* [一、概览](#一概览)
* [Collection](#collection)
* [Map](#map)
* [二、容器中的设计模式](#二容器中的设计模式)
* [迭代器模式](#迭代器模式)
* [适配器模式](#适配器模式)
* [三、散列](#三散列)
* [四、源码分析](#四源码分析)
* [ArrayList](#arraylist)
* [Vector](#vector)
* [LinkedList](#linkedlist)
* [TreeMap](#treemap)
* [HashMap](#hashmap)
* [LinkedHashMap](#linkedhashmap)
* [ConcurrentHashMap](#concurrenthashmap)
* [五、参考资料](#五参考资料)
# 一、概览
容器主要包括 Collection 和 Map 两种,Collection 又包含了 List、Set 以及 Queue。
## Collection
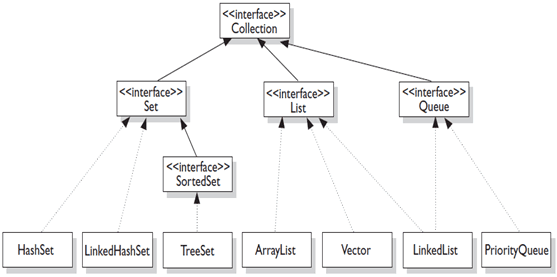
### 1. Set
- HashSet:基于哈希实现,支持快速查找,但不支持有序性操作,例如根据一个范围查找元素的操作。并且失去了元素的插入顺序信息,也就是说使用 Iterator 遍历 HashSet 得到的结果是不确定的。
- TreeSet:基于红黑树实现,支持有序性操作,但是查找效率不如 HashSet,HashSet 查找时间复杂度为 O(1),TreeSet 则为 O(logn);
- LinkedHashSet:具有 HashSet 的查找效率,且内部使用链表维护元素的插入顺序。
### 2. List
- ArrayList:基于动态数组实现,支持随机访问;
- Vector:和 ArrayList 类似,但它是线程安全的;
- LinkedList:基于双向循环链表实现,只能顺序访问,但是可以快速地在链表中间插入和删除元素。不仅如此,LinkedList 还可以用作栈、队列和双端队列。
### 3. Queue
- LinkedList:可以用它来支持双向队列;
- PriorityQueue 是基于堆结构实现,可以用它来实现优先级队列。
## Map
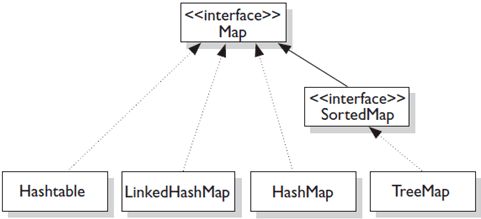
- HashMap:基于哈希实现;
- HashTable:和 HashMap 类似,但它是线程安全的,这意味着同一时刻多个线程可以同时写入 HashTable 并且不会导致数据不一致。它是遗留类,不应该去使用它。现在可以使用 ConcurrentHashMap 来支持线程安全,并且 ConcurrentHashMap 的效率会更高,因为 ConcurrentHashMap 引入了分段锁。
- LinkedHashMap:使用链表来维护元素的顺序,顺序为插入顺序或者最近最少使用(LRU)顺序。
- TreeMap:基于红黑树实现。
# 二、容器中的设计模式
## 迭代器模式
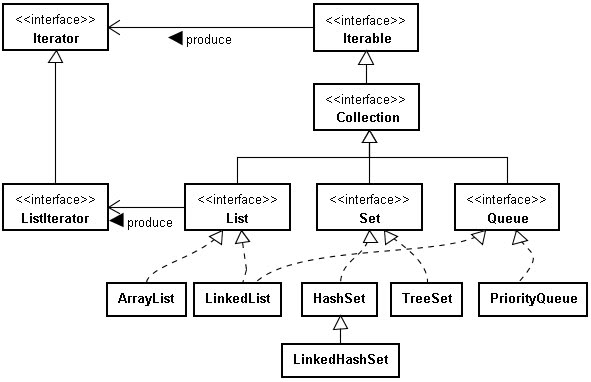
Collection 实现了 Iterable 接口,其中的 iterator() 方法能够产生一个 Iterator 对象,通过这个对象就可以迭代遍历 Collection 中的元素。
从 JDK 5 之后可以使用 foreach 方法来遍历实现了 Iterable 接口的聚合对象。
```java
List list = new ArrayList<>();
list.add("a");
list.add("b");
for (String item : list) {
System.out.println(item);
}
```
> [迭代器模式](https://github.com/CyC2018/Interview-Notebook/blob/master/notes/%E8%AE%BE%E8%AE%A1%E6%A8%A1%E5%BC%8F.md#%E5%8D%81%E4%BA%8C%E8%BF%AD%E4%BB%A3%E5%99%A8%E6%A8%A1%E5%BC%8F)
## 适配器模式
java.util.Arrays#asList() 可以把数组类型转换为 List 类型。
```java
List list = Arrays.asList(1, 2, 3);
int[] arr = {1, 2, 3};
list = Arrays.asList(arr);
```
> [适配器模式](https://github.com/CyC2018/Interview-Notebook/blob/master/notes/%E8%AE%BE%E8%AE%A1%E6%A8%A1%E5%BC%8F.md#%E5%8D%81%E9%80%82%E9%85%8D%E5%99%A8%E6%A8%A1%E5%BC%8F)
