* [一、运行时数据区域](#一运行时数据区域)
* [程序计数器](#程序计数器)
* [Java 虚拟机栈](#java-虚拟机栈)
* [本地方法栈](#本地方法栈)
* [Java 堆](#java-堆)
* [方法区](#方法区)
* [运行时常量池](#运行时常量池)
* [直接内存](#直接内存)
* [二、垃圾收集](#二垃圾收集)
* [判断一个对象是否可回收](#判断一个对象是否可回收)
* [垃圾收集算法](#垃圾收集算法)
* [垃圾收集器](#垃圾收集器)
* [内存分配与回收策略](#内存分配与回收策略)
* [Full GC 的触发条件](#full-gc-的触发条件)
* [三、类加载机制](#三类加载机制)
* [类的生命周期](#类的生命周期)
* [类初始化时机](#类初始化时机)
* [类加载过程](#类加载过程)
* [类加载器](#类加载器)
* [四、JVM 参数](#四jvm-参数)
* [GC 优化配置](#gc-优化配置)
* [GC 类型设置](#gc-类型设置)
* [参考资料](#参考资料)
# 一、运行时数据区域
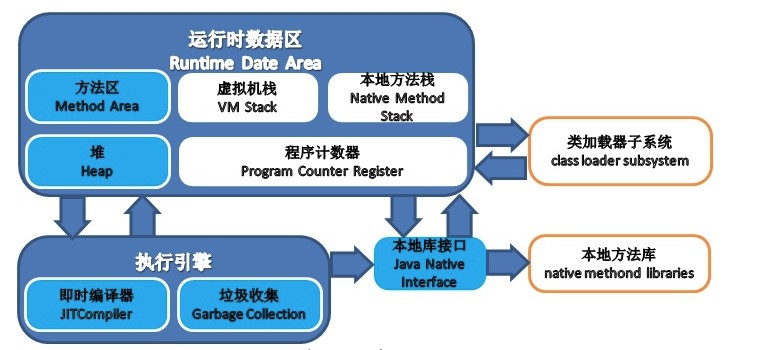
注:白色区域为线程私有,蓝色区域为线程共享。
## 程序计数器
记录正在执行的虚拟机字节码指令的地址(如果正在执行的是本地方法则为空)。
## Java 虚拟机栈
每个 Java 方法在执行的同时会创建一个栈帧用于存储局部变量表、操作数栈、动态链接、方法出口等信息。每一个方法从调用直至执行完成的过程,就对应着一个栈帧在 Java 虚拟机栈中入栈和出栈的过程。
可以通过 -Xss 这个虚拟机参数来指定一个程序的 Java 虚拟机栈内存大小:
```java
java -Xss=512M HackTheJava
```
该区域可能抛出以下异常:
1. 当线程请求的栈深度超过最大值,会抛出 StackOverflowError 异常;
2. 栈进行动态扩展时如果无法申请到足够内存,会抛出 OutOfMemoryError 异常。
## 本地方法栈
本地方法不是用 Java 实现,对待这些方法需要特别处理。
与 Java 虚拟机栈类似,它们之间的区别只不过是本地方法栈为本地方法服务。
## Java 堆
所有对象实例都在这里分配内存。
是垃圾收集的主要区域("GC 堆 "),现代的垃圾收集器基本都是采用分代收集算法,该算法的思想是针对不同的对象采取不同的垃圾回收算法,因此虚拟机把 Java 堆分成以下三块:
- 新生代(Young Generation)
- 老年代(Old Generation)
- 永久代(Permanent Generation)
当一个对象被创建时,它首先进入新生代,之后有可能被转移到老年代中。新生代存放着大量的生命很短的对象,因此新生代在三个区域中垃圾回收的频率最高。为了更高效地进行垃圾回收,把新生代继续划分成以下三个空间:
- Eden
- From Survivor
- To Survivor
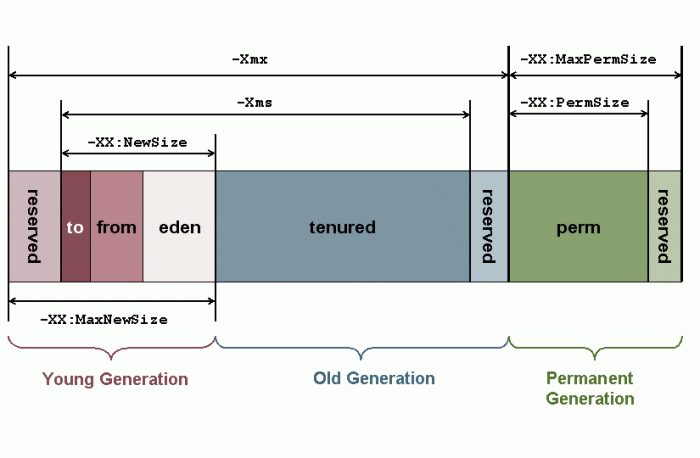
Java 堆不需要连续内存,并且可以通过动态增加其内存,增加失败会抛出 OutOfMemoryError 异常。
可以通过 -Xms 和 -Xmx 两个虚拟机参数来指定一个程序的 Java 堆内存大小,第一个参数设置最小值,第二个参数设置最大值。
