auto commit
This commit is contained in:
parent
0e63010bce
commit
8d90b1721b
96
README.md
96
README.md
@ -1,13 +1,95 @@
|
||||
# 笔记
|
||||
# 数据结构与算法
|
||||
|
||||
- [Leetocde题解](https://github.com/CyC2018/CodeInterview/blob/master/Leetocde%E9%A2%98%E8%A7%A3.md)
|
||||
> [算法](https://github.com/CyC2018/InnterviewNotes/blob/master/notes/算法.md)
|
||||
|
||||
- [剑指offer题解](https://github.com/CyC2018/CodeInterview/blob/master/%E5%89%91%E6%8C%87offer%E9%A2%98%E8%A7%A3.md)
|
||||
整理自《算法 第四版》,主要整理了排序和树。
|
||||
|
||||
- [2016校招真题题解-未完成](https://github.com/CyC2018/CodeInterview/blob/master/2016%E6%A0%A1%E6%8B%9B%E7%9C%9F%E9%A2%98%E9%A2%98%E8%A7%A3.md)
|
||||
> [Leetcode 题解](https://github.com/CyC2018/InnterviewNotes/blob/master/notes/Leetcode%20题解.md)
|
||||
|
||||
# OJ 地址
|
||||
对题目做了一个分类,并对每种题型的解题思想做了总结。
|
||||
|
||||
- 牛客网 : https://www.nowcoder.com/activity/oj
|
||||
已经整理了 300+ 的题目,基本涵盖所有经典题目,持续整理中。
|
||||
|
||||
- Leetcode : https://leetcode.com/problemset/algorithms/
|
||||
> [剑指 offer 题解](https://github.com/CyC2018/InnterviewNotes/blob/master/notes/剑指%20offer%20题解.md)
|
||||
|
||||
目录按《剑指 Offer 第二版》编排,在牛客网的在线编程中出现的题目都已经 AC。
|
||||
|
||||
> [2016 校招真题题解](https://github.com/CyC2018/InnterviewNotes/blob/master/notes/2016%20校招真题题解.md)
|
||||
|
||||
未完成
|
||||
|
||||
# 网络
|
||||
|
||||
> [计算机网络](https://github.com/CyC2018/InnterviewNotes/blob/master/notes/计算机网络.md)
|
||||
|
||||
整理自《计算机网络 第七版》
|
||||
|
||||
> [HTTP](https://github.com/CyC2018/InnterviewNotes/blob/master/notes/HTTP.md)
|
||||
|
||||
整理自《图解 HTTP》
|
||||
|
||||
# 操作系统
|
||||
|
||||
> [计算机操作系统](https://github.com/CyC2018/InnterviewNotes/blob/master/notes/计算机操作系统.md)
|
||||
|
||||
整理自《现代操作系统》
|
||||
|
||||
> [Linux](https://github.com/CyC2018/InnterviewNotes/blob/master/notes/Linux.md)
|
||||
|
||||
整理自《鸟哥的 Linux 私房菜》
|
||||
|
||||
# 面向对象
|
||||
|
||||
> [设计模式](https://github.com/CyC2018/InnterviewNotes/blob/master/notes/设计模式.md)
|
||||
|
||||
整理自《Head First 设计模式》,这本书内容废话太多,笔记内容提取了重点部分。
|
||||
|
||||
> [面向对象思想](https://github.com/CyC2018/InnterviewNotes/blob/master/notes/面向对象思想.md)
|
||||
|
||||
一些面向对象思想和原则
|
||||
|
||||
# 数据库
|
||||
|
||||
> [SQL 语法](https://github.com/CyC2018/InnterviewNotes/blob/master/notes/SQL%20语法.md)
|
||||
|
||||
整理自《SQL 必知必会》,原书内容不多,笔记内容会更简洁。
|
||||
|
||||
> [MySQL](https://github.com/CyC2018/InnterviewNotes/blob/master/notes/MySQL.md)
|
||||
|
||||
整理自《高性能 MySQL》,重点整理。
|
||||
|
||||
# Java
|
||||
|
||||
> [JVM](https://github.com/CyC2018/InnterviewNotes/blob/master/notes/JVM.md)
|
||||
|
||||
整理自《深入理解 Java 虚拟机》,包括内存模型、垃圾回收和类加载机制。
|
||||
|
||||
> [Java IO](https://github.com/CyC2018/InnterviewNotes/blob/master/notes/Java%20IO.md)
|
||||
|
||||
File、InputStream 和 OutputStream、Reader 和 Writer、Serializable、Socket 以及 NIO
|
||||
|
||||
# 资料下载
|
||||
|
||||
> [百度网盘](https://pan.baidu.com/s/1o9oD1s2#list/path=%2F)
|
||||
|
||||
一些 PDF 书籍
|
||||
|
||||
# 后记
|
||||
|
||||
原文发表在 [牛客网:计算机基础重点整理](https://www.nowcoder.com/discuss/66985)
|
||||
|
||||
楼主在牛客网上看了挺多面经,面经里提到的面试重点对楼主的学习帮助很大。但是很少有面经给了比较系统的知识整理,大部分都比较零散,这也是楼主整理这个仓库的原因,希望对大家有所帮助。
|
||||
|
||||
笔记开源在 Github 上,包括数据结构与算法、网络、操作系统、面向对象。数据结构与算法的笔记之前也在牛客网发布过了,包括了算法、Leetcode 题解、剑指 Offer 题解。网络部分除了整理本科学过的计算机网络之外,还特别整理了 HTTP 的内容。操作系统也是,除了整理计算机操作系统课程的内容之外,也特别整理了 Linux 的内容。至于面向对象,重点部分是设计模式笔记,还有就是一些面向对象思想。
|
||||
|
||||
之后会继续整理其它笔记,例如 Java、数据库、系统设计等,可能也会整理一些编码实践相关的笔记,例如重构、代码风格。
|
||||
|
||||
提供一些 PDF 资源的下载,除了一两本不是很清楚,其它都是高清的。
|
||||
|
||||
楼主作为一个轻度强迫症患者,笔记内容会尽量保证排版美观,可读性好。有时候为了加个好看的图,会使用一些画图软件自己画,可见楼主的强迫症多严重,不过应该算还好。为了让笔记内容更整洁,前前后后做了很多次修改,也写了一个为中英混排文档进行排版的脚本,来提高笔记的可读性。
|
||||
|
||||
为了上传笔记到 Github 上,也花了一点时间。楼主使用的笔记软件是为知笔记,怎么把笔记内容提取成文本文档,并且提取笔记中的图片就是一个问题。还有就是 Github 使用的是 GFM 来渲染 md 文档,和普通的 Markdown 不太一样,例如 GFM 不支持 MathJax 公式,也不支持 TOC 标记,为此需要替换 MathJax 公式为 codecogs 的云服务和重新生成 TOC 目录。楼主实现了脚本解决了上述的问题,并且整个过程可以一键进行,包括 git 同步到仓库中,因此把为知笔记的内容同步到仓库中的速度非常快。
|
||||
|
||||
大部分笔记都是楼主一个字一个字打上去的,少数有摘抄其它文章的内容,这些文章都可以在后面的参考链接中找到。笔记内容可随意使用,转载请注明出处,毕竟写了这么久没那么轻松~
|
||||
|
||||
想要支持楼主的话,在 Github 仓库点个 Star 即可。
|
||||
@ -1,33 +1,33 @@
|
||||
<!-- GFM-TOC -->
|
||||
* [前言](#前言)
|
||||
* [1. 小米-小米Git](#1-小米-小米git)
|
||||
* [2. 小米-懂二进制](#2-小米-懂二进制)
|
||||
* [3. 小米-中国牛市](#3-小米-中国牛市)
|
||||
* [4. 微软-LUCKY STRING](#4-微软-lucky-string)
|
||||
* [5. 微软-Numeric Keypad](#5-微软-numeric-keypad)
|
||||
* [6. 微软-Spring Outing](#6-微软-spring-outing)
|
||||
* [7. 微软-S-expression](#7-微软-s-expression)
|
||||
* [8. 华为-最高分是多少](#8-华为-最高分是多少)
|
||||
* [9. 华为-简单错误记录](#9-华为-简单错误记录)
|
||||
* [10. 华为-扑克牌大小](#10-华为-扑克牌大小)
|
||||
* [11. 去哪儿-二分查找](#11-去哪儿-二分查找)
|
||||
* [12. 去哪儿-首个重复字符](#12-去哪儿-首个重复字符)
|
||||
* [13. 去哪儿-寻找Coder](#13-去哪儿-寻找coder)
|
||||
* [14. 美团-最大差值](#14-美团-最大差值)
|
||||
* [15. 美团-棋子翻转](#15-美团-棋子翻转)
|
||||
* [16. 美团-拜访](#16-美团-拜访)
|
||||
* [17. 美团-直方图内最大矩形](#17-美团-直方图内最大矩形)
|
||||
* [18. 美团-字符串计数](#18-美团-字符串计数)
|
||||
* [19. 美团-平均年龄](#19-美团-平均年龄)
|
||||
* [20. 百度-罪犯转移](#20-百度-罪犯转移)
|
||||
* [22. 百度-裁减网格纸](#22-百度-裁减网格纸)
|
||||
* [23. 百度-钓鱼比赛](#23-百度-钓鱼比赛)
|
||||
* [24. 百度-蘑菇阵](#24-百度-蘑菇阵)
|
||||
* [前言](#前言)
|
||||
* [1. 小米-小米Git](#1-小米-小米git)
|
||||
* [2. 小米-懂二进制](#2-小米-懂二进制)
|
||||
* [3. 小米-中国牛市](#3-小米-中国牛市)
|
||||
* [4. 微软-LUCKY STRING](#4-微软-lucky-string)
|
||||
* [5. 微软-Numeric Keypad](#5-微软-numeric-keypad)
|
||||
* [6. 微软-Spring Outing](#6-微软-spring-outing)
|
||||
* [7. 微软-S-expression](#7-微软-s-expression)
|
||||
* [8. 华为-最高分是多少](#8-华为-最高分是多少)
|
||||
* [9. 华为-简单错误记录](#9-华为-简单错误记录)
|
||||
* [10. 华为-扑克牌大小](#10-华为-扑克牌大小)
|
||||
* [11. 去哪儿-二分查找](#11-去哪儿-二分查找)
|
||||
* [12. 去哪儿-首个重复字符](#12-去哪儿-首个重复字符)
|
||||
* [13. 去哪儿-寻找Coder](#13-去哪儿-寻找coder)
|
||||
* [14. 美团-最大差值](#14-美团-最大差值)
|
||||
* [15. 美团-棋子翻转](#15-美团-棋子翻转)
|
||||
* [16. 美团-拜访](#16-美团-拜访)
|
||||
* [17. 美团-直方图内最大矩形](#17-美团-直方图内最大矩形)
|
||||
* [18. 美团-字符串计数](#18-美团-字符串计数)
|
||||
* [19. 美团-平均年龄](#19-美团-平均年龄)
|
||||
* [20. 百度-罪犯转移](#20-百度-罪犯转移)
|
||||
* [22. 百度-裁减网格纸](#22-百度-裁减网格纸)
|
||||
* [23. 百度-钓鱼比赛](#23-百度-钓鱼比赛)
|
||||
* [24. 百度-蘑菇阵](#24-百度-蘑菇阵)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
# 前言
|
||||
# 前言
|
||||
|
||||
省略的代码:
|
||||
省略的代码:
|
||||
|
||||
```java
|
||||
import java.util.*;
|
||||
@ -48,10 +48,10 @@ public class Main {
|
||||
}
|
||||
```
|
||||
|
||||
# 1. 小米-小米Git
|
||||
# 1. 小米-小米Git
|
||||
|
||||
- 重建多叉树
|
||||
- 使用 LCA
|
||||
- 重建多叉树
|
||||
- 使用 LCA
|
||||
|
||||
```java
|
||||
private class TreeNode {
|
||||
@ -65,7 +65,7 @@ private class TreeNode {
|
||||
|
||||
public int getSplitNode(String[] matrix, int indexA, int indexB) {
|
||||
int n = matrix.length;
|
||||
boolean[][] linked = new boolean[n][n]; // 重建邻接矩阵
|
||||
boolean[][] linked = new boolean[n][n]; // 重建邻接矩阵
|
||||
for (int i = 0; i < n; i++) {
|
||||
for (int j = 0; j < n; j++) {
|
||||
linked[i][j] = matrix[i].charAt(j) == '1';
|
||||
@ -80,7 +80,7 @@ private TreeNode constructTree(boolean[][] linked, int root) {
|
||||
TreeNode tree = new TreeNode(root);
|
||||
for (int i = 0; i < linked[root].length; i++) {
|
||||
if (linked[root][i]) {
|
||||
linked[i][root] = false; // 因为题目给的邻接矩阵是双向的,在这里需要把它转为单向的
|
||||
linked[i][root] = false; // 因为题目给的邻接矩阵是双向的,在这里需要把它转为单向的
|
||||
tree.childs.add(constructTree(links, i));
|
||||
}
|
||||
}
|
||||
@ -102,9 +102,9 @@ private TreeNode LCA(TreeNode root, TreeNode p, TreeNode q) {
|
||||
}
|
||||
```
|
||||
|
||||
# 2. 小米-懂二进制
|
||||
# 2. 小米-懂二进制
|
||||
|
||||
对两个数进行异或,结果的二进制表示为 1 的那一位就是两个数不同的位。
|
||||
对两个数进行异或,结果的二进制表示为 1 的那一位就是两个数不同的位。
|
||||
|
||||
```java
|
||||
public int countBitDiff(int m, int n) {
|
||||
@ -112,11 +112,11 @@ public int countBitDiff(int m, int n) {
|
||||
}
|
||||
```
|
||||
|
||||
# 3. 小米-中国牛市
|
||||
# 3. 小米-中国牛市
|
||||
|
||||
背包问题,可以设一个大小为 2 的背包。
|
||||
背包问题,可以设一个大小为 2 的背包。
|
||||
|
||||
状态转移方程如下:
|
||||
状态转移方程如下:
|
||||
|
||||
```html
|
||||
dp[i, j] = max(dp[i, j-1], prices[j] - prices[jj] + dp[i-1, jj]) { jj in range of [0, j-1] } = max(dp[i, j-1], prices[j] + max(dp[i-1, jj] - prices[jj]))
|
||||
@ -137,10 +137,10 @@ public int calculateMax(int[] prices) {
|
||||
}
|
||||
```
|
||||
|
||||
# 4. 微软-LUCKY STRING
|
||||
# 4. 微软-LUCKY STRING
|
||||
|
||||
- 斐波那契数列可以预计算;
|
||||
- 从头到尾遍历字符串的过程,每一轮循环都使用一个 Set 来保存从 i 到 j 出现的字符,并且 Set 保证了字符都不同,因此 Set 的大小就是不同字符的个数。
|
||||
- 斐波那契数列可以预计算;
|
||||
- 从头到尾遍历字符串的过程,每一轮循环都使用一个 Set 来保存从 i 到 j 出现的字符,并且 Set 保证了字符都不同,因此 Set 的大小就是不同字符的个数。
|
||||
|
||||
```java
|
||||
Set<Integer> fibSet = new HashSet<>(Arrays.asList(1, 2, 3, 5, 8, 13, 21, 34, 55, 89));
|
||||
@ -165,7 +165,7 @@ for (String s : arr) {
|
||||
}
|
||||
```
|
||||
|
||||
# 5. 微软-Numeric Keypad
|
||||
# 5. 微软-Numeric Keypad
|
||||
|
||||
```java
|
||||
private static int[][] canReach = {
|
||||
@ -209,17 +209,17 @@ public static void main(String[] args) {
|
||||
}
|
||||
```
|
||||
|
||||
# 6. 微软-Spring Outing
|
||||
# 6. 微软-Spring Outing
|
||||
|
||||
下面以 N = 3,K = 4 来进行讨论。
|
||||
下面以 N = 3,K = 4 来进行讨论。
|
||||
|
||||
初始时,令第 0 个地方成为待定地点,也就是呆在家里。
|
||||
初始时,令第 0 个地方成为待定地点,也就是呆在家里。
|
||||
|
||||
从第 4 个地点开始投票,每个人只需要比较第 4 个地方和第 0 个地方的优先级,里,如果超过半数的人选择了第 4 个地方,那么更新第 4 个地方成为待定地点。
|
||||
从第 4 个地点开始投票,每个人只需要比较第 4 个地方和第 0 个地方的优先级,里,如果超过半数的人选择了第 4 个地方,那么更新第 4 个地方成为待定地点。
|
||||
|
||||
从后往前不断重复以上步骤,不断更新待定地点,直到所有地方都已经投票。
|
||||
从后往前不断重复以上步骤,不断更新待定地点,直到所有地方都已经投票。
|
||||
|
||||
上面的讨论中,先令第 0 个地点成为待定地点,是因为这样的话第 4 个地点就只需要和这个地点进行比较,而不用考虑其它情况。如果最开始先令第 1 个地点成为待定地点,那么在对第 2 个地点进行投票时,每个人不仅要考虑第 2 个地点与第 1 个地点的优先级,也要考虑与其后投票地点的优先级。
|
||||
上面的讨论中,先令第 0 个地点成为待定地点,是因为这样的话第 4 个地点就只需要和这个地点进行比较,而不用考虑其它情况。如果最开始先令第 1 个地点成为待定地点,那么在对第 2 个地点进行投票时,每个人不仅要考虑第 2 个地点与第 1 个地点的优先级,也要考虑与其后投票地点的优先级。
|
||||
|
||||
```java
|
||||
int N = in.nextInt();
|
||||
@ -246,9 +246,9 @@ for (int place = K; place > 0; place--) {
|
||||
System.out.println(ret == 0 ? "otaku" : ret);
|
||||
```
|
||||
|
||||
# 7. 微软-S-expression
|
||||
# 7. 微软-S-expression
|
||||
|
||||
# 8. 华为-最高分是多少
|
||||
# 8. 华为-最高分是多少
|
||||
|
||||
```java
|
||||
int N = in.nextInt();
|
||||
@ -280,7 +280,7 @@ for (int i = 0; i < M; i++) {
|
||||
}
|
||||
```
|
||||
|
||||
# 9. 华为-简单错误记录
|
||||
# 9. 华为-简单错误记录
|
||||
|
||||
```java
|
||||
HashMap<String, Integer> map = new LinkedHashMap<>();
|
||||
@ -300,7 +300,7 @@ for (int i = 0; i < 8 && i < list.size(); i++) {
|
||||
}
|
||||
```
|
||||
|
||||
# 10. 华为-扑克牌大小
|
||||
# 10. 华为-扑克牌大小
|
||||
|
||||
```java
|
||||
public class Main {
|
||||
@ -391,12 +391,12 @@ public class Main {
|
||||
}
|
||||
```
|
||||
|
||||
# 11. 去哪儿-二分查找
|
||||
# 11. 去哪儿-二分查找
|
||||
|
||||
对于有重复元素的有序数组,二分查找需要注意以下要点:
|
||||
对于有重复元素的有序数组,二分查找需要注意以下要点:
|
||||
|
||||
- if (val <= A[m]) h = m;
|
||||
- 因为 h 的赋值为 m 而不是 m - 1,因此 while 循环的条件也就为 l < h。(如果是 m - 1 循环条件为 l <= h)
|
||||
- 因为 h 的赋值为 m 而不是 m - 1,因此 while 循环的条件也就为 l < h。(如果是 m - 1 循环条件为 l <= h)
|
||||
|
||||
```java
|
||||
public int getPos(int[] A, int n, int val) {
|
||||
@ -410,7 +410,7 @@ public int getPos(int[] A, int n, int val) {
|
||||
}
|
||||
```
|
||||
|
||||
# 12. 去哪儿-首个重复字符
|
||||
# 12. 去哪儿-首个重复字符
|
||||
|
||||
```java
|
||||
public char findFirstRepeat(String A, int n) {
|
||||
@ -424,7 +424,7 @@ public char findFirstRepeat(String A, int n) {
|
||||
}
|
||||
```
|
||||
|
||||
# 13. 去哪儿-寻找Coder
|
||||
# 13. 去哪儿-寻找Coder
|
||||
|
||||
```java
|
||||
public String[] findCoder(String[] A, int n) {
|
||||
@ -450,7 +450,7 @@ public String[] findCoder(String[] A, int n) {
|
||||
return ret;
|
||||
}
|
||||
|
||||
// 牛客网无法导入 javafx.util.Pair,这里就自己实现一下 Pair 类
|
||||
// 牛客网无法导入 javafx.util.Pair,这里就自己实现一下 Pair 类
|
||||
private class Pair<T, K> {
|
||||
T t;
|
||||
K k;
|
||||
@ -470,9 +470,9 @@ private class Pair<T, K> {
|
||||
}
|
||||
```
|
||||
|
||||
# 14. 美团-最大差值
|
||||
# 14. 美团-最大差值
|
||||
|
||||
贪心策略。
|
||||
贪心策略。
|
||||
|
||||
```java
|
||||
public int getDis(int[] A, int n) {
|
||||
@ -486,7 +486,7 @@ public int getDis(int[] A, int n) {
|
||||
}
|
||||
```
|
||||
|
||||
# 15. 美团-棋子翻转
|
||||
# 15. 美团-棋子翻转
|
||||
|
||||
```java
|
||||
public int[][] flipChess(int[][] A, int[][] f) {
|
||||
@ -502,7 +502,7 @@ public int[][] flipChess(int[][] A, int[][] f) {
|
||||
}
|
||||
```
|
||||
|
||||
# 16. 美团-拜访
|
||||
# 16. 美团-拜访
|
||||
|
||||
```java
|
||||
private Set<String> paths;
|
||||
@ -554,7 +554,7 @@ private void backtracking(int[][] map, int n, int m, int r, int c, int[][] direc
|
||||
}
|
||||
```
|
||||
|
||||
# 17. 美团-直方图内最大矩形
|
||||
# 17. 美团-直方图内最大矩形
|
||||
|
||||
```java
|
||||
public int countArea(int[] A, int n) {
|
||||
@ -570,15 +570,15 @@ public int countArea(int[] A, int n) {
|
||||
}
|
||||
```
|
||||
|
||||
# 18. 美团-字符串计数
|
||||
# 18. 美团-字符串计数
|
||||
|
||||
字符串都是小写字符,可以把字符串当成是 26 进制。但是字典序的比较和普通的整数比较不同,是从左往右进行比较,例如 "ac" 和 "abc",字典序的比较结果为 "ac" > "abc",如果按照整数方法比较,因为 "abc" 是三位数,显然更大。
|
||||
字符串都是小写字符,可以把字符串当成是 26 进制。但是字典序的比较和普通的整数比较不同,是从左往右进行比较,例如 "ac" 和 "abc",字典序的比较结果为 "ac" > "abc",如果按照整数方法比较,因为 "abc" 是三位数,显然更大。
|
||||
|
||||
由于两个字符串的长度可能不想等,在 s1 空白部分和 s2 对应部分进行比较时,应该把 s1 的空白部分看成是 'a' 字符进行填充的。
|
||||
由于两个字符串的长度可能不想等,在 s1 空白部分和 s2 对应部分进行比较时,应该把 s1 的空白部分看成是 'a' 字符进行填充的。
|
||||
|
||||
还有一点要注意的是,s1 到 s2 长度为 len<sub>i</sub> 的字符串个数只比较前面 i 个字符。例如 'aaa' 和 'bbb' ,长度为 2 的个数为 'aa' 到 'bb' 的字符串个数,不需要考虑后面部分的字符。
|
||||
还有一点要注意的是,s1 到 s2 长度为 len<sub>i</sub> 的字符串个数只比较前面 i 个字符。例如 'aaa' 和 'bbb' ,长度为 2 的个数为 'aa' 到 'bb' 的字符串个数,不需要考虑后面部分的字符。
|
||||
|
||||
在统计个数时,从 len1 开始一直遍历到最大合法长度,每次循环都统计长度为 i 的子字符串个数。
|
||||
在统计个数时,从 len1 开始一直遍历到最大合法长度,每次循环都统计长度为 i 的子字符串个数。
|
||||
|
||||
```java
|
||||
String s1 = in.next();
|
||||
@ -601,7 +601,7 @@ for (int i = len1; i <= len; i++) {
|
||||
System.out.println(ret - 1);
|
||||
```
|
||||
|
||||
# 19. 美团-平均年龄
|
||||
# 19. 美团-平均年龄
|
||||
|
||||
```java
|
||||
int W = in.nextInt();
|
||||
@ -609,15 +609,15 @@ double Y = in.nextDouble();
|
||||
double x = in.nextDouble();
|
||||
int N = in.nextInt();
|
||||
while (N-- > 0) {
|
||||
Y++; // 老员工每年年龄都要加 1
|
||||
Y++; // 老员工每年年龄都要加 1
|
||||
Y += (21 - Y) * x;
|
||||
}
|
||||
System.out.println((int) Math.ceil(Y));
|
||||
```
|
||||
|
||||
# 20. 百度-罪犯转移
|
||||
# 20. 百度-罪犯转移
|
||||
|
||||
部分和问题,将每次求的部分和缓存起来。
|
||||
部分和问题,将每次求的部分和缓存起来。
|
||||
|
||||
```java
|
||||
int n = in.nextInt();
|
||||
@ -640,7 +640,7 @@ for (int s = 0, e = c - 1; e < n; s++, e++) {
|
||||
System.out.println(cnt);
|
||||
```
|
||||
|
||||
# 22. 百度-裁减网格纸
|
||||
# 22. 百度-裁减网格纸
|
||||
|
||||
```java
|
||||
int n = in.nextInt();
|
||||
@ -658,11 +658,11 @@ for (int i = 0; i < n; i++) {
|
||||
System.out.println((int) Math.pow(Math.max(maxX - minX, maxY - minY), 2));
|
||||
```
|
||||
|
||||
# 23. 百度-钓鱼比赛
|
||||
# 23. 百度-钓鱼比赛
|
||||
|
||||
P ( 至少钓一条鱼 ) = 1 - P ( 一条也钓不到 )
|
||||
P ( 至少钓一条鱼 ) = 1 - P ( 一条也钓不到 )
|
||||
|
||||
坑:读取概率矩阵的时候,需要一行一行进行读取,而不能直接用 in.nextDouble()。
|
||||
坑:读取概率矩阵的时候,需要一行一行进行读取,而不能直接用 in.nextDouble()。
|
||||
|
||||
```java
|
||||
public static void main(String[] args) {
|
||||
@ -673,11 +673,11 @@ public static void main(String[] args) {
|
||||
int x = in.nextInt();
|
||||
int y = in.nextInt();
|
||||
int t = in.nextInt();
|
||||
in.nextLine(); // 坑
|
||||
in.nextLine(); // 坑
|
||||
double pcc = 0.0;
|
||||
double sum = 0.0;
|
||||
for (int i = 1; i <= n; i++) {
|
||||
String[] token = in.nextLine().split(" "); // 坑
|
||||
String[] token = in.nextLine().split(" "); // 坑
|
||||
for (int j = 1; j <= m; j++) {
|
||||
double p = Double.parseDouble(token[j - 1]);
|
||||
// double p = in.nextDouble();
|
||||
@ -701,13 +701,13 @@ private static double computePOfIRT(double p, int t) {
|
||||
}
|
||||
```
|
||||
|
||||
# 24. 百度-蘑菇阵
|
||||
# 24. 百度-蘑菇阵
|
||||
|
||||
这题用回溯会超时,需要用 DP。
|
||||
这题用回溯会超时,需要用 DP。
|
||||
|
||||
dp[i][j] 表示到达 (i,j) 位置不会触碰蘑菇的概率。对于 N\*M 矩阵,如果 i == N || j == M,那么 (i,j) 只能有一个移动方向;其它情况下能有两个移动方向。
|
||||
dp[i][j] 表示到达 (i,j) 位置不会触碰蘑菇的概率。对于 N\*M 矩阵,如果 i == N || j == M,那么 (i,j) 只能有一个移动方向;其它情况下能有两个移动方向。
|
||||
|
||||
考虑以下矩阵,其中第 3 行和第 3 列只能往一个方向移动,而其它位置可以有两个方向移动。
|
||||
考虑以下矩阵,其中第 3 行和第 3 列只能往一个方向移动,而其它位置可以有两个方向移动。
|
||||
|
||||
|
||||
```java
|
||||
399
notes/HTTP.md
Normal file
399
notes/HTTP.md
Normal file
@ -0,0 +1,399 @@
|
||||
<!-- GFM-TOC -->
|
||||
* [基础概念](#基础概念)
|
||||
* [Web基础](#web基础)
|
||||
* [URL](#url)
|
||||
* [请求和响应报文](#请求和响应报文)
|
||||
* [HTTP 方法](#http-方法)
|
||||
* [GET:获取资源](#get获取资源)
|
||||
* [POST:传输实体主体](#post传输实体主体)
|
||||
* [HEAD:获取报文首部](#head获取报文首部)
|
||||
* [PUT:上传文件](#put上传文件)
|
||||
* [DELETE:删除文件](#delete删除文件)
|
||||
* [OPTIONS:查询支持的方法](#options查询支持的方法)
|
||||
* [RACE:追踪路径](#race追踪路径)
|
||||
* [CONNECT:要求用隧道协议连接代理](#connect要求用隧道协议连接代理)
|
||||
* [HTTP 状态码](#http-状态码)
|
||||
* [2XX 成功](#2xx-成功)
|
||||
* [3XX 重定向](#3xx-重定向)
|
||||
* [4XX 客户端错误](#4xx-客户端错误)
|
||||
* [5XX 服务器错误](#5xx-服务器错误)
|
||||
* [HTTP首部](#http首部)
|
||||
* [通用首部字段](#通用首部字段)
|
||||
* [请求首部字段](#请求首部字段)
|
||||
* [响应首部字段](#响应首部字段)
|
||||
* [实体首部字段](#实体首部字段)
|
||||
* [具体应用](#具体应用)
|
||||
* [Cookie](#cookie)
|
||||
* [缓存](#缓存)
|
||||
* [持久连接](#持久连接)
|
||||
* [编码](#编码)
|
||||
* [分块传输](#分块传输)
|
||||
* [多部分对象集合](#多部分对象集合)
|
||||
* [范围请求](#范围请求)
|
||||
* [内容协商](#内容协商)
|
||||
* [虚拟主机](#虚拟主机)
|
||||
* [通信数据转发](#通信数据转发)
|
||||
* [HTTPs](#https)
|
||||
* [加密](#加密)
|
||||
* [认证](#认证)
|
||||
* [完整性](#完整性)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
# 基础概念
|
||||
|
||||
## Web基础
|
||||
|
||||
HTTP(HyperText Transfer Protocol,超为本传输协议)。
|
||||
|
||||
WWW(Word Wide Web)的三种技术:HTML、HTTP、URL。
|
||||
|
||||
RFC(Request for Comments,征求修正意见书),互联网的设计文档。
|
||||
|
||||
## URL
|
||||
|
||||
URI(Uniform Resource Indentifier,统一资源标识符),URL(Uniform Resource Locator,统一资源定位符),URN(Uniform Resource Name,统一资源名称),例如 urn:isbn:0-486-27557-4 。URI 包含 URL 和 URN,目前 WEB 只有 URL 比较流行,所以见到的基本都是 URL。
|
||||
|
||||
URL格式:
|
||||
|
||||

|
||||
|
||||
## 请求和响应报文
|
||||
|
||||
**请求报文**
|
||||
|
||||

|
||||
|
||||
**响应报文**
|
||||
|
||||

|
||||
|
||||
# HTTP 方法
|
||||
|
||||
客户端发送的请求报文第一行为请求行,包含了方法字段。
|
||||
|
||||
## GET:获取资源
|
||||
|
||||
## POST:传输实体主体
|
||||
|
||||
POST 主要目的不是获取资源,而是传输实体主体数据。
|
||||
|
||||
GET 和 POST 的请求都能使用额外的参数,但是 GET 的参数是以查询字符串出现在 URL中,而 POST 的参数存储在实体主体部分。
|
||||
|
||||
```
|
||||
GET /test/demo_form.asp?name1=value1&name2=value2 HTTP/1.1
|
||||
```
|
||||
```
|
||||
POST /test/demo_form.asp HTTP/1.1
|
||||
Host: w3schools.com
|
||||
name1=value1&name2=value2
|
||||
```
|
||||
|
||||
GET 的传参方式相比于 POST 安全性较差,因为 GET 传的参数在 URL 是可见的,可能会泄露私密信息。并且 GET 只支持 ASCII 字符,如果参数为中文则可能会出现乱码,而 POST 支持标准字符集。
|
||||
|
||||
## HEAD:获取报文首部
|
||||
|
||||
和 GET 方法一样,但是不返回报文实体主体部分。
|
||||
|
||||
主要用于确认 URL 的有效性以及资源更新的日期时间等。
|
||||
|
||||
## PUT:上传文件
|
||||
|
||||
由于自身不带验证机制,任何人都可以上传文件,因此存在安全性问题,一般 WEB 网站不使用该方法。
|
||||
|
||||
## DELETE:删除文件
|
||||
|
||||
与 PUT 功能相反,并且同样不带验证机制。
|
||||
|
||||
## OPTIONS:查询支持的方法
|
||||
|
||||
查询指定的 URL 能够支持的方法。
|
||||
|
||||
会返回 Allow: GET, POST, HEAD, OPTIONS 这样的内容。
|
||||
|
||||
## RACE:追踪路径
|
||||
|
||||
服务器会将通信路径返回给客户端。
|
||||
|
||||
发送请求时,在 Max-Forwards 首部字段中填入数值,每经过一个服务器就会减 1,当数值为 0 时就停止传输。
|
||||
|
||||
TRACE 一般不会使用,并且它容易受到 XST 攻击(Cross-Site Tracing,跨站追踪),因此更不会去使用它。
|
||||
|
||||

|
||||
|
||||
## CONNECT:要求用隧道协议连接代理
|
||||
|
||||
用隧道协议进行 TCP 通信。
|
||||
|
||||
主要使用 SSL(Secure Sokets Layer,安全套接字)和 TLS(Transport Layer Security,传输层安全)协议把通信内容加密后经网络隧道传输。
|
||||
|
||||

|
||||
|
||||
# HTTP 状态码
|
||||
|
||||
服务器返回的响应报文中第一行为状态行,包含了状态码以及原因短语,来告知客户端请求的结果。
|
||||
|
||||
| 状态码 | 类别 | 原因短语 |
|
||||
| --- | --- | --- |
|
||||
| 1XX | Informational(信息性状态码) | 接收的请求正在处理 |
|
||||
| 2XX | Success(成功状态码) | 请求正常处理完毕 |
|
||||
| 3XX | Redirection(重定向状态码) | 需要进行附加操作以完成请求 |
|
||||
| 4XX | Client Error(客户端错误状态码) | 服务器无法处理请求 |
|
||||
| 5XX | Server Error(服务器错误状态码) | 服务器处理请求出错 |
|
||||
|
||||
## 2XX 成功
|
||||
|
||||
**200 OK**
|
||||
|
||||
**204 No Content**:请求已经成功处理,但是返回的响应报文不包含实体的主体部分。一般在只需要从客户端往服务器发送信息,而不需要返回数据时使用。
|
||||
|
||||
**206 Partial Content**
|
||||
|
||||
## 3XX 重定向
|
||||
|
||||
**301 Moved Permanently**:永久性重定向
|
||||
|
||||
**302 Found**:临时性重定向
|
||||
|
||||
**303 See Other**
|
||||
|
||||
注:虽然 HTTP 协议规定 301、302 状态下重定向时不允许把 POST 方法改成 GET 方法,但是大多数浏览器都会把 301、302 和 303 状态下的重定向把 POST 方法改成 GET 方法。
|
||||
|
||||
**304 Not Modified**:如果请求报文首部包含一些条件,例如:If-Match,If-ModifiedSince,If-None-Match,If-Range,If-Unmodified-Since,但是不满足条件,则服务器会返回 304 状态码。
|
||||
|
||||
**307 Temporary Redirect**:临时重定向,与 302 的含义类似,但是 307 要求浏览器不会把重定向请求的 POST 方法改成 GET 方法。
|
||||
|
||||
## 4XX 客户端错误
|
||||
|
||||
**400 Bad Request**:请求报文中存在语法错误
|
||||
|
||||
**401 Unauthorized**:该状态码表示发送的请求需要有通过 HTTP 认证(BASIC 认证、DIGEST 认证)的认证信息。如果之前已进行过一次请求,则表示用户认证失败。
|
||||
|
||||

|
||||
|
||||
**403 Forbidden**:请求被拒绝,服务器端没有必要给出拒绝的详细理由。
|
||||
|
||||
**404 Not Found**
|
||||
|
||||
## 5XX 服务器错误
|
||||
|
||||
**500 Internal Server Error**:服务器正在执行请求时发生错误
|
||||
|
||||
**503 Service Unavilable**:该状态码表明服务器暂时处于超负载或正在进行停机维护,现在无法处理请求。
|
||||
|
||||
# HTTP首部
|
||||
|
||||
HTTP 报文包含了首部和主体两部分。有 4 种类型的首部字段:通用首部字段、请求首部字段、响应首部字段和实体首部字段。各种首部字段及其含义如下(不需要全记,仅供查阅):
|
||||
|
||||
## 通用首部字段
|
||||
|
||||
| 首部字段名 | 说明 |
|
||||
| -- | -- |
|
||||
| Cache-Control | 控制缓存的行为 |
|
||||
| Connection | 逐跳首部、 连接的管理 |
|
||||
| Date | 创建报文的日期时间 |
|
||||
| Pragma | 报文指令 |
|
||||
| Trailer | 报文末端的首部一览 |
|
||||
| Transfer-Encoding | 指定报文主体的传输编码方式 |
|
||||
| Upgrade | 升级为其他协议 |
|
||||
| Via | 代理服务器的相关信息 |
|
||||
| Warning | 错误通知 |
|
||||
|
||||
## 请求首部字段
|
||||
|
||||
| 首部字段名 | 说明 |
|
||||
| -- | -- |
|
||||
| Accept | 用户代理可处理的媒体类型 |
|
||||
| Accept-Charset | 优先的字符集 |
|
||||
| Accept-Encoding | 优先的内容编码 |
|
||||
| Accept-Language | 优先的语言(自然语言) |
|
||||
| Authorization | Web认证信息 |
|
||||
| Expect | 期待服务器的特定行为 |
|
||||
| From | 用户的电子邮箱地址 |
|
||||
| Host | 请求资源所在服务器 |
|
||||
| If-Match | 比较实体标记(ETag) |
|
||||
| If-Modified-Since | 比较资源的更新时间 |
|
||||
| If-None-Match | 比较实体标记(与 If-Match 相反) |
|
||||
| If-Range | 资源未更新时发送实体 Byte 的范围请求 |
|
||||
| If-Unmodified-Since | 比较资源的更新时间(与If-Modified-Since相反) |
|
||||
| Max-Forwards | 最大传输逐跳数 |
|
||||
| Proxy-Authorization | 代理服务器要求客户端的认证信息 |
|
||||
| Range | 实体的字节范围请求 |
|
||||
| Referer | 对请求中 URI 的原始获取方 |
|
||||
| TE | 传输编码的优先级 |
|
||||
| User-Agent | HTTP 客户端程序的信息 |
|
||||
|
||||
## 响应首部字段
|
||||
|
||||
| 首部字段名 | 说明 |
|
||||
| -- | -- |
|
||||
| Accept-Ranges | 是否接受字节范围请求 |
|
||||
| Age | 推算资源创建经过时间 |
|
||||
| ETag | 资源的匹配信息 |
|
||||
| Location | 令客户端重定向至指定URI |
|
||||
| Proxy-Authenticate | 代理服务器对客户端的认证信息 |
|
||||
| Retry-After | 对再次发起请求的时机要求 |
|
||||
| Server | HTTP服务器的安装信息 |
|
||||
| Vary | 代理服务器缓存的管理信息 |
|
||||
| WWW-Authenticate | 服务器对客户端的认证信息 |
|
||||
|
||||
## 实体首部字段
|
||||
|
||||
| 首部字段名 | 说明 |
|
||||
| -- | -- |
|
||||
| Allow | 资源可支持的HTTP方法 |
|
||||
| Content-Encoding | 实体主体适用的编码方式 |
|
||||
| Content-Language | 实体主体的自然语言 |
|
||||
| Content-Length | 实体主体的大小(单位: 字节) |
|
||||
| Content-Location | 替代对应资源的URI |
|
||||
| Content-MD5 | 实体主体的报文摘要 |
|
||||
| Content-Range | 实体主体的位置范围 |
|
||||
| Content-Type | 实体主体的媒体类型 |
|
||||
| Expires | 实体主体过期的日期时间 |
|
||||
| Last-Modified | 资源的最后修改日期时间 |
|
||||
|
||||
# 具体应用
|
||||
|
||||
## Cookie
|
||||
|
||||
HTTP 协议是无状态的,主要是为了让 HTTP 协议尽可能简单,使得它能够处理大量事务。HTTP/1.1 引入 Cookie 来保存状态信息。
|
||||
|
||||
服务器会发送的响应报文包含 Set-Cookie 字段,客户端得到该相应后把 Cookie 内容保存到浏览器中。下次再发送请求时,从浏览器中读出 Cookie 值,在请求报文中包含 Cookie 字段,这样服务器就知道客户端的状态信息了。Cookie 状态信息保存在客户端浏览器中,而不是服务器上。
|
||||
|
||||

|
||||
|
||||
Set-Cookie 字段有以下属性:
|
||||
|
||||
| 属性 | 说明 |
|
||||
| -- | -- |
|
||||
| NAME=VALUE | 赋予 Cookie 的名称和其值(必需项) |
|
||||
| expires=DATE | Cookie 的有效期(若不明确指定则默认为浏览器关闭前为止) |
|
||||
| path=PATH | 将服务器上的文件目录作为 Cookie 的适用对象(若不指定则默认为文档所在的文件目录) |
|
||||
| domain=域名 | 作为 Cookie 适用对象的域名(若不指定则默认为创建 Cookie 的服务器的域名) |
|
||||
| Secure | 仅在 HTTPS 安全通信时才会发送 Cookie |
|
||||
| HttpOnly | 加以限制,使 Cookie 不能被 JavaScript 脚本访问 |
|
||||
|
||||
**Session 和 Cookie 区别**
|
||||
|
||||
Session 是服务器用来跟踪用户的一种手段,每个 Session 都有一个唯一标识:Session ID。当服务器创建了一个 Session 时,给客户端发送的响应报文就包含了 Set-Cookie 字段,其中有一个名为 sid 的键值对,这个键值对就是 Session ID。客户端收到后就把 Cookie 保存在浏览器中,并且之后发送的请求报文都包含 Session ID。HTTP 就是 Session 和 Cookie 这两种方式一起合作来实现跟踪用户状态的,而 Session 用于服务器端,Cookie 用于客户端。
|
||||
|
||||
**浏览器禁用 Cookie 的情况**
|
||||
|
||||
会使用 URL 重写技术,在 URL 后面加上 sid=xxx 。
|
||||
|
||||
**使用 Cookie 实现用户名和密码的自动填写**
|
||||
|
||||
网站脚本会自动从 Cookie 中读取用户名和密码,从而实现自动填写。
|
||||
|
||||
## 缓存
|
||||
|
||||
有两种缓存方法:让代理服务器进行缓存和让客户端浏览器进行缓存。
|
||||
|
||||
Cache-Control 用于控制缓存的行为。
|
||||
|
||||
Cache-Control: no-cache 有两种含义,如果是客户端向缓存服务器发送的请求报文中含有该指令,表示客户端不想要缓存的资源;如果是源服务器向缓存服务器发送的响应报文中含有该指令,表示缓存服务器不能对资源进行缓存。
|
||||
|
||||
Expires 字段可以用于告知缓存服务器该资源什么时候会过期。当首部字段 Cache-Control 有指定 max-age 指令时,比起首部字段 Expires,会优先处理 max-age 指令。
|
||||
|
||||
## 持久连接
|
||||
|
||||
当浏览器访问一个包含多张图片的 HTML 页面时,除了请求访问 HTML 页面资源,还会请求图片资源,如果每进行一次 HTTP 通信就要断开一次 TCP 连接,连接建立和断开的开销会很大。**持久连接** 只需要进行一次 TCP 连接就能进行多次 HTTP 通信。HTTP/1.1开始,所有的连接默认都是持久连接。
|
||||
|
||||

|
||||
|
||||
持久连接需要使用 Connection 首部字段进行管理。HTTP/1.1 开始HTTP 默认是持久化连接的,如果要断开 TCP 连接,需要由客户端或者服务器端提出断开,使用 Connection: close ;而在HTTP/1.1之前默认是非持久化连接的,如果要维持持续连接,需要使用 Keep-Alive。
|
||||
|
||||
管线化方式可以同时发送多个请求和响应,而不需要发送一个请求然后等待响应之后再发下一个请求。
|
||||
|
||||

|
||||
|
||||
## 编码
|
||||
|
||||
编码(Encoding)主要是为了对实体进行压缩。常用的编码有:gzip、compress、deflate、identity,其中 identity 表示不执行压缩的编码格式。
|
||||
|
||||
## 分块传输
|
||||
|
||||
分块传输(Chunked Transfer Coding)可以把数据分割成多块,让浏览器逐步显示页面。
|
||||
|
||||
## 多部分对象集合
|
||||
|
||||
一份报文主体内可含有多类型的实体同时发送,每个部分之间用 boundary 字段定义的分隔符进行分隔;每个部分都可以有首部字段。
|
||||
|
||||
例如,上传多个表单时可以使用如下方式:
|
||||
|
||||

|
||||
|
||||
## 范围请求
|
||||
|
||||
如果网络出现中断,服务器只发送了一部分数据,范围请求使得客户端能够只请求未发送的那部分数据,从而避免服务器端重新发送所有数据。
|
||||
|
||||
在请求报文首部中添加 Range 字段,然后指定请求的范围,例如 Range : bytes = 5001-10000。请求成功的话服务器发送 206 Partial Content 状态。
|
||||
|
||||
## 内容协商
|
||||
|
||||
通过内容协商返回最合适的内容,例如根据浏览器的默认语言选择返回中文界面还是英文界面。
|
||||
|
||||
涉及以下首部字段:Accept、Accept-Charset、Accept-Encoding、Accept-Language、Content-Language。
|
||||
|
||||
## 虚拟主机
|
||||
|
||||
使用虚拟主机技术,使得一台服务器拥有多个域名,并且在逻辑上可以看成多个服务器。
|
||||
|
||||
## 通信数据转发
|
||||
|
||||
**代理**
|
||||
|
||||
代理服务器接受客户端的请求,并且转发给其它服务器。代理服务器一般是透明的,不会改变 URL。
|
||||
|
||||
使用代理的主要目的是:缓存、网络访问控制以及记录访问日志。
|
||||
|
||||

|
||||
|
||||
**网关**
|
||||
|
||||
与代理服务器不同的是,网关服务器会将 HTTP 转化为其它协议进行通信,从而其它非 HTTP 服务器的服务。
|
||||
|
||||

|
||||
|
||||
**隧道**
|
||||
|
||||
使用 SSL 等加密手段,为客户端和服务器之间建立一条安全的通信线路。
|
||||
|
||||

|
||||
|
||||
# HTTPs
|
||||
|
||||
HTTP 有以下安全性问题:
|
||||
|
||||
1. 通信使用明文,内容可能会被窃听;
|
||||
2. 不验证通信方的身份,因此有可能遭遇伪装;
|
||||
3. 无法证明报文的完整性,所以有可能已遭篡改。
|
||||
|
||||
HTTPs 并不是新协议,而是 HTTP 先和 SSL(Secure Socket Layer)通信,再由 SSL 和 TCP 通信。通过使用 SSL,HTTPs 提供了加密、认证和完整性保护。
|
||||
|
||||
## 加密
|
||||
|
||||
有两种加密方式:对称密钥加密和公开密钥加密。对称密钥加密的加密和解密使用同一密钥,而公开密钥加密使用一对密钥用于加密和解密,分别为公开密钥和私有密钥。公开密钥所有人都可以获得,通信发送方获得接收方的公开密钥之后,就可以使用公开密钥进行加密,接收方收到通信内容后使用私有密钥解密。
|
||||
|
||||
对称密钥加密的缺点:无法安全传输密钥;公开密钥加密的缺点:相对来说更耗时。
|
||||
|
||||
HTTPs 采用 **混合的加密机制**,使用公开密钥加密用于传输对称密钥,之后使用对称密钥加密进行通信。(下图中,共享密钥即对称密钥)
|
||||
|
||||

|
||||
|
||||
## 认证
|
||||
|
||||
通过使用 **证书** 来对通信方进行认证。证书中有公开密钥数据,如果可以验证公开密钥的确属于通信方的,那么就可以确定通信方是可靠的。
|
||||
|
||||
数字证书认证机构(CA,Certificate
|
||||
Authority)颁发的公开密钥证书,可以通过 CA 对其进行验证。
|
||||
|
||||
进行 HTTPs 通信时,服务器会把证书发送给客户端,客户端取得其中的公开密钥之后,就可以开始加密过程。
|
||||
|
||||
使用 OpenSSL 这套开源程序,每个人都可以构建一套属于自己的认证机构,从而自己给自己颁发服务器证书。浏览器在访问该服务器时,会显示“无法确认连接安全性”或“该网站的安全证书存在问题”等警告消息。
|
||||
|
||||
客户端证书需要用户自行安装,只有在业务需要非常高安全性时才使用客户端证书,例如网上银行。
|
||||
|
||||
## 完整性
|
||||
|
||||
SSL 提供摘要功能来验证完整性。
|
||||
|
||||
673
notes/JVM.md
Normal file
673
notes/JVM.md
Normal file
@ -0,0 +1,673 @@
|
||||
<!-- GFM-TOC -->
|
||||
* [内存模型](#内存模型)
|
||||
* [1. 程序计数器](#1-程序计数器)
|
||||
* [2. Java 虚拟机栈](#2-java-虚拟机栈)
|
||||
* [3. 本地方法栈](#3-本地方法栈)
|
||||
* [4. Java 堆](#4-java-堆)
|
||||
* [5. 方法区](#5-方法区)
|
||||
* [6. 运行时常量池](#6-运行时常量池)
|
||||
* [7. 直接内存](#7-直接内存)
|
||||
* [垃圾收集](#垃圾收集)
|
||||
* [1. 判断一个对象是否可回收](#1-判断一个对象是否可回收)
|
||||
* [1.1 引用计数](#11-引用计数)
|
||||
* [1.2 可达性](#12-可达性)
|
||||
* [1.3 引用类型](#13-引用类型)
|
||||
* [1.3.1 强引用](#131-强引用)
|
||||
* [1.3.2 软引用](#132-软引用)
|
||||
* [1.3.3 弱引用](#133-弱引用)
|
||||
* [1.3.4 虚引用](#134-虚引用)
|
||||
* [1.3 方法区的回收](#13-方法区的回收)
|
||||
* [1.4 finalize()](#14-finalize)
|
||||
* [2. 垃圾收集算法](#2-垃圾收集算法)
|
||||
* [2.1 标记 - 清除算法](#21-标记---清除算法)
|
||||
* [2.2 复制算法](#22-复制算法)
|
||||
* [2.3 标记 - 整理算法](#23-标记---整理算法)
|
||||
* [2.4 分代收集算法](#24-分代收集算法)
|
||||
* [3. 垃圾收集器](#3-垃圾收集器)
|
||||
* [3.1 Serial 收集器](#31-serial-收集器)
|
||||
* [3.2 ParNew 收集器](#32-parnew-收集器)
|
||||
* [3.3 Parallel Scavenge 收集器](#33-parallel-scavenge-收集器)
|
||||
* [3.4 Serial Old 收集器](#34-serial-old-收集器)
|
||||
* [3.5 Parallel Old 收集器](#35-parallel-old-收集器)
|
||||
* [3.6 CMS 收集器](#36-cms-收集器)
|
||||
* [3.7 G1 收集器](#37-g1-收集器)
|
||||
* [3.8 七种垃圾收集器的比较](#38-七种垃圾收集器的比较)
|
||||
* [4. 内存分配与回收策略](#4-内存分配与回收策略)
|
||||
* [4.1 优先在 Eden 分配](#41-优先在-eden-分配)
|
||||
* [4.2 大对象直接进入老年代](#42-大对象直接进入老年代)
|
||||
* [4.3 长期存活的对象进入老年代](#43-长期存活的对象进入老年代)
|
||||
* [4.4 动态对象年龄判定](#44-动态对象年龄判定)
|
||||
* [4.5 空间分配担保](#45-空间分配担保)
|
||||
* [4.6 Full GC 的触发条件](#46-full-gc-的触发条件)
|
||||
* [4.6.1 调用 System.gc()](#461-调用-systemgc)
|
||||
* [4.6.2 老年代空间不足](#462-老年代空间不足)
|
||||
* [4.6.3 空间分配担保失败](#463-空间分配担保失败)
|
||||
* [4.6.4 JDK 1.7 及以前的永久代空间不足](#464-jdk-17-及以前的永久代空间不足)
|
||||
* [4.6.5 Concurrent Mode Failure](#465-concurrent-mode-failure)
|
||||
* [类加载机制](#类加载机制)
|
||||
* [1 类的生命周期](#1-类的生命周期)
|
||||
* [2. 类初始化时机](#2-类初始化时机)
|
||||
* [3. 类加载过程](#3-类加载过程)
|
||||
* [3.1 加载](#31-加载)
|
||||
* [3.2 验证](#32-验证)
|
||||
* [3.3 准备](#33-准备)
|
||||
* [3.4 解析](#34-解析)
|
||||
* [3.5 初始化](#35-初始化)
|
||||
* [4. 类加载器](#4-类加载器)
|
||||
* [4.1 类与类加载器](#41-类与类加载器)
|
||||
* [4.2 类加载器分类](#42-类加载器分类)
|
||||
* [4.3 双亲委派模型](#43-双亲委派模型)
|
||||
* [JVM 参数](#jvm-参数)
|
||||
* [GC 优化配置](#gc-优化配置)
|
||||
* [GC 类型设置](#gc-类型设置)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
# 内存模型
|
||||
|
||||

|
||||
|
||||
注:白色区域为线程私有的,蓝色区域为线程共享的。
|
||||
|
||||
## 1. 程序计数器
|
||||
|
||||
记录正在执行的虚拟机字节码指令的地址(如果正在执行的是 Native 方法则为空)。
|
||||
|
||||
## 2. Java 虚拟机栈
|
||||
|
||||
每个 Java 方法在执行的同时会创建一个栈帧用于存储局部变量表、操作数栈、动态链接、方法出口等信息。每一个方法从调用直至执行完成的过程,就对应着一个栈帧在 Java 虚拟机栈中入栈和出栈的过程。
|
||||
|
||||
该区域可能抛出以下异常:
|
||||
|
||||
1. 当线程请求的栈深度超过最大值,会抛出 StackOverflowError 异常;
|
||||
2. 栈进行动态扩展时如果无法申请导足够内存,会抛出 OutOfMemoryError 异常。
|
||||
|
||||
## 3. 本地方法栈
|
||||
|
||||
与 Java 虚拟机栈类似,它们之间的区别只不过是本地方法栈为本地方法服务。
|
||||
|
||||
## 4. Java 堆
|
||||
|
||||
所有对象实例都在这里分配内存。
|
||||
|
||||
这块区域是垃圾收集器管理的主要区域("GC 堆 ")。现在收集器基本都是采用分代收集算法,Java 堆还可以分成:新生代和老年代(新生代还可以分成 Eden 空间、From Survivor 空间、To Survivor 空间等)。
|
||||
|
||||
不需要连续内存,可以通过 -Xmx 和 -Xms 来控制动态扩展内存大小,如果动态扩展失败会抛出 OutOfMemoryError 异常。
|
||||
|
||||
## 5. 方法区
|
||||
|
||||
用于存放已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
|
||||
|
||||
和 Java 堆一样不需要连续的内存,并且可以动态扩展,动态扩展失败一样会抛出 OutOfMemoryError 异常。
|
||||
|
||||
对这块区域进行垃圾回收的主要目标是对常量池的回收和对类的卸载,但是一般比较难实现,HotSpot 虚拟机把它当成永久代来进行垃圾回收。
|
||||
|
||||
## 6. 运行时常量池
|
||||
|
||||
运行时常量池是方法区的一部分。
|
||||
|
||||
类加载后,Class 文件中的常量池(用于存放编译期生成的各种字面量和符号引用)就会被放到这个区域。
|
||||
|
||||
在运行期间也可以用过 String 类的 intern() 方法将新的常量放入该区域。
|
||||
|
||||
## 7. 直接内存
|
||||
|
||||
在 JDK 1.4 中新加入了 NIO 类,引入了一种基于通道(Channel)与缓冲区(Buffer)的 I/O 方式,它可以使用 Native 函数库直接分配堆外内存,然后通过一个存储在 Java 堆里的 DirectByteBuffer 对象作为这块内存的引用进行操作。这样能在一些场景中显著提高性能,因为避免了在 Java 堆和 Native 堆中来回复制数据。
|
||||
|
||||
# 垃圾收集
|
||||
|
||||
程序计数器、虚拟机栈和本地方法栈这三个区域属于线程私有的,只存在于线程的生命周期内,线程结束之后也会消失,因此不需要对这三个区域进行垃圾回收。
|
||||
|
||||
垃圾回收主要是针对 Java 堆和方法区进行。
|
||||
|
||||
## 1. 判断一个对象是否可回收
|
||||
|
||||
### 1.1 引用计数
|
||||
|
||||
给对象添加一个引用计数器,当对象增加一个引用时计数器加 1,引用失效时计数器减 1。
|
||||
|
||||
引用计数为 0 的对象可被回收。
|
||||
|
||||
两个对象会出现循环引用问题,此时引用计数器永远不为 0,导致 GC 收集器无法回收。
|
||||
|
||||
```java
|
||||
objA.instance = objB;
|
||||
objB.instance = objA;
|
||||
```
|
||||
|
||||
### 1.2 可达性
|
||||
|
||||
通过 GC Roots 作为起始点进行搜索,能够到达到的对象都是都是可用的,不可达的对象可被回收。
|
||||
|
||||
GC Roots 一般包含以下内容:
|
||||
|
||||
1. 虚拟机栈中引用的对象
|
||||
2. 方法区中类静态属性引用的对象
|
||||
3. 方法区中的常量引用的对象
|
||||
4. 本地方法栈中引用的对象
|
||||
|
||||
### 1.3 引用类型
|
||||
|
||||
无论是通过引用计算算法判断对象的引用数量,还是通过可达性分析算法判断对象的引用链是否可达,判定独享是否存活都与“引用”有关。
|
||||
|
||||
#### 1.3.1 强引用
|
||||
|
||||
只要强引用存在,垃圾回收器永远不会回收调掉被引用的对象。
|
||||
|
||||
```java
|
||||
Object obj = new Object();
|
||||
```
|
||||
|
||||
#### 1.3.2 软引用
|
||||
|
||||
|
||||
非必须引用,内存溢出之前进行回收。
|
||||
|
||||
```java
|
||||
Object obj = new Object();
|
||||
SoftReference<Object> sf = new SoftReference<Object>(obj);
|
||||
obj = null;
|
||||
sf.get();
|
||||
```
|
||||
|
||||
sf 是对 obj 的一个软引用,通过 sf.get() 方法可以取到这个对象,当然,当这个对象被标记为需要回收的对象时,则返回 null;
|
||||
|
||||
软引用主要用户实现类似缓存的功能,在内存足够的情况下直接通过软引用取值,无需从繁忙的真实来源查询数据,提升速度;当内存不足时,自动删除这部分缓存数据,从真正的来源查询这些数据。
|
||||
|
||||
|
||||
#### 1.3.3 弱引用
|
||||
|
||||
只能生存到下一次垃圾收集发生之前,当垃圾收集器工作时,无论当前内存是否足够,都会被回收。
|
||||
|
||||
```java
|
||||
Object obj = new Object();
|
||||
WeakReference<Object> wf = new WeakReference<Object>(obj);
|
||||
obj = null;
|
||||
wf.get();
|
||||
wf.isEnQueued();
|
||||
```
|
||||
|
||||
#### 1.3.4 虚引用
|
||||
|
||||
又称为幽灵引用或者幻影引用,一个对象是否有虚引用的存在,完全不会对其生存时间构成影响,也无法通过虚引用取得一个对象实例。为一个对象设置虚引用关联的唯一目的就是能在这个对象被收集器回收时收到一个系统通知。
|
||||
|
||||
```java
|
||||
Object obj = new Object();
|
||||
PhantomReference<Object> pf = new PhantomReference<Object>(obj);
|
||||
obj=null;
|
||||
pf.get();
|
||||
pf.isEnQueued();
|
||||
```
|
||||
|
||||
### 1.3 方法区的回收
|
||||
|
||||
在方法区主要是对常量池的回收和对类的卸载。
|
||||
|
||||
常量池的回收和堆中对象回收类似。
|
||||
|
||||
类的卸载条件很多,需要满足以下三个条件,并且满足了也不一定会被卸载:
|
||||
|
||||
1. 该类所有的实例都已经被回收,也就是 Java 堆中不存在该类的任何实例。
|
||||
2. 加载该类的 ClassLoader 已经被回收。
|
||||
3. 该类对应的 java.lang.Class 对象没有在任何地方被引用,也就无法在任何地方通过反射访问该类方法。
|
||||
|
||||
可以通过 -Xnoclassgc 参数来控制是否对类进行卸载。
|
||||
|
||||
在大量使用反射、动态代理、CGLib 等 ByteCode 框架、动态生成 JSP 以及 OSGo 这类频繁自定义 ClassLoader 的场景都需要虚拟机具备类卸载功能,以保证不会出现内存溢出。
|
||||
|
||||
### 1.4 finalize()
|
||||
|
||||
当一个对象可被回收时,如果该对象有必要执行 finalize() 方法,那么就有可能可能通过在该方法中让对象重新被引用,从而实现自救。
|
||||
|
||||
finalize() 类似 C++ 的虚构函数,用来做关闭外部资源等工作。但是 try-finally 等方式可以做的更好,并且该方法运行代价高昂,不确定性大,无法保证各个对象的调用顺序,因此最好不要使用。
|
||||
|
||||
## 2. 垃圾收集算法
|
||||
|
||||
### 2.1 标记 - 清除算法
|
||||
|
||||

|
||||
|
||||
将需要回收的对象进行标记,然后清除。
|
||||
|
||||
不足:
|
||||
|
||||
1. 标记和清除过程效率都不高
|
||||
2. 会产生大量碎片
|
||||
|
||||
之后的算法都是基于该算法进行改进。
|
||||
|
||||
### 2.2 复制算法
|
||||
|
||||

|
||||
|
||||
将内存划分为大小相等的两块,每次只使用其中一块,当这一块内存用完了就将还存活的对象复制到另一块上面,然后再把使用过的内存空间进行一次清理。
|
||||
|
||||
主要不足是只使用了内存的一半。
|
||||
|
||||
现在的商业虚拟机都采用这种收集算法来回收新生代,但是并不是将内存划分为大小相等的两块,而是分为一块较大的 Eden 空间和两块较小的 Survior 空间,每次使用 Eden 空间和其中一块 Survivor。在回收时,将 Eden 和 Survivor 中还存活着的对象一次性复制到另一块 Survivor 空间上,最后清理 Eden 和 Survivor。HotSpot 虚拟机的 Eden 和 Survivor 的大小比例默认为 8:1,保证了内存的利用率达到 90 %。如果每次回收有多于 10% 的对象存活,那么一块 Survivor 空间就不够用了,需要依赖于老年代进行分配担保,也就是借用老年代的空间。
|
||||
|
||||
### 2.3 标记 - 整理算法
|
||||
|
||||

|
||||
|
||||
让所有存活的对象都向一段移动,然后直接清理掉端边界以外的内存。
|
||||
|
||||
### 2.4 分代收集算法
|
||||
|
||||
现在的商业虚拟机采用分代收集算法,它使用了前面介绍的几种收集算法,根据对象存活周期将内存划分为几块,不同块采用适当的收集算法。
|
||||
|
||||
一般将 Java 堆分为新生代和老年代。
|
||||
|
||||
1. 新生代使用:复制算法
|
||||
2. 老年代使用:标记 - 清理 或者 标记 - 整理 算法。
|
||||
|
||||
## 3. 垃圾收集器
|
||||
|
||||

|
||||
|
||||
以上是 HotSpot 虚拟机中的 7 个垃圾收集器,连线表示垃圾收集器可以配合使用。
|
||||
|
||||
### 3.1 Serial 收集器
|
||||
|
||||

|
||||
|
||||
它是单线程的收集器,不仅意味着只会使用一个线程进行垃圾收集工作,更重要的是它在进行垃圾收集时,必须暂停所有其他工作线程,往往造成过长的等待时间。
|
||||
|
||||
它的优点是简单高效,对于单个 CPU 环境来说,由于没有线程交互的开销,因此拥有最高的单线程收集效率。
|
||||
|
||||
在 Client 应用场景中,分配给虚拟机管理的内存一般来说不会很大,该收集器收集几十兆甚至一两百兆的新生代停顿时间可以控制在一百多毫秒以内,只要不是太频繁,这点停顿是可以接受的。
|
||||
|
||||
### 3.2 ParNew 收集器
|
||||
|
||||

|
||||
|
||||
它是 Serial 收集器的多线程版本。
|
||||
|
||||
是 Server 模式下的虚拟机首选新生代收集器,除了性能原因外,主要是因为除了 Serial 收集器,只有它能与 CMS 收集器配合工作。
|
||||
|
||||
默认开始的线程数量与 CPU 数量相同,可以使用 -XX:ParallelGCThreads 参数来设置线程数。
|
||||
|
||||
### 3.3 Parallel Scavenge 收集器
|
||||
|
||||
是并行的多线程收集器。
|
||||
|
||||
其它收集器关注点是尽可能缩短垃圾收集时用户线程的停顿时间,而它的目标是达到一个可控制的吞吐量,它被称为“吞吐量优先”收集器。这里的吞吐量指 CPU 用于运行用户代码的时间占总时间的比值。
|
||||
|
||||
停顿时间越短就越适合需要与用户交互的程序,良好的响应速度能提升用户体验。而高吞吐量则可以高效率地利用 CPU 时间,尽快完成程序的运算任务,主要适合在后台运算而不需要太多交互的任务。
|
||||
|
||||
提供了两个参数用于精确控制吞吐量,分别是控制最大垃圾收集停顿时间 -XX:MaxGCPauseMillis 参数以及直接设置吞吐量大小的 -XX:GCTimeRatio 参数(值为大于 0 且小于 100 的整数)。缩短停顿时间是以牺牲吞吐量和新生代空间来换取的:新生代空间变小,垃圾回收变得频繁,导致吞吐量下降。
|
||||
|
||||
还提供了一个参数 -XX:+UseAdaptiveSizePolicy,这是一个开关参数,打开参数后,就不需要手工指定新生代的大小(-Xmn)、Eden 和 Survivor 区的比例(-XX:SurvivorRatio)、晋升老年代对象年龄(-XX:PretenureSizeThreshold)等细节参数了,虚拟机会根据当前系统的运行情况收集性能监控信息,动态调整这些参数以提供最合适的停顿时间或者最大的吞吐量,这种方式称为 GC 自适应的调节策略(GC Ergonomics)。自适应调节策略也是它与 ParNew 收集器的一个重要区别。
|
||||
|
||||
### 3.4 Serial Old 收集器
|
||||
|
||||

|
||||
|
||||
Serial Old 是 Serial 收集器的老年代版本,也是给 Client 模式下的虚拟机使用。如果用在 Server 模式下,它有两大用途:
|
||||
|
||||
1. 在 JDK 1.5 以及之前版本(Parallel Old 诞生以前)中与 Parallel Scavenge 收集器搭配使用。
|
||||
2. 作为 CMS 收集器的后备预案,在并发收集发生 Concurrent Mode Failure 时使用。
|
||||
|
||||
### 3.5 Parallel Old 收集器
|
||||
|
||||

|
||||
|
||||
是 Parallel Scavenge 收集器的老年代版本。
|
||||
|
||||
在注重吞吐量以及 CPU 资源敏感的场合,都可以优先考虑 Parallel Scavenge 加 Parallel Old 收集器。
|
||||
|
||||
### 3.6 CMS 收集器
|
||||
|
||||

|
||||
|
||||
CMS(Concurrent Mark Sweep),从 Mark Sweep 可以知道它是基于 标记 - 清除 算法实现的。
|
||||
|
||||
特点:并发收集、低停顿。
|
||||
|
||||
分为以下四个流程:
|
||||
|
||||
1. 初始标记:仅仅只是标记一下 GC Roots 能直接关联到的对象,速度很快,需要停顿。
|
||||
2. 并发标记:进行 GC Roots Tracing 的过程,它在整个回收过程中耗时最长,不需要停顿。
|
||||
3. 重新标记:为了修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,需要停顿。
|
||||
4. 并发清除:不需要停顿。
|
||||
|
||||
在整个过程中耗时最长的并发标记和并发清除过程中,收集器线程都可以与用户线程一起工作,不需要进行停顿。
|
||||
|
||||
具有以下缺点:
|
||||
|
||||
1. 对 CPU 资源敏感。CMS 默认启动的回收线程数是 (CPU 数量 + 3) / 4,当 CPU 不足 4 个时,CMS 对用户程序的影响就可能变得很大,如果本来 CPU 负载就比较大,还要分出一半的运算能力去执行收集器线程,就可能导致用户程序的执行速度忽然降低了 50%,其实也让人无法接受。并且低停顿时间是以牺牲吞吐量为代价的,导致 CPU 利用率变低。
|
||||
|
||||
2. 无法处理浮动垃圾。由于并发清理阶段用户线程还在运行着,伴随程序运行自然就还会有新的垃圾不断产生。这一部分垃圾出现在标记过程之后,CMS 无法在当次收集中处理掉它们,只好留到下一次 GC 时再清理掉,这一部分垃圾就被称为“浮动垃圾”。也是由于在垃圾收集阶段用户线程还需要运行,那也就还需要预留有足够的内存空间给用户线程使用,因此它不能像其他收集器那样等到老年代几乎完全被填满了再进行收集,需要预留一部分空间提供并发收集时的程序运作使用。可以使用 -XX:CMSInitiatingOccupancyFraction 的值来改变触发收集器工作的内存占用百分比,JDK 1.5 默认设置下该值为 68,也就是当老年代使用了 68% 的空间之后会触发收集器工作。如果该值设置的太高,导致浮动垃圾无法保存,那么就会出现 Concurrent Mode Failure,此时虚拟机将启动后备预案:临时启用 Serial Old 收集器来重新进行老年代的垃圾收集。
|
||||
|
||||
3. 标记 - 清除算法导致的空间碎片,给大对象分配带来很大麻烦,往往出现老年代空间剩余,但无法找到足够大连续空间来分配当前对象,不得不提前出发一次 Full GC。
|
||||
|
||||
### 3.7 G1 收集器
|
||||
|
||||

|
||||
|
||||
G1(Garbage-First)收集器是当今收集器技术发展最前沿的成果之一,它是一款面向服务端应用的垃圾收集器,HotSpot 开发团队赋予它的使命是(在比较长期的)未来可以替换掉 JDK 1.5 中发布的 CMS 收集器。
|
||||
|
||||
具备如下特点:
|
||||
|
||||
- 并行与并发:能充分利用多 CPU 环境下的硬件优势,使用多个 CPU 来缩短停顿时间;
|
||||
- 分代收集:分代概念依然得以保留,虽然它不需要其它收集器配合就能独立管理整个 GC 堆,但它能够采用不同方式去处理新创建的对象和已存活一段时间、熬过多次 GC 的旧对象来获取更好的收集效果。
|
||||
- 空间整合:整体来看是基于“标记 - 整理”算法实现的收集器,从局部(两个 Region 之间)上来看是基于“复制”算法实现的,这意味着运行期间不会产生内存空间碎片。
|
||||
- 可预测的停顿:这是它相对 CMS 的一大优势,降低停顿时间是 G1 和 CMS 共同的关注点,但 G1 除了降低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为 M 毫秒的时间片段内,消耗在 GC 上的时间不得超过 N 毫秒,这几乎已经是实时 Java(RTSJ)的垃圾收集器的特征了。
|
||||
|
||||
在 G1 之前的其他收集器进行收集的范围都是整个新生代或者老生代,而 G1 不再是这样,Java 堆的内存布局与其他收集器有很大区别,将整个 Java 堆划分为多个大小相等的独立区域(Region)。虽然还保留新生代和老年代的概念,但新生代和老年代不再是物理隔离的了,而都是一部分 Region(不需要连续)的集合。
|
||||
|
||||
之所以能建立可预测的停顿时间模型,是因为它可以有计划地避免在整个 Java 堆中进行全区域的垃圾收集。它跟踪各个 Region 里面的垃圾堆积的价值大小(回收所获得的空间大小以及回收所需时间的经验值),在后台维护一个优先列表,每次根据允许的收集时间,优先回收价值最大的 Region(这也就是 Garbage-First 名称的来由)。这种使用 Region 划分内存空间以及有优先级的区域回收方式,保证了它在有限的时间内可以获取尽可能高的收集效率。
|
||||
|
||||
Region 不可能是孤立的,一个对象分配在某个 Region 中,可以与整个 Java 堆任意的对象发生引用关系。在做可达性分析确定对象是否存活的时候,需要扫描整个 Java 堆才能保证准确性,这显然是对 GC 效率的极大伤害。为了避免全堆扫描的发生,每个 Region 都维护了一个与之对应的 Remembered Set。虚拟机发现程序在对 Reference 类型的数据进行写操作时,会产生一个 Write Barrier 暂时中断写操作,检查 Reference 引用的对象是否处于不同的 Region 之中,如果是,便通过 CardTable 把相关引用信息记录到被引用对象所属的 Region 的 Remembered Set 之中。当进行内存回收时,在 GC 根节点的枚举范围中加入 Remembered Set 即可保证不对全堆扫描也不会有遗漏。
|
||||
|
||||
如果不计算维护 Remembered Set 的操作,G1 收集器的运作大致可划分为以下几个步骤:
|
||||
|
||||
1. 初始标记
|
||||
2. 并发标记
|
||||
3. 最终标记:为了修正在并发标记期间因用户程序继续运作而导致标记产生变动的那一部分标记记录,虚拟机将这段时间对象变化记录在线程的 Remembered Set Logs 里面,最终标记阶段需要把 Remembered Set Logs 的数据合并到 Remembered Set 中。这阶段需要停顿线程,但是可并行执行。
|
||||
4. 筛选回收:首先对各个 Region 中的回收价值和成本进行排序,根据用户所期望的 GC 停顿是时间来制定回收计划。此阶段其实也可以做到与用户程序一起并发执行,但是因为只回收一部分 Region,时间是用户可控制的,而且停顿用户线程将大幅度提高收集效率。
|
||||
|
||||
### 3.8 七种垃圾收集器的比较
|
||||
|
||||
| 收集器 | 串行、并行 or 并发 | 新生代 / 老年代 | 算法 | 目标 | 适用场景 |
|
||||
| --- | --- | --- | --- | --- | --- |
|
||||
| **Serial** | 串行 | 新生代 | 复制算法 | 响应速度优先 | 单 CPU 环境下的 Client 模式 |
|
||||
| **Serial Old** | 串行 | 老年代 | 标记 - 整理 | 响应速度优先 | 单 CPU 环境下的 Client 模式、CMS 的后备预案 |
|
||||
| **ParNew** | 并行 | 新生代 | 复制算法 | 响应速度优先 | 多 CPU 环境时在 Server 模式下与 CMS 配合 |
|
||||
| **Parallel Scavenge** | 并行 | 新生代 | 复制算法 | 吞吐量优先 | 在后台运算而不需要太多交互的任务 |
|
||||
| **Parallel Old** | 并行 | 老年代 | 标记 - 整理 | 吞吐量优先 | 在后台运算而不需要太多交互的任务 |
|
||||
| **CMS** | 并发 | 老年代 | 标记 - 清除 | 响应速度优先 | 集中在互联网站或 B/S 系统服务端上的 Java 应用 |
|
||||
| **G1** | 并发 | both | 标记 - 整理 + 复制算法 | 响应速度优先 | 面向服务端应用,将来替换 CMS |
|
||||
|
||||
## 4. 内存分配与回收策略
|
||||
|
||||
### 4.1 优先在 Eden 分配
|
||||
|
||||
大多数情况下,对象在新生代 Eden 区分配,当 Eden 区空间不够时,发起 Minor GC;
|
||||
|
||||
### 4.2 大对象直接进入老年代
|
||||
|
||||
提供 -XX:PretenureSizeThreshold 参数,大于此值的对象直接在老年代分配,避免在 Eden 区和 Survivor 区之间的大量内存复制;
|
||||
### 4.3 长期存活的对象进入老年代
|
||||
|
||||
JVM 为对象定义年龄计数器,经过 Minor GC 依然存活且被 Survivor 区容纳的,移动到 Survivor 区,年龄加 1,每经历一次 Minor GC 不被清理则年龄加 1,增加到一定年龄则移动到老年区(默认 15 岁,通过 -XX:MaxTenuringThreshold 设置);
|
||||
|
||||
|
||||
### 4.4 动态对象年龄判定
|
||||
|
||||
若 Survivor 区中同年龄所有对象大小总和大于 Survivor 空间一半,则年龄大于等于该年龄的对象可以直接进入老年代;
|
||||
|
||||
### 4.5 空间分配担保
|
||||
|
||||
在发生 Minor GC 之前,JVM 先检查老年代最大可用连续空间是否大于新生代所有对象总空间,成立的话 Minor GC 确认是安全的;否则继续检查老年代最大可用连续空间是否大于历次晋升到老年代对象的平均大小,大于的话进行 Minor GC,小于的话进行 Full GC。
|
||||
|
||||
## 4.6 Full GC 的触发条件
|
||||
|
||||
对于 Minor GC,其触发条件非常简单,当 Eden 区空间满时,就将触发一次 Minor GC。而 Full GC 则相对复杂,有以下条件:
|
||||
|
||||
### 4.6.1 调用 System.gc()
|
||||
|
||||
此方法的调用是建议 JVM 进行 Full GC,虽然只是建议而非一定,但很多情况下它会触发 Full GC,从而增加 Full GC 的频率,也即增加了间歇性停顿的次数。因此强烈建议能不使用此方法就不要使用,让虚拟机自己去管理它的内存,可通过 -XX:+ DisableExplicitGC 来禁止 RMI 调用 System.gc()。
|
||||
|
||||
### 4.6.2 老年代空间不足
|
||||
|
||||
老年代空间不足的常见场景为前文所讲的大对象直接进入老年代、长期存活的对象进入老年代等,当执行 Full GC 后空间仍然不足,则抛出如下错误: Java.lang.OutOfMemoryError: Java heap space 为避免以上两种状况引起的 Full GC,调优时应尽量做到让对象在 Minor GC 阶段被回收、让对象在新生代多存活一段时间及不要创建过大的对象及数组。
|
||||
|
||||
### 4.6.3 空间分配担保失败
|
||||
|
||||
使用复制算法的 Minor GC 需要老年代的内存空间作担保,如果出现了 HandlePromotionFailure 担保失败,则会触发 Full GC。
|
||||
|
||||
### 4.6.4 JDK 1.7 及以前的永久代空间不足
|
||||
|
||||
在 JDK 1.7 及以前,HotSpot 虚拟机中的方法区是用永久代实现的,永久代中存放的为一些 class 的信息、常量、静态变量等数据,当系统中要加载的类、反射的类和调用的方法较多时,Permanet Generation 可能会被占满,在未配置为采用 CMS GC 的情况下也会执行 Full GC。如果经过 Full GC 仍然回收不了,那么 JVM 会抛出如下错误信息:java.lang.OutOfMemoryError: PermGen space 为避免 PermGen 占满造成 Full GC 现象,可采用的方法为增大 PermGen 空间或转为使用 CMS GC。
|
||||
|
||||
在 JDK 1.8 中用元空间替换了永久代作为方法区的实现,元空间是本地内存,因此减少了一种 Full GC 触发的可能性。
|
||||
|
||||
### 4.6.5 Concurrent Mode Failure
|
||||
|
||||
执行 CMS GC 的过程中同时有对象要放入老年代,而此时老年代空间不足(有时候“空间不足”是 CMS GC 时当前的浮动垃圾过多导致暂时性的空间不足触发 Full GC),便会报 Concurrent Mode Failure 错误,并触发 Full GC。
|
||||
|
||||
# 类加载机制
|
||||
|
||||
类是在运行期间动态加载的。
|
||||
|
||||
## 1 类的生命周期
|
||||
|
||||

|
||||
|
||||
包括以下 7 个阶段:
|
||||
|
||||
- **加载(Loading)**
|
||||
- **验证(Verification)**
|
||||
- **准备(Preparation)**
|
||||
- **解析(Resolution)**
|
||||
- **初始化(Initialization)**
|
||||
- 使用(Using)
|
||||
- 卸载(Unloading)
|
||||
|
||||
其中解析过程在某些情况下可以在初始化阶段之后再开始,这是为了支持 Java 的动态绑定。
|
||||
|
||||
## 2. 类初始化时机
|
||||
|
||||
虚拟机规范中并没有强制约束何时进行加载,但是规范严格规定了有且只有下列五种情况必须对类进行初始化:( 加载、验证、准备都会随着发生 )
|
||||
|
||||
1. 遇到 new、getstatic、putstatic、invokestatic 这四条字节码指令时,如果类没有进行过初始化,则必须先触发其初始化。最常见的生成这 4 条指令的场景是:使用 new 关键字实例化对象的时候;读取或设置一个类的静态字段(被 final 修饰、已在编译器把结果放入常量池的静态字段除外)的时候;以及调用一个类的静态方法的时候。
|
||||
|
||||
2. 使用 java.lang.reflect 包的方法对类进行反射调用的时候,如果类没有进行初始化,则需要先触发其初始化。
|
||||
|
||||
3. 当初始化一个类的时候,如果发现其父类还没有进行过初始化,则需要先触发其父类的初始化。
|
||||
|
||||
4. 当虚拟机启动时,用户需要指定一个要执行的主类(包含 main() 方法的那个类),虚拟机会先初始化这个主类;
|
||||
|
||||
5. 当使用 jdk1.7 的动态语言支持时,如果一个 java.lang.invoke.MethodHandle 实例最后的解析结果为 REF_getStatic, REF_putStatic, REF_invokeStatic 的方法句柄,并且这个方法句柄所对应的类没有进行过初始化,则需要先触发其初始化;
|
||||
|
||||
以上 5 种场景中的行为称为对一个类进行主动引用。除此之外,所有引用类的方式都不会触发初始化,称为被动引用。被动引用的常见例子包括:
|
||||
|
||||
1\. 通过子类引用父类的静态字段,不会导致子类初始化。
|
||||
|
||||
```java
|
||||
System.out.println(SubClass.value); // value 字段在 SuperClass 中定义
|
||||
```
|
||||
|
||||
2\. 通过数组定义来引用类,不会触发此类的初始化。该过程会对数组类进行初始化,数组类是一个由虚拟机自动生成的、直接继承自 Object 的子类,其中包含了数组的属性和方法。
|
||||
|
||||
```java
|
||||
SuperClass[] sca = new SuperClass[10];
|
||||
```
|
||||
|
||||
3\. 常量在编译阶段会存入调用类的常量池中,本质上并没有直接引用到定义常量的类,因此不会触发定义常量的类的初始化。
|
||||
|
||||
```java
|
||||
System.out.println(ConstClass.HELLOWORLD);
|
||||
```
|
||||
|
||||
## 3. 类加载过程
|
||||
|
||||
包含了加载、验证、准备、解析和初始化这 5 个阶段。
|
||||
|
||||
### 3.1 加载
|
||||
|
||||
加载是类加载的一个阶段,注意不要混淆。
|
||||
|
||||
加载过程完成以下三件事:
|
||||
|
||||
1. 通过一个类的全限定名来获取定义此类的二进制字节流。
|
||||
2. 将这个字节流所代表的静态存储结构转化为方法区的运行时存储结构。
|
||||
3. 在内存中生成一个代表这个类的 Class 对象,作为方法区这个类的各种数据的访问入口。
|
||||
|
||||
其中二进制字节流可以从以下方式中获取:
|
||||
|
||||
- 从 ZIP 包读取,这很常见,最终成为日后 JAR、EAR、WAR 格式的基础。
|
||||
- 从网络中获取,这种场景最典型的应用是 Applet。
|
||||
- 运行时计算生成,这种场景使用得最多得就是动态代理技术,在 java.lang.reflect.Proxy 中,就是用了 ProxyGenerator.generateProxyClass 的代理类的二进制字节流。
|
||||
- 由其他文件生成,典型场景是 JSP 应用,即由 JSP 文件生成对应的 Class 类。
|
||||
- 从数据库读取,这种场景相对少见,例如有些中间件服务器(如 SAP Netweaver)可以选择把程序安装到数据库中来完成程序代码在集群间的分发。
|
||||
...
|
||||
|
||||
### 3.2 验证
|
||||
|
||||
确保 Class 文件的字节流中包含的信息符合当前虚拟机的要求,并且不会危害虚拟机自身的安全。
|
||||
|
||||
主要有以下 4 个阶段:
|
||||
|
||||
1. 文件格式验证
|
||||
2. 元数据验证(对字节码描述的信息进行语义分析)
|
||||
3. 字节码验证(通过数据流和控制流分析,确保程序语义是合法、符合逻辑的,将对类的方法体进行校验分析)
|
||||
4. 符号引用验证
|
||||
|
||||
### 3.3 准备
|
||||
|
||||
类变量是被 static 修饰的变量,准备阶段为类变量分配内存并设置初始值,使用的是方法区的内存。
|
||||
|
||||
实例变量不会在这阶段分配内存,它将会在对象实例化时随着对象一起分配在 Java 堆中。
|
||||
|
||||
初始值一般为 0 值,例如下面的类变量 value 被初始化为 0 而不是 123。
|
||||
|
||||
```java
|
||||
public static int value = 123;
|
||||
```
|
||||
|
||||
如果类变量是常量,那么会按照表达式来进行初始化,而不是赋值为 0。
|
||||
|
||||
```java
|
||||
public static final int value = 123;
|
||||
```
|
||||
|
||||
### 3.4 解析
|
||||
|
||||
将常量池的符号引用替换为直接引用的过程。
|
||||
|
||||
### 3.5 初始化
|
||||
|
||||
初始化阶段即虚拟机执行类构造器 <clinit>() 方法的过程。
|
||||
|
||||
在准备阶段,类变量已经赋过一次系统要求的初始值,而在初始化阶段,根据程序员通过程序制定的主观计划去初始化类变量和其它资源。
|
||||
|
||||
<clinit>() 方法具有以下特点:
|
||||
|
||||
- 是由编译器自动收集类中所有类变量的赋值动作和静态语句块(static{} 块)中的语句合并产生的,编译器收集的顺序由语句在源文件中出现的顺序决定。特别注意的是,静态语句块只能访问到定义在它之前的类变量,定义在它之后的类变量只能赋值,不能访问。例如以下代码:
|
||||
|
||||
```java
|
||||
public class Test {
|
||||
static {
|
||||
i = 0; // 给变量赋值可以正常编译通过
|
||||
System.out.print(i); // 这句编译器会提示“非法向前引用”
|
||||
}
|
||||
static int i = 1;
|
||||
}
|
||||
```
|
||||
|
||||
- 与类的构造函数(或者说实例构造器 <init>())不同,不需要显式的调用父类的构造器。虚拟机会自动保证在子类的 <clinit>() 方法运行之前,父类的 <clinit>() 方法已经执行结束。因此虚拟机中第一个执行 <clinit>() 方法的类肯定为 java.lang.Object。
|
||||
|
||||
- 由于父类的 <clinit>() 方法先执行,也就意味着父类中定义的静态语句块要优于子类的变量赋值操作。例如以下代码:
|
||||
|
||||
```java
|
||||
static class Parent {
|
||||
public static int A = 1;
|
||||
static {
|
||||
A = 2;
|
||||
}
|
||||
}
|
||||
|
||||
static class Sub extends Parent {
|
||||
public static int B = A;
|
||||
}
|
||||
|
||||
public static void main(String[] args) {
|
||||
System.out.println(Sub.B); // 输出结果是父类中的静态变量值 A,也就是 2
|
||||
}
|
||||
```
|
||||
|
||||
- <clinit>() 方法对于类或接口不是必须的,如果一个类中不包含静态语句块,也没有对类变量的赋值操作,编译器可以不为该类生成 <clinit>() 方法。
|
||||
|
||||
- 接口中不可以使用静态语句块,但仍然有类变量初始化的赋值操作,因此接口与类一样都会生成 <clinit>() 方法。但接口与类不同的是,执行接口的 <clinit>() 方法不需要先执行父接口的 <clinit>() 方法。只有当父接口中定义的变量使用时,父接口才会初始化。另外,接口的实现类在初始化时也一样不会执行接口的 <clinit>() 方法。
|
||||
|
||||
- 虚拟机会保证一个类的 <clinit>() 方法在多线程环境下被正确的加锁和同步,如果多个线程同时初始化一个类,只会有一个线程执行这个类的 <clinit>() 方法,其它线程都会阻塞等待,直到活动线程执行 <clinit>() 方法完毕。如果在一个类的 <clinit>() 方法中有耗时的操作,就可能造成多个进程阻塞,在实际过程中此种阻塞很隐蔽。
|
||||
|
||||
## 4. 类加载器
|
||||
|
||||
虚拟机设计团队把类加载阶段中的“通过一个类的全限定名来获取描述此类的二进制字节流 ( 即字节码 )”这个动作放到 Java 虚拟机外部去实现,以便让应用程序自己决定如何去获取所需要的类。实现这个动作的代码模块称为“类加载器”。
|
||||
|
||||
### 4.1 类与类加载器
|
||||
|
||||
对于任意一个类,都需要由加载它的类加载器和这个类本身一同确立其在 Java 虚拟机中的唯一性,每一个类加载器,都拥有一个独立的类名称空间。通俗而言:比较两个类是否“相等”(这里所指的“相等”,包括类的 Class 对象的 equals() 方法、isAssignableFrom() 方法、isInstance() 方法的返回结果,也包括使用 instanceof() 关键字对做对象所属关系判定等情况),只有在这两个类时由同一个类加载器加载的前提下才有意义,否则,即使这两个类来源于同一个 Class 文件,被同一个虚拟机加载,只要加载它们的类加载器不同,那这两个类就必定不相等。
|
||||
|
||||
### 4.2 类加载器分类
|
||||
|
||||
从 Java 虚拟机的角度来讲,只存在以下两种不同的类加载器:
|
||||
|
||||
一种是启动类加载器(Bootstrap ClassLoader),这个类加载器用 C++ 实现,是虚拟机自身的一部分;另一种就是所有其他类的加载器,这些类由 Java 实现,独立于虚拟机外部,并且全都继承自抽象类 java.lang.ClassLoader。
|
||||
|
||||
从 Java 开发人员的角度看,类加载器可以划分得更细致一些:
|
||||
|
||||
- 启动类加载器(Bootstrap ClassLoader) 此类加载器负责将存放在 <JAVA_HOME>\lib 目录中的,或者被 -Xbootclasspath 参数所指定的路径中的,并且是虚拟机识别的(仅按照文件名识别,如 rt.jar,名字不符合的类库即使放在 lib 目录中也不会被加载)类库加载到虚拟机内存中。 启动类加载器无法被 Java 程序直接引用,用户在编写自定义类加载器时,如果需要把加载请求委派给引导类加载器,直接使用 null 代替即可。
|
||||
|
||||
- 扩展类加载器(Extension ClassLoader) 这个类加载器是由 ExtClassLoader(sun.misc.Launcher$ExtClassLoader)实现的。它负责将 <Java_Home>/lib/ext 或者被 java.ext.dir 系统变量所指定路径中的所有类库加载到内存中,开发者可以直接使用扩展类加载器。
|
||||
|
||||
- 应用程序类加载器(Application ClassLoader) 这个类加载器是由 AppClassLoader(sun.misc.Launcher$AppClassLoader)实现的。由于这个类加载器是 ClassLoader 中的 getSystemClassLoader() 方法的返回值,因此一般称为系统类加载器。它负责加载用户类路径(ClassPath)上所指定的类库,开发者可以直接使用这个类加载器,如果应用程序中没有自定义过自己的类加载器,一般情况下这个就是程序中默认的类加载器。
|
||||
|
||||
### 4.3 双亲委派模型
|
||||
|
||||
应用程序都是由三种类加载器相互配合进行加载的,如果有必要,还可以加入自己定义的类加载器。下图展示的类加载器之间的层次关系,称为类加载器的双亲委派模型(Parents Delegation Model)。该模型要求除了顶层的启动类加载器外,其余的类加载器都应有自己的父类加载器,这里类加载器之间的父子关系一般通过组合(Composition)关系来实现,而不是通过继承(Inheritance)的关系实现。
|
||||
|
||||

|
||||
|
||||
**工作过程**
|
||||
|
||||
如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载,而是把这个请求委派给父类加载器,每一个层次的加载器都是如此,依次递归,因此所有的加载请求最终都应该传送到顶层的启动类加载器中,只有当父加载器反馈自己无法完成此加载请求(它搜索范围中没有找到所需类)时,子加载器才会尝试自己加载。
|
||||
|
||||
**好处**
|
||||
|
||||
使用双亲委派模型来组织类加载器之间的关系,使得 Java 类随着它的类加载器一起具备了一种带有优先级的层次关系。例如类 java.lang.Object,它存放再 rt.jar 中,无论哪个类加载器要加载这个类,最终都是委派给处于模型最顶端的启动类加载器进行加载,因此 Object 类在程序的各种类加载器环境中都是同一个类。相反,如果没有双亲委派模型,由各个类加载器自行加载的话,如果用户编写了一个称为`java.lang.Object 的类,并放在程序的 ClassPath 中,那系统中将会出现多个不同的 Object 类,程序将变得一片混乱。如果开发者尝试编写一个与 rt.jar 类库中已有类重名的 Java 类,将会发现可以正常编译,但是永远无法被加载运行。
|
||||
|
||||
**实现**
|
||||
|
||||
```java
|
||||
protected synchronized Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException{
|
||||
//check the class has been loaded or not
|
||||
Class c = findLoadedClass(name);
|
||||
if(c == null) {
|
||||
try{
|
||||
if(parent != null) {
|
||||
c = parent.loadClass(name, false);
|
||||
} else{
|
||||
c = findBootstrapClassOrNull(name);
|
||||
}
|
||||
} catch(ClassNotFoundException e) {
|
||||
//if throws the exception , the father can not complete the load
|
||||
}
|
||||
if(c == null) {
|
||||
c = findClass(name);
|
||||
}
|
||||
}
|
||||
if(resolve) {
|
||||
resolveClass(c);
|
||||
}
|
||||
return c;
|
||||
}
|
||||
```
|
||||
|
||||
# JVM 参数
|
||||
|
||||
## GC 优化配置
|
||||
|
||||
| 配置 | 描述 |
|
||||
| --- | --- |
|
||||
| -Xms | 初始化堆内存大小 |
|
||||
| -Xmx | 堆内存最大值 |
|
||||
| -Xmn | 新生代大小 |
|
||||
| -XX:PermSize | 初始化永久代大小 |
|
||||
| -XX:MaxPermSize | 永久代最大容量 |
|
||||
|
||||
## GC 类型设置
|
||||
|
||||
| 配置 | 描述 |
|
||||
| --- | --- |
|
||||
| -XX:+UseSerialGC | 串行垃圾回收器 |
|
||||
| -XX:+UseParallelGC | 并行垃圾回收器 |
|
||||
| -XX:+UseConcMarkSweepGC | 并发标记扫描垃圾回收器 |
|
||||
| -XX:ParallelCMSThreads= | 并发标记扫描垃圾回收器 = 为使用的线程数量 |
|
||||
| -XX:+UseG1GC | G1 垃圾回收器 |
|
||||
|
||||
```java
|
||||
java -Xmx12m -Xms3m -Xmn1m -XX:PermSize=20m -XX:MaxPermSize=20m -XX:+UseSerialGC -jar java-application.jar
|
||||
```
|
||||
406
notes/Java IO.md
Normal file
406
notes/Java IO.md
Normal file
@ -0,0 +1,406 @@
|
||||
<!-- GFM-TOC -->
|
||||
* [概览](#概览)
|
||||
* [磁盘操作](#磁盘操作)
|
||||
* [字节操作](#字节操作)
|
||||
* [字符操作](#字符操作)
|
||||
* [对象操作](#对象操作)
|
||||
* [网络操作](#网络操作)
|
||||
* [1. InetAddress](#1-inetaddress)
|
||||
* [2. URL](#2-url)
|
||||
* [3. Sockets](#3-sockets)
|
||||
* [4. Datagram](#4-datagram)
|
||||
* [NIO](#nio)
|
||||
* [1. 流与块](#1-流与块)
|
||||
* [2. 通道与缓冲区](#2-通道与缓冲区)
|
||||
* [2.1 通道](#21-通道)
|
||||
* [2.2 缓冲区](#22-缓冲区)
|
||||
* [3. 缓冲区状态变量](#3-缓冲区状态变量)
|
||||
* [4. 读写文件实例](#4-读写文件实例)
|
||||
* [5. 阻塞与非阻塞](#5-阻塞与非阻塞)
|
||||
* [5.1 阻塞式 I/O](#51-阻塞式-io)
|
||||
* [5.2 非阻塞式 I/O](#52-非阻塞式-io)
|
||||
* [6. 套接字实例](#6-套接字实例)
|
||||
* [6.1 ServerSocketChannel](#61-serversocketchannel)
|
||||
* [6.2 Selectors](#62-selectors)
|
||||
* [6.3 主循环](#63-主循环)
|
||||
* [6.4 监听新连接](#64-监听新连接)
|
||||
* [6.5 接受新的连接](#65-接受新的连接)
|
||||
* [6.6 删除处理过的 SelectionKey](#66-删除处理过的-selectionkey)
|
||||
* [6.7 传入的 I/O](#67-传入的-io)
|
||||
* [参考资料](#参考资料)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
# 概览
|
||||
|
||||
Java 的 I/O 大概可以分成以下几类
|
||||
|
||||
1. 磁盘操作:File
|
||||
2. 字节操作:InputStream 和 OutputStream
|
||||
3. 字符操作:Reader 和 Writer
|
||||
4. 对象操作:Serializable
|
||||
5. 网络操作:Socket
|
||||
6. 非阻塞式 IO:NIO
|
||||
|
||||
# 磁盘操作
|
||||
|
||||
File 类可以用于表示文件和目录,但是它只用于表示文件的信息,而不表示文件的内容。
|
||||
|
||||
# 字节操作
|
||||
|
||||

|
||||
|
||||
Java I/O 使用了装饰者模式来实现。以 InputStream 为例,InputStream 是抽象组件,FileInputStream 是 InputStream 的子类,属于具体组件,提供了字节流的输入操作。FilterInputStream 属于抽象装饰者,装饰者用于装饰组件,为组件提供额外的功能,例如 BufferedInputStream 为 FileInputStream 提供缓存的功能。实例化一个具有缓存功能的字节流对象时,只需要在 FileInputStream 对象上再套一层 BufferedInputStream 对象即可。
|
||||
|
||||
```java
|
||||
BufferedInputStream bis = new BufferedInputStream(new FileInputStream(file));
|
||||
```
|
||||
|
||||
DataInputStream 装饰者提供了对更多数据类型进行输入的操作,比如 int、double 等基本类型。
|
||||
|
||||
批量读入文件中的内容到字节数组中
|
||||
|
||||
```java
|
||||
byte[] buf = new byte[20*1024];
|
||||
int bytes = 0;
|
||||
// 最多读取 buf.length 个字节,返回的是实际读取的个数,返回 -1 的时候表示读到 eof,即文件尾
|
||||
while((bytes = in.read(buf, 0 , buf.length)) != -1) {
|
||||
// ...
|
||||
}
|
||||
```
|
||||
|
||||
# 字符操作
|
||||
|
||||
不管是磁盘还是网络传输,最小的存储单元都是字节,而不是字符,所以 I/O 操作的都是字节而不是字符。但是在程序中操作的数据通常是字符形式,因此需要提供对字符进行操作的方法。
|
||||
|
||||
InputStreamReader 实现从文本文件的字节流解码成字符流;OutputStreamWriter 实现字符流编码成为文本文件的字节流。它们都继承自 Reader 和 Writer。
|
||||
|
||||
编码就是把字符转换为字节,而解码是把字节重新组合成字符。
|
||||
|
||||
```java
|
||||
byte[] bytes = str.getBytes(encoding); // 编码
|
||||
String str = new String(bytes, encoding); // 解码
|
||||
```
|
||||
|
||||
GBK 编码中,中文占 2 个字节,英文占 1 个字节;UTF-8 编码中,中文占 3 个字节,英文占 1 个字节;Java 使用双字节编码 UTF-16be,中文和英文都占 2 个字节。
|
||||
|
||||
如果编码和解码过程使用不同的编码方式那么就出现了乱码。
|
||||
|
||||
# 对象操作
|
||||
|
||||
序列化就是将一个对象转换成字节序列,方便存储和传输。
|
||||
|
||||
序列化:ObjectOutputStream.writeObject()
|
||||
|
||||
反序列化:ObjectInputStream.readObject()
|
||||
|
||||
序列化的类需要实现 Serializable 接口,它只是一个标准,没有任何方法需要实现。
|
||||
|
||||
transient 关键字可以使一些属性不会被序列化。
|
||||
|
||||
**ArrayList 序列化和反序列化的实现**:ArrayList 中存储数据的数组是用 transient 修饰的,因为这个数组是动态扩展的,并不是所有的空间都被使用,因此就不需要所有的内容都被序列化。通过重写序列化和反序列化方法,使得可以只序列化数组中有内容的那部分数据。
|
||||
|
||||
```
|
||||
private transient Object[] elementData;
|
||||
```
|
||||
|
||||
# 网络操作
|
||||
|
||||
Java 中的网络支持:
|
||||
|
||||
1. InetAddress:用于表示网络上的硬件资源,即 IP 地址;
|
||||
2. URL:统一资源定位符,通过 URL 可以直接读取或者写入网络上的数据;
|
||||
3. Sockets:使用 TCP 协议实现网络通信;
|
||||
4. Datagram:使用 UDP 协议实现网络通信。
|
||||
|
||||
## 1. InetAddress
|
||||
|
||||
没有公有构造函数,只能通过静态方法来创建实例,比如 InetAddress.getByName(String host)、InetAddress.getByAddress(byte[] addr)。
|
||||
|
||||
## 2. URL
|
||||
|
||||
可以直接从 URL 中读取字节流数据
|
||||
|
||||
```java
|
||||
URL url = new URL("http://www.baidu.com");
|
||||
InputStream is = url.openStream(); // 字节流
|
||||
InputStreamReader isr = new InputStreamReader(is, "utf-8"); // 字符流
|
||||
BufferedReader br = new BufferedReader(isr);
|
||||
String line = br.readLine();
|
||||
while (line != null) {
|
||||
System.out.println(line);
|
||||
line = br.readLine();
|
||||
}
|
||||
br.close();
|
||||
isr.close();
|
||||
is.close();
|
||||
```
|
||||
|
||||
## 3. Sockets
|
||||
|
||||
Socket 通信模型
|
||||
|
||||

|
||||
|
||||
- ServerSocket:服务器端类
|
||||
- Socket:客户端类
|
||||
|
||||
服务器和客户端通过 InputStream 和 OutputStream 进行输入输出。
|
||||
|
||||
## 4. Datagram
|
||||
|
||||
- DatagramPacket:数据包类
|
||||
- DatagramSocket:通信类
|
||||
|
||||
# NIO
|
||||
|
||||
NIO 将最耗时的 I/O 操作 ( 即填充和提取缓冲区 ) 转移回操作系统,因而 不需要程序员去控制就可以极大地提高运行速度。
|
||||
|
||||
## 1. 流与块
|
||||
|
||||
I/O 与 NIO 最重要的区别是数据打包和传输的方式。正如前面提到的,I/O 以流的方式处理数据,而 NIO 以块的方式处理数据。
|
||||
|
||||
面向流的 I/O 一次一个字节进行处理数据,一个输入流产生一个字节的数据,一个输出流消费一个字节的数据。为流式数据创建过滤器非常容易,链接几个过滤器,以便每个过滤器只负责单个复杂处理机制的一部分,这样也是相对简单的。不利的一面是,面向流的 I/O 通常相当慢。
|
||||
|
||||
一个面向块的 I/O 系统以块的形式处理数据,每一个操作都在一步中产生或者消费一个数据块。按块处理数据比按流处理数据要快得多。但是面向块的 I/O 缺少一些面向流的 I/O 所具有的优雅性和简单性。
|
||||
|
||||
I/O 包和 NIO 已经很好地集成了,java.io.\* 已经以 NIO 为基础重新实现了,所以现在它可以利用 NIO 的一些特性。例如, java.io.\* 包中的一些类包含以块的形式读写数据的方法,这使得即使在更面向流的系统中,处理速度也会更快。
|
||||
|
||||
## 2. 通道与缓冲区
|
||||
|
||||
### 2.1 通道
|
||||
|
||||
通道 Channel 是对原 I/O 包中的流的模拟,可以通过它读取和写入数据。
|
||||
|
||||
通道与流的不同之处在于,流只能在一个方向上移动,(一个流必须是 InputStream 或者 OutputStream 的子类), 而通道是双向的,可以用于读、写或者同时用于读写。
|
||||
|
||||
通道包括以下类型:
|
||||
|
||||
- FileChannel:从文件中读写数据;
|
||||
- DatagramChannel:通过 UDP 读写网络中数据;
|
||||
- SocketChannel:通过 TCP 读写网络中数据;
|
||||
- ServerSocketChannel:可以监听新进来的 TCP 连接,对每一个新进来的连接都会创建一个 SocketChannel。
|
||||
|
||||
### 2.2 缓冲区
|
||||
|
||||
发送给一个通道的所有对象都必须首先放到缓冲区中;同样地,从通道中读取的任何数据都要读到缓冲区中。也就是说,不会直接对通道进行读写数据,而是先经过缓冲区。
|
||||
|
||||
缓冲区实质上是一个数组,但它不仅仅是一个数组。缓冲区提供了对数据的结构化访问,而且还可以跟踪系统的读/写进程。
|
||||
|
||||
缓冲区包括以下类型:
|
||||
|
||||
- ByteBuffer
|
||||
- CharBuffer
|
||||
- ShortBuffer
|
||||
- IntBuffer
|
||||
- LongBuffer
|
||||
- FloatBuffer
|
||||
- DoubleBuffer
|
||||
|
||||
|
||||
## 3. 缓冲区状态变量
|
||||
|
||||
- capacity:最大容量;
|
||||
- position:当前已经读写的字节数;
|
||||
- limit:还可以读写的字节数。
|
||||
|
||||
状态变量的改变过程:
|
||||
|
||||
1\. 新建一个大小为 8 个字节的缓冲区,此时 position 为 0,而 limit == capacity == 9。capacity 变量不会改变,下面的讨论会忽略它。
|
||||
|
||||

|
||||
|
||||
2\. 从输入通道中读取 3 个字节数据写入缓冲区中,此时 position 移动设为 3,limit 保持不变。
|
||||
|
||||

|
||||
|
||||
3\. 在将缓冲区的数据写到输出通道之前,需要先调用 flip() 方法,这个方法将 limit 设置为当前 position,并将 position 设置为 0。
|
||||
|
||||

|
||||
|
||||
4\. 从缓冲区中取 4 个字节到输出缓冲中,此时 position 设为 4。
|
||||
|
||||

|
||||
|
||||
5\. 最后需要调用 clear() 方法来清空缓冲区,此时 position 和 limit 都被设置为最初位置。
|
||||
|
||||

|
||||
|
||||
## 4. 读写文件实例
|
||||
|
||||
1\. 为要读取的文件创建 FileInputStream,之后通过 FileInputStream 获取输入 FileChannel;
|
||||
|
||||
```java
|
||||
FileInputStream fin = new FileInputStream("readandshow.txt");
|
||||
FileChannel fic = fin.getChannel();
|
||||
```
|
||||
|
||||
2\. 创建一个容量为 1024 的 Buffer
|
||||
|
||||
```java
|
||||
ByteBuffer buffer = ByteBuffer.allocate(1024);
|
||||
```
|
||||
|
||||
3\. 将数据从输入 FileChannel 写入到 Buffer 中,如果没有数据的话, read() 方法会返回 -1
|
||||
|
||||
```java
|
||||
int r = fcin.read(buffer);
|
||||
if (r == -1) {
|
||||
break;
|
||||
}
|
||||
```
|
||||
|
||||
4\. 为要写入的文件创建 FileOutputStream,之后通过 FileOutputStream 获取输出 FileChannel
|
||||
|
||||
```java
|
||||
FileOutputStream fout = new FileOutputStream("writesomebytes.txt");
|
||||
FileChannel foc = fout.getChannel();
|
||||
```
|
||||
|
||||
5\. 调用 flip() 切换读写
|
||||
|
||||
```java
|
||||
buffer.flip();
|
||||
```
|
||||
|
||||
6\. 把 Buffer 中的数据读取到输出 FileChannel 中
|
||||
|
||||
```java
|
||||
foc.write(buffer);
|
||||
```
|
||||
|
||||
7\. 最后调用 clear() 重置缓冲区
|
||||
|
||||
```java
|
||||
buffer.clear();
|
||||
```
|
||||
|
||||
## 5. 阻塞与非阻塞
|
||||
|
||||
应当注意,FileChannel 不能切换到非阻塞模式,套接字 Channel 可以。
|
||||
|
||||
### 5.1 阻塞式 I/O
|
||||
|
||||
阻塞式 I/O 在调用 InputStream.read() 方法时会一直等到数据到来时(或超时)才会返回,在调用 ServerSocket.accept() 方法时,也会一直阻塞到有客户端连接才会返回,每个客户端连接过来后,服务端都会启动一个线程去处理该客户端的请求。
|
||||
|
||||

|
||||
|
||||
### 5.2 非阻塞式 I/O
|
||||
|
||||
由一个专门的线程来处理所有的 I/O 事件,并负责分发。
|
||||
|
||||
事件驱动机制:事件到的时候触发,而不是同步的去监视事件。
|
||||
|
||||
线程通信:线程之间通过 wait()、notify() 等方式通信,保证每次上下文切换都是有意义的,减少无谓的线程切换。
|
||||
|
||||

|
||||
|
||||
## 6. 套接字实例
|
||||
|
||||
### 6.1 ServerSocketChannel
|
||||
|
||||
每一个端口都需要有一个 ServerSocketChannel 用来监听连接。
|
||||
|
||||
```java
|
||||
ServerSocketChannel ssc = ServerSocketChannel.open();
|
||||
ssc.configureBlocking(false); // 设置为非阻塞
|
||||
|
||||
ServerSocket ss = ssc.socket();
|
||||
InetSocketAddress address = new InetSocketAddress(ports[i]);
|
||||
ss.bind(address); // 绑定端口号
|
||||
```
|
||||
|
||||
### 6.2 Selectors
|
||||
|
||||
异步 I/O 通过 Selector 注册对特定 I/O 事件的兴趣 ― 可读的数据的到达、新的套接字连接等等,在发生这样的事件时,系统将会发送通知。
|
||||
|
||||
创建 Selectors 之后,就可以对不同的通道对象调用 register() 方法。register() 的第一个参数总是这个 Selector。第二个参数是 OP_ACCEPT,这里它指定我们想要监听 accept 事件,也就是在新的连接建立时所发生的事件。
|
||||
|
||||
SelectionKey 代表这个通道在此 Selector 上的这个注册。当某个 Selector 通知您某个传入事件时,它是通过提供对应于该事件的 SelectionKey 来进行的。SelectionKey 还可以用于取消通道的注册。
|
||||
|
||||
```java
|
||||
Selector selector = Selector.open();
|
||||
SelectionKey key = ssc.register(selector, SelectionKey.OP_ACCEPT);
|
||||
```
|
||||
|
||||
### 6.3 主循环
|
||||
|
||||
首先,我们调用 Selector 的 select() 方法。这个方法会阻塞,直到至少有一个已注册的事件发生。当一个或者更多的事件发生时, select() 方法将返回所发生的事件的数量。
|
||||
|
||||
接下来,我们调用 Selector 的 selectedKeys() 方法,它返回发生了事件的 SelectionKey 对象的一个 集合 。
|
||||
|
||||
我们通过迭代 SelectionKeys 并依次处理每个 SelectionKey 来处理事件。对于每一个 SelectionKey,您必须确定发生的是什么 I/O 事件,以及这个事件影响哪些 I/O 对象。
|
||||
|
||||
```java
|
||||
int num = selector.select();
|
||||
|
||||
Set selectedKeys = selector.selectedKeys();
|
||||
Iterator it = selectedKeys.iterator();
|
||||
|
||||
while (it.hasNext()) {
|
||||
SelectionKey key = (SelectionKey)it.next();
|
||||
// ... deal with I/O event ...
|
||||
}
|
||||
```
|
||||
|
||||
### 6.4 监听新连接
|
||||
|
||||
程序执行到这里,我们仅注册了 ServerSocketChannel,并且仅注册它们“接收”事件。为确认这一点,我们对 SelectionKey 调用 readyOps() 方法,并检查发生了什么类型的事件:
|
||||
|
||||
```java
|
||||
if ((key.readyOps() & SelectionKey.OP_ACCEPT)
|
||||
== SelectionKey.OP_ACCEPT) {
|
||||
// Accept the new connection
|
||||
// ...
|
||||
}
|
||||
```
|
||||
|
||||
可以肯定地说, readOps() 方法告诉我们该事件是新的连接。
|
||||
|
||||
### 6.5 接受新的连接
|
||||
|
||||
因为我们知道这个服务器套接字上有一个传入连接在等待,所以可以安全地接受它;也就是说,不用担心 accept() 操作会阻塞:
|
||||
|
||||
```java
|
||||
ServerSocketChannel ssc = (ServerSocketChannel)key.channel();
|
||||
SocketChannel sc = ssc.accept();
|
||||
```
|
||||
|
||||
下一步是将新连接的 SocketChannel 配置为非阻塞的。而且由于接受这个连接的目的是为了读取来自套接字的数据,所以我们还必须将 SocketChannel 注册到 Selector上,如下所示:
|
||||
|
||||
```java
|
||||
sc.configureBlocking( false );
|
||||
SelectionKey newKey = sc.register( selector, SelectionKey.OP_READ );
|
||||
```
|
||||
|
||||
注意我们使用 register() 的 OP_READ 参数,将 SocketChannel 注册用于 读取 而不是 接受 新连接。
|
||||
|
||||
### 6.6 删除处理过的 SelectionKey
|
||||
|
||||
在处理 SelectionKey 之后,我们几乎可以返回主循环了。但是我们必须首先将处理过的 SelectionKey 从选定的键集合中删除。如果我们没有删除处理过的键,那么它仍然会在主集合中以一个激活的键出现,这会导致我们尝试再次处理它。我们调用迭代器的 remove() 方法来删除处理过的 SelectionKey:
|
||||
|
||||
```java
|
||||
it.remove();
|
||||
```
|
||||
|
||||
现在我们可以返回主循环并接受从一个套接字中传入的数据(或者一个传入的 I/O 事件)了。
|
||||
|
||||
### 6.7 传入的 I/O
|
||||
|
||||
当来自一个套接字的数据到达时,它会触发一个 I/O 事件。这会导致在主循环中调用 Selector.select(),并返回一个或者多个 I/O 事件。这一次, SelectionKey 将被标记为 OP_READ 事件,如下所示:
|
||||
|
||||
```java
|
||||
} else if ((key.readyOps() & SelectionKey.OP_READ)
|
||||
== SelectionKey.OP_READ) {
|
||||
// Read the data
|
||||
SocketChannel sc = (SocketChannel)key.channel();
|
||||
// ...
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
# 参考资料
|
||||
|
||||
- Eckel B, 埃克尔 , 昊鹏 , 等 . Java 编程思想 [M]. 机械工业出版社 , 2002.
|
||||
- [IBM: NIO 入门](https://www.ibm.com/developerworks/cn/education/java/j-nio/j-nio.html)
|
||||
- [ 深入分析 Java I/O 的工作机制 ](https://www.ibm.com/developerworks/cn/java/j-lo-javaio/index.html)
|
||||
- [NIO 与传统 IO 的区别 ](http://blog.csdn.net/shimiso/article/details/24990499)
|
||||
140
notes/Java 基础语法.md
Normal file
140
notes/Java 基础语法.md
Normal file
@ -0,0 +1,140 @@
|
||||
<!-- GFM-TOC -->
|
||||
* [基础](#基础)
|
||||
* [ final](#-final)
|
||||
* [初始化顺序](#初始化顺序)
|
||||
* [访问权限](#访问权限)
|
||||
* [容器](#容器)
|
||||
* [Set](#set)
|
||||
* [Queue](#queue)
|
||||
* [Map](#map)
|
||||
* [反射](#反射)
|
||||
* [异常](#异常)
|
||||
* [参考资料](#参考资料)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
# 基础
|
||||
|
||||
## final
|
||||
|
||||
**final 数据**
|
||||
|
||||
声明数据为常量,可以是编译时常量,也可以是在运行时被初始化后不能被改变的常量。
|
||||
|
||||
对于基本类型,final 使数值不变;对于引用对象,final 使引用不变,也就不能引用其它对象,但是被引用的对象本身是可以修改的。
|
||||
|
||||
**final 方法**
|
||||
|
||||
声明方法不能被子类覆盖。
|
||||
|
||||
private 方法隐式地被指定为 final,如果在子类中定义的方法和基类中的一个 private 方法签名相同,此时子类的方法不是覆盖基类方法,而是重载了。
|
||||
|
||||
**final 类**
|
||||
|
||||
声明类不允许被继承。
|
||||
|
||||
## 初始化顺序
|
||||
|
||||
static 声明的静态数据在内存中只存在一份,只在类第一次实例化时初始化一次,优先于其它数据的初始化。
|
||||
|
||||
```java
|
||||
public static String staticField = "静态变量";
|
||||
```
|
||||
|
||||
static 语句块和 static 数据一样在类第一次实例化时运行一次,具体哪个先运行取决于它们在代码中的顺序。
|
||||
|
||||
```java
|
||||
static {
|
||||
System.out.println("静态初始化块");
|
||||
}
|
||||
```
|
||||
|
||||
普通数据和普通语句块的初始化在静态数据和静态语句块初始化结束之后。
|
||||
|
||||
```java
|
||||
public String field = "变量";
|
||||
```
|
||||
|
||||
```java
|
||||
{
|
||||
System.out.println("初始化块");
|
||||
}
|
||||
```
|
||||
|
||||
最后才是构造函数中的数据进行初始化
|
||||
|
||||
```java
|
||||
public InitialOrderTest()
|
||||
{
|
||||
System.out.println("构造器");
|
||||
}
|
||||
```
|
||||
|
||||
存在继承的情况下,初始化顺序为:
|
||||
|
||||
1. 父类(静态数据、静态语句块)
|
||||
2. 子类(静态数据、静态语句块)
|
||||
3. 父类(数据、语句块)
|
||||
4. 父类(构造器)
|
||||
5. 子类(数据、语句块)
|
||||
6. 子类(构造器)
|
||||
|
||||
## 访问权限
|
||||
|
||||
Java 中有三个访问权限修饰符:private、protected 以及 public,如果不加访问修饰符,表示包级可见。
|
||||
|
||||
可以对类或类中的成员(字段以及方法)加上访问修饰符。成员可见表示其它类可以用成员所在类的对象访问到该成员;类可见表示其它类可以用这个类创建对象,可以把类当做包中的一个成员,然后包表示一个类,这样就好理解了。
|
||||
|
||||
protected 用于修饰成员,表示在继承体系中成员对于子类可见。但是这个访问修饰符对于类没有意义,因为包没有继承体系。
|
||||
|
||||
# 容器
|
||||
|
||||