# 三、散列
hasCode() 返回散列值,使用的是对象的地址。
而 equals() 是用来判断两个对象是否相等的,相等的两个对象散列值一定要相同,但是散列值相同的两个对象不一定相等。
相等必须满足以下五个性质:
**1. 自反性**
```java
x.equals(x); // true
```
**2. 对称性**
```java
x.equals(y) == y.equals(x) // true
```
**3. 传递性**
```java
if(x.equals(y) && y.equals(z)) {
x.equals(z); // true;
}
```
**4. 一致性**
多次调用 equals() 方法结果不变
```java
x.equals(y) == x.equals(y); // true
```
**5. 与 null 的比较**
对任何不是 null 的对象 x 调用 x.equals(null) 结果都为 false
```java
x.euqals(null); // false;
```
# 四、源码分析
建议先阅读 [算法-查找](https://github.com/CyC2018/Interview-Notebook/blob/master/notes/%E7%AE%97%E6%B3%95.md#%E6%9F%A5%E6%89%BE) 部分,对容器类源码的理解有很大帮助。
以下源码属于 JDK 8,下载地址:[JDK-Source-Code](https://github.com/CyC2018/JDK-Source-Code)。
## ArrayList
[ArraList.java](https://github.com/CyC2018/JDK-Source-Code/tree/master/src/ArrayList.java)
### 1. 概览
实现了 RandomAccess 接口,因此支持随机访问,这是理所当然的,因为 ArrayList 是基于数组实现的。
```java
public class ArrayList extends AbstractList
implements List, RandomAccess, Cloneable, java.io.Serializable
```
基于数组实现,保存元素的数组使用 transient 修饰,该关键字声明数组默认不会被序列化。这是 ArrayList 具有动态扩容特性,因此保存元素的数组不一定都会被使用,那么就没必要全部进行序列化。ArrayList 重写了 writeObject() 和 readObject() 来控制只序列化数组中有元素填充那么部分内容。
```java
transient Object[] elementData; // non-private to simplify nested class access
```
数组的默认大小为 10。
```java
private static final int DEFAULT_CAPACITY = 10;
```
删除元素时需要调用 System.arraycopy() 对元素进行复制,因此删除操作成本很高。
```java
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index, numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
```
添加元素时使用 ensureCapacity() 方法来保证容量足够,如果不够时,需要使用 grow() 方法进行扩容,使得新容量为旧容量的 1.5 倍(oldCapacity + (oldCapacity >> 1))。扩容操作需要把原数组整个复制到新数组中,因此最好在创建 ArrayList 对象时就指定大概的容量大小,减少扩容操作的次数。
```java
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
```
### 2. Fail-Fast
modCount 用来记录 ArrayList 结构发生变化的次数。结构发生变化是指添加或者删除至少一个元素的所有操作,或者是调整内部数组的大小,仅仅只是设置元素的值不算结构发生变化。
在进行序列化或者迭代等操作时,需要比较操作前后 modCount 是否改变,如果改变了需要抛出 ConcurrentModificationException。
```java
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject();
// Write out size as capacity for behavioural compatibility with clone()
s.writeInt(size);
// Write out all elements in the proper order.