```java
java -Xms=1M -XmX=2M HackTheJava
```
## 方法区
用于存放已被加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
和 Java 堆一样不需要连续的内存,并且可以动态扩展,动态扩展失败一样会抛出 OutOfMemoryError 异常。
对这块区域进行垃圾回收的主要目标是对常量池的回收和对类的卸载,但是一般比较难实现,HotSpot 虚拟机把它当成永久代来进行垃圾回收。
## 运行时常量池
运行时常量池是方法区的一部分。
Class 文件中的常量池(编译器生成的各种字面量和符号引用)会在类加载后被放入这个区域。
除了在编译期生成的常量,还允许动态生成,例如 String 类的 intern()。这部分常量也会被放入运行时常量池。
## 直接内存
在 JDK 1.4 中新加入了 NIO 类,引入了一种基于通道(Channel)与缓冲区(Buffer)的 I/O 方式,它可以使用 Native 函数库直接分配堆外内存,然后通过一个存储在 Java 堆里的 DirectByteBuffer 对象作为这块内存的引用进行操作。这样能在一些场景中显著提高性能,因为避免了在 Java 堆和 Native 堆中来回复制数据。
# 二、垃圾收集
程序计数器、虚拟机栈和本地方法栈这三个区域属于线程私有的,只存在于线程的生命周期内,线程结束之后也会消失,因此不需要对这三个区域进行垃圾回收。垃圾回收主要是针对 Java 堆和方法区进行。
## 判断一个对象是否可回收
### 1. 引用计数
给对象添加一个引用计数器,当对象增加一个引用时计数器加 1,引用失效时计数器减 1。引用计数为 0 的对象可被回收。
两个对象出现循环引用的情况下,此时引用计数器永远不为 0,导致无法对它们进行回收。
```java
objA.instance = objB;
objB.instance = objA;
```
### 2. 可达性
通过 GC Roots 作为起始点进行搜索,能够到达到的对象都是都是可用的,不可达的对象可被回收。
GC Roots 一般包含以下内容:
1. 虚拟机栈中引用的对象
2. 方法区中类静态属性引用的对象
3. 方法区中的常量引用的对象
4. 本地方法栈中引用的对象
### 3. 引用类型
无论是通过引用计算算法判断对象的引用数量,还是通过可达性分析算法判断对象的引用链是否可达,判定对象是否存活都与“引用”有关。
Java 对引用的概念进行了扩充,引入四种强度不同的引用类型。
**(一)强引用**
只要强引用存在,垃圾回收器永远不会回收调掉被引用的对象。
使用 new 一个新对象的方式来创建强引用。
```java
Object obj = new Object();
```
**(二)软引用**
用来描述一些还有用但是并非必需的对象。
在系统将要发生内存溢出异常之前,将会对这些对象列进回收范围之中进行第二次回收。如果这次回收还没有足够的内存,才会抛出溢出异常。
软引用主要用来实现类似缓存的功能,在内存足够的情况下直接通过软引用取值,无需从繁忙的真实来源获取数据,提升速度;当内存不足时,自动删除这部分缓存数据,从真正的来源获取这些数据。
使用 SoftReference 类来实现软引用。
```java
Object obj = new Object();
SoftReference