|
||||
|
||||
容器主要包括 Collection 和 Map 两种,Collection 又包含了 List、Set 以及 Queue。
|
||||
|
||||
## Set
|
||||
|
||||
- HashSet:使用 Hash 实现,支持快速查找,但是失去有序性;
|
||||
|
||||
- TreeSet:使用树实现,保持有序,但是查找效率不如 HashSet;
|
||||
|
||||
- LinkedListHashSet:具有 HashSet 的查找效率,且内部使用链表维护元素的插入顺序,因此具有有序性。
|
||||
|
||||
## Queue
|
||||
|
||||
只有两个实现:LinkedList 和 PriorityQueue,其中 LinkedList 支持双向队列。
|
||||
|
||||
## Map
|
||||
|
||||
- HashMap:使用 Hash 实现
|
||||
|
||||
- LinkedHashMap:保持有序,顺序为插入顺序或者最近最少使用(LRU)顺序
|
||||
|
||||
- TreeMap:基于红黑树实现
|
||||
|
||||
- ConcurrentHashMap:线程安全 Map,不涉及同步加锁
|
||||
|
||||
# 反射
|
||||
|
||||
每个类都有一个 **Class** 对象,包含了与类有关的信息。当编译一个新类时,会产生一个同名的 .class 文件,该文件内容保存着 Class 对象。
|
||||
|
||||
类加载相当于 Class 对象的加载。类在第一次使用时才动态加载到 JVM 中,可以使用 Class.forName('com.mysql.jdbc.Driver.class') 这种方式来控制类的加载,该方法会返回一个 Class 对象。
|
||||
|
||||
反射可以提供运行时的类信息,并且这个类可以在运行时才加载进来,甚至在编译时期该类的 .class 不存在也可以加载进来。
|
||||
|
||||
Class 和 java.lang.reflect 一起对反射提供了支持,java.lang.reflect 类库包含了 **Field**、**Method** 以及 **Constructor** 类。可以使用 get() 和 set() 方法读取和修改 Field 对象关联的字段,可以使用 invoke() 方法调用与 Method 对象关联的方法,可以用 Constructor 创建新的对象。
|
||||
|
||||
IDE 使用反射机制获取类的信息,在使用一个类的对象时,能够把类的字段、方法和构造函数等信息列出来供用户选择。
|
||||
|
||||
# 异常
|
||||
|
||||
Throwable 可以用来表示任何可以作为异常抛出的类,分为两种:**Error** 和 **Exception**,其中 Error 用来表示编译时系统错误。
|
||||
|
||||
Exception 分为两种:**受检异常** 和 **非受检异常**。受检异常需要用 try...catch... 语句捕获并进行处理,并且可以从异常中恢复;非受检异常是程序运行时错误,例如除 0 会引发 Arithmetic Exception,此时程序奔溃并且无法恢复。
|
||||
|
||||

