||
|
||||
如果一直分裂到根节点,那么就需要创建一个新的根节点。它有一个分隔值和两个子节点。
|
||||
|
||||
|
|
@ -101,7 +101,7 @@ B 树的中序遍历与二叉搜索树的中序遍历也很相似,从最左边
|
|||
|
||||
插入的代码如下:
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
void BTree::insert(int k) {
|
||||
// 如果树为空树
|
||||
|
|
@ -218,17 +218,17 @@ B 树的删除操作相比于插入操作更为复杂,因为删除之后经常
|
|||
|
||||
有两种常用的删除策略:
|
||||
|
||||
1. 定位并删除元素,然后调整树使它满足约束条件。
|
||||
2. 从上到下处理这棵树,在进入一个节点之前,调整树使得之后一旦遇到了要删除的键,它可以被直接删除而不需要再进行调整。
|
||||
1. 定位并删除元素,然后调整树使它满足约束条件。
|
||||
2. 从上到下处理这棵树,在进入一个节点之前,调整树使得之后一旦遇到了要删除的键,它可以被直接删除而不需要再进行调整。
|
||||
|
||||
下面介绍使用第一种策略的删除。
|
||||
|
||||
首先,查找 B 树中需删除的元素,如果该元素在 B 树中存在,则将该元素在其节点中进行删除;删除该元素后,首先判断该元素是否有左右孩子节点,
|
||||
如果有,则上移孩子节点中的某相近元素("左孩子最右边的节点" 或 "右孩子最左边的节点")到父节点中,然后是移动之后的情况;如果没有,直接删除。
|
||||
|
||||
1. 某节点中元素数目小于 $m/2-1$,$m/2$ 向上取整,则需要看其某相邻兄弟节点是否丰满。
|
||||
2. 如果丰满(节点中元素个数大于 $m/2-1$),则向父节点借一个元素来满足条件。
|
||||
3. 如果其相邻兄弟都不丰满,即其节点数目等于 $m/2-1$,则该节点与其相邻的某一兄弟节点进行 "合并" 成一个节点。
|
||||
1. 某节点中元素数目小于 $m/2-1$,$m/2$ 向上取整,则需要看其某相邻兄弟节点是否丰满。
|
||||
2. 如果丰满(节点中元素个数大于 $m/2-1$),则向父节点借一个元素来满足条件。
|
||||
3. 如果其相邻兄弟都不丰满,即其节点数目等于 $m/2-1$,则该节点与其相邻的某一兄弟节点进行 "合并" 成一个节点。
|
||||
|
||||
接下来用一个 5 阶 B 树为例,详细讲解删除的操作。
|
||||
|
||||
|
|
@ -273,7 +273,7 @@ B 树的删除操作相比于插入操作更为复杂,因为删除之后经常
|
|||
|
||||
删除的伪代码如下:
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```text
|
||||
B-Tree-Delete-Key(x, k)
|
||||
if not leaf[x] then
|
||||
|
|
@ -329,8 +329,8 @@ B 树的删除操作相比于插入操作更为复杂,因为删除之后经常
|
|||
|
||||
考虑在磁盘中存储数据的情况,与内存相比,读写磁盘有以下不同点:
|
||||
|
||||
1. 读写磁盘的速度相比内存读写慢很多。
|
||||
2. 每次读写磁盘的单位要比读写内存的最小单位大很多。
|
||||
1. 读写磁盘的速度相比内存读写慢很多。
|
||||
2. 每次读写磁盘的单位要比读写内存的最小单位大很多。
|
||||
|
||||
由于读写磁盘的这个特点,因此对应的数据结构应该尽量的满足 "局部性原理":"当一个数据被用到时,其附近的数据也通常会马上被使用",为了满足局部性原理,
|
||||
所以应该将逻辑上相邻的数据在物理上也尽量存储在一起。这样才能减少读写磁盘的数量。
|
||||
|
|
@ -340,7 +340,7 @@ B 树的删除操作相比于插入操作更为复杂,因为删除之后经常
|
|||
|
||||
## 参考资料
|
||||
|
||||
- [B 树 - 维基百科,自由的百科全书](https://zh.m.wikipedia.org/zh-sg/B%E6%A0%91)
|
||||
- [B 树详解](https://www.cnblogs.com/lwhkdash/p/5313877.html)
|
||||
- [B 树、B + 树索引算法原理(上)](https://www.codedump.info/post/20200609-btree-1/)
|
||||
- [B 树,B + 树详解](https://www.cnblogs.com/lianzhilei/p/11250589.html)
|
||||
- [B 树 - 维基百科,自由的百科全书](https://zh.m.wikipedia.org/zh-sg/B%E6%A0%91)
|
||||
- [B 树详解](https://www.cnblogs.com/lwhkdash/p/5313877.html)
|
||||
- [B 树、B + 树索引算法原理(上)](https://www.codedump.info/post/20200609-btree-1/)
|
||||
- [B 树,B + 树详解](https://www.cnblogs.com/lianzhilei/p/11250589.html)
|
||||
|
|
|
|||
|
|
@ -26,8 +26,8 @@ author: Dev-jqe, HeRaNO, huaruoji
|
|||
|
||||
### 时间复杂度
|
||||
|
||||
- 对于 1,3,4 操作,我们考虑我们在外层线段树上进行 $O(\log{n})$ 次操作,每次操作会在一个内层平衡树树上进行 $O(\log{n})$ 次操作,所以时间复杂度为 $O(\log^2{n})$。
|
||||
- 对于 2 操作,多一个二分过程,为 $O(\log^3{n})$。
|
||||
- 对于 1,3,4 操作,我们考虑我们在外层线段树上进行 $O(\log{n})$ 次操作,每次操作会在一个内层平衡树树上进行 $O(\log{n})$ 次操作,所以时间复杂度为 $O(\log^2{n})$。
|
||||
- 对于 2 操作,多一个二分过程,为 $O(\log^3{n})$。
|
||||
|
||||
## 经典例题
|
||||
|
||||
|
|
|
|||
|
|
@ -115,7 +115,7 @@ void build_heap_2() {
|
|||
|
||||
注意到向下调整的复杂度,为 $O(\log n - k)$,另外注意到叶节点无需调整,因此可从序列约 $n/2$ 的位置开始调整,可减少部分常数但不影响复杂度。
|
||||
|
||||
???+note "证明"
|
||||
???+ note "证明"
|
||||
$$
|
||||
\begin{aligned}
|
||||
\text{总复杂度} & = n \log n - \log 1 - \log 2 - \cdots - \log n \\
|
||||
|
|
@ -137,9 +137,8 @@ void build_heap_2() {
|
|||
??? note "[SP16254 RMID2 - Running Median Again](https://www.luogu.com.cn/problem/SP16254)"
|
||||
维护一个序列,支持两种操作:
|
||||
|
||||
1. 向序列中插入一个元素
|
||||
|
||||
2. 输出并删除当前序列的中位数(若序列长度为偶数,则输出较小的中位数)
|
||||
1. 向序列中插入一个元素
|
||||
2. 输出并删除当前序列的中位数(若序列长度为偶数,则输出较小的中位数)
|
||||
|
||||
这个问题可以被进一步抽象成:动态维护一个序列上第 $k$ 大的数,$k$ 值可能会发生变化。
|
||||
|
||||
|
|
@ -149,11 +148,11 @@ void build_heap_2() {
|
|||
|
||||
这两个堆构成的数据结构支持以下操作:
|
||||
|
||||
- 维护:当小根堆的大小小于 $k$ 时,不断将大根堆堆顶元素取出并插入小根堆,直到小根堆的大小等于 $k$;当小根堆的大小大于 $k$ 时,不断将小根堆堆顶元素取出并插入大根堆,直到小根堆的大小等于 $k$;
|
||||
- 插入元素:若插入的元素大于等于小根堆堆顶元素,则将其插入小根堆,否则将其插入大根堆,然后维护对顶堆;
|
||||
- 查询第 $k$ 大元素:小根堆堆顶元素即为所求;
|
||||
- 删除第 $k$ 大元素:删除小根堆堆顶元素,然后维护对顶堆;
|
||||
- $k$ 值 $+1/-1$:根据新的 $k$ 值直接维护对顶堆。
|
||||
- 维护:当小根堆的大小小于 $k$ 时,不断将大根堆堆顶元素取出并插入小根堆,直到小根堆的大小等于 $k$;当小根堆的大小大于 $k$ 时,不断将小根堆堆顶元素取出并插入大根堆,直到小根堆的大小等于 $k$;
|
||||
- 插入元素:若插入的元素大于等于小根堆堆顶元素,则将其插入小根堆,否则将其插入大根堆,然后维护对顶堆;
|
||||
- 查询第 $k$ 大元素:小根堆堆顶元素即为所求;
|
||||
- 删除第 $k$ 大元素:删除小根堆堆顶元素,然后维护对顶堆;
|
||||
- $k$ 值 $+1/-1$:根据新的 $k$ 值直接维护对顶堆。
|
||||
|
||||
显然,查询第 $k$ 大元素的时间复杂度是 $O(1)$ 的。由于插入、删除或调整 $k$ 值后,小根堆的大小与期望的 $k$ 值最多相差 $1$,故每次维护最多只需对大根堆与小根堆中的元素进行一次调整,因此,这些操作的时间复杂度都是 $O(\log n)$ 的。
|
||||
|
||||
|
|
@ -162,5 +161,5 @@ void build_heap_2() {
|
|||
--8<-- "docs/ds/code/binary-heap/binary-heap_1.cpp"
|
||||
```
|
||||
|
||||
- 双倍经验:[SP15376 RMID - Running Median](https://www.luogu.com.cn/problem/SP15376)
|
||||
- 典型习题:[P1801 黑匣子](https://www.luogu.com.cn/problem/P1801)
|
||||
- 双倍经验:[SP15376 RMID - Running Median](https://www.luogu.com.cn/problem/SP15376)
|
||||
- 典型习题:[P1801 黑匣子](https://www.luogu.com.cn/problem/P1801)
|
||||
|
|
|
|||
|
|
@ -9,8 +9,8 @@
|
|||
???+ note "矩形区域查询"
|
||||
给出 $n$ 个二维平面中的点 $(x_i, y_i)$,其中 $1 \le i \le n, 1 \le x_i, y_i \le n, 1 \le n \le 10^5$, 要求实现以下中操作:
|
||||
|
||||
1. 给出 $a, b, c, d$,询问以 $(a, b)$ 为左上角,$c, d$ 为右下角的矩形区域内点的个数。
|
||||
2. 给出 $x, y$,将横坐标为 $x$ 的点的纵坐标改为 $y$。
|
||||
1. 给出 $a, b, c, d$,询问以 $(a, b)$ 为左上角,$c, d$ 为右下角的矩形区域内点的个数。
|
||||
2. 给出 $x, y$,将横坐标为 $x$ 的点的纵坐标改为 $y$。
|
||||
|
||||
题目 **强制在线**,保证 $x_i \ne x_j(1 \le i, j \le n, i \ne j)$。
|
||||
|
||||
|
|
@ -54,17 +54,17 @@
|
|||
|
||||
## 例题 1
|
||||
|
||||
???+ note " [Intersection of Permutations](https://codeforces.com/problemset/problem/1093/E) "
|
||||
???+ note "[Intersection of Permutations](https://codeforces.com/problemset/problem/1093/E)"
|
||||
给出两个排列 $a$ 和 $b$,要求实现以下两种操作:
|
||||
|
||||
1. 给出 $l_a, r_a, l_b, r_b$,要求查询既出现在 $a[l_a ... r_a]$ 又出现在 $b[l_b ... r_b]$ 中的元素的个数。
|
||||
2. 给出 $x, y$,$swap(b_x, b_y)$。
|
||||
1. 给出 $l_a, r_a, l_b, r_b$,要求查询既出现在 $a[l_a ... r_a]$ 又出现在 $b[l_b ... r_b]$ 中的元素的个数。
|
||||
2. 给出 $x, y$,$swap(b_x, b_y)$。
|
||||
|
||||
序列长度 $n$ 满足 $2 \le n \le 2 \cdot 10^5$,操作个数 $q$ 满足 $1 \le q \le 2 \cdot 10^5$。
|
||||
|
||||
对于每个值 $i$,记 $x_i$ 是它在排列 $b$ 中的下标,$y_i$ 是它在排列 $a$ 中的下标。这样,操作一就变成了一个矩形区域内点的个数的询问,操作 2 可以看成两个修改操作。而且因为是排列,所以满足一个 $x$ 对应一个 $y$,所以这题可以用分块套树状数组来写。
|
||||
|
||||
??? note "参考代码(分块套树状数组-1s)"
|
||||
??? note "参考代码(分块套树状数组 - 1s)"
|
||||
```cpp
|
||||
#include <bits/stdc++.h>
|
||||
using namespace std;
|
||||
|
|
@ -148,7 +148,7 @@
|
|||
}
|
||||
```
|
||||
|
||||
??? node "参考代码(树状数组套Treap-TLE)"
|
||||
??? node "参考代码(树状数组套 Treap-TLE)"
|
||||
```cpp
|
||||
#include <bits/stdc++.h>
|
||||
using namespace std;
|
||||
|
|
@ -294,7 +294,7 @@
|
|||
|
||||
## 例题 2
|
||||
|
||||
???+ note " [Complicated Computations](https://codeforces.com/contest/1436/problem/E) "
|
||||
???+ note "[Complicated Computations](https://codeforces.com/contest/1436/problem/E)"
|
||||
给出一个序列 $a$,将 $a$ 所有连续子序列的 MEX 构成的数组作为 $b$,问 $b$ 的 MEX。一个序列的 MEX 是序列中最小的没出现过的 **正整数**。
|
||||
|
||||
序列的长度 $n$ 满足 $1 \le n \le 10^5$。
|
||||
|
|
@ -309,7 +309,7 @@
|
|||
|
||||
如果在判断完值为 $i$ 的元素之后再将对应的点插入,这时因为 $[l, r]$ 内只存在 $a_j \le i - 1$ 的元素,所以上述三维偏序问题就可以转换为二维偏序的问题。
|
||||
|
||||
??? note "参考代码(分块套树状数组-78ms)"
|
||||
??? note "参考代码(分块套树状数组 - 78ms)"
|
||||
```cpp
|
||||
#include <bits/stdc++.h>
|
||||
using namespace std;
|
||||
|
|
@ -416,7 +416,7 @@
|
|||
}
|
||||
```
|
||||
|
||||
??? note "参考代码(线段树套Treap-468ms)"
|
||||
??? note "参考代码(线段树套 Treap-468ms)"
|
||||
```cpp
|
||||
#include <bits/stdc++.h>
|
||||
using namespace std;
|
||||
|
|
|
|||
|
|
@ -4,7 +4,7 @@
|
|||
|
||||
下面直接给出一种建立块状数组的代码。
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
num = sqrt(n);
|
||||
for (int i = 1; i <= num; i++)
|
||||
|
|
@ -26,14 +26,14 @@
|
|||
|
||||
两种操作:
|
||||
|
||||
1. 区间 $[x,y]$ 每个数都加上 $z$;
|
||||
2. 查询区间 $[x,y]$ 内大于等于 $z$ 的数的个数。
|
||||
1. 区间 $[x,y]$ 每个数都加上 $z$;
|
||||
2. 查询区间 $[x,y]$ 内大于等于 $z$ 的数的个数。
|
||||
|
||||
我们要询问一个块内大于等于一个数的数的个数,所以需要一个 `t` 数组对块内排序,`a` 为原来的(未被排序的)数组。对于整块的修改,使用类似于标记永久化的方式,用 `delta` 数组记录现在块内整体加上的值。设 $q$ 为查询和修改的操作次数总和,则时间复杂度 $O(q\sqrt{n}\log n)$。
|
||||
|
||||
用 `delta` 数组记录每个块的整体赋值情况。
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
void Sort(int k) {
|
||||
for (int i = st[k]; i <= ed[k]; i++) t[i] = a[i];
|
||||
|
|
@ -78,12 +78,12 @@
|
|||
|
||||
两种操作:
|
||||
|
||||
1. 区间 $[x,y]$ 每个数都变成 $z$;
|
||||
2. 查询区间 $[x,y]$ 内小于等于 $z$ 的数的个数。
|
||||
1. 区间 $[x,y]$ 每个数都变成 $z$;
|
||||
2. 查询区间 $[x,y]$ 内小于等于 $z$ 的数的个数。
|
||||
|
||||
用 `delta` 数组记录现在块内被整体赋值为何值。当该块未被整体赋值时,用一个特殊值(如 `0x3f3f3f3f3f3f3f3fll`)加以表示。对于边角块,查询前要 `pushdown`,把块内存的信息下放到每一个数上。赋值之后记得重新 `sort` 一遍。其他方面同上题。
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
void Sort(int k) {
|
||||
for (int i = st[k]; i <= ed[k]; i++) t[i] = a[i];
|
||||
|
|
@ -149,9 +149,9 @@
|
|||
|
||||
## 练习
|
||||
|
||||
1. [单点修改,区间查询](https://loj.ac/problem/130)
|
||||
2. [区间修改,区间查询](https://loj.ac/problem/132)
|
||||
3. [【模板】线段树 2](https://www.luogu.com.cn/problem/P3373)
|
||||
4. [「Ynoi2019 模拟赛」Yuno loves sqrt technology III](https://www.luogu.com.cn/problem/P5048)
|
||||
5. [「Violet」蒲公英](https://www.luogu.com.cn/problem/P4168)
|
||||
6. [作诗](https://www.luogu.com.cn/problem/P4135)
|
||||
1. [单点修改,区间查询](https://loj.ac/problem/130)
|
||||
2. [区间修改,区间查询](https://loj.ac/problem/132)
|
||||
3. [【模板】线段树 2](https://www.luogu.com.cn/problem/P3373)
|
||||
4. [「Ynoi2019 模拟赛」Yuno loves sqrt technology III](https://www.luogu.com.cn/problem/P5048)
|
||||
5. [「Violet」蒲公英](https://www.luogu.com.cn/problem/P4168)
|
||||
6. [作诗](https://www.luogu.com.cn/problem/P4135)
|
||||
|
|
|
|||
|
|
@ -9,7 +9,7 @@ author: HeRaNO, konnyakuxzy, littlefrog
|
|||
所以我们这么定义结构体,代码见下。
|
||||
其中 `sqn` 表示 `sqrt(n)` 即 $\sqrt{n}$,`pb` 表示 `push_back`,即在这个 `node` 中加入一个元素。
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
struct node {
|
||||
node* nxt;
|
||||
|
|
|
|||
|
|
@ -10,10 +10,10 @@ B+ 树的特点是能够保持数据稳定有序,其插入与修改拥有较
|
|||
|
||||
首先介绍一棵 $m$ 阶 B+ 树的特性。$m$ 表示这个树的每一个节点最多可以拥有的子节点个数。一棵 $m$ 阶的 B+ 树和 B 树的差异在于:
|
||||
|
||||
1. 有 $n$ 棵子树的节点中含有 $n$ 个关键字(即每个关键字对应一棵子树)。
|
||||
2. 所有叶子节点中包含了全部关键字的信息,及指向含这些关键字记录的指针,且叶子节点本身依关键字的大小自小而大顺序链接。
|
||||
3. 所有的非叶子节点可以看成是索引部分,节点中仅含有其子树(根节点)中的最大(或最小)关键字。
|
||||
4. 除根节点外,其他所有节点中所含关键字的个数最少有 $\lceil \dfrac{m}{2} \rceil$(注意:B 树中除根以外的所有非叶子节点至少有 $\lceil \dfrac{m}{2} \rceil$ 棵子树)。
|
||||
1. 有 $n$ 棵子树的节点中含有 $n$ 个关键字(即每个关键字对应一棵子树)。
|
||||
2. 所有叶子节点中包含了全部关键字的信息,及指向含这些关键字记录的指针,且叶子节点本身依关键字的大小自小而大顺序链接。
|
||||
3. 所有的非叶子节点可以看成是索引部分,节点中仅含有其子树(根节点)中的最大(或最小)关键字。
|
||||
4. 除根节点外,其他所有节点中所含关键字的个数最少有 $\lceil \dfrac{m}{2} \rceil$(注意:B 树中除根以外的所有非叶子节点至少有 $\lceil \dfrac{m}{2} \rceil$ 棵子树)。
|
||||
|
||||
同时,B+ 树为了方便范围查询,叶子节点之间还用指针串联起来。
|
||||
|
||||
|
|
@ -65,7 +65,7 @@ B+ 树的查找过程和 B 树类似。假设需要查找的键值是 $k$,那
|
|||
|
||||
查找一个键的代码如下:
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
T find(V key) {
|
||||
int i = 0;
|
||||
|
|
@ -86,9 +86,9 @@ B+ 树只在叶子节点的层级上就可以实现整棵树的遍历。从根
|
|||
|
||||
B+ 树的插入算法与 B 树的相近:
|
||||
|
||||
1. 若为空树,创建一个叶子节点,然后将记录插入其中,此时这个叶子节点也是根节点,插入操作结束。
|
||||
2. 针对叶子类型节点:根据关键字找到叶子节点,向这个叶子节点插入记录。插入后,若当前节点关键字的个数小于 $m$,则插入结束。否则将这个叶子节点分裂成左右两个叶子节点,左叶子节点包含前 $m/2$ 个记录,右节点包含剩下的记录,将第 $m/2+1$ 个记录的关键字进位到父节点中(父节点一定是索引类型节点),进位到父节点的关键字左孩子指针向左节点,右孩子指针向右节点。将当前节点的指针指向父节点,然后执行第 3 步。
|
||||
3. 针对索引类型节点(内部节点):若当前节点关键字的个数小于等于 $m-1$,则插入结束。否则,将这个索引类型节点分裂成两个索引节点,左索引节点包含前 $(m-1)/2$ 个 key,右节点包含 $m-(m-1)/2$ 个 key,将第 $m/2$ 个关键字进位到父节点中,进位到父节点的关键字左孩子指向左节点,进位到父节点的关键字右孩子指向右节点。将当前节点的指针指向父节点,然后重复这一步。
|
||||
1. 若为空树,创建一个叶子节点,然后将记录插入其中,此时这个叶子节点也是根节点,插入操作结束。
|
||||
2. 针对叶子类型节点:根据关键字找到叶子节点,向这个叶子节点插入记录。插入后,若当前节点关键字的个数小于 $m$,则插入结束。否则将这个叶子节点分裂成左右两个叶子节点,左叶子节点包含前 $m/2$ 个记录,右节点包含剩下的记录,将第 $m/2+1$ 个记录的关键字进位到父节点中(父节点一定是索引类型节点),进位到父节点的关键字左孩子指针向左节点,右孩子指针向右节点。将当前节点的指针指向父节点,然后执行第 3 步。
|
||||
3. 针对索引类型节点(内部节点):若当前节点关键字的个数小于等于 $m-1$,则插入结束。否则,将这个索引类型节点分裂成两个索引节点,左索引节点包含前 $(m-1)/2$ 个 key,右节点包含 $m-(m-1)/2$ 个 key,将第 $m/2$ 个关键字进位到父节点中,进位到父节点的关键字左孩子指向左节点,进位到父节点的关键字右孩子指向右节点。将当前节点的指针指向父节点,然后重复这一步。
|
||||
|
||||
比如在下图的 B+ 树中,插入新的数据 10:
|
||||
|
||||
|
|
@ -108,8 +108,8 @@ B+ 树的插入算法与 B 树的相近:
|
|||
|
||||
$[2,3,4,5]$ 分裂成了 $[2,3]$ 和 $[4,5]$,因此需要在这两个节点之间新增一个索引值,这个值应该满足:
|
||||
|
||||
1. 大于左子树的最大值;
|
||||
2. 小于等于右子树的最小值。
|
||||
1. 大于左子树的最大值;
|
||||
2. 小于等于右子树的最小值。
|
||||
|
||||
综上,需要在父节点中新增索引 4 和两个指向新节点的指针。
|
||||
|
||||
|
|
@ -117,7 +117,7 @@ $[2,3,4,5]$ 分裂成了 $[2,3]$ 和 $[4,5]$,因此需要在这两个节点之
|
|||
|
||||
插入一个键的代码如下:
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
void BPTree::insert(int x) {
|
||||
if (root == NULL) {
|
||||
|
|
@ -248,9 +248,9 @@ B+ 树的删除也仅在叶子节点中进行,当叶子节点中的最大关
|
|||
|
||||
具体步骤如下:
|
||||
|
||||
1. 首先查询到键值所在的叶子节点,删除该叶子节点的数据。
|
||||
2. 如果删除叶子节点之后的数据数量,满足 B+ 树的平衡条件,则直接返回。
|
||||
3. 否则,就需要做平衡操作:如果该叶子节点的左右兄弟节点的数据量可以借用,就借用过来满足平衡条件。否则,就与相邻的兄弟节点合并成一个新的子节点了。
|
||||
1. 首先查询到键值所在的叶子节点,删除该叶子节点的数据。
|
||||
2. 如果删除叶子节点之后的数据数量,满足 B+ 树的平衡条件,则直接返回。
|
||||
3. 否则,就需要做平衡操作:如果该叶子节点的左右兄弟节点的数据量可以借用,就借用过来满足平衡条件。否则,就与相邻的兄弟节点合并成一个新的子节点了。
|
||||
|
||||
在上面平衡操作中,如果是进行了合并操作,就需要向上修正父节点的指针:删除被合并节点的键值以及指针。
|
||||
|
||||
|
|
@ -722,7 +722,7 @@ B+ 树的删除也仅在叶子节点中进行,当叶子节点中的最大关
|
|||
|
||||
## 参考资料
|
||||
|
||||
- [B+ tree wikipedia](https://en.wikipedia.org/wiki/B%2B_tree)
|
||||
- [B 树、B+ 树索引算法原理(下)](https://www.codedump.info/post/20200615-btree-2/)
|
||||
- [B+ 树详解 + 代码实现(插入篇)](https://www.cnblogs.com/JayL-zxl/p/14304178.html)
|
||||
- [Deletion from a B+ Tree](https://www.programiz.com/dsa/deletion-from-a-b-plus-tree)
|
||||
- [B+ tree wikipedia](https://en.wikipedia.org/wiki/B%2B_tree)
|
||||
- [B 树、B+ 树索引算法原理(下)](https://www.codedump.info/post/20200615-btree-2/)
|
||||
- [B+ 树详解 + 代码实现(插入篇)](https://www.cnblogs.com/JayL-zxl/p/14304178.html)
|
||||
- [Deletion from a B+ Tree](https://www.programiz.com/dsa/deletion-from-a-b-plus-tree)
|
||||
|
|
|
|||
|
|
@ -2,13 +2,13 @@
|
|||
|
||||
二叉搜索树是一种二叉树的树形数据结构,其定义如下:
|
||||
|
||||
1. 空树是二叉搜索树。
|
||||
1. 空树是二叉搜索树。
|
||||
|
||||
2. 若二叉搜索树的左子树不为空,则其左子树上所有点的附加权值均小于其根节点的值。
|
||||
2. 若二叉搜索树的左子树不为空,则其左子树上所有点的附加权值均小于其根节点的值。
|
||||
|
||||
3. 若二叉搜索树的右子树不为空,则其右子树上所有点的附加权值均大于其根节点的值。
|
||||
3. 若二叉搜索树的右子树不为空,则其右子树上所有点的附加权值均大于其根节点的值。
|
||||
|
||||
4. 二叉搜索树的左右子树均为二叉搜索树。
|
||||
4. 二叉搜索树的左右子树均为二叉搜索树。
|
||||
|
||||
二叉搜索树上的基本操作所花费的时间与这棵树的高度成正比。对于一个有 $n$ 个结点的二叉搜索树中,这些操作的最优时间复杂度为 $O(\log n)$,最坏为 $O(n)$。随机构造这样一棵二叉搜索树的期望高度为 $O(\log n)$。
|
||||
|
||||
|
|
@ -22,7 +22,7 @@
|
|||
|
||||
遍历一棵二叉搜索树的代码如下:
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
void print(int o) {
|
||||
// 遍历以 o 为根节点的二叉搜索树
|
||||
|
|
@ -39,7 +39,7 @@
|
|||
|
||||
findmin 和 findmax 函数分别返回最小值和最大值所对应的结点编号 $o$,用 `val[o]` 可以获得相应的最小/最大值。
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
int findmin(int o) {
|
||||
if (!lc[o]) return o;
|
||||
|
|
@ -68,7 +68,7 @@ findmin 和 findmax 函数分别返回最小值和最大值所对应的结点编
|
|||
|
||||
时间复杂度为 $O(h)$。
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
void insert(int& o, int v) {
|
||||
if (!o) {
|
||||
|
|
@ -105,7 +105,7 @@ findmin 和 findmax 函数分别返回最小值和最大值所对应的结点编
|
|||
|
||||
时间复杂度 $O(h)$。
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
int deletemin(int& o) {
|
||||
if (!lc[o]) {
|
||||
|
|
@ -146,7 +146,7 @@ findmin 和 findmax 函数分别返回最小值和最大值所对应的结点编
|
|||
|
||||
时间复杂度 $O(h)$。
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
int queryrnk(int o, int v) {
|
||||
if (val[o] == v) return siz[lc[o]] + 1;
|
||||
|
|
@ -167,7 +167,7 @@ findmin 和 findmax 函数分别返回最小值和最大值所对应的结点编
|
|||
|
||||
时间复杂度 $O(h)$。
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
int querykth(int o, int k) {
|
||||
if (siz[lc[o]] >= k) return querykth(lc[o], k);
|
||||
|
|
@ -207,7 +207,7 @@ findmin 和 findmax 函数分别返回最小值和最大值所对应的结点编
|
|||
|
||||
一段可行的代码为:
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
|
||||
int zig(int now) { // 以now为中心右旋
|
||||
|
|
|
|||
|
|
@ -20,10 +20,10 @@ author: Ir1d, HeRaNO, Xeonacid
|
|||
|
||||
## 区间和
|
||||
|
||||
??? "例题 [LibreOJ 6280 数列分块入门 4](https://loj.ac/problem/6280)"
|
||||
??? " 例题 [LibreOJ 6280 数列分块入门 4](https://loj.ac/problem/6280)"
|
||||
给定一个长度为 $n$ 的序列 $\{a_i\}$,需要执行 $n$ 次操作。操作分为两种:
|
||||
|
||||
1. 给 $a_l \sim a_r$ 之间的所有数加上 $x$;
|
||||
1. 给 $a_l \sim a_r$ 之间的所有数加上 $x$;
|
||||
2. 求 $\sum_{i=l}^r a_i$。
|
||||
|
||||
$1 \leq n \leq 5 \times 10^4$
|
||||
|
|
@ -38,13 +38,13 @@ $$
|
|||
|
||||
首先看查询操作:
|
||||
|
||||
- 若 $l$ 和 $r$ 在同一个块内,直接暴力求和即可,因为块长为 $s$,因此最坏复杂度为 $O(s)$。
|
||||
- 若 $l$ 和 $r$ 不在同一个块内,则答案由三部分组成:以 $l$ 开头的不完整块,中间几个完整块,以 $r$ 结尾的不完整块。对于不完整的块,仍然采用上面暴力计算的方法,对于完整块,则直接利用已经求出的 $b_i$ 求和即可。这种情况下,最坏复杂度为 $O(\dfrac{n}{s}+s)$。
|
||||
- 若 $l$ 和 $r$ 在同一个块内,直接暴力求和即可,因为块长为 $s$,因此最坏复杂度为 $O(s)$。
|
||||
- 若 $l$ 和 $r$ 不在同一个块内,则答案由三部分组成:以 $l$ 开头的不完整块,中间几个完整块,以 $r$ 结尾的不完整块。对于不完整的块,仍然采用上面暴力计算的方法,对于完整块,则直接利用已经求出的 $b_i$ 求和即可。这种情况下,最坏复杂度为 $O(\dfrac{n}{s}+s)$。
|
||||
|
||||
接下来是修改操作:
|
||||
|
||||
- 若 $l$ 和 $r$ 在同一个块内,直接暴力修改即可,因为块长为 $s$,因此最坏复杂度为 $O(s)$。
|
||||
- 若 $l$ 和 $r$ 不在同一个块内,则需要修改三部分:以 $l$ 开头的不完整块,中间几个完整块,以 $r$ 结尾的不完整块。对于不完整的块,仍然是暴力修改每个元素的值(别忘了更新区间和 $b_i$),对于完整块,则直接修改 $b_i$ 即可。这种情况下,最坏复杂度和仍然为 $O(\dfrac{n}{s}+s)$。
|
||||
- 若 $l$ 和 $r$ 在同一个块内,直接暴力修改即可,因为块长为 $s$,因此最坏复杂度为 $O(s)$。
|
||||
- 若 $l$ 和 $r$ 不在同一个块内,则需要修改三部分:以 $l$ 开头的不完整块,中间几个完整块,以 $r$ 结尾的不完整块。对于不完整的块,仍然是暴力修改每个元素的值(别忘了更新区间和 $b_i$),对于完整块,则直接修改 $b_i$ 即可。这种情况下,最坏复杂度和仍然为 $O(\dfrac{n}{s}+s)$。
|
||||
|
||||
利用均值不等式可知,当 $\dfrac{n}{s}=s$,即 $s=\sqrt n$ 时,单次操作的时间复杂度最优,为 $O(\sqrt n)$。
|
||||
|
||||
|
|
@ -93,14 +93,14 @@ $T=\sqrt{n}$ 时,总复杂度 $O(m \sqrt{n})$。
|
|||
|
||||
## 练习题
|
||||
|
||||
- [UVA - 12003 - Array Transformer](https://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&page=show_problem&problem=3154)
|
||||
- [UVA - 11990 Dynamic Inversion](https://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&page=show_problem&problem=3141)
|
||||
- [SPOJ - Give Away](http://www.spoj.com/problems/GIVEAWAY/)
|
||||
- [Codeforces - Till I Collapse](http://codeforces.com/contest/786/problem/C)
|
||||
- [Codeforces - Destiny](http://codeforces.com/contest/840/problem/D)
|
||||
- [Codeforces - Holes](http://codeforces.com/contest/13/problem/E)
|
||||
- [Codeforces - XOR and Favorite Number](https://codeforces.com/problemset/problem/617/E)
|
||||
- [Codeforces - Powerful array](http://codeforces.com/problemset/problem/86/D)
|
||||
- [UVA - 12003 - Array Transformer](https://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&page=show_problem&problem=3154)
|
||||
- [UVA - 11990 Dynamic Inversion](https://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&page=show_problem&problem=3141)
|
||||
- [SPOJ - Give Away](http://www.spoj.com/problems/GIVEAWAY/)
|
||||
- [Codeforces - Till I Collapse](http://codeforces.com/contest/786/problem/C)
|
||||
- [Codeforces - Destiny](http://codeforces.com/contest/840/problem/D)
|
||||
- [Codeforces - Holes](http://codeforces.com/contest/13/problem/E)
|
||||
- [Codeforces - XOR and Favorite Number](https://codeforces.com/problemset/problem/617/E)
|
||||
- [Codeforces - Powerful array](http://codeforces.com/problemset/problem/86/D)
|
||||
- [SPOJ - DQUERY](https://www.spoj.com/problems/DQUERY)
|
||||
|
||||
**本页面主要译自博文 [Sqrt-декомпозиция](http://e-maxx.ru/algo/sqrt_decomposition) 与其英文翻译版 [Sqrt Decomposition](https://cp-algorithms.com/data_structures/sqrt_decomposition.html)。其中俄文版版权协议为 Public Domain + Leave a Link;英文版版权协议为 CC-BY-SA 4.0。**
|
||||
|
|
|
|||
|
|
@ -18,8 +18,8 @@
|
|||
|
||||
**排列**:定义一个 $n$ 阶排列 $P$ 是一个大小为 $n$ 的序列,使得 $P_i$ 取遍 $1,2,\cdots,n$。说得形式化一点,$n$ 阶排列 $P$ 是一个有序集合满足:
|
||||
|
||||
1. $|P|=n$.
|
||||
2. $\forall i,P_i\in[1,n]$.
|
||||
1. $|P|=n$.
|
||||
2. $\forall i,P_i\in[1,n]$.
|
||||
3. $\nexists i,j\in[1,n],P_i=P_j$.
|
||||
|
||||
**连续段**:对于排列 $P$,定义连续段 $(P,[l,r])$ 表示一个区间 $[l,r]$,要求 $P_{l\sim r}$ 值域是连续的。说得更形式化一点,对于排列 $P$,连续段表示一个区间 $[l,r]$ 满足:
|
||||
|
|
@ -38,11 +38,11 @@ $$
|
|||
|
||||
定义 $A=(P,[a,b]),B=(P,[x,y])$,且 $A,B\in I_P$。于是连续段的关系和运算可以表示为:
|
||||
|
||||
1. $A\subseteq B\iff x\le a\wedge b\le y$.
|
||||
2. $A=B\iff a=x\wedge b=y$.
|
||||
3. $A\cap B=(P,[\max(a,x),\min(b,y)])$.
|
||||
4. $A\cup B=(P,[\min(a,x),\max(b,y)])$.
|
||||
5. $A\setminus B=(P,\{i|i\in[a,b]\wedge i\notin[x,y]\})$.
|
||||
1. $A\subseteq B\iff x\le a\wedge b\le y$.
|
||||
2. $A=B\iff a=x\wedge b=y$.
|
||||
3. $A\cap B=(P,[\max(a,x),\min(b,y)])$.
|
||||
4. $A\cup B=(P,[\min(a,x),\max(b,y)])$.
|
||||
5. $A\setminus B=(P,\{i|i\in[a,b]\wedge i\notin[x,y]\})$.
|
||||
|
||||
其实这些运算就是普通的集合交并差放在区间上而已。
|
||||
|
||||
|
|
@ -76,11 +76,11 @@ $$
|
|||
|
||||
这里我们直接给出定义,稍候再来讨论它的正确性。
|
||||
|
||||
1. **值域区间**:对于一个结点 $u$,用 $[u_l,u_r]$ 表示该结点的值域区间。
|
||||
2. **儿子序列**:对于析合树上的一个结点 $u$,假设它的儿子结点是一个 **有序** 序列,该序列是以值域区间为元素的(单个的数 $x$ 可以理解为 $[x,x]$ 的区间)。我们把这个序列称为儿子序列。记作 $S_u$。
|
||||
3. **儿子排列**:对于一个儿子序列 $S_u$,把它的元素离散化成正整数后形成的排列称为儿子排列。举个例子,对于结点 $[5,8]$,它的儿子序列为 $\{[5,5],[6,7],[8,8]\}$,那么把区间排序标个号,则它的儿子排列就为 $\{1,2,3\}$;类似的,结点 $[4,8]$ 的儿子排列为 $\{2,1\}$。结点 $u$ 的儿子排列记为 $P_u$。
|
||||
4. **合点**:我们认为,儿子排列为顺序或者逆序的点为合点。形式化地说,满足 $P_u=\{1,2,\cdots,|S_u|\}$ 或者 $P_u=\{|S_u|,|S_u-1|,\cdots,1\}$ 的点称为合点。**叶子结点没有儿子排列,我们也认为它是合点**。
|
||||
5. **析点**:不是合点的就是析点。
|
||||
1. **值域区间**:对于一个结点 $u$,用 $[u_l,u_r]$ 表示该结点的值域区间。
|
||||
2. **儿子序列**:对于析合树上的一个结点 $u$,假设它的儿子结点是一个 **有序** 序列,该序列是以值域区间为元素的(单个的数 $x$ 可以理解为 $[x,x]$ 的区间)。我们把这个序列称为儿子序列。记作 $S_u$。
|
||||
3. **儿子排列**:对于一个儿子序列 $S_u$,把它的元素离散化成正整数后形成的排列称为儿子排列。举个例子,对于结点 $[5,8]$,它的儿子序列为 $\{[5,5],[6,7],[8,8]\}$,那么把区间排序标个号,则它的儿子排列就为 $\{1,2,3\}$;类似的,结点 $[4,8]$ 的儿子排列为 $\{2,1\}$。结点 $u$ 的儿子排列记为 $P_u$。
|
||||
4. **合点**:我们认为,儿子排列为顺序或者逆序的点为合点。形式化地说,满足 $P_u=\{1,2,\cdots,|S_u|\}$ 或者 $P_u=\{|S_u|,|S_u-1|,\cdots,1\}$ 的点称为合点。**叶子结点没有儿子排列,我们也认为它是合点**。
|
||||
5. **析点**:不是合点的就是析点。
|
||||
|
||||
从图中可以看到,只有 $[1,10]$ 不是合点。因为 $[1,10]$ 的儿子排列是 $\{3,1,4,2\}$。
|
||||
|
||||
|
|
@ -106,9 +106,9 @@ $$
|
|||
|
||||
我们考虑增量法。用一个栈维护前 $i-1$ 个元素构成的析合森林。在这里我需要 **着重强调**,析合森林的意思是,在任何时侯,栈中结点要么是析点要么是合点。现在考虑当前结点 $P_i$。
|
||||
|
||||
1. 我们先判断它能否成为栈顶结点的儿子,如果能就变成栈顶的儿子,然后把栈顶取出,作为当前结点。重复上述过程直到栈空或者不能成为栈顶结点的儿子。
|
||||
2. 如果不能成为栈顶的儿子,就看能不能把栈顶的若干个连续的结点都合并成一个结点(判断能否合并的方法在后面),把合并后的点,作为当前结点。
|
||||
3. 重复上述过程直到不能进行为止。然后结束此次增量,直接把当前结点压栈。
|
||||
1. 我们先判断它能否成为栈顶结点的儿子,如果能就变成栈顶的儿子,然后把栈顶取出,作为当前结点。重复上述过程直到栈空或者不能成为栈顶结点的儿子。
|
||||
2. 如果不能成为栈顶的儿子,就看能不能把栈顶的若干个连续的结点都合并成一个结点(判断能否合并的方法在后面),把合并后的点,作为当前结点。
|
||||
3. 重复上述过程直到不能进行为止。然后结束此次增量,直接把当前结点压栈。
|
||||
|
||||
接下来我们仔细解释一下。
|
||||
|
||||
|
|
@ -118,9 +118,9 @@ $$
|
|||
|
||||
如果无法成为栈顶结点的儿子,那么我们就看栈顶连续的若干个点能否与当前点一起合并。设 $l$ 为当前点所在区间的左端点。我们计算 $L_i$ 表示右端点下标为 $i$ 的连续段中,左端点 $< l$ 的最大值。当前结点为 $P_i$,栈顶结点记为 $t$。
|
||||
|
||||
1. 如果 $L_i$ 不存在,那么显然当前结点无法合并;
|
||||
2. 如果 $t_l=L_i$,那么这就是两个结点合并,合并后就是一个 **合点**;
|
||||
3. 否则在栈中一定存在一个点 $t'$ 的左端点 ${t'}_l=L_i$,那么一定可以从当前结点合并到 $t’$ 形成一个 **析点**;
|
||||
1. 如果 $L_i$ 不存在,那么显然当前结点无法合并;
|
||||
2. 如果 $t_l=L_i$,那么这就是两个结点合并,合并后就是一个 **合点**;
|
||||
3. 否则在栈中一定存在一个点 $t'$ 的左端点 ${t'}_l=L_i$,那么一定可以从当前结点合并到 $t’$ 形成一个 **析点**;
|
||||
|
||||
#### 判断能否合并
|
||||
|
||||
|
|
@ -152,10 +152,10 @@ $$
|
|||
|
||||
因此我们对 $Q$ 的维护可以这样描述:
|
||||
|
||||
1. 找到最大的 $j$ 使得 $P_{j}>P_{i+1}$,那么显然,$P_{j+1\sim i}$ 这一段数全部小于 $P_{i+1}$,于是就需要更新 $Q_{j+1\sim i}$ 的最大值。由于 $P_{i},\max(P_i,P_{i-1}),\max(P_i,P_{i-1},P_{i-2}),\cdots,\max(P_i,P_{i-1},\cdots,P_{j+1})$ 是(非严格)单调递增的,因此可以每一段相同的 $\max$ 做相同的更新,即区间加操作。
|
||||
2. 更新 $\min$ 同理。
|
||||
3. 把每一个 $Q_j$ 都减 $1$。因为区间长度加 $1$。
|
||||
4. 查询 $L_i$:即查询 $Q$ 的最小值的所在的 **下标**。
|
||||
1. 找到最大的 $j$ 使得 $P_{j}>P_{i+1}$,那么显然,$P_{j+1\sim i}$ 这一段数全部小于 $P_{i+1}$,于是就需要更新 $Q_{j+1\sim i}$ 的最大值。由于 $P_{i},\max(P_i,P_{i-1}),\max(P_i,P_{i-1},P_{i-2}),\cdots,\max(P_i,P_{i-1},\cdots,P_{j+1})$ 是(非严格)单调递增的,因此可以每一段相同的 $\max$ 做相同的更新,即区间加操作。
|
||||
2. 更新 $\min$ 同理。
|
||||
3. 把每一个 $Q_j$ 都减 $1$。因为区间长度加 $1$。
|
||||
4. 查询 $L_i$:即查询 $Q$ 的最小值的所在的 **下标**。
|
||||
|
||||
没错,我们可以使用线段树维护 $Q$!现在还有一个问题:怎么找到相同的一段使得他们的 $\max/\min$ 都相同?使用单调栈维护!维护两个单调栈分别表示 $\max/\min$。那么显然,栈中以相邻两个元素为端点的区间的 $\max/\min$ 是相同的,于是在维护单调栈的时侯顺便更新线段树即可。
|
||||
|
||||
|
|
|
|||
|
|
@ -18,10 +18,10 @@ author: Xarfa
|
|||
|
||||
两个关键数组:
|
||||
|
||||
tree[log(N),N]:也就是树,要存下所有的值,空间复杂度 $O(n\log n)$。
|
||||
toleft[log(N),n]:也就是每一层 1~i 进入左儿子的数量,这里需要理解一下,这是一个前缀和。
|
||||
tree\[log(N),N]: 也就是树,要存下所有的值,空间复杂度 $O(n\log n)$。
|
||||
toleft\[log(N),n]: 也就是每一层 1\~i 进入左儿子的数量,这里需要理解一下,这是一个前缀和。
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```pascal
|
||||
procedure Build(left,right,deep:longint); // left,right 表示区间左右端点,deep是第几层
|
||||
var
|
||||
|
|
@ -64,7 +64,7 @@ toleft[log(N),n]:也就是每一层 1~i 进入左儿子的数量,这里
|
|||
|
||||

|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```pascal
|
||||
function Query(left,right,k,l,r,deep:longint):longint;
|
||||
var
|
||||
|
|
@ -94,7 +94,7 @@ toleft[log(N),n]:也就是每一层 1~i 进入左儿子的数量,这里
|
|||
|
||||
## 划分树的应用
|
||||
|
||||
例题:[Luogu P3157\[CQOI2011\]动态逆序对](https://www.luogu.com.cn/problem/P3157)
|
||||
例题:[Luogu P3157\[CQOI2011\] 动态逆序对](https://www.luogu.com.cn/problem/P3157)
|
||||
|
||||
> 题意简述:给定一个 $n$ 个元素的排列($n\leq 10^5$),有 m 次询问($m\leq 5\times 10^4$),每次删去排列中的一个数,求删去这个数之后排列的逆序对个数。
|
||||
|
||||
|
|
|
|||
|
|
@ -69,10 +69,10 @@ $$
|
|||
|
||||
设操作前 $c$ 的势能为 $\Phi(c)$,操作后为 $\Phi(c')$,这里 $c$ 可以是任意一个 $rnk(c)>0$ 的非根节点,操作可以是任意操作,包括下面的 find 操作。我们分三种情况讨论。
|
||||
|
||||
1. $iter(c)$ 和 $level(c)$ 并未增加。显然有 $\Phi(c)=\Phi(c')$。
|
||||
2. $iter(c)$ 增加了,$level(c)$ 并未增加。这里 $iter(c)$ 至少增加一,即 $\Phi(c')\leq \Phi(c)-1$,势能函数减少了,并且至少减少 1。
|
||||
3. $level(c)$ 增加了,$iter(c)$ 可能减少。但是由于 $0<iter(c)\leq rnk(c)$,$iter(c)$ 最多减少 $rnk(c)-1$,而 $level(c)$ 至少增加 $1$。由定义 $\Phi(c)=(\alpha(n)-level(c))\times rnk(c)-iter(c)$,可得 $\Phi(c')\leq\Phi(c)-1$。
|
||||
4. 其他情况。由于 $rnk(c)$ 不变,$rnk(fa(c))$ 不减,所以不存在。
|
||||
1. $iter(c)$ 和 $level(c)$ 并未增加。显然有 $\Phi(c)=\Phi(c')$。
|
||||
2. $iter(c)$ 增加了,$level(c)$ 并未增加。这里 $iter(c)$ 至少增加一,即 $\Phi(c')\leq \Phi(c)-1$,势能函数减少了,并且至少减少 1。
|
||||
3. $level(c)$ 增加了,$iter(c)$ 可能减少。但是由于 $0<iter(c)\leq rnk(c)$,$iter(c)$ 最多减少 $rnk(c)-1$,而 $level(c)$ 至少增加 $1$。由定义 $\Phi(c)=(\alpha(n)-level(c))\times rnk(c)-iter(c)$,可得 $\Phi(c')\leq\Phi(c)-1$。
|
||||
4. 其他情况。由于 $rnk(c)$ 不变,$rnk(fa(c))$ 不减,所以不存在。
|
||||
|
||||
所以,势能增加的节点仅可能是 $x$ 或 $y$。而 $x$ 从树根变成了非树根,如果 $rnk(x)=0$,则一直有 $\Phi(x)=\Phi(x')=0$。否则,一定有 $\alpha(x)\times rnk(x)\geq(\alpha(n)-level(x))\times rnk(x)-iter(x)$。即,$\Phi(x')\leq \Phi(x)$。
|
||||
|
||||
|
|
@ -136,9 +136,9 @@ $$
|
|||
|
||||
首先,可以从秩参与证明的性质来说明。如果 $size$ 可以代替 $rnk$ 的地位,则可以使用启发式合并。快速总结一下,秩参与证明的性质有以下三条:
|
||||
|
||||
1. 每次合并,最多有一个节点的秩上升,而且最多上升 1。
|
||||
2. 总有 $rnk(fa(x))\geq rnk(x)+1$。
|
||||
3. 节点的秩不减。
|
||||
1. 每次合并,最多有一个节点的秩上升,而且最多上升 1。
|
||||
2. 总有 $rnk(fa(x))\geq rnk(x)+1$。
|
||||
3. 节点的秩不减。
|
||||
|
||||
关于第二条和第三条,$siz$ 显然满足,然而第一条不满足,如果将 $x$ 合并到 $y$ 上面,则 $siz(y)$ 会增大 $siz(x)$ 那么多。
|
||||
|
||||
|
|
|
|||
|
|
@ -8,19 +8,19 @@ author: HeRaNO, JuicyMio, Xeonacid, sailordiary, ouuan
|
|||
|
||||
顾名思义,并查集支持两种操作:
|
||||
|
||||
- 合并(Union):合并两个元素所属集合(合并对应的树)
|
||||
- 查询(Find):查询某个元素所属集合(查询对应的树的根节点),这可以用于判断两个元素是否属于同一集合
|
||||
- 合并(Union):合并两个元素所属集合(合并对应的树)
|
||||
- 查询(Find):查询某个元素所属集合(查询对应的树的根节点),这可以用于判断两个元素是否属于同一集合
|
||||
|
||||
并查集在经过修改后可以支持单个元素的删除、移动;使用动态开点线段树还可以实现可持久化并查集。
|
||||
|
||||
!!! warning
|
||||
??? warning
|
||||
并查集无法以较低复杂度实现集合的分离。
|
||||
|
||||
## 初始化
|
||||
|
||||
初始时,每个元素都位于一个单独的集合,表示为一棵只有根节点的树。方便起见,我们将根节点的父亲设为自己。
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
=== "C++"
|
||||
|
||||
```cpp
|
||||
|
|
@ -45,7 +45,7 @@ author: HeRaNO, JuicyMio, Xeonacid, sailordiary, ouuan
|
|||
|
||||