for (int i=0; i()); 返回一个线程安全的 ArrayList,也可以使用 concurrent 并发包下的 CopyOnWriteArrayList 类;
### 4. 和 LinkedList 的区别
- ArrayList 基于动态数组实现,LinkedList 基于双向循环链表实现;
- ArrayList 支持随机访问,LinkedList 不支持;
- LinkedList 在任意位置添加删除元素更快。
## Vector
[Vector.java](https://github.com/CyC2018/JDK-Source-Code/tree/master/src/Vector.java)
## LinkedList
[LinkedList.java](https://github.com/CyC2018/JDK-Source-Code/tree/master/src/LinkedList.java)
## TreeMap
[TreeMap.java](https://github.com/CyC2018/JDK-Source-Code/tree/master/src/TreeMap.java)
## HashMap
[HashMap.java](https://github.com/CyC2018/JDK-Source-Code/tree/master/src/HashMap.java)
### 1. 存储结构
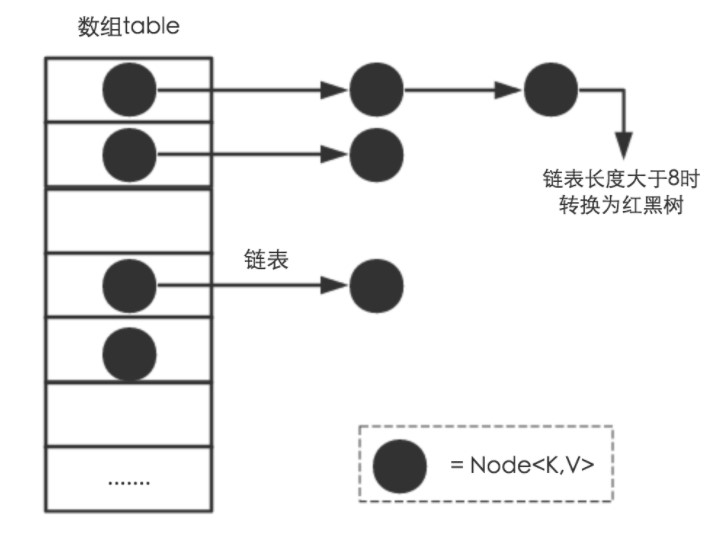
使用拉链法来解决冲突,内部包含了一个 Entry 类型的数组 table,数组中的每个位置被当成一个桶。
```java
transient Entry[] table;
```
其中,Entry 就是存储数据的键值对,它包含了四个字段。从 next 字段我们可以看出 Entry 是一个链表,即每个桶会存放一个链表。
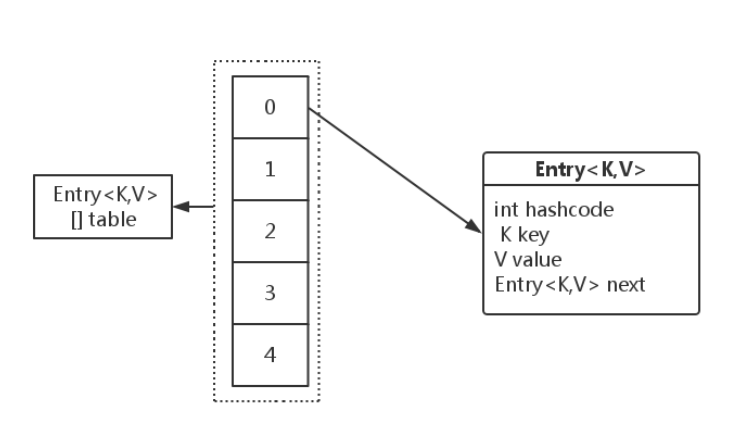
Java 8 使用 Node 类型存储一个键值对,它依然继承自 Entry,因此可以按照上面的存储结构来理解。
```java
static class Node implements Map.Entry {
final int hash;
final K key;
V value;
Node next;
Node(int hash, K key, V value, Node next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry e = (Map.Entry)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
```
### 2. 拉链法的工作原理
```java
HashMap map = new HashMap<>(); // 默认大小为 16
map.put("sachin", 30);
map.put("vishal", 20);
map.put("vaibhav", 20);
```
- 计算 "sachin" 的 hashcode 为 115,使用除留余数法得到 115 % 16 = 3,因此 ("sachin", 30) 键值对放到第 3 个桶上。
- 同样得到 ("vishal", 20) 和 ("vaibhav", 20) 都应该放到第 6 个桶上。("vishal", 20) 先放入, ("vaibhav", 20) 链接到 ("vishal", 20) 之后。
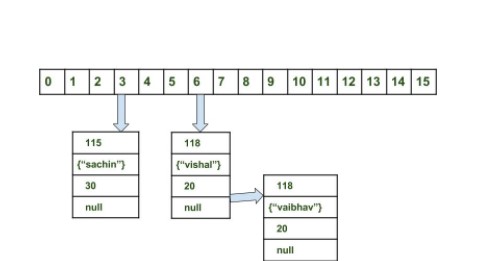
当进行查找时,需要分成两步进行,第一步是先根据 hashcode 计算出所在的桶,第二步是在链表上顺序查找。由于 table 是数组形式的,具有随机读取的特性,因此第一步的时间复杂度为 O(1),而第二步需要在链表上顺序查找,时间复杂度显然和链表的长度成正比。
### 3. 链表转红黑树
应该注意到,从 Java 8 开始,一个桶存储的链表长度大于 8 时会将链表转换为红黑树。
### 4. 扩容
因为从 Java 8 开始引入了红黑树,因此扩容操作较为复杂,为了便于理解,以下内容使用 Java 7 的内容。