|
||||
|
||||
# 参考资料
|
||||
|
||||
- Eckel B, 埃克尔 , 昊鹏 , 等 . Java 编程思想 [M]. 机械工业出版社 , 2002.
|
||||
- [Java 类初始化顺序 ](https://segmentfault.com/a/1190000004527951)
|
||||
File diff suppressed because it is too large
Load Diff
1071
notes/Linux.md
Normal file
1071
notes/Linux.md
Normal file
File diff suppressed because it is too large
Load Diff
444
notes/MySQL.md
Normal file
444
notes/MySQL.md
Normal file
@ -0,0 +1,444 @@
|
||||
<!-- GFM-TOC -->
|
||||
* [事务四大特性](#事务四大特性)
|
||||
* [1. 原子性](#1-原子性)
|
||||
* [2. 一致性](#2-一致性)
|
||||
* [3. 隔离性](#3-隔离性)
|
||||
* [4. 持久性](#4-持久性)
|
||||
* [存储引擎](#存储引擎)
|
||||
* [1. InnoDB](#1-innodb)
|
||||
* [2. MyISAM](#2-myisam)
|
||||
* [3. InnoDB 与 MyISAM 的比较](#3-innodb-与-myisam-的比较)
|
||||
* [数据类型](#数据类型)
|
||||
* [1. 整型](#1-整型)
|
||||
* [2. 浮点数](#2-浮点数)
|
||||
* [3. 字符串](#3-字符串)
|
||||
* [4. 时间和日期](#4-时间和日期)
|
||||
* [索引](#索引)
|
||||
* [1. 索引分类](#1-索引分类)
|
||||
* [1.1 B-Tree 索引](#11-b-tree-索引)
|
||||
* [1.2 哈希索引](#12-哈希索引)
|
||||
* [1.3. 空间索引数据(R-Tree)](#13-空间索引数据(r-tree))
|
||||
* [1.4 全文索引](#14-全文索引)
|
||||
* [2. 索引的优点](#2-索引的优点)
|
||||
* [3. 索引优化](#3-索引优化)
|
||||
* [3.1 独立的列](#31-独立的列)
|
||||
* [3.2 前缀索引](#32-前缀索引)
|
||||
* [3.3 多列索引](#33-多列索引)
|
||||
* [3.4 索引列的顺序](#34-索引列的顺序)
|
||||
* [3.5 聚簇索引](#35-聚簇索引)
|
||||
* [3.6 覆盖索引](#36-覆盖索引)
|
||||
* [4. B-Tree 和 B+Tree 原理](#4-b-tree-和-b+tree-原理)
|
||||
* [4. 1 B-Tree](#4-1-b-tree)
|
||||
* [4.2 B+Tree](#42-b+tree)
|
||||
* [4.3 带有顺序访问指针的 B+Tree](#43-带有顺序访问指针的-b+tree)
|
||||
* [4.4 为什么使用 B-Tree 和 B+Tree](#44-为什么使用-b-tree-和-b+tree)
|
||||
* [查询性能优化](#查询性能优化)
|
||||
* [1. Explain](#1-explain)
|
||||
* [2. 减少返回的列](#2-减少返回的列)
|
||||
* [3. 减少返回的行](#3-减少返回的行)
|
||||
* [4. 拆分大的 DELETE 或 INSERT 语句](#4-拆分大的-delete-或-insert-语句)
|
||||
* [分库与分表](#分库与分表)
|
||||
* [故障转移和故障恢复](#故障转移和故障恢复)
|
||||
* [1. 故障转移](#1-故障转移)
|
||||
* [2. 故障恢复](#2-故障恢复)
|
||||
* [参考资料](#参考资料)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
# 事务四大特性
|
||||
|
||||
## 1. 原子性
|
||||
|
||||
要么都执行,要么都不执行。
|
||||
|
||||
## 2. 一致性
|
||||
|
||||
事务执行前后都保持一致性状态。
|
||||
|
||||
## 3. 隔离性
|
||||
|
||||
多个事务单独执行,互不影响。
|
||||
|
||||
## 4. 持久性
|
||||
|
||||
即使系统发生故障,事务执行的结果也不能丢失。
|
||||
|
||||
# 存储引擎
|
||||
|
||||
## 1. InnoDB
|
||||
|
||||
InnoDB 是 MySQL 的默认事务型引擎,只有在需要 InnoDB 不支持的特性时,才考虑使用其它存储引擎。
|
||||
|
||||
采用 MVCC 来支持高并发,并且实现了四个标准的隔离级别,默认级别是可重复读。
|
||||
|
||||
表是基于聚簇索引建立的,它对主键的查询性能有很高的提升。
|
||||
|
||||
内部做了很多优化,包括从磁盘读取数据时采用的可预测性读,能够自动在内存中创建 hash 索引以加速读操作的自适应哈希索引,以及能够加速插入操作的插入缓冲区等。
|
||||
|
||||
通过一些机制和工具支持真正的热备份。
|
||||
|
||||
## 2. MyISAM
|
||||
|
||||
MyISAM 提供了大量的特性,包括全文索引、压缩、空间函数(GIS)等。但 MyISAM 不支持事务和行级锁,而且奔溃后无法安全恢复。
|
||||
|
||||
只能对整张表加锁,而不是针对行。
|
||||
|
||||
可以手工或者自动执行检查和修复操作,但是和事务恢复以及奔溃恢复不同,可能导致一些数据丢失,而且修复操作是非常慢的。
|
||||
|
||||
可以包含动态或者静态的行。
|
||||
|
||||
如果指定了 DELAY_KEY_WRITE 选项,在每次修改执行完成时,不会立即将修改的索引数据写入磁盘,而是会写到内存中的键缓冲区,只有在清理键缓冲区或者关闭表的时候才会将对应的索引块写入磁盘。这种方式可以极大的提升写入性能,但是在数据库或者主机奔溃时会造成索引损坏,需要执行修复操作。
|
||||
|
||||
如果表在创建并导入数据以后,不会再进行修改操作,那么这样的表适合采用 MyISAM 压缩表。
|
||||
|
||||
对于只读数据,或者表比较小、可以容忍修复操作,则依然可以继续使用 MyISAM。
|
||||
|
||||
MyISAM 设计简单,数据以紧密格式存储,所以在某些场景下性能很好。
|
||||
|
||||
## 3. InnoDB 与 MyISAM 的比较
|
||||
|
||||
**事务**
|
||||
|
||||
InnoDB 是事务型的。
|
||||
|
||||
**备份**
|
||||
|
||||
InnoDB 支持在线热备份。
|
||||
|
||||
**奔溃恢复**
|
||||
|
||||
MyISAM 奔溃后发生损坏的概率比 InnoDB 高很多,而且恢复的速度也更慢。
|
||||
|
||||
**并发**
|
||||
|
||||
MyISAM 只支持表级锁,而 InnoDB 还支持行级锁。
|
||||
|
||||
**其它特性**
|
||||
|
||||
MyISAM 支持全文索引,地理空间索引;
|
||||
|
||||
# 数据类型
|
||||
|
||||
## 1. 整型
|
||||
|
||||
TINYINT, SMALLINT, MEDIUMINT, INT, BIGINT 分别使用 8, 16, 24, 64 位存储空间,一般情况下越小的列越好。
|
||||
|
||||
INT(11) 中的数字只是规定了交互工具显示字符的个数,对于存储和计算来说是没有意义的。
|
||||
|
||||
## 2. 浮点数
|
||||
|
||||
FLOAT 和 DOUBLE 为浮点类型,DECIMAL 为高精度小数类型。CPU 原生支持浮点运算,但是不支持 DECIMAl 类型的计算,因此 DECIMAL 的计算比浮点类型需要更高的代价。
|
||||
|
||||
FLOAT、DOUBLE 和 DECIMAL 都可以指定列宽,例如 DECIMAL(18, 9) 表示总共 18 位,取 9 位存储小数部分,剩下 9 位存储整数部分。
|
||||
|
||||
## 3. 字符串
|
||||
|
||||
主要有 CHAR 和 VARCHAR 两种类型,一种是定长的,一种是变长的。
|
||||
|
||||
VARCHAR 这种变长类型能够节省空间,因为只需要存储必要的内容。但是在执行 UPDATE 时可能会使行变得比原来长,当超出一个页所能容纳的大小时,就要执行额外的操作,MyISAM 会将行拆成不同的片段存储,而 InnoDB 则需要分裂页来使行放进页内。
|
||||
|
||||
VARCHAR 会保留字符串末尾的空格,而 CHAR 会删除。
|
||||
|
||||
## 4. 时间和日期
|
||||
|
||||
MySQL 提供了两种相似的日期时间类型:DATATIME 和 TIMESTAMP。
|
||||
|
||||
**DATATIME**
|
||||
|
||||
能够保存从 1001 年到 9999 年的日期和时间,精度为秒,使用 8 字节的存储空间。
|
||||
|
||||
它与时区无关。
|
||||
|
||||
默认情况下,MySQL 以一种可排序的、无歧义的格式显示 DATATIME 值,例如“2008-01016 22:37:08”,这是 ANSI 标准定义的日期和时间表示方法。
|
||||
|
||||
**TIMESTAMP**
|
||||
|
||||
和 UNIX 时间戳相同,保存从 1970 年 1 月 1 日午夜(格林威治时间)以来的秒数,使用 4 个字节,只能表示从 1970 年 到 2038 年。
|
||||
|
||||
它和时区有关。
|
||||
|
||||
MySQL 提供了 FROM_UNIXTIME() 函数把 Unxi 时间戳转换为日期,并提供了 UNIX_TIMESTAMP() 函数把日期转换为 Unix 时间戳。
|
||||
|
||||
默认情况下,如果插入时没有指定 TIMESTAMP 列的值,会将这个值设置为当前时间。
|
||||
|
||||
应该尽量使用 TIMESTAMP,因为它比 DATETIME 空间效率更高。
|
||||
|
||||
# 索引
|
||||
|
||||
索引是在存储引擎层实现的,而不是在服务器层实现的,所以不同存储引擎具有不同的索引类型和实现。
|
||||
|
||||
索引能够轻易将查询性能提升几个数量级。
|
||||
|
||||
对于非常小的表、大部分情况下简单的全表扫描比建立索引更高效。对于中到大型的表,索引就非常有效。但是对于特大型的表,建立和使用索引的代价将会随之增长。这种情况下,需要用到一种技术可以直接区分出需要查询的一组数据,而不是一条记录一条记录地匹配,例如可以使用分区技术。
|
||||
|
||||
## 1. 索引分类
|
||||
|
||||
### 1.1 B-Tree 索引
|
||||
|
||||
B-Tree 索引是大多数 MySQL 存储引擎的默认索引类型。
|
||||
|
||||
因为不再需要进行全表扫描,只需要对树进行搜索即可,因此查找速度快很多。
|
||||
|
||||
可以指定多个列作为索引列,多个索引列共同组成键。B-Tree 索引适用于全键值、键值范围和键前缀查找,其中键前缀查找只适用于最左前缀查找。
|
||||
|
||||
除了用于查找,还可以用于排序和分组。
|
||||
|
||||
如果不是按照索引列的顺序进行查找,则无法使用索引。
|
||||
|
||||
### 1.2 哈希索引
|
||||
|
||||
基于哈希表实现,优点是查找非常快。
|
||||
|
||||
在 MySQL 中只有 Memory 引擎显式支持哈希索引。
|
||||
|
||||
InnoDB 引擎有一个特殊的功能叫“自适应哈希索引”,当某个索引值被使用的非常频繁时,会在 B-Tree 索引之上再创建一个哈希索引,这样就让 B-Tree 索引具有哈希索引的一些优点,比如快速的哈希查找。
|
||||
|
||||
限制:哈希索引只包含哈希值和行指针,而不存储字段值,所以不能使用索引中的值来避免读取行。不过,访问内存中的行的速度很快,所以大部分情况下这一点对性能影响并不明显;无法用于分组与排序;只支持精确查找,无法用于部分查找和范围查找;如果哈希冲突很多,查找速度会变得很慢。
|
||||
|
||||
### 1.3. 空间索引数据(R-Tree)
|
||||
|
||||
MyISAM 存储引擎支持空间索引,可以用于地理数据存储。
|
||||
|
||||
空间索引会从所有维度来索引数据,可以有效地使用任意维度来进行组合查询。
|
||||
|
||||
### 1.4 全文索引
|
||||
|
||||
MyISAM 存储引擎支持全文索引,用于查找文本中的关键词,而不是直接比较索引中的值。
|
||||
|
||||
使用 MATCH AGAINST,而不是普通的 WHERE。
|
||||
|
||||
## 2. 索引的优点
|
||||
|
||||
- 大大减少了服务器需要扫描的数据量;
|
||||
|
||||
- 帮助服务器避免进行排序和创建临时表;
|
||||
|
||||
- 将随机 I/O 变为顺序 I/O。
|
||||
|
||||
## 3. 索引优化
|
||||
|
||||
### 3.1 独立的列
|
||||
|
||||
在进行查询时,索引列不能是表达式的一部分,也不能是函数的参数,否则无法使用索引。
|
||||
|
||||
例如下面的查询不能使用 actor_id 列的索引:
|
||||
|
||||
```sql
|
||||
SELECT actor_id FROM sakila.actor WHERE actor_id + 1 = 5;
|
||||
```
|
||||
|
||||
### 3.2 前缀索引
|
||||
|
||||
对于 BLOB、TEXT 和 VARCHAR 类型的列,必须使用前缀索引,只索引开始的部分字符。
|
||||
|
||||
对于前缀长度的选取需要根据 **索引选择性** 来确定:不重复的索引值和记录总数的比值。选择性越高,查询效率也越高。最大值为 1 ,此时每个记录都有唯一的索引与其对应。
|
||||
|
||||
### 3.3 多列索引
|
||||
|
||||
在需要使用多个列作为条件进行查询时,使用多列索引比使用多个单列索引性能更好。例如下面的语句中,最好把 actor_id 和 file_id 设置为多列索引。
|
||||
|
||||
```sql
|
||||
SELECT file_id, actor_ id FROM sakila.film_actor
|
||||
WhERE actor_id = 1 OR film_id = 1;
|
||||
```
|
||||
|
||||
### 3.4 索引列的顺序
|
||||
|
||||
让选择性最强的索引列放在前面,例如下面显示的结果中 customer_id 的选择性比 staff_id 更高,因此最好把 customer_id 列放在多列索引的前面。
|
||||
|
||||
```sql
|
||||
SELECT COUNT(DISTINCT staff_id)/COUNT(*) AS staff_id_selectivity,
|
||||
COUNT(DISTINCT customer_id)/COUNT(*) AS customer_id_selectivity,
|
||||
COUNT(*)
|
||||
FROM payment;
|
||||
```
|
||||
|
||||
```html
|
||||
staff_id_selectivity: 0.0001
|
||||
customer_id_selectivity: 0.0373
|
||||
COUNT(*): 16049
|
||||
```
|
||||
|
||||
### 3.5 聚簇索引
|
||||
|
||||