|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
=== "C++"
|
||||
|
||||
```cpp
|
||||
|
|
@ -65,7 +65,7 @@ author: HeRaNO, JuicyMio, Xeonacid, sailordiary, ouuan
|
|||
|
||||

|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
=== "C++"
|
||||
|
||||
```cpp
|
||||
|
|
@ -87,7 +87,7 @@ author: HeRaNO, JuicyMio, Xeonacid, sailordiary, ouuan
|
|||
|
||||

|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
=== "C++"
|
||||
|
||||
```cpp
|
||||
|
|
@ -110,13 +110,13 @@ author: HeRaNO, JuicyMio, Xeonacid, sailordiary, ouuan
|
|||
|
||||
当然,我们不总能遇到恰好如上所述的集合——点数与深度都更小。鉴于点数与深度这两个特征都很容易维护,我们常常从中择一,作为估价函数。而无论选择哪一个,时间复杂度都为 $O (m\alpha(m,n))$,具体的证明可参见 References 中引用的论文。
|
||||
|
||||
在算法竞赛的实际代码中,即便不使用启发式合并,代码也往往能够在规定时间内完成任务。在 Tarjan 的论文[1]中,证明了不使用启发式合并、只使用路径压缩的最坏时间复杂度是 $O (m \log n)$。在姚期智的论文[2]中,证明了不使用启发式合并、只使用路径压缩,在平均情况下,时间复杂度依然是 $O (m\alpha(m,n))$。
|
||||
在算法竞赛的实际代码中,即便不使用启发式合并,代码也往往能够在规定时间内完成任务。在 Tarjan 的论文 \[1] 中,证明了不使用启发式合并、只使用路径压缩的最坏时间复杂度是 $O (m \log n)$。在姚期智的论文 \[2] 中,证明了不使用启发式合并、只使用路径压缩,在平均情况下,时间复杂度依然是 $O (m\alpha(m,n))$。
|
||||
|
||||
如果只使用启发式合并,而不使用路径压缩,时间复杂度为 $O(m\log n)$。由于路径压缩单次合并可能造成大量修改,有时路径压缩并不适合使用。例如,在可持久化并查集、线段树分治 + 并查集中,一般使用只启发式合并的并查集。
|
||||
|
||||
按节点数合并的参考实现:
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
=== "C++"
|
||||
|
||||
```cpp
|
||||
|
|
@ -159,7 +159,7 @@ author: HeRaNO, JuicyMio, Xeonacid, sailordiary, ouuan
|
|||
|
||||
要删除一个叶子节点,我们可以将其父亲设为自己。为了保证要删除的元素都是叶子,我们可以预先为每个节点制作副本,并将其副本作为父亲。
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
=== "C++"
|
||||
|
||||
```cpp
|
||||
|
|
@ -195,7 +195,7 @@ author: HeRaNO, JuicyMio, Xeonacid, sailordiary, ouuan
|
|||
|
||||
与删除类似,通过以副本作为父亲,保证要移动的元素都是叶子。
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
=== "C++"
|
||||
|
||||
```cpp
|
||||
|
|
@ -243,12 +243,12 @@ $A(m, n) = \begin{cases}n+1&\text{if }m=0\\A(m-1,1)&\text{if }m>0\text{ and }n=0
|
|||
|
||||
## 例题
|
||||
|
||||
???+note "[UVA11987 Almost Union-Find](https://www.luogu.com.cn/problem/UVA11987)"
|
||||
???+ note "[UVA11987 Almost Union-Find](https://www.luogu.com.cn/problem/UVA11987)"
|
||||
实现类似并查集的数据结构,支持以下操作:
|
||||
|
||||
1. 合并两个元素所属集合
|
||||
2. 移动单个元素
|
||||
3. 查询某个元素所属集合的大小及元素和
|
||||
1. 合并两个元素所属集合
|
||||
2. 移动单个元素
|
||||
3. 查询某个元素所属集合的大小及元素和
|
||||
|
||||
??? note "参考代码"
|
||||
=== "C++"
|
||||
|
|
@ -281,7 +281,7 @@ $A(m, n) = \begin{cases}n+1&\text{if }m=0\\A(m-1,1)&\text{if }m>0\text{ and }n=0
|
|||
|
||||
## 参考资料与拓展阅读
|
||||
|
||||
- [1]Tarjan, R. E., & Van Leeuwen, J. (1984). Worst-case analysis of set union algorithms. Journal of the ACM (JACM), 31(2), 245-281.[ResearchGate PDF](https://www.researchgate.net/profile/Jan_Van_Leeuwen2/publication/220430653_Worst-case_Analysis_of_Set_Union_Algorithms/links/0a85e53cd28bfdf5eb000000/Worst-case-Analysis-of-Set-Union-Algorithms.pdf)
|
||||
- [2]Yao, A. C. (1985). On the expected performance of path compression algorithms.[SIAM Journal on Computing, 14(1), 129-133.](https://epubs.siam.org/doi/abs/10.1137/0214010?journalCode=smjcat)
|
||||
- [3][知乎回答:是否在并查集中真的有二分路径压缩优化?](<https://www.zhihu.com/question/28410263/answer/40966441>)
|
||||
- [4]Gabow, H. N., & Tarjan, R. E. (1985). A Linear-Time Algorithm for a Special Case of Disjoint Set Union. JOURNAL OF COMPUTER AND SYSTEM SCIENCES, 30, 209-221.[PDF](https://dl.acm.org/doi/pdf/10.1145/800061.808753)
|
||||
- \[1]Tarjan, R. E., & Van Leeuwen, J. (1984). Worst-case analysis of set union algorithms. Journal of the ACM (JACM), 31(2), 245-281.[ResearchGate PDF](https://www.researchgate.net/profile/Jan_Van_Leeuwen2/publication/220430653_Worst-case_Analysis_of_Set_Union_Algorithms/links/0a85e53cd28bfdf5eb000000/Worst-case-Analysis-of-Set-Union-Algorithms.pdf)
|
||||
- \[2]Yao, A. C. (1985). On the expected performance of path compression algorithms.[SIAM Journal on Computing, 14(1), 129-133.](https://epubs.siam.org/doi/abs/10.1137/0214010?journalCode=smjcat)
|
||||
- \[3][知乎回答:是否在并查集中真的有二分路径压缩优化?](https://www.zhihu.com/question/28410263/answer/40966441)
|
||||
- \[4]Gabow, H. N., & Tarjan, R. E. (1985). A Linear-Time Algorithm for a Special Case of Disjoint Set Union. JOURNAL OF COMPUTER AND SYSTEM SCIENCES, 30, 209-221.[PDF](https://dl.acm.org/doi/pdf/10.1145/800061.808753)
|
||||
|
|
|
|||
|
|
@ -206,7 +206,7 @@ void Delete(int u, int v) {
|
|||
|
||||
点 $u$ 和点 $v$ 连通,当且仅当两个点属于同一棵树 $T$,即 $(u, u)$ 和 $(v, v)$ 属于 $\operatorname{ETR}(T)$,这可以根据点 $u$ 和点 $v$ 对应的 Treap 节点所在的 Treap 的根是否相同判断。
|
||||
|
||||
### 例题 [P2147\[SDOI2008\]洞穴勘测](https://www.luogu.com.cn/problem/P2147)
|
||||
### 例题 [P2147\[SDOI2008\] 洞穴勘测](https://www.luogu.com.cn/problem/P2147)
|
||||
|
||||
维护连通性的模板题。
|
||||
|
||||
|
|
@ -251,5 +251,5 @@ void Delete(int u, int v) {
|
|||
|
||||
## 参考资料
|
||||
|
||||
- Dynamic trees as search trees via euler tours, applied to the network simplex algorithm - Robert E. Tarjan
|
||||
- Randomized fully dynamic graph algorithms with polylogarithmic time per operation - Henzinger et al.
|
||||
- Dynamic trees as search trees via euler tours, applied to the network simplex algorithm - Robert E. Tarjan
|
||||
- Randomized fully dynamic graph algorithms with polylogarithmic time per operation - Henzinger et al.
|
||||
|
|
|
|||
|
|
@ -9,30 +9,29 @@ author: HeRaNO, Zhoier, Ir1d, Xeonacid, wangdehu, ouuan, ranwen, ananbaobeichicu
|
|||
|
||||
已知一个数列 $a$,你需要进行下面两种操作:
|
||||
|
||||
- 给定 $x, y$,将 $a[x]$ 自增 $y$。
|
||||
|
||||
- 给定 $l, r$,求解 $a[l \ldots r]$ 的和。
|
||||
- 给定 $x, y$,将 $a[x]$ 自增 $y$。
|
||||
- 给定 $l, r$,求解 $a[l \ldots r]$ 的和。
|
||||
|
||||
其中第一种操作就是「单点修改」,第二种操作就是「区间查询」。
|
||||
|
||||
类似地,还有:「区间修改」、「单点查询」。它们分别的一个例子如下:
|
||||
|
||||
- 区间修改:给定 $l, r, x$,将 $a[l \ldots r]$ 中的每个数都分别自增 $x$;
|
||||
- 单点查询:给定 $x$,求解 $a[x]$ 的值。
|
||||
- 区间修改:给定 $l, r, x$,将 $a[l \ldots r]$ 中的每个数都分别自增 $x$;
|
||||
- 单点查询:给定 $x$,求解 $a[x]$ 的值。
|
||||
|
||||
注意到,区间问题一般严格强于单点问题,因为对单点的操作相当于对一个长度为 $1$ 的区间操作。
|
||||
|
||||
普通树状数组维护的信息及运算要满足 **结合律** 且 **可差分**,如加法(和)、乘法(积)、异或等。
|
||||
|
||||
- 结合律:$(x \circ y) \circ z = x \circ (y \circ z)$,其中 $\circ$ 是一个二元运算符。
|
||||
- 可差分:具有逆运算的运算,即已知 $x \circ y$ 和 $x$ 可以求出 $y$。
|
||||
- 结合律:$(x \circ y) \circ z = x \circ (y \circ z)$,其中 $\circ$ 是一个二元运算符。
|
||||
- 可差分:具有逆运算的运算,即已知 $x \circ y$ 和 $x$ 可以求出 $y$。
|
||||
|
||||
需要注意的是:
|
||||
|
||||
- 模意义下的乘法若要可差分,需保证每个数都存在逆元(模数为质数时一定存在);
|
||||
- 模意义下的乘法若要可差分,需保证每个数都存在逆元(模数为质数时一定存在);
|
||||
- 例如 $\gcd$,$\max$ 这些信息不可差分,所以不能用普通树状数组处理,但是:
|
||||
- 使用两个树状数组可以用于处理区间最值,见 [Efficient Range Minimum Queries using Binary Indexed Trees](http://history.ioinformatics.org/oi/files/volume9.pdf#page=41)。
|
||||
- 本页面也会介绍一种支持不可差分信息查询的,$\Theta(\log^2n)$ 时间复杂度的拓展树状数组。
|
||||
- 使用两个树状数组可以用于处理区间最值,见 [Efficient Range Minimum Queries using Binary Indexed Trees](http://history.ioinformatics.org/oi/files/volume9.pdf#page=41)。
|
||||
- 本页面也会介绍一种支持不可差分信息查询的,$\Theta(\log^2n)$ 时间复杂度的拓展树状数组。
|
||||
|
||||
事实上,树状数组能解决的问题是线段树能解决的问题的子集:树状数组能做的,线段树一定能做;线段树能做的,树状数组不一定可以。然而,树状数组的代码要远比线段树短,时间效率常数也更小,因此仍有学习价值。
|
||||
|
||||
|
|
@ -64,11 +63,11 @@ $c$ 数组就是用来储存原始数组 $a$ 某段区间的和的,也就是
|
|||
|
||||
例如,从图中可以看出:
|
||||
|
||||
- $c_2$ 管辖的是 $a[1 \ldots 2]$;
|
||||
- $c_4$ 管辖的是 $a[1 \ldots 4]$;
|
||||
- $c_6$ 管辖的是 $a[5 \ldots 6]$;
|
||||
- $c_8$ 管辖的是 $a[1 \ldots 8]$;
|
||||
- 剩下的 $c[x]$ 管辖的都是 $a[x]$ 自己(可以看做 $a[x \ldots x]$ 的长度为 $1$ 的小区间)。
|
||||
- $c_2$ 管辖的是 $a[1 \ldots 2]$;
|
||||
- $c_4$ 管辖的是 $a[1 \ldots 4]$;
|
||||
- $c_6$ 管辖的是 $a[5 \ldots 6]$;
|
||||
- $c_8$ 管辖的是 $a[1 \ldots 8]$;
|
||||
- 剩下的 $c[x]$ 管辖的都是 $a[x]$ 自己(可以看做 $a[x \ldots x]$ 的长度为 $1$ 的小区间)。
|
||||
|
||||
不难发现,$c[x]$ 管辖的一定是一段右边界是 $x$ 的区间总信息。我们先不关心左边界,先来感受一下树状数组是如何查询的。
|
||||
|
||||
|
|
@ -92,8 +91,8 @@ $c$ 数组就是用来储存原始数组 $a$ 某段区间的和的,也就是
|
|||
|
||||
树状数组中,规定 $c[x]$ 管辖的区间长度为 $2^{k}$,其中:
|
||||
|
||||
- 设二进制最低位为第 $0$ 位,则 $k$ 恰好为 $x$ 二进制表示中,最低位的 `1` 所在的二进制位数;
|
||||
- $2^k$($c[x]$ 的管辖区间长度)恰好为 $x$ 二进制表示中,最低位的 `1` 以及后面所有 `0` 组成的数。
|
||||
- 设二进制最低位为第 $0$ 位,则 $k$ 恰好为 $x$ 二进制表示中,最低位的 `1` 所在的二进制位数;
|
||||
- $2^k$($c[x]$ 的管辖区间长度)恰好为 $x$ 二进制表示中,最低位的 `1` 以及后面所有 `0` 组成的数。
|
||||
|
||||
举个例子,$c_{88}$ 管辖的是哪个区间?
|
||||
|
||||
|
|
@ -114,7 +113,7 @@ $c$ 数组就是用来储存原始数组 $a$ 某段区间的和的,也就是
|
|||
|
||||
`(...)` 和 `[...]` 中省略号的每一位分别相反,所以 `x & -x = (...)10...00 & [...]10...00 = 10...00`,得到的结果就是 `lowbit`。
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
=== "C++"
|
||||
|
||||
```cpp
|
||||
|
|
@ -162,15 +161,15 @@ $c$ 数组就是用来储存原始数组 $a$ 某段区间的和的,也就是
|
|||
|
||||
我们可以写出查询 $a[1 \ldots x]$ 的过程:
|
||||
|
||||
- 从 $c[x]$ 开始往前跳,有 $c[x]$ 管辖 $a[x-\operatorname{lowbit}(x)+1 \ldots x]$;
|
||||
- 令 $x \gets x - \operatorname{lowbit}(x)$,如果 $x = 0$ 说明已经跳到尽头了,终止循环;否则回到第一步。
|
||||
- 将跳到的 $c$ 合并。
|
||||
- 从 $c[x]$ 开始往前跳,有 $c[x]$ 管辖 $a[x-\operatorname{lowbit}(x)+1 \ldots x]$;
|
||||
- 令 $x \gets x - \operatorname{lowbit}(x)$,如果 $x = 0$ 说明已经跳到尽头了,终止循环;否则回到第一步。
|
||||
- 将跳到的 $c$ 合并。
|
||||
|
||||
实现时,我们不一定要先把 $c$ 都跳出来然后一起合并,可以边跳边合并。
|
||||
|
||||
比如我们要维护的信息是和,直接令初始 $\mathrm{ans} = 0$,然后每跳到一个 $c[x]$ 就 $\mathrm{ans} \gets \mathrm{ans} + c[x]$,最终 $\mathrm{ans}$ 就是所有合并的结果。
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
=== "C++"
|
||||
|
||||
```cpp
|
||||
|
|
@ -201,9 +200,9 @@ $c$ 数组就是用来储存原始数组 $a$ 某段区间的和的,也就是
|
|||
|
||||
我们约定:
|
||||
|
||||
- $l(x) = x - \operatorname{lowbit}(x) + 1$。即,$l(x)$ 是 $c[x]$ 管辖范围的左端点。
|
||||
- 对于任意正整数 $x$,总能将 $x$ 表示成 $s \times 2^{k + 1} + 2^k$ 的形式,其中 $\operatorname{lowbit}(x) = 2^k$。
|
||||
- 下面「$c[x]$ 和 $c[y]$ 不交」指 $c[x]$ 的管辖范围和 $c[y]$ 的管辖范围不相交,即 $[l(x), x]$ 和 $[l(y), y]$ 不相交。「$c[x]$ 包含于 $c[y]$」等表述同理。
|
||||
- $l(x) = x - \operatorname{lowbit}(x) + 1$。即,$l(x)$ 是 $c[x]$ 管辖范围的左端点。
|
||||
- 对于任意正整数 $x$,总能将 $x$ 表示成 $s \times 2^{k + 1} + 2^k$ 的形式,其中 $\operatorname{lowbit}(x) = 2^k$。
|
||||
- 下面「$c[x]$ 和 $c[y]$ 不交」指 $c[x]$ 的管辖范围和 $c[y]$ 的管辖范围不相交,即 $[l(x), x]$ 和 $[l(y), y]$ 不相交。「$c[x]$ 包含于 $c[y]$」等表述同理。
|
||||
|
||||
**性质 $\boldsymbol{1}$:对于 $\boldsymbol{x \le y}$,要么有 $\boldsymbol{c[x]}$ 和 $\boldsymbol{c[y]}$ 不交,要么有 $\boldsymbol{c[x]}$ 包含于 $\boldsymbol{c[y]}$。**
|
||||
|
||||
|
|
@ -248,25 +247,25 @@ $c$ 数组就是用来储存原始数组 $a$ 某段区间的和的,也就是
|
|||
|
||||
这棵树天然满足了很多美好性质,下面列举若干比较重要的(设 $fa[u]$ 表示 $u$ 的直系父亲):
|
||||
|
||||
- $u < fa[u]$。
|
||||
- $u$ 大于任何一个 $u$ 的后代,小于任何一个 $u$ 的祖先。
|
||||
- 点 $u$ 的 $\operatorname{lowbit}$ 严格小于 $fa[u]$ 的 $\operatorname{lowbit}$。
|
||||
- $u < fa[u]$。
|
||||
- $u$ 大于任何一个 $u$ 的后代,小于任何一个 $u$ 的祖先。
|
||||
- 点 $u$ 的 $\operatorname{lowbit}$ 严格小于 $fa[u]$ 的 $\operatorname{lowbit}$。
|
||||
|
||||
??? note "证明"
|
||||
设 $y = x + \operatorname{lowbit}(x)$,$x = s \times 2^{k + 1} + 2^k$,则 $y = (s + 1) \times 2^{k +1}$,不难发现 $\operatorname{lowbit}(y) \ge 2^{k + 1} > \operatorname{lowbit}(x)$,证毕。
|
||||
|
||||
- 我们认为 $c[1]$ 的高度是 $0$,则点 $x$ 的高度是 $\log_2\operatorname{lowbit}(x)$,即 $x$ 二进制最低位 `1` 的位数。
|
||||
- $c[u]$ 真包含于 $c[fa[u]]$(性质 $2$)。
|
||||
- $c[u]$ 真包含于 $c[v]$,其中 $v$ 是 $u$ 的任一祖先(在上一条性质上归纳)。
|
||||
- $c[u]$ 真包含 $c[v]$,其中 $v$ 是 $u$ 的任一后代(上面那条性质 $u$,$v$ 颠倒)。
|
||||
- 对于任意 $v' > u$,若 $v'$ 不是 $u$ 的祖先,则 $c[u]$ 和 $c[v']$ 不交。
|
||||
- 我们认为 $c[1]$ 的高度是 $0$,则点 $x$ 的高度是 $\log_2\operatorname{lowbit}(x)$,即 $x$ 二进制最低位 `1` 的位数。
|
||||
- $c[u]$ 真包含于 $c[fa[u]]$(性质 $2$)。
|
||||
- $c[u]$ 真包含于 $c[v]$,其中 $v$ 是 $u$ 的任一祖先(在上一条性质上归纳)。
|
||||
- $c[u]$ 真包含 $c[v]$,其中 $v$ 是 $u$ 的任一后代(上面那条性质 $u$,$v$ 颠倒)。
|
||||
- 对于任意 $v' > u$,若 $v'$ 不是 $u$ 的祖先,则 $c[u]$ 和 $c[v']$ 不交。
|
||||
|
||||
??? note "证明"
|
||||
$u$ 和 $u$ 的祖先中,一定存在一个点 $v$ 使得 $v < v' < fa[v]$,根据性质 $3$ 得 $c[v']$ 不相交于 $c[v]$,而 $c[v]$ 包含 $c[u]$,因此 $c[v']$ 不交于 $c[u]$。
|
||||
|
||||
- 对于任意 $v < u$,如果 $v$ 不在 $u$ 的子树上,则 $c[u]$ 和 $c[v]$ 不交(上面那条性质 $u$,$v'$ 颠倒)。
|
||||
- 对于任意 $v < u$,如果 $v$ 不在 $u$ 的子树上,则 $c[u]$ 和 $c[v]$ 不交(上面那条性质 $u$,$v'$ 颠倒)。
|
||||
- 设 $u = s \times 2^{k + 1} + 2^k$,则其儿子数量为 $k = \log_2\operatorname{lowbit}(x)$,编号分别为 $u - 2^t(0 \le t < k)$。
|
||||
- 举例:假设 $k = 3$,$u$ 的二进制编号为 `...1000`,则 $u$ 有三个儿子,二进制编号分别为 `...0111`、`...0110`、`...0100`。
|
||||
- 举例:假设 $k = 3$,$u$ 的二进制编号为 `...1000`,则 $u$ 有三个儿子,二进制编号分别为 `...0111`、`...0110`、`...0100`。
|
||||
|
||||
??? note "证明"
|
||||
在一个数 $x$ 的基础上减去 $2^t$,$x$ 二进制第 $t$ 位会反转,而更低的位保持不变。
|
||||
|
|
@ -280,11 +279,11 @@ $c$ 数组就是用来储存原始数组 $a$ 某段区间的和的,也就是
|
|||
**考虑 $\boldsymbol{t > k}$**,则 $v = u - 2^t$,$v$ 的第 $k$ 位是 $1$,所以 $\operatorname{lowbit}(v) = 2^k$,**不满足** $\operatorname{lowbit}(v) = 2^t$。
|
||||
|
||||
- $u$ 的所有儿子对应 $c$ 的管辖区间恰好拼接成 $[l(u), u - 1]$。
|
||||
- 举例:假设 $k = 3$,$u$ 的二进制编号为 `...1000`,则 $u$ 有三个儿子,二进制编号分别为 `...0111`、`...0110`、`...0100`。
|
||||
- `c[...0100]` 表示 `a[...0001 ~ ...0100]`。
|
||||
- `c[...0110]` 表示 `a[...0101 ~ ...0110]`。
|
||||
- `c[...0111]` 表示 `a[...0111 ~ ...0111]`。
|
||||
- 不难发现上面是三个管辖区间的并集恰好是 `a[...0001 ~ ...0111]`,即 $[l(u), u - 1]$。
|
||||
- 举例:假设 $k = 3$,$u$ 的二进制编号为 `...1000`,则 $u$ 有三个儿子,二进制编号分别为 `...0111`、`...0110`、`...0100`。
|
||||
- `c[...0100]` 表示 `a[...0001 ~ ...0100]`。
|
||||
- `c[...0110]` 表示 `a[...0101 ~ ...0110]`。
|
||||
- `c[...0111]` 表示 `a[...0111 ~ ...0111]`。
|
||||
- 不难发现上面是三个管辖区间的并集恰好是 `a[...0001 ~ ...0111]`,即 $[l(u), u - 1]$。
|
||||
|
||||
??? note "证明"
|
||||
$u$ 的儿子总能表示成 $u - 2^t(0 \le t < k)$,不难发现,$t$ 越小,$u - 2^t$ 越大,代表的区间越靠右。我们设 $f(t) = u - 2^t$,则 $f(k - 1), f(k - 2), \ldots, f(0)$ 分别构成 $u$ 从左到右的儿子。
|
||||
|
|
@ -309,20 +308,20 @@ $c$ 数组就是用来储存原始数组 $a$ 某段区间的和的,也就是
|
|||
|
||||
设 $n$ 表示 $a$ 的大小,不难写出单点修改 $a[x]$ 的过程:
|
||||
|
||||
- 初始令 $x' = x$。
|
||||
- 修改 $c[x']$。
|
||||
- 令 $x' \gets x' + \operatorname{lowbit}(x')$,如果 $x' > n$ 说明已经跳到尽头了,终止循环;否则回到第二步。
|
||||
- 初始令 $x' = x$。
|
||||
- 修改 $c[x']$。
|
||||
- 令 $x' \gets x' + \operatorname{lowbit}(x')$,如果 $x' > n$ 说明已经跳到尽头了,终止循环;否则回到第二步。
|
||||
|
||||
区间信息和单点修改的种类,共同决定 $c[x']$ 的修改方式。下面给几个例子:
|
||||
|
||||
- 若 $c[x']$ 维护区间和,修改种类是将 $a[x]$ 加上 $p$,则修改方式则是将所有 $c[x']$ 也加上 $p$。
|
||||
- 若 $c[x']$ 维护区间积,修改种类是将 $a[x]$ 乘上 $p$,则修改方式则是将所有 $c[x']$ 也乘上 $p$。
|
||||
- 若 $c[x']$ 维护区间和,修改种类是将 $a[x]$ 加上 $p$,则修改方式则是将所有 $c[x']$ 也加上 $p$。
|
||||
- 若 $c[x']$ 维护区间积,修改种类是将 $a[x]$ 乘上 $p$,则修改方式则是将所有 $c[x']$ 也乘上 $p$。
|
||||
|
||||
然而,单点修改的自由性使得修改的种类和维护的信息不一定是同种运算,比如,若 $c[x']$ 维护区间和,修改种类是将 $a[x]$ 赋值为 $p$,可以考虑转化为将 $a[x]$ 加上 $p - a[x]$。如果是将 $a[x]$ 乘上 $p$,就考虑转化为 $a[x]$ 加上 $a[x] \times p - a[x]$。
|
||||
|
||||
下面以维护区间和,单点加为例给出实现。
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
=== "C++"
|
||||
|
||||
```cpp
|
||||
|
|
@ -359,8 +358,8 @@ $c$ 数组就是用来储存原始数组 $a$ 某段区间的和的,也就是
|
|||
|
||||
时间复杂度:
|
||||
|
||||
- 对于区间查询操作:整个 $x \gets x - \operatorname{lowbit}(x)$ 的迭代过程,可看做将 $x$ 二进制中的所有 $1$,从低位到高位逐渐改成 $0$ 的过程,拆分出的区间数等于 $x$ 二进制中 $1$ 的数量(即 $\operatorname{popcount}(x)$)。因此,单次查询时间复杂度是 $\Theta(\log n)$;
|
||||
- 对于单点修改操作:跳父亲时,访问到的高度一直严格增加,且始终有 $x \le n$。由于点 $x$ 的高度是 $\log_2\operatorname{lowbit}(x)$,所以跳到的高度不会超过 $\log_2n$,所以访问到的 $c$ 的数量是 $\log n$ 级别。因此,单次单点修改复杂度是 $\Theta(\log n)$。
|
||||
- 对于区间查询操作:整个 $x \gets x - \operatorname{lowbit}(x)$ 的迭代过程,可看做将 $x$ 二进制中的所有 $1$,从低位到高位逐渐改成 $0$ 的过程,拆分出的区间数等于 $x$ 二进制中 $1$ 的数量(即 $\operatorname{popcount}(x)$)。因此,单次查询时间复杂度是 $\Theta(\log n)$;
|
||||
- 对于单点修改操作:跳父亲时,访问到的高度一直严格增加,且始终有 $x \le n$。由于点 $x$ 的高度是 $\log_2\operatorname{lowbit}(x)$,所以跳到的高度不会超过 $\log_2n$,所以访问到的 $c$ 的数量是 $\log n$ 级别。因此,单次单点修改复杂度是 $\Theta(\log n)$。
|
||||
|
||||
## 区间加区间和
|
||||
|
||||
|
|
@ -393,9 +392,9 @@ $\sum_{i=1}^r d_i$ 并不能推出 $\sum_{i=1}^r d_i \times i$ 的值,所以
|
|||
|
||||
因为差分是 $d[i] = a[i] - a[i - 1]$,
|
||||
|
||||
- $a[l]$ 多了 $v$ 而 $a[l - 1]$ 不变,所以 $d[l]$ 的值多了 $v$。
|
||||
- $a[r + 1]$ 不变而 $a[r]$ 多了 $v$,所以 $d[r + 1]$ 的值少了 $v$。
|
||||
- 对于不等于 $l$ 且不等于 $r+1$ 的任意 $i$,$a[i]$ 和 $a[i - 1]$ 要么都没发生变化,要么都加了 $v$,$a[i] + v - (a[i - 1] + v)$ 还是 $a[i] - a[i - 1]$,所以其它的 $d[i]$ 均不变。
|
||||
- $a[l]$ 多了 $v$ 而 $a[l - 1]$ 不变,所以 $d[l]$ 的值多了 $v$。
|
||||
- $a[r + 1]$ 不变而 $a[r]$ 多了 $v$,所以 $d[r + 1]$ 的值少了 $v$。
|
||||
- 对于不等于 $l$ 且不等于 $r+1$ 的任意 $i$,$a[i]$ 和 $a[i - 1]$ 要么都没发生变化,要么都加了 $v$,$a[i] + v - (a[i - 1] + v)$ 还是 $a[i] - a[i - 1]$,所以其它的 $d[i]$ 均不变。
|
||||
|
||||
那就不难想到维护方式了:对于维护 $d_i$ 的树状数组,对 $l$ 单点加 $v$,$r + 1$ 单点加 $-v$;对于维护 $d_i \times i$ 的树状数组,对 $l$ 单点加 $v \times l$,$r + 1$ 单点加 $-v \times (r + 1)$。
|
||||
|
||||
|
|
@ -403,7 +402,7 @@ $\sum_{i=1}^r d_i$ 并不能推出 $\sum_{i=1}^r d_i \times i$ 的值,所以
|
|||
|
||||
这里直接给出「区间加区间和」的代码:
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
=== "C++"
|
||||
|
||||
```cpp
|
||||
|
|
@ -521,7 +520,7 @@ $$
|
|||
|
||||
下面给出单点加、查询子矩阵和的代码。
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
=== "单点加"
|
||||
|
||||
```cpp
|
||||
|
|
@ -621,7 +620,7 @@ $$
|
|||
|
||||
下面给出代码:
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
typedef long long ll;
|
||||
ll t1[N][N], t2[N][N], t3[N][N], t4[N][N];
|
||||
|
|
@ -675,7 +674,7 @@ $$
|
|||
|
||||
另外,权值数组是原数组无序性的一种表示:它重点描述数组的元素内容,忽略了数组的顺序,若两数组只是顺序不同,所含内容一致,则它们的权值数组相同。
|
||||
|
||||
因此,对于给定数组的顺序不影响答案的问题,在权值数组的基础上思考一般更直观,比如 [\[NOIP2021\]数列](https://www.luogu.com.cn/problem/P7961)。
|
||||
因此,对于给定数组的顺序不影响答案的问题,在权值数组的基础上思考一般更直观,比如 [\[NOIP2021\] 数列](https://www.luogu.com.cn/problem/P7961)。
|
||||
|
||||
运用权值树状数组,我们可以解决一些经典问题。
|
||||
|
||||
|
|
@ -695,8 +694,8 @@ $$
|
|||
|
||||
设 $x = 0$,$\mathrm{sum} = 0$,枚举 $i$ 从 $\log_2n$ 降为 $0$:
|
||||
|
||||
- 查询权值数组中 $[x + 1 \ldots x + 2^i]$ 的区间和 $t$。
|
||||
- 如果 $\mathrm{sum} + t < k$,扩展成功,$x \gets x + 2^i$,$\mathrm{sum} \gets \mathrm{sum} + t$;否则扩展失败,不操作。
|
||||
- 查询权值数组中 $[x + 1 \ldots x + 2^i]$ 的区间和 $t$。
|
||||
- 如果 $\mathrm{sum} + t < k$,扩展成功,$x \gets x + 2^i$,$\mathrm{sum} \gets \mathrm{sum} + t$;否则扩展失败,不操作。
|
||||
|
||||
这样得到的 $x$ 是满足 $[1 \ldots x]$ 前缀和 $< k$ 的最大值,所以最终 $x + 1$ 就是答案。
|
||||
|
||||
|
|
@ -706,7 +705,7 @@ $$
|
|||
|
||||
如此以来,时间复杂度降低为 $\Theta(\log n)$。
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
=== "C++"
|
||||
|
||||
```cpp
|
||||
|
|
@ -750,8 +749,8 @@ $$
|
|||
|
||||
事实上,我们只需要这样做(设当前 $a[i] = x$):
|
||||
|
||||
- 查询 $b[1 \ldots x - 1]$ 的前缀和,即为左端点为 $a[i]$ 的逆序对数量。
|
||||
- $b[x]$ 自增 $1$;
|
||||
- 查询 $b[1 \ldots x - 1]$ 的前缀和,即为左端点为 $a[i]$ 的逆序对数量。
|
||||
- $b[x]$ 自增 $1$;
|
||||
|
||||
原因十分自然:出现在 $b[1 \ldots x-1]$ 中的元素一定比当前的 $x = a[i]$ 小,而 $i$ 的倒序枚举,自然使得这些已在权值数组中的元素,在原数组上的索引 $j$ 大于当前遍历到的索引 $i$。
|
||||
|
||||
|
|
@ -759,30 +758,30 @@ $$
|
|||
|
||||
$i$ 按照 $5 \to 1$ 扫:
|
||||
|
||||
- $a[5] = 1$,查询 $b[1 \ldots 0]$ 前缀和,为 $0$,$b[1]$ 自增 $1$,$b = (1, 0, 0, 0)$。
|
||||
- $a[4] = 2$,查询 $b[1 \ldots 1]$ 前缀和,为 $1$,$b[2]$ 自增 $1$,$b = (1, 1, 0, 0)$。
|
||||
- $a[3] = 1$,查询 $b[1 \ldots 0]$ 前缀和,为 $0$,$b[1]$ 自增 $1$,$b = (2, 1, 0, 0)$。
|
||||
- $a[2] = 3$,查询 $b[1 \ldots 2]$ 前缀和,为 $3$,$b[3]$ 自增 $1$,$b = (2, 1, 1, 0)$。
|
||||
- $a[1] = 4$,查询 $b[1 \ldots 3]$ 前缀和,为 $4$,$b[4]$ 自增 $1$,$b = (2, 1, 1, 1)$。
|
||||
- $a[5] = 1$,查询 $b[1 \ldots 0]$ 前缀和,为 $0$,$b[1]$ 自增 $1$,$b = (1, 0, 0, 0)$。
|
||||
- $a[4] = 2$,查询 $b[1 \ldots 1]$ 前缀和,为 $1$,$b[2]$ 自增 $1$,$b = (1, 1, 0, 0)$。
|
||||
- $a[3] = 1$,查询 $b[1 \ldots 0]$ 前缀和,为 $0$,$b[1]$ 自增 $1$,$b = (2, 1, 0, 0)$。
|
||||
- $a[2] = 3$,查询 $b[1 \ldots 2]$ 前缀和,为 $3$,$b[3]$ 自增 $1$,$b = (2, 1, 1, 0)$。
|
||||
- $a[1] = 4$,查询 $b[1 \ldots 3]$ 前缀和,为 $4$,$b[4]$ 自增 $1$,$b = (2, 1, 1, 1)$。
|
||||
|
||||
所以最终答案为 $0 + 1 + 0 + 3 + 4 = 8$。
|
||||
|
||||
注意到,遍历 $i$ 后的查询 $b[1 \ldots x - 1]$ 和自增 $b[x]$ 的两个步骤可以颠倒,变成先自增 $b[x]$ 再查询 $b[1 \ldots x - 1]$,不影响答案。两个角度来解释:
|
||||
|
||||
- 对 $b[x]$ 的修改不影响对 $b[1 \ldots x - 1]$ 的查询。
|
||||
- 颠倒后,实质是在查询 $i \le j$ 且 $a[i] > a[j]$ 的数对数量,而 $i = j$ 时不存在 $a[i] > a[j]$,所以 $i \le j$ 相当于 $i < j$,所以这与原来的逆序对问题是等价的。
|
||||
- 对 $b[x]$ 的修改不影响对 $b[1 \ldots x - 1]$ 的查询。
|
||||
- 颠倒后,实质是在查询 $i \le j$ 且 $a[i] > a[j]$ 的数对数量,而 $i = j$ 时不存在 $a[i] > a[j]$,所以 $i \le j$ 相当于 $i < j$,所以这与原来的逆序对问题是等价的。
|
||||
|
||||
如果查询非严格逆序对($i < j$ 且 $a[i] \ge a[j]$)的数量,那就要改为查询 $b[1 \ldots x]$ 的和,这时就不能颠倒两步了,还是两个角度来解释:
|
||||
|
||||
- 对 $b[x]$ 的修改 **影响** 对 $b[1 \ldots x]$ 的查询。
|
||||
- 颠倒后,实质是在查询 $i \le j$ 且 $a[i] \ge a[j]$ 的数对数量,而 $i = j$ 时恒有 $a[i] \ge a[j]$,所以 $i \le j$ **不相当于** $i < j$,与原问题 **不等价**。
|
||||
- 对 $b[x]$ 的修改 **影响** 对 $b[1 \ldots x]$ 的查询。
|
||||
- 颠倒后,实质是在查询 $i \le j$ 且 $a[i] \ge a[j]$ 的数对数量,而 $i = j$ 时恒有 $a[i] \ge a[j]$,所以 $i \le j$ **不相当于** $i < j$,与原问题 **不等价**。
|
||||
|
||||
如果查询 $i \le j$ 且 $a[i] \ge a[j]$ 的数对数量,那这两步就需要颠倒了。
|
||||
|
||||
另外,对于原逆序对问题,还有一种做法是正着枚举 $j$,查询有多少 $i < j$ 满足 $a[i] > a[j]$。做法如下(设 $x = a[j]$):
|
||||
|
||||
- 查询 $b[x + 1 \ldots V]$($V$ 是 $b$ 的大小,即 $a$ 的值域(或离散化后的值域))的区间和。
|
||||
- 将 $b[x]$ 自增 $1$。
|
||||
- 查询 $b[x + 1 \ldots V]$($V$ 是 $b$ 的大小,即 $a$ 的值域(或离散化后的值域))的区间和。
|
||||
- 将 $b[x]$ 自增 $1$。
|
||||
|
||||
原因:出现在 $b[x + 1 \ldots V]$ 中的元素一定比当前的 $x = a[j]$ 大,而 $j$ 的正序枚举,自然使得这些已在权值数组中的元素,在原数组上的索引 $i$ 小于当前遍历到的索引 $j$。
|
||||
|
||||
|
|
@ -798,12 +797,12 @@ $i$ 按照 $5 \to 1$ 扫:
|
|||
|
||||
因此,如果我们跳到了 $c[x]$,先判断下一次要跳到的 $x - \operatorname{lowbit}(x)$ 是否小于 $l$:
|
||||
|
||||
- 如果小于 $l$,我们直接把 **$\boldsymbol{a[x]}$ 单点** 合并到总信息里,然后跳到 $c[x - 1]$。
|
||||
- 如果大于等于 $l$,说明没越界,正常合并 $c[x]$,然后跳到 $c[x - \operatorname{lowbit}(x)]$ 即可。
|
||||
- 如果小于 $l$,我们直接把 **$\boldsymbol{a[x]}$ 单点** 合并到总信息里,然后跳到 $c[x - 1]$。
|
||||
- 如果大于等于 $l$,说明没越界,正常合并 $c[x]$,然后跳到 $c[x - \operatorname{lowbit}(x)]$ 即可。
|
||||
|
||||
下面以查询区间最大值为例,给出代码:
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
int getmax(int l, int r) {
|
||||
int ans = 0;
|
||||
|
|
@ -845,7 +844,7 @@ $i$ 按照 $5 \to 1$ 扫:
|
|||
|
||||
考虑 $c[y]$ 的儿子们,它们的信息一定是正确的(因为我们先更新儿子再更新父亲),而这些儿子又恰好组成了 $[l(y), y - 1]$ 这一段管辖区间,那再合并一个单点 $a[y]$ 就可以合并出 $[l(y), y]$,也就是 $c[y]$ 了。这样,我们能用至多 $\log n$ 个区间重构合并出每个需要修改的 $c$。
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
void update(int x, int v) {
|
||||
a[x] = v;
|
||||
|
|
@ -877,7 +876,7 @@ $i$ 按照 $5 \to 1$ 扫:
|
|||
|
||||
每一个节点的值是由所有与自己直接相连的儿子的值求和得到的。因此可以倒着考虑贡献,即每次确定完儿子的值后,用自己的值更新自己的直接父亲。
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
=== "C++"
|
||||
|
||||
```cpp
|
||||
|
|
@ -907,7 +906,7 @@ $i$ 按照 $5 \to 1$ 扫:
|
|||
|
||||
前面讲到 $c[i]$ 表示的区间是 $[i-\operatorname{lowbit}(i)+1, i]$,那么我们可以先预处理一个 $\mathrm{sum}$ 前缀和数组,再计算 $c$ 数组。
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
=== "C++"
|
||||
|
||||
```cpp
|
||||
|
|
@ -930,7 +929,7 @@ $i$ 按照 $5 \to 1$ 扫:
|
|||
|
||||
对付多组数据很常见的技巧。若每次输入新数据都暴力清空树状数组,就可能会造成超时。因此使用 $\mathrm{tag}$ 标记,存储当前节点上次使用时间(即最近一次是被第几组数据使用)。每次操作时判断这个位置 $\mathrm{tag}$ 中的时间和当前时间是否相同,就可以判断这个位置应该是 $0$ 还是数组内的值。
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
=== "C++"
|
||||
|
||||
```cpp
|
||||
|
|
@ -982,9 +981,9 @@ $i$ 按照 $5 \to 1$ 扫:
|
|||
|
||||
## 例题
|
||||
|
||||
- [树状数组 1:单点修改,区间查询](https://loj.ac/problem/130)
|
||||
- [树状数组 2:区间修改,单点查询](https://loj.ac/problem/131)
|
||||
- [树状数组 3:区间修改,区间查询](https://loj.ac/problem/132)
|
||||
- [二维树状数组 1:单点修改,区间查询](https://loj.ac/problem/133)
|
||||
- [二维树状数组 2:区间修改,单点查询](https://loj.ac/problem/134)
|
||||
- [二维树状数组 3:区间修改,区间查询](https://loj.ac/problem/135)
|
||||
- [树状数组 1:单点修改,区间查询](https://loj.ac/problem/130)
|
||||
- [树状数组 2:区间修改,单点查询](https://loj.ac/problem/131)
|
||||
- [树状数组 3:区间修改,区间查询](https://loj.ac/problem/132)
|
||||
- [二维树状数组 1:单点修改,区间查询](https://loj.ac/problem/133)
|
||||
- [二维树状数组 2:区间修改,单点查询](https://loj.ac/problem/134)
|
||||
- [二维树状数组 3:区间修改,区间查询](https://loj.ac/problem/135)
|
||||
|
|
|
|||
|
|
@ -17,9 +17,9 @@ author: isdanni
|
|||
|
||||
手指树在树的“手指”(叶子)的地方存储数据,访问时间为分摊常量。手指是一个可以访问部分数据结构的点。在命令式语言(imperative language)中,这被称做指针。在手指树中,“手指”是指向序列末端或叶节点的结构。手指树还在每个内部节点中存储对其后代应用一些关联操作的结果。存储在内部节点中的数据可用于提供除树类数据结构之外的功能。
|
||||
|
||||
1. 手指树的深度由下到上计算。
|
||||
2. 手指树的第一级,即树的叶节点,仅包含值,深度为 $0$。第二级为深度 $1$。第三级为深度 $2$,依此类推。
|
||||
3. 离根越近,节点指向的原始树(在它是手指树之前的树)的子树越深。这样,沿着树向下工作就是从叶子到树的根,这与典型的树数据结构相反。为了获得这种的结构,我们必须确保原始树具有统一的深度。在声明节点对象时,必须通过子节点的类型进行参数化。深度为 $1$ 及以上的脊椎上的节点指向树,通过这种参数化,它们可以由嵌套节点表示。
|
||||
1. 手指树的深度由下到上计算。
|
||||
2. 手指树的第一级,即树的叶节点,仅包含值,深度为 $0$。第二级为深度 $1$。第三级为深度 $2$,依此类推。
|
||||
3. 离根越近,节点指向的原始树(在它是手指树之前的树)的子树越深。这样,沿着树向下工作就是从叶子到树的根,这与典型的树数据结构相反。为了获得这种的结构,我们必须确保原始树具有统一的深度。在声明节点对象时,必须通过子节点的类型进行参数化。深度为 $1$ 及以上的脊椎上的节点指向树,通过这种参数化,它们可以由嵌套节点表示。
|
||||
|
||||
### 将一棵树变成手指树
|
||||
|
||||
|
|
@ -57,10 +57,10 @@ type Digit a = One a | Two a a | Three a a a | Four a a a a
|
|||
|
||||
### 双向队列操作
|
||||
|
||||
指状树也可以制作高效的双向队列。无论结构是否持久,所有操作都需要 `Θ(1)` 时间。它可以被看作是的隐式双端队列的扩展[3]:
|
||||
指状树也可以制作高效的双向队列。无论结构是否持久,所有操作都需要 `Θ(1)` 时间。它可以被看作是的隐式双端队列的扩展 \[3]:
|
||||
|
||||
1. 用 2-3 个节点替换对提供了足够的灵活性来支持有效的串联。(为了保持恒定时间的双端队列操作,必须将 Digit 扩展为四。)
|
||||
2. 用幺半群(monoid)注释内部节点允许有效的分裂。
|
||||
1. 用 2-3 个节点替换对提供了足够的灵活性来支持有效的串联。(为了保持恒定时间的双端队列操作,必须将 Digit 扩展为四。)
|
||||
2. 用幺半群(monoid)注释内部节点允许有效的分裂。
|
||||
|
||||
```haskell
|
||||
data ImplicitDeque a = Empty
|
||||
|
|
@ -95,6 +95,6 @@ data Digit a = One a | Two a a | Three a a a
|
|||
|
||||
## 参考资料与拓展阅读
|
||||
|
||||
- [1]Ralf Hinze and Ross Paterson, "[Finger trees: a simple general-purpose data structure](http://www.staff.city.ac.uk/~ross/papers/FingerTree.html)", Journal of Functional Programming 16:2 (2006) pp 197-217.
|
||||
- [2][Finger Tree - Wikipedia](<https://en.wikipedia.org/wiki/Finger_tree>)
|
||||
- [3][Purely Functional Data Structures](<https://www.cambridge.org/us/academic/subjects/computer-science/programming-languages-and-applied-logic/purely-functional-data-structures>), Chris Okasaki (1999)
|
||||
- \[1]Ralf Hinze and Ross Paterson, "[Finger trees: a simple general-purpose data structure](http://www.staff.city.ac.uk/~ross/papers/FingerTree.html)", Journal of Functional Programming 16:2 (2006) pp 197-217.
|
||||
- \[2][Finger Tree - Wikipedia](https://en.wikipedia.org/wiki/Finger_tree)
|
||||
- \[3][Purely Functional Data Structures](https://www.cambridge.org/us/academic/subjects/computer-science/programming-languages-and-applied-logic/purely-functional-data-structures), Chris Okasaki (1999)
|
||||
|
|
|
|||
|
|
@ -28,10 +28,10 @@ $$
|
|||
|
||||
霍夫曼算法用于构造一棵霍夫曼树,算法步骤如下:
|
||||
|
||||
1. **初始化**:由给定的 $n$ 个权值构造 $n$ 棵只有一个根节点的二叉树,得到一个二叉树集合 $F$。
|
||||
2. **选取与合并**:从二叉树集合 $F$ 中选取根节点权值 **最小的两棵** 二叉树分别作为左右子树构造一棵新的二叉树,这棵新二叉树的根节点的权值为其左、右子树根结点的权值和。
|
||||
3. **删除与加入**:从 $F$ 中删除作为左、右子树的两棵二叉树,并将新建立的二叉树加入到 $F$ 中。
|
||||
4. 重复 2、3 步,当集合中只剩下一棵二叉树时,这棵二叉树就是霍夫曼树。
|
||||
1. **初始化**:由给定的 $n$ 个权值构造 $n$ 棵只有一个根节点的二叉树,得到一个二叉树集合 $F$。
|
||||
2. **选取与合并**:从二叉树集合 $F$ 中选取根节点权值 **最小的两棵** 二叉树分别作为左右子树构造一棵新的二叉树,这棵新二叉树的根节点的权值为其左、右子树根结点的权值和。
|
||||
3. **删除与加入**:从 $F$ 中删除作为左、右子树的两棵二叉树,并将新建立的二叉树加入到 $F$ 中。
|
||||
4. 重复 2、3 步,当集合中只剩下一棵二叉树时,这棵二叉树就是霍夫曼树。
|
||||
|
||||

|
||||
|
||||
|
|
@ -47,9 +47,9 @@ $$
|
|||
|
||||
霍夫曼树可用于构造 **最短的前缀编码**,即 **霍夫曼编码(Huffman Code)**,其构造步骤如下:
|
||||
|
||||
1. 设需要编码的字符集为:$d_1,d_2,\dots,d_n$,他们在字符串中出现的频率为:$w_1,w_2,\dots,w_n$。
|
||||
2. 以 $d_1,d_2,\dots,d_n$ 作为叶结点,$w_1,w_2,\dots,w_n$ 作为叶结点的权值,构造一棵霍夫曼树。
|
||||
3. 规定哈夫曼编码树的左分支代表 $0$,右分支代表 $1$,则从根结点到每个叶结点所经过的路径组成的 $0$、$1$ 序列即为该叶结点对应字符的编码。
|
||||
1. 设需要编码的字符集为:$d_1,d_2,\dots,d_n$,他们在字符串中出现的频率为:$w_1,w_2,\dots,w_n$。
|
||||
2. 以 $d_1,d_2,\dots,d_n$ 作为叶结点,$w_1,w_2,\dots,w_n$ 作为叶结点的权值,构造一棵霍夫曼树。
|
||||
3. 规定哈夫曼编码树的左分支代表 $0$,右分支代表 $1$,则从根结点到每个叶结点所经过的路径组成的 $0$、$1$ 序列即为该叶结点对应字符的编码。
|
||||
|
||||