设 HashMap 的 table 长度为 M,需要存储的键值对数量为 N,如果哈希函数满足均匀性的要求,那么每条链表的长度大约为 N/M,因此平均查找次数的数量级为 O(N/M)。
为了让查找的成本降低,应该尽可能使得 N/M 尽可能小,因此需要保证 M 尽可能大,可就是说 table 要尽可能大。HashMap 采用动态扩容来根据当前的 N 值来调整 M 值,使得空间效率和时间效率都能得到保证。
和扩容相关的参数主要有:capacity、size、threshold 和 load_factor。
| 参数 | 含义 |
| :--: | :-- |
| capacity | table 的容量大小,默认为 16,需要注意的是 capacity 必须保证为 2 的次方。|
| size | table 的实际使用量。 |
| threshold | size 的临界值,size 必须小于 threshold,如果大于等于,就必须进行扩容操作。 |
| load_factor | table 能够使用的比例,threshold = capacity * load_factor。|
```java
static final int DEFAULT_INITIAL_CAPACITY = 16;
static final int MAXIMUM_CAPACITY = 1 << 30;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
transient Entry[] table;
transient int size;
int threshold;
final float loadFactor;
transient int modCount;
```
从下面的添加元素代码中可以看出,当需要扩容时,令 capacity 为原来的两倍。
```java
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length);
}
```
扩容使用 resize() 实现,需要注意的是,扩容操作同样需要把旧 table 的所有键值对重新插入新的 table 中,因此这一步是很费时的。
```java
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry e = src[j];
if (e != null) {
src[j] = null;
do {
Entry next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
```
### 5. 确定桶下标
需要三步操作:计算 Key 的 hashCode、高位运算、除留余数法取模。

**(一)hashcode()**
```java
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
```
**(二)高位运算**
通过 hashCode() 的高 16 位异或低 16 位,使得数组比较小时,也能保证高低位都参与到了哈希计算中。
```java
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
```
**(三)除留余数**
令 x = 1<<4,即 x 为 2 的 4 次方,它具有以下性质:
```
x : 00010000
x-1 : 00001111
```
令一个数 y 与 x-1 做与运算,可以去除 y 位级表示的第 4 位以上数:
```
y : 10110010
x-1 : 00001111
y&(x-1) : 00000010
```
这个性质和 y 对 x 取模式一样的:
```
x : 00010000
y : 10110010
y%x : 00000010
```
我们知道,位运算的代价比求模运算小的多,因此在进行这种计算时能用位运算的话能带来更高的性能。
拉链法需要使用除留余数法来得到桶下标,也就是需要进行以下计算:hash%capacity,如果能保证 capacity 为 2 的幂次方,那么就可以将这个操作转换位位运算。