|
||||
|
||||
聚簇索引并不是一种索引类型,而是一种数据存储方式。
|
||||
|
||||
术语“聚簇”表示数据行和相邻的键值紧密地存储在一起,InnoDB 的聚簇索引的数据行存放在 B-Tree 的叶子页中。
|
||||
|
||||
因为无法把数据行存放在两个不同的地方,所以一个表只能有一个聚簇索引。
|
||||
|
||||
**优点**
|
||||
|
||||
1. 可以把相关数据保存在一起,减少 I/O 操作;
|
||||
2. 因为数据保存在 B-Tree 中,因此数据访问更快。
|
||||
|
||||
**缺点**
|
||||
|
||||
1. 聚簇索引最大限度提高了 I/O 密集型应用的性能,但是如果数据全部放在内存,就没必要用聚簇索引。
|
||||
2. 插入速度严重依赖于插入顺序,按主键的顺序插入是最快的。
|
||||
3. 更新操作代价很高,因为每个被更新的行都会移动到新的位置。
|
||||
4. 当插入到某个已满的页中,存储引擎会将该页分裂成两个页面来容纳该行,页分裂会导致表占用更多的磁盘空间。
|
||||
5. 如果行比较稀疏,或者由于页分裂导致数据存储不连续时,聚簇索引可能导致全表扫描速度变慢。
|
||||
|
||||
### 3.6 覆盖索引
|
||||
|
||||
索引包含所有需要查询的字段的值。
|
||||
|
||||
## 4. B-Tree 和 B+Tree 原理
|
||||
|
||||
### 4. 1 B-Tree
|
||||
|
||||