|
||||
|
||||
|
|
|
|||
|
|
@ -12,13 +12,13 @@ k-D Tree 具有二叉搜索树的形态,二叉搜索树上的每个结点都
|
|||
|
||||
假设我们已经知道了 $k$ 维空间内的 $n$ 个不同的点的坐标,要将其构建成一棵 k-D Tree,步骤如下:
|
||||
|
||||
1. 若当前超长方体中只有一个点,返回这个点。
|
||||
1. 若当前超长方体中只有一个点,返回这个点。
|
||||
|
||||
2. 选择一个维度,将当前超长方体按照这个维度分成两个超长方体。
|
||||
2. 选择一个维度,将当前超长方体按照这个维度分成两个超长方体。
|
||||
|
||||
3. 选择切割点:在选择的维度上选择一个点,这一维度上的值小于这个点的归入一个超长方体(左子树),其余的归入另一个超长方体(右子树)。
|
||||
3. 选择切割点:在选择的维度上选择一个点,这一维度上的值小于这个点的归入一个超长方体(左子树),其余的归入另一个超长方体(右子树)。
|
||||
|
||||
4. 将选择的点作为这棵子树的根节点,递归对分出的两个超长方体构建左右子树,维护子树的信息。
|
||||
4. 将选择的点作为这棵子树的根节点,递归对分出的两个超长方体构建左右子树,维护子树的信息。
|
||||
|
||||
为了方便理解,我们举一个 $k=2$ 时的例子。
|
||||
|
||||
|
|
@ -32,9 +32,9 @@ k-D Tree 具有二叉搜索树的形态,二叉搜索树上的每个结点都
|
|||
|
||||
这样的复杂度无法保证。对于 $2,3$ 两步,我们提出两个优化:
|
||||
|
||||
1. 选择的维度要满足其内部点的分布的差异度最大,即每次选择的切割维度是方差最大的维度。
|
||||
1. 选择的维度要满足其内部点的分布的差异度最大,即每次选择的切割维度是方差最大的维度。
|
||||
|
||||
2. 每次在维度上选择切割点时选择该维度上的 **中位数**,这样可以保证每次分成的左右子树大小尽量相等。
|
||||
2. 每次在维度上选择切割点时选择该维度上的 **中位数**,这样可以保证每次分成的左右子树大小尽量相等。
|
||||
|
||||
可以发现,使用优化 $2$ 后,构建出的 k-D Tree 的树高最多为 $O(\log n)$。
|
||||
|
||||
|
|
@ -58,7 +58,7 @@ k-D Tree 具有二叉搜索树的形态,二叉搜索树上的每个结点都
|
|||
|
||||
## 邻域查询
|
||||
|
||||
???+note " 例题[luogu P1429 平面最近点对(加强版)](https://www.luogu.com.cn/problem/P1429)"
|
||||
???+ note " 例题 [luogu P1429 平面最近点对(加强版)](https://www.luogu.com.cn/problem/P1429)"
|
||||
给定平面上的 $n$ 个点 $(x_i,y_i)$,找出平面上最近两个点对之间的 [欧几里得距离](../geometry/distance.md#欧氏距离)。
|
||||
|
||||
$2\le n\le 200000 , 0\le x_i,y_i\le 10^9$
|
||||
|
|
@ -76,7 +76,7 @@ k-D Tree 具有二叉搜索树的形态,二叉搜索树上的每个结点都
|
|||
--8<-- "docs/ds/code/kdt/kdt_1.cpp"
|
||||
```
|
||||
|
||||
???+note " 例题[「CQOI2016」K 远点对](https://loj.ac/problem/2043)"
|
||||
???+ note " 例题 [「CQOI2016」K 远点对](https://loj.ac/problem/2043)"
|
||||
给定平面上的 $n$ 个点 $(x_i,y_i)$,求欧几里得距离下的第 $k$ 远无序点对之间的距离。
|
||||
|
||||
$n\le 100000 , 1\le k\le 100 , 0\le x_i,y_i<2^{31}$
|
||||
|
|
@ -92,11 +92,11 @@ k-D Tree 具有二叉搜索树的形态,二叉搜索树上的每个结点都
|
|||
|
||||
## 高维空间上的操作
|
||||
|
||||
???+note " 例题[luogu P4148 简单题](https://www.luogu.com.cn/problem/P4148)"
|
||||
???+ note " 例题 [luogu P4148 简单题](https://www.luogu.com.cn/problem/P4148)"
|
||||
在一个初始值全为 $0$ 的 $n\times n$ 的二维矩阵上,进行 $q$ 次操作,每次操作为以下两种之一:
|
||||
|
||||
1. `1 x y A`:将坐标 $(x,y)$ 上的数加上 $A$。
|
||||
2. `2 x1 y1 x2 y2`:输出以 $(x1,y1)$ 为左下角,$(x2,y2)$ 为右上角的矩形内(包括矩形边界)的数字和。
|
||||
1. `1 x y A`:将坐标 $(x,y)$ 上的数加上 $A$。
|
||||
2. `2 x1 y1 x2 y2`:输出以 $(x1,y1)$ 为左下角,$(x2,y2)$ 为右上角的矩形内(包括矩形边界)的数字和。
|
||||
|
||||
强制在线。内存限制 `20M`。保证答案及所有过程量在 `int` 范围内。
|
||||
|
||||
|
|
|
|||
218
docs/ds/lct.md
218
docs/ds/lct.md
|
|
@ -12,16 +12,16 @@ Splay Tree 是 LCT 的基础,但是 LCT 用的 Splay Tree 和普通的 Splay
|
|||
|
||||
维护一棵树,支持如下操作:
|
||||
|
||||
- 修改两点间路径权值。
|
||||
- 查询两点间路径权值和。
|
||||
- 修改某点子树权值。
|
||||
- 查询某点子树权值和。
|
||||
- 修改两点间路径权值。
|
||||
- 查询两点间路径权值和。
|
||||
- 修改某点子树权值。
|
||||
- 查询某点子树权值和。
|
||||
|
||||
唔,看上去是一道树剖模版题。
|
||||
|
||||
那么我们再加一个操作
|
||||
|
||||
- 断开并连接一些边,保证仍是一棵树。
|
||||
- 断开并连接一些边,保证仍是一棵树。
|
||||
|
||||
要求在线求出上面的答案。
|
||||
|
||||
|
|
@ -35,8 +35,8 @@ Splay Tree 是 LCT 的基础,但是 LCT 用的 Splay Tree 和普通的 Splay
|
|||
|
||||
### 从 LCT 的角度回顾一下树链剖分
|
||||
|
||||
- 对整棵树按子树大小进行剖分,并重新标号。
|
||||
- 我们发现重新标号之后,在树上形成了一些以链为单位的连续区间,并且可以用线段树进行区间操作。
|
||||
- 对整棵树按子树大小进行剖分,并重新标号。
|
||||
- 我们发现重新标号之后,在树上形成了一些以链为单位的连续区间,并且可以用线段树进行区间操作。
|
||||
|
||||
### 转向动态树问题
|
||||
|
||||
|
|
@ -62,10 +62,10 @@ Splay Tree 是 LCT 的基础,但是 LCT 用的 Splay Tree 和普通的 Splay
|
|||
|
||||
在本文里,你可以认为一些 Splay 构成了一个辅助树,每棵辅助树维护的是一棵树,一些辅助树构成了 LCT,其维护的是整个森林。
|
||||
|
||||
1. 辅助树由多棵 Splay 组成,每棵 Splay 维护原树中的一条路径,且中序遍历这棵 Splay 得到的点序列,从前到后对应原树“从上到下”的一条路径。
|
||||
2. 原树每个节点与辅助树的 Splay 节点一一对应。
|
||||
3. 辅助树的各棵 Splay 之间并不是独立的。每棵 Splay 的根节点的父亲节点本应是空,但在 LCT 中每棵 Splay 的根节点的父亲节点指向原树中 **这条链** 的父亲节点(即链最顶端的点的父亲节点)。这类父亲链接与通常 Splay 的父亲链接区别在于儿子认父亲,而父亲不认儿子,对应原树的一条 **虚边**。因此,每个连通块恰好有一个点的父亲节点为空。
|
||||
4. 由于辅助树的以上性质,我们维护任何操作都不需要维护原树,辅助树可以在任何情况下拿出一个唯一的原树,我们只需要维护辅助树即可。(本句来源自 @PoPoQQQ 大爷的 PPT)
|
||||
1. 辅助树由多棵 Splay 组成,每棵 Splay 维护原树中的一条路径,且中序遍历这棵 Splay 得到的点序列,从前到后对应原树“从上到下”的一条路径。
|
||||
2. 原树每个节点与辅助树的 Splay 节点一一对应。
|
||||
3. 辅助树的各棵 Splay 之间并不是独立的。每棵 Splay 的根节点的父亲节点本应是空,但在 LCT 中每棵 Splay 的根节点的父亲节点指向原树中 **这条链** 的父亲节点(即链最顶端的点的父亲节点)。这类父亲链接与通常 Splay 的父亲链接区别在于儿子认父亲,而父亲不认儿子,对应原树的一条 **虚边**。因此,每个连通块恰好有一个点的父亲节点为空。
|
||||
4. 由于辅助树的以上性质,我们维护任何操作都不需要维护原树,辅助树可以在任何情况下拿出一个唯一的原树,我们只需要维护辅助树即可。(本句来源自 @PoPoQQQ 大爷的 PPT)
|
||||
|
||||
现在我们有一棵原树,如图。(加粗边是实边,虚线边是虚边)
|
||||
|
||||
|
|
@ -77,53 +77,53 @@ Splay Tree 是 LCT 的基础,但是 LCT 用的 Splay Tree 和普通的 Splay
|
|||
|
||||
### 考虑原树和辅助树的结构关系
|
||||
|
||||
- 原树中的实链 : 在辅助树中节点都在一棵 Splay 中。
|
||||
- 原树中的虚链 : 在辅助树中,子节点所在 Splay 的 Father 指向父节点,但是父节点的两个儿子都不指向子节点。
|
||||
- 注意:原树的根不等于辅助树的根。
|
||||
- 原树的 Father 指向不等于辅助树的 Father 指向。
|
||||
- 辅助树是可以在满足辅助树、Splay 的性质下任意换根的。
|
||||
- 虚实链变换可以轻松在辅助树上完成,这也就是实现了动态维护树链剖分。
|
||||
- 原树中的实链 : 在辅助树中节点都在一棵 Splay 中。
|
||||
- 原树中的虚链 : 在辅助树中,子节点所在 Splay 的 Father 指向父节点,但是父节点的两个儿子都不指向子节点。
|
||||
- 注意:原树的根不等于辅助树的根。
|
||||
- 原树的 Father 指向不等于辅助树的 Father 指向。
|
||||
- 辅助树是可以在满足辅助树、Splay 的性质下任意换根的。
|
||||
- 虚实链变换可以轻松在辅助树上完成,这也就是实现了动态维护树链剖分。
|
||||
|
||||
### 接下来要用到的变量声明
|
||||
|
||||
- `ch[N][2]` 左右儿子
|
||||
- `f[N]` 父亲指向
|
||||
- `sum[N]` 路径权值和
|
||||
- `val[N]` 点权
|
||||
- `tag[N]` 翻转标记
|
||||
- `laz[N]` 权值标记
|
||||
- `siz[N]` 辅助树上子树大小
|
||||
- Other_Vars
|
||||
- `ch[N][2]` 左右儿子
|
||||
- `f[N]` 父亲指向
|
||||
- `sum[N]` 路径权值和
|
||||
- `val[N]` 点权
|
||||
- `tag[N]` 翻转标记
|
||||
- `laz[N]` 权值标记
|
||||
- `siz[N]` 辅助树上子树大小
|
||||
- Other\_Vars
|
||||
|
||||
### 函数声明
|
||||
|
||||
#### 一般数据结构函数(字面意思)
|
||||
|
||||
1. `PushUp(x)`
|
||||
2. `PushDown(x)`
|
||||
1. `PushUp(x)`
|
||||
2. `PushDown(x)`
|
||||
|
||||
#### Splay 系函数(不会多做解释)
|
||||
|
||||
1. `Get(x)` 获取 $x$ 是父亲的哪个儿子。
|
||||
2. `Splay(x)` 通过和 Rotate 操作联动实现把 $x$ 旋转到 **当前 Splay 的根**。
|
||||
3. `Rotate(x)` 将 $x$ 向上旋转一层的操作。
|
||||
1. `Get(x)` 获取 $x$ 是父亲的哪个儿子。
|
||||
2. `Splay(x)` 通过和 Rotate 操作联动实现把 $x$ 旋转到 **当前 Splay 的根**。
|
||||
3. `Rotate(x)` 将 $x$ 向上旋转一层的操作。
|
||||
|
||||
#### 新操作
|
||||
|
||||
1. `Access(x)` 把从根到 $x$ 的所有点放在一条实链里,使根到 $x$ 成为一条实路径,并且在同一棵 Splay 里。**只有此操作是必须实现的,其他操作视题目而实现。**
|
||||
2. `IsRoot(x)` 判断 $x$ 是否是所在树的根。
|
||||
3. `Update(x)` 在 `Access` 操作之后,递归地从上到下 `PushDown` 更新信息。
|
||||
4. `MakeRoot(x)` 使 $x$ 点成为其所在树的根。
|
||||
5. `Link(x, y)` 在 $x, y$ 两点间连一条边。
|
||||
6. `Cut(x, y)` 把 $x, y$ 两点间边删掉。
|
||||
7. `Find(x)` 找到 $x$ 所在树的根节点编号。
|
||||
8. `Fix(x, v)` 修改 $x$ 的点权为 $v$。
|
||||
9. `Split(x, y)` 提取出 $x, y$ 间的路径,方便做区间操作。
|
||||
1. `Access(x)` 把从根到 $x$ 的所有点放在一条实链里,使根到 $x$ 成为一条实路径,并且在同一棵 Splay 里。**只有此操作是必须实现的,其他操作视题目而实现。**
|
||||
2. `IsRoot(x)` 判断 $x$ 是否是所在树的根。
|
||||
3. `Update(x)` 在 `Access` 操作之后,递归地从上到下 `PushDown` 更新信息。
|
||||
4. `MakeRoot(x)` 使 $x$ 点成为其所在树的根。
|
||||
5. `Link(x, y)` 在 $x, y$ 两点间连一条边。
|
||||
6. `Cut(x, y)` 把 $x, y$ 两点间边删掉。
|
||||
7. `Find(x)` 找到 $x$ 所在树的根节点编号。
|
||||
8. `Fix(x, v)` 修改 $x$ 的点权为 $v$。
|
||||
9. `Split(x, y)` 提取出 $x, y$ 间的路径,方便做区间操作。
|
||||
|
||||
### 宏定义
|
||||
|
||||
- `#define ls ch[p][0]`
|
||||
- `#define rs ch[p][1]`
|
||||
- `#define ls ch[p][0]`
|
||||
- `#define rs ch[p][1]`
|
||||
|
||||
## 函数讲解
|
||||
|
||||
|
|
@ -213,31 +213,31 @@ inline int Access(int x) {
|
|||
|
||||

|
||||
|
||||
- 实现的方法是从下到上逐步更新 Splay。
|
||||
- 实现的方法是从下到上逐步更新 Splay。
|
||||
|
||||
- 首先我们要把 $N$ 旋至当前 Splay 的根。
|
||||
- 首先我们要把 $N$ 旋至当前 Splay 的根。
|
||||
|
||||
- 为了保证 AuxTree(辅助树)的性质,原来 $N$ 到 $O$ 的实边要更改为虚边。
|
||||
- 为了保证 AuxTree(辅助树)的性质,原来 $N$ 到 $O$ 的实边要更改为虚边。
|
||||
|
||||
- 由于认父不认子的性质,我们可以单方面的把 $N$ 的儿子改为 Null。
|
||||
- 由于认父不认子的性质,我们可以单方面的把 $N$ 的儿子改为 Null。
|
||||
|
||||
- 于是原来的 AuxTree 就从下图变成了下下图。
|
||||
|
||||

|
||||
|
||||
- 下一步,我们把 $N$ 指向的 Father $I$ 也旋转到 $I$ 的 Splay 树根。
|
||||
- 下一步,我们把 $N$ 指向的 Father $I$ 也旋转到 $I$ 的 Splay 树根。
|
||||
|
||||
- 原来的实边 $I$—$K$ 要去掉,这时候我们把 $I$ 的右儿子指向 $N$,就得到了 $I$—$L$ 这样一棵 Splay。
|
||||
|
||||

|
||||
|
||||
- 接下来,按照刚刚的操作步骤,由于 $I$ 的 Father 指向 $H$,我们把 $H$ 旋转到他所在 Splay Tree 的根,然后把 $H$ 的 rs 设为 $I$。
|
||||
- 接下来,按照刚刚的操作步骤,由于 $I$ 的 Father 指向 $H$,我们把 $H$ 旋转到他所在 Splay Tree 的根,然后把 $H$ 的 rs 设为 $I$。
|
||||
|
||||
- 之后的树是这样的。
|
||||
|
||||

|
||||
|
||||
- 同理我们 `Splay(A)`,并把 $A$ 的右儿子指向 $H$。
|
||||
- 同理我们 `Splay(A)`,并把 $A$ 的右儿子指向 $H$。
|
||||
|
||||
- 于是我们得到了这样一棵 AuxTree。并且发现 $A$—$N$ 的整个路径已经在同一棵 Splay 中了。大功告成!
|
||||
|
||||
|
|
@ -256,15 +256,15 @@ inline int Access(int x) {
|
|||
|
||||
我们发现 `Access()` 其实很容易,只有如下四步操作:
|
||||
|
||||
1. 把当前节点转到根。
|
||||
2. 把儿子换成之前的节点。
|
||||
3. 更新当前点的信息。
|
||||
4. 把当前点换成当前点的父亲,继续操作。
|
||||
1. 把当前节点转到根。
|
||||
2. 把儿子换成之前的节点。
|
||||
3. 更新当前点的信息。
|
||||
4. 把当前点换成当前点的父亲,继续操作。
|
||||
|
||||
这里提供的 Access 还有一个返回值。这个返回值相当于最后一次虚实链变换时虚边父亲节点的编号。该值有两个含义:
|
||||
|
||||
- 连续两次 Access 操作时,第二次 Access 操作的返回值等于这两个节点的 LCA.
|
||||
- 表示 $x$ 到根的链所在的 Splay 树的根。这个节点一定已经被旋转到了根节点,且父亲一定为空。
|
||||
- 连续两次 Access 操作时,第二次 Access 操作的返回值等于这两个节点的 LCA.
|
||||
- 表示 $x$ 到根的链所在的 Splay 树的根。这个节点一定已经被旋转到了根节点,且父亲一定为空。
|
||||
|
||||
### `Update()`
|
||||
|
||||
|
|
@ -278,13 +278,13 @@ void Update(int p) {
|
|||
|
||||
### `makeRoot()`
|
||||
|
||||
- `Make_Root()` 的重要性丝毫不亚于 `Access()`。我们在需要维护路径信息的时候,一定会出现路径深度无法严格递增的情况,根据 AuxTree 的性质,这种路径是不能出现在一棵 Splay 中的。
|
||||
- 这时候我们需要用到 `Make_Root()`。
|
||||
- `Make_Root()` 的作用是使指定的点成为原树的根,考虑如何实现这种操作。
|
||||
- 设 `Access(x)` 的返回值为 $y$,则此时 $x$ 到当前根的路径恰好构成一个 Splay,且该 Splay 的根为 $y$.
|
||||
- 考虑将树用有向图表示出来,给每条边定一个方向,表示从儿子到父亲的方向。容易发现换根相当于将 $x$ 到根的路径的所有边反向(请仔细思考)。
|
||||
- 因此将 $x$ 到当前根的路径翻转即可。
|
||||
- 由于 $y$ 是 $x$ 到当前根的路径所代表的 Splay 的根,因此将以 $y$ 为根的 Splay 树进行区间翻转即可。
|
||||
- `Make_Root()` 的重要性丝毫不亚于 `Access()`。我们在需要维护路径信息的时候,一定会出现路径深度无法严格递增的情况,根据 AuxTree 的性质,这种路径是不能出现在一棵 Splay 中的。
|
||||
- 这时候我们需要用到 `Make_Root()`。
|
||||
- `Make_Root()` 的作用是使指定的点成为原树的根,考虑如何实现这种操作。
|
||||
- 设 `Access(x)` 的返回值为 $y$,则此时 $x$ 到当前根的路径恰好构成一个 Splay,且该 Splay 的根为 $y$.
|
||||
- 考虑将树用有向图表示出来,给每条边定一个方向,表示从儿子到父亲的方向。容易发现换根相当于将 $x$ 到根的路径的所有边反向(请仔细思考)。
|
||||
- 因此将 $x$ 到当前根的路径翻转即可。
|
||||
- 由于 $y$ 是 $x$ 到当前根的路径所代表的 Splay 的根,因此将以 $y$ 为根的 Splay 树进行区间翻转即可。
|
||||
|
||||
```cpp
|
||||
inline void makeRoot(int p) {
|
||||
|
|
@ -296,7 +296,7 @@ inline void makeRoot(int p) {
|
|||
|
||||
### `Link()`
|
||||
|
||||
- Link 两个点其实很简单,先 `Make_Root(x)`,然后把 $x$ 的父亲指向 $y$ 即可。显然,这个操作肯定不能发生在同一棵树内,所以记得先判一下。
|
||||
- Link 两个点其实很简单,先 `Make_Root(x)`,然后把 $x$ 的父亲指向 $y$ 即可。显然,这个操作肯定不能发生在同一棵树内,所以记得先判一下。
|
||||
|
||||
```cpp
|
||||
inline void Link(int x, int p) {
|
||||
|
|
@ -308,15 +308,15 @@ inline void Link(int x, int p) {
|
|||
|
||||
### `Split()`
|
||||
|
||||
- `Split` 操作意义很简单,就是拿出一棵 Splay,维护的是 $x$ 到 $y$ 的路径。
|
||||
- 先 `MakeRoot(x)`,然后 `Access(y)`。如果要 $y$ 做根,再 `Splay(y)`。
|
||||
- 就这三句话,没写代码,需要的时候可以直接打这三个就好辣!
|
||||
- 另外 Split 这三个操作直接可以把需要的路径拿出到 $y$ 的子树上,那不是随便干嘛咯。
|
||||
- `Split` 操作意义很简单,就是拿出一棵 Splay,维护的是 $x$ 到 $y$ 的路径。
|
||||
- 先 `MakeRoot(x)`,然后 `Access(y)`。如果要 $y$ 做根,再 `Splay(y)`。
|
||||
- 就这三句话,没写代码,需要的时候可以直接打这三个就好辣!
|
||||
- 另外 Split 这三个操作直接可以把需要的路径拿出到 $y$ 的子树上,那不是随便干嘛咯。
|
||||
|
||||
### `Cut()`
|
||||
|
||||
- `Cut` 有两种情况,保证合法和不一定保证合法。(废话)
|
||||
- 如果保证合法,直接 `Split(x, y)`,这时候 $y$ 是根,$x$ 一定是它的儿子,双向断开即可。就像这样:
|
||||
- `Cut` 有两种情况,保证合法和不一定保证合法。(废话)
|
||||
- 如果保证合法,直接 `Split(x, y)`,这时候 $y$ 是根,$x$ 一定是它的儿子,双向断开即可。就像这样:
|
||||
|
||||
```cpp
|
||||
inline void Cut(int x, int p) {
|
||||
|
|
@ -328,9 +328,9 @@ inline void Cut(int x, int p) {
|
|||
|
||||
想要删边,必须要满足如下三个条件:
|
||||
|
||||
1. $x,y$ 连通。
|
||||
2. $x,y$ 的路径上没有其他的链。
|
||||
3. $x$ 没有右儿子。
|
||||
1. $x,y$ 连通。
|
||||
2. $x,y$ 的路径上没有其他的链。
|
||||
3. $x$ 没有右儿子。
|
||||
|
||||
总结一下,上面三句话的意思就一个:$x,y$ 之间有边。
|
||||
|
||||
|
|
@ -338,9 +338,9 @@ inline void Cut(int x, int p) {
|
|||
|
||||
### `Find()`
|
||||
|
||||
- `Find()` 查找的是 $x$ 所在的 **原树** 的根,请不要把原树根和辅助树根弄混。在 `Access(p)` 后,再 `Splay(p)`。这样根就是树里深度最小的那个,一直往左儿子走,沿途 `PushDown` 即可。
|
||||
- 一直走到没有 ls,非常简单。
|
||||
- 注意,每次查询之后需要把查询到的答案对应的结点 `Splay` 上去以保证复杂度。
|
||||
- `Find()` 查找的是 $x$ 所在的 **原树** 的根,请不要把原树根和辅助树根弄混。在 `Access(p)` 后,再 `Splay(p)`。这样根就是树里深度最小的那个,一直往左儿子走,沿途 `PushDown` 即可。
|
||||
- 一直走到没有 ls,非常简单。
|
||||
- 注意,每次查询之后需要把查询到的答案对应的结点 `Splay` 上去以保证复杂度。
|
||||
|
||||
```cpp
|
||||
inline int Find(int p) {
|
||||
|
|
@ -355,25 +355,25 @@ inline int Find(int p) {
|
|||
|
||||
### 一些提醒
|
||||
|
||||
- 干点啥前一定要想一想需不需要 `PushUp` 或者 `PushDown`,LCT 由于特别灵活的原因,少 `Pushdown` 或者 `Pushup` 一次就可能把修改改到不该改的点上!
|
||||
- LCT 的 `Rotate` 和 Splay 的不太一样,`if (z)` 一定要放在前面。
|
||||
- LCT 的 `Splay` 操作就是旋转到根,没有旋转到谁儿子的操作,因为不需要。
|
||||
- 干点啥前一定要想一想需不需要 `PushUp` 或者 `PushDown`,LCT 由于特别灵活的原因,少 `Pushdown` 或者 `Pushup` 一次就可能把修改改到不该改的点上!
|
||||
- LCT 的 `Rotate` 和 Splay 的不太一样,`if (z)` 一定要放在前面。
|
||||
- LCT 的 `Splay` 操作就是旋转到根,没有旋转到谁儿子的操作,因为不需要。
|
||||
|
||||
## 习题
|
||||
|
||||
- [「BZOJ 3282」Tree](https://hydro.ac/d/bzoj/p/3282)
|
||||
- [「HNOI2010」弹飞绵羊](https://www.luogu.com.cn/problem/P3203)
|
||||
- [「BZOJ 3282」Tree](https://hydro.ac/d/bzoj/p/3282)
|
||||
- [「HNOI2010」弹飞绵羊](https://www.luogu.com.cn/problem/P3203)
|
||||
|
||||
## 维护树链信息
|
||||
|
||||
LCT 通过 `Split(x,y)` 操作,可以将树上从点 $x$ 到点 $y$ 的路径提取到以 $y$ 为根的 Splay 内,树链信息的修改和统计转化为平衡树上的操作,这使得 LCT 在维护树链信息上具有优势。此外,借助 LCT 实现的在树链上二分比树链剖分少一个 $O(\log n)$ 的复杂度。
|
||||
|
||||
???+note " 例题[「国家集训队」Tree II](https://www.luogu.com.cn/problem/P1501)"
|
||||
???+ note " 例题 [「国家集训队」Tree II](https://www.luogu.com.cn/problem/P1501)"
|
||||
给出一棵有 $n$ 个结点的树,每个点的初始权值为 $1$。$q$ 次操作,每次操作均为以下四种之一:
|
||||
|
||||
1. `- u1 v1 u2 v2`:将树上 $u_1,v_1$ 两点之间的边删除,连接 $u_2,v_2$ 两点,保证操作合法且连边后仍是一棵树。
|
||||
2. `+ u v c`:将树上 $u,v$ 两点之间的路径上的点权都增加 $c$。
|
||||
3. `* u v c`:将树上 $u,v$ 两点之间的路径上的点权都乘以 $c$。
|
||||
1. `- u1 v1 u2 v2`:将树上 $u_1,v_1$ 两点之间的边删除,连接 $u_2,v_2$ 两点,保证操作合法且连边后仍是一棵树。
|
||||
2. `+ u v c`:将树上 $u,v$ 两点之间的路径上的点权都增加 $c$。
|
||||
3. `* u v c`:将树上 $u,v$ 两点之间的路径上的点权都乘以 $c$。
|
||||
4. `/ u v`:输出树上 $u,v$ 两点之间的路径上的点权之和对 $51061$ 取模后的值。
|
||||
|
||||
$1\le n,q\le 10^5,0\le c\le 10^4$
|
||||
|
|
@ -548,9 +548,9 @@ LCT 通过 `Split(x,y)` 操作,可以将树上从点 $x$ 到点 $y$ 的路径
|
|||
|
||||
### 习题
|
||||
|
||||
- [luogu P3690【模板】Link Cut Tree(动态树)](https://www.luogu.com.cn/problem/P3690)
|
||||
- [「SDOI2011」染色](https://www.luogu.com.cn/problem/P2486)
|
||||
- [「SHOI2014」三叉神经树](https://loj.ac/problem/2187)
|
||||
- [luogu P3690【模板】Link Cut Tree(动态树)](https://www.luogu.com.cn/problem/P3690)
|
||||
- [「SDOI2011」染色](https://www.luogu.com.cn/problem/P2486)
|
||||
- [「SHOI2014」三叉神经树](https://loj.ac/problem/2187)
|
||||
|
||||
## 维护连通性质
|
||||
|
||||
|
|
@ -558,12 +558,12 @@ LCT 通过 `Split(x,y)` 操作,可以将树上从点 $x$ 到点 $y$ 的路径
|
|||
|
||||
借助 LCT 的 `Find()` 函数,可以判断动态森林上的两点是否连通。如果有 `Find(x)==Find(y)`,则说明 $x,y$ 两点在一棵树上,相互连通。
|
||||
|
||||
???+note " 例题[「SDOI2008」洞穴勘测](https://www.luogu.com.cn/problem/P2147)"
|
||||
???+ note " 例题 [「SDOI2008」洞穴勘测](https://www.luogu.com.cn/problem/P2147)"
|
||||
一开始有 $n$ 个独立的点,$m$ 次操作。每次操作为以下之一:
|
||||
|
||||
1. `Connect u v`:在 $u,v$ 两点之间连接一条边。
|
||||
2. `Destroy u v`:删除在 $u,v$ 两点之间的边,保证之前存在这样的一条边。
|
||||
3. `Query u v`:询问 $u,v$ 两点是否连通。
|
||||
1. `Connect u v`:在 $u,v$ 两点之间连接一条边。
|
||||
2. `Destroy u v`:删除在 $u,v$ 两点之间的边,保证之前存在这样的一条边。
|
||||
3. `Query u v`:询问 $u,v$ 两点是否连通。
|
||||
|
||||
保证在任何时刻图的形态都是一个森林。
|
||||
|
||||
|
|
@ -665,11 +665,11 @@ LCT 通过 `Split(x,y)` 操作,可以将树上从点 $x$ 到点 $y$ 的路径
|
|||
|
||||
如果要求将边双连通分量缩成点,每次添加一条边,所连接的树上的两点如果相互连通,那么这条路径上的所有点都会被缩成一个点。
|
||||
|
||||
???+note " 例题[「AHOI2005」航线规划](https://www.luogu.com.cn/problem/P2542)"
|
||||
???+ note " 例题 [「AHOI2005」航线规划](https://www.luogu.com.cn/problem/P2542)"
|
||||
给出 $n$ 个点,初始时有 $m$ 条无向边,$q$ 次操作,每次操作为以下之一:
|
||||
|
||||
1. `0 u v`:删除 $u,v$ 之间的连边,保证此时存在这样的一条边。
|
||||
2. `1 u v`:查询此时 $u,v$ 两点之间可能的所有路径必须经过的边的数量。
|
||||
1. `0 u v`:删除 $u,v$ 之间的连边,保证此时存在这样的一条边。
|
||||
2. `1 u v`:查询此时 $u,v$ 两点之间可能的所有路径必须经过的边的数量。
|
||||
|
||||
保证图在任意时刻都连通。
|
||||
|
||||
|
|
@ -858,15 +858,15 @@ LCT 通过 `Split(x,y)` 操作,可以将树上从点 $x$ 到点 $y$ 的路径
|
|||
|
||||
### 习题
|
||||
|
||||
- [luogu P3950 部落冲突](https://www.luogu.com.cn/problem/P3950)
|
||||
- [bzoj 4998 星球联盟](https://hydro.ac/d/bzoj/p/4998)
|
||||
- [bzoj 2959 长跑](https://hydro.ac/d/bzoj/p/2959)
|
||||
- [luogu P3950 部落冲突](https://www.luogu.com.cn/problem/P3950)
|
||||
- [bzoj 4998 星球联盟](https://hydro.ac/d/bzoj/p/4998)
|
||||
- [bzoj 2959 长跑](https://hydro.ac/d/bzoj/p/2959)
|
||||
|
||||
## 维护边权
|
||||
|
||||
LCT 并不能直接处理边权,此时需要对每条边建立一个对应点,方便查询链上的边信息。利用这一技巧可以动态维护生成树。
|
||||
|
||||
???+note " 例题 [luogu P4234 最小差值生成树](https://www.luogu.com.cn/problem/P4234)"
|
||||
???+ note " 例题 [luogu P4234 最小差值生成树](https://www.luogu.com.cn/problem/P4234)"
|
||||
给定一个 $n$ 个点,$m$ 条边的带权无向图,求其边权最大值和边权最小值的差值最小的生成树,输出这个差值。
|
||||
|
||||
数据保证至少存在一棵生成树。
|
||||
|
|
@ -1033,19 +1033,19 @@ LCT 上没有固定的父子关系,所以不能将边权记录在点权中。
|
|||
|
||||
### 习题
|
||||
|
||||
- [「WC2006」水管局长](https://www.luogu.com.cn/problem/P4172)
|
||||
- [「BJWC2010」严格次小生成树](https://www.luogu.com.cn/problem/P4180)
|
||||
- [「NOI2014」魔法森林](https://uoj.ac/problem/3)
|
||||
- [「WC2006」水管局长](https://www.luogu.com.cn/problem/P4172)
|
||||
- [「BJWC2010」严格次小生成树](https://www.luogu.com.cn/problem/P4180)
|
||||
- [「NOI2014」魔法森林](https://uoj.ac/problem/3)
|
||||
|
||||
## 维护子树信息
|
||||
|
||||
LCT 不擅长维护子树信息。统计一个结点所有虚子树的信息,就可以求得整棵树的信息。
|
||||
|
||||
???+note " 例题[「BJOI2014」大融合](https://loj.ac/problem/2230)"
|
||||
???+ note " 例题 [「BJOI2014」大融合](https://loj.ac/problem/2230)"
|
||||
给定 $n$ 个结点和 $q$ 次操作,每个操作为如下形式:
|
||||
|
||||
1. `A x y` 在结点 $x$ 和 $y$ 之间连接一条边。
|
||||
2. `Q x y` 给定一条已经存在的边 $(x,y)$,求有多少条简单路径,其中包含边 $(x,y)$。
|
||||
1. `A x y` 在结点 $x$ 和 $y$ 之间连接一条边。
|
||||
2. `Q x y` 给定一条已经存在的边 $(x,y)$,求有多少条简单路径,其中包含边 $(x,y)$。
|
||||
|
||||
保证在任意时刻,图的形态都是一棵森林。
|
||||
|
||||
|
|
@ -1096,10 +1096,10 @@ st.siz2[y] += st.siz[x];
|
|||
|
||||
代码修改的细节讲完了,总结一下 LCT 维护子树信息的要求与方法:
|
||||
|
||||
1. 维护的信息要有 **可减性**,如子树结点数,子树权值和,但不能直接维护子树最大最小值,因为在将一条虚边变成实边时要排除原先虚边的贡献。
|
||||
2. 新建一个附加值存储虚子树的贡献,在统计时将其加入本结点答案,在改变边的虚实时及时维护。
|
||||
3. 其余部分同普通 LCT,在统计子树信息时一定将其作为根节点。
|
||||
4. 如果维护的信息没有可减性,如维护区间最值,可以对每个结点开一个平衡树维护结点的虚子树中的最值。
|
||||
1. 维护的信息要有 **可减性**,如子树结点数,子树权值和,但不能直接维护子树最大最小值,因为在将一条虚边变成实边时要排除原先虚边的贡献。
|
||||
2. 新建一个附加值存储虚子树的贡献,在统计时将其加入本结点答案,在改变边的虚实时及时维护。
|
||||
3. 其余部分同普通 LCT,在统计子树信息时一定将其作为根节点。
|
||||
4. 如果维护的信息没有可减性,如维护区间最值,可以对每个结点开一个平衡树维护结点的虚子树中的最值。
|
||||
|
||||
??? "参考代码"
|
||||
```cpp
|
||||
|
|
@ -1213,5 +1213,5 @@ st.siz2[y] += st.siz[x];
|
|||
|
||||
### 习题
|
||||
|
||||
- [luogu P4299 首都](https://www.luogu.com.cn/problem/P4299)
|
||||
- [SPOJ QTREE5 - Query on a tree V](https://www.luogu.com.cn/problem/SP2939)
|
||||
- [luogu P4299 首都](https://www.luogu.com.cn/problem/P4299)
|
||||
- [SPOJ QTREE5 - Query on a tree V](https://www.luogu.com.cn/problem/SP2939)
|
||||
|
|
|
|||
|
|
@ -8,9 +8,9 @@ Leafy Tree 是一种依靠旋转维持重量平衡的平衡树。
|
|||
|
||||
## Leafy Tree 的特点
|
||||
|
||||
1. 所有的信息维护在叶子节点上。
|
||||
2. 类似 Kruskal 重构树的结构,每个非叶子节点一定有两个孩子,且非叶子节点统计两个孩子的信息(类似线段树上传信息),所以维护 $n$ 个信息的 Leafy Tree 有 $2n-1$ 个节点。
|
||||
3. 可以完成区间操作,比如翻转,以及可持久化等。
|
||||
1. 所有的信息维护在叶子节点上。
|
||||
2. 类似 Kruskal 重构树的结构,每个非叶子节点一定有两个孩子,且非叶子节点统计两个孩子的信息(类似线段树上传信息),所以维护 $n$ 个信息的 Leafy Tree 有 $2n-1$ 个节点。
|
||||
3. 可以完成区间操作,比如翻转,以及可持久化等。
|
||||
|
||||
注意到,一个 Leafy 结构的每个节点必定有两个孩子。对其进行插入删除时,在插入删除叶子时必定会额外修改一个非叶节点。
|
||||
常见的平衡树均属于每个节点同时维护值和结构的 Nodey Tree。如果将一个 Nodey 结构的所有孩子的空指针指向一个维护值的节点,那么这棵树将变为一个 Leafy 结构。
|
||||
|
|
@ -104,10 +104,10 @@ inline int find(Node *u, int x) {
|
|||
|
||||
## 例题
|
||||
|
||||
- [Luogu P2286 宠物收养场](https://www.luogu.com.cn/problem/P2286)
|
||||
- [Luogu P2286 宠物收养场](https://www.luogu.com.cn/problem/P2286)
|
||||
|
||||
## 参考资料
|
||||
|
||||
- [WBLT 学习笔记](https://shiroi-he.gitee.io/blog/2020/07/23/WBLT%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0/)
|
||||
- [Leafy Tree](https://www.cnblogs.com/onionQAQ/p/10979867.html)
|
||||
- [Luogu P2286\[HNOI2004\]宠物收养场](https://www.programminghunter.com/article/64011263567/)
|
||||
- [WBLT 学习笔记](https://shiroi-he.gitee.io/blog/2020/07/23/WBLT%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0/)
|
||||
- [Leafy Tree](https://www.cnblogs.com/onionQAQ/p/10979867.html)
|
||||
- [Luogu P2286\[HNOI2004\] 宠物收养场](https://www.programminghunter.com/article/64011263567/)
|
||||
|
|
|
|||
|
|
@ -24,7 +24,7 @@
|
|||
|
||||
参考代码:
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
int merge(int x, int y) {
|
||||
if (!x || !y) return x | y; // 若一个堆为空则返回另一个堆
|
||||
|
|
@ -41,7 +41,7 @@
|
|||
|
||||
左偏树还有一种无需交换左右儿子的写法:将 $\mathrm{dist}$ 较大的儿子视作左儿子,$\mathrm{dist}$ 较小的儿子视作右儿子:
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
int& rs(int x) { return t[x].ch[t[t[x].ch[1]].d < t[t[x].ch[0]].d]; }
|
||||
|
||||
|
|
@ -70,7 +70,7 @@
|
|||
|
||||
先将左右儿子合并,然后自底向上更新 $\mathrm{dist}$、不满足左偏性质时交换左右儿子,当 $\mathrm{dist}$ 无需更新时结束递归:
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
int& rs(int x) { return t[x].ch[t[t[x].ch[1]].d < t[t[x].ch[0]].d]; }
|
||||
|
||||
|
|
@ -98,8 +98,8 @@
|
|||
|
||||
继续递归下去有两种情况:
|
||||
|
||||
1. $x$ 是 $y$ 的右儿子,此时 $y$ 的初始 $\mathrm{dist}$ 为 $x$ 的初始 $\mathrm{dist}$ 加一。
|
||||
2. $x$ 是 $y$ 的左儿子,只有 $y$ 的左右儿子初始 $\mathrm{dist}$ 相等时(此时左儿子 $\mathrm{dist}$ 减一会导致左右儿子互换)才会继续递归下去,因此 $y$ 的初始 $\mathrm{dist}$ 仍然是 $x$ 的初始 $\mathrm{dist}$ 加一。
|
||||
1. $x$ 是 $y$ 的右儿子,此时 $y$ 的初始 $\mathrm{dist}$ 为 $x$ 的初始 $\mathrm{dist}$ 加一。
|
||||
2. $x$ 是 $y$ 的左儿子,只有 $y$ 的左右儿子初始 $\mathrm{dist}$ 相等时(此时左儿子 $\mathrm{dist}$ 减一会导致左右儿子互换)才会继续递归下去,因此 $y$ 的初始 $\mathrm{dist}$ 仍然是 $x$ 的初始 $\mathrm{dist}$ 加一。
|
||||
|
||||
所以,我们得到,除了第一次 `pushup`(因为被删除节点的父亲的初始 $\mathrm{dist}$ 不一定等于被删除节点左右儿子合并后的初始 $\mathrm{dist}$ 加一),每递归一层 $x$ 的初始 $\mathrm{dist}$ 就会加一,因此最多递归 $O(\log n)$ 层。
|
||||
|
||||
|
|
@ -109,7 +109,7 @@
|
|||
|
||||
在根打上标记,删除根/合并堆(访问儿子)时下传标记即可:
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
int merge(int x, int y) {
|
||||
if (!x || !y) return x | y;
|
||||
|
|
@ -131,7 +131,7 @@
|
|||
|
||||
直接贴上代码
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
int merge(int x, int y) {
|
||||
if (!x || !y) return x | y;
|
||||
|
|
@ -157,9 +157,9 @@
|
|||
|
||||
需要注意的是:
|
||||
|
||||
1. 合并前要检查是否已经在同一堆中。
|
||||
1. 合并前要检查是否已经在同一堆中。
|
||||
|
||||
2. 左偏树的深度可能达到 $O(n)$,因此找一个点所在的堆顶要用并查集维护,不能直接暴力跳父亲。(虽然很多题数据水,暴力跳父亲可以过……)(用并查集维护根时要保证原根指向新根,新根指向自己。)
|
||||
2. 左偏树的深度可能达到 $O(n)$,因此找一个点所在的堆顶要用并查集维护,不能直接暴力跳父亲。(虽然很多题数据水,暴力跳父亲可以过……)(用并查集维护根时要保证原根指向新根,新根指向自己。)
|
||||
|
||||
??? "罗马游戏参考代码"
|
||||
```cpp
|
||||
|
|
@ -193,13 +193,13 @@
|
|||
|
||||
所以,每个操作分别如下:
|
||||
|
||||
1. 暴力下传点数较小的堆的标记,合并两个堆,更新 size、tag,在 multiset 中删去合并后不在堆顶的那个原堆顶。
|
||||
2. 删除节点,更新值,插入回来,更新 multiset。需要分删除节点是否为根来讨论一下。
|
||||
3. 堆顶打标记,更新 multiset。
|
||||
4. 打全局标记。
|
||||
5. 查询值 + 堆顶标记 + 全局标记。
|
||||
6. 查询根的值 + 堆顶标记 + 全局标记。
|
||||
7. 查询 multiset 最大值 + 全局标记。
|
||||
1. 暴力下传点数较小的堆的标记,合并两个堆,更新 size、tag,在 multiset 中删去合并后不在堆顶的那个原堆顶。
|
||||
2. 删除节点,更新值,插入回来,更新 multiset。需要分删除节点是否为根来讨论一下。
|
||||
3. 堆顶打标记,更新 multiset。
|
||||
4. 打全局标记。
|
||||
5. 查询值 + 堆顶标记 + 全局标记。
|
||||
6. 查询根的值 + 堆顶标记 + 全局标记。
|
||||
7. 查询 multiset 最大值 + 全局标记。
|
||||
|
||||
??? "棘手的操作参考代码"
|
||||
```cpp
|
||||
|
|
|
|||
|
|
@ -1,10 +1,10 @@
|
|||
## 引入
|
||||
|
||||
???+note "[洛谷 4097 [HEOI2013]Segment](https://www.luogu.com.cn/problem/P4097)"
|
||||
???+ note "[洛谷 4097 \[HEOI2013\]Segment](https://www.luogu.com.cn/problem/P4097)"
|
||||
要求在平面直角坐标系下维护两个操作(强制在线):
|
||||
|
||||
1. 在平面上加入一条线段。记第 $i$ 条被插入的线段的标号为 $i$,该线段的两个端点分别为 $(x_0,y_0)$,$(x_1,y_1)$。
|
||||
2. 给定一个数 $k$,询问与直线 $x = k$ 相交的线段中,交点纵坐标最大的线段的编号(若有多条线段与查询直线的交点纵坐标都是最大的,则输出编号最小的线段)。特别地,若不存在线段与给定直线相交,输出 $0$。
|
||||
1. 在平面上加入一条线段。记第 $i$ 条被插入的线段的标号为 $i$,该线段的两个端点分别为 $(x_0,y_0)$,$(x_1,y_1)$。
|
||||
2. 给定一个数 $k$,询问与直线 $x = k$ 相交的线段中,交点纵坐标最大的线段的编号(若有多条线段与查询直线的交点纵坐标都是最大的,则输出编号最小的线段)。特别地,若不存在线段与给定直线相交,输出 $0$。
|
||||
|
||||
数据满足:操作总数 $1 \leq n \leq 10^5$,$1 \leq k, x_0, x_1 \leq 39989$,$1 \leq y_0, y_1 \leq 10^9$。
|
||||
|
||||
|
|
@ -14,10 +14,10 @@
|
|||
|
||||
我们可以把任务转化为维护如下操作:
|
||||
|
||||
- 加入一个一次函数,定义域为 $[l,r]$;
|
||||
- 给定 $k$,求定义域包含 $k$ 的所有一次函数中,在 $x=k$ 处取值最大的那个,如果有多个函数取值相同,选编号最小的。
|
||||
- 加入一个一次函数,定义域为 $[l,r]$;
|
||||
- 给定 $k$,求定义域包含 $k$ 的所有一次函数中,在 $x=k$ 处取值最大的那个,如果有多个函数取值相同,选编号最小的。
|
||||
|
||||
???+warning "注意"
|
||||
???+ warning "注意"
|
||||
当线段垂直于 $x$ 轴时,会出现除以零的情况。假设线段两端点分别为 $(x,y_0)$ 和 $(x,y_1)$,$y_0<y_1$,则插入定义域为 $[x,x]$ 的一次函数 $f(x)=0\cdot x+y_1$。
|
||||
|
||||
看到区间修改,我们按照线段树解决区间问题的常见方法,给每个节点一个懒标记。每个节点 $i$ 的懒标记都是一条线段,记为 $l_i$,表示要用 $l_i$ 更新该节点所表示的整个区间。
|
||||
|
|
@ -34,9 +34,9 @@
|
|||
|
||||
如果新线段 $f$ 更优,则将 $f$ 和 $g$ 交换。那么现在考虑在中点处 $f$ 不如 $g$ 优的情况:
|
||||
|
||||
1. 若在左端点处 $f$ 更优,那么 $f$ 和 $g$ 必然在左半区间中产生了交点,$f$ 只有在左区间才可能优于 $g$,递归到左儿子中进行下传;
|
||||
2. 若在右端点处 $f$ 更优,那么 $f$ 和 $g$ 必然在右半区间中产生了交点,$f$ 只有在右区间才可能优于 $g$,递归到右儿子中进行下传;
|
||||
3. 若在左右端点处 $g$ 都更优,那么 $f$ 不可能成为答案,不需要继续下传。
|
||||
1. 若在左端点处 $f$ 更优,那么 $f$ 和 $g$ 必然在左半区间中产生了交点,$f$ 只有在左区间才可能优于 $g$,递归到左儿子中进行下传;
|
||||
2. 若在右端点处 $f$ 更优,那么 $f$ 和 $g$ 必然在右半区间中产生了交点,$f$ 只有在右区间才可能优于 $g$,递归到右儿子中进行下传;
|
||||
3. 若在左右端点处 $g$ 都更优,那么 $f$ 不可能成为答案,不需要继续下传。
|
||||
|
||||
除了这两种情况之外,还有一种情况是 $f$ 和 $g$ 刚好交于中点,在程序实现时可以归入中点处 $f$ 不如 $g$ 优的情况,结果会往 $f$ 更优的一个端点进行递归下传。
|
||||
|
||||
|
|
@ -44,7 +44,7 @@
|
|||
|
||||
下传标记:
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
const double eps = 1e-9;
|
||||
|
||||
|
|
@ -69,7 +69,7 @@
|
|||
|
||||
拆分线段:
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
void update(int root, int cl, int cr, int l, int r,
|
||||
int u) { // 定位插入线段完全覆盖到的区间
|
||||
|
|
@ -93,7 +93,7 @@
|
|||
|
||||
查询:
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
pdi query(int root, int l, int r, int d) { // 查询
|
||||
if (r < d || d < l) return {0, 0};
|
||||
|
|
@ -107,7 +107,7 @@
|
|||
|
||||
根据上面的描述,查询过程的时间复杂度显然为 $O(\log n)$,而插入过程中,我们需要将原线段拆分到 $O(\log n)$ 个区间中,对于每个区间,我们又需要花费 $O(\log n)$ 的时间递归下传,从而插入过程的时间复杂度为 $O(\log^2 n)$。
|
||||
|
||||
??? note "[[HEOI2013]Segment](https://www.luogu.com.cn/problem/P4097) 参考代码"
|
||||
??? note "[\[HEOI2013\]Segment](https://www.luogu.com.cn/problem/P4097) 参考代码 "
|
||||
```cpp
|
||||
--8<-- "docs/ds/code/li-chao-tree/li-chao-tree_1.cpp"
|
||||
```
|
||||
|
|
|
|||
|
|
@ -23,7 +23,7 @@
|
|||
|
||||