以下操作在 Java 8 中没有,但是原理上相同。
```java
static int indexFor(int h, int length) {
return h & (length-1);
}
```
### 6. null 值
get() 操作需要分成两种情况,key 为 null 和不为 null,从中可以看出 HashMap 允许插入 null 作为键。
```java
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
for (Entry e = table[indexFor(hash, table.length)]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
```
put() 操作也需要根据 key 是否为 null 做不同的处理,需要注意的是如果本来没有 key 为 null 的键值对,新插入一个 key 为 null 的键值对时默认是放在数组的 0 位置,这是因为 null 不能计算 hash 值,也就无法知道应该放在哪个链表上。
```java
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
```
```java
private V putForNullKey(V value) {
for (Entry e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
```
### 7. 与 HashTable 的区别
- HashTable 是同步的,它使用了 synchronized 来进行同步。它也是线程安全的,多个线程可以共享同一个 HashTable。HashMap 不是同步的,但是可以使用 ConcurrentHashMap,它是 HashTable 的替代,而且比 HashTable 可扩展性更好。
- HashMap 可以插入键为 null 的 Entry。
- HashMap 的迭代器是 fail-fast 迭代器,而 Hashtable 的 enumerator 迭代器不是 fail-fast 的。
- 由于 Hashtable 是线程安全的也是 synchronized,所以在单线程环境下它比 HashMap 要慢。
- HashMap 不能保证随着时间的推移 Map 中的元素次序是不变的。
## LinkedHashMap
[LinkedHashMap.java](https://github.com/CyC2018/JDK-Source-Code/tree/master/src/HashMap.java)
## ConcurrentHashMap
[ConcurrentHashMap.java](https://github.com/CyC2018/JDK-Source-Code/tree/master/src/HashMap.java)
[探索 ConcurrentHashMap 高并发性的实现机制](https://www.ibm.com/developerworks/cn/java/java-lo-concurrenthashmap/)
# 五、参考资料
- Java 编程思想
- [Java Collection Framework](https://www.w3resource.com/java-tutorial/java-collections.php)
- [Iterator 模式](https://openhome.cc/Gossip/DesignPattern/IteratorPattern.htm)
- [Java 8 系列之重新认识 HashMap](https://tech.meituan.com/java-hashmap.html)
- [What is difference between HashMap and Hashtable in Java?](http://javarevisited.blogspot.hk/2010/10/difference-between-hashmap-and.html)