|
||||
|
||||
为了描述 B-Tree,首先定义一条数据记录为一个二元组 [key, data],key 为记录的键,data 为数据记录除 key 外的数据。
|
||||
|
||||
B-Tree 是满足下列条件的数据结构:
|
||||
|
||||
- 所有叶节点具有相同的深度,也就是说 B-Tree 是平衡的;
|
||||
- 一个节点中的 key 从左到右非递减排列;
|
||||
- 如果某个指针的左右相邻 key 分别是 key<sub>i</sub> 和 key<sub>i+1</sub>,且不为 null,则该指针指向节点的所有 key 大于 key<sub>i</sub> 且小于 key<sub>i+1</sub>。
|
||||
|
||||
在 B-Tree 中按 key 检索数据的算法非常直观:首先从根节点进行二分查找,如果找到则返回对应节点的 data,否则对相应区间的指针指向的节点递归进行查找,直到找到节点或找到 null 指针,前者查找成功,后者查找失败。
|
||||
|
||||
由于插入删除新的数据记录会破坏 B-Tree 的性质,因此在插入删除时,需要对树进行一个分裂、合并、转移等操作以保持 B-Tree 性质。
|
||||
|
||||
### 4.2 B+Tree
|
||||
|
||||

|
||||
|
||||
与 B-Tree 相比,B+Tree 有以下不同点:
|
||||
|
||||
- 每个节点的指针上限为 2d 而不是 2d+1;
|
||||
- 内节点不存储 data,只存储 key,叶子节点不存储指针。
|
||||
|
||||
### 4.3 带有顺序访问指针的 B+Tree
|
||||
|
||||

|
||||
|
||||
一般在数据库系统或文件系统中使用的 B+Tree 结构都在经典 B+Tree 基础上进行了优化,在叶子节点增加了顺序访问指针,做这个优化的目的是为了提高区间访问的性能。
|
||||
|
||||
### 4.4 为什么使用 B-Tree 和 B+Tree
|
||||
|
||||
红黑树等数据结构也可以用来实现索引,但是文件系统及数据库系统普遍采用 B-/+Tree 作为索引结构。
|
||||
|
||||
页是计算机管理存储器的逻辑块,硬件及操作系统往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(在许多操作系统中,页得大小通常为 4k),主存和磁盘以页为单位交换数据。
|
||||
|
||||
一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。为了减少磁盘 I/O,磁盘往往不是严格按需读取,而是每次都会预读。这样做的理论依据是计算机科学中著名的局部性原理:当一个数据被用到时,其附近的数据也通常会马上被使用。数据库系统的设计者巧妙利用了磁盘预读原理,将一个节点的大小设为等于一个页,这样每个节点只需要一次 I/O 就可以完全载入。B-Tree 中一次检索最多需要 h-1 次 I/O(根节点常驻内存),渐进复杂度为 O(h)=O(logdN)。一般实际应用中,出度 d 是非常大的数字,通常超过 100,因此 h 非常小(通常不超过 3)。而红黑树这种结构,h 明显要深的多。并且于逻辑上很近的节点(父子)物理上可能很远,无法利用局部性,效率明显比 B-Tree 差很多。
|
||||
|
||||
B+Tree 更适合外存索引,原因和内节点出度 d 有关。由于 B+Tree 内节点去掉了 data 域,因此可以拥有更大的出度,拥有更好的性能。
|
||||
|
||||
# 查询性能优化
|
||||
|
||||
## 1. Explain
|
||||
|
||||
用来分析 SQL 语句,分析结果中比较重要的字段有:
|
||||
|
||||
- select_type : 查询类型,有简单查询、联合查询和子查询
|
||||
|
||||
- key : 使用的索引
|
||||
|
||||
- rows : 扫描的行数
|
||||
|
||||
## 2. 减少返回的列
|
||||
|
||||
慢查询主要是因为访问了过多数据,除了访问过多行之外,也包括访问过多列。
|
||||
|
||||
最好不要使用 SELECT * 语句,要根据需要选择查询的列。
|
||||
|
||||
## 3. 减少返回的行
|
||||
|
||||
最好使用 LIMIT 语句来取出想要的那些行。
|
||||
|
||||
还可以建立索引来减少条件语句的全表扫描。例如对于下面的语句,不适用索引的情况下需要进行全表扫描,而使用索引只需要扫描几行记录即可,使用 Explain 语句可以通过观察 rows 字段来看出这种差异。
|
||||
|
||||
```sql
|
||||
SELECT * FROM sakila.film_actor WHERE film_id = 1;
|
||||
```
|
||||
|
||||
## 4. 拆分大的 DELETE 或 INSERT 语句
|
||||
|
||||
如果一次性执行的话,可能一次锁住很多数据、占满整个事务日志、耗尽系统资源、阻塞很多小的但重要的查询。
|
||||
|
||||
```sql
|
||||
DELEFT FROM messages WHERE create < DATE_SUB(NOW(), INTERVAL 3 MONTH);
|
||||
```
|
||||
```sql
|
||||
rows_affected = 0
|
||||
do {
|
||||
rows_affected = do_query(
|
||||
"DELETE FROM messages WHERE create < DATE_SUB(NOW(), INTERVAL 3 MONTH) LIMIT 10000")
|
||||
} while rows_affected > 0
|
||||
```
|
||||
|
||||
# 分库与分表
|
||||
|
||||
**1. 分表与分区的不同**
|
||||
|
||||
分表,就是讲一张表分成多个小表,这些小表拥有不同的表名;而分区是将一张表的数据分为多个区块,这些区块可以存储在同一个磁盘上,也可以存储在不同的磁盘上,这种方式下表仍然只有一个。
|
||||
|
||||
**2. 使用分库与分表的原因**
|
||||
|
||||
随着时间和业务的发展,数据库中的表会越来越多,并且表中的数据量也会越来越大,那么读写操作的开销也会随着增大。
|
||||
|
||||
**3. 垂直切分**
|
||||
|
||||
将表按功能模块、关系密切程度划分出来,部署到不同的库上。例如,我们会建立商品数据库 payDB、用户数据库 userDB 等,分别用来存储项目与商品有关的表和与用户有关的表。
|
||||
|
||||
**4. 水平切分**
|
||||
|
||||
把表中的数据按照某种规则存储到多个结构相同的表中,例如按 id 的散列值、性别等进行划分,
|
||||
|
||||
**5. 垂直切分与水平切分的选择**
|
||||
|
||||
如果数据库中的表太多,并且项目各项业务逻辑清晰,那么垂直切分是首选。
|
||||
|
||||
如果数据库的表不多,但是单表的数据量很大,应该选择水平切分。
|
||||
|
||||
**6. 水平切分的实现方式**
|
||||
|
||||
最简单的是使用 merge 存储引擎。
|
||||
|
||||
**7. 分库与分表存在的问题**
|
||||
|
||||
(1) 事务问题
|
||||
|
||||
在执行分库分表之后,由于数据存储到了不同的库上,数据库事务管理出现了困难。如果依赖数据库本身的分布式事务管理功能去执行事务,将付出高昂的性能代价;如果由应用程序去协助控制,形成程序逻辑上的事务,又会造成编程方面的负担。
|
||||
|
||||
(2) 跨库跨表连接问题
|
||||
|
||||
在执行了分库分表之后,难以避免会将原本逻辑关联性很强的数据划分到不同的表、不同的库上。这时,表的连接操作将受到限制,我们无法连接位于不同分库的表,也无法连接分表粒度不同的表,导致原本只需要一次查询就能够完成的业务需要进行多次才能完成。
|
||||
|
||||
# 故障转移和故障恢复
|
||||
|
||||
故障转移也叫做切换,当主库出现故障时就切换到备库,使备库成为主库。故障恢复顾名思义就是从故障中恢复过来,并且保证数据的正确性。
|
||||
|
||||
## 1. 故障转移
|
||||
|
||||
**1.1 提升备库或切换角色**
|
||||
|
||||
提升一台备库为主库,或者在一个主-主复制结构中调整主动和被动角色。
|
||||
|
||||
**1.2 虚拟 IP 地址和 IP 托管**
|
||||
|
||||
为 MySQL 实例指定一个逻辑 IP 地址,当 MySQL 实例失效时,可以将 IP 地址转移到另一台 MySQL 服务器上。
|
||||
|
||||
**1.3 中间件解决方案**
|
||||
|
||||
通过代理,可以路由流量到可以使用的服务器上。
|
||||
|
||||

|
||||
|
||||
**1.4 在应用中处理故障转移**
|
||||
|
||||
将故障转移整合到应用中可能导致应用变得太过笨拙。
|
||||
|
||||
## 2. 故障恢复
|
||||
|
||||
|
||||
# 参考资料
|
||||
|
||||
- 高性能 MySQL
|
||||
- [MySQL 索引背后的数据结构及算法原理 ](http://blog.codinglabs.org/articles/theory-of-mysql-index.html)
|
||||
- [MySQL 索引优化全攻略 ](http://www.runoob.com/w3cnote/mysql-index.html)
|
||||
- [20+ 条 MySQL 性能优化的最佳经验 ](https://www.jfox.info/20-tiao-mysql-xing-nen-you-hua-de-zui-jia-jing-yan.html)
|
||||
734
notes/SQL 语法.md
Normal file
734
notes/SQL 语法.md
Normal file
@ -0,0 +1,734 @@
|
||||
<!-- GFM-TOC -->
|
||||
* [基础](#基础)
|
||||
* [查询](#查询)
|
||||
* [排序](#排序)
|
||||
* [过滤](#过滤)
|
||||
* [通配符](#通配符)
|
||||
* [计算字段](#计算字段)
|
||||
* [函数](#函数)
|
||||
* [文本处理](#文本处理)
|
||||
* [日期和时间处理](#日期和时间处理)
|
||||
* [数值处理](#数值处理)
|
||||
* [汇总](#汇总)
|
||||
* [分组](#分组)
|
||||
* [子查询](#子查询)
|
||||
* [连接](#连接)
|
||||
* [内连接](#内连接)
|
||||
* [自连接](#自连接)
|
||||
* [自然连接](#自然连接)
|
||||
* [外连接](#外连接)
|
||||
* [组合查询](#组合查询)
|
||||
* [插入](#插入)
|
||||
* [更新](#更新)
|
||||
* [删除](#删除)
|
||||
* [创建表](#创建表)
|
||||
* [修改表](#修改表)
|
||||
* [视图](#视图)
|
||||
* [存储过程](#存储过程)
|
||||
* [游标](#游标)
|
||||
* [触发器](#触发器)
|
||||
* [事务处理](#事务处理)
|
||||
* [字符集](#字符集)
|
||||
* [权限管理](#权限管理)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
# 基础
|
||||
|
||||
模式:定义了数据如何存储、存储什么样的数据以及数据如何分解等信息,数据库和表都有模式。
|
||||
|
||||
主键的值不允许修改,也不允许复用(不能使用已经删除的主键值赋给新数据行的主键)。
|
||||
|
||||
SQL(Structured Query Language),标准 SQL 由 ANSI 标准委员会管理,从而称为 ANSI SQL,各个 DBMS 都有自己的实现,如 PL/SQL、Transact-SQL 等。
|
||||
|
||||
# 查询
|
||||
|
||||
SQL 语句不区分大小写,但是数据库表名、列名和值是否区分依赖于具体的 DBMS 以及配置。
|
||||
|
||||
**DISTINCT**
|
||||
|
||||
相同值只会出现一次。它作用于所有列,也就是说所有列的值都相同才算相同。
|
||||
|
||||
```sql
|
||||
SELECT DISTINCT col1, col2
|
||||
FROM mytable;
|
||||
```
|
||||
|
||||
**LIMIT**
|
||||
|
||||
限制返回的行数。可以有两个参数,第一个参数为起始行,从 0 开始;第二个参数为返回的总行数。
|
||||
|
||||
返回前 5 行的 SQL:
|
||||
|
||||
```sql
|
||||
SELECT *
|
||||
FROM mytable
|
||||
LIMIT 5;
|
||||
```
|
||||
|
||||
```sql
|
||||
SELECT *
|
||||
FROM mytable
|
||||
LIMIT 0, 5;
|
||||
```
|
||||
|
||||
返回第 3 \~ 5 行:
|
||||
|
||||
```sql
|
||||
SELECT *
|
||||
FROM mytable
|
||||
LIMIT 2, 3;
|
||||
```
|
||||
|
||||
**注释**
|
||||
|
||||
```sql
|
||||
# 注释
|
||||
SELECT *
|
||||
FROM mytable -- 注释
|
||||
/* 注释1
|
||||
注释2 */
|
||||
```
|
||||
|
||||
# 排序
|
||||
|
||||
**ASC**:升序(默认)
|
||||
**DESC**:降序
|
||||
|
||||
可以按多个列进行排序:
|
||||
|
||||
```sql
|
||||
SELECT *
|
||||
FROM mytable
|
||||
ORDER BY col1 DESC, col2 ASC;
|
||||
```
|
||||
|
||||
# 过滤
|
||||
|
||||
在应用层也可以过滤数据,但是不在服务器端进行过滤的数据非常大,导致通过网络传输了很多多余的数据,从而浪费了网络带宽。
|
||||
|
||||
```sql
|
||||
SELECT *
|
||||
FROM mytable
|
||||
WHERE col IS NULL;
|
||||
```
|
||||
|
||||
下表显示了 WHERE 子句可用的操作符
|
||||
|
||||
| 操作符 | 说明 |
|
||||
| ------------ | ------------ |
|
||||
| = < > | 等于 小于 大于 |
|
||||
| <> != | 不等于 |
|
||||
| <= !> | 小于等于 |
|
||||
| >= !< | 大于等于 |
|
||||
| BETWEEN | 在两个值之间 |
|
||||
| IS NULL | 为NULL值 |
|
||||
|
||||
应该注意到,NULL 与 0 、空字符串都不同。
|
||||
|
||||
**AND OR** 用于连接多个过滤条件。优先处理 AND,因此当一个过滤表达式涉及到多个 AND 和 OR 时,应当使用 () 来决定优先级。
|
||||
|
||||
**IN** 操作符用于匹配一组值,其后也可以接一个 SELECT 子句,从而匹配子查询得到的一组值。
|
||||
|
||||
**NOT** 操作符用于否定一个条件。
|
||||
|
||||
# 通配符
|
||||
|
||||
通配符也是用在过滤语句中,只能用于文本字段。
|
||||
|
||||
- **%** 匹配 >=0 个任意字符,类似于 \*;
|
||||
|
||||
- **\_** 匹配 ==1 个任意字符,类似于 \.;
|
||||
|
||||
- **[ ]** 可以匹配集合内的字符,用脱字符 ^ 可以对其进行否定
|
||||
|
||||
使用 Like 来进行通配符匹配。
|
||||
|
||||
```sql
|
||||
SELECT *
|
||||
FROM mytable
|
||||
WHERE col LIKE '[^AB]%' -- 不以AB开头的任意文本
|
||||
```
|
||||
|
||||
不要滥用通配符,通配符位于开头处匹配会非常慢。
|
||||
|
||||
# 计算字段
|
||||
|
||||
在数据库服务器上完成数据的转换和格式化的工作往往比客户端上快得多,并且转换和格式化后的数据量更少的话可以减少网络通信量。
|
||||
|
||||
计算字段通常需要使用 **AS** 来取别名,否则输出的时候字段名为计算表达式。
|
||||
|
||||
```sql
|
||||
SELECT col1*col2 AS alias
|
||||
FROM mytable
|
||||
```
|
||||
|
||||
**Concat()** 用于连接两个字段。许多数据库会使用空格把一个值填充为列宽,因此连接的结果会出现一些不必要的空格,使用 **TRIM()** 可以去除首尾空格。
|
||||
|
||||
```sql
|
||||
SELECT Concat(TRIM(col1), ' (', TRIM(col2), ')')
|
||||
FROM mytable
|
||||
```
|
||||
|
||||
# 函数
|
||||
|
||||
各个 DBMS 的函数都是不相同的,因此不可移植。
|
||||
|
||||
## 文本处理
|
||||
|
||||
| 函数 | 说明 |
|
||||
| ------------ | ------------ |
|
||||
| LEFT() RIGHT() | 左边或者右边的字符 |
|
||||
| LOWER() UPPER() | 转换为小写或者大写 |
|
||||
| LTRIM() RTIM() | 去除左边或者右边的空格 |
|
||||
| LENGTH() | 长度 |
|
||||
| SUNDEX() | 转换为语音值 |
|
||||
|
||||
其中,**SOUNDEX()** 是将一个字符串转换为描述其语音表示的字母数字模式的算法,它是根据发音而不是字母比较。
|
||||
|
||||
```sql
|
||||
SELECT *
|
||||
FROM mytable
|
||||
WHERE SOUNDEX(col1) = SOUNDEX('apple')
|
||||
```
|
||||
## 日期和时间处理
|
||||
|
||||
日期格式:YYYY-MM-DD
|
||||
|
||||
时间格式:HH:MM:SS
|
||||
|
||||
|函 数 | 说 明|
|
||||
| --- | --- |
|
||||
| AddDate() | 增加一个日期(天、周等)|
|
||||
| AddTime() | 增加一个时间(时、分等)|
|
||||
| CurDate() | 返回当前日期 |
|
||||
| CurTime() | 返回当前时间 |
|
||||
|Date() |返回日期时间的日期部分|
|
||||
|DateDiff() |计算两个日期之差|
|
||||
|Date_Add() |高度灵活的日期运算函数|
|
||||
|Date_Format() |返回一个格式化的日期或时间串|
|
||||
|Day()| 返回一个日期的天数部分|
|
||||
|DayOfWeek() |对于一个日期,返回对应的星期几|
|
||||
|Hour() |返回一个时间的小时部分|
|
||||
|Minute() |返回一个时间的分钟部分|
|
||||
|Month() |返回一个日期的月份部分|
|
||||
|Now() |返回当前日期和时间|
|
||||
|Second() |返回一个时间的秒部分|
|
||||
|Time() |返回一个日期时间的时间部分|
|
||||
|Year() |返回一个日期的年份部分|
|
||||
|
||||
```sql
|
||||
mysql> SELECT NOW();
|
||||
-> '2017-06-28 14:01:52'
|
||||
```
|
||||
|
||||
## 数值处理
|
||||
|
||||
| 函数 | 说明 |
|
||||
| --- | --- |
|
||||
| SIN() | 正弦 |
|
||||
|COS() | 余弦 |
|
||||
| TAN() | 正切 |
|
||||
| ABS() | 绝对值 |
|
||||
| SQRT() | 平方根|
|
||||
| MOD() | 余数|
|
||||
| EXP() | 指数|
|
||||
| PI() | 圆周率|
|
||||
|RAND() | 随机数|
|
||||
|
||||
## 汇总
|
||||
|
||||
|函 数 |说 明|
|
||||
| --- | --- |
|
||||
|AVG() |返回某列的平均值|
|
||||
|COUNT()| 返回某列的行数|
|
||||
|MAX()| 返回某列的最大值|
|
||||
|MIN()| 返回某列的最小值|
|
||||
|SUM() |返回某列值之和|
|
||||
|
||||
AVG() 会忽略 NULL 行。
|
||||
|
||||
DISTINCT 关键字会只汇总不同的值。
|
||||
|
||||
```sql
|
||||
SELECT AVG(DISTINCT col1) AS avg_col
|
||||
FROM mytable
|
||||
```
|
||||
|
||||
# 分组
|
||||
|
||||
分组就是把相同的数据放在同一组中。
|
||||
|
||||
可以对每组数据使用汇总函数进行处理,例如求每组数的平均值等。
|
||||
|
||||
按 col 排序并分组数据:
|
||||
|
||||
```sql
|
||||
SELECT col, COUNT(*) AS num
|
||||
FROM mytable
|
||||
GROUP BY col;
|
||||
```
|
||||
|
||||
WHERE 过滤行,HAVING 过滤分组,行过滤应当先与分组过滤;
|
||||
|
||||
```sql
|
||||
SELECT col, COUNT(*) AS num
|
||||
FROM mytable
|
||||
WHERE col > 2
|
||||
GROUP BY col
|
||||
HAVING COUNT(*) >= 2;
|
||||
```
|
||||
|
||||
GROUP BY 的排序结果为分组字段,而 ORDER BY 也可以以聚集字段来进行排序。
|
||||
|
||||
```sql
|
||||
SELECT col, COUNT(*) AS num
|
||||
FROM mytable
|
||||
GROUP BY col
|
||||
ORDER BY num;
|
||||
```
|
||||
|
||||
分组规定:
|
||||
|
||||
1. GROUP BY 子句出现在 WHERE 子句之后,ORDER BY 子句之前;
|
||||
2. 除了汇总计算语句之外,SELECT 语句中的每一列都必须在 GROUP BY 子句中给出;
|
||||
3. NULL 的行会单独分为一组;
|
||||
4. 大多数 SQL 实现不支持 GROUP BY 列具有可变长度的数据类型。
|
||||
|
||||
# 子查询
|
||||
|
||||
子查询中只能返回一个列。
|
||||
|
||||
可以将子查询的结果作为 WHRER 语句的过滤条件:
|
||||
|
||||
```
|
||||
SELECT *
|
||||
FROM mytable1
|
||||
WHERE col1 IN (SELECT col2
|
||||
FROM mytable2);
|
||||
```
|
||||
|
||||
下面的语句可以检索出客户的订单数量。子查询语句会对检索出的每个客户执行一次:
|
||||
|
||||
```sql
|
||||
SELECT cust_name, (SELECT COUNT(*)
|
||||
FROM Orders
|
||||
WHERE Orders.cust_id = Customers.cust_id)
|
||||
AS orders_num
|
||||
FROM Customers
|
||||
ORDER BY cust_name;
|
||||
```
|
||||
|
||||
# 连接
|
||||
|
||||
连接用于连接多个表,使用 JOIN 关键字,并且条件语句使用 ON。
|
||||
|
||||
连接可以替换子查询,并且比子查询的效率一般会更快。
|
||||
|
||||
可以用 AS 给列名、计算字段和表名取别名,给表名取别名是为了简化 SQL 语句以及连接相同表。
|
||||
|
||||
## 内连接
|
||||
|
||||
内连接又称等值连接,使用 INNER JOIN 关键字。
|
||||
|
||||
```
|
||||
select a, b, c
|
||||
from A inner join B
|
||||
on A.key = B.key
|
||||
```
|
||||
|
||||
可以不明确使用 INNER JOIN,而使用普通查询并在 WHERE 中将两个表中要连接的列用等值方法连接起来。
|
||||
|
||||
```
|
||||
select a, b, c
|
||||
from A, B
|
||||
where A.key = B.key
|
||||
```
|
||||
|
||||
在没有条件语句的情况下返回笛卡尔积。
|
||||
|
||||
## 自连接
|
||||
|
||||
自连接可以看成内连接的一种,只是连接的表是自身而已。
|
||||
|
||||
一张员工表,包含员工姓名和员工所属部门,要找出与 Jim 处在同一部门的所有员工姓名。
|
||||
|
||||
**子查询版本**
|
||||
|
||||
```
|
||||
select name
|
||||
from employee
|
||||
where department = (
|
||||
select department
|
||||
from employee
|
||||
where name = "Jim");
|
||||
```
|
||||
|
||||
**自连接版本**
|
||||
|
||||
```
|
||||
select name
|
||||
from employee as e1, employee as e2
|
||||
where e1.department = e2.department
|
||||
and e1.name = "Jim";
|
||||
```
|
||||
|
||||
连接一般比子查询的效率高。
|
||||
|
||||
## 自然连接
|
||||
|
||||
自然连接是把同名列通过等值测试连接起来的,同名列可以有多个。
|
||||
|
||||
内连接和自然连接的区别:内连接提供连接的列,而自然连接自动连接所有同名列;内连接属于自然连接。
|
||||
|
||||
```
|
||||
select *
|
||||
from employee natural join department;
|
||||
```
|
||||
|
||||
## 外连接
|
||||
|
||||
外连接保留了没有关联的那些行。分为左外连接,右外连接以及全外连接,左外连接就是保留左表的所有行。
|
||||
|
||||
检索所有顾客的订单信息,包括还没有订单信息的顾客。
|
||||
|
||||
```
|
||||
select Customers.cust_id, Orders.order_num
|
||||
from Customers left outer join Orders
|
||||
on Customers.cust_id = Orders.curt_id
|
||||
```
|
||||
|
||||
如果需要统计顾客的订单数,使用聚集函数。
|
||||
|
||||
```
|
||||
select Customers.cust_id,
|
||||
COUNT(Orders.order_num) as num_ord
|
||||
from Customers left outer join Orders
|
||||
on Customers.cust_id = Orders.curt_id
|
||||
group by Customers.cust_id
|
||||
```
|
||||
|
||||
# 组合查询
|
||||
|
||||
使用 **UNION** 来连接两个查询,每个查询必须包含相同的列、表达式或者聚集函数。
|
||||
|
||||
默认会去除相同行,如果需要保留相同行,使用 UNION ALL 。
|
||||
|
||||
只能包含一个 ORDER BY 子句,并且必须位于语句的最后。
|
||||
|
||||
```sql
|
||||
SELECT col
|
||||
FROM mytable
|
||||
WHERE col = 1
|
||||
UNION
|
||||
SELECT col
|
||||
FROM mytable
|
||||
WHERE col =2;
|
||||
```
|
||||
|
||||
# 插入
|
||||
|
||||
**普通插入**
|
||||
|
||||
```sql
|
||||
INSERT INTO mytable(col1, col2)
|
||||
VALUES(val1, val2);
|
||||
```
|
||||
|
||||
**插入检索出来的数据**
|
||||
|
||||
```sql
|
||||
INSERT INTO mytable1(col1, col2)
|
||||
SELECT col1, col2
|
||||
FROM mytable2;
|
||||
```
|
||||
|
||||
**将一个表的内容复制到一个新表**
|
||||
|
||||
```sql
|
||||
CREATE TABLE newtable AS
|
||||
SELECT * FROM mytable;
|
||||
```
|
||||
|
||||
# 更新
|
||||
|
||||
```sql
|
||||
UPDATE mytable
|
||||
SET col = val
|
||||
WHERE id = 1;
|
||||
```
|
||||
|
||||
# 删除
|
||||
|
||||
```sql
|
||||
DELETE FROM mytable
|
||||
WHERE id = 1;
|
||||
```
|
||||
|
||||
**TRUNCATE TABLE** 可以清空表,也就是删除所有行。
|
||||
|
||||
使用更新和删除操作时一定要用 WHERE 子句,不然会把整张表的数据都破坏。可以先用 SELECT 语句进行测试,防止错误删除。
|
||||
|
||||
# 创建表
|
||||
|
||||
```sql
|
||||
CREATE TABLE mytable (
|
||||
id INT NOT NULL AUTO_INCREMENT,
|
||||
col1 INT NOT NULL DEFAULT 1,
|
||||
col2 VARCHAR(45) NULL,
|
||||
col3 DATE NULL,
|
||||
PRIMARY KEY (`id`));
|
||||
```
|
||||
|
||||
# 修改表
|
||||
|
||||
**添加列**
|
||||
|
||||
```sql
|
||||
ALTER TABLE mytable
|
||||
ADD col CHAR(20);
|
||||
```
|
||||
|
||||
**删除列**
|
||||
|
||||
```sql
|
||||
ALTER TABLE mytable
|
||||
DROP COLUMN col;
|
||||
```
|
||||
|
||||
**删除表**
|
||||
|
||||
```sql
|
||||
DROP TABLE mytable;
|
||||
```
|
||||
|
||||
# 视图
|
||||
|
||||
视图是虚拟的表,本身不包含数据,也就不能对其进行索引操作。对视图的操作和对普通表的操作一样。
|
||||
|
||||
视图具有如下好处:
|
||||
|
||||
1. 简化复杂的 SQL 操作,比如复杂的联结;
|
||||
2. 只使用实际表的一部分数据;
|
||||
3. 通过只给用户访问视图的权限,保证数据的安全性;
|
||||
4. 更改数据格式和表示。
|
||||
|
||||
```sql
|
||||
CREATE VIEW myview AS
|
||||
SELECT Concat(col1, col2) AS concat_col, col3*col4 AS count_col
|
||||
FROM mytable
|
||||
WHERE col5 = val;
|
||||
```
|
||||
|
||||
# 存储过程
|
||||
|
||||
存储过程可以看成是对一系列 SQL 操作的批处理;
|
||||
|
||||
**使用存储过程的好处**
|
||||
|
||||
1. 把实现封装在了存储过程中,不仅简单,也保证了安全性;
|
||||
2. 可以复用代码;
|
||||
3. 由于是预先编译,因此具有很高的性能。
|
||||
|
||||
**创建存储过程**
|
||||
|
||||
命令行中创建存储过程需要自定义分隔符,因为命令行是以 ; 为结束符,而存储过程中也包含了分号,因此会错误把这部分分号当成是结束符,造成语法错误。
|
||||
|
||||
包含 in、out 和 inout 三种参数。
|
||||
|
||||
给变量赋值都需要用 select into 语句。
|
||||
|
||||
每次只能给一个变量赋值,不支持集合的操作。
|
||||
|
||||
```sql
|
||||
delimiter //
|
||||
|
||||
create procedure myprocedure( out ret int )
|
||||
begin
|
||||
declare y int;
|
||||
select sum(col1)
|
||||
from mytable
|
||||
into y;
|
||||
select y*y into ret;
|
||||
end //
|
||||
delimiter ;
|
||||
```
|
||||
|
||||
```sql
|
||||
call myprocedure(@ret);
|
||||
select @ret;
|
||||
```
|
||||
|
||||
# 游标
|
||||
|
||||
在存储过程中使用游标可以对一个结果集进行移动遍历。
|
||||
|
||||
游标主要用于交互式应用,其中用户需要对数据集中的任意行进行浏览和修改。
|
||||
|
||||
**使用游标的四个步骤:**
|
||||
|
||||
1. 声明游标,这个过程没有实际检索出数据;
|
||||
2. 打开游标;
|
||||
3. 取出数据;
|
||||
4. 关闭游标;
|
||||
|
||||
```sql
|
||||
delimiter //
|
||||
create procedure myprocedure(out ret int)
|
||||
begin
|
||||
declare done boolean default 0;
|
||||
|
||||
declare mycursor cursor for
|
||||
select col1 from mytable;
|
||||
# 定义了一个continue handler,当 sqlstate '02000' 这个条件出现时,会执行 set done = 1
|
||||
declare continue handler for sqlstate '02000' set done = 1;
|
||||
|
||||
open mycursor;
|
||||
|
||||
repeat
|
||||
fetch mycursor into ret;
|
||||
select ret;
|
||||
until done end repeat;
|
||||
|
||||
close mycursor;
|
||||
end //
|
||||
delimiter ;
|
||||
```
|
||||
|
||||
# 触发器
|
||||
|
||||
触发器会在某个表执行以下语句时而自动执行:DELETE、INSERT、UPDATE
|
||||
|
||||
触发器必须指定在语句执行之前还是之后自动执行,之前执行使用 BEFORE 关键字,之后执行使用 AFTER 关键字。BEFORE 用于数据验证和净化。
|
||||
|
||||
INSERT 触发器包含一个名为 NEW 的虚拟表。
|
||||
|
||||
```sql
|
||||
CREATE TRIGGER mytrigger AFTER INSERT ON mytable
|
||||
FOR EACH ROW SELECT NEW.col;
|
||||
```
|
||||
|
||||
DELETE 触发器包含一个名为 OLD 的虚拟表,并且是只读的。
|
||||
|
||||
UPDATE 触发器包含一个名为 NEW 和一个名为 OLD 的虚拟表,其中 NEW 是可以被修改地,而 OLD 是只读的。
|
||||
|
||||
可以使用触发器来进行审计跟踪,把修改记录到另外一张表中。
|
||||
|
||||
MySQL 不允许在触发器中使用 CALL 语句 ,也就是不能调用存储过程。
|
||||
|
||||
# 事务处理
|
||||
|
||||
**基本术语**
|
||||
|
||||
1. 事务(transaction)指一组 SQL 语句;
|
||||
2. 回退(rollback)指撤销指定 SQL 语句的过程;
|
||||
3. 提交(commit)指将未存储的 SQL 语句结果写入数据库表;
|
||||
4. 保留点(savepoint)指事务处理中设置的临时占位符(placeholder),你可以对它发布回退(与回退整个事务处理不同)。
|
||||
|
||||
不能回退 SELECT 语句,回退 SELECT 语句也没意义;也不能回退 CRETE 和 DROP 语句。
|
||||
|
||||
MySQL 的事务提交默认是隐式提交,也就是每执行一条语句就会提交一次。当出现 START TRANSACTION 语句时,会关闭隐式提交;当 COMMIT 或 ROLLBACK 语句执行后,事务会自动关闭,重新恢复隐式提交。
|
||||
|
||||
通过设置 autocommit 为 0 可以取消自动提交,直到 autocommit 被设置为 1 才会提交;autocommit 标记是针对每个连接而不是针对服务器的。
|
||||
|
||||
如果没有设置保留点,ROLLBACK 会回退到 START TRANSACTION 语句处;如果设置了保留点,并且在 ROLLBACK 中指定该保留点,则会回退到该保留点。
|
||||
|
||||
```sql
|
||||
START TRANSACTION
|
||||
// ...
|
||||
SAVEPOINT delete1
|
||||
// ...
|
||||
ROLLBACK TO delete1
|
||||
// ...
|
||||
COMMIT
|
||||
```
|
||||
|
||||
# 字符集
|
||||
|
||||
**基本术语**
|
||||
|
||||
1. 字符集为字母和符号的集合;
|
||||
2. 编码为某个字符集成员的内部表示;
|
||||
3. 校对字符指定如何比较,主要用于排序和分组。
|
||||
|
||||
除了给表指定字符集和校对外,也可以给列指定:
|
||||
|
||||
```sql
|
||||
CREATE TABLE mytable
|
||||
(col VARCHAR(10) CHARACTER SET latin COLLATE latin1_general_ci )
|
||||
DEFAULT CHARACTER SET hebrew COLLATE hebrew_general_ci;
|
||||
```
|
||||
|
||||
可以在排序、分组时指定校对:
|
||||
|
||||
```sql
|
||||
SELECT *
|
||||
FROM mytable
|
||||
ORDER BY col COLLATE latin1_general_ci;
|
||||
```
|
||||
|
||||
# 权限管理
|
||||
|
||||
MySQL 的账户信息保存在 mysql 这个数据库中。
|
||||
|
||||
```sql
|
||||
USE mysql;
|
||||
SELECT user FROM user;
|
||||
```
|
||||
|
||||
**创建账户**
|
||||
|
||||
```sql
|
||||
CREATE USER myuser IDENTIFIED BY 'mypassword';
|
||||
```
|
||||
|
||||
新创建的账户没有任何权限。
|
||||
|
||||
**修改账户名**
|
||||
|
||||
```sql
|
||||
RENAME myuser TO newuser;
|
||||
```
|
||||
|
||||
**删除账户**
|
||||
|
||||
```sql
|
||||
DROP USER myuser;
|
||||
```
|
||||
|
||||
**查看权限**
|
||||
|
||||
```sql
|
||||
SHOW GRANTS FOR myuser;
|
||||
```
|
||||