|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
=== "C++"
|
||||
|
||||
```c++
|
||||
|
|
@ -48,7 +48,7 @@
|
|||
|
||||

|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
=== "C++"
|
||||
|
||||
```c++
|
||||
|
|
@ -75,19 +75,19 @@
|
|||
|
||||
流程大致如下:
|
||||
|
||||
1. 初始化待插入的数据 `node`;
|
||||
2. 将 `node` 的 `next` 指针指向 `p` 的下一个结点;
|
||||
3. 将 `p` 的 `next` 指针指向 `node`。
|
||||
1. 初始化待插入的数据 `node`;
|
||||
2. 将 `node` 的 `next` 指针指向 `p` 的下一个结点;
|
||||
3. 将 `p` 的 `next` 指针指向 `node`。
|
||||
|
||||
具体过程可参考下图:
|
||||
|
||||
1. 
|
||||
2. 
|
||||
3. 
|
||||
1. 
|
||||
2. 
|
||||
3. 
|
||||
|
||||
代码实现如下:
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
=== "C++"
|
||||
|
||||
```c++
|
||||
|
|
@ -115,21 +115,21 @@
|
|||
|
||||
大致流程如下:
|
||||
|
||||
1. 初始化待插入的数据 `node`;
|
||||
2. 判断给定链表 `p` 是否为空;
|
||||
3. 若为空,则将 `node` 的 `next` 指针和 `p` 都指向自己;
|
||||
4. 否则,将 `node` 的 `next` 指针指向 `p` 的下一个结点;
|
||||
5. 将 `p` 的 `next` 指针指向 `node`。
|
||||
1. 初始化待插入的数据 `node`;
|
||||
2. 判断给定链表 `p` 是否为空;
|
||||
3. 若为空,则将 `node` 的 `next` 指针和 `p` 都指向自己;
|
||||
4. 否则,将 `node` 的 `next` 指针指向 `p` 的下一个结点;
|
||||
5. 将 `p` 的 `next` 指针指向 `node`。
|
||||
|
||||
具体过程可参考下图:
|
||||
|
||||
1. 
|
||||
2. 
|
||||
3. 
|
||||
1. 
|
||||
2. 
|
||||
3. 
|
||||
|
||||
代码实现如下:
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
=== "C++"
|
||||
|
||||
```c++
|
||||
|
|
@ -168,17 +168,17 @@
|
|||
|
||||
大致流程如下:
|
||||
|
||||
1. 初始化待插入的数据 `node`;
|
||||
2. 判断给定链表 `p` 是否为空;
|
||||
3. 若为空,则将 `node` 的 `left` 和 `right` 指针,以及 `p` 都指向自己;
|
||||
4. 否则,将 `node` 的 `left` 指针指向 `p`;
|
||||
5. 将 `node` 的 `right` 指针指向 `p` 的右结点;
|
||||
6. 将 `p` 右结点的 `left` 指针指向 `node`;
|
||||
7. 将 `p` 的 `right` 指针指向 `node`。
|
||||
1. 初始化待插入的数据 `node`;
|
||||
2. 判断给定链表 `p` 是否为空;
|
||||
3. 若为空,则将 `node` 的 `left` 和 `right` 指针,以及 `p` 都指向自己;
|
||||
4. 否则,将 `node` 的 `left` 指针指向 `p`;
|
||||
5. 将 `node` 的 `right` 指针指向 `p` 的右结点;
|
||||
6. 将 `p` 右结点的 `left` 指针指向 `node`;
|
||||
7. 将 `p` 的 `right` 指针指向 `node`。
|
||||
|
||||
代码实现如下:
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
=== "C++"
|
||||
|
||||
```c++
|
||||
|
|
@ -223,20 +223,20 @@
|
|||
|
||||
流程大致如下:
|
||||
|
||||
1. 将 `p` 下一个结点的值赋给 `p`,以抹掉 `p->value`;
|
||||
2. 新建一个临时结点 `t` 存放 `p->next` 的地址;
|
||||
3. 将 `p` 的 `next` 指针指向 `p` 的下下个结点,以抹掉 `p->next`;
|
||||
4. 删除 `t`。此时虽然原结点 `p` 的地址还在使用,删除的是原结点 `p->next` 的地址,但 `p` 的数据被 `p->next` 覆盖,`p` 名存实亡。
|
||||
1. 将 `p` 下一个结点的值赋给 `p`,以抹掉 `p->value`;
|
||||
2. 新建一个临时结点 `t` 存放 `p->next` 的地址;
|
||||
3. 将 `p` 的 `next` 指针指向 `p` 的下下个结点,以抹掉 `p->next`;
|
||||
4. 删除 `t`。此时虽然原结点 `p` 的地址还在使用,删除的是原结点 `p->next` 的地址,但 `p` 的数据被 `p->next` 覆盖,`p` 名存实亡。
|
||||
|
||||
具体过程可参考下图:
|
||||
|
||||
1. 
|
||||
2. 
|
||||
3. 
|
||||
1. 
|
||||
2. 
|
||||
3. 
|
||||
|
||||
代码实现如下:
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
=== "C++"
|
||||
|
||||
```c++
|
||||
|
|
@ -260,15 +260,15 @@
|
|||
|
||||
流程大致如下:
|
||||
|
||||
1. 将 `p` 左结点的右指针指向 `p` 的右节点;
|
||||
2. 将 `p` 右结点的左指针指向 `p` 的左节点;
|
||||
3. 新建一个临时结点 `t` 存放 `p` 的地址;
|
||||
4. 将 `p` 的右节点地址赋给 `p`,以避免 `p` 变成悬垂指针;
|
||||
5. 删除 `t`。
|
||||
1. 将 `p` 左结点的右指针指向 `p` 的右节点;
|
||||
2. 将 `p` 右结点的左指针指向 `p` 的左节点;
|
||||
3. 新建一个临时结点 `t` 存放 `p` 的地址;
|
||||
4. 将 `p` 的右节点地址赋给 `p`,以避免 `p` 变成悬垂指针;
|
||||
5. 删除 `t`。
|
||||
|
||||
代码实现如下:
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
=== "C++"
|
||||
|
||||
```c++
|
||||
|
|
|
|||
|
|
@ -8,9 +8,9 @@
|
|||
|
||||
一棵红黑树满足如下性质:
|
||||
|
||||
1. 节点是红色或黑色;
|
||||
2. 红色的节点的所有儿子的颜色必须是黑色,即从每个叶子到根的所有路径上不能有两个连续的红色节点;
|
||||
3. 从任一节点到其子树中的每个叶子的所有简单路径上都包含相同数目的黑色节点。(黑高平衡)
|
||||
1. 节点是红色或黑色;
|
||||
2. 红色的节点的所有儿子的颜色必须是黑色,即从每个叶子到根的所有路径上不能有两个连续的红色节点;
|
||||
3. 从任一节点到其子树中的每个叶子的所有简单路径上都包含相同数目的黑色节点。(黑高平衡)
|
||||
|
||||
这保证了从根节点到任意叶子的最长路径(红黑交替)不会超过最短路径(全黑)的二倍。从而保证了树的平衡性。
|
||||
|
||||
|
|
@ -26,8 +26,8 @@
|
|||
|
||||
左偏红黑树对红黑树进行了进一步限制,一个黑色节点的左右儿子:
|
||||
|
||||
- 要么全是黑色;
|
||||
- 要么左儿子是红色,右儿子是黑色。
|
||||
- 要么全是黑色;
|
||||
- 要么左儿子是红色,右儿子是黑色。
|
||||
|
||||
符合条件的情况:
|
||||
|
||||
|
|
@ -515,5 +515,5 @@
|
|||
|
||||
## 参考资料与拓展阅读
|
||||
|
||||
- [Left-Leaning Red-Black Trees](https://sedgewick.io/wp-content/themes/sedgewick/papers/2008LLRB.pdf)- Robert Sedgewick Princeton University
|
||||
- [Balanced Search Trees](https://algs4.cs.princeton.edu/lectures/keynote/33BalancedSearchTrees-2x2.pdf)-\_Algorithms_Robert Sedgewick | Kevin Wayne
|
||||
- [Left-Leaning Red-Black Trees](https://sedgewick.io/wp-content/themes/sedgewick/papers/2008LLRB.pdf)- Robert Sedgewick Princeton University
|
||||
- [Balanced Search Trees](https://algs4.cs.princeton.edu/lectures/keynote/33BalancedSearchTrees-2x2.pdf)-\_Algorithms\_Robert Sedgewick | Kevin Wayne
|
||||
|
|
|
|||
|
|
@ -7,7 +7,7 @@ author: Link-cute, Xeonacid, ouuan, Alphnia, Lyccrius
|
|||
???+ warning "注意"
|
||||
在 [NOI 大纲](https://www.noi.cn/xw/2021-04-02/724387.shtml) 中,单调队列被称为“有序队列”。
|
||||
|
||||
???+note "例题"
|
||||
???+ note "例题"
|
||||
[Sliding Window](http://poj.org/problem?id=2823)
|
||||
|
||||
本题大意是给出一个长度为 $n$ 的数组,编程输出每 $k$ 个连续的数中的最大值和最小值。
|
||||
|
|
@ -74,7 +74,7 @@ Ps. 单调队列中的 "队列" 与正常的队列有一定的区别,稍后会
|
|||
|
||||
Ps. 此处的 "队列" 跟普通队列的一大不同就在于可以从队尾进行操作,STL 中有类似的数据结构 deque。
|
||||
|
||||
???+ note "例题 2 [Luogu P2698 Flowerpot S ](https://www.luogu.com.cn/problem/P2698)"
|
||||
???+ note " 例题 2 [Luogu P2698 Flowerpot S](https://www.luogu.com.cn/problem/P2698)"
|
||||
给出 $N$ 滴水的坐标,$y$ 表示水滴的高度,$x$ 表示它下落到 $x$ 轴的位置。每滴水以每秒 1 个单位长度的速度下落。你需要把花盆放在 $x$ 轴上的某个位置,使得从被花盆接着的第 1 滴水开始,到被花盆接着的最后 1 滴水结束,之间的时间差至少为 $D$。
|
||||
我们认为,只要水滴落到 $x$ 轴上,与花盆的边沿对齐,就认为被接住。给出 $N$ 滴水的坐标和 $D$ 的大小,请算出最小的花盆的宽度 $W$。$1\leq N \leq 100000 , 1 \leq D \leq 1000000, 0 \leq x,y\leq 10^6$
|
||||
|
||||
|
|
|
|||
|
|
@ -20,7 +20,7 @@
|
|||
|
||||
用伪代码描述如下:
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```text
|
||||
insert x
|
||||
while !sta.empty() && sta.top()<x
|
||||
|
|
@ -47,5 +47,5 @@
|
|||
|
||||
## 习题
|
||||
|
||||
- [洛谷 P5788【模板】单调栈](https://www.luogu.com.cn/problem/P5788)
|
||||
- [洛谷 P1901 发射站](https://www.luogu.com.cn/problem/P1901)
|
||||
- [洛谷 P5788【模板】单调栈](https://www.luogu.com.cn/problem/P5788)
|
||||
- [洛谷 P1901 发射站](https://www.luogu.com.cn/problem/P1901)
|
||||
|
|
|
|||
|
|
@ -38,7 +38,7 @@ struct Node {
|
|||
|
||||
需要注意的是,一个节点的儿子链表是按插入时间排序的,即最右边的节点最早成为父节点的儿子,最左边的节点最近成为父节点的儿子。
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
Node* meld(Node* x, Node* y) {
|
||||
// 若有一个为空则直接返回另一个
|
||||
|
|
@ -66,8 +66,8 @@ struct Node {
|
|||
|
||||
为了保证总的均摊复杂度,需要使用一个“两步走”的合并方法:
|
||||
|
||||
1. 把儿子们两两配成一对,用 `meld` 操作把被配成同一对的两个儿子合并到一起(见下图 1),
|
||||
2. 将新产生的堆 **从右往左**(即老的儿子到新的儿子的方向)挨个合并在一起(见下图 2)。
|
||||
1. 把儿子们两两配成一对,用 `meld` 操作把被配成同一对的两个儿子合并到一起(见下图 1),
|
||||
2. 将新产生的堆 **从右往左**(即老的儿子到新的儿子的方向)挨个合并在一起(见下图 2)。
|
||||
|
||||

|
||||
|
||||
|
|
@ -75,7 +75,7 @@ struct Node {
|
|||
|
||||
先实现一个辅助函数 `merges`,作用是合并一个节点的所有兄弟。
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
Node* merges(Node* x) {
|
||||
if (x == nullptr || x->sibling == nullptr)
|
||||
|
|
@ -89,15 +89,15 @@ struct Node {
|
|||
|
||||
最后一句话是该函数的核心,这句话分三部分:
|
||||
|
||||
1. `meld(x,y)`“配对”了 x 和 y。
|
||||
2. `merges(c)` 递归合并 c 和他的兄弟们。
|
||||
3. 将上面 2 个操作产生的 2 个新树合并。
|
||||
1. `meld(x,y)`“配对”了 x 和 y。
|
||||
2. `merges(c)` 递归合并 c 和他的兄弟们。
|
||||
3. 将上面 2 个操作产生的 2 个新树合并。
|
||||
|
||||
需要注意到的是,上文提到了第二步时的合并方向是有要求的(从右往左合并),该递归函数的实现已保证了这个顺序,如果读者需要自行实现迭代版本的话请务必注意保证该顺序,否则复杂度将失去保证。
|
||||
|
||||
有了 `merges` 函数,`delete-min` 操作就显然了。
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
Node* delete_min(Node* x) {
|
||||
Node* t = merges(x->child);
|
||||
|
|
@ -112,7 +112,7 @@ struct Node {
|
|||
|
||||
首先节点的定义修改为:
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
struct Node {
|
||||
LL v;
|
||||
|
|
@ -124,7 +124,7 @@ struct Node {
|
|||
|
||||
`meld` 操作修改为:
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
Node* meld(Node* x, Node* y) {
|
||||
if (x == nullptr) return y;
|
||||
|
|
@ -142,7 +142,7 @@ struct Node {
|
|||
|
||||
`merges` 操作修改为:
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
Node *merges(Node *x) {
|
||||
if (x == nullptr) return nullptr;
|
||||
|
|
@ -159,7 +159,7 @@ struct Node {
|
|||
首先我们发现,当我们减少节点 `x` 的权值之后,以 `x` 为根的子树仍然满足配对堆性质,但 `x` 的父亲和 `x` 之间可能不再满足堆性质。
|
||||
因此我们把整棵以 `x` 为根的子树剖出来,现在两棵树都符合配对堆性质了,然后把他们合并起来,就完成了全部操作。
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
// root为堆的根,x为要操作的节点,v为新的权值,调用时需保证 v <= x->v
|
||||
// 返回值为新的根节点
|
||||
|
|
@ -201,5 +201,5 @@ struct Node {
|
|||
|
||||
[^ref4]: [Towards a Final Analysis of Pairing Heaps](http://web.eecs.umich.edu/~pettie/papers/focs05.pdf)
|
||||
|
||||
- <https://en.wikipedia.org/wiki/Pairing_heap>
|
||||
- <https://brilliant.org/wiki/pairing-heap/>
|
||||
- <https://en.wikipedia.org/wiki/Pairing_heap>
|
||||
- <https://brilliant.org/wiki/pairing-heap/>
|
||||
|
|
|
|||
|
|
@ -26,24 +26,24 @@
|
|||
|
||||
在复制一个节点 $X_{a}$($X$ 节点的第 $a$ 个版本)的新版本 $X_{a+1}$($X$ 节点的第 $a+1$ 个版本)以后:
|
||||
|
||||
- 如果某个儿子节点 $Y$ 不用修改信息,那么就把 $X_{a+1}$ 的指针直接指向 $Y_{a}$($Y$ 节点的第 $a$ 个版本)即可。
|
||||
- 反之,如果要修改 $Y$,那么就在 **递归到下层** 时 **新建** $Y_{a+1}$($Y$ 节点的第 $a+1$ 个版本)这个新节点用于 **存储新的信息**,同时把 $X_{a+1}$ 的指针指向 $Y_{a+1}$($Y$ 节点的第 $a+1$ 个版本)。
|
||||
- 如果某个儿子节点 $Y$ 不用修改信息,那么就把 $X_{a+1}$ 的指针直接指向 $Y_{a}$($Y$ 节点的第 $a$ 个版本)即可。
|
||||
- 反之,如果要修改 $Y$,那么就在 **递归到下层** 时 **新建** $Y_{a+1}$($Y$ 节点的第 $a+1$ 个版本)这个新节点用于 **存储新的信息**,同时把 $X_{a+1}$ 的指针指向 $Y_{a+1}$($Y$ 节点的第 $a+1$ 个版本)。
|
||||
|
||||
## 可持久化
|
||||
|
||||
需要的东西:
|
||||
|
||||
- 一个 `struct` 数组 存 **每个节点** 的信息(一般叫做 `tree` 数组);(当然写 **指针版** 平衡树的大佬就可以考虑不用这个数组了)
|
||||
- 一个 `struct` 数组 存 **每个节点** 的信息(一般叫做 `tree` 数组);(当然写 **指针版** 平衡树的大佬就可以考虑不用这个数组了)
|
||||
|
||||
- 一个 **根节点数组**,存每个版本的*树根*,每次查询版本信息时就从 **根数组存的节点** 开始;
|
||||
- 一个 **根节点数组**,存每个版本的*树根*,每次查询版本信息时就从 **根数组存的节点** 开始;
|
||||
|
||||
- `split()` 分裂 **从树中分裂出两棵树**
|
||||
- `split()` 分裂 **从树中分裂出两棵树**
|
||||
|
||||
- `merge()` 合并 **把两棵树按照随机权值合并**
|
||||
- `merge()` 合并 **把两棵树按照随机权值合并**
|
||||
|
||||
- `newNode()` 新建一个节点
|
||||
- `newNode()` 新建一个节点
|
||||
|
||||
- `build()` 建树
|
||||
- `build()` 建树
|
||||
|
||||
### Split
|
||||
|
||||
|
|
@ -53,8 +53,8 @@
|
|||
|
||||
表示把 $_x$ 为根的树的前 $k$ 个元素放在 **一棵树** 中,剩下的节点构成在另一棵树中,返回这两棵树的根(first 是第一棵树的根,second 是第二棵树的)。
|
||||
|
||||
- 如果 $x$ 的 **左子树** 的 $key \geq k$,那么 **直接递归进左子树**,把左子树分出来的第二颗树和当前的 $x$ **右子树** 合并。
|
||||
- 否则递归 **右子树**。
|
||||
- 如果 $x$ 的 **左子树** 的 $key \geq k$,那么 **直接递归进左子树**,把左子树分出来的第二颗树和当前的 $x$ **右子树** 合并。
|
||||
- 否则递归 **右子树**。
|
||||
|
||||
```cpp
|
||||
static std::pair<int, int> _split(int _x, int k) {
|
||||
|
|
@ -105,15 +105,15 @@ static int _merge(int _x, int _y) {
|
|||
|
||||
## 例题
|
||||
|
||||
???+note "[洛谷 P3835【模版】可持久化平衡树](https://www.luogu.com.cn/problem/P3835)"
|
||||
???+ note "[洛谷 P3835【模版】可持久化平衡树](https://www.luogu.com.cn/problem/P3835)"
|
||||
你需要实现一个数据结构,要求提供如下操作(最开始时数据结构内无数据):
|
||||
|
||||
1. 插入 $x$ 数;
|
||||
2. 删除 $x$ 数(若有多个相同的数,应只删除一个,如果没有请忽略该操作);
|
||||
3. 查询 $x$ 数的排名(排名定义为比当前数小的数的个数 + 1);
|
||||
4. 查询排名为 $x$ 的数;
|
||||
5. 求 $x$ 的前驱(前驱定义为小于 $x$,且最大的数,如不存在输出 $-2\,147\,483\,647$);
|
||||
6. 求 $x$ 的后继(后继定义为大于 $x$,且最小的数,如不存在输出 $2\,147\,483\,647$)。
|
||||
1. 插入 $x$ 数;
|
||||
2. 删除 $x$ 数(若有多个相同的数,应只删除一个,如果没有请忽略该操作);
|
||||
3. 查询 $x$ 数的排名(排名定义为比当前数小的数的个数 + 1);
|
||||
4. 查询排名为 $x$ 的数;
|
||||
5. 求 $x$ 的前驱(前驱定义为小于 $x$,且最大的数,如不存在输出 $-2\,147\,483\,647$);
|
||||
6. 求 $x$ 的后继(后继定义为大于 $x$,且最小的数,如不存在输出 $2\,147\,483\,647$)。
|
||||
|
||||
以上操作均基于某一个历史版本,同时生成一个新的版本(操作 3, 4, 5, 6 即保持原版本无变化)。而每个版本的编号则为操作的序号。特别地,最初的版本编号为 0。
|
||||
|
||||
|
|
@ -123,8 +123,8 @@ static int _merge(int _x, int _y) {
|
|||
|
||||
## 推荐的练手题
|
||||
|
||||
1. [「Luogu P3919」可持久化数组(模板题)](https://www.luogu.com.cn/problem/P3919)
|
||||
1. [「Luogu P3919」可持久化数组(模板题)](https://www.luogu.com.cn/problem/P3919)
|
||||
|
||||
2. [「Codeforces 702F」T-shirt](http://codeforces.com/problemset/problem/702/F)
|
||||
2. [「Codeforces 702F」T-shirt](http://codeforces.com/problemset/problem/702/F)
|
||||
|
||||
3. [「Luogu P5055」可持久化文艺平衡树](https://www.luogu.com.cn/problem/P5055)
|
||||
3. [「Luogu P5055」可持久化文艺平衡树](https://www.luogu.com.cn/problem/P5055)
|
||||
|
|
|
|||
|
|
@ -1 +0,0 @@
|
|||
|
||||
|
|
@ -10,13 +10,13 @@
|
|||
|
||||
回顾左偏树的合并过程,假设我们要合并分别以 $x,y$ 为根节点的两棵左偏树,且维护的左偏树满足小根堆的性质:
|
||||
|
||||
1. 如果 $x,y$ 中有结点为空,返回 $x+y$。
|
||||
1. 如果 $x,y$ 中有结点为空,返回 $x+y$。
|
||||
|
||||
2. 选择 $x,y$ 两结点中权值更小的结点,作为合并后左偏树的根。
|
||||
2. 选择 $x,y$ 两结点中权值更小的结点,作为合并后左偏树的根。
|
||||
|
||||
3. 递归合并 $x$ 的右子树与 $y$,将合并后的根节点作为 $x$ 的右儿子。
|
||||
3. 递归合并 $x$ 的右子树与 $y$,将合并后的根节点作为 $x$ 的右儿子。
|
||||
|
||||
4. 维护当前合并后左偏树的左偏性质,维护 `dist` 值,返回选择的根节点。
|
||||
4. 维护当前合并后左偏树的左偏性质,维护 `dist` 值,返回选择的根节点。
|
||||
|
||||
由于每次递归都会使 `dist[x]+dist[y]` 减少一,而 `dist[x]` 是 $O(\log n)$ 的,一次最多只会修改 $O(\log n)$ 个结点,所以这样做的时间复杂度是 $O(\log n)$ 的。
|
||||
|
||||
|
|
@ -24,13 +24,13 @@
|
|||
|
||||
所以可持久化左偏树的合并过程是这样的:
|
||||
|
||||
1. 如果 $x,y$ 中有结点为空,返回 $x+y$。
|
||||
1. 如果 $x,y$ 中有结点为空,返回 $x+y$。
|
||||
|
||||
2. 选择 $x,y$ 两结点中权值更小的结点,新建该结点的一个复制 $p$,作为合并后左偏树的根。
|
||||
2. 选择 $x,y$ 两结点中权值更小的结点,新建该结点的一个复制 $p$,作为合并后左偏树的根。
|
||||
|
||||
3. 递归合并 $p$ 的右子树与 $y$,将合并后的根节点作为 $p$ 的右儿子。
|
||||
3. 递归合并 $p$ 的右子树与 $y$,将合并后的根节点作为 $p$ 的右儿子。
|
||||
|
||||
4. 维护以 $p$ 为根的左偏树的左偏性质,维护其 `dist` 值,返回 $p$。
|
||||
4. 维护以 $p$ 为根的左偏树的左偏性质,维护其 `dist` 值,返回 $p$。
|
||||
|
||||
由于左偏树一次最多只会修改并新建 $O(\log n)$ 个结点,设操作次数为 $m$,则可持久化左偏树的时间复杂度和空间复杂度均为 $O(m\log n)$。
|
||||
|
||||
|
|
|
|||
|
|
@ -2,7 +2,7 @@
|
|||
|
||||
主席树全称是可持久化权值线段树,参见 [知乎讨论](https://www.zhihu.com/question/59195374)。
|
||||
|
||||
???+warning "关于函数式线段树"
|
||||
???+ warning "关于函数式线段树"
|
||||
**函数式线段树** 是指使用函数式编程思想的线段树。在函数式编程思想中,将计算机运算视为数学函数,并避免可改变的状态或变量。不难发现,函数式线段树是 [完全可持久化](../persistent/#完全可持久化-fully-persistent) 的。
|
||||
|
||||
## 引入
|
||||
|
|
|
|||
|
|
@ -4,11 +4,11 @@
|
|||
|
||||
大部分的可持久化 Trie 题中,Trie 都是以 [01-Trie](../string/trie.md#维护异或极值) 的形式出现的。
|
||||
|
||||
??? note " 例题[最大异或和](https://www.luogu.com.cn/problem/P4735)"
|
||||
??? note " 例题 [最大异或和](https://www.luogu.com.cn/problem/P4735)"
|
||||
对一个长度为 $n$ 的数组 $a$ 维护以下操作:
|
||||
|
||||
1. 在数组的末尾添加一个数 $x$,数组的长度 $n$ 自增 $1$。
|
||||
2. 给出查询区间 $[l,r]$ 和一个值 $k$,求当 $l\le p\le r$ 时,$k \oplus \bigoplus^{n}_{i=p} a_i$ 的最大值。
|
||||
1. 在数组的末尾添加一个数 $x$,数组的长度 $n$ 自增 $1$。
|
||||
2. 给出查询区间 $[l,r]$ 和一个值 $k$,求当 $l\le p\le r$ 时,$k \oplus \bigoplus^{n}_{i=p} a_i$ 的最大值。
|
||||
|
||||
## 过程
|
||||
|
||||
|
|
|
|||
|
|
@ -38,5 +38,5 @@ author: morris821028
|
|||
|
||||
## 参考
|
||||
|
||||
- <https://en.wikipedia.org/wiki/Persistent_data_structure>
|
||||
- MIT 课程 <https://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-854j-advanced-algorithms-fall-2005/lecture-notes/persistent.pdf>
|
||||
- <https://en.wikipedia.org/wiki/Persistent_data_structure>
|
||||
- MIT 课程 <https://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-854j-advanced-algorithms-fall-2005/lecture-notes/persistent.pdf>
|
||||
|
|
|
|||
|
|
@ -59,10 +59,10 @@ PQ 树有三种结点:**叶子结点**、**P 结点** 和 **Q 结点**。其
|
|||
|
||||
如果 $u$ 有黑色儿子和白色儿子,且 $u$ 不是相关根,那么做以下操作:
|
||||
|
||||
- 新建一个 P 结点 $f$ 成为所有黑色儿子的根。
|
||||
- 新建一个 P 结点 $e$ 成为所有白色儿子的根。
|
||||
- 如果 $e$(和/或 $f$)只有一个儿子,那么不要新建结点,而是将 $e$(和/或 $f$)直接赋值成那个儿子。
|
||||
- 将 $u$ 改成 Q 结点并把其儿子设为 $e$ 和 $f$,将其标记为灰色。
|
||||
- 新建一个 P 结点 $f$ 成为所有黑色儿子的根。
|
||||
- 新建一个 P 结点 $e$ 成为所有白色儿子的根。
|
||||
- 如果 $e$(和/或 $f$)只有一个儿子,那么不要新建结点,而是将 $e$(和/或 $f$)直接赋值成那个儿子。
|
||||
- 将 $u$ 改成 Q 结点并把其儿子设为 $e$ 和 $f$,将其标记为灰色。
|
||||
|
||||
注意到根据之前的定义,Q 结点至少有 3 个儿子,因此这里的 $u$ 被视为一个”伪结点“,并且将在后面被继续处理。
|
||||
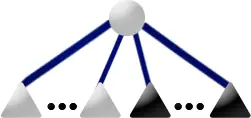
|
||||
|
|
@ -74,22 +74,22 @@ PQ 树有三种结点:**叶子结点**、**P 结点** 和 **Q 结点**。其
|
|||
|
||||
如果 $u$ 有一个灰色儿子 $p$,且 $u$ 不是相关根,那么进行以下操作:
|
||||
|
||||
- 新建一个 P 结点 $f$ 成为所有黑色儿子的根。
|
||||
- 新建一个 P 结点 $e$ 成为所有白色儿子的根。
|
||||
- 如果 $e$(和/或 $f$)只有一个儿子,那么不要新建结点,而是将 $e$(和/或 $f$)直接赋值成那个儿子。
|
||||
- 将 $e$ 的兄弟设为 $p$ 最后一个白色儿子,然后把 $e$ 设为 $p$ 的最后一个儿子。
|
||||
- 将 $f$ 的兄弟设为 $p$ 最后一个黑色儿子,然后把 $f$ 设为 $p$ 的最后一个儿子。
|
||||
- 新建一个 P 结点 $f$ 成为所有黑色儿子的根。
|
||||
- 新建一个 P 结点 $e$ 成为所有白色儿子的根。
|
||||
- 如果 $e$(和/或 $f$)只有一个儿子,那么不要新建结点,而是将 $e$(和/或 $f$)直接赋值成那个儿子。
|
||||
- 将 $e$ 的兄弟设为 $p$ 最后一个白色儿子,然后把 $e$ 设为 $p$ 的最后一个儿子。
|
||||
- 将 $f$ 的兄弟设为 $p$ 最后一个黑色儿子,然后把 $f$ 设为 $p$ 的最后一个儿子。
|
||||
|
||||
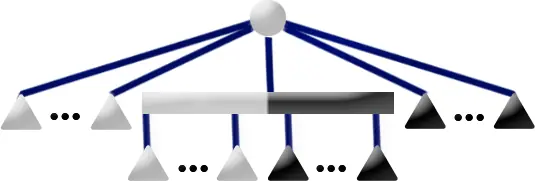
|
||||