|
||||
|
||||
账户用 username@host 的形式定义,username@% 使用的是默认主机名。
|
||||
|
||||
**授予权限**
|
||||
|
||||
```sql
|
||||
GRANT SELECT, INSERT ON mydatabase.* TO myuser;
|
||||
```
|
||||
|
||||
**删除权限**
|
||||
|
||||
```sql
|
||||
REVOKE SELECT, INSERT ON mydatabase.* FROM myuser;
|
||||
```
|
||||
|
||||
GRANT 和 REVOKE 可在几个层次上控制访问权限:
|
||||
|
||||
- 整个服务器,使用 GRANT ALL和 REVOKE ALL;
|
||||
- 整个数据库,使用 ON database.\*;
|
||||
- 特定的表,使用 ON database.table;
|
||||
- 特定的列;
|
||||
- 特定的存储过程。
|
||||
|
||||
**更改密码**
|
||||
|
||||
必须使用 Password() 函数
|
||||
|
||||
```sql
|
||||
SET PASSWROD FOR myuser = Password('newpassword');
|
||||
```
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
1632
notes/算法.md
Normal file
1632
notes/算法.md
Normal file
File diff suppressed because it is too large
Load Diff
739
notes/计算机操作系统.md
Normal file
739
notes/计算机操作系统.md
Normal file
@ -0,0 +1,739 @@
|
||||
<!-- GFM-TOC -->
|
||||
* [第一章 概述](#第一章-概述)
|
||||
* [操作系统基本特征](#操作系统基本特征)
|
||||
* [1. 并发](#1-并发)
|
||||
* [2. 共享](#2-共享)
|
||||
* [3. 虚拟](#3-虚拟)
|
||||
* [4. 异步](#4-异步)
|
||||
* [系统调用](#系统调用)
|
||||
* [中断分类](#中断分类)
|
||||
* [1. 外中断](#1-外中断)
|
||||
* [2. 异常](#2-异常)
|
||||
* [3. 陷入](#3-陷入)
|
||||
* [大内核和微内核](#大内核和微内核)
|
||||
* [1. 大内核](#1-大内核)
|
||||
* [2. 微内核](#2-微内核)
|
||||
* [第二章 进程管理](#第二章-进程管理)
|
||||
* [进程与线程](#进程与线程)
|
||||
* [1. 进程](#1-进程)
|
||||
* [2. 线程](#2-线程)
|
||||
* [3. 区别](#3-区别)
|
||||
* [进程状态的切换](#进程状态的切换)
|
||||
* [调度算法](#调度算法)
|
||||
* [1. 批处理系统中的调度](#1-批处理系统中的调度)
|
||||
* [1.1 先来先服务(FCFS)](#11-先来先服务(fcfs))
|
||||
* [1.2 短作业优先(SJF)](#12-短作业优先(sjf))
|
||||
* [1.3 最短剩余时间优先(SRTN)](#13-最短剩余时间优先(srtn))
|
||||
* [2. 交互式系统中的调度](#2-交互式系统中的调度)
|
||||
* [2.1 优先权优先](#21-优先权优先)
|
||||
* [2.2 时间片轮转](#22-时间片轮转)
|
||||
* [2.3 多级反馈队列](#23-多级反馈队列)
|
||||
* [2.4 短进程优先](#24-短进程优先)
|
||||
* [3. 实时系统中的调度](#3-实时系统中的调度)
|
||||
* [进程同步](#进程同步)
|
||||
* [1. 临界区](#1-临界区)
|
||||
* [2. 同步与互斥](#2-同步与互斥)
|
||||
* [3. 信号量](#3-信号量)
|
||||
* [4. 管程](#4-管程)
|
||||
* [进程通信](#进程通信)
|
||||
* [1. 管道](#1-管道)
|
||||
* [2. 信号量](#2-信号量)
|
||||
* [3. 消息队列](#3-消息队列)
|
||||
* [4. 信号](#4-信号)
|
||||
* [5. 共享内存](#5-共享内存)
|
||||
* [6. 套接字](#6-套接字)
|
||||
* [经典同步问题](#经典同步问题)
|
||||
* [1. 读者-写者问题](#1-读者-写者问题)
|
||||
* [2. 哲学家进餐问题](#2-哲学家进餐问题)
|
||||
* [第三章 死锁](#第三章-死锁)
|
||||
* [死锁的条件](#死锁的条件)
|
||||
* [死锁的处理方法](#死锁的处理方法)
|
||||
* [1. 鸵鸟策略](#1-鸵鸟策略)
|
||||
* [2. 死锁预防](#2-死锁预防)
|
||||
* [2.1 破坏互斥条件](#21-破坏互斥条件)
|
||||
* [2.2 破坏请求与保持条件](#22-破坏请求与保持条件)
|
||||
* [2.3 破坏不可抢占条件](#23-破坏不可抢占条件)
|
||||
* [2.4 破坏环路等待](#24-破坏环路等待)
|
||||
* [3. 死锁避免](#3-死锁避免)
|
||||
* [3.1 安全状态](#31-安全状态)
|
||||
* [3.2 单个资源的银行家算法](#32-单个资源的银行家算法)
|
||||
* [3.3 多个资源的银行家算法](#33-多个资源的银行家算法)
|
||||
* [4. 死锁检测与死锁恢复](#4-死锁检测与死锁恢复)
|
||||
* [4.1 死锁检测算法](#41-死锁检测算法)
|
||||
* [4.2 死锁恢复](#42-死锁恢复)
|
||||
* [第四章 存储器管理](#第四章-存储器管理)
|
||||
* [虚拟内存](#虚拟内存)
|
||||
* [分页与分段](#分页与分段)
|
||||
* [1. 分页](#1-分页)
|
||||
* [2. 分段](#2-分段)
|
||||
* [3. 段页式](#3-段页式)
|
||||
* [4. 分页与分段区别](#4-分页与分段区别)
|
||||
* [页面置换算法](#页面置换算法)
|
||||
* [1. 最佳(Optimal)](#1-最佳(optimal))
|
||||
* [2. 先进先出(FIFO)](#2-先进先出(fifo))
|
||||
* [3. 最近最久未使用(LRU,Least Recently Used)](#3-最近最久未使用(lru,least-recently-used))
|
||||
* [4. 时钟(Clock)](#4-时钟(clock))
|
||||
* [第五章 设备管理](#第五章-设备管理)
|
||||
* [磁盘调度算法](#磁盘调度算法)
|
||||
* [1. 先来先服务(FCFS,First Come First Serverd)](#1-先来先服务(fcfs,first-come-first-serverd))
|
||||
* [2. 最短寻道时间优先(SSTF,Shortest Seek Time First)](#2-最短寻道时间优先(sstf,shortest-seek-time-first))
|
||||
* [3. 扫描算法(SCAN)](#3-扫描算法(scan))
|
||||
* [4. 循环扫描算法(CSCAN)](#4-循环扫描算法(cscan))
|
||||
* [参考资料](#参考资料)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
# 第一章 概述
|
||||
|
||||
## 操作系统基本特征
|
||||
|
||||
### 1. 并发
|
||||
|
||||
并发性是指宏观上在一段时间内能同时运行多个程序,而并行性则指同一时刻能运行多个指令。
|
||||
|
||||
并行需要硬件支持,如多流水线或者多处理器。
|
||||
|
||||
操作系统通过引入进程和线程,使得程序能够并发运行。
|
||||
|
||||
### 2. 共享
|
||||
|
||||
共享是指系统中的资源可以供多个并发的进程共同使用。
|
||||
|
||||
有两种共享方式:互斥共享和同时共享。
|
||||
|
||||
互斥共享的资源称为临界资源,例如打印机等,在同一时间只允许一个进程访问,否则会出现错误,需要用同步机制来实现对临界资源的访问。
|
||||
|
||||
### 3. 虚拟
|
||||
|
||||
虚拟技术把一个物理实体转换为多个逻辑实体。主要有两种虚拟技术:时分复用技术和空分复用技术,例如多个进程能在同一个处理器上并发执行使用了时分复用技术,让每个进程轮流占有处理器,每次只执行一小个时间片并快速切换,这样就好像有多个处理器进行处理。
|
||||
|
||||
### 4. 异步
|
||||
|
||||
异步是指进程不是一次性执行完毕,而是走走停停,以不可知的速度向前推进。
|
||||
|
||||
## 系统调用
|
||||
|
||||
如果一个进程在用户态需要用到操作系统的一些功能,就需要使用系统调用从而陷入内核,由操作系统代为完成。
|
||||
|
||||
可以由系统调用请求的功能有设备管理、文件管理、进程管理、进程通信、存储器管理等。
|
||||
|
||||
## 中断分类
|
||||
|
||||
### 1. 外中断
|
||||
|
||||
由 CPU 执行指令以外的事件引起,如 I/O 结束中断,表示设备输入/输出处理已经完成,处理器能够发送下一个输入/输出请求。此外还有时钟中断、控制台中断等。
|
||||
|
||||
### 2. 异常
|
||||
|
||||
由 CPU 执行指令的内部事件引起,如非法操作码、地址越界、算术溢出等。
|
||||
|
||||
### 3. 陷入
|
||||
|
||||
在用户程序中使用系统调用。
|
||||
|
||||
## 大内核和微内核
|
||||
|
||||
### 1. 大内核
|
||||
|
||||
大内核是将操作系统功能作为一个紧密结合的整体放到内核,由于各模块共享信息,因此有很高的性能。
|
||||
|
||||
### 2. 微内核
|
||||
|
||||
由于操作系统不断复杂,因此将一部分操作系统功能移出内核,从而降低内核的复杂性。移出的部分根据分层的原则划分成若干服务,相互独立。但是需要频繁地在用户态和核心态之间进行切换,会有一定的性能损失。
|
||||
|
||||
# 第二章 进程管理
|
||||
|
||||
## 进程与线程
|
||||
|
||||
### 1. 进程
|
||||
|
||||
进程是操作系统进行资源分配的基本单位。
|
||||
|
||||
进程控制块 (Process Control Block, PCB) 描述进程的基本信息和运行状态,所谓的创建进程和撤销进程,都是指对 PCB 的操作。
|
||||
|
||||
### 2. 线程
|
||||
|
||||
一个线程中可以有多个线程,是独立调度的基本单位。同一个进程中的多个线程之间可以并发执行,它们共享进程资源。
|
||||
|
||||
### 3. 区别
|
||||
|
||||
① 拥有资源:进程是资源分配的基本单位,但是线程不拥有资源,线程可以访问率属进程的资源。
|
||||
|
||||
② 调度:线程是独立调度的基本单位,在同一进程中,线程的切换不会引起进程切换,从一个进程内的线程切换到另一个进程中的线程时,会引起进程切换。
|
||||
|
||||
③ 系统开销:由于创建或撤销进程时,系统都要为之分配或回收资源,如内存空间、I/O 设备等,因此操作系统所付出的开销远大于创建或撤销线程时的开销。类似地,在进行进程切换时,涉及当前执行进程 CPU 环境的保存及新调度进程 CPU 环境的设置。而线程切换时只需保存和设置少量寄存器内容,开销很小。此外,由于同一进程内的多个线程共享进程的地址空间,因此,这些线程之间的同步与通信非常容易实现,甚至无需操作系统的干预。
|
||||
|
||||
④ 通信方面:进程间通信 (IPC) 需要进程同步和互斥手段的辅助,以保证数据的一致性,而线程间可以通过直接读/写进程数据段(如全局变量)来进行通信。
|
||||
|
||||
举例:QQ 和 浏览器是两个进程,浏览器进程里面有很多线程,例如 http 请求线程、事件响应线程、渲染线程等等,线程的并发执行使得在浏览器中点击一个新链接从而发起 http 请求时,浏览器还可以响应用户的其它事件。
|
||||
|
||||
## 进程状态的切换
|
||||
|
||||

|
||||
|
||||
阻塞状态是缺少需要的资源从而由运行状态转换而来,但是该资源不包括 CPU,缺少 CPU 会让进程从运行态转换为就绪态。
|
||||
|
||||
只有就绪态和运行态可以相互转换,其它的都是单向转换。就绪状态的进程通过调度算法从而获得 CPU 时间,转为运行状态;而运行状态的进程,在分配给它的 CPU 时间片用完之后就会转为就绪状态,等待下一次调度。
|
||||
|
||||
## 调度算法
|
||||
|
||||
需要针对不同环境来讨论调度算法。
|
||||
|
||||
### 1. 批处理系统中的调度
|
||||
|
||||
#### 1.1 先来先服务(FCFS)
|
||||
|
||||
first-come first-serverd。
|
||||
|
||||
调度最先进入就绪队列的作业。
|
||||
|
||||
有利于长作业,但不利于短作业,因为短作业必须一直等待前面的长作业执行完毕才能执行,而长作业又需要执行很长时间,造成了短作业等待时间过长。
|
||||
|
||||
#### 1.2 短作业优先(SJF)
|
||||
|
||||
shortest job first。
|
||||
|
||||
调度估计运行时间最短的作业。
|
||||
|
||||
长作业有可能会饿死,处于一直等待短作业执行完毕的状态。如果一直有短作业到来,那么长作业永远得不到调度。
|
||||
|
||||
#### 1.3 最短剩余时间优先(SRTN)
|
||||
|
||||
shortest remaining time next。
|
||||
|
||||
### 2. 交互式系统中的调度
|
||||
|
||||
#### 2.1 优先权优先
|
||||
|
||||
除了可以手动赋予优先权之外,还可以把响应比作为优先权,这种调度方式叫做高响应比优先调度算法。
|
||||
|
||||
响应比 = (等待时间 + 要求服务时间) / 要求服务时间 = 响应时间 / 要求服务时间
|
||||
|
||||
这种调度算法主要是为了解决 SJF 中长作业可能会饿死的问题,因为随着等待时间的增长,响应比也会越来越高。
|
||||
|
||||
#### 2.2 时间片轮转
|
||||
|
||||
将所有就绪进程按 FCFS 的原则排成一个队列,每次调度时,把 CPU 分配给队首进程,该进程可以执行一个时间片。当时间片用完时,由计时器发出时钟中断,调度程序便停止该进程的执行,并将它送往就绪队列的末尾,同时继续把 CPU 分配给队首的进程。
|
||||
|
||||
时间片轮转算法的效率和时间片有很大关系。因为每次进程切换都要保存进程的信息并且载入新进程的信息,如果时间片太短,进程切换太频繁,在进程切换上就会花过多时间。
|
||||
|
||||
#### 2.3 多级反馈队列
|
||||
|
||||

|
||||
|
||||
① 设置多个就绪队列,并为各个队列赋予不同的优先级。第一个队列的优先级最高,第二个队列次之,其余各队列的优先权逐个降低。该算法赋予各个队列中进程执行时间片的大小也各不相同,在优先权越高的队列中,为每个进程所规定的执行时间片就越小。
|
||||
|
||||
② 当一个新进程进入内存后,首先将它放入第一队列的末尾,按 FCFS 原则排队等待调度。当轮到该进程执行时,如它能在该时间片内完成,便可准备撤离系统;如果它在一个时间片结束时尚未完成,调度程序便将该进程转入下一个队列的队尾。
|
||||
|
||||
③ 仅当前 i -1 个队列均空时,才会调度第 i 队列中的进程运行。
|
||||
|
||||
优点:实时性好,也适合运行短作业和长作业。
|
||||
|
||||
#### 2.4 短进程优先
|
||||
|
||||
### 3. 实时系统中的调度
|
||||
|
||||
实时系统要一个服务请求在一个确定时间内得到响应。
|
||||
|
||||
分为硬实时和软实时,前者必须满足绝对的截止时间,后者可以容忍一定的超时。
|
||||
|
||||
## 进程同步
|
||||
|
||||
### 1. 临界区
|
||||
|
||||
对临界资源进行访问的那段代码称为临界区。
|
||||
|
||||
为了互斥访问临界资源,每个进程在进入临界区之前,需要先进行检查。
|
||||
|
||||
```html
|
||||
// entry section
|
||||
// critical section;
|
||||
// exit section
|
||||
```
|
||||
|
||||
### 2. 同步与互斥
|
||||
|
||||
同步指多个进程按一定顺序执行;互斥指多个进程在同一时刻只有一个进程能进入临界区。
|
||||
|
||||
同步是在对临界区互斥访问的基础上,通过其它机制来实现有序访问的。
|
||||
|
||||
### 3. 信号量
|
||||
|
||||
**信号量(Samaphore)**是一个整型变量,可以对其执行 down 和 up 操作,也就是常见的 P 和 V 操作。
|
||||
|
||||
- **down** : 如果信号量大于 0 ,执行 - 1 操作;如果信号量等于 0,将进程睡眠,等待信号量大于 0;
|
||||
- **up**:对信号量执行 + 1 操作,并且唤醒睡眠的进程,让进程完成 down 操作。
|
||||
|
||||
down 和 up 操作需要被设计成原语,不可分割,通常的做法是在执行这些操作的时候屏蔽中断。
|
||||
|
||||
如果信号量的取值只能为 0 或者 1,那么就成为了**互斥量(Mutex)**,0 表示临界区已经加锁,1 表示临界区解锁。
|
||||
|
||||
```c
|
||||
typedef int samaphore;
|
||||
samaphore mutex = 1;
|
||||
void P1() {
|
||||
down(mutex);
|
||||
// 临界区
|
||||
up(mutex);
|
||||
}
|
||||
|
||||
void P2() {
|
||||
down(mutex);
|
||||
// 临界区
|
||||
up(mutex);
|
||||
}
|
||||
```
|
||||
|
||||
**使用信号量实现生产者-消费者问题**
|
||||
|
||||
使用一个互斥量 mutex 来对临界资源进行访问;empty 记录空缓冲区的数量,full 记录满缓冲区的数量。
|
||||
|
||||
注意,必须先执行 down 操作再用互斥量对临界区加锁,否则会出现死锁。如果都先对临界区加锁,然后再执行 down 操作,考虑这种情况:生产者对临界区加锁后,执行 down(empty) 操作,发现 empty = 0,此时生成者睡眠。消费者此时不能进入临界区,因为生产者对临界区加锁了,也就无法对执行 up(empty) 操作,那么生产者和消费者就会一直等待下去。
|
||||
|
||||
```c
|
||||
#define N 100
|
||||
typedef int samaphore;
|
||||
samaphore mutex = 1;
|
||||
samaphore empty = N;
|
||||
samaphore full = 0;
|
||||
|
||||
void producer() {
|
||||
while(TRUE){
|
||||
int item = produce_item;
|
||||
down(empty);
|
||||
down(mutex);
|
||||
insert_item(item);
|
||||
up(mutex);
|
||||
up(full);
|
||||
}
|
||||
}
|
||||
|
||||
void consumer() {
|
||||
while(TRUE){
|
||||
down(full);
|
||||
down(mutex);
|
||||
int item = remove_item(item);
|
||||
up(mutex);
|
||||
up(empty);
|
||||
consume_item(item);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 4. 管程
|
||||
|
||||
使用信号量机制实现的生产者消费者问题需要客户端代码做很多控制,而管程把控制的代码独立出来,不仅不容易出错,也使得客户端代码调用更容易。
|
||||
|
||||
c 语言不支持管程,下面的示例代码使用了类 Pascal 语言来描述管程。示例代码中的管程提供了 insert() 和 remove() 方法,客户端代码通过调用这两个方法来解决生产者-消费者问题。
|
||||
|
||||
```html
|
||||
monitor ProducerConsumer
|
||||
integer i;
|
||||
condition c;
|
||||
|
||||
procedure insert();
|
||||
begin
|
||||
|
||||
end;
|
||||
|
||||
procedure remove();
|
||||
begin
|
||||
|
||||
end;
|
||||
end monitor;
|
||||
```
|
||||
|
||||
管程有一个重要特性:在一个时刻只能有一个进程使用管程。进程在无法继续执行的时候不能一直占用管程,必须将进程阻塞,否者其它进程永远不能使用管程。
|
||||
|
||||
管程引入了 **条件变量** 以及相关的操作:**wait()** 和 **signal()** 来实现同步操作。对条件变量执行 wait() 操作会导致调用进程阻塞,把管程让出来让另一个进程持有。signal() 操作用于唤醒被阻塞的进程。
|
||||
|
||||
**使用管程实现生成者-消费者问题**
|
||||
|
||||
```html
|
||||
monitor ProducerConsumer
|
||||
condition full, empty;
|
||||
integer count := 0;
|
||||
condition c;
|
||||
|
||||
procedure insert(item: integer);
|
||||
begin
|
||||
if count = N then wait(full);
|
||||
insert_item(item);
|
||||
count := count + 1;
|
||||
if count = 1 ten signal(empty);
|
||||
end;
|
||||
|
||||
function remove: integer;
|
||||
begin
|
||||
if count = 0 then wait(empty);
|
||||
remove = remove_item;
|
||||
count := count - 1;
|
||||
if count = N -1 then signal(full);
|
||||
end;
|
||||
end monitor;
|
||||
|
||||
procedure producer
|
||||
begin
|
||||
while true do
|
||||
begin
|
||||
item = produce_item;
|
||||
ProducerConsumer.insert(item);
|
||||
end
|
||||
end;
|
||||
|
||||
procedure consumer
|
||||
begin
|
||||
while true do
|
||||
begin
|
||||
item = ProducerConsumer.remove;
|
||||
consume_item(item);
|
||||
end
|
||||
end;
|
||||
```
|
||||
|
||||
## 进程通信
|
||||
|
||||
进程通信可以看成是不同进程间的线程通信,对于同一个进程内线程的通信方式,主要使用信号量、条件变量等同步机制。
|
||||
|
||||
### 1. 管道
|
||||
|
||||
管道是单向的、先进先出的、无结构的、固定大小的字节流,它把一个进程的标准输出和另一个进程的标准输入连接在一起。写进程在管道的尾端写入数据,读进程在管道的首端读出数据。数据读出后将从管道中移走,其它读进程都不能再读到这些数据。
|
||||
|
||||
管道提供了简单的流控制机制,进程试图读空管道时,在有数据写入管道前,进程将一直阻塞。同样地,管道已经满时,进程再试图写管道,在其它进程从管道中移走数据之前,写进程将一直阻塞。
|
||||
|
||||
Linux 中管道是通过空文件来实现。
|
||||
|
||||
管道有三种:
|
||||
|
||||
① 普通管道:有两个限制:一是只支持半双工通信方式,即只能单向传输;二是只能在父子进程之间使用;
|
||||
|
||||
② 流管道:去除第一个限制,支持双向传输;
|
||||
|
||||
③ 命名管道:去除第二个限制,可以在不相关进程之间进行通信。
|
||||
|
||||
### 2. 信号量
|
||||
|
||||
信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其它进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
|
||||
|
||||
### 3. 消息队列
|
||||
|
||||
消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
|
||||
|
||||
### 4. 信号
|
||||
|
||||
信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
|
||||
|
||||
### 5. 共享内存
|
||||
|
||||
共享内存就是映射一段能被其它进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其它进程间通信方式运行效率低而专门设计的。它往往与其它通信机制(如信号量)配合使用,来实现进程间的同步和通信。
|
||||
|
||||
### 6. 套接字
|
||||
|
||||
套接字也是一种进程间通信机制,与其它通信机制不同的是,它可用于不同机器间的进程通信。
|
||||
|
||||
## 经典同步问题
|
||||
|
||||
生产者和消费者问题前面已经讨论过。
|
||||
|
||||
### 1. 读者-写者问题
|
||||
|
||||
允许多个进程同时对数据进行读操作,但是不允许读和写以及写和写操作同时发生。
|
||||
|
||||
一个整型变量 count 记录在对数据进行读操作的进程数量,一个互斥量 count_mutex 用于对 count 加锁,一个互斥量 data_mutex 用于对读写的数据加锁。
|
||||
|
||||
```c
|
||||
typedef int semaphore;
|
||||
semaphore count_mutex = 1;
|
||||
semaphore data_mutex = 1;
|
||||
int count = 0;
|
||||
|
||||
void reader() {
|
||||
while(TRUE) {
|
||||
down(count_mutex);
|
||||
count++;
|
||||
if(count == 1) down(data_mutex); // 第一个读者需要对数据进行加锁,防止写进程访问
|
||||
up(count_mutex);
|
||||
read();
|
||||
down(count_mutex);
|
||||
count--;
|
||||
if(count == 0) up(data_mutex);
|
||||
up(count_mutex);
|
||||
}
|
||||
}
|
||||
|
||||
void writer() {
|
||||
while(TRUE) {
|
||||
down(data_mutex);
|
||||
write();
|
||||
up(data_mutex);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 2. 哲学家进餐问题
|
||||
|
||||

|
||||
|
||||
五个哲学家围着一张圆周,每个哲学家面前放着饭。哲学家的生活有两种交替活动:吃饭以及思考。当一个哲学家吃饭时,需要先一根一根拿起左右两边的筷子。
|
||||
|
||||
下面是一种错误的解法,考虑到如果每个哲学家同时拿起左手边的筷子,那么就无法拿起右手边的筷子,造成死锁。
|
||||
|
||||
```c
|
||||
#define N 5
|
||||
#define LEFT (i + N - 1) % N
|
||||
#define RIGHT (i + N) % N
|
||||
typedef int semaphore;
|
||||
semaphore chopstick[N];
|
||||
|
||||
void philosopher(int i) {
|
||||
while(TURE){
|
||||
think();
|
||||
down(chopstick[LEFT[i]]);
|
||||
down(chopstick[RIGHT[i]]);
|
||||
eat();
|
||||
up(chopstick[RIGHT[i]]);
|
||||
up(chopstick[LEFT[i]]);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
为了防止死锁的发生,可以加一点限制,只允许同时拿起左右两边的筷子,方法是引入一个互斥量,对拿起两个筷子的那段代码加锁。
|
||||
|
||||
```c
|
||||
semaphore mutex = 1;
|
||||
|
||||
void philosopher(int i) {
|
||||
while(TURE){
|
||||
think();
|
||||
down(mutex);
|
||||
down(chopstick[LEFT[i]]);
|
||||
down(chopstick[RIGHT[i]]);
|
||||
up(mutex);
|
||||
eat();
|
||||
down(mutex);
|
||||
up(chopstick[RIGHT[i]]);
|
||||
up(chopstick[LEFT[i]]);
|
||||
up(mutex);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
# 第三章 死锁
|
||||
|
||||
## 死锁的条件
|
||||
|
||||

|
||||
|
||||
1. 互斥
|
||||
2. 请求与保持:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
|
||||
3. 不可抢占
|
||||
4. 环路等待
|
||||
|
||||
## 死锁的处理方法
|
||||
|
||||
### 1. 鸵鸟策略
|
||||
|
||||
把头埋在沙子里,假装根本没发生问题。
|
||||
|
||||
这种策略不可取。
|
||||
|
||||
### 2. 死锁预防
|
||||
|
||||
在程序运行之前预防发生死锁。
|
||||
|
||||
#### 2.1 破坏互斥条件
|
||||
|
||||
例如假脱机打印机技术允许若干个进程同时输出,唯一真正请求物理打印机的进程是打印机守护进程。
|
||||
|
||||
#### 2.2 破坏请求与保持条件
|
||||
|
||||
一种实现方式是规定所有进程在开始执行前请求所需要的全部资源。
|
||||
|
||||
#### 2.3 破坏不可抢占条件
|
||||
|
||||
#### 2.4 破坏环路等待
|
||||
|
||||
给资源统一编号,进程只能按编号顺序来请求资源。
|
||||
|
||||
### 3. 死锁避免
|
||||
|
||||
在程序运行时避免发生死锁。
|
||||
|
||||
#### 3.1 安全状态
|
||||
|
||||

|
||||
|
||||
图 a 的第二列 has 表示已拥有的资源数,第三列 max 表示总共需要的资源数,free 表示还有可以使用的资源数。从图 a 开始出发,先让 B 拥有所需的所有资源,运行结束后释放 B,此时 free 变为 4;接着以同样的方式运行 C 和 A,使得所有进程都能成功运行,因此可以称图 a 所示的状态时安全的。
|
||||
|
||||
定义:如果没有死锁发生,并且即使所有进程突然请求对资源的最大需求,也仍然存在某种调度次序能够使得每一个进程运行完毕,则称该状态是安全的。
|
||||
|
||||
#### 3.2 单个资源的银行家算法
|
||||
|
||||
一个小城镇的银行家,他向一群客户分别承诺了一定的贷款额度,算法要做的是判断对请求的满足是否会进入不安全状态,如果是,就拒绝请求;否则予以分配。
|
||||
|
||||

|
||||
|
||||
上图 c 为不安全状态,因此算法会拒绝之前的请求,从而避免进入图 c 中的状态。
|
||||
|
||||
#### 3.3 多个资源的银行家算法
|
||||
|
||||

|
||||
|
||||
上图中有五个进程,四个资源。左边的图表示已经分配的资源,右边的图表示还需要分配的资源。最右边的 E、P 以及 A 分别表示:总资源、已分配资源以及可用资源,注意这三个为向量,而不是具体数值,例如 A=(1020),表示 4 个资源分别还剩下 1/0/2/0。
|
||||
|
||||
检查一个状态是否安全的算法如下:
|
||||
|
||||
① 查找右边的矩阵是否存在一行小于等于向量 A。如果不存在这样的行,那么系统将会发生死锁,状态是不安全的。
|
||||
|
||||
② 假若找到这样一行,将该进程标记为终止,并将其已分配资源加到 A 中。
|
||||
|
||||
③ 重复以上两步,直到所有进程都标记为终止,则状态时安全的。
|
||||
|
||||
### 4. 死锁检测与死锁恢复
|
||||
|
||||
不试图组织死锁,而是当检测到死锁发生时,采取措施进行恢复。
|
||||
|
||||
#### 4.1 死锁检测算法
|
||||
|
||||
死锁检测的基本思想是,如果一个进程所请求的资源能够被满足,那么就让它执行,释放它拥有的所有资源,然后让其它能满足条件的进程执行。
|
||||
|
||||

|
||||
|
||||
上图中,有三个进程四个资源,每个数据代表的含义如下:
|
||||
|
||||
E 向量:资源总量
|
||||
A 向量:资源剩余量
|
||||
C 矩阵:每个进程所拥有的资源数量,每一行都代表一个进程拥有资源的数量
|
||||
R 矩阵:每个进程请求的资源数量
|
||||
|
||||
进程 P<sub>1</sub> 和 P<sub>2</sub> 所请求的资源都得不到满足,只有进程 P<sub>3</sub> 可以,让 P<sub>3</sub> 执行,之后释放 P<sub>3</sub> 拥有的资源,此时 A = (2 2 2 0)。P<sub>1</sub> 可以执行,执行后释放 P<sub>1</sub> 拥有的资源, A = (4 2 2 2) ,P<sub>2</sub> 也可以执行。所有进程都可以顺利执行,没有死锁。
|
||||
|
||||
算法总结如下:
|
||||
|
||||
每个进程最开始时都不被标记,执行过程有可能被标记。当算法结束时,任何没有被标记的进程都是死锁进程。
|
||||
|
||||
① 寻找一个没有标记的进程 P<sub>i</sub>,它所请求的资源小于等于 A。
|
||||
② 如果找到了这样一个进程,那么将 C 矩阵的第 i 行向量加到 A 中,标记该进程,并转回 ①。
|
||||
③ 如果有没有这样一个进程,算法终止。
|
||||
|
||||
#### 4.2 死锁恢复
|
||||
|
||||
① 利用抢占恢复
|
||||
② 杀死进程
|
||||
|
||||
# 第四章 存储器管理
|
||||
|
||||
## 虚拟内存
|
||||
|
||||
每个程序拥有自己的地址空间,这个地址空间被分割成多个块,每一块称为一 页。这些页被映射到物理内存,但不需要映射到连续的物理内存,也不需要所有页都必须在物理内存中。
|
||||
|
||||
当程序引用到一部分在物理内存中的地址空间时,由硬件立即执行必要的映射。当程序引用到一部分不在物理内存中的地址空间时,由操作系统负责将缺失的部分装入物理内存并重新执行失败的指令。
|
||||
|
||||
## 分页与分段
|
||||
|
||||
### 1. 分页
|
||||
|
||||
用户程序的地址空间被划分为若干固定大小的区域,称为“页”。相应地,内存空间分成若干个物理块,页和块的大小相等。可将用户程序的任一页放在内存的任一块中,实现了离散分配,由一个页表来维护它们之间的映射关系。
|
||||
|
||||
### 2. 分段
|
||||
|
||||

|
||||
|
||||
上图为一个编译器在编译过程中建立的多个表,有 4 个表是动态增长的,如果使用分页系统的一维地址空间,动态递增的特点会导致覆盖问题的出现。
|
||||
|
||||

|
||||
|
||||
分段的做法是把每个表分成段,一个段构成一个独立的地址空间。每个段的长度可以不同,可以动态改变。
|
||||
|
||||
每个段都需要程序员来划分。
|
||||
|
||||
### 3. 段页式
|
||||
|
||||
用分段方法来分配和管理虚拟存储器。程序的地址空间按逻辑单位分成基本独立的段,而每一段有自己的段名,再把每段分成固定大小的若干页。
|
||||
|
||||
用分页方法来分配和管理实存。即把整个主存分成与上述页大小相等的存储块,可装入作业的任何一页。程序对内存的调入或调出是按页进行的。但它又可按段实现共享和保护。
|
||||
|
||||
### 4. 分页与分段区别
|
||||
|
||||
① 对程序员的透明性:分页透明,但是分段需要程序员显示划分每个段。
|
||||
|
||||
② 地址空间的维度:分页是一维地址空间,分段是二维的。
|
||||
|
||||
③ 大小是否可以改变:页的大小不可变,段的大小可以动态改变。
|
||||
|
||||
④ 出现的原因:分页主要用于实现虚拟内存,从而获得更大的地址空间;分段主要是为了使程序和数据可以被划分为逻辑上独立的地址空间并且有助于共享和保护。
|
||||
|
||||
## 页面置换算法
|
||||
|
||||
在程序运行过程中,若其所要访问的页面不在内存而需要把它们调入内存,但是内存已无空闲空间时,系统必须从内存中调出一个页面到磁盘对换区中,并且将程序所需要的页面调入内存中。页面置换算法的主要目标是使页面置换频率最低(也可以说缺页率最低)。
|
||||
|
||||
### 1. 最佳(Optimal)
|
||||
|
||||
所选择的被换出的页面将是最长时间内不再被访问,通常可以保证获得最低的缺页率。
|
||||
|
||||
是一种理论上的算法,因为无法知道一个页面多长时间会被再访问到。
|
||||
|
||||
举例:一个系统为某进程分配了三个物理块,并有如下页面引用序列:
|
||||
|
||||
7,0,1,2,0,3,0,4,2,3,0,3,2,1,2,0,1,7,0,1
|
||||
|
||||
进程运行时,先将 7,0,1 三个页面装入内存。当进程要访问页面 2 时,产生缺页中断,会将页面 7 换出,因为页面 7 再次被访问的时间最长。
|
||||
|
||||
### 2. 先进先出(FIFO)
|
||||
|
||||
所选择换出的页面是最先进入的页面。
|
||||
|
||||
该算法会将那些经常被访问的页面也被换出,从而使缺页率升高。
|
||||
|
||||
### 3. 最近最久未使用(LRU,Least Recently Used)
|
||||
|
||||
虽然无法知道将来要使用的页面情况,但是可以知道过去使用页面的情况。LRU 将最近最久未使用的页面换出。
|
||||
|
||||
可以用栈来实现该算法,栈中存储页面的页面号。当进程访问一个页面时,将该页面的页面号从栈移除,并将它压入栈顶,这样,最近被访问的页面的页面号总是在栈顶,而最近最久未使用的页面的页面号总是在栈底。
|
||||
|
||||
4,7,0,7,1,0,1,2,1,2,6
|
||||
|
||||

|
||||
|
||||
### 4. 时钟(Clock)
|
||||
|
||||
Clock 页面置换算法需要用到一个访问位,当一个页面被访问时,将访问为置为 1。
|
||||
|
||||
首先,将内存中的所有页面链接成一个循环队列,当缺页中断发生时,检查当前指针所指向页面的访问位,如果访问位为 0,就将该页面换出;否则将该页的访问位设置为 0,给该页面第二次的机会,移动指针继续检查。
|
||||
|
||||
# 第五章 设备管理
|
||||
|
||||
## 磁盘调度算法
|
||||
|
||||
当多个进程同时请求访问磁盘时,需要进行磁盘调度来控制对磁盘的访问。磁盘调度的主要目标是使磁盘的平均寻道时间最少。
|
||||
|
||||
### 1. 先来先服务(FCFS,First Come First Serverd)
|
||||
|
||||
根据进程请求访问磁盘的先后次序来进行调度。优点是公平和简单,缺点也很明显,因为未对寻道做任何优化,使平均寻道时间可能较长。
|
||||
|
||||
### 2. 最短寻道时间优先(SSTF,Shortest Seek Time First)
|
||||
|
||||
要求访问的磁道与当前磁头所在磁道距离最近的优先进行调度。这种算法并不能保证平均寻道时间最短,但是比 FCFS 好很多。
|
||||
|
||||
### 3. 扫描算法(SCAN)
|
||||
|
||||
SSTF 会出现进行饥饿现象。考虑以下情况,新进程请求访问的磁道与磁头所在磁道的距离总是比一个在等待的进程来的近,那么等待的进程会一直等待下去。
|
||||
|
||||
SCAN 算法在 SSTF 算法之上考虑了磁头的移动方向,要求所请求访问的磁道在磁头当前移动方向上才能够得到调度。因为考虑了移动方向,那么一个进程请求访问的磁道一定会得到调度。
|
||||
|
||||
当一个磁头自里向外移动时,移到最外侧会改变移动方向为自外向里,这种移动的规律类似于电梯的运行,因此又常称 SCAN 算法为电梯调度算法。
|
||||
|
||||
### 4. 循环扫描算法(CSCAN)
|
||||
|
||||
CSCAN 对 SCAN 进行了改动,要求磁头始终沿着一个方向移动。
|
||||
|
||||
# 参考资料
|
||||
|
||||
- Tanenbaum A S, Bos H. Modern operating systems[M]. Prentice Hall Press, 2014.
|
||||
|
||||
- 汤子瀛, 哲凤屏, 汤小丹. 计算机操作系统[M]. 西安电子科技大学出版社, 2001.
|
||||
|
||||
- Bryant, R. E., & O’Hallaron, D. R. (2004). 深入理解计算机系统.
|
||||
|
||||
- [小土刀的面试刷题笔记](http://wdxtub.com/interview/index.html)
|
||||
|
||||
- [进程间的几种通信方式](http://blog.csdn.net/yufaw/article/details/7409596)
|
||||
841
notes/计算机网络.md
Normal file
841
notes/计算机网络.md
Normal file
@ -0,0 +1,841 @@
|
||||
<!-- GFM-TOC -->
|
||||
* [第一章 概述](#第一章-概述)
|
||||
* [网络的网络](#网络的网络)
|
||||
* [ISP](#isp)
|
||||
* [互联网的组成](#互联网的组成)
|
||||
* [主机之间的通信方式](#主机之间的通信方式)
|
||||
* [电路交换与分组交换](#电路交换与分组交换)
|
||||
* [1. 电路交换](#1-电路交换)
|
||||
* [2. 报文交换](#2-报文交换)
|
||||
* [3. 分组交换](#3-分组交换)
|
||||
* [时延](#时延)
|
||||
* [1. 发送时延](#1-发送时延)
|
||||
* [2. 传播时延](#2-传播时延)
|
||||
* [3. 处理时延](#3-处理时延)
|
||||
* [4. 排队时延](#4-排队时延)
|
||||
* [计算机网络体系结构](#计算机网络体系结构)
|
||||
* [1. 七层协议](#1-七层协议)
|
||||
* [2. 五层协议](#2-五层协议)
|
||||
* [3. 数据在各层之间的传递过程](#3-数据在各层之间的传递过程)
|
||||
* [4. TCP/IP 体系结构](#4-tcpip-体系结构)
|
||||
* [第二章 物理层](#第二章-物理层)
|
||||
* [通信方式](#通信方式)
|
||||
* [带通调制](#带通调制)
|
||||
* [信道复用技术](#信道复用技术)
|
||||
* [1. 频分复用、时分复用](#1-频分复用时分复用)
|
||||
* [2. 统计时分复用](#2-统计时分复用)
|
||||
* [3. 波分复用](#3-波分复用)
|
||||
* [4. 码分复用](#4-码分复用)
|
||||
* [第三章 数据链路层](#第三章-数据链路层)
|
||||
* [三个基本问题](#三个基本问题)
|
||||
* [1. 封装成帧](#1-封装成帧)
|
||||
* [2. 透明传输](#2-透明传输)
|
||||
* [3. 差错检测](#3-差错检测)
|
||||
* [点对点信道 -PPP 协议](#点对点信道--ppp-协议)
|
||||
* [局域网的拓扑](#局域网的拓扑)
|
||||
* [广播信道 -CSMA/CD 协议](#广播信道--csmacd-协议)
|
||||
* [集线器](#集线器)
|
||||
* [MAC 层](#mac-层)
|
||||
* [虚拟局域网](#虚拟局域网)
|
||||
* [第四章 网络层](#第四章-网络层)
|
||||
* [网际协议 IP 概述](#网际协议-ip-概述)
|
||||
* [IP 数据报格式](#ip-数据报格式)
|
||||
* [IP 地址编址](#ip-地址编址)
|
||||
* [1. 分类的 IP 地址](#1-分类的-ip-地址)
|
||||
* [2. 划分子网](#2-划分子网)
|
||||
* [3. 无分类编址 CIDR(构成超网)](#3-无分类编址-cidr(构成超网))
|
||||
* [IP 地址和 MAC 地址](#ip-地址和-mac-地址)
|
||||
* [地址解析协议 ARP](#地址解析协议-arp)
|
||||
* [路由器的结构](#路由器的结构)
|
||||
* [交换机与路由器的区别](#交换机与路由器的区别)
|
||||
* [路由器分组转发流程](#路由器分组转发流程)
|
||||
* [路由选择协议](#路由选择协议)
|
||||
* [1. 内部网关协议 RIP](#1-内部网关协议-rip)
|
||||
* [2. 内部网关协议 OSPF](#2-内部网关协议-ospf)
|
||||
* [3. 外部网关协议 BGP](#3-外部网关协议-bgp)
|
||||
* [网际控制报文协议 ICMP](#网际控制报文协议-icmp)
|
||||
* [分组网间探测 PING](#分组网间探测-ping)
|
||||
* [IP 多播](#ip-多播)
|
||||
* [虚拟专用网 VPN](#虚拟专用网-vpn)
|
||||
* [网络地址转换 NAT](#网络地址转换-nat)
|
||||
* [第五章 运输层](#第五章-运输层)
|
||||
* [UDP 和 TCP 的特点](#udp-和-tcp-的特点)
|
||||
* [UDP 首部格式](#udp-首部格式)
|
||||
* [TCP 首部格式](#tcp-首部格式)
|
||||
* [TCP 的三次握手](#tcp-的三次握手)
|
||||
* [TCP 的四次挥手](#tcp-的四次挥手)
|
||||
* [TCP 滑动窗口](#tcp-滑动窗口)
|
||||
* [TCP 可靠传输](#tcp-可靠传输)
|
||||
* [TCP 流量控制](#tcp-流量控制)
|
||||
* [TCP 拥塞控制](#tcp-拥塞控制)
|
||||
* [慢开始与拥塞避免](#慢开始与拥塞避免)
|
||||
* [快重传与快恢复](#快重传与快恢复)
|
||||
* [第六章 应用层](#第六章-应用层)
|
||||
* [域名系统 DNS](#域名系统-dns)
|
||||
* [1. 层次结构](#1-层次结构)
|
||||
* [2. 解析过程](#2-解析过程)
|
||||
* [文件传输协议 FTP](#文件传输协议-ftp)
|
||||
* [远程终端协议 TELNET](#远程终端协议-telnet)
|
||||
* [万维网 WWW](#万维网-www)
|
||||
* [电子邮件协议](#电子邮件协议)
|
||||
* [POP3](#pop3)
|
||||
* [IMAP](#imap)
|
||||
* [SMTP](#smtp)
|
||||
* [动态主机配置协议 DHCP](#动态主机配置协议-dhcp)
|
||||
* [点对点传输 P2P](#点对点传输-p2p)
|
||||
* [在浏览器中输入 www.baidu.com 后执行的全部过程](#在浏览器中输入-wwwbaiducom-后执行的全部过程)
|
||||
* [常用端口](#常用端口)
|
||||
* [参考资料](#参考资料)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
# 第一章 概述
|
||||
|
||||
## 网络的网络
|
||||
|
||||
网络把主机连接起来,而互联网是把多种不同的网络连接起来,因此互联网是网络的网络。
|
||||
|
||||

|
||||
|
||||
## ISP
|
||||
|
||||
互联网服务提供商 ISP 可以从互联网管理机构获得许多 IP 地址,同时拥有通信线路以及路由器等联网设备,个人或机构向 ISP 缴纳一定的费用就可以接入互联网。
|
||||
|
||||
目前的互联网是一种多层次 ISP 结构,ISP 根据覆盖面积的大小分为主干 ISP、地区 ISP 和本地 ISP。
|
||||
|
||||
互联网交换点 IXP 允许两个网络直接相连而不用经过第三个来转发分组。
|
||||
|
||||

|
||||
|
||||
## 互联网的组成
|
||||
|
||||
1. 边缘部分:所有连接在互联网上的主机。用户可以直接使用;
|
||||
2. 核心部分:由大量的网络和连接这些网络的路由器组成。为边缘部分的主机提供服务。
|
||||
|
||||

|
||||
|
||||
## 主机之间的通信方式
|
||||
|
||||
**1. 客户 - 服务器(C/S)**
|
||||
|
||||
客户即是服务请求方,服务器是服务提供方。
|
||||
|
||||
**2. 对等(P2P)**
|
||||
|
||||
不区分客户和服务器。
|
||||
|
||||
## 电路交换与分组交换
|
||||
|
||||

|
||||
|
||||
### 1. 电路交换
|
||||
|
||||
电路交换用于电话通信系统,两个用户要通信之前需要建立一条专用的物理链路,并且在整个通信过程中始终占用该链路。由于通信的过程中不可能一直在使用传输线路,因此电路交换对线路的利用率很低,往往不到 10%。
|
||||
|
||||
### 2. 报文交换
|
||||
|
||||
报文交换用于邮局通信系统,邮局接收到一份报文之后,先存储下来,然后根据目的地选择性地把报文转发到下一个目的地,这个过程就是存储转发过程。
|
||||
|
||||
### 3. 分组交换
|
||||
|
||||
分组交换也使用了存储转发,但是转发的是分组而不是报文。把整块数据称为一个报文,由于一个报文可能很长,需要先进行切分,来满足分组能处理的大小。在每个切分的数据前面加上首部之后就成为了分组,首部包含了目的地址和源地址等控制信息。
|
||||
|
||||

|
||||
|
||||
存储转发允许在一条传输线路上传送多个主机的分组,也就是分组交换不需要占用端到端的线路资源。
|
||||
|
||||
相比于报文交换,由于分组比报文更小,存储转发的速度也就更快。
|
||||
|
||||
## 时延
|
||||
|
||||
总时延 = 发送时延 + 传播时延 + 处理时延 + 排队时延
|
||||
|
||||

|
||||
|
||||
|
||||
### 1. 发送时延
|
||||
|
||||
主机或路由器发送数据帧所需要的时间。
|
||||
|
||||
}{v(bit/s)})
|
||||
|
||||
其中 l 表示数据帧的长度,v 表示发送速率。
|
||||
|
||||
### 2. 传播时延
|
||||
|
||||
电磁波在信道中传播一定的距离需要花费的时间,电磁波传播速度接近光速。
|
||||
|
||||
}{v(m/s)})
|
||||
|
||||
其中 l 表示信道长度,v 表示电磁波在信道上的传播速率。
|
||||
|
||||
### 3. 处理时延
|
||||
|
||||
主机或路由器收到分组时进行处理所需要的时间,例如分析首部,从分组中提取数据部分等。
|
||||
|
||||
### 4. 排队时延
|
||||
|
||||
分组在路由器的输入队列和输出队列中排队等待的时间,取决于网络当前的通信量。
|
||||
|
||||
## 计算机网络体系结构
|
||||
|
||||

|
||||
|
||||
### 1. 七层协议
|
||||
|
||||
如图 a 所示,其中表示层和会话层用途如下:
|
||||
|
||||
1. 表示层:信息的语法语义以及它们的关联,如加密解密、转换翻译、压缩解压缩;
|
||||
2. 会话层:不同机器上的用户之间建立及管理会话。
|
||||
|
||||
### 2. 五层协议
|
||||
|
||||
1. 应用层:为特定应用程序提供数据传输服务,例如 HTTP、DNS 等。数据单位为报文。
|
||||
|
||||
2. 运输层:提供的是进程间的通用数据传输服务。由于应用层协议很多,定义通用的运输层协议就可以支持不断增多的应用层协议。运输层包括两种协议:传输控制协议 TCP,提供面向连接、可靠的数据传输服务,数据单位为报文段;用户数据报协议 UDP,提供无连接、尽最大努力的数据传输服务,数据单位为用户数据报。
|
||||
|
||||
3. 网络层:为主机之间提供服务,而不是像运输层协议那样是为主机中的进程提供服务。网络层把运输层产生的报文段或者用户数据报封装成分组来进行传输。
|
||||
|
||||
4. 数据链路层:网络层针对的还是主机之间,而主机之间可以有很多链路,链路层协议就是为相邻结点之间提供服务。数据链路层把网络层传来的分组封装成帧。
|
||||
|
||||
5. 物理层:考虑的是怎样在传输媒体上传输数据比特流,而不是指具体的传输媒体。物理层的作用是尽可能屏蔽传输媒体和通信手段的差异,使物理层上的数据链路层感觉不到这些差异。
|
||||
|
||||
### 3. 数据在各层之间的传递过程
|
||||
|
||||
在向下的过程中,需要添加下层协议所需要的首部或者尾部,而在向上的过程中不断拆开首部和尾部。
|
||||
|
||||
路由器只有下面三层协议,因为路由器位于网络核心中,不需要为进程或者应用程序提供服务。
|
||||
|
||||

|
||||
|
||||
### 4. TCP/IP 体系结构
|
||||
|
||||
它只有四层,相当于五层协议中数据链路层和物理层合并为网络接口层。
|
||||
|
||||
现在的 TCP/IP 体系结构不严格遵循 OSI 分层概念,应用层可能会直接使用 IP 层或者网络接口层。
|
||||
|
||||

|
||||
|
||||
TCP/IP 协议族是一种沙漏形状,中间小两边大,IP 协议在其中占用举足轻重的地位。
|
||||
|
||||

|
||||
|
||||
# 第二章 物理层
|
||||
|
||||
## 通信方式
|
||||
|
||||
1. 单向通信,又称为单工通信;
|
||||
2. 双向交替通信,又称为半双工通信;
|
||||
3. 双向同时通信,又称为全双工通信。
|
||||
|
||||
## 带通调制
|
||||
|
||||
模拟信号是连续的信号,数字信号是离散的信号。带通调制把数字信号转换为模拟信号。
|
||||
|
||||

|
||||
|
||||
## 信道复用技术
|
||||
|
||||
### 1. 频分复用、时分复用
|
||||
|
||||
频分复用的所有用户在相同的时间占用不同的频率带宽资源;时分复用的所有用户在不同的时间占用相同的频率带宽资源。
|
||||
|
||||
使用这两种方式进行通信,在通信的过程中用户会一直占用一部分信道资源。但是由于计算机数据的突发性质,没必要一直占用信道资源而不让出给其它用户使用,因此这两种方式对信道的利用率都不高。
|
||||
|
||||

|
||||
|
||||
### 2. 统计时分复用
|
||||
|
||||
是对时分复用的一种改进,不固定每个用户在时分复用帧中的位置,只要有数据就集中起来组成时分复用帧然后发送。
|
||||
|
||||

|
||||
|
||||
### 3. 波分复用
|
||||
|
||||
光的频分复用。由于光的频率很高,因此习惯上用波长而不是频率来表示所使用的光载波。
|
||||
|
||||

|
||||
|
||||
### 4. 码分复用
|
||||
|
||||
为每个用户分配 m bit 的码片,并且所有的码片正交,对于任意两个码片 $\vec{S}$ 和 $\vec{T}$ 有
|
||||
|
||||
|
||||
|
||||
为了方便,取 m=8,设码片 $\vec{S}$ 为 00011011。在拥有该码片的用户发送比特 1 时就发送该码片,发送比特 0 时就发送该码片的反码 11100100。
|
||||
|
||||
在计算时将 00011011 记作 (-1 -1 -1 +1 +1 -1 +1 +1),可以得到
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
其中 $\vec{S'}$ 为 $\vec{S}$ 的反码。
|
||||
|
||||
利用上面的式子我们知道,当接收端使用码片 $\vec{S}$ 对接收到的数据进行内积运算时,结果为 0 的是其它用户发送的数据,结果为 1 的是用户发送的比特 1,结果为 -1 的是用户发送的比特 0。
|
||||
|
||||
码分复用发送的数据量为原先的 m 倍。
|
||||
|
||||

|
||||
|
||||
# 第三章 数据链路层
|
||||
|
||||
## 三个基本问题
|
||||
|
||||
### 1. 封装成帧
|
||||
|
||||
将网络层传下来的分组添加首部和尾部,用于标记帧的开始和结束。
|
||||
|
||||

|
||||
|
||||
### 2. 透明传输
|
||||
|
||||
透明表示一个实际存在的事物看起来好像不存在一样。
|
||||
|
||||
帧中有首部和尾部,如果帧的数据部分含有和首部尾部相同的内容,那么帧的开始和结束位置就会被错误的判定。需要在数据中出现首部尾部相同的内容前面插入转义字符,如果需要传输的内容正好就是转义字符,那么就在转义字符前面再加个转义字符,在接收端进行处理之后可以还原出原始数据。这个过程透明传输的内容是转义字符,用户很难察觉到转义字符的存在。
|
||||
|
||||

|
||||
|
||||
### 3. 差错检测
|
||||
|
||||
目前数据链路层广泛使用了循环冗余检验(CRC)来检查比特差错。
|
||||
|
||||
## 点对点信道 -PPP 协议
|
||||
|
||||
互联网用户通常需要连接到某个 ISP 之后才能接入到互联网,PPP 协议就是用户计算机和 ISP 进行通信时所使用的数据链路层协议。
|
||||
|
||||

|
||||
|
||||
在 PPP 的帧中,F 字段为帧的定界符,A 和 C 暂时没有意义。FCS 是使用 CRC 的检验序列。信息字段的长度不超过 1500。
|
||||
|
||||

|
||||
|
||||
## 局域网的拓扑
|
||||
|
||||

|
||||
|
||||
## 广播信道 -CSMA/CD 协议
|
||||
|
||||
在广播信道上,同一时间只能允许一台计算机发送数据。
|
||||
|
||||
CSMA/CD 表示载波监听多点接入 / 碰撞检测。
|
||||
|
||||
**多点接入**:说明这是总线型网络,许多计算机以多点的方式连接到总线上。
|
||||
**载波监听**:每个站都必须不停地检听信道。在发送前,如果检听信道正在使用,就必须等待。
|
||||
**碰撞检测**:在发送中,如果检听信道已有其它站正在发送数据,就表示发生了碰撞。虽然每一个站在发送数据之前都已经检听信道为空闲,但是由于电磁波的传播时延的存在,还是有可能会发生碰撞。
|
||||
|
||||

|
||||
|
||||
记端到端的传播时延为 τ,最先发送的站点最多经过 2τ 就可以知道是否发生了碰撞,称 2τ 为 **争用期**。只有经过争用期之后还没有检测到碰撞,才能肯定这次发送不会发生碰撞。
|
||||
|
||||
当发生碰撞时,站点要停止发送,等待一段时间再发送。这个时间采用 **截断二进制指数退避算法** 来确定,从离散的整数集合 {0, 1, .., (2<sup>k</sup>-1)} 中随机取出一个数,记作 r,然后取 r 倍的争用期作为重传等待时间。
|
||||
|
||||
## 集线器
|
||||
|
||||
从表面上看,使用集线器的局域网在物理上是一个星型网。但是集线器使用电子器件来模拟实际缆线的工作,逻辑上仍是一个总线网,整个系统仍像一个传统以太网那样运行。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
## MAC 层
|
||||
|
||||
MAC 地址是 6 字节(48 位)的地址,用于唯一表示适配器,一台主机拥有多个适配器就有多个 MAC 地址,例如笔记本电脑普遍存在无线网络适配器和有线网络适配器。
|
||||
|
||||
MAC 帧用类型字段来标记上层使用什么协议;数据字段长度在 46-1500 之间,如果太小则需要填充;FCS 为帧检验序列,使用的是 CRC 检验方法;前面插入的前同步码只是为了计算 FCS 临时加入的,计算结束之后会丢弃。
|
||||
|
||||

|
||||
|
||||
## 虚拟局域网
|
||||
|
||||
虚拟局域网可以建立与物理位置无关的逻辑组,只有在同一个虚拟局域网中的成员才会收到广播信息,例如下图中 (A1, A2, A3, A4) 属于一个虚拟局域网,A1 发送的广播会被 A2、A3、A4 收到,而其它站点收不到。
|
||||
|
||||

|
||||
|
||||
# 第四章 网络层
|
||||
|
||||
## 网际协议 IP 概述
|
||||
|
||||
因为网络层是整个互联网的核心,因此应当让网络层尽可能简单。网络层向上只提供简单灵活的、无连接的、尽最大努力交互的数据报服务。
|
||||
|
||||
使用 IP 协议,可以把异构的物理网络连接起来,使得在网络层看起来好像是一个统一的网络。
|
||||
|
||||

|
||||
|
||||
与 IP 协议配套使用的还有三个协议:
|
||||
|
||||
1. 地址解析协议 ARP(Address Resolution Protocol)
|
||||
2. 网际控制报文协议 ICMP(Internet Control Message Protocol)
|
||||
3. 网际组管理协议 IGMP(Internet Group Management Protocol)
|
||||
|
||||

|
||||
|
||||
## IP 数据报格式
|
||||
|
||||

|
||||
|
||||
**版本** : 有 4(IPv4)和 6(IPv6)两个值;
|
||||
|
||||
**首部长度** : 占 4 位,因此最大值为 15。值为 1 表示的是 1 个 32 位字的长度,也就是 4 字节。因为首部固定长度为 20 字节,因此该值最小为 5。如果可选部分的长度不是 4 字节的整数倍,就用尾部的填充部分来填充。
|
||||
|
||||
**区分服务** : 用来获得更好的服务,一般情况下不适用。
|
||||
|
||||
**总长度** : 包括首部长度和数据部分长度。
|
||||
|
||||
**标识** : 在数据报长度过长从而发生分片的情况下,相同数据报的不同分片具有相同的标识符。
|
||||
|
||||
**片偏移** : 和标识符一起,用于发生分片的情况。片偏移的单位为 8 字节。
|
||||
|
||||

|
||||
|
||||
**生存时间** :TTL,它的存在为了防止无法交付的数据报在互联网中不断兜圈子。以路由器跳数为单位,当 TTL 为 0 时就丢弃数据报。
|
||||
|
||||
**协议**:指出携带的数据应该上交给哪个协议进行处理,例如 ICMP、TCP、UDP 等。
|
||||
|
||||
**首部检验和**:因为数据报每经过一个路由器,都要重新计算检验和,因此检验和不包含数据部分可以减少计算的工作量。
|
||||
|
||||
## IP 地址编址
|
||||
|
||||
IP 地址的编址方式经历了三个历史阶段:
|
||||
|
||||
1. 分类的 IP 地址;
|
||||
2. 子网的划分;
|
||||
3. 构成超网。
|
||||
|
||||
### 1. 分类的 IP 地址
|
||||
|
||||
由两部分组成,网络号和主机号,其中不同类别具有不同的网络号长度,并且是固定的。
|
||||
|
||||
IP 地址 ::= {< 网络号 >, < 主机号 >}
|
||||
|
||||

|
||||
|
||||
### 2. 划分子网
|
||||
|
||||
通过在网络号字段中拿一部分作为子网号,把两级 IP 地址划分为三级 IP 地址。注意,外部网络看不到子网的存在。
|
||||
|
||||
IP 地址 ::= {< 网络号 >, < 子网号 >, < 主机号 >}
|
||||
|
||||
要使用子网,必须配置子网掩码。一个 B 类地址的默认子网掩码为 255.255.0.0,如果 B 类地址的子网占两个比特,那么子网掩码为 11111111 11111111 11000000 000000,也就是 255.255.192.0。
|
||||
|
||||
### 3. 无分类编址 CIDR(构成超网)
|
||||
|
||||
CIDR 消除了传统 A 类、B 类和 C 类地址以及划分子网的概念,使用网络前缀和主机号来对 IP 地址进行编码,网络前缀的长度可以根据需要变化。
|
||||
|
||||
IP 地址 ::= {< 网络前缀号 >, < 主机号 >}
|
||||
|
||||
CIDR 的记法上采用在 IP 地址后面加上网络前缀长度的方法,例如 128.14.35.7/20 表示前 20 位为网络前缀。
|
||||
|
||||
CIDR 的地址掩码可以继续称为子网掩码,子网掩码首 1 长度为网络前缀的长度。
|
||||
|
||||
一个 CIDR 地址块中有很多地址,一个 CIDR 表示的网络就可以表示原来的很多个网络,并且在路由表中只需要一个路由就可以代替原来的多个路由,减少了路由表项的数量。把这种通过使用网络前缀来减少路由表项的方式称为路由聚合,也称为构成超网。
|
||||
|
||||
在路由表中每个项目由“网络前缀”和“下一跳地址”组成,在查找时可能会得到不止一个匹配结果,应当采用最长前缀匹配。
|
||||
|
||||
## IP 地址和 MAC 地址
|
||||
|
||||
网络层实现主机之间的通信,而链路层实现具体每段链路之间的通信。因此在通信过程中,IP 数据报的源地址和目的地址始终不变,而 MAC 地址随着链路的改变而改变。
|
||||
|
||||

|
||||
|
||||
|
||||
## 地址解析协议 ARP
|
||||
|
||||
实现由 IP 地址得到 MAC 地址。
|
||||
|
||||
每个主机都有一个 ARP 高速缓存,存放映射表。如果一个 IP 地址 到 MAC 地址的映射不在该表中,主机通过广播的方式发送 ARP 请求分组,匹配 IP 地址的主机会发送 ARP 响应分组告知 MAC 地址。
|
||||
|
||||

|
||||
|
||||
## 路由器的结构
|
||||
|
||||
路由器可以划分为两大部分:路由选择和分组转发。
|
||||
|
||||
分组转发部分由三部分组成:交换结构、一组输入端口和一组输出端口。
|
||||
|
||||

|
||||
|
||||
交换结构的交换网络有以下三种实现方式:
|
||||
|
||||

|
||||
|
||||
## 交换机与路由器的区别
|
||||
|
||||
- 交换机工作于数据链路层,能识别 MAC 地址,根据 MAC 地址转发链路层数据帧。具有自学机制来维护 IP 地址与 MAC 地址的映射。
|
||||
|
||||
- 路由器位于网络层,能识别 IP 地址并根据 IP 地址转发分组。维护着路由表,根据路由表选择最佳路线。
|
||||
|
||||
## 路由器分组转发流程
|
||||
|
||||
1. 从数据报的首部提取目的主机的 IP 地址 D,得到目的网络地址 N。(路由表项是网络号而不是 IP 地址,这样做大大减少了路由表条目数量)
|
||||
2. 若 N 就是与此路由器直接相连的某个网络地址,则进行直接交付;
|
||||
3. 若路由表中有目的地址为 D 的特定主机路由,则把数据报传送给表中所指明的下一跳路由器;
|
||||
4. 若路由表中有到达网络 N 的路由,则把数据报传送给路由表中所指明的下一跳路由器;
|
||||
5. 若路由表中有一个默认路由,则把数据报传送给路由表中所指明的默认路由器;
|
||||
6. 报告转发分组出错。
|
||||
|
||||

|
||||
|
||||
## 路由选择协议
|
||||
|
||||
互联网使用的路由选择协议都是自适应的,能随着网络通信量和拓扑变化而自适应地进行调整。
|
||||
|
||||
互联网可以划分为许多较小的自治系统 AS,一个 AS 可以使用一种和别的 AS 不同的路由选择协议。
|
||||
|
||||
可以把路由选择协议划分为两大类:
|
||||
|
||||
1. 内部网关协议 IGP(Interior Gateway Protocol) 在自治系统内部使用,如 RIP 和 OSPF。
|
||||
2. 外部网关协议 EGP(External Gateway Protocol) 在自治系统之间使用,如 BGP。
|
||||
|
||||