|
||||
|
||||
如果 $u$ 恰有两个灰色儿子 $p_1,p_2$,那么进行以下操作:
|
||||
|
||||
- 新建一个 P 结点 $f$ 成为所有黑色儿子的根。
|
||||
- 如果 $f$ 只有一个儿子,那么不要新建结点,而是将 $f$ 直接赋值成那个儿子。
|
||||
- 把 $p_1$ 的最后一个黑色儿子的兄弟设为 $f$。
|
||||
- 把 $f$ 的兄弟设为 $p_2$ 的最后一个黑色儿子。
|
||||
- 把 $p_2$ 的最后一个儿子设为 $p_2$ 的最后一个白色儿子。
|
||||
- 新建一个 P 结点 $f$ 成为所有黑色儿子的根。
|
||||
- 如果 $f$ 只有一个儿子,那么不要新建结点,而是将 $f$ 直接赋值成那个儿子。
|
||||
- 把 $p_1$ 的最后一个黑色儿子的兄弟设为 $f$。
|
||||
- 把 $f$ 的兄弟设为 $p_2$ 的最后一个黑色儿子。
|
||||
- 把 $p_2$ 的最后一个儿子设为 $p_2$ 的最后一个白色儿子。
|
||||
|
||||
可以发现这样 $p_2$ 就被合并进了 $p_1$。
|
||||
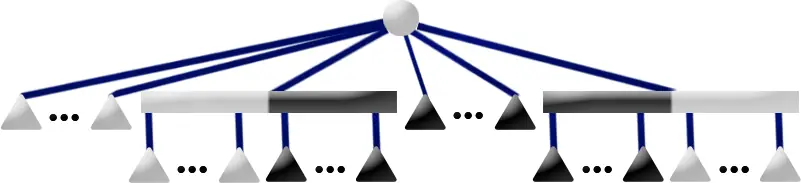
|
||||
|
|
@ -103,10 +103,10 @@ PQ 树有三种结点:**叶子结点**、**P 结点** 和 **Q 结点**。其
|
|||
|
||||
如果 $u$ 有一个灰色儿子 $p$,且所有标记相同的儿子均连续出现,那么进行如下操作:
|
||||
|
||||
- 设 $p_f$ 为 $p$ 最后一个黑色儿子,$p_e$ 为 $p$ 最后一个白色儿子,$f$ 为 $p$ 的黑色兄弟,$e$ 为 $p$ 的白色兄弟。
|
||||
- 将 $f$ 的兄弟设为 $p_f$,$e$ 的兄弟设为 $p_e$。
|
||||
- 如果 $p$ 没有一个白色兄弟或黑色兄弟,将 $u$ 的最后一个儿子设成 $p$ 的最后一个儿子。
|
||||
- 删除 $p$。
|
||||
- 设 $p_f$ 为 $p$ 最后一个黑色儿子,$p_e$ 为 $p$ 最后一个白色儿子,$f$ 为 $p$ 的黑色兄弟,$e$ 为 $p$ 的白色兄弟。
|
||||
- 将 $f$ 的兄弟设为 $p_f$,$e$ 的兄弟设为 $p_e$。
|
||||
- 如果 $p$ 没有一个白色兄弟或黑色兄弟,将 $u$ 的最后一个儿子设成 $p$ 的最后一个儿子。
|
||||
- 删除 $p$。
|
||||
|
||||

|
||||

|
||||
|
|
@ -125,32 +125,32 @@ PQ 树有三种结点:**叶子结点**、**P 结点** 和 **Q 结点**。其
|
|||
|
||||
#### P 结点
|
||||
|
||||
- 如果 $u$ 有多于两个灰色儿子,无解。
|
||||
- 如果 $u$ 只有一个灰色儿子,且没有黑色儿子,递归处理灰色儿子。
|
||||
- 否则先清空 $u$ 的儿子,然后加入所有的白色儿子。新建一个 Q 结点 $q_1$ 并成为 $u$ 的儿子。在 $q_1$ 中加入所有的灰色儿子。新建一个 P 结点 $p$ 作为所有黑色儿子的根,将 $p$ 插入 $q_1$ 的中间。(对应了自底向上法 P 结点的所有情况。)
|
||||
- 如果 $u$ 有多于两个灰色儿子,无解。
|
||||
- 如果 $u$ 只有一个灰色儿子,且没有黑色儿子,递归处理灰色儿子。
|
||||
- 否则先清空 $u$ 的儿子,然后加入所有的白色儿子。新建一个 Q 结点 $q_1$ 并成为 $u$ 的儿子。在 $q_1$ 中加入所有的灰色儿子。新建一个 P 结点 $p$ 作为所有黑色儿子的根,将 $p$ 插入 $q_1$ 的中间。(对应了自底向上法 P 结点的所有情况。)
|
||||
|
||||
注意到我们会要求两个灰色节点白色全在左侧,黑色全在右侧(或相反),因此我们需要实现一个分裂函数 `split`,可以把这个子树的点分裂成黑白部分,并同时保留分裂成的子树的节点的 **所有可能**。
|
||||
|
||||
#### Q 结点
|
||||
|
||||
- 找到最左边和最右边的非白色节点位置 $l,r$。如果 $[l+1,r-1]$ 内有非黑色节点,无解。
|
||||
- 如果没有黑色节点,只有一个灰色节点,递归处理这个灰色节点,否则只需要将 $l$ 和 $r$ 位置的节点分裂。
|
||||
- 找到最左边和最右边的非白色节点位置 $l,r$。如果 $[l+1,r-1]$ 内有非黑色节点,无解。
|
||||
- 如果没有黑色节点,只有一个灰色节点,递归处理这个灰色节点,否则只需要将 $l$ 和 $r$ 位置的节点分裂。
|
||||
|
||||
#### 分裂函数
|
||||
|
||||
令要分裂的点为 $u$,我们想把 $u$ 分裂成左边全是白色,右边全是黑色的森林。如果 $u$ 不是灰色结点则直接返回子树。只考虑灰色结点的情况。
|
||||
如果 $u$ 是 P 类结点:
|
||||
|
||||
- 如果 $u$ 有至少两个灰色儿子,则无解。
|
||||
- 否则左边是所有白色儿子,中间递归处理灰色儿子,右边是所有黑色儿子。注意到要保留所有的可能,因此要新建两个 P 结点分别作为白色儿子和黑色儿子的根。(对应自底向上法的 P4 情况。)
|
||||
- 删除 $u$。
|
||||
- 如果 $u$ 有至少两个灰色儿子,则无解。
|
||||
- 否则左边是所有白色儿子,中间递归处理灰色儿子,右边是所有黑色儿子。注意到要保留所有的可能,因此要新建两个 P 结点分别作为白色儿子和黑色儿子的根。(对应自底向上法的 P4 情况。)
|
||||
- 删除 $u$。
|
||||
|
||||
如果 $u$ 是 Q 类结点:
|
||||
|
||||
- 如果正序和反序都不满足白 - 灰 - 黑,则无解。
|
||||
- 如果有至少两个灰色儿子,也无解。
|
||||
- 否则递归分裂灰色儿子即可。
|
||||
- 删除 $u$。
|
||||
- 如果正序和反序都不满足白 - 灰 - 黑,则无解。
|
||||
- 如果有至少两个灰色儿子,也无解。
|
||||
- 否则递归分裂灰色儿子即可。
|
||||
- 删除 $u$。
|
||||
|
||||
最后把所有多余的结点(只有一个儿子的结点)删除。
|
||||
|
||||
|
|
@ -355,11 +355,11 @@ class PQTree {
|
|||
|
||||
## 习题
|
||||
|
||||
- [CF243E Matrix](https://codeforces.com/problemset/problem/243/E)
|
||||
- [CF1552I Organizing a Music Festival](https://codeforces.com/contest/1552/problem/I)
|
||||
- [CF243E Matrix](https://codeforces.com/problemset/problem/243/E)
|
||||
- [CF1552I Organizing a Music Festival](https://codeforces.com/contest/1552/problem/I)
|
||||
|
||||
## 参考资料
|
||||
|
||||
- Booth, Kellogg S. & Lueker, George S. (1976).["Testing for the consecutive ones property, interval graphs, and graph planarity using PQ-tree algorithms"](https://www.sciencedirect.com/science/article/pii/S0022000076800451?via%3Dihub).*[Journal of Computer and System Sciences](https://en.wikipedia.org/wiki/Journal_of_Computer_and_System_Sciences)*.**13**(3): 335–379.[doi](https://en.wikipedia.org/wiki/Doi_(identifier)):[10.1016/S0022-0000(76)80045-1](https://doi.org/10.1016%2FS0022-0000%2876%2980045-1).
|
||||
- [PQ Tree Algorithm and Consecutive Ones Problem](https://gregable.com/2008/11/pq-tree-algorithm.html)
|
||||
- [CF243E Matrix PQTree - RainAir's Blog](https://blog.aor.sd.cn/archives/1657/)
|
||||
- Booth, Kellogg S. & Lueker, George S. (1976).["Testing for the consecutive ones property, interval graphs, and graph planarity using PQ-tree algorithms"](https://www.sciencedirect.com/science/article/pii/S0022000076800451?via%3Dihub).*[Journal of Computer and System Sciences](https://en.wikipedia.org/wiki/Journal_of_Computer_and_System_Sciences)*.**13**(3): 335–379.[doi](https://en.wikipedia.org/wiki/Doi_\(identifier\)):[10.1016/S0022-0000(76)80045-1](https://doi.org/10.1016%2FS0022-0000%2876%2980045-1).
|
||||
- [PQ Tree Algorithm and Consecutive Ones Problem](https://gregable.com/2008/11/pq-tree-algorithm.html)
|
||||
- [CF243E Matrix PQTree - RainAir's Blog](https://blog.aor.sd.cn/archives/1657/)
|
||||
|
|
|
|||
102
docs/ds/queue.md
102
docs/ds/queue.md
|
|
@ -16,11 +16,11 @@ int q[SIZE], ql = 1, qr;
|
|||
|
||||
队列操作对应的代码如下:
|
||||
|
||||
- 插入元素:`q[++qr] = x;`
|
||||
- 删除元素:`ql++;`
|
||||
- 访问队首:`q[ql]`
|
||||
- 访问队尾:`q[qr]`
|
||||
- 清空队列:`ql = 1; qr = 0;`
|
||||
- 插入元素:`q[++qr] = x;`
|
||||
- 删除元素:`ql++;`
|
||||
- 访问队首:`q[ql]`
|
||||
- 访问队尾:`q[qr]`
|
||||
- 清空队列:`ql = 1; qr = 0;`
|
||||
|
||||
## 双栈模拟队列
|
||||
|
||||
|
|
@ -28,8 +28,8 @@ int q[SIZE], ql = 1, qr;
|
|||
|
||||
这种方法使用两个栈 F, S 模拟一个队列,其中 F 是队尾的栈,S 代表队首的栈,支持 push(在队尾插入),pop(在队首弹出)操作:
|
||||
|
||||
- push:插入到栈 F 中。
|
||||
- pop:如果 S 非空,让 S 弹栈;否则把 F 的元素倒过来压到 S 中(其实就是一个一个弹出插入,做完后是首尾颠倒的),然后再让 S 弹栈。
|
||||
- push:插入到栈 F 中。
|
||||
- pop:如果 S 非空,让 S 弹栈;否则把 F 的元素倒过来压到 S 中(其实就是一个一个弹出插入,做完后是首尾颠倒的),然后再让 S 弹栈。
|
||||
|
||||
容易证明,每个元素只会进入/转移/弹出一次,均摊复杂度 $O(1)$。
|
||||
|
||||
|
|
@ -37,7 +37,7 @@ int q[SIZE], ql = 1, qr;
|
|||
|
||||
C++ 在 STL 中提供了一个容器 `std::queue`,使用前需要先引入 `<queue>` 头文件。
|
||||
|
||||
???+ info "STL 中对 `queue` 的定义"
|
||||
???+ info "STL 中对 `queue` 的定义 "
|
||||
```cpp
|
||||
// clang-format off
|
||||
template<
|
||||
|
|
@ -50,24 +50,24 @@ C++ 在 STL 中提供了一个容器 `std::queue`,使用前需要先引入 `<q
|
|||
|
||||
`Container` 为用于存储元素的底层容器类型。这个容器必须提供通常语义的下列函数:
|
||||
|
||||
- `back()`
|
||||
- `front()`
|
||||
- `push_back()`
|
||||
- `pop_front()`
|
||||
- `back()`
|
||||
- `front()`
|
||||
- `push_back()`
|
||||
- `pop_front()`
|
||||
|
||||
STL 容器 `std::deque` 和 `std::list` 满足这些要求。如果不指定,则默认使用 `std::deque` 作为底层容器。
|
||||
|
||||
STL 中的 `queue` 容器提供了一众成员函数以供调用。其中较为常用的有:
|
||||
|
||||
- 元素访问
|
||||
- `q.front()` 返回队首元素
|
||||
- `q.back()` 返回队尾元素
|
||||
- `q.front()` 返回队首元素
|
||||
- `q.back()` 返回队尾元素
|
||||
- 修改
|
||||
- `q.push()` 在队尾插入元素
|
||||
- `q.pop()` 弹出队首元素
|
||||
- `q.push()` 在队尾插入元素
|
||||
- `q.pop()` 弹出队首元素
|
||||
- 容量
|
||||
- `q.empty()` 队列是否为空
|
||||
- `q.size()` 返回队列中元素的数量
|
||||
- `q.empty()` 队列是否为空
|
||||
- `q.size()` 返回队列中元素的数量
|
||||
|
||||
此外,`queue` 还提供了一些运算符。较为常用的是使用赋值运算符 `=` 为 `queue` 赋值,示例:
|
||||
|
||||
|
|
@ -91,10 +91,10 @@ std::cout << q2.front() << std::endl;
|
|||
|
||||
双端队列是指一个可以在队首/队尾插入或删除元素的队列。相当于是栈与队列功能的结合。具体地,双端队列支持的操作有 4 个:
|
||||
|
||||
- 在队首插入一个元素
|
||||
- 在队尾插入一个元素
|
||||
- 在队首删除一个元素
|
||||
- 在队尾删除一个元素
|
||||
- 在队首插入一个元素
|
||||
- 在队尾插入一个元素
|
||||
- 在队首删除一个元素
|
||||
- 在队尾删除一个元素
|
||||
|
||||
数组模拟双端队列的方式与普通队列相同。
|
||||
|
||||
|
|
@ -102,7 +102,7 @@ std::cout << q2.front() << std::endl;
|
|||
|
||||
C++ 在 STL 中也提供了一个容器 `std::deque`,使用前需要先引入 `<deque>` 头文件。
|
||||
|
||||
??? info "STL 中对 `deque` 的定义"
|
||||
??? info "STL 中对 `deque` 的定义 "
|
||||
```cpp
|
||||
// clang-format off
|
||||
template<
|
||||
|
|
@ -118,23 +118,23 @@ C++ 在 STL 中也提供了一个容器 `std::deque`,使用前需要先引入
|
|||
STL 中的 `deque` 容器提供了一众成员函数以供调用。其中较为常用的有:
|
||||
|
||||
- 元素访问
|
||||
- `q.front()` 返回队首元素
|
||||
- `q.back()` 返回队尾元素
|
||||
- `q.front()` 返回队首元素
|
||||
- `q.back()` 返回队尾元素
|
||||
- 修改
|
||||
- `q.push_back()` 在队尾插入元素
|
||||
- `q.pop_back()` 弹出队尾元素
|
||||
- `q.push_front()` 在队首插入元素
|
||||
- `q.pop_front()` 弹出队首元素
|
||||
- `q.insert()` 在指定位置前插入元素(传入迭代器和元素)
|
||||
- `q.erase()` 删除指定位置的元素(传入迭代器)
|
||||
- `q.push_back()` 在队尾插入元素
|
||||
- `q.pop_back()` 弹出队尾元素
|
||||
- `q.push_front()` 在队首插入元素
|
||||
- `q.pop_front()` 弹出队首元素
|
||||
- `q.insert()` 在指定位置前插入元素(传入迭代器和元素)
|
||||
- `q.erase()` 删除指定位置的元素(传入迭代器)
|
||||
- 容量
|
||||
- `q.empty()` 队列是否为空
|
||||
- `q.size()` 返回队列中元素的数量
|
||||
- `q.empty()` 队列是否为空
|
||||
- `q.size()` 返回队列中元素的数量
|
||||
|
||||
此外,`deque` 还提供了一些运算符。其中较为常用的有:
|
||||
|
||||
- 使用赋值运算符 `=` 为 `deque` 赋值,类似 `queue`。
|
||||
- 使用 `[]` 访问元素,类似 `vector`。
|
||||
- 使用赋值运算符 `=` 为 `deque` 赋值,类似 `queue`。
|
||||
- 使用 `[]` 访问元素,类似 `vector`。
|
||||
|
||||
`<queue>` 头文件中还提供了优先队列 `std::priority_queue`,因其与 [堆](./heap.md) 更为相似,在此不作过多介绍。
|
||||
|
||||
|
|
@ -144,7 +144,7 @@ STL 中的 `deque` 容器提供了一众成员函数以供调用。其中较为
|
|||
|
||||
示例如下:
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```python
|
||||
from collections import deque
|
||||
|
||||
|
|
@ -170,29 +170,29 @@ STL 中的 `deque` 容器提供了一众成员函数以供调用。其中较为
|
|||
|
||||
## 例题
|
||||
|
||||
???+note "[LOJ6515「雅礼集训 2018 Day10」贪玩蓝月](https://loj.ac/problem/6515)"
|
||||
???+ note "[LOJ6515「雅礼集训 2018 Day10」贪玩蓝月](https://loj.ac/problem/6515)"
|
||||
一个双端队列(deque),m 个事件:
|
||||
|
||||
1. 在前端插入 (w,v)
|
||||
2. 在后端插入 (w,v)
|
||||
3. 删除前端的二元组
|
||||
4. 删除后端的二元组
|
||||
1. 在前端插入 (w,v)
|
||||
2. 在后端插入 (w,v)
|
||||
3. 删除前端的二元组
|
||||
4. 删除后端的二元组
|
||||
5. 给定 l,r,在当前 deque 中选择一个子集 S 使得 $\sum_{(w,v)\in S}w\bmod p\in[l,r]$,且最大化 $\sum_{(w,v)\in S}v$.
|
||||
|
||||
$m\leq 5\times 10^4,p\leq 500$.
|
||||
|
||||
??? note "解题思路"
|
||||
每个二元组是有一段存活时间的,因此对时间建立线段树,每个二元组做 log 个存活标记。因此我们要做的就是对每个询问,求其到根节点的路径上的标记的一个最优子集。显然这个可以 DP 做。$f[S,j]$ 表示选择集合 S 中的物品余数为 j 的最大价值。(其实实现的时侯是有序的,直接 f[i,j]做)
|
||||
每个二元组是有一段存活时间的,因此对时间建立线段树,每个二元组做 log 个存活标记。因此我们要做的就是对每个询问,求其到根节点的路径上的标记的一个最优子集。显然这个可以 DP 做。$f[S,j]$ 表示选择集合 S 中的物品余数为 j 的最大价值。(其实实现的时侯是有序的,直接 f\[i,j] 做)
|
||||
|
||||
一共有 $O(m\log m)$ 个标记,因此这么做的话复杂度是 $O(mp\log m)$ 的。
|
||||
|
||||
* * *
|
||||
***
|
||||
|
||||
这是一个在线算法比离线算法快的神奇题目。而且还比离线的好写。
|
||||
|
||||
上述离线算法其实是略微小题大做的,因为如果把题目的 deque 改成直接维护一个集合的话(即随机删除集合内元素),那么离线算法同样适用。既然是 deque,不妨在数据结构上做点文章。
|
||||
|
||||
* * *
|
||||
***
|
||||
|
||||
如果题目中维护的数据结构是一个栈呢?
|
||||
|
||||
|
|
@ -206,13 +206,13 @@ STL 中的 `deque` 容器提供了一众成员函数以供调用。其中较为
|
|||
|
||||
删除的时侯直接指针前移即可。这样做的复杂度是 $O(mp)$ 的。
|
||||
|
||||
* * *
|
||||
***
|
||||
|
||||
如果题目中维护的数据结构是队列?
|
||||
|
||||
有一种操作叫双栈模拟队列。这就是这个东西的用武之地。因为用栈是可以轻松维护 DP 过程的,而双栈模拟队列的复杂度是均摊 $O(1)$ 的,因此,复杂度仍是 $O(mp)$。
|
||||
|
||||
* * *
|
||||
***
|
||||
|
||||
回到原题,那么 Deque 怎么做?
|
||||
|
||||
|
|
@ -222,7 +222,7 @@ STL 中的 `deque` 容器提供了一众成员函数以供调用。其中较为
|
|||
|
||||
这样的复杂度其实均摊下来仍是常数级别。具体地说,丢一半指的是把一个栈靠近栈底的一半倒过来丢到另一个栈中。也就是说要手写栈以支持这样的操作。
|
||||
|
||||
* * *
|
||||
***
|
||||
|
||||
似乎可以用 [势能分析法](https://yhx-12243.github.io/OI-transit/records/cf601E.html) 证明。其实本蒟蒻有一个很仙的想法。我们考虑这个双栈结构的整体复杂度。m 个事件,我们希望尽可能增加这个结构的复杂度。
|
||||
|
||||
|
|
@ -242,9 +242,9 @@ STL 中的 `deque` 容器提供了一众成员函数以供调用。其中较为
|
|||
|
||||
于是,总复杂度仍是 $O(mp)$。
|
||||
|
||||
* * *
|
||||
***
|
||||
|
||||
在询问的时侯,我们要处理的应该是“在两个栈中选若干个元素的最大价值”的问题。因此要对栈顶的 DP 值做查询,即两个 $f,g$ 对于询问[l,r]的最大价值:
|
||||
在询问的时侯,我们要处理的应该是“在两个栈中选若干个元素的最大价值”的问题。因此要对栈顶的 DP 值做查询,即两个 $f,g$ 对于询问 \[l,r] 的最大价值:
|
||||
|
||||
$$
|
||||
\max_{0\leq i<p}\left\{f[i]+\max_{l\leq i+j\leq r}g_j\right\}
|
||||
|
|
@ -259,5 +259,5 @@ STL 中的 `deque` 容器提供了一众成员函数以供调用。其中较为
|
|||
|
||||
## 参考资料
|
||||
|
||||
1. [std::queue - zh.cppreference.com](https://zh.cppreference.com/w/cpp/container/queue)
|
||||
2. [std::deque - zh.cppreference.com](https://zh.cppreference.com/w/cpp/container/deque)
|
||||
1. [std::queue - zh.cppreference.com](https://zh.cppreference.com/w/cpp/container/queue)
|
||||
2. [std::deque - zh.cppreference.com](https://zh.cppreference.com/w/cpp/container/deque)
|
||||
|
|
|
|||
|
|
@ -4,10 +4,10 @@
|
|||
|
||||
一棵合法的红黑树必须遵循以下四条性质:
|
||||
|
||||
1. 节点为红色或黑色
|
||||
2. NIL 节点(空叶子节点)为黑色
|
||||
3. 红色节点的子节点为黑色
|
||||
4. 从根节点到 NIL 节点的每条路径上的黑色节点数量相同
|
||||
1. 节点为红色或黑色
|
||||
2. NIL 节点(空叶子节点)为黑色
|
||||
3. 红色节点的子节点为黑色
|
||||
4. 从根节点到 NIL 节点的每条路径上的黑色节点数量相同
|
||||
|
||||
下图为一棵合法的红黑树:
|
||||
|
||||
|
|
@ -66,7 +66,7 @@ class RBTreeMap {
|
|||
|
||||
这里给出红黑树中节点的左旋操作的示例代码:
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
void rotateLeft(ConstNodePtr node) {
|
||||
// clang-format off
|
||||
|
|
@ -127,7 +127,7 @@ class RBTreeMap {
|
|||
|
||||
当前节点 N 的父节点 P 是为根节点且为红色,将其染为黑色即可,此时性质也已满足,不需要进一步修正。
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
// clang-format off
|
||||
// Case 3: Parent is root and is RED
|
||||
|
|
@ -151,12 +151,12 @@ class RBTreeMap {
|
|||
|
||||
因此,这种情况的维护需要:
|
||||
|
||||
1. 将 P,U 节点染黑,将 G 节点染红(可以保证每条路径上黑色节点个数不发生改变)。
|
||||
2. 递归维护 G 节点(因为不确定 G 的父节点的状态,递归维护可以确保性质 3 成立)。
|
||||
1. 将 P,U 节点染黑,将 G 节点染红(可以保证每条路径上黑色节点个数不发生改变)。
|
||||
2. 递归维护 G 节点(因为不确定 G 的父节点的状态,递归维护可以确保性质 3 成立)。
|
||||
|
||||

|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
// clang-format off
|
||||
// Case 4: Both parent and uncle are RED
|
||||
|
|
@ -184,7 +184,7 @@ class RBTreeMap {
|
|||
|
||||

|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
// clang-format off
|
||||
// Case 5: Current node is the opposite direction as parent
|
||||
|
|
@ -217,12 +217,12 @@ class RBTreeMap {
|
|||
|
||||
因此,这种情况的维护需要:
|
||||
|
||||
1. 若 N 为左子节点则左旋祖父节点 G,否则右旋祖父节点 G.(该操作使得旋转过后 P - N 这条路径上的黑色节点个数比 P - G - U 这条路径上少 1,暂时打破性质 4)。
|
||||
2. 重新染色,将 P 染黑,将 N 染红,同时满足了性质 3 和 4。
|
||||
1. 若 N 为左子节点则左旋祖父节点 G,否则右旋祖父节点 G.(该操作使得旋转过后 P - N 这条路径上的黑色节点个数比 P - G - U 这条路径上少 1,暂时打破性质 4)。
|
||||
2. 重新染色,将 P 染黑,将 N 染红,同时满足了性质 3 和 4。
|
||||
|
||||

|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
// clang-format off
|
||||
// Case 6: Current node is the same direction as parent
|
||||
|
|
@ -266,7 +266,7 @@ class RBTreeMap {
|
|||
|
||||
注:这里选择的前驱或后继节点保证不会是一个既有非 NIL 左子节点又有非 NIL 右子节点的节点。这里拿后继节点进行简单说明:若该节点包含非空左子节点,则该节点并非是 N 节点右子树上键值最小的节点,与后继节点的性质矛盾,因此后继节点的左子节点必须为 NIL。
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
// clang-format off
|
||||
// Case 1: If the node is strictly internal
|
||||
|
|
@ -304,7 +304,7 @@ class RBTreeMap {
|
|||
|
||||
注:由于维护操作不会改变待删除节点的任何结构和数据,因此此处的代码示例中为了实现方便起见选择先进行维护,再解引用相关节点。
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
// clang-format off
|
||||
// Case 2: Current node is a leaf
|
||||
|
|
@ -328,7 +328,7 @@ class RBTreeMap {
|
|||
|
||||
待删除节点有且仅有一个非 NIL 子节点,若待删除节点为红色,直接使用其子节点 S 替换即可;若为黑色,则直接使用子节点 S 替代会打破性质 4,需要在使用 S 替代后判断 S 的颜色,若为红色,则将其染黑后即可满足性质 4,否则需要进行维护才可以满足性质 4。
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
// Case 3: Current node has a single left or right child
|
||||
// Step 1. Replace N with its child
|
||||
|
|
@ -369,13 +369,13 @@ class RBTreeMap {
|
|||
|
||||
这种情况的维护需要:
|
||||
|
||||
1. 若待删除节点 N 为左子节点,左旋 P; 若为右子节点,右旋 P。
|
||||
2. 将 S 染黑,P 染红(保证 S 节点的父节点满足性质 4)。
|
||||
3. 此时只需根据结构对以当前 P 节点为根的子树进行维护即可(无需再考虑旋转染色后的 S 和 D 节点)。
|
||||
1. 若待删除节点 N 为左子节点,左旋 P; 若为右子节点,右旋 P。
|
||||
2. 将 S 染黑,P 染红(保证 S 节点的父节点满足性质 4)。
|
||||
3. 此时只需根据结构对以当前 P 节点为根的子树进行维护即可(无需再考虑旋转染色后的 S 和 D 节点)。
|
||||
|
||||

|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
// clang-format off
|
||||
|
||||
|
|
@ -410,7 +410,7 @@ class RBTreeMap {
|
|||
|
||||

|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
// clang-format off
|
||||
// Case 2: Sibling and nephews are BLACK, parent is RED
|
||||
|
|
@ -434,7 +434,7 @@ class RBTreeMap {
|
|||
|
||||

|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
// clang-format off
|
||||
// Case 3: Sibling, parent and nephews are all black
|
||||
|
|
@ -459,13 +459,13 @@ class RBTreeMap {
|
|||
|
||||
该过程分为三步:
|
||||
|
||||
1. 若 N 为左子节点,右旋 P,否则左旋 P。
|
||||
2. 将节点 C 染红,将节点 S 染黑。
|
||||
3. 此时已满足 Case 5 的条件,进入 Case 5 完成后续维护。
|
||||
1. 若 N 为左子节点,右旋 P,否则左旋 P。
|
||||
2. 将节点 C 染红,将节点 S 染黑。
|
||||
3. 此时已满足 Case 5 的条件,进入 Case 5 完成后续维护。
|
||||
|
||||

|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
// clang-format off
|
||||
// Case 4: Sibling is BLACK, close nephew is RED,
|
||||
|
|
@ -499,13 +499,13 @@ class RBTreeMap {
|
|||
|
||||
兄弟节点是黑色,且 close nephew 节点 C 为红色,distant nephew 节点 D 为黑色,父节点既可为红色又可为黑色。此时性质 4 无法满足,通过旋转操作使得黑色节点 S 变为该子树的根节点再进行染色即可满足性质 4。具体步骤如下:
|
||||
|
||||
1. 若 N 为左子节点,左旋 P,反之右旋 P。
|
||||
2. 交换父节点 P 和兄弟节点 S 的颜色,此时性质 3 可能被打破。
|
||||
3. 将 distant nephew 节点 D 染黑,同时保证了性质 3 和 4。
|
||||
1. 若 N 为左子节点,左旋 P,反之右旋 P。
|
||||
2. 交换父节点 P 和兄弟节点 S 的颜色,此时性质 3 可能被打破。
|
||||
3. 将 distant nephew 节点 D 染黑,同时保证了性质 3 和 4。
|
||||
|
||||