|
||||
|
||||
### 1. 内部网关协议 RIP
|
||||
|
||||
RIP 是一种分布式的基于距离向量的路由选择协议。距离是指跳数,直接相连的路由器跳数为 1,跳数最多为 15,超过 15 表示不可达。
|
||||
|
||||
RIP 按固定的时间间隔仅和相邻路由器交换自己的路由表,经过若干次交换之后,所有路由器最终会知道到达本自治系统中任何一个网络的最短距离和下一跳路由器地址。
|
||||
|
||||
距离向量算法:
|
||||
|
||||
1. 对地址为 X 的相邻路由器发来的 RIP 报文,先修改报文中的所有项目,把下一跳字段中的地址改为 X,并把所有的距离字段加 1;
|
||||
2. 对修改后的 RIP 报文中的每一个项目,进行以下步骤:
|
||||
- 若原来的路由表中没有目的网络 N,则把该项目添加到路由表中;
|
||||
- 否则:若下一跳路由器地址是 X,则把收到的项目替换原来路由表中的项目;否则:若收到的项目中的距离 d 小于路由表中的距离,则进行更新(例如原始路由表项为 Net2, 5, P,新表项为 Net2, 4, X,则更新);否则什么也不做。
|
||||
3. 若 3 分钟还没有收到相邻路由器的更新路由表,则把该相邻路由器标为不可达,即把距离置为 16。
|
||||
|
||||
RIP 协议实现简单,开销小,但是 RIP 能使用的最大距离为 15,限制了网络的规模。并且当网络出现故障时,要经过比较长的时间才能将此消息传送到所有路由器。
|
||||
|
||||
### 2. 内部网关协议 OSPF
|
||||
|
||||
开放最短路径优先 OSPF,是为了克服 RIP 的缺点而开发出来的。
|
||||
|
||||
开放表示 OSPF 不受某一家厂商控制,而是公开发表的;最短路径优先是因为使用了 Dijkstra 提出的最短路径算法 SPF。
|
||||
|
||||
OSPF 具有以下特点:
|
||||
|
||||
1. 向本自治系统中的所有路由器发送信息,这种方法是洪泛法。
|
||||
2. 发送的信息就是与相邻路由器的链路状态,链路状态包括与哪些路由器相连以及链路的度量,度量用费用、距离、时延、带宽等来表示。
|
||||
3. 只有当链路状态发生变化时,路由器才会发送信息。
|
||||
|
||||
所有路由器都具有全网的拓扑结构图,并且是一致的。相比于 RIP,OSPF 的更新过程收敛的很快。
|
||||
|
||||
### 3. 外部网关协议 BGP
|
||||
|
||||
AS 之间的路由选择很困难,主要是互联网规模很大。并且各个 AS 内部使用不同的路由选择协议,就无法准确定义路径的度量。并且 AS 之间的路由选择必须考虑有关的策略,比如有些 AS 不愿意让其它 AS 经过。
|
||||
|
||||
BGP 只能寻找一条比较好的路由,而不是最佳路由。它采用路径向量路由选择协议。
|
||||
|
||||
每个 AS 都必须配置 BGP 发言人,通过在两个相邻 BGP 发言人之间建立 TCP 连接来交换路由信息。
|
||||
|
||||

|
||||
|
||||
## 网际控制报文协议 ICMP
|
||||
|
||||
ICMP 是为了更有效地转发 IP 数据报和提高交付成功的机会。它封装在 IP 数据报中,但是不属于高层协议。
|
||||
|
||||

|
||||
|
||||
ICMP 报文分为差错报告报文和询问报文。
|
||||
|
||||

|
||||
|
||||
## 分组网间探测 PING
|
||||
|
||||
PING 是 ICMP 的一个重要应用,主要用来测试两台主机之间的连通性。
|
||||
|
||||
PING 的过程:
|
||||
|
||||
1. PING 同一个网段的主机,查找目的主机的 MAC 地址,然后直接交付。如果无法查找到 MAC 地址,就要进行一次 ARP 请求。
|
||||
2. PING 不同网段的主机,就发送给网关让其进行转发。同样要发送给网关也需要通过查找网关的 MAC 地址,根据 MAC 地址进行转发。
|
||||
|
||||
## IP 多播
|
||||
|
||||
在一对多的通信中,多播不需要将分组复制多份,从而大大节约网络资源。
|
||||
|
||||

|
||||
|
||||
## 虚拟专用网 VPN
|
||||
|
||||
由于 IP 地址的紧缺,一个机构能申请到的 IP 地址数往往远小于本机构所拥有的主机数。并且一个机构并不需要把所有的主机接入到外部的互联网中,机构内的计算机可以使用仅在本机构有效的 IP 地址(专用地址)。
|
||||
|
||||
有三个专用地址块:
|
||||
|
||||
1. 10.0.0.0 \~ 10.255.255.255
|
||||
2. 172.16.0.0 \~ 172.31.255.255
|
||||
3. 192.168.0.0 \~ 192.168.255.255
|
||||
|
||||
VPN 使用公用的互联网作为本机构各专用网之间的通信载体。专用指机构内的主机只与本机构内的其它主机通信;虚拟指“好像是”,而实际上并不是,它有经过公用的互联网。
|
||||
|
||||
下图中,场所 A 和 B 的通信部经过互联网,如果场所 A 的主机 X 要和另一个场所 B 的主机 Y 通信,IP 数据报的源地址是 10.1.0.1,目的地址是 10.2.0.3。数据报先发送到与互联网相连的路由器 R1,R1 对内部数据进行加密,然后重新加上数据报的首部,源地址是路由器 R1 的全球地址 125.1.2.3,目的地址是路由器 R2 的全球地址 194.4.5.6。路由器 R2 收到数据报后将数据部分进行解密,恢复原来的数据报,此时目的地址为 10.2.0.3,就交付给 Y。
|
||||
|
||||

|
||||
|
||||
## 网络地址转换 NAT
|
||||
|
||||
专用网内部的主机使用本地 IP 地址又想和互联网上的主机通信时,可以使用 NAT 来将本地 IP 转换为全球 IP。
|
||||
|
||||
在以前,NAT 将本地 IP 和全球 IP 一一对应,这种方式下拥有 n 个全球 IP 地址的专用网内最多只可以同时有 n 台主机接入互联网。为了更有效地利用全球 IP 地址,现在常用的 NAT 转换表把运输层的端口号也用上了,这样可以使得多个专用网内部的主机共用一个全球 IP 地址。使用端口号的 NAT 也叫做网络地址与端口转换 NAPT。
|
||||
|
||||

|
||||
|
||||
# 第五章 运输层
|
||||
|
||||
网络层只把分组发送到目的主机,但是真正通信的并不是主机而是主机中的进程。
|
||||
|
||||
运输层提供了应用进程间的逻辑通信。运输层向高层用户屏蔽了下面网络层的核心细节,使应用程序看见的好像在两个运输层实体之间有一条端到端的逻辑通信信道。
|
||||
|
||||
## UDP 和 TCP 的特点
|
||||
|
||||
用户数据包协议 UDP(User Datagram Protocol)
|
||||
传输控制协议 TCP(Transmission Control Protocol)
|
||||
|
||||
UDP 是无连接的,尽最大可能交付,没有拥塞控制,面向报文(对于应用程序传下来的报文不合并也不拆分,只是添加 UDP 首部)。
|
||||
|
||||
TCP 是面向连接的,提供可靠交付,有流量控制,拥塞控制,提供全双工通信,面向字节流(把应用层传下来的报文看成字节流,把字节流组织成大小不等的数据块)
|
||||
|
||||
## UDP 首部格式
|
||||
|
||||

|
||||
|
||||
首部字段只有 8 个字节,包括源端口、目的端口、长度、检验和。12 字节的伪首部是为了计算检验和而临时添加的。
|
||||
|
||||
## TCP 首部格式
|
||||
|
||||

|
||||
|
||||
**序号** :用于对字节流进行编号,例如序号为 301,表示第一个字节的编号为 301,如果携带的数据长度为 100 字节,那么下一个报文段的序号应为 401。
|
||||
|
||||
**确认号** :期望收到的下一个报文段的序号。例如 B 正确收到 A 发送来的一个报文段,序号为 501,携带的数据长度为 200 字节,因此 B 期望下一个报文段的序号为 701,B 发送给 A 的确认报文段中确认号就为 701。
|
||||
|
||||
**数据偏移** :指的是数据部分距离报文段起始处的偏移量,实际上指的是首部的长度。
|
||||
|
||||
**确认 ACK** :当 ACK=1 时确认号字段有效,否则无效。TCP 规定,在连接建立后所有传送的报文段都必须把 ACK 置 1。
|
||||
|
||||
**同步 SYN** :在连接建立时用来同步序号。当 SYN=1,ACK=0 时表示这是一个连接请求报文段。若对方同意建立连接,则响应报文中 SYN=1,ACK=1。
|
||||
|
||||
**终止 FIN** :用来释放一个连接,当 FIN=1 时,表示此报文段的发送方的数据已发送完毕,并要求释放运输连接。
|
||||
|
||||
**窗口** :窗口值作为接收方让发送方设置其发送窗口的依据。之所以要有这个限制,是因为接收方的数据缓存空间是有限的。
|
||||
|
||||
## TCP 的三次握手
|
||||
|
||||

|
||||
|
||||
假设 A 为客户端,B 为服务器端。
|
||||
|
||||
1. 首先 B 处于 LISTEN(监听)状态,等待客户的连接请求。
|
||||
2. A 向 B 发送连接请求报文段,SYN=1,ACK=0,选择一个初始的序号 x。
|
||||
3. B 收到连接请求报文段,如果同意建立连接,则向 A 发送连接确认报文段,SYN=1,ACK=1,确认号为 x+1,同时也选择一个初始的序号 y。
|
||||
4. A 收到 B 的连接确认报文段后,还要向 B 发出确认,确认号为 y+1,序号为 x+1。
|
||||
5. B 收到 A 的确认后,连接建立。
|
||||
|
||||
|
||||
## TCP 的四次挥手
|
||||
|
||||

|
||||
|
||||
以下描述不讨论序号和确认号,因为序号和确认号的规则比较简单。并且不讨论 ACK,因为 ACK 在连接建立之后都为 1。
|
||||
|
||||
1. A 发送连接释放报文段,FIN=1;
|
||||
2. B 收到之后发出确认,此时 TCP 属于半关闭状态,B 能向 A 发送数据但是 A 不能向 B 发送数据;
|
||||
3. 当 B 要不再需要连接时,发送连接释放请求报文段,FIN=1;
|
||||
4. A 收到后发出确认,此时连接释放。
|
||||
|
||||
**TIME_WAIT**
|
||||
|
||||
客户端接收到服务器端的 FIN 报文后进入此状态,此时并不是直接进入 CLOSED 状态,还需要等待一个时间计时器设置的时间。这么做有两个理由:
|
||||
|
||||
1. 确保最后一个确认报文段能够到达。如果 B 没收到 A 发送来的确认报文段,那么就会重新发送连接释放请求报文段,A 等待一段时间就是为了处理这种情况的发生。
|
||||
2. 连接过程可能“已失效的连接请求报文段”,为了防止这种报文段出现在本次连接之外,需要等待一段时间。
|
||||
|
||||
## TCP 滑动窗口
|
||||
|
||||

|
||||
|
||||
窗口是缓存的一部分,用来暂时存放字节流。发送方和接收方各有一个窗口,接收方通过 TCP 报文段中的窗口字段告诉发送方自己的窗口大小,发送方根据这个值和其它信息设置自己的窗口大小。
|
||||
|
||||
发送窗口内的字节都允许被发送,接收窗口内的字节都允许被接收。如果发送窗口左部的字节已经发送并且收到了确认,那么就将发送窗口向右滑动一定距离,直到左部第一个字节不是已发送并且已确认的状态;接收窗口的滑动类似,接收窗口左部字节已经发送确认并交付主机,就向右滑动接收窗口。
|
||||
|
||||
接收窗口只会对窗口内最后一个按序到达的字节进行确认,例如接收窗口已经收到的字节为 {31, 32, 34, 35},其中 {31, 32} 按序到达,而 {34, 35} 就不是,因此只对字节 32 进行确认。发送方得到一个字节的确认之后,就知道这个字节之前的所有字节都已经被接收。
|
||||
|
||||
## TCP 可靠传输
|
||||
|
||||
TCP 使用超时重传来实现可靠传输:如果一个已经发送的报文段在超时时间内没有收到确认,那么就重传这个报文段。
|
||||
|
||||
一个报文段从发送到接收到确认所经过的时间称为往返时间 RTT,加权平均往返时间 RTTs 计算如下:
|
||||
|
||||
*(RTTs)+a*RTT)
|
||||
|
||||
可以知道,超时时间 RTO 应该略大于 RRTs,TCP 使用的超时时间计算如下:
|
||||
|
||||
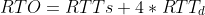
|
||||
|
||||
其中 RTT<sub>d</sub> 为偏差,它与新的 RRT 和 RRTs 有关。
|
||||
|
||||
## TCP 流量控制
|
||||
|
||||
流量控制是为了控制发送方发送速率,保证接收方来得及接收。
|
||||
|
||||
接收方发送的确认报文中的窗口字段可以用来控制发送方窗口大小,从而影响发送方的发送速率。例如将窗口字段设置为 0,则发送方不能发送数据。
|
||||
|
||||
## TCP 拥塞控制
|
||||
|
||||
如果网络出现拥塞,分组将会丢失,此时发送方会继续重传,从而导致网络拥塞程度更高。因此当出现拥塞时,应当控制发送方的速率。这一点和流量控制很像,但是出发点不同。流量控制是为了让接收方能来得及接受,而拥塞控制是为了降低整个网络的拥塞程度。
|
||||
|
||||

|
||||
|
||||
TCP 主要通过四种算法来进行拥塞控制:慢开始、拥塞避免、快重传、快恢复。发送方需要维护有一个叫做拥塞窗口(cwnd)的状态变量。注意拥塞窗口与发送方窗口的区别,拥塞窗口只是一个状态变量,实际决定发送方能发送多少数据的是发送方窗口。
|
||||
|
||||
为了便于讨论,做如下假设:
|
||||
|
||||
1. 接收方有足够大的接收缓存,因此不会发生流量控制;
|
||||
2. 虽然 TCP 的窗口基于字节,但是这里设窗口的大小单位为报文段。
|
||||
|
||||

|
||||
|
||||
### 慢开始与拥塞避免
|
||||
|
||||
发送的最初执行慢开始,令 cwnd=1,发送方只能发送 1 个报文段;当收到确认后,将 cwnd 加倍,因此之后发送方能够发送的报文段为:2、4、8 ...
|
||||
|
||||
注意到慢开始每个轮次都将 cwnd 加倍,这样会让 cwnd 增长速度非常快,从而使得发送方发送的速度增长速度过快,网络拥塞的可能也就更高。设置一个慢开始门限 ssthresh,当 cwnd >= ssthresh 时,进入拥塞避免,每个轮次只将 cwnd 加 1。
|
||||
|
||||
如果出现了超时,则令 ssthresh = cwnd / 2,然后重新执行慢开始。
|
||||
|
||||
### 快重传与快恢复
|
||||
|
||||
在接收方,要求每次接收到报文段都应该发送对已收到有序报文段的确认,例如已经接收到 M<sub>1</sub> 和 M<sub>2</sub>,此时收到 M<sub>4</sub>,应当发送对 M<sub>2</sub> 的确认。
|
||||
|
||||
在发送方,如果收到三个重复确认,那么可以确认下一个报文段丢失,例如收到三个 M<sub>2</sub> ,则 M<sub>3</sub> 丢失。此时执行快重传,立即重传下一个报文段。
|
||||
|
||||
在这种情况下,只是丢失个别报文段,而不是网络拥塞,因此执行快恢复,令 ssthresh = cwnd / 2 ,cwnd = ssthresh,注意到此时直接进入拥塞避免。
|
||||
|
||||

|
||||
|
||||
# 第六章 应用层
|
||||
|
||||
## 域名系统 DNS
|
||||
|
||||
把主机名解析为 IP 地址。
|
||||
|
||||
被设计成分布式系统。
|
||||
|
||||
### 1. 层次结构
|
||||
|
||||
一个域名由多个层次构成,从上层到下层分别为顶级域名、二级域名、三级域名以及四级域名。所有域名可以画成一颗域名树。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
域名服务器可以分为以下四类:
|
||||
|
||||
**(1) 根域名服务器**:解析顶级域名;
|
||||
|
||||
**(2) 顶级域名服务器**:解析二级域名;
|
||||
|
||||
**(3) 权限域名服务器**:解析区内的域名;
|
||||
|
||||
区和域的概念不同,可以在一个域中划分多个区。图 b 在域 abc.com 中划分了两个区:abc.com 和 y.abc.com
|
||||
|
||||

|
||||
|
||||
因此就需要两个权限域名服务器:
|
||||
|
||||

|
||||
|
||||
**(4) 本地域名服务器**:也称为默认域名服务器。可以在其中配置高速缓存。
|
||||
|
||||
### 2. 解析过程
|
||||
|
||||
主机向本地域名服务器解析的过程采用递归,而本地域名服务器向其它域名服务器解析可以使用递归和迭代两种方式。
|
||||
|
||||
迭代的方式下,本地域名服务器向一个域名服务器解析请求解析之后,结果返回到本地域名服务器,然后本地域名服务器继续向其它域名服务器请求解析;而递归地方式下,结果不是直接返回的,而是继续向前请求解析,最后的结果才会返回。
|
||||
|
||||

|
||||
|
||||
## 文件传输协议 FTP
|
||||
|
||||
FTP 在运输层使用 TCP,并且需要建立两个并行的 TCP 连接:控制连接和数据连接。控制连接在整个会话期间一直保持打开,而数据连接在数据传送完毕之后就关闭。控制连接使用端口号 21,数据连接使用端口号 20。
|
||||
|
||||

|
||||
|
||||
## 远程终端协议 TELNET
|
||||
|
||||
TELNET 用于登录到远程主机上,并且远程主机上的输出也会返回。
|
||||
|
||||
TELNET 可以适应许多计算机和操作系统的差异,例如不同操作系统系统的换行符定义。
|
||||
|
||||
## 万维网 WWW
|
||||
|
||||
见 HTTP 笔记。
|
||||
|
||||
## 电子邮件协议
|
||||
|
||||
一个电子邮件系统由三部分组成:用户代理、邮件服务器以及邮件发送协议和读取协议。其中发送协议常用 SMTP,读取协议常用 POP3 和 IMAP。
|
||||
|
||||

|
||||
|
||||
### POP3
|
||||
|
||||
POP3 的特点是只要用户从服务器上读取了邮件,就把该邮件删除。
|
||||
|
||||
### IMAP
|
||||
|
||||
IMAP 协议中客户端和服务器上的邮件保持同步,如果不去手动删除邮件,那么服务器上的邮件也不会被删除。IMAP 这种做法可以让用户随时随地去访问服务器上的邮件。IMAP 协议也支持创建自定义的文件夹。
|
||||
|
||||
### SMTP
|
||||
|
||||
SMTP 只能发送 ASCII 码,而互联网邮件扩充 MIME 可以发送二进制文件。MIME 并没有改动或者取代 SMTP,而是增加邮件主题的结构,定义了非 ASCII 码的编码规则。
|
||||
|
||||

|
||||
|
||||
## 动态主机配置协议 DHCP
|
||||
|
||||
DHCP 提供了即插即用的连网方式,用户不再需要去手动配置 IP 地址等信息。
|
||||
|
||||
DHCP 配置的内容不仅是 IP 地址,还包括子网掩码、默认路由器 IP 地址、域名服务器的 IP 地址。
|
||||
|
||||
工作方式如下:需要 IP 地址的主机广播发送 DHCP 发现报文(将目的地址置为全 1,即 255.255.255.255:67,源地址设置为全 0,即 0.0.0.0:68),DHCP 服务器收到发现报文之后,则在 IP 地址池中取一个地址,发送 DHCP 提供报文给该主机。
|
||||
|
||||
## 点对点传输 P2P
|
||||
|
||||
把某个文件分发的所有对等集合称为一个洪流。文件的数据单元称为文件块,它的大小是固定的。一个新的对等方加入某个洪流,一开始并没有文件块,但是能够从其它对等方中逐渐地下载到一些文件块,与此同时,它也为别的对等方上传一些文件块。
|
||||
|
||||
每个洪流都有一个基础设施,称为追踪器。当一个对等方加入洪流时,必须向追踪器登记,并周期性地通知追踪器它仍在洪流中。可以在任何时间加入和退出某个洪流。
|
||||
|
||||
一个新的对等方加入洪流时,追踪器会随机从洪流中选择若干个对等方,并让新对等方与这些对等方建立连接,把这些对等方称为相邻对等方。接收和发送文件块都是在相邻对等方中进行。
|
||||
|
||||
当一个对等方需要很多文件块时,通过使用最稀有优先的策略来取得文件块,也就是一个文件块在相邻对等方中副本最少,那么就优先请求这个文件块。
|
||||
|
||||
当很多对等方向同一个对等方请求文件块时,该对等方优先选择以最高速率向其发送文件块的对等方。
|
||||
|
||||
P2P 是一个分布式系统,任何时候都有对等方加入或者退出。使用分布式散列表 DHT,可以查找洪流中的资源和 IP 地址映射。
|
||||
|
||||
## 在浏览器中输入 www.baidu.com 后执行的全部过程
|
||||
|
||||
1、客户端浏览器通过 DNS 解析到 www.baidu.com 的 IP 地址 220.181.27.48,通过这个 IP 地址找到客户端到服务器的路径。客户端浏览器发起一个 HTTP 会话到 220.161.27.48,然后通过 TCP 进行封装数据包,输入到网络层。
|
||||
|
||||
2、在客户端的传输层,把 HTTP 会话请求分成报文段,添加源和目的端口,如服务器使用 80 端口监听客户端的请求,客户端由系统随机选择一个端口如 5000,与服务器进行交换,服务器把相应的请求返回给客户端的 5000 端口。然后使用 IP 层的 IP 地址查找目的端。
|
||||
|
||||
3、客户端的网络层不用关系应用层或者传输层的东西,主要做的是通过查找路由表确定如何到达服务器,期间可能经过多个路由器,这些都是由路由器来完成的工作,我不作过多的描述,无非就是通过查找路由表决定通过那个路径到达服务器。
|
||||
|
||||
4、客户端的链路层,包通过链路层发送到路由器,通过邻居协议查找给定 IP 地址的 MAC 地址,然后发送 ARP 请求查找目的地址,如果得到回应后就可以使用 ARP 的请求应答交换的 IP 数据包现在就可以传输了,然后发送 IP 数据包到达服务器的地址。
|
||||
|
||||
|
||||
## 常用端口
|
||||
|
||||
| 应用层协议 | 端口号 | 运输层协议 |
|
||||
| -- | -- | -- |
|
||||
| DNS | 53 | UDP |
|
||||
| FTP | 控制连接 21,数据连接 20 | TCP |
|
||||
| TELNET | 23 | TCP |
|
||||
| DHCP | 67 68 | UDP |
|
||||
| HTTP | 80 | TCP |
|
||||
| SMTP | 25 | TCP |
|
||||
| POP3 | 110 | TCP |
|
||||
| IMAP | 143 | TCP |
|
||||
|
||||
# 参考资料
|
||||
|
||||
- 计算机网络 第七版
|
||||
- 自顶向下计算机网络
|
||||
- [ 计算机网络之面试常考 ](https://www.nowcoder.com/discuss/1937)
|
||||
1744
notes/设计模式.md
Normal file
1744
notes/设计模式.md
Normal file
File diff suppressed because it is too large
Load Diff
307
notes/面向对象思想.md
Normal file
307
notes/面向对象思想.md
Normal file
@ -0,0 +1,307 @@
|
||||
<!-- GFM-TOC -->
|
||||
* [S.O.L.I.D](#solid)
|
||||
* [1. 单一责任原则](#1-单一责任原则)
|
||||
* [2. 开放封闭原则](#2-开放封闭原则)
|
||||
* [3. 里氏替换原则](#3-里氏替换原则)
|
||||
* [4. 接口分离原则](#4-接口分离原则)
|
||||
* [5. 依赖倒置原则](#5-依赖倒置原则)
|
||||
* [封装、继承、多态](#封装继承多态)
|
||||
* [1. 封装](#1-封装)
|
||||
* [2. 继承](#2-继承)
|
||||
* [3. 多态](#3-多态)
|
||||
* [UML](#uml)
|
||||
* [1. 类图](#1-类图)
|
||||
* [2. 时序图](#2-时序图)
|
||||
* [参考资料](#参考资料)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
# S.O.L.I.D
|
||||
|
||||
S.O.L.I.D是面向对象设计和编程(OOD&OOP)中几个重要编码原则(Programming Priciple)的首字母缩写。
|
||||
|
||||
|简写 |全拼 |中文翻译|
|
||||
| -- | -- | -- |
|
||||
|SRP| The Single Responsibility Principle |单一责任原则|
|
||||
|OCP| The Open Closed Principle | 开放封闭原则|
|
||||
|LSP| The Liskov Substitution Principle |里氏替换原则|
|
||||
|ISP| The Interface Segregation Principle |接口分离原则|
|
||||
|DIP| The Dependency Inversion Principle |依赖倒置原则|
|
||||
|
||||
|
||||
## 1. 单一责任原则
|
||||
|
||||
当需要修改某个类的时候原因有且只有一个。换句话说就是让一个类只做一种类型责任,当这个类需要承当其他类型的责任的时候,就需要分解这个类。
|
||||
|
||||
## 2. 开放封闭原则
|
||||
|
||||
软件实体应该是可扩展,而不可修改的。也就是说,对扩展是开放的,而对修改是封闭的。
|
||||
|
||||
## 3. 里氏替换原则
|
||||
|
||||
当一个子类的实例应该能够替换任何其超类的实例时,它们之间才具有 is-a 关系。
|
||||
|
||||
## 4. 接口分离原则
|
||||
|
||||
不能强迫用户去依赖那些他们不使用的接口。换句话说,使用多个专门的接口比使用单一的总接口总要好。
|
||||
|
||||
## 5. 依赖倒置原则
|
||||
|
||||
1. 高层模块不应该依赖于低层模块,二者都应该依赖于抽象
|
||||
2. 抽象不应该依赖于细节,细节应该依赖于抽象
|
||||
|
||||
# 封装、继承、多态
|
||||
|
||||
封装、继承、多态是面向对象的三大特性。
|
||||
|
||||
## 1. 封装
|
||||
|
||||
利用抽象数据类型将数据和基于数据的操作封装在一起,使其构成一个不可分割的独立实体,数据被保护在抽象数据类型的内部,尽可能地隐藏内部的细节,只保留一些对外接口使之与外部发生联系。用户是无需知道对象内部的细节,但可以通过该对象对外的提供的接口来访问该对象。
|
||||
|
||||
封装有三大好处:
|
||||
|
||||
1. 良好的封装能够减少耦合。
|
||||
|
||||
2. 类内部的结构可以自由修改。
|
||||
|
||||
3. 可以对成员进行更精确的控制。
|
||||
|
||||
4. 隐藏信息,实现细节。
|
||||
|
||||
以下 Person 类封装 name、gender、age 等属性,外界只能通过 get() 方法获取一个 Person 对象的 name 属性和 gender 属性,而无法获取 age 属性,但是 age 属性可以供 work() 方法使用。
|
||||
|
||||
注意到 gender 属性使用 int 数据类型进行存储,封装使得用户注意不到这种实现细节。并且在需要修改使用的数据类型时,也可以在不影响客户端代码的情况下进行。
|
||||
|
||||
```java
|
||||
public class Person {
|
||||
private String name;
|
||||
private int gender;
|
||||
private int age;
|
||||
|
||||
public String getName() {
|
||||
return name;
|
||||
}
|
||||
|
||||
public String getGender() {
|
||||
return gender == 0 ? "man" : "woman";
|
||||
}
|
||||
|
||||
public void work() {
|
||||
if(18 <= age && age <= 50) {
|
||||
System.out.println(name + " is working very hard!");
|
||||
} else {
|
||||
System.out.println(name + " can't work!");
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## 2. 继承
|
||||
|
||||
继承实现了 **is-a** 关系,例如 Cat 和 Animal 就是一种 is-a 关系,因此可以将 Cat 继承自 Animal,从而获得 Animal 非 private 的属性和方法。
|
||||
|
||||
Cat 可以当做 Animal 来使用,也就是可以使用 Animal 引用 Cat 对象,这种子类转换为父类称为 **向上转型**。
|
||||
|
||||
继承应该遵循里氏替换原则:当一个子类的实例应该能够替换任何其超类的实例时,它们之间才具有 is-a 关系。
|
||||
|
||||
```java
|
||||
Animal animal = new Cat();
|
||||
```
|
||||
|
||||
## 3. 多态
|
||||
|
||||
多态分为编译时多态和运行时多态。编译时多态主要指方法的重装,运行时多态指程序中定义的对象引用所指向的具体类型在运行期间才确定。
|
||||
|
||||
多态有三个条件:1. 继承;2. 覆盖父类方法;3. 向上转型。
|
||||
|
||||
下面的代码中,乐器类(Instrument)有两个子类:Wind 和 Percussion,它们都覆盖了 play() 方法,并且在 main() 方法中使用父类 Instrument 来引用 Wind 和 Percussion 对象。在 Instrument 引用调用 play() 方法时,会执行实际引用对象所在类的 play() 方法,而不是 Instrument 类的方法。
|
||||
|
||||
```java
|
||||
public class Instrument {
|
||||
public void play() {
|
||||
System.out.println("Instument is playing...");
|
||||
}
|
||||
}
|
||||
|
||||
public class Wind extends Instrument {
|
||||
public void play() {
|
||||
System.out.println("Wind is playing...");
|
||||
}
|
||||
}
|
||||
|
||||
public class Percussion extends Instrument {
|
||||
public void play() {
|
||||
System.out.println("Percussion is playing...");
|
||||
}
|
||||
}
|
||||
|
||||
public class Music {
|
||||
public static void main(String[] args){
|
||||
List<Instrument> instruments = new ArrayList<>();
|
||||
instruments.add(new Wind());
|
||||
instruments.add(new Percussion());
|
||||
for(Instrument instrument : instruments){
|
||||
instrument.play();
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
# UML
|
||||
|
||||
## 1. 类图
|
||||
|
||||
**1.1 继承相关**
|
||||
|
||||
继承有两种形式: 泛化(generalize)和实现(realize),表现为 is-a 关系。
|
||||
|
||||
① 泛化关系(generalization)
|
||||
|
||||
从具体类中继承
|
||||
|
||||

|
||||
|
||||
② 实现关系(realize)
|
||||
|
||||
从抽象类或者接口中继承
|
||||
|
||||

|
||||
|
||||
**1.2 整体和部分**
|
||||
|
||||
① 聚合关系(aggregation)
|
||||
|
||||
表示整体由部分组成,但是整体和部分不是强依赖的,整体不存在了部分还是会存在。以下表示 B 由 A 组成:
|
||||
|
||||

|
||||
|
||||
|
||||
② 组合关系(composition)
|
||||
|
||||
和聚合不同,组合中整体和部分是强依赖的,整体不存在了部分也不存在了。比如公司和部门,公司没了部门就不存在了。但是公司和员工就属于聚合关系了,因为公司没了员工还在。
|
||||
|
||||

|
||||
|
||||
**1.3 相互联系**
|
||||
|
||||
① 关联关系(association)
|
||||
|
||||
表示不同类对象之间有关联,这是一种静态关系,与运行过程的状态无关,在最开始就可以确定。因此也可以用 1 对 1、多对 1、多对多这种关联关系来表示。比如学生和学校就是一种关联关系,一个学校可以有很多学生,但是一个学生只属于一个学校,因此这是一种多对一的关系,在运行开始之前就可以确定。
|
||||
|
||||

|
||||
|
||||
② 依赖关系(dependency)
|
||||
|
||||
和关联关系不同的是, 依赖关系是在运行过程中起作用的。一般依赖作为类的构造器或者方法的参数传入。双向依赖时一种不好的设计。
|
||||
|
||||

|
||||
|
||||
|
||||
## 2. 时序图
|
||||
|
||||
**2.1 定义**
|
||||
|
||||
时序图描述了对象之间传递消息的时间顺序,它用来表示用例的行为顺序。它的主要作用是通过对象间的交互来描述用例(注意是对象),从而寻找类的操作。
|
||||
|
||||
**2.2 赤壁之战时序图**
|
||||
|
||||
从虚线从上往下表示时间的推进。
|
||||
|
||||

|
||||
|
||||
可见,通过时序图可以知道每个类具有以下操作:
|
||||
|
||||
```java
|
||||
publc class 刘备 {
|
||||
public void 应战();
|
||||
}
|
||||
|
||||
publc class 孔明 {
|
||||
public void 拟定策略();
|
||||
public void 联合孙权();
|
||||
private void 借东风火攻();
|
||||
}
|
||||
|
||||
public class 关羽 {
|
||||
public void 防守荊州();
|
||||
}
|
||||
|
||||
public class 张飞 {
|
||||
public void 防守荆州前线();
|
||||
}
|
||||
|
||||
public class 孙权 {
|
||||
public void 领兵相助();
|
||||
}
|
||||
```
|
||||
|
||||
**2.3 活动图、时序图之间的关系**
|
||||
|
||||
活动图示从用户的角度来描述用例;
|
||||
|
||||
时序图是从计算机的角度(对象间的交互)描述用例。
|
||||
|
||||
**2.4 类图与时序图的关系**
|
||||
|
||||
类图描述系统的静态结构,时序图描述系统的动态行为。
|
||||
|
||||
**2.5 时序图的组成**
|
||||
|
||||
① 对象
|
||||
|
||||
有三种表现形式
|
||||
|
||||

|
||||
|
||||
在画图时,应该遵循以下原则:
|
||||
|
||||
1. 把交互频繁的对象尽可能地靠拢。
|
||||
|
||||
2. 把初始化整个交互活动的对象(有时是一个参与者)放置在最左边。
|
||||
|
||||
② 生命线
|
||||
|
||||
生命线从对象的创建开始到对象销毁时终止
|
||||
|
||||

|
||||
|
||||
③ 消息
|
||||
|
||||
对象之间的交互式通过发送消息来实现的。
|
||||
|
||||
消息有4种类型:
|
||||
|
||||
1\. 简单消息,不区分同步异步。
|
||||
|
||||

|
||||
|
||||
2\. 同步消息,发送消息之后需要暂停活动来等待回应。
|
||||
|
||||

|
||||
|
||||
3\. 异步消息,发送消息之后不需要等待。
|
||||
|
||||

|
||||
|
||||
4\. 返回消息,可选。
|
||||
|
||||
④ 激活
|
||||
|
||||
生命线上的方框表示激活状态,其它时间处于休眠状态。
|
||||
|
||||

|
||||
|
||||
|
||||
# 参考资料
|
||||
|
||||
- Java 编程思想
|
||||
|
||||
- [面向对象设计的SOLID原则](http://www.cnblogs.com/shanyou/archive/2009/09/21/1570716.html)
|
||||
|
||||
- [看懂UML类图和时序图](http://design-patterns.readthedocs.io/zh_CN/latest/read_uml.html#generalization)
|
||||
|
||||
- [UML系列——时序图(顺序图)sequence diagram](http://www.cnblogs.com/wolf-sun/p/UML-Sequence-diagram.html)
|
||||
|
||||
- [面向对象编程三大特性------封装、继承、多态](http://blog.csdn.net/jianyuerensheng/article/details/51602015)
|
||||
Loading…
x
Reference in New Issue
Block a user