|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
// clang-format off
|
||||
// Case 5: Sibling is BLACK, close nephew is BLACK,
|
||||
|
|
@ -550,7 +550,7 @@ class RBTreeMap {
|
|||
|
||||
源码:
|
||||
|
||||
- [linux/lib/rbtree.c](https://elixir.bootlin.com/linux/latest/source/lib/rbtree.c)
|
||||
- [linux/lib/rbtree.c](https://elixir.bootlin.com/linux/latest/source/lib/rbtree.c)
|
||||
|
||||
Linux 中的红黑树所有操作均使用循环迭代进行实现,保证效率的同时又增加了大量的注释来保证代码可读性,十分建议读者阅读学习。Linux 内核中的红黑树使用非常广泛,这里仅列举几个经典案例。
|
||||
|
||||
|
|
@ -566,8 +566,8 @@ epoll 全称 event poll,是 Linux 内核实现 IO 多路复用 (IO multiplexin
|
|||
|
||||
源码:
|
||||
|
||||
- [nginx/src/core/ngx_rbtree.h](https://github.com/nginx/nginx/blob/master/src/core/ngx_rbtree.h)
|
||||
- [nginx/src/core/ngx_rbtree.c](https://github.com/nginx/nginx/blob/master/src/core/ngx_rbtree.c)
|
||||
- [nginx/src/core/ngx\_rbtree.h](https://github.com/nginx/nginx/blob/master/src/core/ngx_rbtree.h)
|
||||
- [nginx/src/core/ngx\_rbtree.c](https://github.com/nginx/nginx/blob/master/src/core/ngx_rbtree.c)
|
||||
|
||||
nginx 中的用户态定时器是通过红黑树实现的。在 nginx 中,所有 timer 节点都由一棵红黑树进行维护,在 worker 进程的每一次循环中都会调用 `ngx_process_events_and_timers` 函数,在该函数中就会调用处理定时器的函数 `ngx_event_expire_timers`,每次该函数都不断的从红黑树中取出时间值最小的,查看他们是否已经超时,然后执行他们的函数,直到取出的节点的时间没有超时为止。
|
||||
|
||||
|
|
@ -578,14 +578,14 @@ nginx 中的用户态定时器是通过红黑树实现的。在 nginx 中,所
|
|||
源码:
|
||||
|
||||
- GNU libstdc++
|
||||
- [libstdc++-v3/include/bits/stl_tree.h](https://github.com/gcc-mirror/gcc/blob/master/libstdc%2B%2B-v3/include/bits/stl_tree.h)
|
||||
- [libstdc++-v3/src/c++98/tree.cc](https://github.com/gcc-mirror/gcc/blob/master/libstdc%2B%2B-v3/src/c%2B%2B98/tree.cc)
|
||||
- [libstdc++-v3/include/bits/stl\_tree.h](https://github.com/gcc-mirror/gcc/blob/master/libstdc%2B%2B-v3/include/bits/stl_tree.h)
|
||||
- [libstdc++-v3/src/c++98/tree.cc](https://github.com/gcc-mirror/gcc/blob/master/libstdc%2B%2B-v3/src/c%2B%2B98/tree.cc)
|
||||
|
||||
- LLVM libcxx
|
||||
- [libcxx/include/\_\_tree](https://github.com/llvm/llvm-project/blob/main/libcxx/include/__tree)
|
||||
- [libcxx/include/\_\_tree](https://github.com/llvm/llvm-project/blob/main/libcxx/include/__tree)
|
||||
|
||||
- Microsoft STL
|
||||
- [stl/inc/xtree](https://github.com/microsoft/STL/blob/main/stl/inc/xtree)
|
||||
- [stl/inc/xtree](https://github.com/microsoft/STL/blob/main/stl/inc/xtree)
|
||||
|
||||
大多数 STL 中的 `std::map` 和 `std::set` 的内部数据结构就是一棵红黑树(例如上面提到的这些)。不过值得注意的是,这些红黑树(包括可能有读者用过的 `std::_Rb_tree`) 都不是 C++ 标准,虽然部分竞赛(例如 NOIP) 并未命令禁止这类数据结构,但还是应当注意这类标准库中的非标准实现不应该在工程项目中直接使用。
|
||||
|
||||
|
|
@ -595,9 +595,9 @@ nginx 中的用户态定时器是通过红黑树实现的。在 nginx 中,所
|
|||
|
||||
源码:
|
||||
|
||||
- [java.util.TreeMap<K, V>](https://github.com/openjdk/jdk/blob/master/src/java.base/share/classes/java/util/TreeMap.java)
|
||||
- [java.util.TreeSet<K, V>](https://github.com/openjdk/jdk/blob/master/src/java.base/share/classes/java/util/TreeSet.java)
|
||||
- [java.util.HashMap<K, V>](https://github.com/openjdk/jdk/blob/master/src/java.base/share/classes/java/util/HashMap.java)
|
||||
- [java.util.TreeMap\<K, V>](https://github.com/openjdk/jdk/blob/master/src/java.base/share/classes/java/util/TreeMap.java)
|
||||
- [java.util.TreeSet\<K, V>](https://github.com/openjdk/jdk/blob/master/src/java.base/share/classes/java/util/TreeSet.java)
|
||||
- [java.util.HashMap\<K, V>](https://github.com/openjdk/jdk/blob/master/src/java.base/share/classes/java/util/HashMap.java)
|
||||
|
||||
JDK 中的 `TreeMap` 和 `TreeSet` 都是使用红黑树作为底层数据结构的。同时在 JDK 1.8 之后 `HashMap` 内部哈希表中每个表项的链表长度超过 8 时也会自动转变为红黑树以提升查找效率。
|
||||
|
||||
|
|
@ -614,5 +614,5 @@ JDK 中的 `TreeMap` 和 `TreeSet` 都是使用红黑树作为底层数据结构
|
|||
|
||||
## 其他资料
|
||||
|
||||
- [Red-Black Tree - Wikipedia](https://en.wikipedia.org/wiki/Red%E2%80%93black_tree)
|
||||
- [Red-Black Tree Visualization](https://www.cs.usfca.edu/~galles/visualization/RedBlack.html)
|
||||
- [Red-Black Tree - Wikipedia](https://en.wikipedia.org/wiki/Red%E2%80%93black_tree)
|
||||
- [Red-Black Tree Visualization](https://www.cs.usfca.edu/~galles/visualization/RedBlack.html)
|
||||
|
|
|
|||
|
|
@ -8,17 +8,17 @@
|
|||
|
||||
> 维护一个序列 $a$:
|
||||
>
|
||||
> 1. `0 l r t` $\forall l\le i\le r,\ a_i=\min(a_i,t)$。
|
||||
> 2. `1 l r` 输出区间 $[l,r]$ 中的最大值。
|
||||
> 3. `2 l r` 输出区间和。
|
||||
> 1. `0 l r t` $\forall l\le i\le r,\ a_i=\min(a_i,t)$。
|
||||
> 2. `1 l r` 输出区间 $[l,r]$ 中的最大值。
|
||||
> 3. `2 l r` 输出区间和。
|
||||
>
|
||||
> 多组数据,$T\le 100,n\le 10^6,\sum m\le 10^6$。
|
||||
|
||||
区间取 min,意味着只对那些大于 $t$ 的数有更改。因此这个操作的对象不再是整个区间,而是“这个区间中大于 $t$ 的数”。于是我们可以有这样的思路:每个结点维护该区间的最大值 $Max$、次大值 $Se$、区间和 $Sum$ 以及最大值的个数 $Cnt$。接下来我们考虑区间对 $t$ 取 $\min$ 的操作。
|
||||
|
||||
1. 如果 $Max\le t$,显然这个 $t$ 是没有意义的,直接返回;
|
||||
2. 如果 $Se<t\le Max$,那么这个 $t$ 就能更新当前区间中的最大值。于是我们让区间和加上 $Cnt(t-Max)$,然后更新 $Max$ 为 $t$,并打一个标记。
|
||||
3. 如果 $t\le Se$,那么这时你发现你不知道有多少个数涉及到更新的问题。于是我们的策略就是,暴力递归向下操作。然后上传信息。
|
||||
1. 如果 $Max\le t$,显然这个 $t$ 是没有意义的,直接返回;
|
||||
2. 如果 $Se<t\le Max$,那么这个 $t$ 就能更新当前区间中的最大值。于是我们让区间和加上 $Cnt(t-Max)$,然后更新 $Max$ 为 $t$,并打一个标记。
|
||||
3. 如果 $t\le Se$,那么这时你发现你不知道有多少个数涉及到更新的问题。于是我们的策略就是,暴力递归向下操作。然后上传信息。
|
||||
|
||||
这个算法的复杂度如何?使用势能分析法可以得到复杂度是 $O(m\log n)$ 的。具体分析过程见论文。
|
||||
|
||||
|
|
@ -34,10 +34,10 @@
|
|||
|
||||
同样的方法,我们维护最大、次大、最大个数、最小、次小、最小个数、区间和。除了这些信息,我们还需要维护区间 $\max$、区间 $\min$、区间加的标记。相比上一道题,这就涉及到标记下传的顺序问题了。我们采用这样的策略:
|
||||
|
||||
1. 我们认为区间加的标记是最优先的,其余两种标记地位平等。
|
||||
2. 对一个结点加上一个 $v$ 标记,除了用 $v$ 更新卫星信息和当前结点的区间加标记外,我们用这个 v 更新区间 $\max$ 和区间 $\min$ 的标记。
|
||||
3. 对一个结点取 $v$ 的 $\min$(这里忽略暴搜的过程,假定标记满足添加的条件),除了更新卫星信息,我们要与区间 $\max$ 的标记做比较。如果 $v$ 小于区间 $\max$ 的标记,则所有的数最后都会变成 v,那么把区间 $\max$ 的标记也变成 $v$。否则不管。
|
||||
4. 区间取 v 的 $\max$ 同理。
|
||||
1. 我们认为区间加的标记是最优先的,其余两种标记地位平等。
|
||||
2. 对一个结点加上一个 $v$ 标记,除了用 $v$ 更新卫星信息和当前结点的区间加标记外,我们用这个 v 更新区间 $\max$ 和区间 $\min$ 的标记。
|
||||
3. 对一个结点取 $v$ 的 $\min$(这里忽略暴搜的过程,假定标记满足添加的条件),除了更新卫星信息,我们要与区间 $\max$ 的标记做比较。如果 $v$ 小于区间 $\max$ 的标记,则所有的数最后都会变成 v,那么把区间 $\max$ 的标记也变成 $v$。否则不管。
|
||||
4. 区间取 v 的 $\max$ 同理。
|
||||
|
||||
另外,BZOJ 这道题卡常……多数组线段树的常数比结构体线段树的常数大……在维护信息的时侯,当只有一两个数的时侯可能发生数集重合,比如一个数既是最大值又是次小值。这种要特判。
|
||||
|
||||
|
|
@ -51,10 +51,10 @@
|
|||
|
||||
> 两个序列 $A,B$,一开始 $B$ 中的数都是 $0$。维护的操作是:
|
||||
>
|
||||
> 1. 对 $A$ 做区间取 $\min$
|
||||
> 2. 对 $A$ 做区间取 $\max$
|
||||
> 3. 对 $A$ 做区间加
|
||||
> 4. 询问 $B$ 的区间和
|
||||
> 1. 对 $A$ 做区间取 $\min$
|
||||
> 2. 对 $A$ 做区间取 $\max$
|
||||
> 3. 对 $A$ 做区间加
|
||||
> 4. 询问 $B$ 的区间和
|
||||
>
|
||||
> 每次操作完后,如果 $A_i$ 的值发生变化,就给 $B_i$ 加 $1$。$n,m\le 3\times 10^5$。
|
||||
|
||||
|
|
@ -66,10 +66,10 @@
|
|||
|
||||
> 两个序列 $A,B$:
|
||||
>
|
||||
> 1. 对 $A$ 做区间取 $\min$
|
||||
> 2. 对 $B$ 做区间取 $\min$
|
||||
> 3. 对 $A$ 做区间加
|
||||
> 4. 对 $B$ 做区间加
|
||||
> 1. 对 $A$ 做区间取 $\min$
|
||||
> 2. 对 $B$ 做区间取 $\min$
|
||||
> 3. 对 $A$ 做区间加
|
||||
> 4. 对 $B$ 做区间加
|
||||
> 5. 询问区间的 $A_i+B_i$ 的最大值
|
||||
>
|
||||
> $n,m\le 3\times 10^5$。
|
||||
|
|
@ -120,10 +120,10 @@ $$
|
|||
|
||||
> 序列 $A,B$ 一开始相同:
|
||||
>
|
||||
> 1. 对 $A$ 做区间覆盖 $x$
|
||||
> 2. 对 $A$ 做区间加 $x$
|
||||
> 3. 询问 $A$ 的区间 $\max$
|
||||
> 4. 询问 $B$ 的区间 $\max$
|
||||
> 1. 对 $A$ 做区间覆盖 $x$
|
||||
> 2. 对 $A$ 做区间加 $x$
|
||||
> 3. 询问 $A$ 的区间 $\max$
|
||||
> 4. 询问 $B$ 的区间 $\max$
|
||||
>
|
||||
> 每次操作后,我们都进行一次更新,$\forall i\in [1,n],\ B_i=\max(B_i,A_i)$。$n,m\le 10^5$。
|
||||
|
||||
|
|
@ -131,9 +131,9 @@ $$
|
|||
|
||||
这个定义可能比较模糊。因此我们先解释一下标记的生存周期。一个标记会经历这样的过程:
|
||||
|
||||
1. 在结点 $u$ 被建立。
|
||||
2. 在结点 $u$ 接受若干个新的标记的同时,与新的标记合并(指同类标记)
|
||||
3. 结点 $u$ 的标记下传给 $u$ 的儿子,$u$ 的标记清空
|
||||
1. 在结点 $u$ 被建立。
|
||||
2. 在结点 $u$ 接受若干个新的标记的同时,与新的标记合并(指同类标记)
|
||||
3. 结点 $u$ 的标记下传给 $u$ 的儿子,$u$ 的标记清空
|
||||
|
||||
我们认为在这个过程中,从 1 开始到 3 之前,都是结点 $u$ 的标记的生存周期。两个标记合并后,成为同一个标记,那么他们的生存周期也会合并(即取建立时间较早的那个做为生存周期的开始)。一个与之等价的说法是,从上次把这个结点的标记下传的时刻到当前时刻这一时间段。
|
||||
|
||||
|
|
@ -151,8 +151,8 @@ $$
|
|||
|
||||
区间覆盖操作,会把所有的数变成一个数。在这之后,无论是区间加减还是覆盖,整个区间的数仍是同一个(除非你结束当前标记的生存周期,下传标记)。因此我们可以把第一次区间覆盖后的所有标记都看成区间覆盖标记。也就是说一个标记的生存周期被大致分成两个阶段:
|
||||
|
||||
1. 若干个加减操作标记的合并,没有接收过覆盖标记。
|
||||
2. 覆盖操作的标记,没有所谓的加减标记(加减标记转化为覆盖标记)
|
||||
1. 若干个加减操作标记的合并,没有接收过覆盖标记。
|
||||
2. 覆盖操作的标记,没有所谓的加减标记(加减标记转化为覆盖标记)
|
||||
|
||||
于是我们把这个结点的 Pre 标记拆成 $(P_1,P_2)$。$P_1$ 表示第一阶段的最大加减标记;$P_2$ 表示第二阶段的最大覆盖标记。利用相似的方法,我们可以对这个做标记下传和信息更新。时间复杂度是 $O(m\log n)$ 的(这个问题并没有区间对 $x$ 取最值的操作哦~)
|
||||
|
||||
|
|
|
|||
|
|
@ -1 +0,0 @@
|
|||
|
||||
|
|
@ -4,11 +4,11 @@ author: Ir1d, sshwy, Enter-tainer, H-J-Granger, ouuan, GavinZhengOI, hsfzLZH1, x
|
|||
|
||||
如果区间变成动态的呢?即,如果还要求支持一种操作:单点修改某一位上的值,又该怎么办呢?
|
||||
|
||||
??? note "例题 [二逼平衡树(树套树)](https://loj.ac/problem/106)"
|
||||
|
||||
|
||||
??? note "例题 [ZOJ 2112 Dynamic Rankings](https://zoj.pintia.cn/problem-sets/91827364500/problems/91827365611)"
|
||||
??? note " 例题 [二逼平衡树(树套树)](https://loj.ac/problem/106)"
|
||||
|
||||
|
||||
??? note " 例题 [ZOJ 2112 Dynamic Rankings](https://zoj.pintia.cn/problem-sets/91827364500/problems/91827365611)"
|
||||
|
||||
|
||||
如果用 [线段树套平衡树](./balanced-in-seg.md) 中所论述的,用线段树套平衡树,即对于线段树的每一个节点,对于其所表示的区间维护一个平衡树,然后用二分来查找 $k$ 小值。由于每次查询操作都要覆盖多个区间,即有多个节点,但是平衡树并不能多个值一起查找,所以时间复杂度是 $O(n\log^3 n)$,并不是最优的。
|
||||
|
||||
|
|
|
|||
|
|
@ -382,11 +382,11 @@ int query(int p, int s, int t, int l, int r) {
|
|||
|
||||
这里总结几个线段树的优化:
|
||||
|
||||
- 在叶子节点处无需下放懒惰标记,所以懒惰标记可以不下传到叶子节点。
|
||||
- 在叶子节点处无需下放懒惰标记,所以懒惰标记可以不下传到叶子节点。
|
||||
|
||||
- 下放懒惰标记可以写一个专门的函数 `pushdown`,从儿子节点更新当前节点也可以写一个专门的函数 `maintain`(或者对称地用 `pushup`),降低代码编写难度。
|
||||
- 下放懒惰标记可以写一个专门的函数 `pushdown`,从儿子节点更新当前节点也可以写一个专门的函数 `maintain`(或者对称地用 `pushup`),降低代码编写难度。
|
||||
|
||||
- 标记永久化:如果确定懒惰标记不会在中途被加到溢出(即超过了该类型数据所能表示的最大范围),那么就可以将标记永久化。标记永久化可以避免下传懒惰标记,只需在进行询问时把标记的影响加到答案当中,从而降低程序常数。具体如何处理与题目特性相关,需结合题目来写。这也是树套树和可持久化数据结构中会用到的一种技巧。
|
||||
- 标记永久化:如果确定懒惰标记不会在中途被加到溢出(即超过了该类型数据所能表示的最大范围),那么就可以将标记永久化。标记永久化可以避免下传懒惰标记,只需在进行询问时把标记的影响加到答案当中,从而降低程序常数。具体如何处理与题目特性相关,需结合题目来写。这也是树套树和可持久化数据结构中会用到的一种技巧。
|
||||
|
||||
## C++ 模板
|
||||
|
||||
|
|
@ -405,8 +405,8 @@ int query(int p, int s, int t, int l, int r) {
|
|||
???+ note "[luogu P3372【模板】线段树 1](https://www.luogu.com.cn/problem/P3372)"
|
||||
已知一个数列,你需要进行下面两种操作:
|
||||
|
||||
- 将某区间每一个数加上 $k$。
|
||||
- 求出某区间每一个数的和。
|
||||
- 将某区间每一个数加上 $k$。
|
||||
- 求出某区间每一个数的和。
|
||||
|
||||
??? "参考代码"
|
||||
```cpp
|
||||
|
|
@ -416,9 +416,9 @@ int query(int p, int s, int t, int l, int r) {
|
|||
???+ note "[luogu P3373【模板】线段树 2](https://www.luogu.com.cn/problem/P3373)"
|
||||
已知一个数列,你需要进行下面三种操作:
|
||||
|
||||
- 将某区间每一个数乘上 $x$。
|
||||
- 将某区间每一个数加上 $x$。
|
||||
- 求出某区间每一个数的和。
|
||||
- 将某区间每一个数乘上 $x$。
|
||||
- 将某区间每一个数加上 $x$。
|
||||
- 求出某区间每一个数的和。
|
||||
|
||||
??? "参考代码"
|
||||
```cpp
|
||||
|
|
@ -455,9 +455,9 @@ int query(int p, int s, int t, int l, int r) {
|
|||
|
||||
在查询 $[l,r]$ 这段区间的信息和的时候,将线段树树上代表 $[l,l]$ 的节点和代表 $[r,r]$ 这段区间的节点在线段树上的 LCA 求出来,设这个节点 $p$ 代表的区间为 $[L,R]$,我们会发现一些非常有趣的性质:
|
||||
|
||||
1. $[L,R]$ 这个区间一定包含 $[l,r]$。显然,因为它既是 $l$ 的祖先又是 $r$ 的祖先。
|
||||
1. $[L,R]$ 这个区间一定包含 $[l,r]$。显然,因为它既是 $l$ 的祖先又是 $r$ 的祖先。
|
||||
|
||||
2. $[l,r]$ 这个区间一定跨越 $[L,R]$ 的中点。由于 $p$ 是 $l$ 和 $r$ 的 LCA,这意味着 $p$ 的左儿子是 $l$ 的祖先而不是 $r$ 的祖先,$p$ 的右儿子是 $r$ 的祖先而不是 $l$ 的祖先。因此,$l$ 一定在 $[L,\mathit{mid}]$ 这个区间内,$r$ 一定在 $(\mathit{mid},R]$ 这个区间内。
|
||||
2. $[l,r]$ 这个区间一定跨越 $[L,R]$ 的中点。由于 $p$ 是 $l$ 和 $r$ 的 LCA,这意味着 $p$ 的左儿子是 $l$ 的祖先而不是 $r$ 的祖先,$p$ 的右儿子是 $r$ 的祖先而不是 $l$ 的祖先。因此,$l$ 一定在 $[L,\mathit{mid}]$ 这个区间内,$r$ 一定在 $(\mathit{mid},R]$ 这个区间内。
|
||||
|
||||
有了这两个性质,我们就可以将询问的复杂度降至 $O(1)$ 了。
|
||||
|
||||
|
|
@ -499,6 +499,6 @@ int query(int p, int s, int t, int l, int r) {
|
|||
|
||||
### 参考
|
||||
|
||||
- [immortalCO 大爷的博客](https://immortalco.blog.uoj.ac/blog/2102)
|
||||
- [\[Kle77\]](http://ieeexplore.ieee.org/document/1675628/) V. Klee,“Can the Measure of be Computed in Less than O (n log n) Steps?,”Am. Math. Mon., vol. 84, no. 4, pp. 284–285, Apr. 1977.
|
||||
- [\[BeW80\]](https://www.tandfonline.com/doi/full/10.1080/00029890.1977.11994336) Bentley and Wood,“An Optimal Worst Case Algorithm for Reporting Intersections of Rectangles,”IEEE Trans. Comput., vol. C–29, no. 7, pp. 571–577, Jul. 1980.
|
||||
- [immortalCO 大爷的博客](https://immortalco.blog.uoj.ac/blog/2102)
|
||||
- [\[Kle77\]](http://ieeexplore.ieee.org/document/1675628/) V. Klee,“Can the Measure of be Computed in Less than O (n log n) Steps?,”Am. Math. Mon., vol. 84, no. 4, pp. 284–285, Apr. 1977.
|
||||
- [\[BeW80\]](https://www.tandfonline.com/doi/full/10.1080/00029890.1977.11994336) Bentley and Wood,“An Optimal Worst Case Algorithm for Reporting Intersections of Rectangles,”IEEE Trans. Comput., vol. C–29, no. 7, pp. 571–577, Jul. 1980.
|
||||
|
|
|
|||
|
|
@ -6,7 +6,7 @@ author: Ir1d, 0xis-cn
|
|||
|
||||
我们在此实现一个可重的权值平衡树。
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
int cnt, // 树中元素总数
|
||||
rt, // 根节点,初值为 0 代表空树
|
||||
|
|
@ -127,7 +127,7 @@ void Del(int& k, int p) {
|
|||
}
|
||||
```
|
||||
|
||||
### upper_bound
|
||||
### upper\_bound
|
||||
|
||||
返回权值严格大于某值的最小名次。
|
||||
|
||||
|
|
|
|||
|
|
@ -370,5 +370,5 @@ bool erase(const K &key) {
|
|||
|
||||
1. [Skip Lists: A Probabilistic Alternative to
|
||||
Balanced Trees](https://15721.courses.cs.cmu.edu/spring2018/papers/08-oltpindexes1/pugh-skiplists-cacm1990.pdf)
|
||||
2. [Skip List](https://en.wikipedia.org/wiki/Skip_list)
|
||||
3. [A Skip List Cookbook](http://cglab.ca/~morin/teaching/5408/refs/p90b.pdf)
|
||||
2. [Skip List](https://en.wikipedia.org/wiki/Skip_list)
|
||||
3. [A Skip List Cookbook](http://cglab.ca/~morin/teaching/5408/refs/p90b.pdf)
|
||||
|
|
|
|||
|
|
@ -4,10 +4,10 @@
|
|||
|
||||
ST 表是用于解决 **可重复贡献问题** 的数据结构。
|
||||
|
||||
???+note "什么是可重复贡献问题?"
|
||||
???+ note "什么是可重复贡献问题?"
|
||||
**可重复贡献问题** 是指对于运算 $\operatorname{opt}$,满足 $x\operatorname{opt} x=x$,则对应的区间询问就是一个可重复贡献问题。例如,最大值有 $\max(x,x)=x$,gcd 有 $\operatorname{gcd}(x,x)=x$,所以 RMQ 和区间 GCD 就是一个可重复贡献问题。像区间和就不具有这个性质,如果求区间和的时候采用的预处理区间重叠了,则会导致重叠部分被计算两次,这是我们所不愿意看到的。另外,$\operatorname{opt}$ 还必须满足结合律才能使用 ST 表求解。
|
||||
|
||||
???+note "什么是RMQ?"
|
||||
???+ note "什么是 RMQ?"
|
||||
RMQ 是英文 Range Maximum/Minimum Query 的缩写,表示区间最大(最小)值。解决 RMQ 问题有很多种方法,可以参考 [RMQ 专题](../topic/rmq.md)。
|
||||
|
||||
## 引入
|
||||
|
|
@ -66,9 +66,9 @@ ST 表基于 [倍增](../basic/binary-lifting.md) 思想,可以做到 $\Theta(
|
|||
|
||||
## 注意点
|
||||
|
||||
1. 输入输出数据一般很多,建议开启输入输出优化。
|
||||
1. 输入输出数据一般很多,建议开启输入输出优化。
|
||||
|
||||
2. 每次用 [std::log](https://en.cppreference.com/w/cpp/numeric/math/log) 重新计算 log 函数值并不值得,建议进行如下的预处理:
|
||||
2. 每次用 [std::log](https://en.cppreference.com/w/cpp/numeric/math/log) 重新计算 log 函数值并不值得,建议进行如下的预处理:
|
||||
|
||||
$$
|
||||
\left\{\begin{aligned}
|
||||
|
|
@ -95,7 +95,7 @@ ST 表能较好的维护“可重复贡献”的区间信息(同时也应满
|
|||
|
||||
[「SCOI2007」降雨量](https://loj.ac/problem/2279)
|
||||
|
||||
[\[USACO07JAN\]平衡的阵容 Balanced Lineup](https://www.luogu.com.cn/problem/P2880)
|
||||
[\[USACO07JAN\] 平衡的阵容 Balanced Lineup](https://www.luogu.com.cn/problem/P2880)
|
||||
|
||||
## 附录:ST 表求区间 GCD 的时间复杂度分析
|
||||
|
||||
|
|
|
|||
|
|
@ -16,19 +16,19 @@ Splay 树由 Daniel Sleator 和 Robert Tarjan 于 1985 年发明。
|
|||
|
||||
### 节点维护信息
|
||||
|
||||
| rt | tot | fa[i] | ch[i][0/1] | val[i] | cnt[i] | sz[i] |
|
||||
| :---: | :--: | :---: | :--------: | :----: | :----: | :---: |
|
||||
| 根节点编号 | 节点个数 | 父亲 | 左右儿子编号 | 节点权值 | 权值出现次数 | 子树大小 |
|
||||
| rt | tot | fa\[i] | ch\[i]\[0/1] | val\[i] | cnt\[i] | sz\[i] |
|
||||
| :---: | :--: | :----: | :----------: | :-----: | :-----: | :----: |
|
||||
| 根节点编号 | 节点个数 | 父亲 | 左右儿子编号 | 节点权值 | 权值出现次数 | 子树大小 |
|
||||
|
||||
## 操作
|
||||
|
||||
### 基本操作
|
||||
|
||||
- `maintain(x)`:在改变节点位置后,将节点 $x$ 的 $\text{size}$ 更新。
|
||||
- `get(x)`:判断节点 $x$ 是父亲节点的左儿子还是右儿子。
|
||||
- `clear(x)`:销毁节点 $x$。
|
||||
- `maintain(x)`:在改变节点位置后,将节点 $x$ 的 $\text{size}$ 更新。
|
||||
- `get(x)`:判断节点 $x$ 是父亲节点的左儿子还是右儿子。
|
||||
- `clear(x)`:销毁节点 $x$。
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```cpp
|
||||
void maintain(int x) { sz[x] = sz[ch[x][0]] + sz[ch[x][1]] + cnt[x]; }
|
||||
|
||||
|
|
@ -43,9 +43,9 @@ Splay 树由 Daniel Sleator 和 Robert Tarjan 于 1985 年发明。
|
|||
|
||||
**旋转需要保证**:
|
||||
|
||||
- 整棵 Splay 的中序遍历不变(不能破坏二叉查找树的性质)。
|
||||
- 受影响的节点维护的信息依然正确有效。
|
||||
- `root` 必须指向旋转后的根节点。
|
||||
- 整棵 Splay 的中序遍历不变(不能破坏二叉查找树的性质)。
|
||||
- 受影响的节点维护的信息依然正确有效。
|
||||
- `root` 必须指向旋转后的根节点。
|
||||
|
||||
在 Splay 中旋转分为两种:左旋和右旋。
|
||||
|
||||
|
|
@ -55,9 +55,9 @@ Splay 树由 Daniel Sleator 和 Robert Tarjan 于 1985 年发明。
|
|||
|
||||
**具体分析旋转步骤**(假设需要旋转的节点为 $x$,其父亲为 $y$,以右旋为例)
|
||||
|
||||
1. 将 $y$ 的左儿子指向 $x$ 的右儿子,且 $x$ 的右儿子(如果 $x$ 有右儿子的话)的父亲指向 $y$;`ch[y][0]=ch[x][1]; fa[ch[x][1]]=y;`
|
||||
2. 将 $x$ 的右儿子指向 $y$,且 $y$ 的父亲指向 $x$;`ch[x][chk^1]=y; fa[y]=x;`
|
||||
3. 如果原来的 $y$ 还有父亲 $z$,那么把 $z$ 的某个儿子(原来 $y$ 所在的儿子位置)指向 $x$,且 $x$ 的父亲指向 $z$。`fa[x]=z; if(z) ch[z][y==ch[z][1]]=x;`
|
||||
1. 将 $y$ 的左儿子指向 $x$ 的右儿子,且 $x$ 的右儿子(如果 $x$ 有右儿子的话)的父亲指向 $y$;`ch[y][0]=ch[x][1]; fa[ch[x][1]]=y;`
|
||||
2. 将 $x$ 的右儿子指向 $y$,且 $y$ 的父亲指向 $x$;`ch[x][chk^1]=y; fa[y]=x;`
|
||||
3. 如果原来的 $y$ 还有父亲 $z$,那么把 $z$ 的某个儿子(原来 $y$ 所在的儿子位置)指向 $x$,且 $x$ 的父亲指向 $z$。`fa[x]=z; if(z) ch[z][y==ch[z][1]]=x;`
|
||||
|
||||
#### 实现
|
||||
|
||||
|
|
@ -111,7 +111,7 @@ Splay 操作即对 $x$ 做一系列的 **splay 步骤**。每次对 $x$ 做一
|
|||
|
||||

|
||||
|
||||
!!! tip
|
||||
??? tip
|
||||
请读者尝试自行模拟 $6$ 种旋转情况,以理解 Splay 的基本思想。
|
||||
|
||||
#### 实现
|
||||
|
|
@ -181,9 +181,9 @@ $$
|
|||
|
||||
插入操作是一个比较复杂的过程,具体步骤如下(假设插入的值为 $k$):
|
||||
|
||||
- 如果树空了,则直接插入根并退出。
|
||||
- 如果当前节点的权值等于 $k$ 则增加当前节点的大小并更新节点和父亲的信息,将当前节点进行 Splay 操作。
|
||||
- 否则按照二叉查找树的性质向下找,找到空节点就插入即可(请不要忘记 Splay 操作)。
|
||||
- 如果树空了,则直接插入根并退出。
|
||||
- 如果当前节点的权值等于 $k$ 则增加当前节点的大小并更新节点和父亲的信息,将当前节点进行 Splay 操作。
|
||||
- 否则按照二叉查找树的性质向下找,找到空节点就插入即可(请不要忘记 Splay 操作)。
|
||||
|
||||
#### 实现
|
||||
|
||||
|
|
@ -227,9 +227,9 @@ void ins(int k) {
|
|||
|
||||
根据二叉查找树的定义和性质,显然可以按照以下步骤查询 $x$ 的排名:
|
||||
|
||||
- 如果 $x$ 比当前节点的权值小,向其左子树查找。
|
||||
- 如果 $x$ 比当前节点的权值大,将答案加上左子树($size$)和当前节点($cnt$)的大小,向其右子树查找。
|
||||
- 如果 $x$ 与当前节点的权值相同,将答案加 $1$ 并返回。
|
||||
- 如果 $x$ 比当前节点的权值小,向其左子树查找。
|
||||
- 如果 $x$ 比当前节点的权值大,将答案加上左子树($size$)和当前节点($cnt$)的大小,向其右子树查找。
|
||||
- 如果 $x$ 与当前节点的权值相同,将答案加 $1$ 并返回。
|
||||
|
||||
注意最后需要进行 Splay 操作。
|
||||
|
||||
|
|
@ -260,8 +260,8 @@ int rk(int k) {
|
|||
|
||||
设 $k$ 为剩余排名,具体步骤如下:
|
||||
|
||||
- 如果左子树非空且剩余排名 $k$ 不大于左子树的大小 $size$,那么向左子树查找。
|
||||
- 否则将 $k$ 减去左子树的和根的大小。如果此时 $k$ 的值小于等于 $0$,则返回根节点的权值,否则继续向右子树查找。
|
||||
- 如果左子树非空且剩余排名 $k$ 不大于左子树的大小 $size$,那么向左子树查找。
|
||||
- 否则将 $k$ 减去左子树的和根的大小。如果此时 $k$ 的值小于等于 $0$,则返回根节点的权值,否则继续向右子树查找。
|
||||
|
||||
#### 实现
|
||||
|
||||
|
|
@ -325,8 +325,8 @@ int nxt() {
|
|||
|
||||
合并两棵 Splay 树,设两棵树的根节点分别为 $x$ 和 $y$,那么我们要求 $x$ 树中的最大值小于 $y$ 树中的最小值。合并操作如下:
|
||||
|
||||
- 如果 $x$ 和 $y$ 其中之一或两者都为空树,直接返回不为空的那一棵树的根节点或空树。
|
||||
- 否则将 $x$ 树中的最大值 $\operatorname{Splay}$ 到根,然后把它的右子树设置为 $y$ 并更新节点的信息,然后返回这个节点。
|
||||
- 如果 $x$ 和 $y$ 其中之一或两者都为空树,直接返回不为空的那一棵树的根节点或空树。
|
||||
- 否则将 $x$ 树中的最大值 $\operatorname{Splay}$ 到根,然后把它的右子树设置为 $y$ 并更新节点的信息,然后返回这个节点。
|
||||
|
||||
### 删除操作
|
||||
|
||||
|
|
@ -336,8 +336,8 @@ int nxt() {
|
|||
|
||||
首先将 $x$ 旋转到根的位置。
|
||||
|
||||
- 如果 $cnt[x]>1$(有不止一个 $x$),那么将 $cnt[x]$ 减 $1$ 并退出。
|
||||
- 否则,合并它的左右两棵子树即可。
|
||||
- 如果 $cnt[x]>1$(有不止一个 $x$),那么将 $cnt[x]$ 减 $1$ 并退出。
|
||||
- 否则,合并它的左右两棵子树即可。
|
||||
|
||||
#### 实现
|
||||
|
||||
|
|
@ -551,17 +551,17 @@ int main() {
|
|||
|
||||
以下题目都是裸的 Splay 维护二叉查找树。
|
||||
|
||||
- [【模板】普通平衡树](https://loj.ac/problem/104)
|
||||
- [【模板】文艺平衡树](https://loj.ac/problem/105)
|
||||
- [「HNOI2002」营业额统计](https://loj.ac/problem/10143)
|
||||
- [「HNOI2004」宠物收养所](https://loj.ac/problem/10144)
|
||||
- [【模板】普通平衡树](https://loj.ac/problem/104)
|
||||
- [【模板】文艺平衡树](https://loj.ac/problem/105)
|
||||
- [「HNOI2002」营业额统计](https://loj.ac/problem/10143)
|
||||
- [「HNOI2004」宠物收养所](https://loj.ac/problem/10144)
|
||||
|
||||
## 习题
|
||||
|
||||
- [「Cerc2007」robotic sort 机械排序](https://www.luogu.com.cn/problem/P4402)
|
||||
- [二逼平衡树(树套树)](https://loj.ac/problem/106)
|
||||
- [bzoj 2827 千山鸟飞绝](https://hydro.ac/d/bzoj/p/2827)
|
||||
- [「Lydsy1706 月赛」K 小值查询](https://hydro.ac/d/bzoj/p/4923)
|
||||
- [「Cerc2007」robotic sort 机械排序](https://www.luogu.com.cn/problem/P4402)
|
||||
- [二逼平衡树(树套树)](https://loj.ac/problem/106)
|
||||
- [bzoj 2827 千山鸟飞绝](https://hydro.ac/d/bzoj/p/2827)
|
||||
- [「Lydsy1706 月赛」K 小值查询](https://hydro.ac/d/bzoj/p/4923)
|
||||
|
||||
## 参考资料与注释
|
||||
|
||||
|
|
|
|||
|
|
@ -10,9 +10,9 @@ Sqrt Tree 可以在 $O(n\log\log n)$ 的时间内预处理,并在 $O(1)$ 的
|
|||
|
||||
首先我们把整个序列分成 $O(\sqrt{n})$ 个块,每一块的大小为 $O(\sqrt{n})$。对于每个块,我们计算:
|
||||
|
||||
1. $P_i$ 块内的前缀区间询问
|
||||
2. $S_i$ 块内的后缀区间询问
|
||||
3. 维护一个额外的数组 $\left\langle B_{i,j}\right\rangle$ 表示第 $i$ 个块到第 $j$ 个块的区间答案。
|
||||
1. $P_i$ 块内的前缀区间询问
|
||||
2. $S_i$ 块内的后缀区间询问
|
||||
3. 维护一个额外的数组 $\left\langle B_{i,j}\right\rangle$ 表示第 $i$ 个块到第 $j$ 个块的区间答案。
|
||||
|
||||
举个例子,假设 $\circ$ 代表加法运算 $+$,序列为 $\{1,2,3,4,5,6,7,8,9\}$。
|
||||
|
||||
|
|
@ -54,8 +54,8 @@ $$
|
|||
|
||||
我们假设
|
||||
|
||||
1. 每一块的大小都是 $2$ 的整数幂次;
|
||||
2. 每一层上的块大小是相同的。
|
||||
1. 每一块的大小都是 $2$ 的整数幂次;
|
||||
2. 每一层上的块大小是相同的。
|
||||
|
||||
为此我们需要在序列的末位补充一些 $0$ 元素,使得它的长度变成 $2$ 的整数次幂。尽管有些块可能会变成原来的两倍大小,但这样仍是 $O(\sqrt{k})$ 的,于是预处理分块的复杂度仍是 $O(n)$ 的。
|
||||
|
||||
|
|
@ -70,8 +70,8 @@ $$
|
|||
|
||||
因此我们需要检查区间两个端点是否只有后 $k$ 位不同,即 $l\oplus r\le 2^k-1$。因此我们可以快速找到答案区间所在的层:
|
||||
|
||||
1. 对于每个 $i\in [1,n]$,我们找到找到 $i$ 最高位上的 $1$;
|
||||
2. 现在对于一个询问 $[l,r]$,我们计算 $l\oplus r$ 的最高位,这样就可以快速确定答案区间所在的层。
|
||||
1. 对于每个 $i\in [1,n]$,我们找到找到 $i$ 最高位上的 $1$;
|
||||
2. 现在对于一个询问 $[l,r]$,我们计算 $l\oplus r$ 的最高位,这样就可以快速确定答案区间所在的层。
|
||||
|
||||
这样我们就可以在 $O(1)$ 的时间内回答询问啦。
|
||||
|
||||
|
|
@ -95,9 +95,9 @@ $$
|
|||
|
||||
因此我们可以这样更新 $index$ 树:
|
||||
|
||||
1. 在 $O(\sqrt{n})$ 的时间内更新 $\left\langle P_i\right\rangle$ 和 $\left\langle S_i\right\rangle$。
|
||||
2. 更新 $index$,它的长度是 $O(n)$ 的,但我们只需要更新其中的一个元素(这个元素代表了被改变的块),这一步的时间复杂度是 $O(\sqrt{n})$ 的(使用朴素实现的算法)。
|
||||
3. 进入产生变化的子节点并使用朴素实现的算法在 $O(\sqrt{n})$ 的时间内更新信息。
|
||||
1. 在 $O(\sqrt{n})$ 的时间内更新 $\left\langle P_i\right\rangle$ 和 $\left\langle S_i\right\rangle$。
|
||||
2. 更新 $index$,它的长度是 $O(n)$ 的,但我们只需要更新其中的一个元素(这个元素代表了被改变的块),这一步的时间复杂度是 $O(\sqrt{n})$ 的(使用朴素实现的算法)。
|
||||
3. 进入产生变化的子节点并使用朴素实现的算法在 $O(\sqrt{n})$ 的时间内更新信息。
|
||||
|
||||
注意,查询的复杂度仍是 $O(1)$ 的,因为我们最多使用 $index$ 树一次。于是单点修改的复杂度就是 $O(\sqrt{n})$ 的。
|
||||
|
||||
|
|
@ -111,19 +111,19 @@ Sqrt Tree 也支持区间覆盖操作 $\operatorname{Update}(l,r,x)$,即把区
|
|||
|
||||
在第一种实现中,我们只会给第 $1$ 层的结点(结点区间长度为 $O(\sqrt{n})$)打懒标记,在下传标记的时侯直接更新整个子树,复杂度为 $O(\sqrt{n}\log\log n)$。操作过程如下:
|
||||
|
||||
1. 考虑第 $1$ 层上的结点,对于那些被修改区间完全包含的结点,给他们打一个懒标记;
|
||||
1. 考虑第 $1$ 层上的结点,对于那些被修改区间完全包含的结点,给他们打一个懒标记;
|
||||
|
||||
2. 有两个块只有部分区间被覆盖,我们直接在 $O(\sqrt{n}\log\log n)$ 的时间内 **重建** 这两个块。如果它本身带有之前修改的懒标记,就在重建的时侯顺便下传标记;
|
||||
2. 有两个块只有部分区间被覆盖,我们直接在 $O(\sqrt{n}\log\log n)$ 的时间内 **重建** 这两个块。如果它本身带有之前修改的懒标记,就在重建的时侯顺便下传标记;
|
||||
|
||||
3. 更新根结点的 $\left\langle P_i\right\rangle$ 和 $\left\langle S_i\right\rangle$,时间复杂度 $O(\sqrt{n})$;
|
||||
3. 更新根结点的 $\left\langle P_i\right\rangle$ 和 $\left\langle S_i\right\rangle$,时间复杂度 $O(\sqrt{n})$;
|
||||
|
||||
4. 重建 $index$ 树,时间复杂度 $O(\sqrt{n}\log\log n)$。
|
||||
4. 重建 $index$ 树,时间复杂度 $O(\sqrt{n}\log\log n)$。
|
||||
|
||||
现在我们可以高效完成区间修改了。那么如何利用懒标记回答询问?操作如下:
|
||||
|
||||
1. 如果我们的询问被包含在一个有懒标记的块内,可以利用懒标记计算答案;
|
||||
1. 如果我们的询问被包含在一个有懒标记的块内,可以利用懒标记计算答案;
|
||||
|
||||
2. 如果我们的询问包含多个块,那么我们只需要关心最左边和最右边不完整块的答案。中间的块的答案可以在 $index$ 树中查询(因为 $index$ 树在每次修改完后会重建),复杂度是 $O(1)$。
|
||||
2. 如果我们的询问包含多个块,那么我们只需要关心最左边和最右边不完整块的答案。中间的块的答案可以在 $index$ 树中查询(因为 $index$ 树在每次修改完后会重建),复杂度是 $O(1)$。
|
||||
|
||||
因此询问的复杂度仍为 $O(1)$。
|
||||
|
||||
|
|
@ -131,11 +131,11 @@ Sqrt Tree 也支持区间覆盖操作 $\operatorname{Update}(l,r,x)$,即把区
|
|||
|
||||
在这种实现中,每一个结点都可以被打上懒标记。因此在处理一个询问的时侯,我们需要考虑祖先中的懒标记,那么查询的复杂度将变成 $O(\log\log n)$。不过更新信息的复杂度就会变得更快。操作如下:
|
||||
|
||||
1. 被修改区间完全包含的块,我们把懒标记添加到这些块上,复杂度 $O(\sqrt{n})$;
|
||||
2. 被修改区间部分覆盖的块,更新 $\left\langle P_i\right\rangle$ 和 $\left\langle S_i\right\rangle$,复杂度 $O(\sqrt{n})$(因为只有两个被修改的块);
|
||||
3. 更新 $index$ 树,复杂度 $O(\sqrt{n})$(使用同样的更新算法);
|
||||
4. 对于没有索引的子树更新他们的 $\left\langle B_{i,j}\right\rangle$;
|
||||
5. 递归地更新两个没有被完全覆盖的区间。
|
||||
1. 被修改区间完全包含的块,我们把懒标记添加到这些块上,复杂度 $O(\sqrt{n})$;
|
||||
2. 被修改区间部分覆盖的块,更新 $\left\langle P_i\right\rangle$ 和 $\left\langle S_i\right\rangle$,复杂度 $O(\sqrt{n})$(因为只有两个被修改的块);
|
||||
3. 更新 $index$ 树,复杂度 $O(\sqrt{n})$(使用同样的更新算法);
|
||||
4. 对于没有索引的子树更新他们的 $\left\langle B_{i,j}\right\rangle$;
|
||||
5. 递归地更新两个没有被完全覆盖的区间。
|
||||
|
||||
时间复杂度是 $O(\sqrt{n}+\sqrt{\sqrt{n}}+\dotsb)=O(\sqrt{n})$。
|
||||
|
||||
|
|
|
|||
|
|
@ -6,7 +6,7 @@
|
|||
|
||||
栈的修改是按照后进先出的原则进行的,因此栈通常被称为是后进先出(last in first out)表,简称 LIFO 表。
|
||||
|
||||
!!! warning
|
||||
??? warning
|
||||
LIFO 表达的是 **当前在容器** 内最后进来的最先出去。
|
||||
|
||||
我们考虑这样一个栈
|
||||
|
|
@ -26,7 +26,7 @@
|
|||
|
||||
我们可以方便的使用数组来模拟一个栈,如下:
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
=== "C++"
|
||||
|
||||
```cpp
|
||||
|
|
@ -71,7 +71,7 @@
|
|||
|
||||
C++ 中的 STL 也提供了一个容器 `std::stack`,使用前需要引入 `stack` 头文件。
|
||||
|
||||
???+ info "STL 中对 `stack` 的定义"
|
||||
???+ info "STL 中对 `stack` 的定义 "
|
||||
```cpp
|
||||
// clang-format off
|
||||
template<
|
||||
|
|
@ -84,22 +84,22 @@ C++ 中的 STL 也提供了一个容器 `std::stack`,使用前需要引入 `st
|
|||
|
||||
`Container` 为用于存储元素的底层容器类型。这个容器必须提供通常语义的下列函数:
|
||||
|
||||
- `back()`
|
||||
- `push_back()`
|
||||
- `pop_back()`
|
||||
- `back()`
|
||||
- `push_back()`
|
||||
- `pop_back()`
|
||||
|
||||
STL 容器 `std::vector`、`std::deque` 和 `std::list` 满足这些要求。如果不指定,则默认使用 `std::deque` 作为底层容器。
|
||||
|
||||
STL 中的 `stack` 容器提供了一众成员函数以供调用,其中较为常用的有:
|
||||
|
||||
- 元素访问
|
||||
- `st.top()` 返回栈顶
|
||||
- `st.top()` 返回栈顶
|
||||
- 修改
|
||||
- `st.push()` 插入传入的参数到栈顶
|
||||
- `st.pop()` 弹出栈顶
|
||||
- `st.push()` 插入传入的参数到栈顶
|
||||
- `st.pop()` 弹出栈顶
|
||||
- 容量
|
||||
- `st.empty()` 返回是否为空
|
||||
- `st.size()` 返回元素数量
|
||||
- `st.empty()` 返回是否为空
|
||||
- `st.size()` 返回元素数量
|
||||
|
||||
此外,`std::stack` 还提供了一些运算符。较为常用的是使用赋值运算符 `=` 为 `stack` 赋值,示例:
|
||||
|
||||
|
|
@ -122,7 +122,7 @@ cout << st2.top() << endl;
|
|||
|
||||
在 Python 中,你可以使用列表来模拟一个栈:
|
||||
|
||||
???+note "实现"
|
||||
???+ note "实现"
|
||||
```python
|
||||
st = [5, 1, 4]
|
||||
|
||||
|
|
@ -143,4 +143,4 @@ cout << st2.top() << endl;
|
|||
|
||||
## 参考资料
|
||||
|
||||
1. [std::stack - zh.cppreference.com](https://zh.cppreference.com/w/cpp/container/stack)
|
||||
1. [std::stack - zh.cppreference.com](https://zh.cppreference.com/w/cpp/container/stack)
|
||||
|
|
|
|||
|
|
@ -1 +0,0 @@
|
|||
|
||||
|
|
@ -8,12 +8,12 @@ Treap(树堆)是一种 **弱平衡** 的 **二叉搜索树**。它同时符
|
|||
|
||||
其中,二叉搜索树的性质是:
|
||||
|
||||
- 左子节点的值($\textit{val}$)比父节点大
|
||||
- 右子节点的值($\textit{val}$)比父节点小(当然这也是可以反过来的)
|
||||
- 左子节点的值($\textit{val}$)比父节点大
|
||||
- 右子节点的值($\textit{val}$)比父节点小(当然这也是可以反过来的)
|
||||
|
||||
堆的性质是:
|
||||
|
||||
- 子节点值($\textit{priority}$)比父节点大或小(取决于是小根堆还是大根堆)
|
||||
- 子节点值($\textit{priority}$)比父节点大或小(取决于是小根堆还是大根堆)
|
||||
|
||||
不难看出,如果用的是同一个值,那这两种数据结构的性质是矛盾的,所以我们再在搜索树的基础上,引入一个给堆的值 $\textit{priority}$。对于 $\textit{val}$ 值,我们维护搜索树的性质,对于 $\textit{priority}$ 值,我们维护堆的性质。其中 $\textit{priority}$ 这个值是随机给出的。
|
||||
|
||||
|
|
@ -49,7 +49,7 @@ Treap(树堆)是一种 **弱平衡** 的 **二叉搜索树**。它同时符
|
|||
|
||||
首先,我们需要认识到一个节点的 $\textit{priority}$ 属性是和它所在的层数有直接关联的。再回忆堆的性质:
|
||||
|
||||
- 子节点值($\textit{priority}$)比父节点大或小(取决于是小根堆还是大根堆)
|
||||
- 子节点值($\textit{priority}$)比父节点大或小(取决于是小根堆还是大根堆)
|
||||
|
||||
我们发现层数低的节点,比如整个树的根节点,它的 $\textit{priority}$ 属性也会更小(在小根堆中)。并且,在朴素的搜索树中,先被插入的节点,也更有可能会有比较小的层数。我们可以把这个 $\textit{priority}$ 属性和被插入的顺序关联起来理解,这样,也就理解了为什么 treap 可以把节点插入的顺序通过 $\textit{priority}$ 打乱。
|
||||
|
||||
|
|
@ -62,7 +62,8 @@ Treap(树堆)是一种 **弱平衡** 的 **二叉搜索树**。它同时符
|
|||
旋转 treap 在做普通平衡树题的时候,是所有平衡树中常数较小的。因为普通的二叉搜索树会被递增或递减的数据卡,用 treap 对每个节点定义一个由 `rand` 得到的权值,从而防止特殊数据卡。同时在每次删除/插入时通过这个权值决定要不要旋转即可,其他操作与二叉搜索树类似。
|
||||
|
||||
大部分的树形数据结构都有指针和数组模拟两种实现方法,下面将会详细的分部分讲解指针版的代码,如果想要学习数组实现,可以拉到最下面的完整代码部分。
|
||||
???+info
|
||||
|
||||
???+ info
|
||||
注意本代码中的 `rank` 代表前面讲的 $\textit{priority}$ 变量(堆的值)。并且,维护的堆的性质是小根堆($\textit{priority}$ 小的在上面)。本代码来源。[^ref1]
|
||||
|
||||
### 节点结构
|
||||
|
|
@ -97,8 +98,8 @@ struct Node {
|
|||
|
||||
旋转操作的含义:
|
||||
|
||||
- 在不影响搜索树性质的前提下,把和旋转方向相反的子树变成根节点(如左旋,就是把右子树变成根节点)
|
||||
- 不影响性质,并且在旋转过后,跟旋转方向相同的子节点变成了原来的根节点(如左旋,旋转完之后的左子节点是旋转前的根节点)
|
||||
- 在不影响搜索树性质的前提下,把和旋转方向相反的子树变成根节点(如左旋,就是把右子树变成根节点)
|
||||
- 不影响性质,并且在旋转过后,跟旋转方向相同的子节点变成了原来的根节点(如左旋,旋转完之后的左子节点是旋转前的根节点)
|
||||
|
||||
左旋和右旋操作是相互的,如下图。
|
||||
|
||||
|
|
@ -260,9 +261,9 @@ int _query_rank(Node *cur, int val) {
|
|||
|
||||
以下是一个判断方法的表:
|
||||
|
||||
| 左子树 | 根节点/当前节点 | 右子树 |
|
||||
| -------------- | ---------------------------------------- | --------- |
|
||||
| 排名一定小于等于左子树的大小 | 排名应该 >= 左子树的大小,并且<= 左子树的大小 + 根节点的重复次数 | 不然的话就在右子树 |
|
||||
| 左子树 | 根节点/当前节点 | 右子树 |
|
||||
| -------------- | -------------------------------------- | --------- |
|
||||
| 排名一定小于等于左子树的大小 | 排名应该 >= 左子树的大小,并且 <= 左子树的大小 + 根节点的重复次数 | 不然的话就在右子树 |
|
||||
|
||||
注意如果在右子树,递归的时候需要对原来的 `rank` 进行处理。递归的时候就相当去查,在右子树中为这个排名的值,为了把排名转换成基于右子树的,需要把原来的 `rank` 减去左子树的大小和根节点的重复次数。
|
||||
|
||||
|
|
|
|||
|
|
@ -9,8 +9,8 @@ disqus:
|
|||
在阅读完之后,请点击下方的按钮,然后开始编辑。
|
||||
|
||||
???+ 敬请留意
|
||||
- 请您记得在文件头的 author 字段后方按照格式加上您的 GitHub ID;
|
||||
- 根据 Issue [#3061](https://github.com/OI-wiki/OI-wiki/issues/3061),现在您的更改将会视 Commit Message 质量以 Rebase 或 Squash 方式之一合并,且在 Squash 方式下您可能会是该 commit 的 author 而不是 committer,敬请留意。
|
||||
- 请您记得在文件头的 author 字段后方按照格式加上您的 GitHub ID;
|
||||
- 根据 Issue [#3061](https://github.com/OI-wiki/OI-wiki/issues/3061),现在您的更改将会视 Commit Message 质量以 Rebase 或 Squash 方式之一合并,且在 Squash 方式下您可能会是该 commit 的 author 而不是 committer,敬请留意。
|
||||
|
||||
<a id="btn-startedit" style="padding: 0.75em 1.25em; display: inline-block; line-height: 1; text-decoration: none; white-space: nowrap; cursor: pointer; border: 1px solid #6190e8; border-radius: 5px; background-color: #6190e8; color: #fff; outline: none; font-size: 0.75em;">开始编辑</a>
|
||||
|
||||
|
|
|
|||
|
|
@ -12,10 +12,10 @@
|
|||
|
||||
如并不了解:
|
||||
|
||||
- 几何基础
|
||||
- 平面直角坐标系
|
||||
- 向量(包括向量积)
|
||||
- 极坐标与极坐标系
|
||||
- 几何基础
|
||||
- 平面直角坐标系
|
||||
- 向量(包括向量积)
|
||||
- 极坐标与极坐标系
|
||||
|
||||
请先阅读 [向量](../math/linear-algebra/vector.md) 和 [极坐标](../math/coordinate.md#平面极坐标系)。
|
||||
|
||||
|
|
|
|||
|
|
@ -40,13 +40,13 @@ $$
|
|||
|
||||
#### 两直线夹角定义与关系充要条件
|
||||
|
||||
- 两直线的方向向量的夹角,叫做两直线的夹角。
|
||||
- 两直线的方向向量的夹角,叫做两直线的夹角。
|
||||
|
||||
有了这个命题,我们就可以得出以下结论:已知两条直线 $l_1, l_2$,它们的方向向量分别是 $s_1 (m_1, n_1, p_1)$,$s_2 (m_2, n_2, p_2)$,设 $\varphi$ 为两直线夹角,我们可以得到 $\cos \varphi = \dfrac{\left | m_1m_2+n_1n_2+p_1p_2 \right |}{\sqrt{m_1^2+n_1^2+p_1^2}\sqrt{m_2^2+n_2^2+p_2^2}}$.
|
||||
|
||||
- $l_1 \perp l_2 \iff m_1m_2 + n_1n_2 + p_1p_2 = 0$
|
||||
- $l_1 \perp l_2 \iff m_1m_2 + n_1n_2 + p_1p_2 = 0$
|
||||
|
||||
- $l_1 \parallel l_2 \iff \dfrac{m_1}{m_2} = \dfrac{n_1}{n_2} = \dfrac{p_1}{p_2}$.
|
||||
- $l_1 \parallel l_2 \iff \dfrac{m_1}{m_2} = \dfrac{n_1}{n_2} = \dfrac{p_1}{p_2}$.
|
||||
|
||||
### 三维向量与平面的夹角
|
||||
|
||||
|
|
@ -54,11 +54,11 @@ $$
|
|||
|
||||
设直线向量 $s(m, n, p)$,平面法线向量 $f(a, b, c)$,那么以下命题成立:
|
||||
|
||||
- 角度的正弦值:$\sin\varphi = \dfrac{\left | am + bn + cp \right |}{\sqrt{a^2+b^2+c^2}\sqrt{m^2+n^2+p^2}}$
|
||||
- 角度的正弦值:$\sin\varphi = \dfrac{\left | am + bn + cp \right |}{\sqrt{a^2+b^2+c^2}\sqrt{m^2+n^2+p^2}}$
|
||||
|
||||
- 直线与平面平行 $\iff am+bn+cp = 0$
|
||||
- 直线与平面平行 $\iff am+bn+cp = 0$
|
||||
|
||||
- 直线与平面垂直 $\iff \dfrac{a}{m} = \dfrac{b}{n} = \dfrac{c}{p}$
|
||||
- 直线与平面垂直 $\iff \dfrac{a}{m} = \dfrac{b}{n} = \dfrac{c}{p}$
|
||||
|
||||
### 点到平面的距离
|
||||
|
||||
|
|
@ -78,4 +78,4 @@ $$
|
|||
|
||||
## 参考资料
|
||||
|
||||
- [3D 空间基础概念之一:点、向量(矢量)和齐次坐标](https://www.cnblogs.com/CodeBlove/articles/1319563.html)
|
||||
- [3D 空间基础概念之一:点、向量(矢量)和齐次坐标](https://www.cnblogs.com/CodeBlove/articles/1319563.html)
|
||||
|
|
|
|||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue