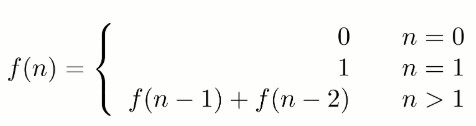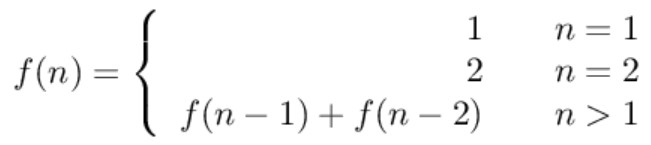diff --git a/docs/README.md b/docs/README.md
index 972f95b7..756b1422 100644
--- a/docs/README.md
+++ b/docs/README.md
@@ -1,61 +1,2 @@
-- [Github](https://github.com/CyC2018/CS-Notes)
+# 😃 该网站已迁移至 >>> [www.cyc2018.xyz](http://www.cyc2018.xyz)
-## ✏️ 算法
-
-- [剑指 Offer 题解](notes/剑指%20Offer%20题解%20-%20目录2.md)
-- [Leetcode 题解](notes/Leetcode%20题解%20-%20目录1.md)
-- [算法](notes/算法%20-%20目录1.md)
-
-## 💻 操作系统
-
-- [计算机操作系统](notes/计算机操作系统%20-%20目录1.md)
-- [Linux](notes/Linux.md)
-
-## ☁️ 网络
-
-- [计算机网络](notes/计算机网络%20-%20目录1.md)
-- [HTTP](notes/HTTP.md)
-- [Socket](notes/Socket.md)
-
-## 💾 数据库
-
-- [数据库系统原理](notes/数据库系统原理.md)
-- [SQL 语法](notes/SQL%20语法.md)
-- [SQL 练习](notes/SQL%20练习.md)
-- [MySQL](notes/MySQL.md)
-- [Redis](notes/Redis.md)
-
-## ☕️ Java
-
-- [Java 基础](notes/Java%20基础.md)
-- [Java 容器](notes/Java%20容器.md)
-- [Java 并发](notes/Java%20并发.md)
-- [Java 虚拟机](notes/Java%20虚拟机.md)
-- [Java I/O](notes/Java%20IO.md)
-
-## 💡 系统设计
-
-- [系统设计基础](notes/系统设计基础.md)
-- [分布式](notes/分布式.md)
-- [集群](notes/集群.md)
-- [攻击技术](notes/攻击技术.md)
-- [缓存](notes/缓存.md)
-- [消息队列](notes/消息队列.md)
-
-## 🎨 面向对象
-
-- [设计模式](notes/设计模式%20-%20目录1.md)
-- [面向对象思想](notes/面向对象思想.md)
-
-## 🔧 工具
-
-- [Git](notes/Git.md)
-- [Docker](notes/Docker.md)
-- [正则表达式](notes/正则表达式.md)
-- [构建工具](notes/构建工具.md)
-
-
diff --git a/docs/_404.md b/docs/_404.md
new file mode 100644
index 00000000..831dac82
--- /dev/null
+++ b/docs/_404.md
@@ -0,0 +1 @@
+# 😃 该网站已迁移至 >>> [www.cyc2018.xyz](http://www.cyc2018.xyz)
\ No newline at end of file
diff --git a/docs/_coverpage.md b/docs/_coverpage.md
index 630c6137..df3eaa88 100644
--- a/docs/_coverpage.md
+++ b/docs/_coverpage.md
@@ -7,5 +7,5 @@
[](https://github.com/CyC2018/CS-Notes) [](https://github.com/CyC2018/CS-Notes)
-[开始阅读](README.md)
+[开始阅读](http://www.cyc2018.xyz)
diff --git a/docs/index.html b/docs/index.html
index cffaa7c0..c810d4c9 100644
--- a/docs/index.html
+++ b/docs/index.html
@@ -422,7 +422,8 @@
depth: 6
},
// subMaxLevel: 2,
- coverpage: true
+ coverpage: true,
+ notFoundPage: true
}
diff --git a/docs/notes/10.1 斐波那契数列.md b/docs/notes/10.1 斐波那契数列.md
deleted file mode 100644
index 2d4326fe..00000000
--- a/docs/notes/10.1 斐波那契数列.md
+++ /dev/null
@@ -1,76 +0,0 @@
-# 10.1 斐波那契数列
-
-## 题目链接
-
-[NowCoder](https://www.nowcoder.com/practice/c6c7742f5ba7442aada113136ddea0c3?tpId=13&tqId=11160&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-求斐波那契数列的第 n 项,n <= 39。
-
-
-
-
-
-## 解题思路
-
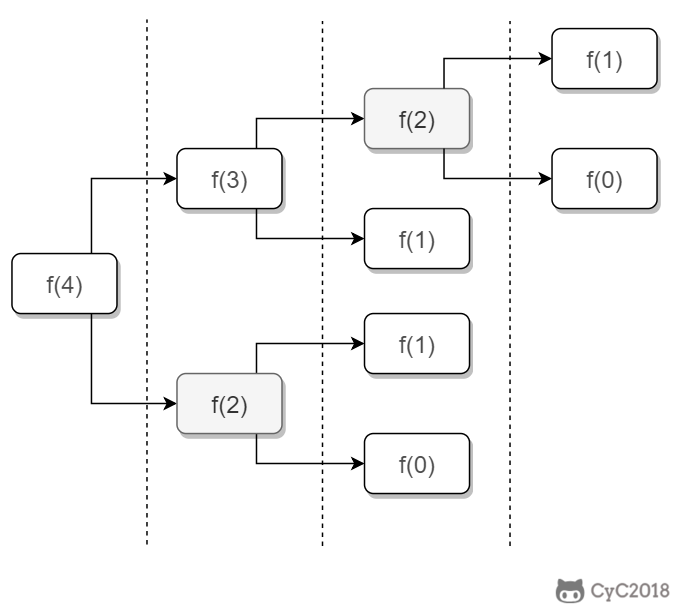
-如果使用递归求解,会重复计算一些子问题。例如,计算 f(4) 需要计算 f(3) 和 f(2),计算 f(3) 需要计算 f(2) 和 f(1),可以看到 f(2) 被重复计算了。
-
-
-
-递归是将一个问题划分成多个子问题求解,动态规划也是如此,但是动态规划会把子问题的解缓存起来,从而避免重复求解子问题。
-
-```java
-public int Fibonacci(int n) {
- if (n <= 1)
- return n;
- int[] fib = new int[n + 1];
- fib[1] = 1;
- for (int i = 2; i <= n; i++)
- fib[i] = fib[i - 1] + fib[i - 2];
- return fib[n];
-}
-```
-
-考虑到第 i 项只与第 i-1 和第 i-2 项有关,因此只需要存储前两项的值就能求解第 i 项,从而将空间复杂度由 O(N) 降低为 O(1)。
-
-```java
-public int Fibonacci(int n) {
- if (n <= 1)
- return n;
- int pre2 = 0, pre1 = 1;
- int fib = 0;
- for (int i = 2; i <= n; i++) {
- fib = pre2 + pre1;
- pre2 = pre1;
- pre1 = fib;
- }
- return fib;
-}
-```
-
-由于待求解的 n 小于 40,因此可以将前 40 项的结果先进行计算,之后就能以 O(1) 时间复杂度得到第 n 项的值。
-
-```java
-public class Solution {
-
- private int[] fib = new int[40];
-
- public Solution() {
- fib[1] = 1;
- for (int i = 2; i < fib.length; i++)
- fib[i] = fib[i - 1] + fib[i - 2];
- }
-
- public int Fibonacci(int n) {
- return fib[n];
- }
-}
-```
-
-
-
-
-
-
-
diff --git a/docs/notes/10.2 矩形覆盖.md b/docs/notes/10.2 矩形覆盖.md
deleted file mode 100644
index ecc7a646..00000000
--- a/docs/notes/10.2 矩形覆盖.md
+++ /dev/null
@@ -1,49 +0,0 @@
-# 10.2 矩形覆盖
-
-## 题目链接
-
-[NowCoder](https://www.nowcoder.com/practice/72a5a919508a4251859fb2cfb987a0e6?tpId=13&tqId=11163&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-我们可以用 2\*1 的小矩形横着或者竖着去覆盖更大的矩形。请问用 n 个 2\*1 的小矩形无重叠地覆盖一个 2\*n 的大矩形,总共有多少种方法?
-
-
-
-## 解题思路
-
-当 n 为 1 时,只有一种覆盖方法:
-
-
-
-当 n 为 2 时,有两种覆盖方法:
-
-
-
-要覆盖 2\*n 的大矩形,可以先覆盖 2\*1 的矩形,再覆盖 2\*(n-1) 的矩形;或者先覆盖 2\*2 的矩形,再覆盖 2\*(n-2) 的矩形。而覆盖 2\*(n-1) 和 2\*(n-2) 的矩形可以看成子问题。该问题的递推公式如下:
-
-
-
-
-
-```java
-public int RectCover(int n) {
- if (n <= 2)
- return n;
- int pre2 = 1, pre1 = 2;
- int result = 0;
- for (int i = 3; i <= n; i++) {
- result = pre2 + pre1;
- pre2 = pre1;
- pre1 = result;
- }
- return result;
-}
-```
-
-
-
-
-
-
-
diff --git a/docs/notes/10.3 跳台阶.md b/docs/notes/10.3 跳台阶.md
deleted file mode 100644
index bd89c6fd..00000000
--- a/docs/notes/10.3 跳台阶.md
+++ /dev/null
@@ -1,47 +0,0 @@
-# 10.3 跳台阶
-
-## 题目链接
-
-[NowCoder](https://www.nowcoder.com/practice/8c82a5b80378478f9484d87d1c5f12a4?tpId=13&tqId=11161&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-一只青蛙一次可以跳上 1 级台阶,也可以跳上 2 级。求该青蛙跳上一个 n 级的台阶总共有多少种跳法。
-
-
-
-## 解题思路
-
-当 n = 1 时,只有一种跳法:
-
-
-
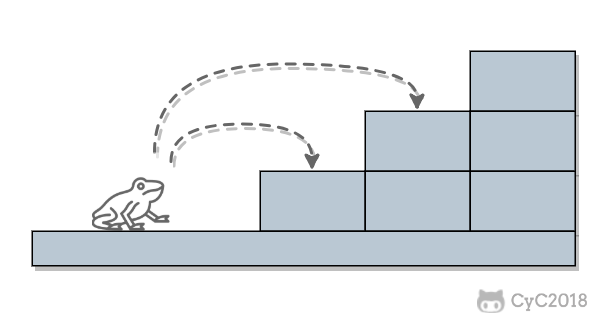
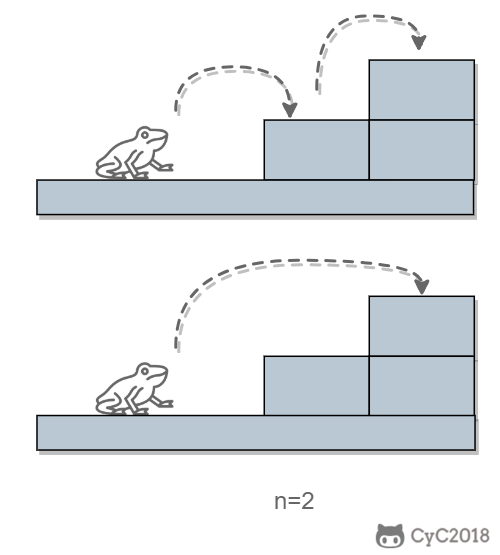
-当 n = 2 时,有两种跳法:
-
-
-
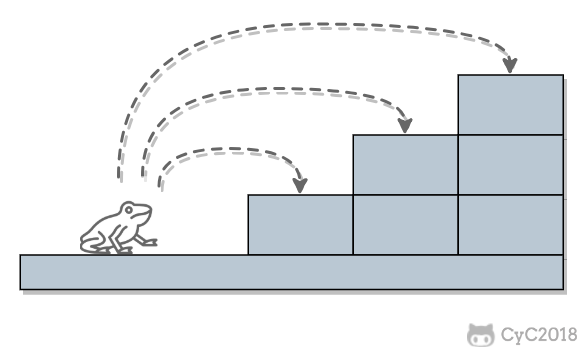
-跳 n 阶台阶,可以先跳 1 阶台阶,再跳 n-1 阶台阶;或者先跳 2 阶台阶,再跳 n-2 阶台阶。而 n-1 和 n-2 阶台阶的跳法可以看成子问题,该问题的递推公式为:
-
-
-
-```java
-public int JumpFloor(int n) {
- if (n <= 2)
- return n;
- int pre2 = 1, pre1 = 2;
- int result = 0;
- for (int i = 2; i < n; i++) {
- result = pre2 + pre1;
- pre2 = pre1;
- pre1 = result;
- }
- return result;
-}
-```
-
-
-
-
-
-
-
diff --git a/docs/notes/10.4 变态跳台阶.md b/docs/notes/10.4 变态跳台阶.md
deleted file mode 100644
index 0e779d00..00000000
--- a/docs/notes/10.4 变态跳台阶.md
+++ /dev/null
@@ -1,67 +0,0 @@
-# 10.4 变态跳台阶
-
-## 题目链接
-
-[NowCoder](https://www.nowcoder.com/practice/22243d016f6b47f2a6928b4313c85387?tpId=13&tqId=11162&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-一只青蛙一次可以跳上 1 级台阶,也可以跳上 2 级... 它也可以跳上 n 级。求该青蛙跳上一个 n 级的台阶总共有多少种跳法。
-
-
-
-## 解题思路
-
-### 动态规划
-
-```java
-public int JumpFloorII(int target) {
- int[] dp = new int[target];
- Arrays.fill(dp, 1);
- for (int i = 1; i < target; i++)
- for (int j = 0; j < i; j++)
- dp[i] += dp[j];
- return dp[target - 1];
-}
-```
-
-### 数学推导
-
-跳上 n-1 级台阶,可以从 n-2 级跳 1 级上去,也可以从 n-3 级跳 2 级上去...,那么
-
-```
-f(n-1) = f(n-2) + f(n-3) + ... + f(0)
-```
-
-同样,跳上 n 级台阶,可以从 n-1 级跳 1 级上去,也可以从 n-2 级跳 2 级上去... ,那么
-
-```
-f(n) = f(n-1) + f(n-2) + ... + f(0)
-```
-
-综上可得
-
-```
-f(n) - f(n-1) = f(n-1)
-```
-
-即
-
-```
-f(n) = 2*f(n-1)
-```
-
-所以 f(n) 是一个等比数列
-
-```source-java
-public int JumpFloorII(int target) {
- return (int) Math.pow(2, target - 1);
-}
-```
-
-
-
-
-
-
-
diff --git a/docs/notes/11. 旋转数组的最小数字.md b/docs/notes/11. 旋转数组的最小数字.md
deleted file mode 100644
index c1022565..00000000
--- a/docs/notes/11. 旋转数组的最小数字.md
+++ /dev/null
@@ -1,74 +0,0 @@
-# 11. 旋转数组的最小数字
-
-## 题目链接
-
-[牛客网](https://www.nowcoder.com/practice/9f3231a991af4f55b95579b44b7a01ba?tpId=13&tqId=11159&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-把一个数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转。输入一个非递减排序的数组的一个旋转,输出旋转数组的最小元素。
-
-
-
-## 解题思路
-
-将旋转数组对半分可以得到一个包含最小元素的新旋转数组,以及一个非递减排序的数组。新的旋转数组的长度是原数组的一半,从而将问题规模减少了一半,这种折半性质的算法的时间复杂度为 O(log2N)。
-
-
-
-此时问题的关键在于确定对半分得到的两个数组哪一个是旋转数组,哪一个是非递减数组。我们很容易知道非递减数组的第一个元素一定小于等于最后一个元素。
-
-通过修改二分查找算法进行求解(l 代表 low,m 代表 mid,h 代表 high):
-
-- 当 nums[m] <= nums[h] 时,表示 [m, h] 区间内的数组是非递减数组,[l, m] 区间内的数组是旋转数组,此时令 h = m;
-- 否则 [m + 1, h] 区间内的数组是旋转数组,令 l = m + 1。
-
-```java
-public int minNumberInRotateArray(int[] nums) {
- if (nums.length == 0)
- return 0;
- int l = 0, h = nums.length - 1;
- while (l < h) {
- int m = l + (h - l) / 2;
- if (nums[m] <= nums[h])
- h = m;
- else
- l = m + 1;
- }
- return nums[l];
-}
-```
-
-如果数组元素允许重复,会出现一个特殊的情况:nums[l] == nums[m] == nums[h],此时无法确定解在哪个区间,需要切换到顺序查找。例如对于数组 {1,1,1,0,1},l、m 和 h 指向的数都为 1,此时无法知道最小数字 0 在哪个区间。
-
-```java
-public int minNumberInRotateArray(int[] nums) {
- if (nums.length == 0)
- return 0;
- int l = 0, h = nums.length - 1;
- while (l < h) {
- int m = l + (h - l) / 2;
- if (nums[l] == nums[m] && nums[m] == nums[h])
- return minNumber(nums, l, h);
- else if (nums[m] <= nums[h])
- h = m;
- else
- l = m + 1;
- }
- return nums[l];
-}
-
-private int minNumber(int[] nums, int l, int h) {
- for (int i = l; i < h; i++)
- if (nums[i] > nums[i + 1])
- return nums[i + 1];
- return nums[l];
-}
-```
-
-
-
-
-
-
-
diff --git a/docs/notes/12. 矩阵中的路径.md b/docs/notes/12. 矩阵中的路径.md
deleted file mode 100644
index 217f5696..00000000
--- a/docs/notes/12. 矩阵中的路径.md
+++ /dev/null
@@ -1,71 +0,0 @@
-# 12. 矩阵中的路径
-
-[NowCoder](https://www.nowcoder.com/practice/c61c6999eecb4b8f88a98f66b273a3cc?tpId=13&tqId=11218&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
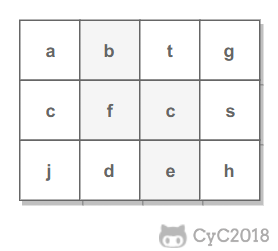
-判断在一个矩阵中是否存在一条包含某字符串所有字符的路径。路径可以从矩阵中的任意一个格子开始,每一步可以在矩阵中向上下左右移动一个格子。如果一条路径经过了矩阵中的某一个格子,则该路径不能再进入该格子。
-
-例如下面的矩阵包含了一条 bfce 路径。
-
-
-
-## 解题思路
-
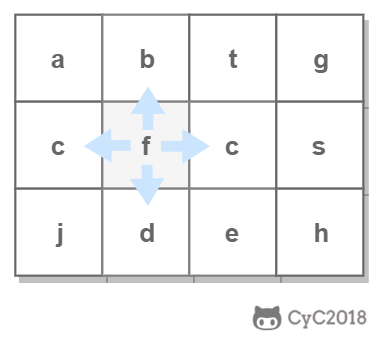
-使用回溯法(backtracking)进行求解,它是一种暴力搜索方法,通过搜索所有可能的结果来求解问题。回溯法在一次搜索结束时需要进行回溯(回退),将这一次搜索过程中设置的状态进行清除,从而开始一次新的搜索过程。例如下图示例中,从 f 开始,下一步有 4 种搜索可能,如果先搜索 b,需要将 b 标记为已经使用,防止重复使用。在这一次搜索结束之后,需要将 b 的已经使用状态清除,并搜索 c。
-
-
-
-本题的输入是数组而不是矩阵(二维数组),因此需要先将数组转换成矩阵。
-
-```java
-private final static int[][] next = {{0, -1}, {0, 1}, {-1, 0}, {1, 0}};
-private int rows;
-private int cols;
-
-public boolean hasPath(char[] array, int rows, int cols, char[] str) {
- if (rows == 0 || cols == 0) return false;
- this.rows = rows;
- this.cols = cols;
- boolean[][] marked = new boolean[rows][cols];
- char[][] matrix = buildMatrix(array);
- for (int i = 0; i < rows; i++)
- for (int j = 0; j < cols; j++)
- if (backtracking(matrix, str, marked, 0, i, j))
- return true;
-
- return false;
-}
-
-private boolean backtracking(char[][] matrix, char[] str,
- boolean[][] marked, int pathLen, int r, int c) {
-
- if (pathLen == str.length) return true;
- if (r < 0 || r >= rows || c < 0 || c >= cols
- || matrix[r][c] != str[pathLen] || marked[r][c]) {
-
- return false;
- }
- marked[r][c] = true;
- for (int[] n : next)
- if (backtracking(matrix, str, marked, pathLen + 1, r + n[0], c + n[1]))
- return true;
- marked[r][c] = false;
- return false;
-}
-
-private char[][] buildMatrix(char[] array) {
- char[][] matrix = new char[rows][cols];
- for (int r = 0, idx = 0; r < rows; r++)
- for (int c = 0; c < cols; c++)
- matrix[r][c] = array[idx++];
- return matrix;
-}
-```
-
-
-
-
-
-
-
diff --git a/docs/notes/13. 机器人的运动范围.md b/docs/notes/13. 机器人的运动范围.md
deleted file mode 100644
index 50477b07..00000000
--- a/docs/notes/13. 机器人的运动范围.md
+++ /dev/null
@@ -1,65 +0,0 @@
-# 13. 机器人的运动范围
-
-[NowCoder](https://www.nowcoder.com/practice/6e5207314b5241fb83f2329e89fdecc8?tpId=13&tqId=11219&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-地上有一个 m 行和 n 列的方格。一个机器人从坐标 (0, 0) 的格子开始移动,每一次只能向左右上下四个方向移动一格,但是不能进入行坐标和列坐标的数位之和大于 k 的格子。
-
-例如,当 k 为 18 时,机器人能够进入方格 (35,37),因为 3+5+3+7=18。但是,它不能进入方格 (35,38),因为 3+5+3+8=19。请问该机器人能够达到多少个格子?
-
-## 解题思路
-
-使用深度优先搜索(Depth First Search,DFS)方法进行求解。回溯是深度优先搜索的一种特例,它在一次搜索过程中需要设置一些本次搜索过程的局部状态,并在本次搜索结束之后清除状态。而普通的深度优先搜索并不需要使用这些局部状态,虽然还是有可能设置一些全局状态。
-
-```java
-private static final int[][] next = {{0, -1}, {0, 1}, {-1, 0}, {1, 0}};
-private int cnt = 0;
-private int rows;
-private int cols;
-private int threshold;
-private int[][] digitSum;
-
-public int movingCount(int threshold, int rows, int cols) {
- this.rows = rows;
- this.cols = cols;
- this.threshold = threshold;
- initDigitSum();
- boolean[][] marked = new boolean[rows][cols];
- dfs(marked, 0, 0);
- return cnt;
-}
-
-private void dfs(boolean[][] marked, int r, int c) {
- if (r < 0 || r >= rows || c < 0 || c >= cols || marked[r][c])
- return;
- marked[r][c] = true;
- if (this.digitSum[r][c] > this.threshold)
- return;
- cnt++;
- for (int[] n : next)
- dfs(marked, r + n[0], c + n[1]);
-}
-
-private void initDigitSum() {
- int[] digitSumOne = new int[Math.max(rows, cols)];
- for (int i = 0; i < digitSumOne.length; i++) {
- int n = i;
- while (n > 0) {
- digitSumOne[i] += n % 10;
- n /= 10;
- }
- }
- this.digitSum = new int[rows][cols];
- for (int i = 0; i < this.rows; i++)
- for (int j = 0; j < this.cols; j++)
- this.digitSum[i][j] = digitSumOne[i] + digitSumOne[j];
-}
-```
-
-
-
-
-
-
-
diff --git a/docs/notes/14. 剪绳子.md b/docs/notes/14. 剪绳子.md
deleted file mode 100644
index 853f42e4..00000000
--- a/docs/notes/14. 剪绳子.md
+++ /dev/null
@@ -1,74 +0,0 @@
-# 14. 剪绳子
-
-## 题目链接
-
-[Leetcode](https://leetcode.com/problems/integer-break/description/)
-
-## 题目描述
-
-把一根绳子剪成多段,并且使得每段的长度乘积最大。
-
-```html
-n = 2
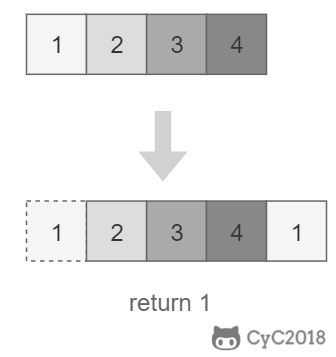
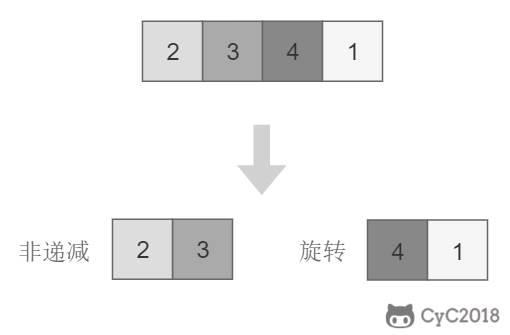
-return 1 (2 = 1 + 1)
-
-n = 10
-return 36 (10 = 3 + 3 + 4)
-```
-
-## 解题思路
-
-### 贪心
-
-尽可能得多剪长度为 3 的绳子,并且不允许有长度为 1 的绳子出现。如果出现了,就从已经切好长度为 3 的绳子中拿出一段与长度为 1 的绳子重新组合,把它们切成两段长度为 2 的绳子。以下为证明过程。
-
-将绳子拆成 1 和 n-1,则 1(n-1)-n=-1<0,即拆开后的乘积一定更小,所以不能出现长度为 1 的绳子。
-
-将绳子拆成 2 和 n-2,则 2(n-2)-n = n-4,在 n>=4 时这样拆开能得到的乘积会比不拆更大。
-
-将绳子拆成 3 和 n-3,则 3(n-3)-n = 2n-9,在 n>=5 时效果更好。
-
-将绳子拆成 4 和 n-4,因为 4=2\*2,因此效果和拆成 2 一样。
-
-将绳子拆成 5 和 n-5,因为 5=2+3,而 5<2\*3,所以不能出现 5 的绳子,而是尽可能拆成 2 和 3。
-
-将绳子拆成 6 和 n-6,因为 6=3+3,而 6<3\*3,所以不能出现 6 的绳子,而是拆成 3 和 3。这里 6 同样可以拆成 6=2+2+2,但是 3(n - 3) - 2(n - 2) = n - 5 >= 0,在 n>=5 的情况下将绳子拆成 3 比拆成 2 效果更好。
-
-继续拆成更大的绳子可以发现都比拆成 2 和 3 的效果更差,因此我们只考虑将绳子拆成 2 和 3,并且优先拆成 3,当拆到绳子长度 n 等于 4 时,也就是出现 3+1,此时只能拆成 2+2。
-
-```java
-public int integerBreak(int n) {
- if (n < 2)
- return 0;
- if (n == 2)
- return 1;
- if (n == 3)
- return 2;
- int timesOf3 = n / 3;
- if (n - timesOf3 * 3 == 1)
- timesOf3--;
- int timesOf2 = (n - timesOf3 * 3) / 2;
- return (int) (Math.pow(3, timesOf3)) * (int) (Math.pow(2, timesOf2));
-}
-```
-
-### 动态规划
-
-```java
-public int integerBreak(int n) {
- int[] dp = new int[n + 1];
- dp[1] = 1;
- for (int i = 2; i <= n; i++)
- for (int j = 1; j < i; j++)
- dp[i] = Math.max(dp[i], Math.max(j * (i - j), dp[j] * (i - j)));
- return dp[n];
-}
-```
-
-
-
-
-
-
-
-
diff --git a/docs/notes/15. 二进制中 1 的个数.md b/docs/notes/15. 二进制中 1 的个数.md
deleted file mode 100644
index d3532e14..00000000
--- a/docs/notes/15. 二进制中 1 的个数.md
+++ /dev/null
@@ -1,34 +0,0 @@
-# 15. 二进制中 1 的个数
-
-## 题目链接
-
-[牛客网](https://www.nowcoder.com/practice/8ee967e43c2c4ec193b040ea7fbb10b8?tpId=13&tqId=11164&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-输入一个整数,输出该数二进制表示中 1 的个数。
-
-### 解题思路
-
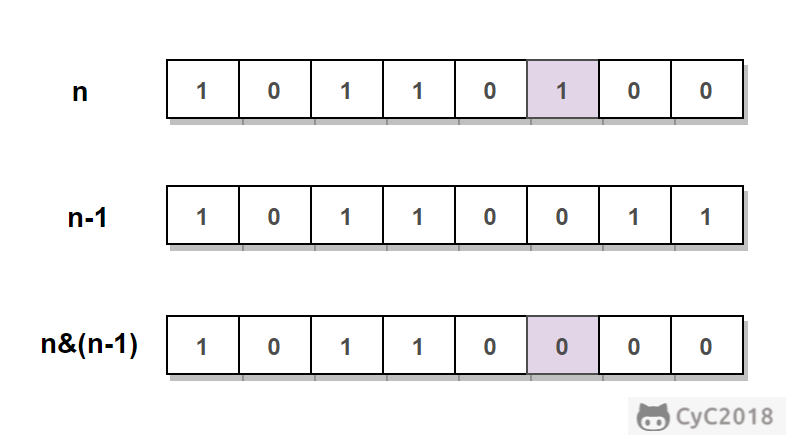
-n&(n-1) 位运算可以将 n 的位级表示中最低的那一位 1 设置为 0。不断将 1 设置为 0,直到 n 为 0。时间复杂度:O(M),其中 M 表示 1 的个数。
-
-
-
-
-```java
-public int NumberOf1(int n) {
- int cnt = 0;
- while (n != 0) {
- cnt++;
- n &= (n - 1);
- }
- return cnt;
-}
-```
-
-
-
-
-
-
-
diff --git a/docs/notes/16. 数值的整数次方.md b/docs/notes/16. 数值的整数次方.md
deleted file mode 100644
index e8e579fc..00000000
--- a/docs/notes/16. 数值的整数次方.md
+++ /dev/null
@@ -1,53 +0,0 @@
-# 16. 数值的整数次方
-
-## 题目链接
-
-[牛客网](https://www.nowcoder.com/practice/1a834e5e3e1a4b7ba251417554e07c00?tpId=13&tqId=11165&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-给定一个 double 类型的浮点数 x和 int 类型的整数 n,求 x 的 n 次方。
-
-## 解题思路
-
-
-
-最直观的解法是将 x 重复乘 n 次,x\*x\*x...\*x,那么时间复杂度为 O(N)。因为乘法是可交换的,所以可以将上述操作拆开成两半 (x\*x..\*x)\* (x\*x..\*x),两半的计算是一样的,因此只需要计算一次。而且对于新拆开的计算,又可以继续拆开。这就是分治思想,将原问题的规模拆成多个规模较小的子问题,最后子问题的解合并起来。
-
-本题中子问题是 xn/2,在将子问题合并时将子问题的解乘于自身相乘即可。但如果 n 不为偶数,那么拆成两半还会剩下一个 x,在将子问题合并时还需要需要多乘于一个 x。
-
-
-
-
-
-
-因为 (x\*x)n/2 可以通过递归求解,并且每次递归 n 都减小一半,因此整个算法的时间复杂度为 O(logN)。
-
-```java
-public double Power(double x, int n) {
- boolean isNegative = false;
- if (n < 0) {
- n = -n;
- isNegative = true;
- }
- double res = pow(x, n);
- return isNegative ? 1 / res : res;
-}
-
-private double pow(double x, int n) {
- if (n == 0) return 1;
- if (n == 1) return x;
- double res = pow(x, n / 2);
- res = res * res;
- if (n % 2 != 0) res *= x;
- return res;
-}
-```
-
-
-
-
-
-
-
-
diff --git a/docs/notes/17. 打印从 1 到最大的 n 位数.md b/docs/notes/17. 打印从 1 到最大的 n 位数.md
deleted file mode 100644
index 28ad68e5..00000000
--- a/docs/notes/17. 打印从 1 到最大的 n 位数.md
+++ /dev/null
@@ -1,47 +0,0 @@
-# 17. 打印从 1 到最大的 n 位数
-
-## 题目描述
-
-输入数字 n,按顺序打印出从 1 到最大的 n 位十进制数。比如输入 3,则打印出 1、2、3 一直到最大的 3 位数即 999。
-
-## 解题思路
-
-由于 n 可能会非常大,因此不能直接用 int 表示数字,而是用 char 数组进行存储。
-
-使用回溯法得到所有的数。
-
-```java
-public void print1ToMaxOfNDigits(int n) {
- if (n <= 0)
- return;
- char[] number = new char[n];
- print1ToMaxOfNDigits(number, 0);
-}
-
-private void print1ToMaxOfNDigits(char[] number, int digit) {
- if (digit == number.length) {
- printNumber(number);
- return;
- }
- for (int i = 0; i < 10; i++) {
- number[digit] = (char) (i + '0');
- print1ToMaxOfNDigits(number, digit + 1);
- }
-}
-
-private void printNumber(char[] number) {
- int index = 0;
- while (index < number.length && number[index] == '0')
- index++;
- while (index < number.length)
- System.out.print(number[index++]);
- System.out.println();
-}
-```
-
-
-
-
-
-
-
diff --git a/docs/notes/18.1 在 O(1) 时间内删除链表节点.md b/docs/notes/18.1 在 O(1) 时间内删除链表节点.md
deleted file mode 100644
index 8cd0a5ee..00000000
--- a/docs/notes/18.1 在 O(1) 时间内删除链表节点.md
+++ /dev/null
@@ -1,44 +0,0 @@
-# 18.1 在 O(1) 时间内删除链表节点
-
-## 解题思路
-
-① 如果该节点不是尾节点,那么可以直接将下一个节点的值赋给该节点,然后令该节点指向下下个节点,再删除下一个节点,时间复杂度为 O(1)。
-
-
-
-② 否则,就需要先遍历链表,找到节点的前一个节点,然后让前一个节点指向 null,时间复杂度为 O(N)。
-
-
-
-综上,如果进行 N 次操作,那么大约需要操作节点的次数为 N-1+N=2N-1,其中 N-1 表示 N-1 个不是尾节点的每个节点以 O(1) 的时间复杂度操作节点的总次数,N 表示 1 个尾节点以 O(N) 的时间复杂度操作节点的总次数。(2N-1)/N \~ 2,因此该算法的平均时间复杂度为 O(1)。
-
-```java
-public ListNode deleteNode(ListNode head, ListNode tobeDelete) {
- if (head == null || tobeDelete == null)
- return null;
- if (tobeDelete.next != null) {
- // 要删除的节点不是尾节点
- ListNode next = tobeDelete.next;
- tobeDelete.val = next.val;
- tobeDelete.next = next.next;
- } else {
- if (head == tobeDelete)
- // 只有一个节点
- head = null;
- else {
- ListNode cur = head;
- while (cur.next != tobeDelete)
- cur = cur.next;
- cur.next = null;
- }
- }
- return head;
-}
-```
-
-
-
-
-
-
-
diff --git a/docs/notes/18.2 删除链表中重复的结点.md b/docs/notes/18.2 删除链表中重复的结点.md
deleted file mode 100644
index 555a0754..00000000
--- a/docs/notes/18.2 删除链表中重复的结点.md
+++ /dev/null
@@ -1,32 +0,0 @@
-# 18.2 删除链表中重复的结点
-
-[NowCoder](https://www.nowcoder.com/practice/fc533c45b73a41b0b44ccba763f866ef?tpId=13&tqId=11209&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-
-
-## 解题描述
-
-```java
-public ListNode deleteDuplication(ListNode pHead) {
- if (pHead == null || pHead.next == null)
- return pHead;
- ListNode next = pHead.next;
- if (pHead.val == next.val) {
- while (next != null && pHead.val == next.val)
- next = next.next;
- return deleteDuplication(next);
- } else {
- pHead.next = deleteDuplication(pHead.next);
- return pHead;
- }
-}
-```
-
-
-
-
-
-
-
diff --git a/docs/notes/19. 正则表达式匹配.md b/docs/notes/19. 正则表达式匹配.md
deleted file mode 100644
index c8af6f83..00000000
--- a/docs/notes/19. 正则表达式匹配.md
+++ /dev/null
@@ -1,47 +0,0 @@
-# 19. 正则表达式匹配
-
-[NowCoder](https://www.nowcoder.com/practice/45327ae22b7b413ea21df13ee7d6429c?tpId=13&tqId=11205&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-请实现一个函数用来匹配包括 '.' 和 '\*' 的正则表达式。模式中的字符 '.' 表示任意一个字符,而 '\*' 表示它前面的字符可以出现任意次(包含 0 次)。
-
-在本题中,匹配是指字符串的所有字符匹配整个模式。例如,字符串 "aaa" 与模式 "a.a" 和 "ab\*ac\*a" 匹配,但是与 "aa.a" 和 "ab\*a" 均不匹配。
-
-## 解题思路
-
-应该注意到,'.' 是用来当做一个任意字符,而 '\*' 是用来重复前面的字符。这两个的作用不同,不能把 '.' 的作用和 '\*' 进行类比,从而把它当成重复前面字符一次。
-
-```java
-public boolean match(char[] str, char[] pattern) {
-
- int m = str.length, n = pattern.length;
- boolean[][] dp = new boolean[m + 1][n + 1];
-
- dp[0][0] = true;
- for (int i = 1; i <= n; i++)
- if (pattern[i - 1] == '*')
- dp[0][i] = dp[0][i - 2];
-
- for (int i = 1; i <= m; i++)
- for (int j = 1; j <= n; j++)
- if (str[i - 1] == pattern[j - 1] || pattern[j - 1] == '.')
- dp[i][j] = dp[i - 1][j - 1];
- else if (pattern[j - 1] == '*')
- if (pattern[j - 2] == str[i - 1] || pattern[j - 2] == '.') {
- dp[i][j] |= dp[i][j - 1]; // a* counts as single a
- dp[i][j] |= dp[i - 1][j]; // a* counts as multiple a
- dp[i][j] |= dp[i][j - 2]; // a* counts as empty
- } else
- dp[i][j] = dp[i][j - 2]; // a* only counts as empty
-
- return dp[m][n];
-}
-```
-
-
-
-
-
-
-
diff --git a/docs/notes/20. 表示数值的字符串.md b/docs/notes/20. 表示数值的字符串.md
deleted file mode 100644
index 8afe4f91..00000000
--- a/docs/notes/20. 表示数值的字符串.md
+++ /dev/null
@@ -1,56 +0,0 @@
-# 20. 表示数值的字符串
-
-[NowCoder](https://www.nowcoder.com/practice/6f8c901d091949a5837e24bb82a731f2?tpId=13&tqId=11206&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-```
-true
-
-"+100"
-"5e2"
-"-123"
-"3.1416"
-"-1E-16"
-```
-
-```
-false
-
-"12e"
-"1a3.14"
-"1.2.3"
-"+-5"
-"12e+4.3"
-```
-
-
-## 解题思路
-
-使用正则表达式进行匹配。
-
-```html
-[] : 字符集合
-() : 分组
-? : 重复 0 ~ 1 次
-+ : 重复 1 ~ n 次
-* : 重复 0 ~ n 次
-. : 任意字符
-\\. : 转义后的 .
-\\d : 数字
-```
-
-```java
-public boolean isNumeric(char[] str) {
- if (str == null || str.length == 0)
- return false;
- return new String(str).matches("[+-]?\\d*(\\.\\d+)?([eE][+-]?\\d+)?");
-}
-```
-
-
-
-
-
-
-
diff --git a/docs/notes/21. 调整数组顺序使奇数位于偶数前面.md b/docs/notes/21. 调整数组顺序使奇数位于偶数前面.md
deleted file mode 100644
index 2c965dab..00000000
--- a/docs/notes/21. 调整数组顺序使奇数位于偶数前面.md
+++ /dev/null
@@ -1,69 +0,0 @@
-# 21. 调整数组顺序使奇数位于偶数前面
-
-## 题目链接
-
-[牛客网](https://www.nowcoder.com/practice/beb5aa231adc45b2a5dcc5b62c93f593?tpId=13&tqId=11166&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
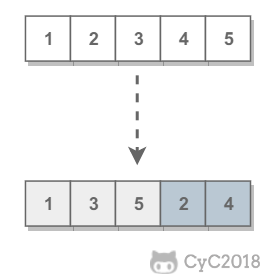
-需要保证奇数和奇数,偶数和偶数之间的相对位置不变,这和书本不太一样。例如对于 [1,2,3,4,5],调整后得到 [1,3,5,2,4],而不能是 {5,1,3,4,2} 这种相对位置改变的结果。
-
-
-
-## 解题思路
-
-方法一:创建一个新数组,时间复杂度 O(N),空间复杂度 O(N)。
-
-```java
-public void reOrderArray(int[] nums) {
- // 奇数个数
- int oddCnt = 0;
- for (int x : nums)
- if (!isEven(x))
- oddCnt++;
- int[] copy = nums.clone();
- int i = 0, j = oddCnt;
- for (int num : copy) {
- if (num % 2 == 1)
- nums[i++] = num;
- else
- nums[j++] = num;
- }
-}
-
-private boolean isEven(int x) {
- return x % 2 == 0;
-}
-```
-
-方法二:使用冒泡思想,每次都将当前偶数上浮到当前最右边。时间复杂度 O(N2),空间复杂度 O(1),时间换空间。
-
-```java
-public void reOrderArray(int[] nums) {
- int N = nums.length;
- for (int i = N - 1; i > 0; i--) {
- for (int j = 0; j < i; j++) {
- if (isEven(nums[j]) && !isEven(nums[j + 1])) {
- swap(nums, j, j + 1);
- }
- }
- }
-}
-
-private boolean isEven(int x) {
- return x % 2 == 0;
-}
-
-private void swap(int[] nums, int i, int j) {
- int t = nums[i];
- nums[i] = nums[j];
- nums[j] = t;
-}
-```
-
-
-
-
-
-
-
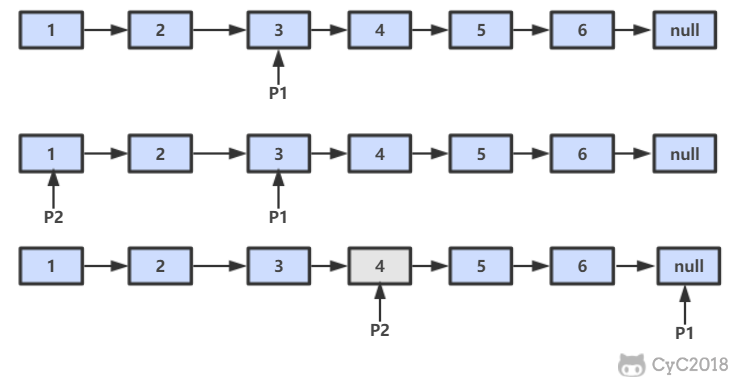
-
-```java
-public ListNode FindKthToTail(ListNode head, int k) {
- if (head == null)
- return null;
- ListNode P1 = head;
- while (P1 != null && k-- > 0)
- P1 = P1.next;
- if (k > 0)
- return null;
- ListNode P2 = head;
- while (P1 != null) {
- P1 = P1.next;
- P2 = P2.next;
- }
- return P2;
-}
-```
-
-
-
-
-
-
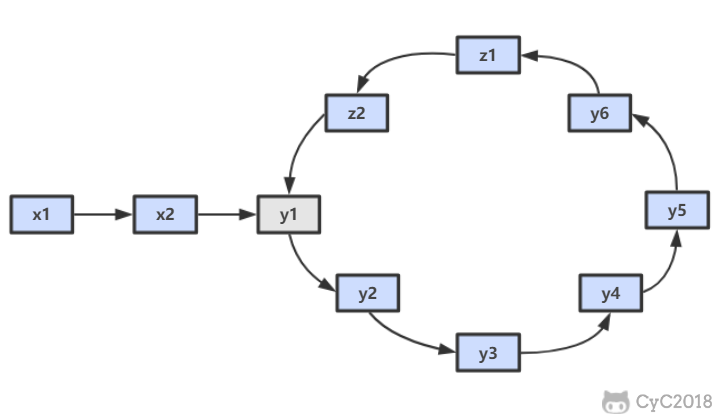
- 
-
-```java
-public ListNode EntryNodeOfLoop(ListNode pHead) {
- if (pHead == null || pHead.next == null)
- return null;
- ListNode slow = pHead, fast = pHead;
- do {
- fast = fast.next.next;
- slow = slow.next;
- } while (slow != fast);
- fast = pHead;
- while (slow != fast) {
- slow = slow.next;
- fast = fast.next;
- }
- return slow;
-}
-```
-
-
-
-
-
-
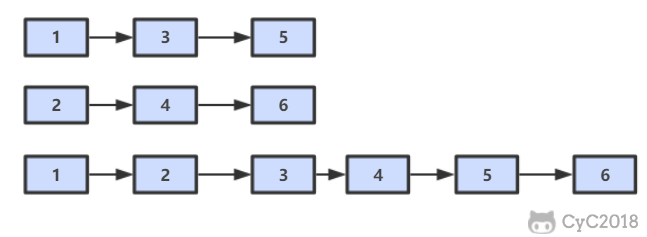
- 
-
-## 解题思路
-
-### 递归
-
-```java
-public ListNode Merge(ListNode list1, ListNode list2) {
- if (list1 == null)
- return list2;
- if (list2 == null)
- return list1;
- if (list1.val <= list2.val) {
- list1.next = Merge(list1.next, list2);
- return list1;
- } else {
- list2.next = Merge(list1, list2.next);
- return list2;
- }
-}
-```
-
-### 迭代
-
-```java
-public ListNode Merge(ListNode list1, ListNode list2) {
- ListNode head = new ListNode(-1);
- ListNode cur = head;
- while (list1 != null && list2 != null) {
- if (list1.val <= list2.val) {
- cur.next = list1;
- list1 = list1.next;
- } else {
- cur.next = list2;
- list2 = list2.next;
- }
- cur = cur.next;
- }
- if (list1 != null)
- cur.next = list1;
- if (list2 != null)
- cur.next = list2;
- return head.next;
-}
-```
-
-
-
-
-
-
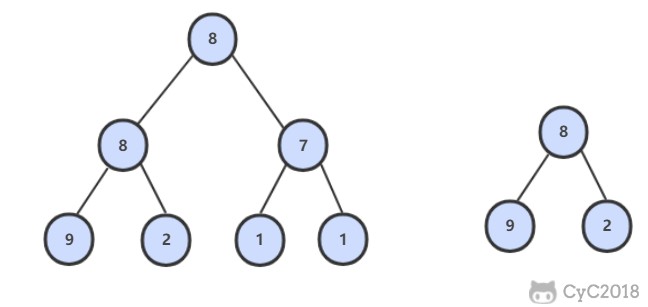
- 
-
-## 解题思路
-
-```java
-public boolean HasSubtree(TreeNode root1, TreeNode root2) {
- if (root1 == null || root2 == null)
- return false;
- return isSubtreeWithRoot(root1, root2) || HasSubtree(root1.left, root2) || HasSubtree(root1.right, root2);
-}
-
-private boolean isSubtreeWithRoot(TreeNode root1, TreeNode root2) {
- if (root2 == null)
- return true;
- if (root1 == null)
- return false;
- if (root1.val != root2.val)
- return false;
- return isSubtreeWithRoot(root1.left, root2.left) && isSubtreeWithRoot(root1.right, root2.right);
-}
-```
-
-
-
-
-
-
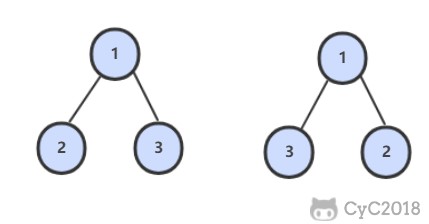
- 
-
-## 解题思路
-
-```java
-public void Mirror(TreeNode root) {
- if (root == null)
- return;
- swap(root);
- Mirror(root.left);
- Mirror(root.right);
-}
-
-private void swap(TreeNode root) {
- TreeNode t = root.left;
- root.left = root.right;
- root.right = t;
-}
-```
-
-
-
-
-
-
-
-
-## 解题思路
-
-```java
-boolean isSymmetrical(TreeNode pRoot) {
- if (pRoot == null)
- return true;
- return isSymmetrical(pRoot.left, pRoot.right);
-}
-
-boolean isSymmetrical(TreeNode t1, TreeNode t2) {
- if (t1 == null && t2 == null)
- return true;
- if (t1 == null || t2 == null)
- return false;
- if (t1.val != t2.val)
- return false;
- return isSymmetrical(t1.left, t2.right) && isSymmetrical(t1.right, t2.left);
-}
-```
-
-
-
-
-
-
- 
-
-
-
-## 解题思路
-
-一层一层从外到里打印,观察可知每一层打印都有相同的处理步骤,唯一不同的是上下左右的边界不同了。因此使用四个变量 r1, r2, c1, c2 分别存储上下左右边界值,从而定义当前最外层。打印当前最外层的顺序:从左到右打印最上一行->从上到下打印最右一行->从右到左打印最下一行->从下到上打印最左一行。应当注意只有在 r1 != r2 时才打印最下一行,也就是在当前最外层的行数大于 1 时才打印最下一行,这是因为当前最外层只有一行时,继续打印最下一行,会导致重复打印。打印最左一行也要做同样处理。
-
- 
-
-```java
-public ArrayList printMatrix(int[][] matrix) {
- ArrayList ret = new ArrayList<>();
- int r1 = 0, r2 = matrix.length - 1, c1 = 0, c2 = matrix[0].length - 1;
- while (r1 <= r2 && c1 <= c2) {
- // 上
- for (int i = c1; i <= c2; i++)
- ret.add(matrix[r1][i]);
- // 右
- for (int i = r1 + 1; i <= r2; i++)
- ret.add(matrix[i][c2]);
- if (r1 != r2)
- // 下
- for (int i = c2 - 1; i >= c1; i--)
- ret.add(matrix[r2][i]);
- if (c1 != c2)
- // 左
- for (int i = r2 - 1; i > r1; i--)
- ret.add(matrix[i][c1]);
- r1++; r2--; c1++; c2--;
- }
- return ret;
-}
-```
-
-
-
-
-
-
- 
-
-
-```java
-public boolean duplicate(int[] nums, int length, int[] duplication) {
- if (nums == null || length <= 0)
- return false;
- for (int i = 0; i < length; i++) {
- while (nums[i] != i) {
- if (nums[i] == nums[nums[i]]) {
- duplication[0] = nums[i];
- return true;
- }
- swap(nums, i, nums[i]);
- }
- }
- return false;
-}
-
-private void swap(int[] nums, int i, int j) {
- int t = nums[i];
- nums[i] = nums[j];
- nums[j] = t;
-}
-```
-
-
-
-
-
-
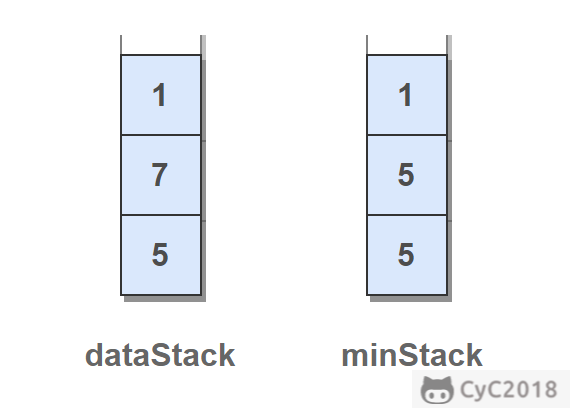
- 
-
-```java
-private Stack dataStack = new Stack<>();
-private Stack minStack = new Stack<>();
-
-public void push(int node) {
- dataStack.push(node);
- minStack.push(minStack.isEmpty() ? node : Math.min(minStack.peek(), node));
-}
-
-public void pop() {
- dataStack.pop();
- minStack.pop();
-}
-
-public int top() {
- return dataStack.peek();
-}
-
-public int min() {
- return minStack.peek();
-}
-```
-
-
-
-
-
-
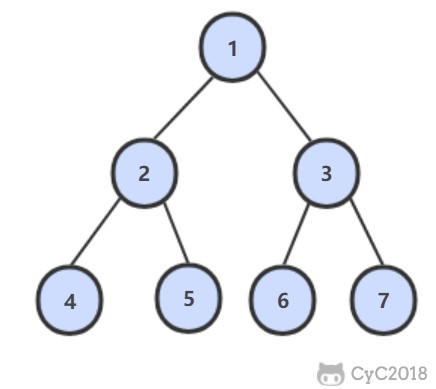
- 
-
-## 解题思路
-
-使用队列来进行层次遍历。
-
-不需要使用两个队列分别存储当前层的节点和下一层的节点,因为在开始遍历一层的节点时,当前队列中的节点数就是当前层的节点数,只要控制遍历这么多节点数,就能保证这次遍历的都是当前层的节点。
-
-```java
-public ArrayList PrintFromTopToBottom(TreeNode root) {
- Queue queue = new LinkedList<>();
- ArrayList ret = new ArrayList<>();
- queue.add(root);
- while (!queue.isEmpty()) {
- int cnt = queue.size();
- while (cnt-- > 0) {
- TreeNode t = queue.poll();
- if (t == null)
- continue;
- ret.add(t.val);
- queue.add(t.left);
- queue.add(t.right);
- }
- }
- return ret;
-}
-```
-
-
-
-
-
-
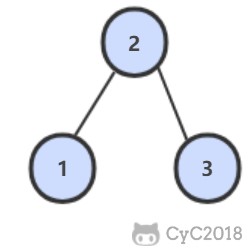
- 
-
-## 解题思路
-
-```java
-public boolean VerifySquenceOfBST(int[] sequence) {
- if (sequence == null || sequence.length == 0)
- return false;
- return verify(sequence, 0, sequence.length - 1);
-}
-
-private boolean verify(int[] sequence, int first, int last) {
- if (last - first <= 1)
- return true;
- int rootVal = sequence[last];
- int cutIndex = first;
- while (cutIndex < last && sequence[cutIndex] <= rootVal)
- cutIndex++;
- for (int i = cutIndex; i < last; i++)
- if (sequence[i] < rootVal)
- return false;
- return verify(sequence, first, cutIndex - 1) && verify(sequence, cutIndex, last - 1);
-}
-```
-
-
-
-
-
-
- 
-
-## 解题思路
-
-```java
-private ArrayList> ret = new ArrayList<>();
-
-public ArrayList> FindPath(TreeNode root, int target) {
- backtracking(root, target, new ArrayList<>());
- return ret;
-}
-
-private void backtracking(TreeNode node, int target, ArrayList path) {
- if (node == null)
- return;
- path.add(node.val);
- target -= node.val;
- if (target == 0 && node.left == null && node.right == null) {
- ret.add(new ArrayList<>(path));
- } else {
- backtracking(node.left, target, path);
- backtracking(node.right, target, path);
- }
- path.remove(path.size() - 1);
-}
-```
-
-
-
-
-
-
- 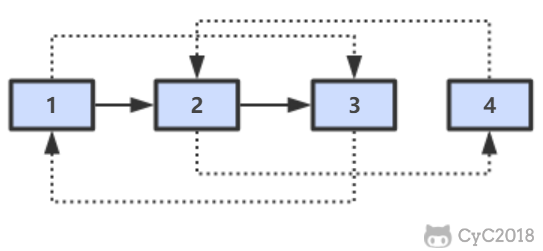
-
-## 解题思路
-
-第一步,在每个节点的后面插入复制的节点。
-
- 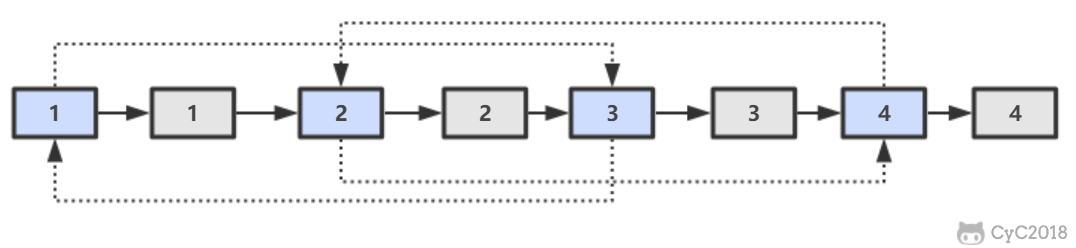
-
-第二步,对复制节点的 random 链接进行赋值。
-
- 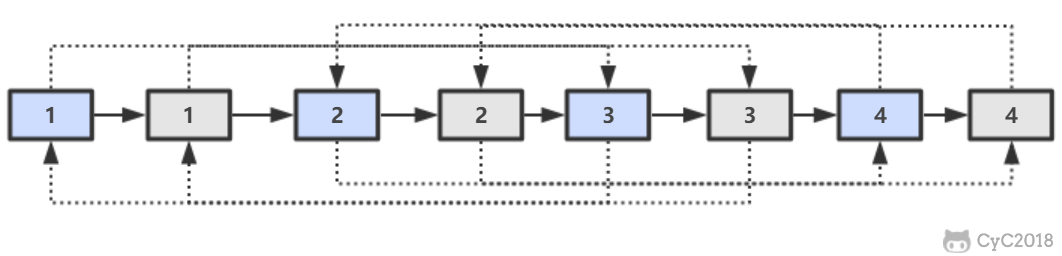
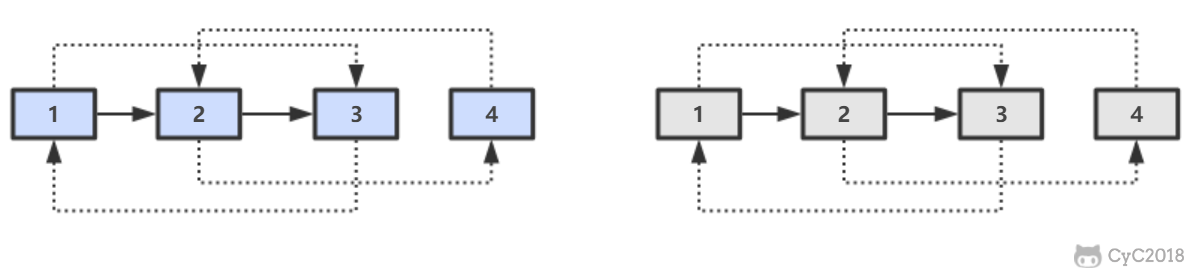
-
-第三步,拆分。
-
- 
-
-```java
-public RandomListNode Clone(RandomListNode pHead) {
- if (pHead == null)
- return null;
- // 插入新节点
- RandomListNode cur = pHead;
- while (cur != null) {
- RandomListNode clone = new RandomListNode(cur.label);
- clone.next = cur.next;
- cur.next = clone;
- cur = clone.next;
- }
- // 建立 random 链接
- cur = pHead;
- while (cur != null) {
- RandomListNode clone = cur.next;
- if (cur.random != null)
- clone.random = cur.random.next;
- cur = clone.next;
- }
- // 拆分
- cur = pHead;
- RandomListNode pCloneHead = pHead.next;
- while (cur.next != null) {
- RandomListNode next = cur.next;
- cur.next = next.next;
- cur = next;
- }
- return pCloneHead;
-}
-```
-
-
-
-
-
-
- 
-
-## 解题思路
-
-```java
-private TreeNode pre = null;
-private TreeNode head = null;
-
-public TreeNode Convert(TreeNode root) {
- inOrder(root);
- return head;
-}
-
-private void inOrder(TreeNode node) {
- if (node == null)
- return;
- inOrder(node.left);
- node.left = pre;
- if (pre != null)
- pre.right = node;
- pre = node;
- if (head == null)
- head = node;
- inOrder(node.right);
-}
-```
-
-
-
-
-
-
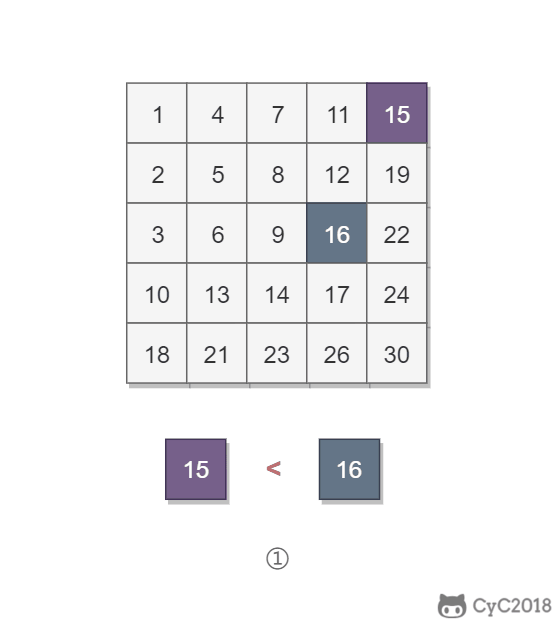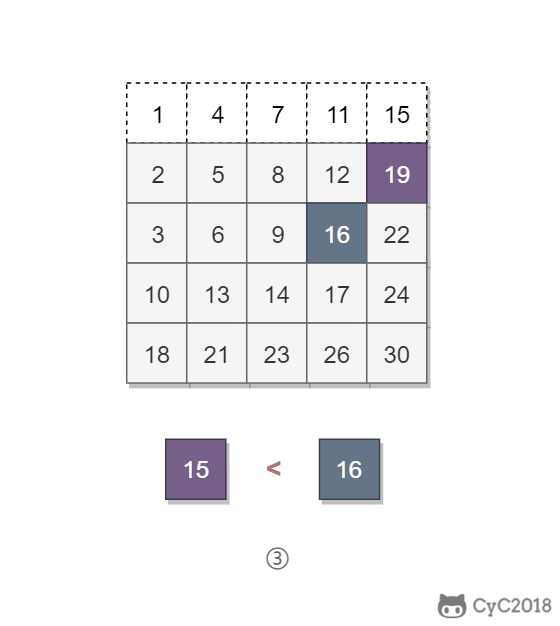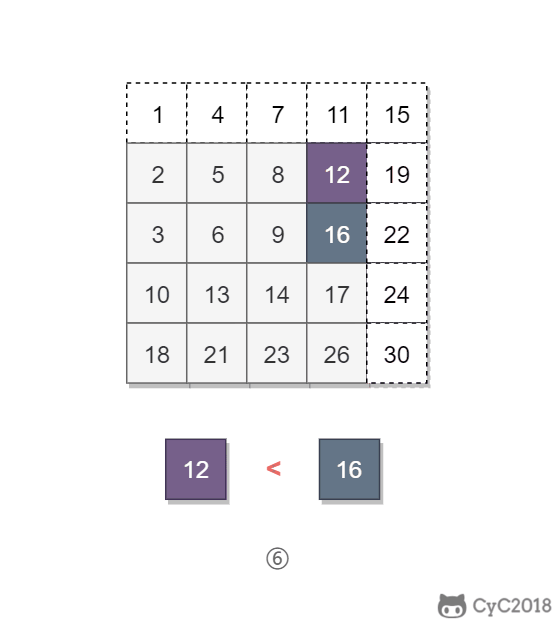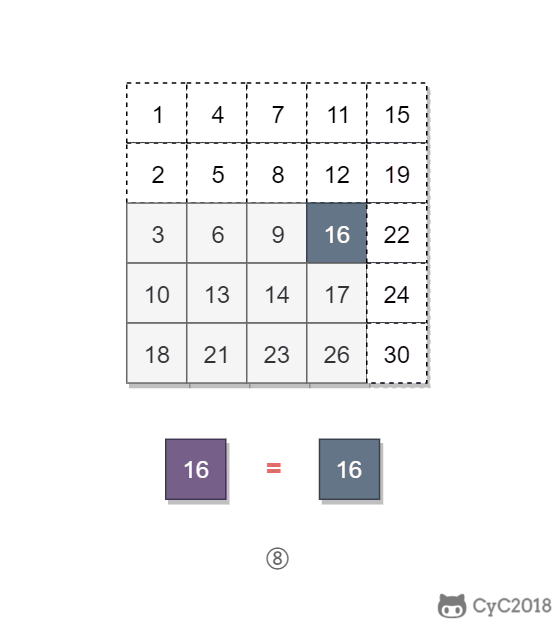
- 
-
-```java
-public boolean Find(int target, int[][] matrix) {
- if (matrix == null || matrix.length == 0 || matrix[0].length == 0)
- return false;
- int rows = matrix.length, cols = matrix[0].length;
- int r = 0, c = cols - 1; // 从右上角开始
- while (r <= rows - 1 && c >= 0) {
- if (target == matrix[r][c])
- return true;
- else if (target > matrix[r][c])
- r++;
- else
- c--;
- }
- return false;
-}
-```
-
-
-
-
-
-
- 
-
-```java
-public String replaceSpace(StringBuffer str) {
- int P1 = str.length() - 1;
- for (int i = 0; i <= P1; i++)
- if (str.charAt(i) == ' ')
- str.append(" ");
-
- int P2 = str.length() - 1;
- while (P1 >= 0 && P2 > P1) {
- char c = str.charAt(P1--);
- if (c == ' ') {
- str.setCharAt(P2--, '0');
- str.setCharAt(P2--, '2');
- str.setCharAt(P2--, '%');
- } else {
- str.setCharAt(P2--, c);
- }
- }
- return str.toString();
-}
-```
-
-
-
-
-
-
- 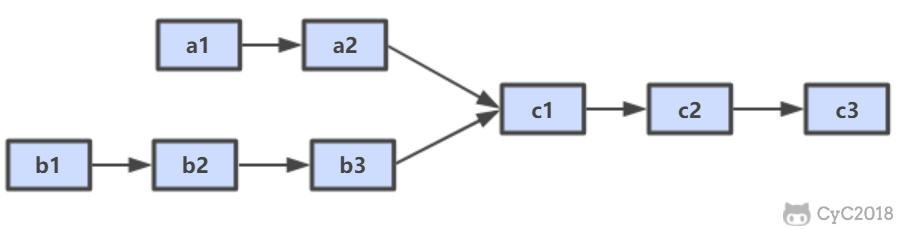
-
-## 解题思路
-
-设 A 的长度为 a + c,B 的长度为 b + c,其中 c 为尾部公共部分长度,可知 a + c + b = b + c + a。
-
-当访问链表 A 的指针访问到链表尾部时,令它从链表 B 的头部重新开始访问链表 B;同样地,当访问链表 B 的指针访问到链表尾部时,令它从链表 A 的头部重新开始访问链表 A。这样就能控制访问 A 和 B 两个链表的指针能同时访问到交点。
-
-```java
-public ListNode FindFirstCommonNode(ListNode pHead1, ListNode pHead2) {
- ListNode l1 = pHead1, l2 = pHead2;
- while (l1 != l2) {
- l1 = (l1 == null) ? pHead2 : l1.next;
- l2 = (l2 == null) ? pHead1 : l2.next;
- }
- return l1;
-}
-```
-
-
-
-
-
-
- 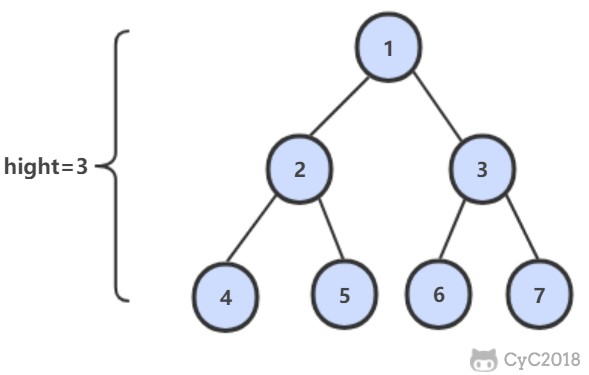
-
-## 解题思路
-
-```java
-public int TreeDepth(TreeNode root) {
- return root == null ? 0 : 1 + Math.max(TreeDepth(root.left), TreeDepth(root.right));
-}
-```
-
-
-
-
-
-
- 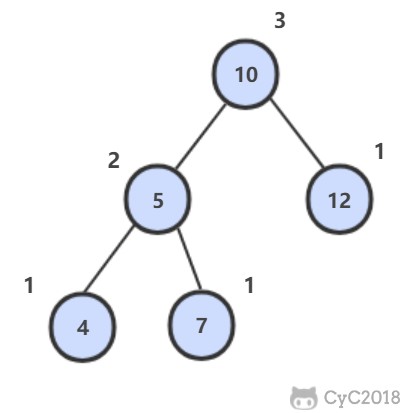
-
-## 解题思路
-
-```java
-private boolean isBalanced = true;
-
-public boolean IsBalanced_Solution(TreeNode root) {
- height(root);
- return isBalanced;
-}
-
-private int height(TreeNode root) {
- if (root == null || !isBalanced)
- return 0;
- int left = height(root.left);
- int right = height(root.right);
- if (Math.abs(left - right) > 1)
- isBalanced = false;
- return 1 + Math.max(left, right);
-}
-```
-
-
-
-
-
-
-
-
-## 解题思路
-
-维护一个大小为窗口大小的大顶堆,顶堆元素则为当前窗口的最大值。
-
-假设窗口的大小为 M,数组的长度为 N。在窗口向右移动时,需要先在堆中删除离开窗口的元素,并将新到达的元素添加到堆中,这两个操作的时间复杂度都为 log2M,因此算法的时间复杂度为 O(Nlog2M),空间复杂度为 O(M)。
-
-```java
-public ArrayList maxInWindows(int[] num, int size) {
- ArrayList ret = new ArrayList<>();
- if (size > num.length || size < 1)
- return ret;
- PriorityQueue heap = new PriorityQueue<>((o1, o2) -> o2 - o1); /* 大顶堆 */
- for (int i = 0; i < size; i++)
- heap.add(num[i]);
- ret.add(heap.peek());
- for (int i = 0, j = i + size; j < num.length; i++, j++) { /* 维护一个大小为 size 的大顶堆 */
- heap.remove(num[i]);
- heap.add(num[j]);
- ret.add(heap.peek());
- }
- return ret;
-}
-```
-
-
-
-
-
-
- 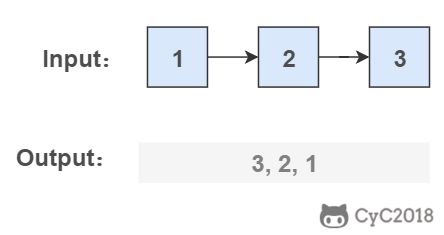
-
-## 解题思路
-
-### 1. 使用递归
-
-要逆序打印链表 1->2->3(3,2,1),可以先逆序打印链表 2->3(3,2),最后再打印第一个节点 1。而链表 2->3 可以看成一个新的链表,要逆序打印该链表可以继续使用求解函数,也就是在求解函数中调用自己,这就是递归函数。
-
-```java
-public ArrayList printListFromTailToHead(ListNode listNode) {
- ArrayList ret = new ArrayList<>();
- if (listNode != null) {
- ret.addAll(printListFromTailToHead(listNode.next));
- ret.add(listNode.val);
- }
- return ret;
-}
-```
-
-### 2. 使用头插法
-
-头插法顾名思义是将节点插入到头部:在遍历原始链表时,将当前节点插入新链表的头部,使其成为第一个节点。
-
-链表的操作需要维护后继关系,例如在某个节点 node1 之后插入一个节点 node2,我们可以通过修改后继关系来实现:
-
-```java
-node3 = node1.next;
-node2.next = node3;
-node1.next = node2;
-```
-
- 
-
-
-
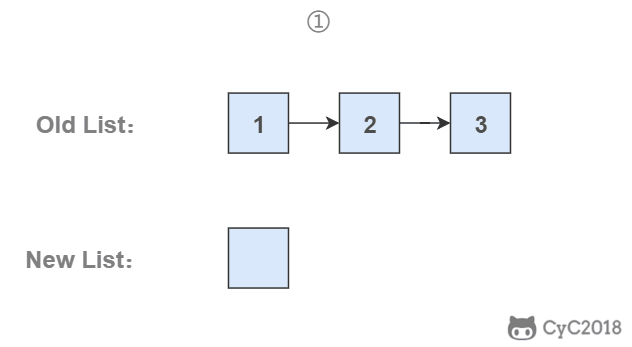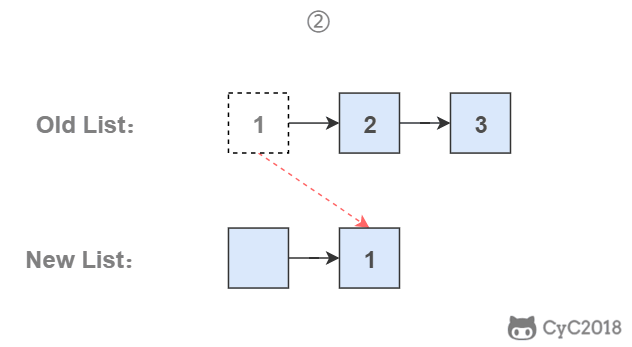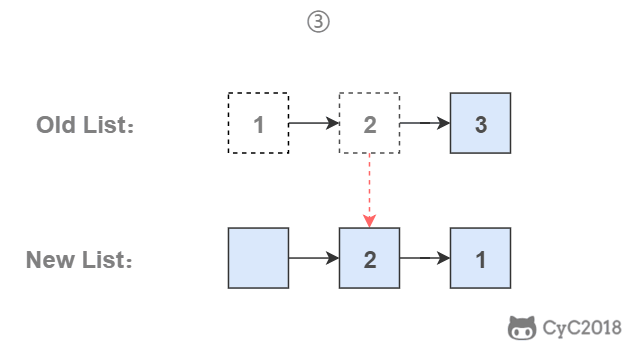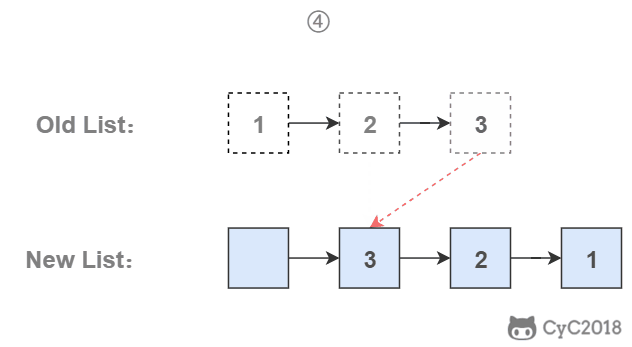
-为了能将一个节点插入头部,我们引入了一个叫头结点的辅助节点,该节点不存储值,只是为了方便进行插入操作。不要将头结点与第一个节点混起来,第一个节点是链表中第一个真正存储值的节点。
-
- 
-
-```java
-public ArrayList printListFromTailToHead(ListNode listNode) {
- // 头插法构建逆序链表
- ListNode head = new ListNode(-1);
- while (listNode != null) {
- ListNode memo = listNode.next;
- listNode.next = head.next;
- head.next = listNode;
- listNode = memo;
- }
- // 构建 ArrayList
- ArrayList ret = new ArrayList<>();
- head = head.next;
- while (head != null) {
- ret.add(head.val);
- head = head.next;
- }
- return ret;
-}
-```
-
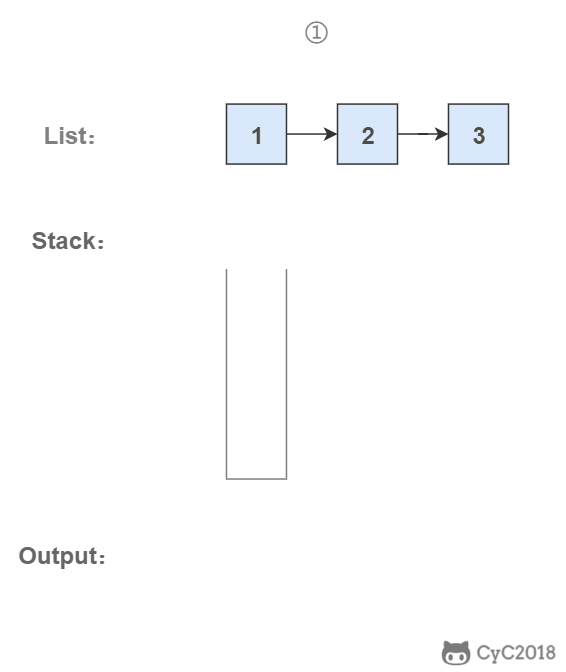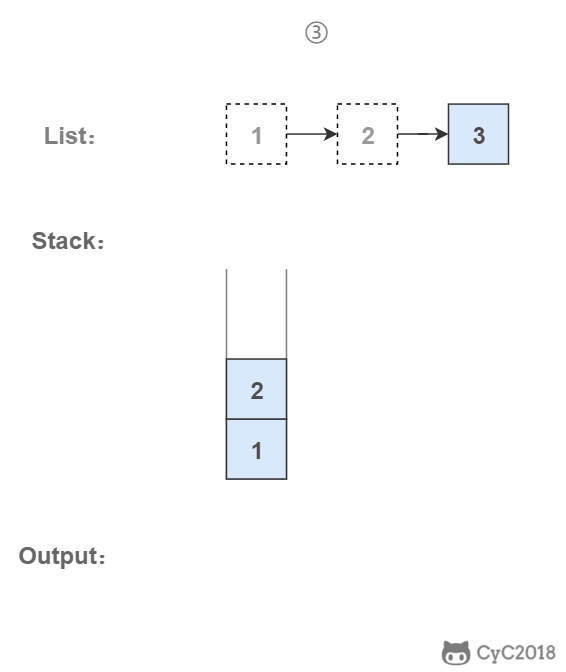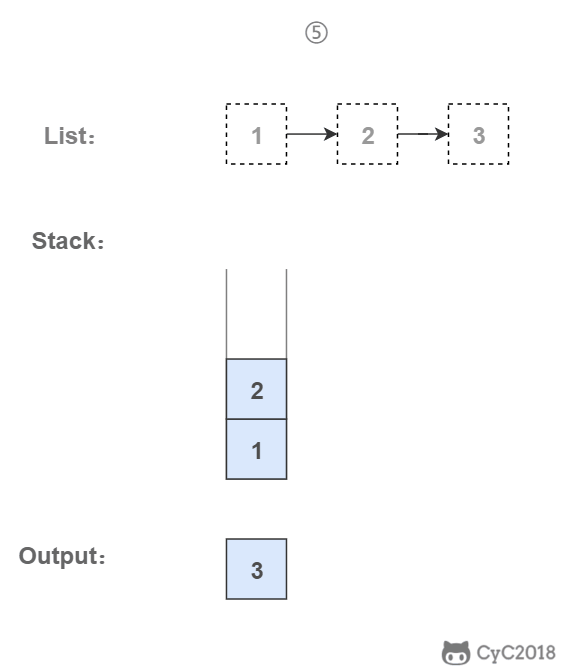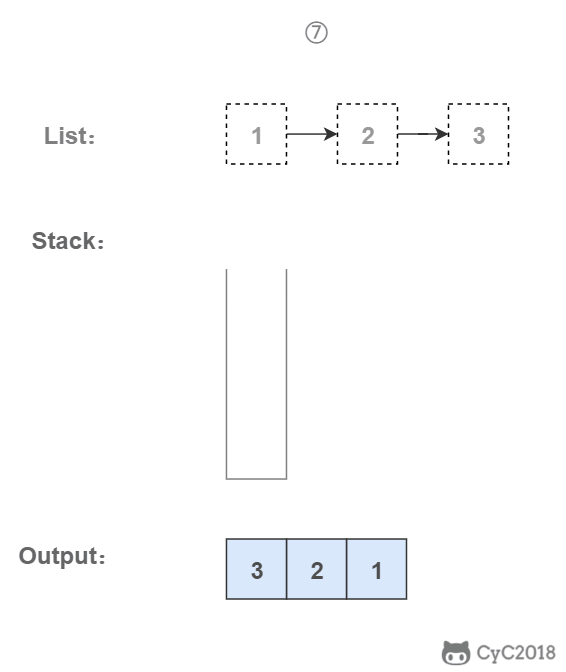
-### 3. 使用栈
-
-栈具有后进先出的特点,在遍历链表时将值按顺序放入栈中,最后出栈的顺序即为逆序。
-
- 
-
-```java
-public ArrayList printListFromTailToHead(ListNode listNode) {
- Stack stack = new Stack<>();
- while (listNode != null) {
- stack.add(listNode.val);
- listNode = listNode.next;
- }
- ArrayList ret = new ArrayList<>();
- while (!stack.isEmpty())
- ret.add(stack.pop());
- return ret;
-}
-```
-
-
-
-
-
-
-
diff --git a/docs/notes/60. n 个骰子的点数.md b/docs/notes/60. n 个骰子的点数.md
deleted file mode 100644
index d298cc9a..00000000
--- a/docs/notes/60. n 个骰子的点数.md
+++ /dev/null
@@ -1,81 +0,0 @@
-# 60. n 个骰子的点数
-
-## 题目链接
-
-[Lintcode](https://www.lintcode.com/en/problem/dices-sum/)
-
-## 题目描述
-
-把 n 个骰子扔在地上,求点数和为 s 的概率。
-
-
-
-## 解题思路
-
-### 动态规划
-
-使用一个二维数组 dp 存储点数出现的次数,其中 dp\[i]\[j] 表示前 i 个骰子产生点数 j 的次数。
-
-空间复杂度:O(N2)
-
-```java
-public List> dicesSum(int n) {
- final int face = 6;
- final int pointNum = face * n;
- long[][] dp = new long[n + 1][pointNum + 1];
-
- for (int i = 1; i <= face; i++)
- dp[1][i] = 1;
-
- for (int i = 2; i <= n; i++)
- for (int j = i; j <= pointNum; j++) /* 使用 i 个骰子最小点数为 i */
- for (int k = 1; k <= face && k <= j; k++)
- dp[i][j] += dp[i - 1][j - k];
-
- final double totalNum = Math.pow(6, n);
- List> ret = new ArrayList<>();
- for (int i = n; i <= pointNum; i++)
- ret.add(new AbstractMap.SimpleEntry<>(i, dp[n][i] / totalNum));
-
- return ret;
-}
-```
-
-### 动态规划 + 旋转数组
-
-空间复杂度:O(N)
-
-```java
-public List> dicesSum(int n) {
- final int face = 6;
- final int pointNum = face * n;
- long[][] dp = new long[2][pointNum + 1];
-
- for (int i = 1; i <= face; i++)
- dp[0][i] = 1;
-
- int flag = 1; /* 旋转标记 */
- for (int i = 2; i <= n; i++, flag = 1 - flag) {
- for (int j = 0; j <= pointNum; j++)
- dp[flag][j] = 0; /* 旋转数组清零 */
-
- for (int j = i; j <= pointNum; j++)
- for (int k = 1; k <= face && k <= j; k++)
- dp[flag][j] += dp[1 - flag][j - k];
- }
-
- final double totalNum = Math.pow(6, n);
- List> ret = new ArrayList<>();
- for (int i = n; i <= pointNum; i++)
- ret.add(new AbstractMap.SimpleEntry<>(i, dp[1 - flag][i] / totalNum));
-
- return ret;
-}
-```
-
-
-
-
-
-
- 
-
-
-## 解题思路
-
-```java
-public boolean isContinuous(int[] nums) {
-
- if (nums.length < 5)
- return false;
-
- Arrays.sort(nums);
-
- // 统计癞子数量
- int cnt = 0;
- for (int num : nums)
- if (num == 0)
- cnt++;
-
- // 使用癞子去补全不连续的顺子
- for (int i = cnt; i < nums.length - 1; i++) {
- if (nums[i + 1] == nums[i])
- return false;
- cnt -= nums[i + 1] - nums[i] - 1;
- }
-
- return cnt >= 0;
-}
-```
-
-
-
-
-
-
- 
-
-## 解题思路
-
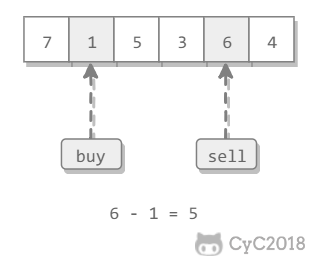
-使用贪心策略,假设第 i 轮进行卖出操作,买入操作价格应该在 i 之前并且价格最低。因此在遍历数组时记录当前最低的买入价格,并且尝试将每个位置都作为卖出价格,取收益最大的即可。
-
-```java
-public int maxProfit(int[] prices) {
- if (prices == null || prices.length == 0)
- return 0;
- int soFarMin = prices[0];
- int maxProfit = 0;
- for (int i = 1; i < prices.length; i++) {
- soFarMin = Math.min(soFarMin, prices[i]);
- maxProfit = Math.max(maxProfit, prices[i] - soFarMin);
- }
- return maxProfit;
-}
-```
-
-
-
-
-
-
- 
-
-
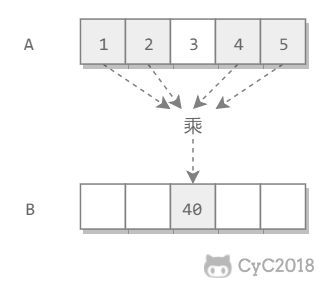
-## 解题思路
-
-```java
-public int[] multiply(int[] A) {
- int n = A.length;
- int[] B = new int[n];
- for (int i = 0, product = 1; i < n; product *= A[i], i++) /* 从左往右累乘 */
- B[i] = product;
- for (int i = n - 1, product = 1; i >= 0; product *= A[i], i--) /* 从右往左累乘 */
- B[i] *= product;
- return B;
-}
-```
-
-
-
-
-
-
- 
-
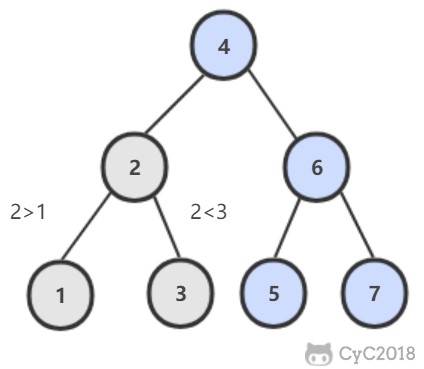
-```java
-public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
- if (root == null)
- return root;
- if (root.val > p.val && root.val > q.val)
- return lowestCommonAncestor(root.left, p, q);
- if (root.val < p.val && root.val < q.val)
- return lowestCommonAncestor(root.right, p, q);
- return root;
-}
-```
-
-## 68.2 普通二叉树
-
-### 题目链接
-
-[Leetcode : 236. Lowest Common Ancestor of a Binary Tree](https://leetcode.com/problems/lowest-common-ancestor-of-a-binary-tree/description/)
-
-### 解题思路
-
-在左右子树中查找是否存在 p 或者 q,如果 p 和 q 分别在两个子树中,那么就说明根节点就是最低公共祖先。
-
- 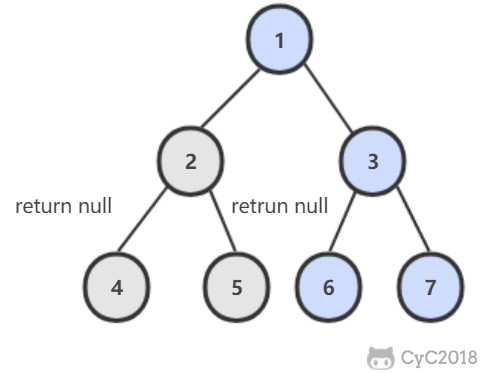
-
-```java
-public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
- if (root == null || root == p || root == q)
- return root;
- TreeNode left = lowestCommonAncestor(root.left, p, q);
- TreeNode right = lowestCommonAncestor(root.right, p, q);
- return left == null ? right : right == null ? left : root;
-}
-```
-
-
-
-
-
-
- 
-
-## 解题思路
-
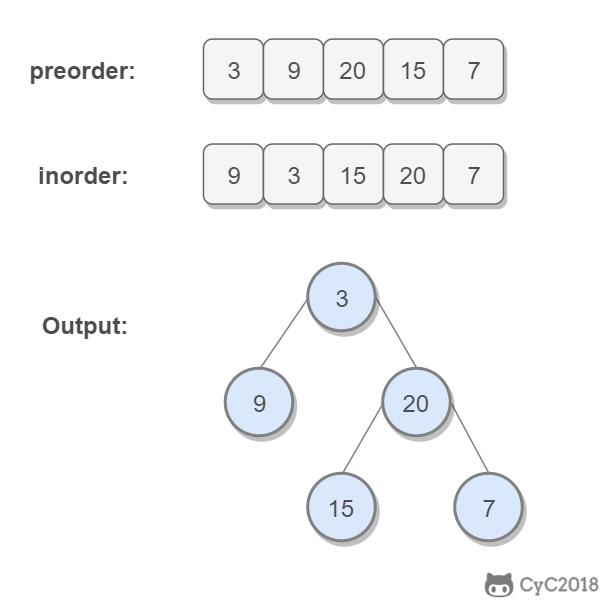
-前序遍历的第一个值为根节点的值,使用这个值将中序遍历结果分成两部分,左部分为树的左子树中序遍历结果,右部分为树的右子树中序遍历的结果。然后分别对左右子树递归地求解。
-
- 
-
-```java
-// 缓存中序遍历数组每个值对应的索引
-private Map indexForInOrders = new HashMap<>();
-
-public TreeNode reConstructBinaryTree(int[] pre, int[] in) {
- for (int i = 0; i < in.length; i++)
- indexForInOrders.put(in[i], i);
- return reConstructBinaryTree(pre, 0, pre.length - 1, 0);
-}
-
-private TreeNode reConstructBinaryTree(int[] pre, int preL, int preR, int inL) {
- if (preL > preR)
- return null;
- TreeNode root = new TreeNode(pre[preL]);
- int inIndex = indexForInOrders.get(root.val);
- int leftTreeSize = inIndex - inL;
- root.left = reConstructBinaryTree(pre, preL + 1, preL + leftTreeSize, inL);
- root.right = reConstructBinaryTree(pre, preL + leftTreeSize + 1, preR, inL + leftTreeSize + 1);
- return root;
-}
-```
-
-
-
-
-
-
- 
-
-
-
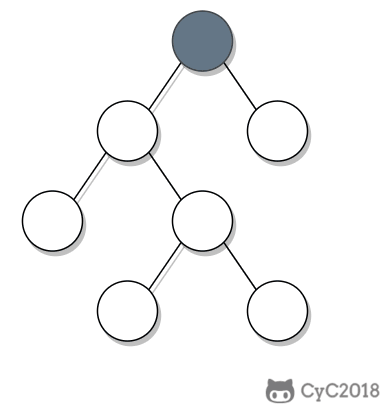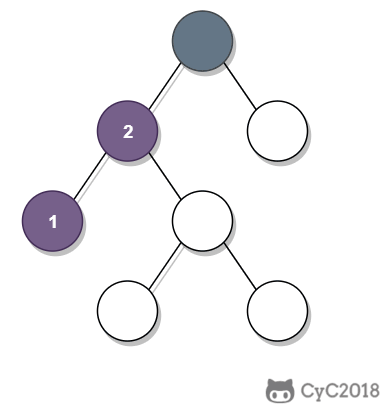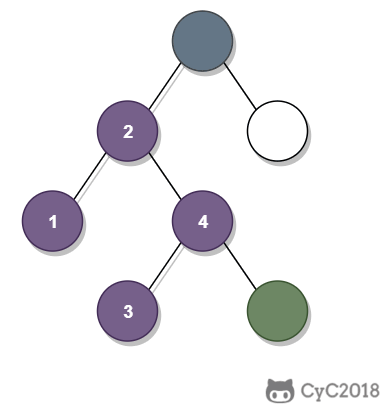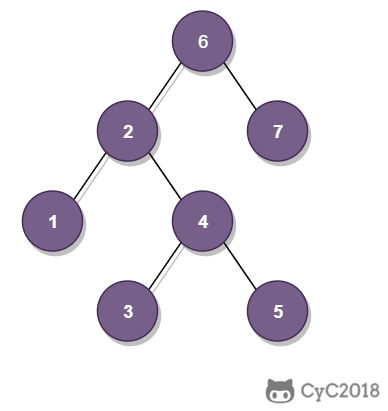
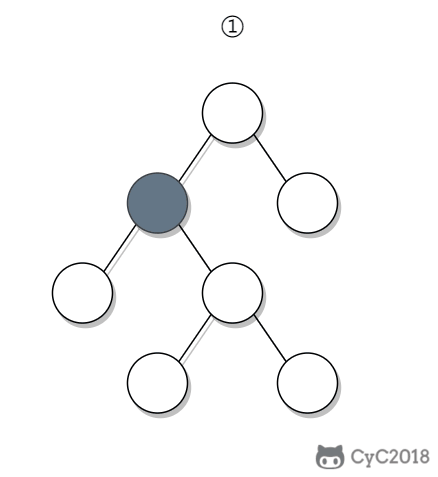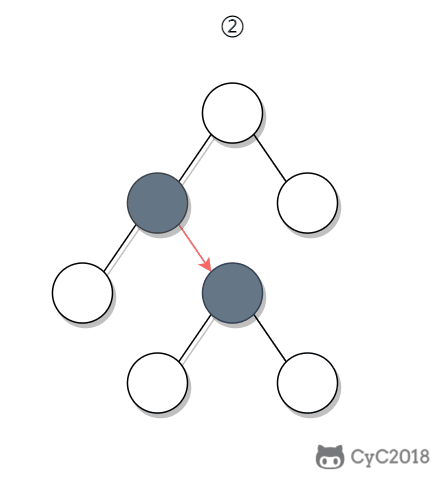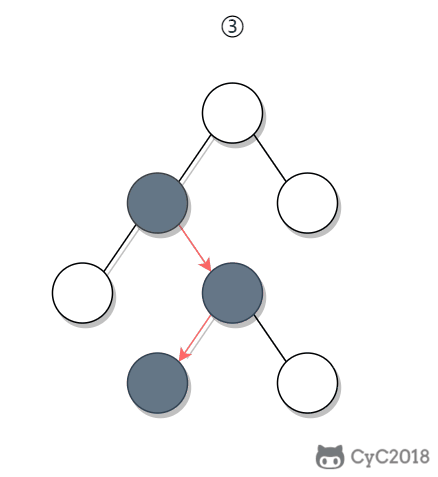
-① 如果一个节点的右子树不为空,那么该节点的下一个节点是右子树的最左节点;
-
- 
-
-② 否则,向上找第一个左链接指向的树包含该节点的祖先节点。
-
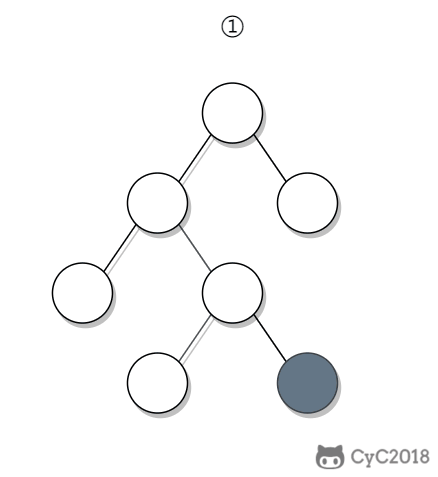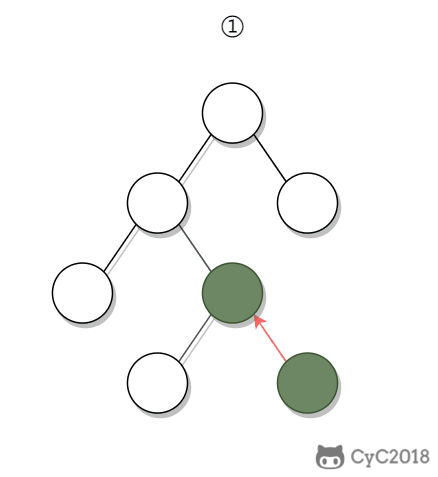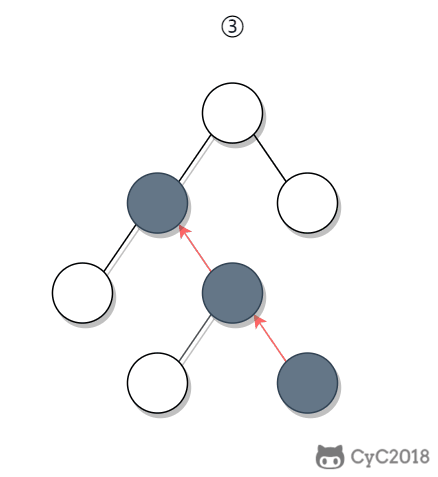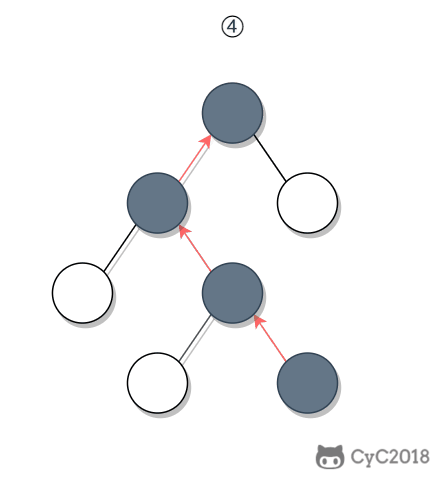
- 
-
-```java
-public TreeLinkNode GetNext(TreeLinkNode pNode) {
- if (pNode.right != null) {
- TreeLinkNode node = pNode.right;
- while (node.left != null)
- node = node.left;
- return node;
- } else {
- while (pNode.next != null) {
- TreeLinkNode parent = pNode.next;
- if (parent.left == pNode)
- return parent;
- pNode = pNode.next;
- }
- }
- return null;
-}
-```
-
-
-
-
-
-
- 
-
-```java
-Stack in = new Stack();
-Stack out = new Stack();
-
-public void push(int node) {
- in.push(node);
-}
-
-public int pop() throws Exception {
- if (out.isEmpty())
- while (!in.isEmpty())
- out.push(in.pop());
-
- if (out.isEmpty())
- throw new Exception("queue is empty");
-
- return out.pop();
-}
-```
-
-
-
-
-
-
-
diff --git a/docs/notes/Docker.md b/docs/notes/Docker.md
deleted file mode 100644
index 7647d26c..00000000
--- a/docs/notes/Docker.md
+++ /dev/null
@@ -1,96 +0,0 @@
-
-* [一、解决的问题](#一解决的问题)
-* [二、与虚拟机的比较](#二与虚拟机的比较)
-* [三、优势](#三优势)
-* [四、使用场景](#四使用场景)
-* [五、镜像与容器](#五镜像与容器)
-* [参考资料](#参考资料)
-
-
-
-# 一、解决的问题
-
-由于不同的机器有不同的操作系统,以及不同的库和组件,在将一个应用部署到多台机器上需要进行大量的环境配置操作。
-
-Docker 主要解决环境配置问题,它是一种虚拟化技术,对进程进行隔离,被隔离的进程独立于宿主操作系统和其它隔离的进程。使用 Docker 可以不修改应用程序代码,不需要开发人员学习特定环境下的技术,就能够将现有的应用程序部署在其它机器上。
-
-
-
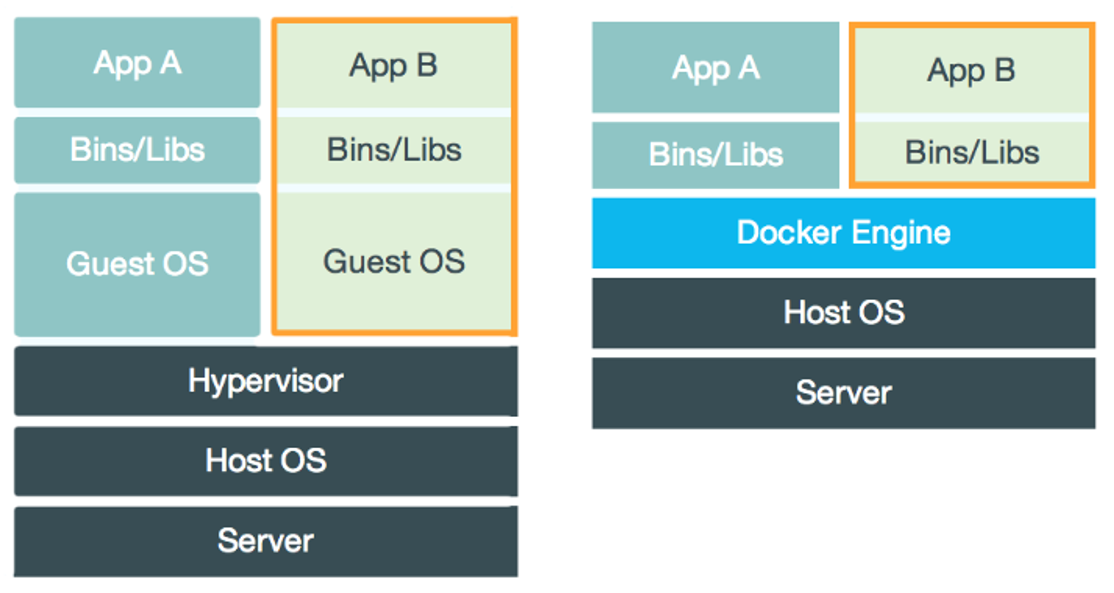
-# 二、与虚拟机的比较
-
-虚拟机也是一种虚拟化技术,它与 Docker 最大的区别在于它是通过模拟硬件,并在硬件上安装操作系统来实现。
-
-
-
-## 启动速度
-
-启动虚拟机需要先启动虚拟机的操作系统,再启动应用,这个过程非常慢;
-
-而启动 Docker 相当于启动宿主操作系统上的一个进程。
-
-## 占用资源
-
-虚拟机是一个完整的操作系统,需要占用大量的磁盘、内存和 CPU 资源,一台机器只能开启几十个的虚拟机。
-
-而 Docker 只是一个进程,只需要将应用以及相关的组件打包,在运行时占用很少的资源,一台机器可以开启成千上万个 Docker。
-
-# 三、优势
-
-除了启动速度快以及占用资源少之外,Docker 具有以下优势:
-
-## 更容易迁移
-
-提供一致性的运行环境。已经打包好的应用可以在不同的机器上进行迁移,而不用担心环境变化导致无法运行。
-
-## 更容易维护
-
-使用分层技术和镜像,使得应用可以更容易复用重复的部分。复用程度越高,维护工作也越容易。
-
-## 更容易扩展
-
-可以使用基础镜像进一步扩展得到新的镜像,并且官方和开源社区提供了大量的镜像,通过扩展这些镜像可以非常容易得到我们想要的镜像。
-
-# 四、使用场景
-
-## 持续集成
-
-持续集成指的是频繁地将代码集成到主干上,这样能够更快地发现错误。
-
-Docker 具有轻量级以及隔离性的特点,在将代码集成到一个 Docker 中不会对其它 Docker 产生影响。
-
-## 提供可伸缩的云服务
-
-根据应用的负载情况,可以很容易地增加或者减少 Docker。
-
-## 搭建微服务架构
-
-Docker 轻量级的特点使得它很适合用于部署、维护、组合微服务。
-
-# 五、镜像与容器
-
-镜像是一种静态的结构,可以看成面向对象里面的类,而容器是镜像的一个实例。
-
-镜像包含着容器运行时所需要的代码以及其它组件,它是一种分层结构,每一层都是只读的(read-only layers)。构建镜像时,会一层一层构建,前一层是后一层的基础。镜像的这种分层存储结构很适合镜像的复用以及定制。
-
-构建容器时,通过在镜像的基础上添加一个可写层(writable layer),用来保存着容器运行过程中的修改。
-
-
-
-# 参考资料
-
-- [DOCKER 101: INTRODUCTION TO DOCKER WEBINAR RECAP](https://blog.docker.com/2017/08/docker-101-introduction-docker-webinar-recap/)
-- [Docker 入门教程](http://www.ruanyifeng.com/blog/2018/02/docker-tutorial.html)
-- [Docker container vs Virtual machine](http://www.bogotobogo.com/DevOps/Docker/Docker_Container_vs_Virtual_Machine.php)
-- [How to Create Docker Container using Dockerfile](https://linoxide.com/linux-how-to/dockerfile-create-docker-container/)
-- [理解 Docker(2):Docker 镜像](http://www.cnblogs.com/sammyliu/p/5877964.html)
-- [为什么要使用 Docker?](https://yeasy.gitbooks.io/docker_practice/introduction/why.html)
-- [What is Docker](https://www.docker.com/what-docker)
-- [持续集成是什么?](http://www.ruanyifeng.com/blog/2015/09/continuous-integration.html)
-
-
-
-
-
-
-
-
diff --git a/docs/notes/Git.md b/docs/notes/Git.md
deleted file mode 100644
index 94e3dc3f..00000000
--- a/docs/notes/Git.md
+++ /dev/null
@@ -1,158 +0,0 @@
-
-* [集中式与分布式](#集中式与分布式)
-* [中心服务器](#中心服务器)
-* [工作流](#工作流)
-* [分支实现](#分支实现)
-* [冲突](#冲突)
-* [Fast forward](#fast-forward)
-* [储藏(Stashing)](#储藏stashing)
-* [SSH 传输设置](#ssh-传输设置)
-* [.gitignore 文件](#gitignore-文件)
-* [Git 命令一览](#git-命令一览)
-* [参考资料](#参考资料)
-
-
-
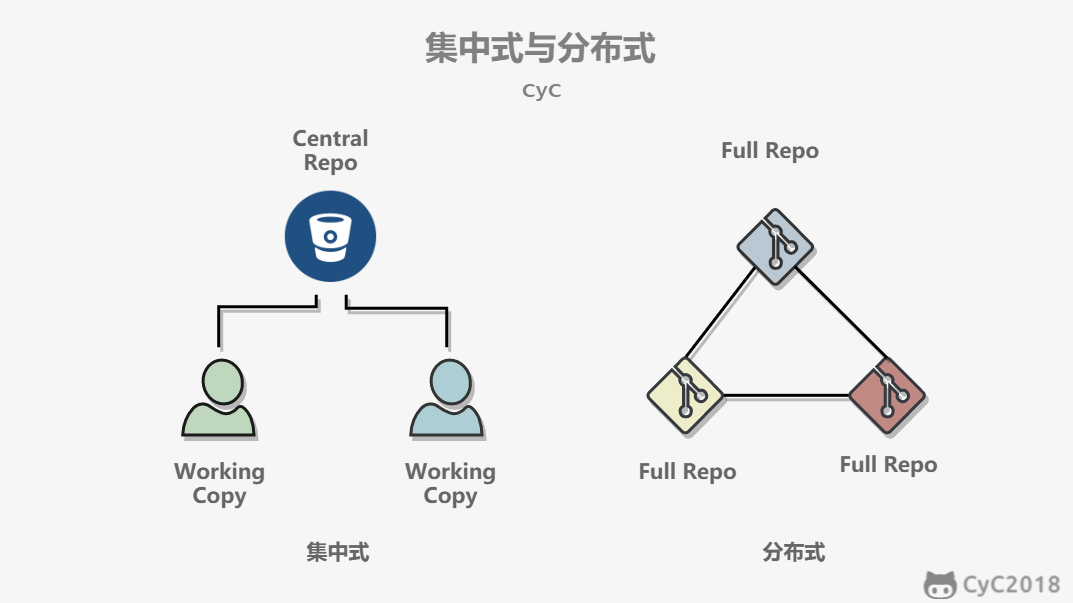
-# 集中式与分布式
-
-Git 属于分布式版本控制系统,而 SVN 属于集中式。
-
-
-
-集中式版本控制只有中心服务器拥有一份代码,而分布式版本控制每个人的电脑上就有一份完整的代码。
-
-集中式版本控制有安全性问题,当中心服务器挂了所有人都没办法工作了。
-
-集中式版本控制需要连网才能工作,如果网速过慢,那么提交一个文件会慢的无法让人忍受。而分布式版本控制不需要连网就能工作。
-
-分布式版本控制新建分支、合并分支操作速度非常快,而集中式版本控制新建一个分支相当于复制一份完整代码。
-
-# 中心服务器
-
-中心服务器用来交换每个用户的修改,没有中心服务器也能工作,但是中心服务器能够 24 小时保持开机状态,这样就能更方便的交换修改。
-
-Github 就是一个中心服务器。
-
-# 工作流
-
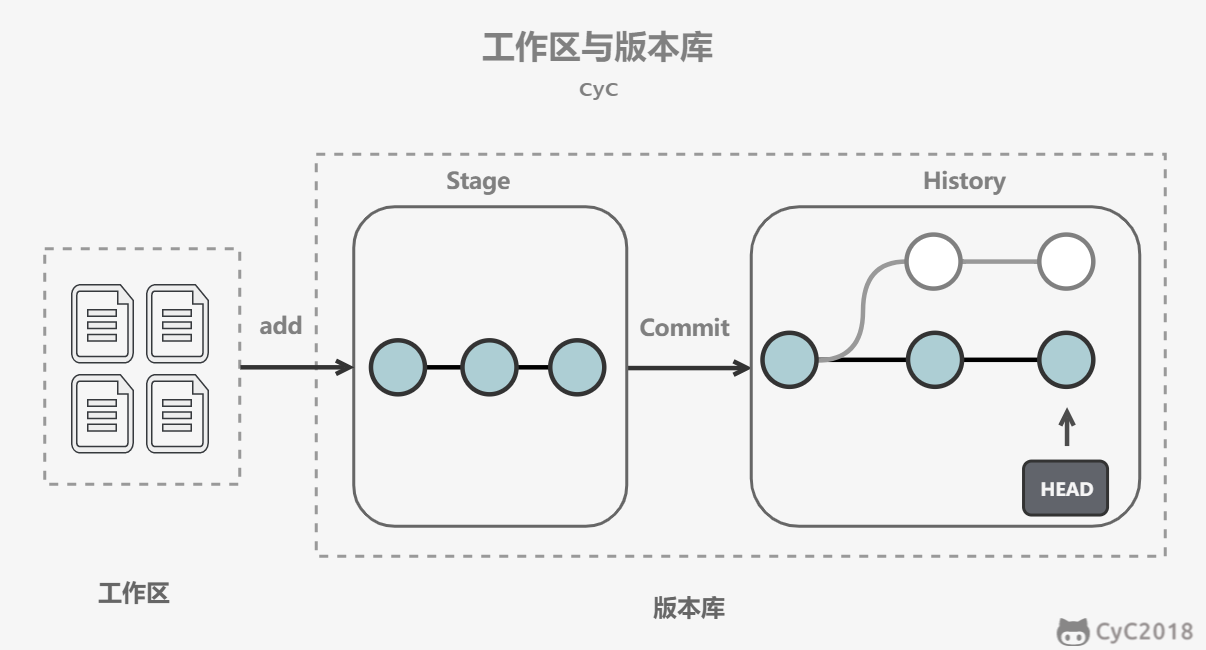
-新建一个仓库之后,当前目录就成为了工作区,工作区下有一个隐藏目录 .git,它属于 Git 的版本库。
-
-Git 的版本库有一个称为 Stage 的暂存区以及最后的 History 版本库,History 存储所有分支信息,使用一个 HEAD 指针指向当前分支。
-
-
-
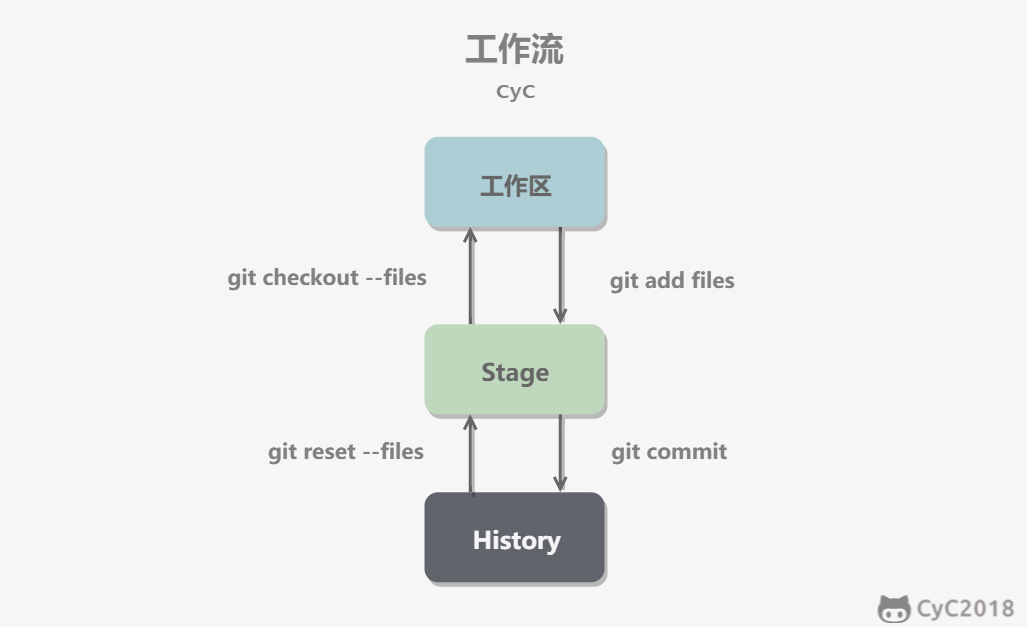
-- git add files 把文件的修改添加到暂存区
-- git commit 把暂存区的修改提交到当前分支,提交之后暂存区就被清空了
-- git reset -- files 使用当前分支上的修改覆盖暂存区,用来撤销最后一次 git add files
-- git checkout -- files 使用暂存区的修改覆盖工作目录,用来撤销本地修改
-
-
-
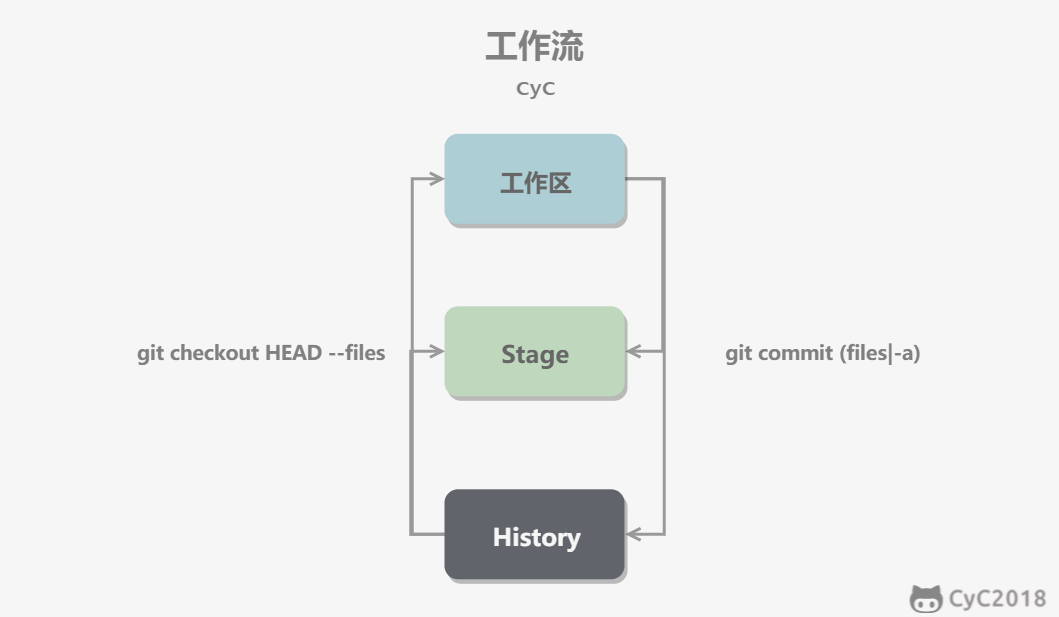
-可以跳过暂存区域直接从分支中取出修改,或者直接提交修改到分支中。
-
-- git commit -a 直接把所有文件的修改添加到暂存区然后执行提交
-- git checkout HEAD -- files 取出最后一次修改,可以用来进行回滚操作
-
-
-
-# 分支实现
-
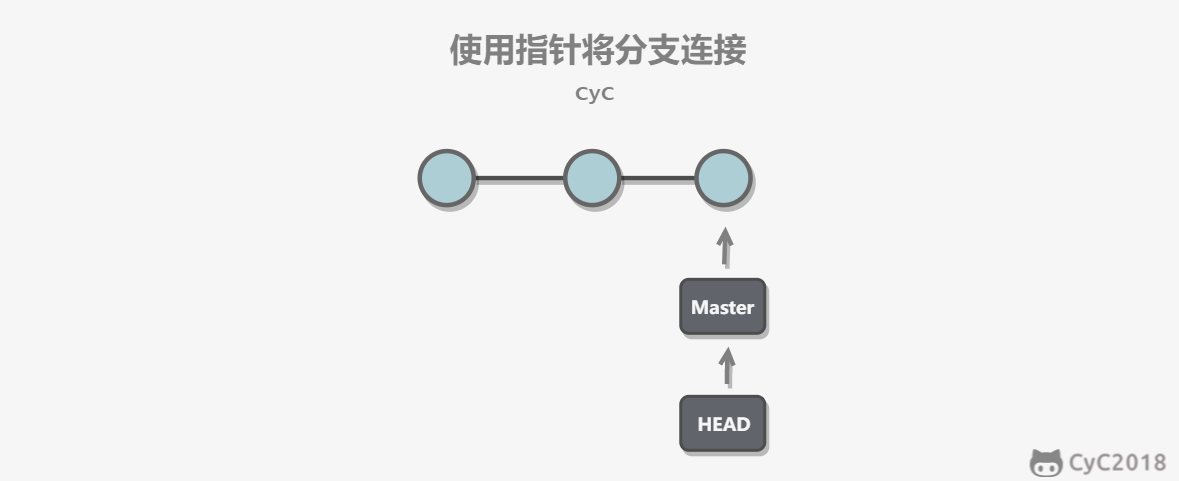
-使用指针将每个提交连接成一条时间线,HEAD 指针指向当前分支指针。
-
-
-
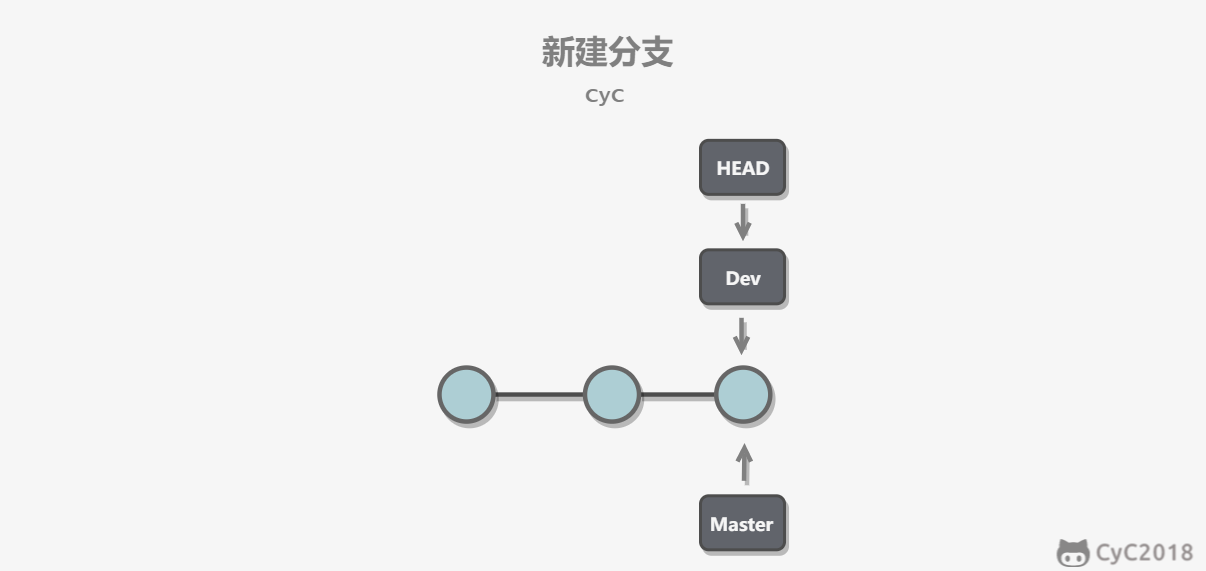
-新建分支是新建一个指针指向时间线的最后一个节点,并让 HEAD 指针指向新分支,表示新分支成为当前分支。
-
-
-
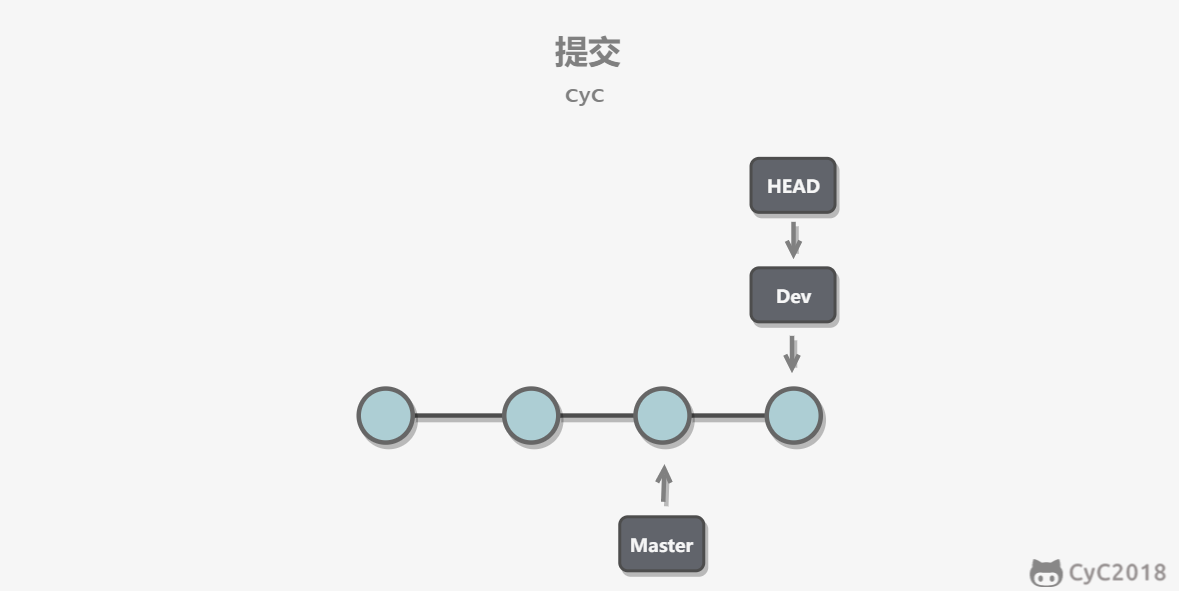
-每次提交只会让当前分支指针向前移动,而其它分支指针不会移动。
-
-
-
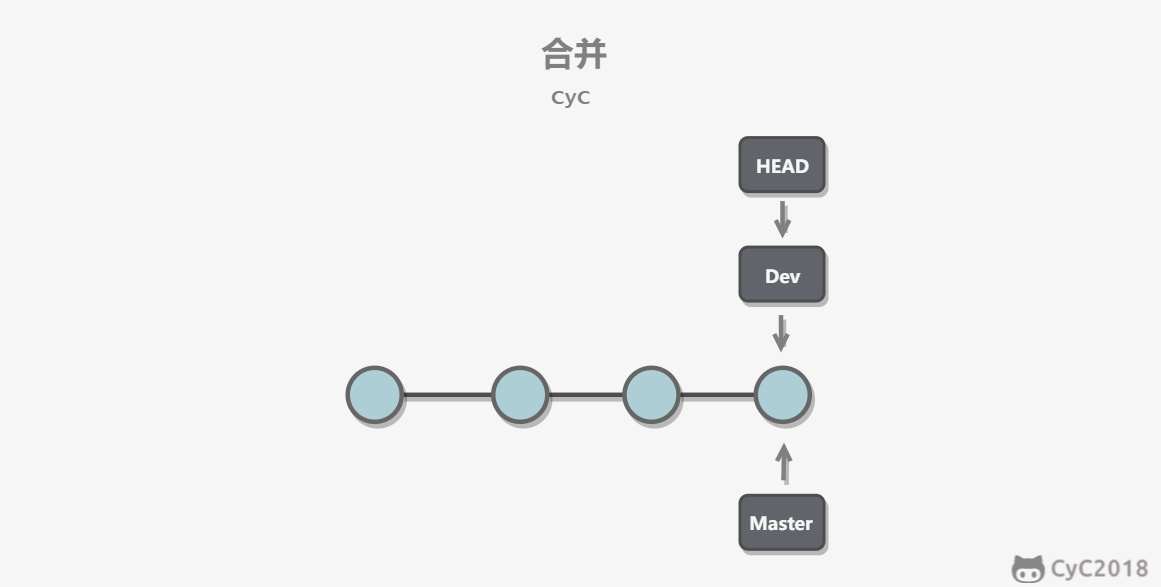
-合并分支也只需要改变指针即可。
-
-
-
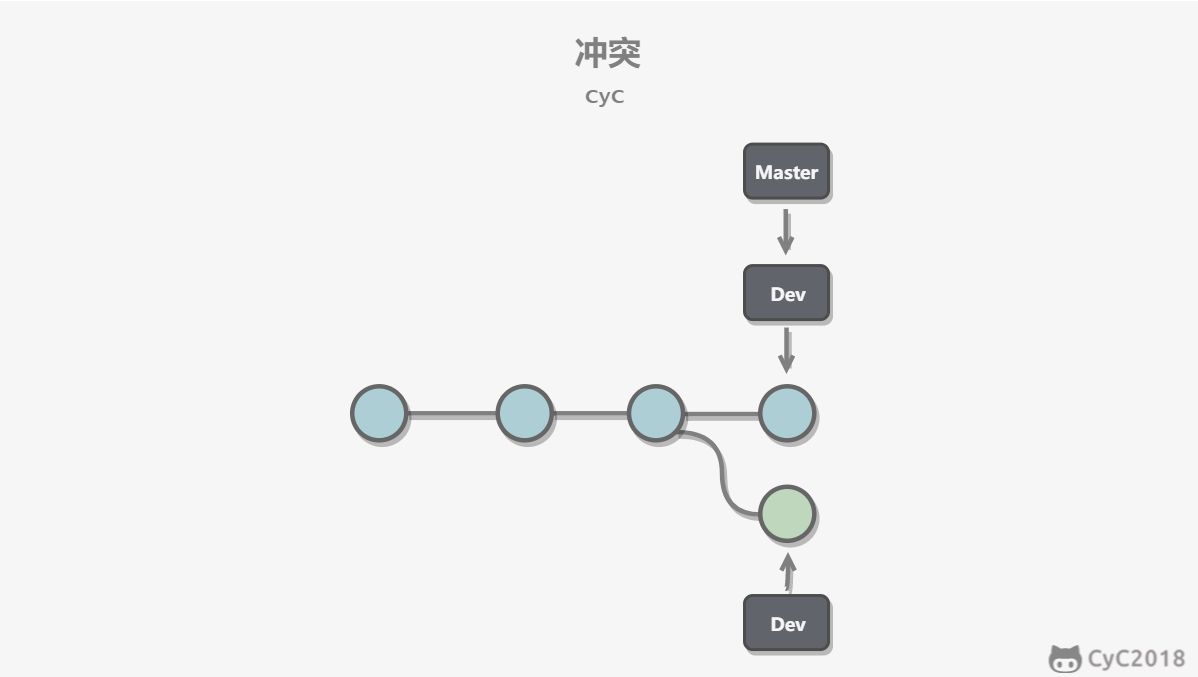
-# 冲突
-
-当两个分支都对同一个文件的同一行进行了修改,在分支合并时就会产生冲突。
-
-
-
-Git 会使用 <<<<<<< ,======= ,>>>>>>> 标记出不同分支的内容,只需要把不同分支中冲突部分修改成一样就能解决冲突。
-
-```
-<<<<<<< HEAD
-Creating a new branch is quick & simple.
-=======
-Creating a new branch is quick AND simple.
->>>>>>> feature1
-```
-
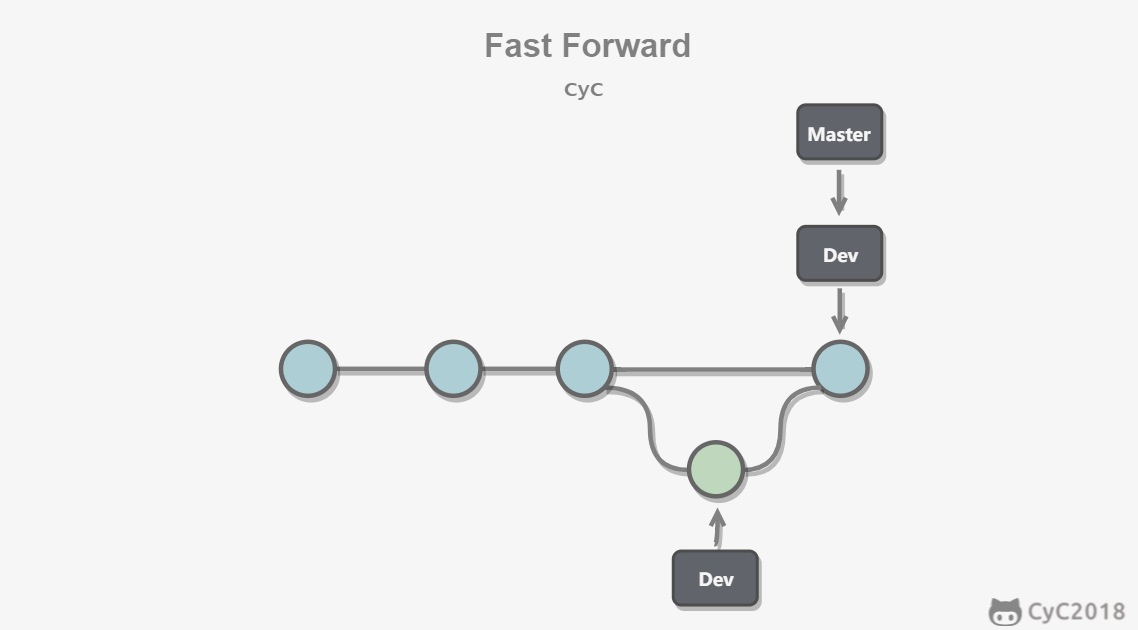
-# Fast forward
-
-"快进式合并"(fast-farward merge),会直接将 master 分支指向合并的分支,这种模式下进行分支合并会丢失分支信息,也就不能在分支历史上看出分支信息。
-
-可以在合并时加上 --no-ff 参数来禁用 Fast forward 模式,并且加上 -m 参数让合并时产生一个新的 commit。
-
-```
-$ git merge --no-ff -m "merge with no-ff" dev
-```
-
-
-
-# 储藏(Stashing)
-
-在一个分支上操作之后,如果还没有将修改提交到分支上,此时进行切换分支,那么另一个分支上也能看到新的修改。这是因为所有分支都共用一个工作区的缘故。
-
-可以使用 git stash 将当前分支的修改储藏起来,此时当前工作区的所有修改都会被存到栈中,也就是说当前工作区是干净的,没有任何未提交的修改。此时就可以安全的切换到其它分支上了。
-
-```
-$ git stash
-Saved working directory and index state \ "WIP on master: 049d078 added the index file"
-HEAD is now at 049d078 added the index file (To restore them type "git stash apply")
-```
-
-该功能可以用于 bug 分支的实现。如果当前正在 dev 分支上进行开发,但是此时 master 上有个 bug 需要修复,但是 dev 分支上的开发还未完成,不想立即提交。在新建 bug 分支并切换到 bug 分支之前就需要使用 git stash 将 dev 分支的未提交修改储藏起来。
-
-# SSH 传输设置
-
-Git 仓库和 Github 中心仓库之间的传输是通过 SSH 加密。
-
-如果工作区下没有 .ssh 目录,或者该目录下没有 id_rsa 和 id_rsa.pub 这两个文件,可以通过以下命令来创建 SSH Key:
-
-```
-$ ssh-keygen -t rsa -C "youremail@example.com"
-```
-
-然后把公钥 id_rsa.pub 的内容复制到 Github "Account settings" 的 SSH Keys 中。
-
-# .gitignore 文件
-
-忽略以下文件:
-
-- 操作系统自动生成的文件,比如缩略图;
-- 编译生成的中间文件,比如 Java 编译产生的 .class 文件;
-- 自己的敏感信息,比如存放口令的配置文件。
-
-不需要全部自己编写,可以到 [https://github.com/github/gitignore](https://github.com/github/gitignore) 中进行查询。
-
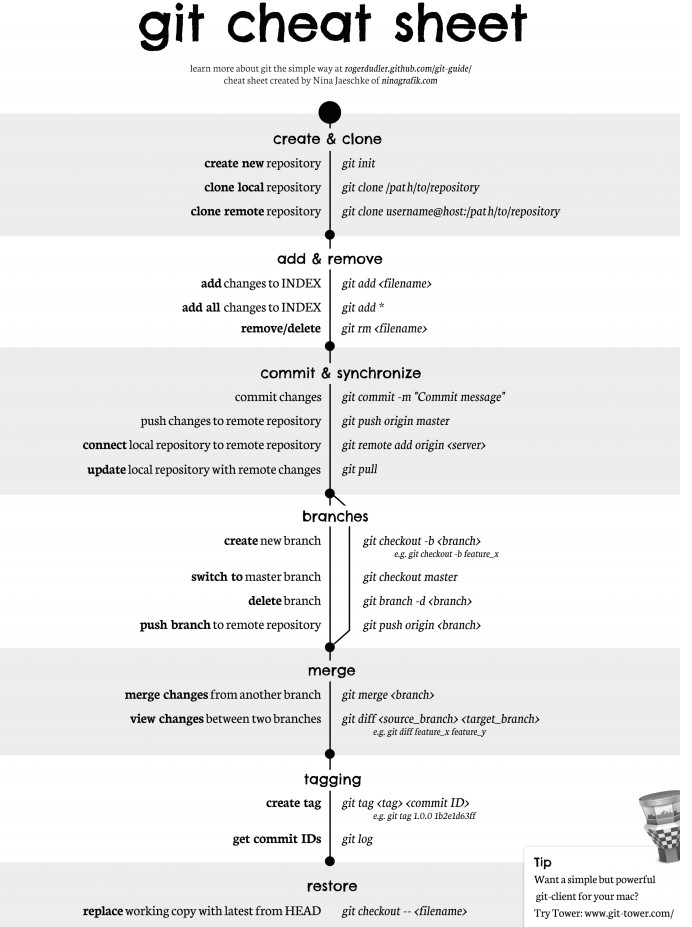
-# Git 命令一览
-
-
-
-比较详细的地址:http://www.cheat-sheets.org/saved-copy/git-cheat-sheet.pdf
-
-# 参考资料
-
-- [Git - 简明指南](http://rogerdudler.github.io/git-guide/index.zh.html)
-- [图解 Git](http://marklodato.github.io/visual-git-guide/index-zh-cn.html)
-- [廖雪峰 : Git 教程](https://www.liaoxuefeng.com/wiki/0013739516305929606dd18361248578c67b8067c8c017b000)
-- [Learn Git Branching](https://learngitbranching.js.org/)
-
-
-
-
-
-
-
diff --git a/docs/notes/HTTP.md b/docs/notes/HTTP.md
deleted file mode 100644
index 55ebf275..00000000
--- a/docs/notes/HTTP.md
+++ /dev/null
@@ -1,948 +0,0 @@
-
-* [一 、基础概念](#一-基础概念)
- * [请求和响应报文](#请求和响应报文)
- * [URL](#url)
-* [二、HTTP 方法](#二http-方法)
- * [GET](#get)
- * [HEAD](#head)
- * [POST](#post)
- * [PUT](#put)
- * [PATCH](#patch)
- * [DELETE](#delete)
- * [OPTIONS](#options)
- * [CONNECT](#connect)
- * [TRACE](#trace)
-* [三、HTTP 状态码](#三http-状态码)
- * [1XX 信息](#1xx-信息)
- * [2XX 成功](#2xx-成功)
- * [3XX 重定向](#3xx-重定向)
- * [4XX 客户端错误](#4xx-客户端错误)
- * [5XX 服务器错误](#5xx-服务器错误)
-* [四、HTTP 首部](#四http-首部)
- * [通用首部字段](#通用首部字段)
- * [请求首部字段](#请求首部字段)
- * [响应首部字段](#响应首部字段)
- * [实体首部字段](#实体首部字段)
-* [五、具体应用](#五具体应用)
- * [连接管理](#连接管理)
- * [Cookie](#cookie)
- * [缓存](#缓存)
- * [内容协商](#内容协商)
- * [内容编码](#内容编码)
- * [范围请求](#范围请求)
- * [分块传输编码](#分块传输编码)
- * [多部分对象集合](#多部分对象集合)
- * [虚拟主机](#虚拟主机)
- * [通信数据转发](#通信数据转发)
-* [六、HTTPS](#六https)
- * [加密](#加密)
- * [认证](#认证)
- * [完整性保护](#完整性保护)
- * [HTTPS 的缺点](#https-的缺点)
-* [七、HTTP/2.0](#七http20)
- * [HTTP/1.x 缺陷](#http1x-缺陷)
- * [二进制分帧层](#二进制分帧层)
- * [服务端推送](#服务端推送)
- * [首部压缩](#首部压缩)
-* [八、HTTP/1.1 新特性](#八http11-新特性)
-* [九、GET 和 POST 比较](#九get-和-post-比较)
- * [作用](#作用)
- * [参数](#参数)
- * [安全](#安全)
- * [幂等性](#幂等性)
- * [可缓存](#可缓存)
- * [XMLHttpRequest](#xmlhttprequest)
-* [参考资料](#参考资料)
-
-
-
-# 一 、基础概念
-
-## 请求和响应报文
-
-客户端发送一个请求报文给服务器,服务器根据请求报文中的信息进行处理,并将处理结果放入响应报文中返回给客户端。
-
-请求报文结构:
-
-- 第一行是包含了请求方法、URL、协议版本;
-- 接下来的多行都是请求首部 Header,每个首部都有一个首部名称,以及对应的值。
-- 一个空行用来分隔首部和内容主体 Body
-- 最后是请求的内容主体
-
-```
-GET http://www.example.com/ HTTP/1.1
-Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
-Accept-Encoding: gzip, deflate
-Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
-Cache-Control: max-age=0
-Host: www.example.com
-If-Modified-Since: Thu, 17 Oct 2019 07:18:26 GMT
-If-None-Match: "3147526947+gzip"
-Proxy-Connection: keep-alive
-Upgrade-Insecure-Requests: 1
-User-Agent: Mozilla/5.0 xxx
-
-param1=1¶m2=2
-```
-
-响应报文结构:
-
-- 第一行包含协议版本、状态码以及描述,最常见的是 200 OK 表示请求成功了
-- 接下来多行也是首部内容
-- 一个空行分隔首部和内容主体
-- 最后是响应的内容主体
-
-```
-HTTP/1.1 200 OK
-Age: 529651
-Cache-Control: max-age=604800
-Connection: keep-alive
-Content-Encoding: gzip
-Content-Length: 648
-Content-Type: text/html; charset=UTF-8
-Date: Mon, 02 Nov 2020 17:53:39 GMT
-Etag: "3147526947+ident+gzip"
-Expires: Mon, 09 Nov 2020 17:53:39 GMT
-Keep-Alive: timeout=4
-Last-Modified: Thu, 17 Oct 2019 07:18:26 GMT
-Proxy-Connection: keep-alive
-Server: ECS (sjc/16DF)
-Vary: Accept-Encoding
-X-Cache: HIT
-
-
-
-
- Example Domain
- // 省略...
-
-
-
-```
-
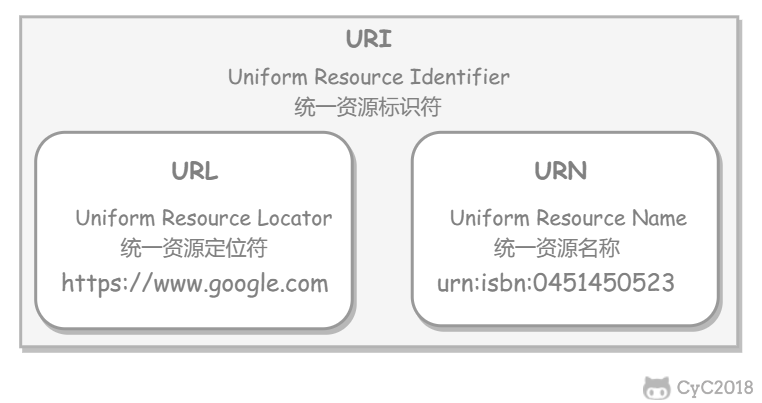
-## URL
-
-http 使用 URL( **U** niform **R**esource **L**ocator,统一资源定位符)来定位资源,它可以认为是是 URI(**U**niform **R**esource **I**dentifier,统一资源标识符)的一个子集,URL 在 URI 的基础上增加了定位能力。URI 除了包含 URL 之外,还包含 URN(Uniform Resource Name,统一资源名称),它知识用来定义一个资源的名称,并不具备定位该资源的能力。例如 urn:isbn:0451450523 用来定义一个书籍,但是却没有表示怎么找到这本书。
-
-
-
-- [wikipedia:统一资源标志符](https://zh.wikipedia.org/wiki/统一资源标志符)
-- [wikipedia: URL](https://en.wikipedia.org/wiki/URL)
-- [rfc2616:3.2.2 http URL](https://www.w3.org/Protocols/rfc2616/rfc2616-sec3.html#sec3.2.2)
-- [What is the difference between a URI, a URL and a URN?](https://stackoverflow.com/questions/176264/what-is-the-difference-between-a-uri-a-url-and-a-urn)
-
-# 二、HTTP 方法
-
-客户端发送的 **请求报文** 第一行为请求行,包含了方法字段。
-
-## GET
-
-> 获取资源
-
-当前网络请求中,绝大部分使用的是 GET 方法。
-
-## HEAD
-
-> 获取报文首部
-
-和 GET 方法类似,但是不返回报文实体主体部分。
-
-主要用于确认 URL 的有效性以及资源更新的日期时间等。
-
-## POST
-
-> 传输实体主体
-
-POST 主要用来传输数据,而 GET 主要用来获取资源。
-
-更多 POST 与 GET 的比较请见第九章。
-
-## PUT
-
-> 上传文件
-
-由于自身不带验证机制,任何人都可以上传文件,因此存在安全性问题,一般不使用该方法。
-
-```html
-PUT /new.html HTTP/1.1
-Host: example.com
-Content-type: text/html
-Content-length: 16
-
-New File
-```
-
-## PATCH
-
-> 对资源进行部分修改
-
-PUT 也可以用于修改资源,但是只能完全替代原始资源,PATCH 允许部分修改。
-
-```html
-PATCH /file.txt HTTP/1.1
-Host: www.example.com
-Content-Type: application/example
-If-Match: "e0023aa4e"
-Content-Length: 100
-
-[description of changes]
-```
-
-## DELETE
-
-> 删除文件
-
-与 PUT 功能相反,并且同样不带验证机制。
-
-```html
-DELETE /file.html HTTP/1.1
-```
-
-## OPTIONS
-
-> 查询支持的方法
-
-查询指定的 URL 能够支持的方法。
-
-会返回 `Allow: GET, POST, HEAD, OPTIONS` 这样的内容。
-
-## CONNECT
-
-> 要求在与代理服务器通信时建立隧道
-
-使用 SSL(Secure Sockets Layer,安全套接层)和 TLS(Transport Layer Security,传输层安全)协议把通信内容加密后经网络隧道传输。
-
-```html
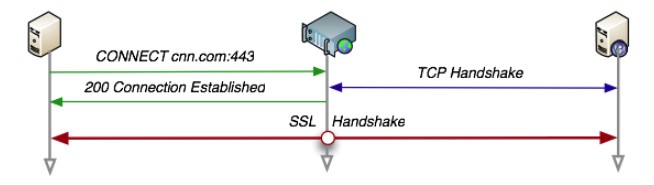
-CONNECT www.example.com:443 HTTP/1.1
-```
-
- 
-
-## TRACE
-
-> 追踪路径
-
-服务器会将通信路径返回给客户端。
-
-发送请求时,在 Max-Forwards 首部字段中填入数值,每经过一个服务器就会减 1,当数值为 0 时就停止传输。
-
-通常不会使用 TRACE,并且它容易受到 XST 攻击(Cross-Site Tracing,跨站追踪)。
-
-- [rfc2616:9 Method Definitions](https://www.w3.org/Protocols/rfc2616/rfc2616-sec9.html)
-
-# 三、HTTP 状态码
-
-服务器返回的 **响应报文** 中第一行为状态行,包含了状态码以及原因短语,用来告知客户端请求的结果。
-
-| 状态码 | 类别 | 含义 |
-| :---: | :---: | :---: |
-| 1XX | Informational(信息性状态码) | 接收的请求正在处理 |
-| 2XX | Success(成功状态码) | 请求正常处理完毕 |
-| 3XX | Redirection(重定向状态码) | 需要进行附加操作以完成请求 |
-| 4XX | Client Error(客户端错误状态码) | 服务器无法处理请求 |
-| 5XX | Server Error(服务器错误状态码) | 服务器处理请求出错 |
-
-## 1XX 信息
-
-- **100 Continue** :表明到目前为止都很正常,客户端可以继续发送请求或者忽略这个响应。
-
-## 2XX 成功
-
-- **200 OK**
-
-- **204 No Content** :请求已经成功处理,但是返回的响应报文不包含实体的主体部分。一般在只需要从客户端往服务器发送信息,而不需要返回数据时使用。
-
-- **206 Partial Content** :表示客户端进行了范围请求,响应报文包含由 Content-Range 指定范围的实体内容。
-
-## 3XX 重定向
-
-- **301 Moved Permanently** :永久性重定向
-
-- **302 Found** :临时性重定向
-
-- **303 See Other** :和 302 有着相同的功能,但是 303 明确要求客户端应该采用 GET 方法获取资源。
-
-- 注:虽然 HTTP 协议规定 301、302 状态下重定向时不允许把 POST 方法改成 GET 方法,但是大多数浏览器都会在 301、302 和 303 状态下的重定向把 POST 方法改成 GET 方法。
-
-- **304 Not Modified** :如果请求报文首部包含一些条件,例如:If-Match,If-Modified-Since,If-None-Match,If-Range,If-Unmodified-Since,如果不满足条件,则服务器会返回 304 状态码。
-
-- **307 Temporary Redirect** :临时重定向,与 302 的含义类似,但是 307 要求浏览器不会把重定向请求的 POST 方法改成 GET 方法。
-
-## 4XX 客户端错误
-
-- **400 Bad Request** :请求报文中存在语法错误。
-
-- **401 Unauthorized** :该状态码表示发送的请求需要有认证信息(BASIC 认证、DIGEST 认证)。如果之前已进行过一次请求,则表示用户认证失败。
-
-- **403 Forbidden** :请求被拒绝。
-
-- **404 Not Found**
-
-## 5XX 服务器错误
-
-- **500 Internal Server Error** :服务器正在执行请求时发生错误。
-
-- **503 Service Unavailable** :服务器暂时处于超负载或正在进行停机维护,现在无法处理请求。
-
-# 四、HTTP 首部
-
-有 4 种类型的首部字段:通用首部字段、请求首部字段、响应首部字段和实体首部字段。
-
-各种首部字段及其含义如下(不需要全记,仅供查阅):
-
-## 通用首部字段
-
-| 首部字段名 | 说明 |
-| :--: | :--: |
-| Cache-Control | 控制缓存的行为 |
-| Connection | 控制不再转发给代理的首部字段、管理持久连接|
-| Date | 创建报文的日期时间 |
-| Pragma | 报文指令 |
-| Trailer | 报文末端的首部一览 |
-| Transfer-Encoding | 指定报文主体的传输编码方式 |
-| Upgrade | 升级为其他协议 |
-| Via | 代理服务器的相关信息 |
-| Warning | 错误通知 |
-
-## 请求首部字段
-
-| 首部字段名 | 说明 |
-| :--: | :--: |
-| Accept | 用户代理可处理的媒体类型 |
-| Accept-Charset | 优先的字符集 |
-| Accept-Encoding | 优先的内容编码 |
-| Accept-Language | 优先的语言(自然语言) |
-| Authorization | Web 认证信息 |
-| Expect | 期待服务器的特定行为 |
-| From | 用户的电子邮箱地址 |
-| Host | 请求资源所在服务器 |
-| If-Match | 比较实体标记(ETag) |
-| If-Modified-Since | 比较资源的更新时间 |
-| If-None-Match | 比较实体标记(与 If-Match 相反) |
-| If-Range | 资源未更新时发送实体 Byte 的范围请求 |
-| If-Unmodified-Since | 比较资源的更新时间(与 If-Modified-Since 相反) |
-| Max-Forwards | 最大传输逐跳数 |
-| Proxy-Authorization | 代理服务器要求客户端的认证信息 |
-| Range | 实体的字节范围请求 |
-| Referer | 对请求中 URI 的原始获取方 |
-| TE | 传输编码的优先级 |
-| User-Agent | HTTP 客户端程序的信息 |
-
-## 响应首部字段
-
-| 首部字段名 | 说明 |
-| :--: | :--: |
-| Accept-Ranges | 是否接受字节范围请求 |
-| Age | 推算资源创建经过时间 |
-| ETag | 资源的匹配信息 |
-| Location | 令客户端重定向至指定 URI |
-| Proxy-Authenticate | 代理服务器对客户端的认证信息 |
-| Retry-After | 对再次发起请求的时机要求 |
-| Server | HTTP 服务器的安装信息 |
-| Vary | 代理服务器缓存的管理信息 |
-| WWW-Authenticate | 服务器对客户端的认证信息 |
-
-## 实体首部字段
-
-| 首部字段名 | 说明 |
-| :--: | :--: |
-| Allow | 资源可支持的 HTTP 方法 |
-| Content-Encoding | 实体主体适用的编码方式 |
-| Content-Language | 实体主体的自然语言 |
-| Content-Length | 实体主体的大小 |
-| Content-Location | 替代对应资源的 URI |
-| Content-MD5 | 实体主体的报文摘要 |
-| Content-Range | 实体主体的位置范围 |
-| Content-Type | 实体主体的媒体类型 |
-| Expires | 实体主体过期的日期时间 |
-| Last-Modified | 资源的最后修改日期时间 |
-
-# 五、具体应用
-
-## 连接管理
-
- 
-
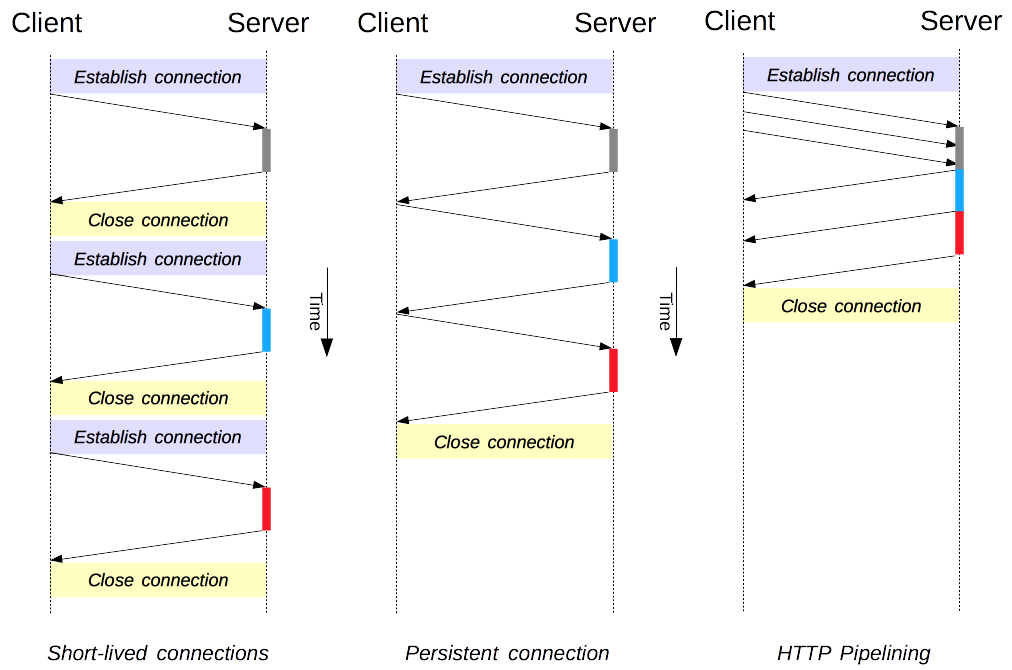
-### 1. 短连接与长连接
-
-当浏览器访问一个包含多张图片的 HTML 页面时,除了请求访问的 HTML 页面资源,还会请求图片资源。如果每进行一次 HTTP 通信就要新建一个 TCP 连接,那么开销会很大。
-
-长连接只需要建立一次 TCP 连接就能进行多次 HTTP 通信。
-
-- 从 HTTP/1.1 开始默认是长连接的,如果要断开连接,需要由客户端或者服务器端提出断开,使用 `Connection : close`;
-- 在 HTTP/1.1 之前默认是短连接的,如果需要使用长连接,则使用 `Connection : Keep-Alive`。
-
-### 2. 流水线
-
-默认情况下,HTTP 请求是按顺序发出的,下一个请求只有在当前请求收到响应之后才会被发出。由于受到网络延迟和带宽的限制,在下一个请求被发送到服务器之前,可能需要等待很长时间。
-
-流水线是在同一条长连接上连续发出请求,而不用等待响应返回,这样可以减少延迟。
-
-## Cookie
-
-HTTP 协议是无状态的,主要是为了让 HTTP 协议尽可能简单,使得它能够处理大量事务。HTTP/1.1 引入 Cookie 来保存状态信息。
-
-Cookie 是服务器发送到用户浏览器并保存在本地的一小块数据,它会在浏览器之后向同一服务器再次发起请求时被携带上,用于告知服务端两个请求是否来自同一浏览器。由于之后每次请求都会需要携带 Cookie 数据,因此会带来额外的性能开销(尤其是在移动环境下)。
-
-Cookie 曾一度用于客户端数据的存储,因为当时并没有其它合适的存储办法而作为唯一的存储手段,但现在随着现代浏览器开始支持各种各样的存储方式,Cookie 渐渐被淘汰。新的浏览器 API 已经允许开发者直接将数据存储到本地,如使用 Web storage API(本地存储和会话存储)或 IndexedDB。
-
-### 1. 用途
-
-- 会话状态管理(如用户登录状态、购物车、游戏分数或其它需要记录的信息)
-- 个性化设置(如用户自定义设置、主题等)
-- 浏览器行为跟踪(如跟踪分析用户行为等)
-
-### 2. 创建过程
-
-服务器发送的响应报文包含 Set-Cookie 首部字段,客户端得到响应报文后把 Cookie 内容保存到浏览器中。
-
-```html
-HTTP/1.0 200 OK
-Content-type: text/html
-Set-Cookie: yummy_cookie=choco
-Set-Cookie: tasty_cookie=strawberry
-
-[page content]
-```
-
-客户端之后对同一个服务器发送请求时,会从浏览器中取出 Cookie 信息并通过 Cookie 请求首部字段发送给服务器。
-
-```html
-GET /sample_page.html HTTP/1.1
-Host: www.example.org
-Cookie: yummy_cookie=choco; tasty_cookie=strawberry
-```
-
-### 3. 分类
-
-- 会话期 Cookie:浏览器关闭之后它会被自动删除,也就是说它仅在会话期内有效。
-- 持久性 Cookie:指定过期时间(Expires)或有效期(max-age)之后就成为了持久性的 Cookie。
-
-```html
-Set-Cookie: id=a3fWa; Expires=Wed, 21 Oct 2015 07:28:00 GMT;
-```
-
-### 4. 作用域
-
-Domain 标识指定了哪些主机可以接受 Cookie。如果不指定,默认为当前文档的主机(不包含子域名)。如果指定了 Domain,则一般包含子域名。例如,如果设置 Domain=mozilla.org,则 Cookie 也包含在子域名中(如 developer.mozilla.org)。
-
-Path 标识指定了主机下的哪些路径可以接受 Cookie(该 URL 路径必须存在于请求 URL 中)。以字符 %x2F ("/") 作为路径分隔符,子路径也会被匹配。例如,设置 Path=/docs,则以下地址都会匹配:
-
-- /docs
-- /docs/Web/
-- /docs/Web/HTTP
-
-### 5. JavaScript
-
-浏览器通过 `document.cookie` 属性可创建新的 Cookie,也可通过该属性访问非 HttpOnly 标记的 Cookie。
-
-```html
-document.cookie = "yummy_cookie=choco";
-document.cookie = "tasty_cookie=strawberry";
-console.log(document.cookie);
-```
-
-### 6. HttpOnly
-
-标记为 HttpOnly 的 Cookie 不能被 JavaScript 脚本调用。跨站脚本攻击 (XSS) 常常使用 JavaScript 的 `document.cookie` API 窃取用户的 Cookie 信息,因此使用 HttpOnly 标记可以在一定程度上避免 XSS 攻击。
-
-```html
-Set-Cookie: id=a3fWa; Expires=Wed, 21 Oct 2015 07:28:00 GMT; Secure; HttpOnly
-```
-
-### 7. Secure
-
-标记为 Secure 的 Cookie 只能通过被 HTTPS 协议加密过的请求发送给服务端。但即便设置了 Secure 标记,敏感信息也不应该通过 Cookie 传输,因为 Cookie 有其固有的不安全性,Secure 标记也无法提供确实的安全保障。
-
-### 8. Session
-
-除了可以将用户信息通过 Cookie 存储在用户浏览器中,也可以利用 Session 存储在服务器端,存储在服务器端的信息更加安全。
-
-Session 可以存储在服务器上的文件、数据库或者内存中。也可以将 Session 存储在 Redis 这种内存型数据库中,效率会更高。
-
-使用 Session 维护用户登录状态的过程如下:
-
-- 用户进行登录时,用户提交包含用户名和密码的表单,放入 HTTP 请求报文中;
-- 服务器验证该用户名和密码,如果正确则把用户信息存储到 Redis 中,它在 Redis 中的 Key 称为 Session ID;
-- 服务器返回的响应报文的 Set-Cookie 首部字段包含了这个 Session ID,客户端收到响应报文之后将该 Cookie 值存入浏览器中;
-- 客户端之后对同一个服务器进行请求时会包含该 Cookie 值,服务器收到之后提取出 Session ID,从 Redis 中取出用户信息,继续之前的业务操作。
-
-应该注意 Session ID 的安全性问题,不能让它被恶意攻击者轻易获取,那么就不能产生一个容易被猜到的 Session ID 值。此外,还需要经常重新生成 Session ID。在对安全性要求极高的场景下,例如转账等操作,除了使用 Session 管理用户状态之外,还需要对用户进行重新验证,比如重新输入密码,或者使用短信验证码等方式。
-
-### 9. 浏览器禁用 Cookie
-
-此时无法使用 Cookie 来保存用户信息,只能使用 Session。除此之外,不能再将 Session ID 存放到 Cookie 中,而是使用 URL 重写技术,将 Session ID 作为 URL 的参数进行传递。
-
-### 10. Cookie 与 Session 选择
-
-- Cookie 只能存储 ASCII 码字符串,而 Session 则可以存储任何类型的数据,因此在考虑数据复杂性时首选 Session;
-- Cookie 存储在浏览器中,容易被恶意查看。如果非要将一些隐私数据存在 Cookie 中,可以将 Cookie 值进行加密,然后在服务器进行解密;
-- 对于大型网站,如果用户所有的信息都存储在 Session 中,那么开销是非常大的,因此不建议将所有的用户信息都存储到 Session 中。
-
-## 缓存
-
-### 1. 优点
-
-- 缓解服务器压力;
-- 降低客户端获取资源的延迟:缓存通常位于内存中,读取缓存的速度更快。并且缓存服务器在地理位置上也有可能比源服务器来得近,例如浏览器缓存。
-
-### 2. 实现方法
-
-- 让代理服务器进行缓存;
-- 让客户端浏览器进行缓存。
-
-### 3. Cache-Control
-
-HTTP/1.1 通过 Cache-Control 首部字段来控制缓存。
-
-**3.1 禁止进行缓存**
-
-no-store 指令规定不能对请求或响应的任何一部分进行缓存。
-
-```html
-Cache-Control: no-store
-```
-
-**3.2 强制确认缓存**
-
-no-cache 指令规定缓存服务器需要先向源服务器验证缓存资源的有效性,只有当缓存资源有效时才能使用该缓存对客户端的请求进行响应。
-
-```html
-Cache-Control: no-cache
-```
-
-**3.3 私有缓存和公共缓存**
-
-private 指令规定了将资源作为私有缓存,只能被单独用户使用,一般存储在用户浏览器中。
-
-```html
-Cache-Control: private
-```
-
-public 指令规定了将资源作为公共缓存,可以被多个用户使用,一般存储在代理服务器中。
-
-```html
-Cache-Control: public
-```
-
-**3.4 缓存过期机制**
-
-max-age 指令出现在请求报文,并且缓存资源的缓存时间小于该指令指定的时间,那么就能接受该缓存。
-
-max-age 指令出现在响应报文,表示缓存资源在缓存服务器中保存的时间。
-
-```html
-Cache-Control: max-age=31536000
-```
-
-Expires 首部字段也可以用于告知缓存服务器该资源什么时候会过期。
-
-```html
-Expires: Wed, 04 Jul 2012 08:26:05 GMT
-```
-
-- 在 HTTP/1.1 中,会优先处理 max-age 指令;
-- 在 HTTP/1.0 中,max-age 指令会被忽略掉。
-
-### 4. 缓存验证
-
-需要先了解 ETag 首部字段的含义,它是资源的唯一标识。URL 不能唯一表示资源,例如 `http://www.google.com/` 有中文和英文两个资源,只有 ETag 才能对这两个资源进行唯一标识。
-
-```html
-ETag: "82e22293907ce725faf67773957acd12"
-```
-
-可以将缓存资源的 ETag 值放入 If-None-Match 首部,服务器收到该请求后,判断缓存资源的 ETag 值和资源的最新 ETag 值是否一致,如果一致则表示缓存资源有效,返回 304 Not Modified。
-
-```html
-If-None-Match: "82e22293907ce725faf67773957acd12"
-```
-
-Last-Modified 首部字段也可以用于缓存验证,它包含在源服务器发送的响应报文中,指示源服务器对资源的最后修改时间。但是它是一种弱校验器,因为只能精确到一秒,所以它通常作为 ETag 的备用方案。如果响应首部字段里含有这个信息,客户端可以在后续的请求中带上 If-Modified-Since 来验证缓存。服务器只在所请求的资源在给定的日期时间之后对内容进行过修改的情况下才会将资源返回,状态码为 200 OK。如果请求的资源从那时起未经修改,那么返回一个不带有实体主体的 304 Not Modified 响应报文。
-
-```html
-Last-Modified: Wed, 21 Oct 2015 07:28:00 GMT
-```
-
-```html
-If-Modified-Since: Wed, 21 Oct 2015 07:28:00 GMT
-```
-
-## 内容协商
-
-通过内容协商返回最合适的内容,例如根据浏览器的默认语言选择返回中文界面还是英文界面。
-
-### 1. 类型
-
-**1.1 服务端驱动型**
-
-客户端设置特定的 HTTP 首部字段,例如 Accept、Accept-Charset、Accept-Encoding、Accept-Language,服务器根据这些字段返回特定的资源。
-
-它存在以下问题:
-
-- 服务器很难知道客户端浏览器的全部信息;
-- 客户端提供的信息相当冗长(HTTP/2 协议的首部压缩机制缓解了这个问题),并且存在隐私风险(HTTP 指纹识别技术);
-- 给定的资源需要返回不同的展现形式,共享缓存的效率会降低,而服务器端的实现会越来越复杂。
-
-**1.2 代理驱动型**
-
-服务器返回 300 Multiple Choices 或者 406 Not Acceptable,客户端从中选出最合适的那个资源。
-
-### 2. Vary
-
-```html
-Vary: Accept-Language
-```
-
-在使用内容协商的情况下,只有当缓存服务器中的缓存满足内容协商条件时,才能使用该缓存,否则应该向源服务器请求该资源。
-
-例如,一个客户端发送了一个包含 Accept-Language 首部字段的请求之后,源服务器返回的响应包含 `Vary: Accept-Language` 内容,缓存服务器对这个响应进行缓存之后,在客户端下一次访问同一个 URL 资源,并且 Accept-Language 与缓存中的对应的值相同时才会返回该缓存。
-
-## 内容编码
-
-内容编码将实体主体进行压缩,从而减少传输的数据量。
-
-常用的内容编码有:gzip、compress、deflate、identity。
-
-浏览器发送 Accept-Encoding 首部,其中包含有它所支持的压缩算法,以及各自的优先级。服务器则从中选择一种,使用该算法对响应的消息主体进行压缩,并且发送 Content-Encoding 首部来告知浏览器它选择了哪一种算法。由于该内容协商过程是基于编码类型来选择资源的展现形式的,响应报文的 Vary 首部字段至少要包含 Content-Encoding。
-
-## 范围请求
-
-如果网络出现中断,服务器只发送了一部分数据,范围请求可以使得客户端只请求服务器未发送的那部分数据,从而避免服务器重新发送所有数据。
-
-### 1. Range
-
-在请求报文中添加 Range 首部字段指定请求的范围。
-
-```html
-GET /z4d4kWk.jpg HTTP/1.1
-Host: i.imgur.com
-Range: bytes=0-1023
-```
-
-请求成功的话服务器返回的响应包含 206 Partial Content 状态码。
-
-```html
-HTTP/1.1 206 Partial Content
-Content-Range: bytes 0-1023/146515
-Content-Length: 1024
-...
-(binary content)
-```
-
-### 2. Accept-Ranges
-
-响应首部字段 Accept-Ranges 用于告知客户端是否能处理范围请求,可以处理使用 bytes,否则使用 none。
-
-```html
-Accept-Ranges: bytes
-```
-
-### 3. 响应状态码
-
-- 在请求成功的情况下,服务器会返回 206 Partial Content 状态码。
-- 在请求的范围越界的情况下,服务器会返回 416 Requested Range Not Satisfiable 状态码。
-- 在不支持范围请求的情况下,服务器会返回 200 OK 状态码。
-
-## 分块传输编码
-
-Chunked Transfer Encoding,可以把数据分割成多块,让浏览器逐步显示页面。
-
-## 多部分对象集合
-
-一份报文主体内可含有多种类型的实体同时发送,每个部分之间用 boundary 字段定义的分隔符进行分隔,每个部分都可以有首部字段。
-
-例如,上传多个表单时可以使用如下方式:
-
-```html
-Content-Type: multipart/form-data; boundary=AaB03x
-
---AaB03x
-Content-Disposition: form-data; name="submit-name"
-
-Larry
---AaB03x
-Content-Disposition: form-data; name="files"; filename="file1.txt"
-Content-Type: text/plain
-
-... contents of file1.txt ...
---AaB03x--
-```
-
-## 虚拟主机
-
-HTTP/1.1 使用虚拟主机技术,使得一台服务器拥有多个域名,并且在逻辑上可以看成多个服务器。
-
-## 通信数据转发
-
-### 1. 代理
-
-代理服务器接受客户端的请求,并且转发给其它服务器。
-
-使用代理的主要目的是:
-
-- 缓存
-- 负载均衡
-- 网络访问控制
-- 访问日志记录
-
-代理服务器分为正向代理和反向代理两种:
-
-- 用户察觉得到正向代理的存在。
-
- 
-
-- 而反向代理一般位于内部网络中,用户察觉不到。
-
- 
-
-### 2. 网关
-
-与代理服务器不同的是,网关服务器会将 HTTP 转化为其它协议进行通信,从而请求其它非 HTTP 服务器的服务。
-
-### 3. 隧道
-
-使用 SSL 等加密手段,在客户端和服务器之间建立一条安全的通信线路。
-
-# 六、HTTPS
-
-HTTP 有以下安全性问题:
-
-- 使用明文进行通信,内容可能会被窃听;
-- 不验证通信方的身份,通信方的身份有可能遭遇伪装;
-- 无法证明报文的完整性,报文有可能遭篡改。
-
-HTTPS 并不是新协议,而是让 HTTP 先和 SSL(Secure Sockets Layer)通信,再由 SSL 和 TCP 通信,也就是说 HTTPS 使用了隧道进行通信。
-
-通过使用 SSL,HTTPS 具有了加密(防窃听)、认证(防伪装)和完整性保护(防篡改)。
-
- 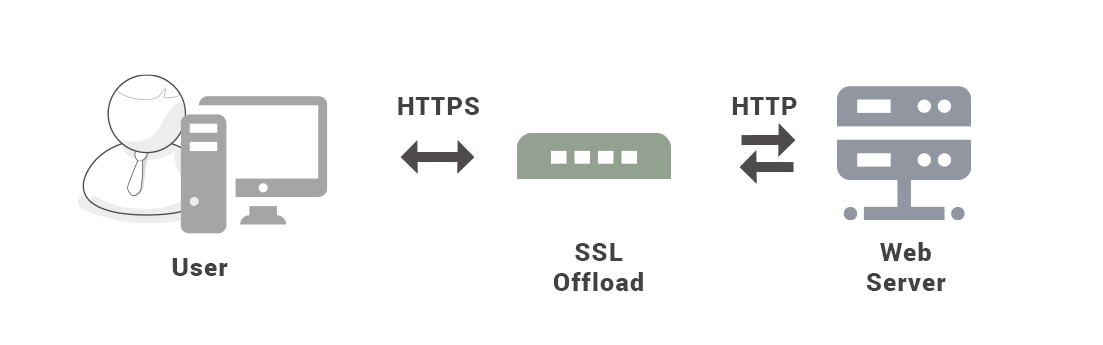
-
-## 加密
-
-### 1. 对称密钥加密
-
-对称密钥加密(Symmetric-Key Encryption),加密和解密使用同一密钥。
-
-- 优点:运算速度快;
-- 缺点:无法安全地将密钥传输给通信方。
-
- 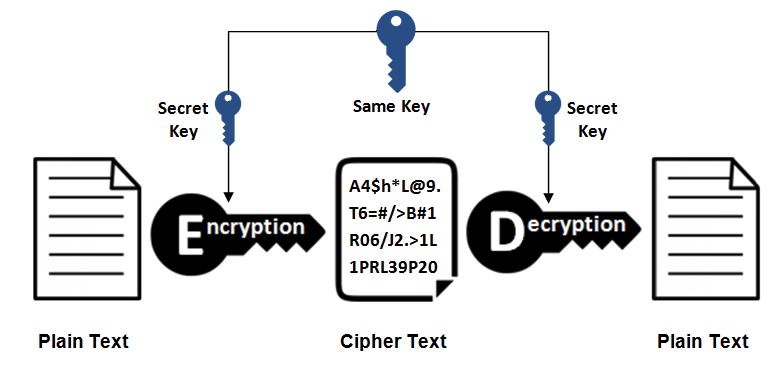
-
-### 2.非对称密钥加密
-
-非对称密钥加密,又称公开密钥加密(Public-Key Encryption),加密和解密使用不同的密钥。
-
-公开密钥所有人都可以获得,通信发送方获得接收方的公开密钥之后,就可以使用公开密钥进行加密,接收方收到通信内容后使用私有密钥解密。
-
-非对称密钥除了用来加密,还可以用来进行签名。因为私有密钥无法被其他人获取,因此通信发送方使用其私有密钥进行签名,通信接收方使用发送方的公开密钥对签名进行解密,就能判断这个签名是否正确。
-
-- 优点:可以更安全地将公开密钥传输给通信发送方;
-- 缺点:运算速度慢。
-
- 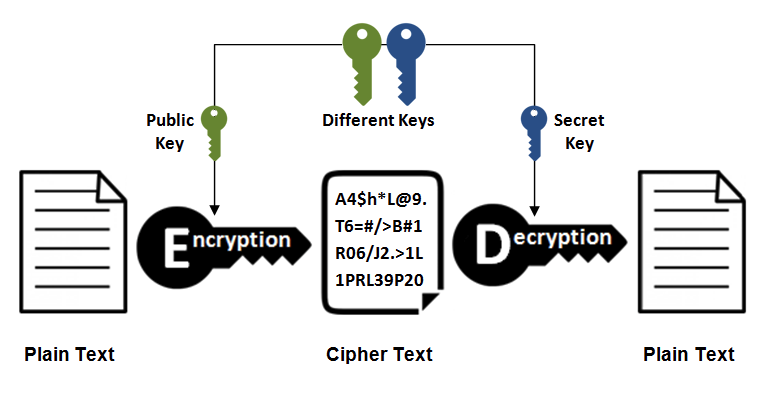
-
-### 3. HTTPS 采用的加密方式
-
-上面提到对称密钥加密方式的传输效率更高,但是无法安全地将密钥 Secret Key 传输给通信方。而非对称密钥加密方式可以保证传输的安全性,因此我们可以利用非对称密钥加密方式将 Secret Key 传输给通信方。HTTPS 采用混合的加密机制,正是利用了上面提到的方案:
-
-- 使用非对称密钥加密方式,传输对称密钥加密方式所需要的 Secret Key,从而保证安全性;
-- 获取到 Secret Key 后,再使用对称密钥加密方式进行通信,从而保证效率。(下图中的 Session Key 就是 Secret Key)
-
- 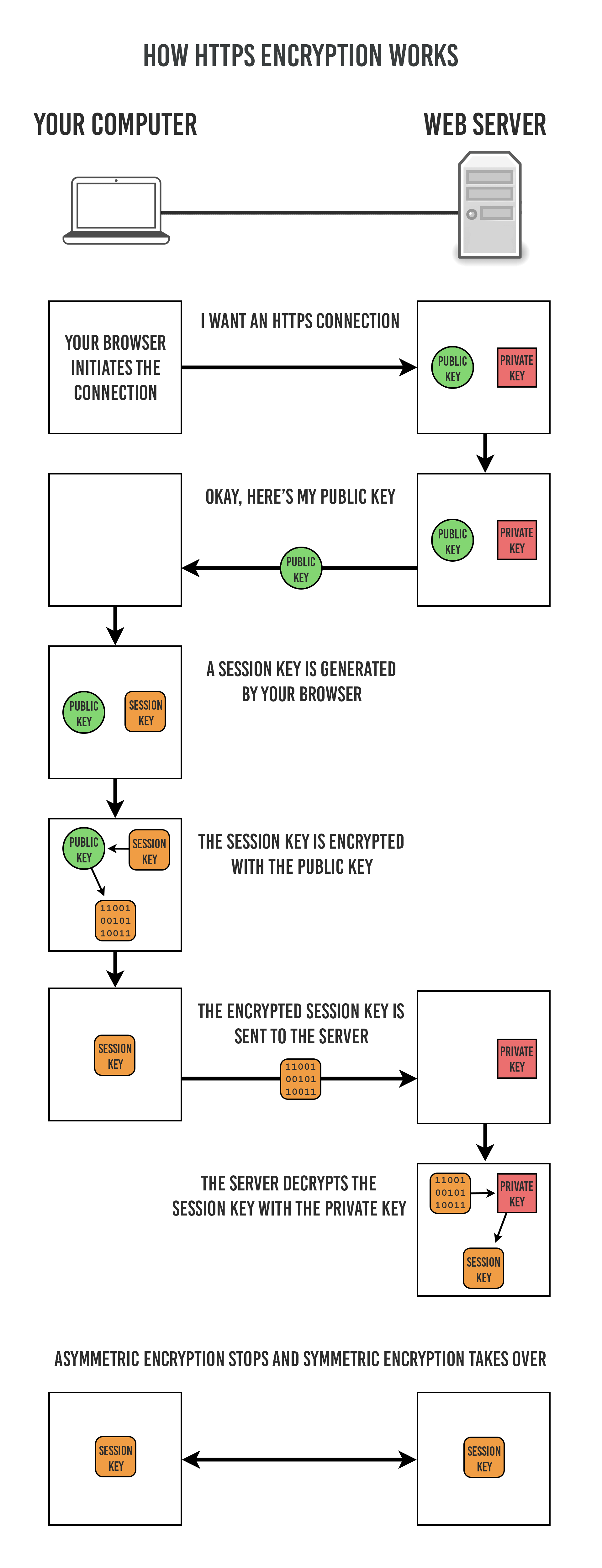
-
-## 认证
-
-通过使用 **证书** 来对通信方进行认证。
-
-数字证书认证机构(CA,Certificate Authority)是客户端与服务器双方都可信赖的第三方机构。
-
-服务器的运营人员向 CA 提出公开密钥的申请,CA 在判明提出申请者的身份之后,会对已申请的公开密钥做数字签名,然后分配这个已签名的公开密钥,并将该公开密钥放入公开密钥证书后绑定在一起。
-
-进行 HTTPS 通信时,服务器会把证书发送给客户端。客户端取得其中的公开密钥之后,先使用数字签名进行验证,如果验证通过,就可以开始通信了。
-
- 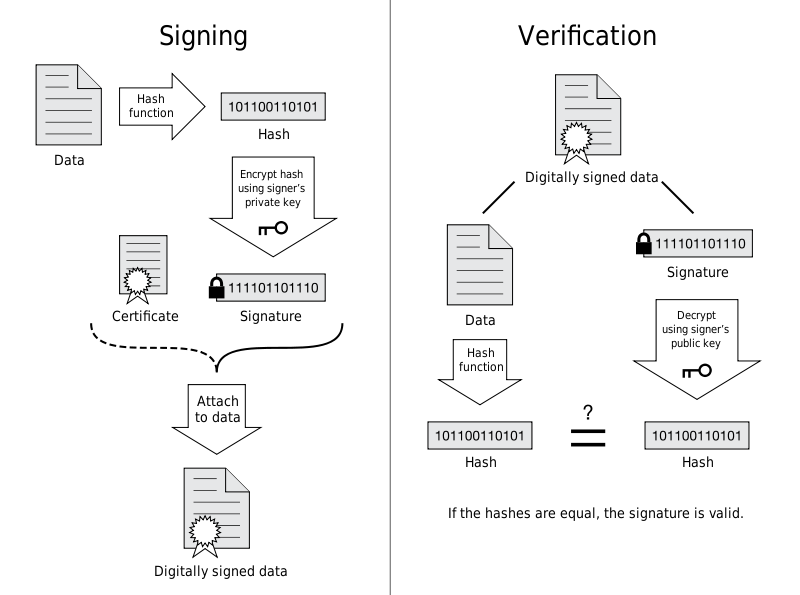
-
-## 完整性保护
-
-SSL 提供报文摘要功能来进行完整性保护。
-
-HTTP 也提供了 MD5 报文摘要功能,但不是安全的。例如报文内容被篡改之后,同时重新计算 MD5 的值,通信接收方是无法意识到发生了篡改。
-
-HTTPS 的报文摘要功能之所以安全,是因为它结合了加密和认证这两个操作。试想一下,加密之后的报文,遭到篡改之后,也很难重新计算报文摘要,因为无法轻易获取明文。
-
-## HTTPS 的缺点
-
-- 因为需要进行加密解密等过程,因此速度会更慢;
-- 需要支付证书授权的高额费用。
-
-# 七、HTTP/2.0
-
-## HTTP/1.x 缺陷
-
-HTTP/1.x 实现简单是以牺牲性能为代价的:
-
-- 客户端需要使用多个连接才能实现并发和缩短延迟;
-- 不会压缩请求和响应首部,从而导致不必要的网络流量;
-- 不支持有效的资源优先级,致使底层 TCP 连接的利用率低下。
-
-## 二进制分帧层
-
-HTTP/2.0 将报文分成 HEADERS 帧和 DATA 帧,它们都是二进制格式的。
-
- 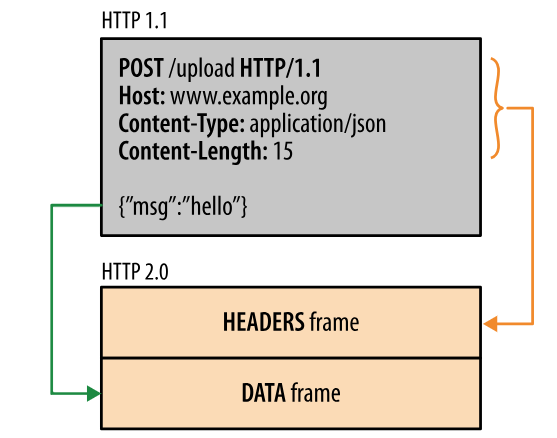
-
-在通信过程中,只会有一个 TCP 连接存在,它承载了任意数量的双向数据流(Stream)。
-
-- 一个数据流(Stream)都有一个唯一标识符和可选的优先级信息,用于承载双向信息。
-- 消息(Message)是与逻辑请求或响应对应的完整的一系列帧。
-- 帧(Frame)是最小的通信单位,来自不同数据流的帧可以交错发送,然后再根据每个帧头的数据流标识符重新组装。
-
- 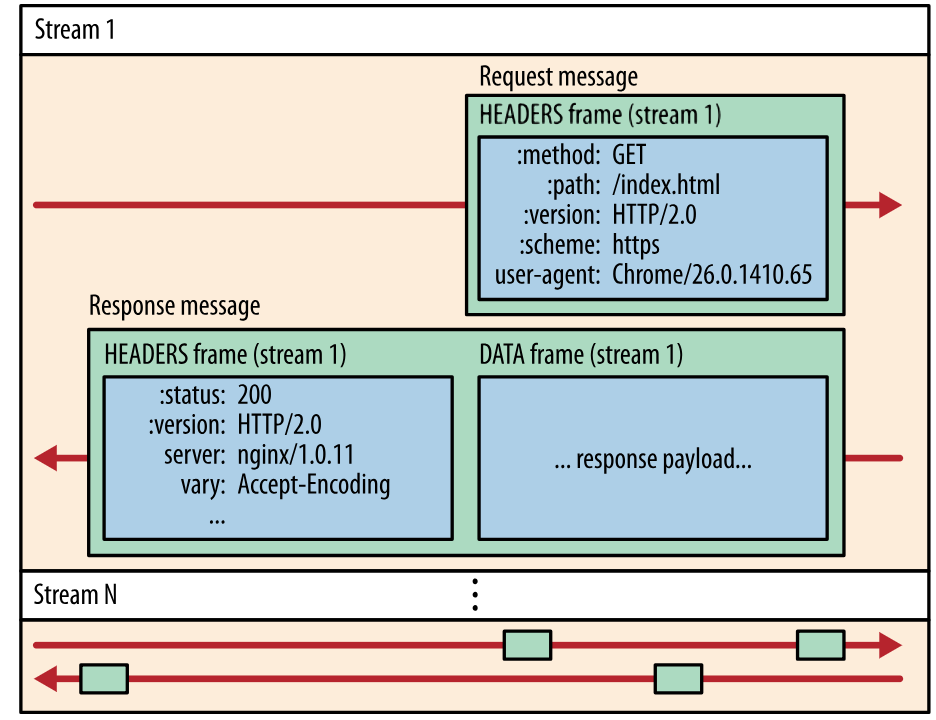
-
-## 服务端推送
-
-HTTP/2.0 在客户端请求一个资源时,会把相关的资源一起发送给客户端,客户端就不需要再次发起请求了。例如客户端请求 page.html 页面,服务端就把 script.js 和 style.css 等与之相关的资源一起发给客户端。
-
- 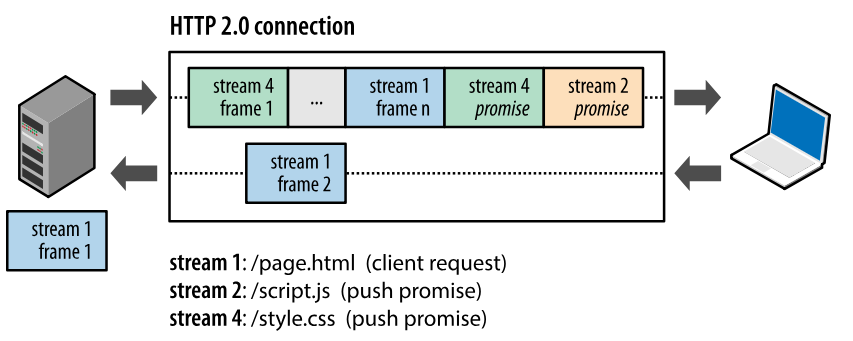
-
-## 首部压缩
-
-HTTP/1.1 的首部带有大量信息,而且每次都要重复发送。
-
-HTTP/2.0 要求客户端和服务器同时维护和更新一个包含之前见过的首部字段表,从而避免了重复传输。
-
-不仅如此,HTTP/2.0 也使用 Huffman 编码对首部字段进行压缩。
-
- 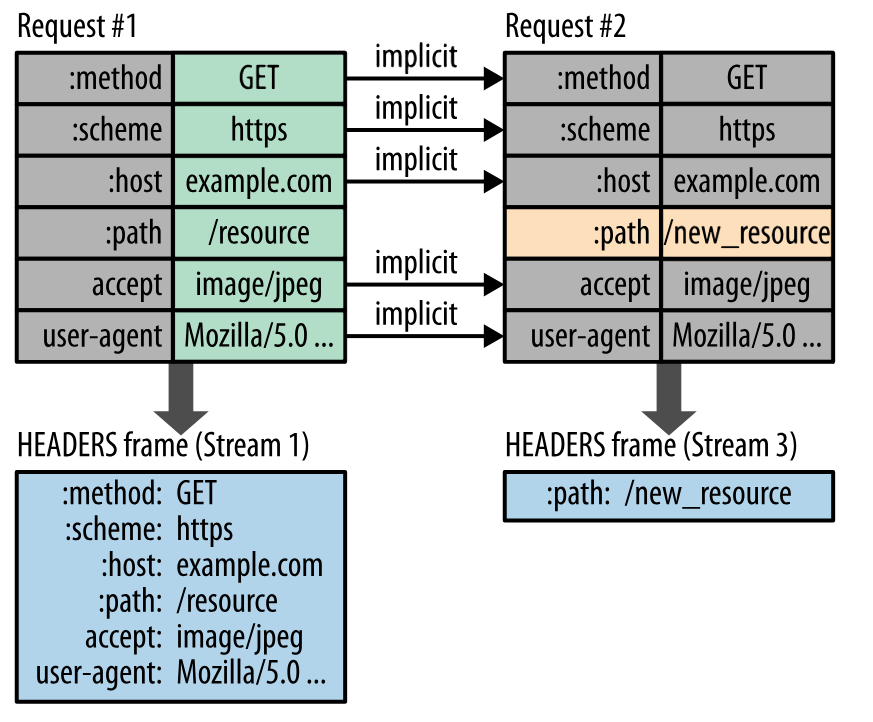
-
-# 八、HTTP/1.1 新特性
-
-详细内容请见上文
-
-- 默认是长连接
-- 支持流水线
-- 支持同时打开多个 TCP 连接
-- 支持虚拟主机
-- 新增状态码 100
-- 支持分块传输编码
-- 新增缓存处理指令 max-age
-
-# 九、GET 和 POST 比较
-
-## 作用
-
-GET 用于获取资源,而 POST 用于传输实体主体。
-
-## 参数
-
-GET 和 POST 的请求都能使用额外的参数,但是 GET 的参数是以查询字符串出现在 URL 中,而 POST 的参数存储在实体主体中。不能因为 POST 参数存储在实体主体中就认为它的安全性更高,因为照样可以通过一些抓包工具(Fiddler)查看。
-
-因为 URL 只支持 ASCII 码,因此 GET 的参数中如果存在中文等字符就需要先进行编码。例如 `中文` 会转换为 `%E4%B8%AD%E6%96%87`,而空格会转换为 `%20`。POST 参数支持标准字符集。
-
-```
-GET /test/demo_form.asp?name1=value1&name2=value2 HTTP/1.1
-```
-
-```
-POST /test/demo_form.asp HTTP/1.1
-Host: w3schools.com
-name1=value1&name2=value2
-```
-
-## 安全
-
-安全的 HTTP 方法不会改变服务器状态,也就是说它只是可读的。
-
-GET 方法是安全的,而 POST 却不是,因为 POST 的目的是传送实体主体内容,这个内容可能是用户上传的表单数据,上传成功之后,服务器可能把这个数据存储到数据库中,因此状态也就发生了改变。
-
-安全的方法除了 GET 之外还有:HEAD、OPTIONS。
-
-不安全的方法除了 POST 之外还有 PUT、DELETE。
-
-## 幂等性
-
-幂等的 HTTP 方法,同样的请求被执行一次与连续执行多次的效果是一样的,服务器的状态也是一样的。换句话说就是,幂等方法不应该具有副作用(统计用途除外)。
-
-所有的安全方法也都是幂等的。
-
-在正确实现的条件下,GET,HEAD,PUT 和 DELETE 等方法都是幂等的,而 POST 方法不是。
-
-GET /pageX HTTP/1.1 是幂等的,连续调用多次,客户端接收到的结果都是一样的:
-
-```
-GET /pageX HTTP/1.1
-GET /pageX HTTP/1.1
-GET /pageX HTTP/1.1
-GET /pageX HTTP/1.1
-```
-
-POST /add_row HTTP/1.1 不是幂等的,如果调用多次,就会增加多行记录:
-
-```
-POST /add_row HTTP/1.1 -> Adds a 1nd row
-POST /add_row HTTP/1.1 -> Adds a 2nd row
-POST /add_row HTTP/1.1 -> Adds a 3rd row
-```
-
-DELETE /idX/delete HTTP/1.1 是幂等的,即使不同的请求接收到的状态码不一样:
-
-```
-DELETE /idX/delete HTTP/1.1 -> Returns 200 if idX exists
-DELETE /idX/delete HTTP/1.1 -> Returns 404 as it just got deleted
-DELETE /idX/delete HTTP/1.1 -> Returns 404
-```
-
-## 可缓存
-
-如果要对响应进行缓存,需要满足以下条件:
-
-- 请求报文的 HTTP 方法本身是可缓存的,包括 GET 和 HEAD,但是 PUT 和 DELETE 不可缓存,POST 在多数情况下不可缓存的。
-- 响应报文的状态码是可缓存的,包括:200, 203, 204, 206, 300, 301, 404, 405, 410, 414, and 501。
-- 响应报文的 Cache-Control 首部字段没有指定不进行缓存。
-
-## XMLHttpRequest
-
-为了阐述 POST 和 GET 的另一个区别,需要先了解 XMLHttpRequest:
-
-> XMLHttpRequest 是一个 API,它为客户端提供了在客户端和服务器之间传输数据的功能。它提供了一个通过 URL 来获取数据的简单方式,并且不会使整个页面刷新。这使得网页只更新一部分页面而不会打扰到用户。XMLHttpRequest 在 AJAX 中被大量使用。
-
-- 在使用 XMLHttpRequest 的 POST 方法时,浏览器会先发送 Header 再发送 Data。但并不是所有浏览器会这么做,例如火狐就不会。
-- 而 GET 方法 Header 和 Data 会一起发送。
-
-# 参考资料
-
-- 上野宣. 图解 HTTP[M]. 人民邮电出版社, 2014.
-- [MDN : HTTP](https://developer.mozilla.org/en-US/docs/Web/HTTP)
-- [HTTP/2 简介](https://developers.google.com/web/fundamentals/performance/http2/?hl=zh-cn)
-- [htmlspecialchars](http://php.net/manual/zh/function.htmlspecialchars.php)
-- [Difference between file URI and URL in java](http://java2db.com/java-io/how-to-get-and-the-difference-between-file-uri-and-url-in-java)
-- [How to Fix SQL Injection Using Java PreparedStatement & CallableStatement](https://software-security.sans.org/developer-how-to/fix-sql-injection-in-java-using-prepared-callable-statement)
-- [浅谈 HTTP 中 Get 与 Post 的区别](https://www.cnblogs.com/hyddd/archive/2009/03/31/1426026.html)
-- [Are http:// and www really necessary?](https://www.webdancers.com/are-http-and-www-necesary/)
-- [HTTP (HyperText Transfer Protocol)](https://www.ntu.edu.sg/home/ehchua/programming/webprogramming/HTTP_Basics.html)
-- [Web-VPN: Secure Proxies with SPDY & Chrome](https://www.igvita.com/2011/12/01/web-vpn-secure-proxies-with-spdy-chrome/)
-- [File:HTTP persistent connection.svg](http://en.wikipedia.org/wiki/File:HTTP_persistent_connection.svg)
-- [Proxy server](https://en.wikipedia.org/wiki/Proxy_server)
-- [What Is This HTTPS/SSL Thing And Why Should You Care?](https://www.x-cart.com/blog/what-is-https-and-ssl.html)
-- [What is SSL Offloading?](https://securebox.comodo.com/ssl-sniffing/ssl-offloading/)
-- [Sun Directory Server Enterprise Edition 7.0 Reference - Key Encryption](https://docs.oracle.com/cd/E19424-01/820-4811/6ng8i26bn/index.html)
-- [An Introduction to Mutual SSL Authentication](https://www.codeproject.com/Articles/326574/An-Introduction-to-Mutual-SSL-Authentication)
-- [The Difference Between URLs and URIs](https://danielmiessler.com/study/url-uri/)
-- [Cookie 与 Session 的区别](https://juejin.im/entry/5766c29d6be3ff006a31b84e#comment)
-- [COOKIE 和 SESSION 有什么区别](https://www.zhihu.com/question/19786827)
-- [Cookie/Session 的机制与安全](https://harttle.land/2015/08/10/cookie-session.html)
-- [HTTPS 证书原理](https://shijianan.com/2017/06/11/https/)
-- [What is the difference between a URI, a URL and a URN?](https://stackoverflow.com/questions/176264/what-is-the-difference-between-a-uri-a-url-and-a-urn)
-- [XMLHttpRequest](https://developer.mozilla.org/zh-CN/docs/Web/API/XMLHttpRequest)
-- [XMLHttpRequest (XHR) Uses Multiple Packets for HTTP POST?](https://blog.josephscott.org/2009/08/27/xmlhttprequest-xhr-uses-multiple-packets-for-http-post/)
-- [Symmetric vs. Asymmetric Encryption – What are differences?](https://www.ssl2buy.com/wiki/symmetric-vs-asymmetric-encryption-what-are-differences)
-- [Web 性能优化与 HTTP/2](https://www.kancloud.cn/digest/web-performance-http2)
-- [HTTP/2 简介](https://developers.google.com/web/fundamentals/performance/http2/?hl=zh-cn)
-
-
-
-
-
-
- 
-
-实例化一个具有缓存功能的字节流对象时,只需要在 FileInputStream 对象上再套一层 BufferedInputStream 对象即可。
-
-```java
-FileInputStream fileInputStream = new FileInputStream(filePath);
-BufferedInputStream bufferedInputStream = new BufferedInputStream(fileInputStream);
-```
-
-DataInputStream 装饰者提供了对更多数据类型进行输入的操作,比如 int、double 等基本类型。
-
-# 四、字符操作
-
-## 编码与解码
-
-编码就是把字符转换为字节,而解码是把字节重新组合成字符。
-
-如果编码和解码过程使用不同的编码方式那么就出现了乱码。
-
-- GBK 编码中,中文字符占 2 个字节,英文字符占 1 个字节;
-- UTF-8 编码中,中文字符占 3 个字节,英文字符占 1 个字节;
-- UTF-16be 编码中,中文字符和英文字符都占 2 个字节。
-
-UTF-16be 中的 be 指的是 Big Endian,也就是大端。相应地也有 UTF-16le,le 指的是 Little Endian,也就是小端。
-
-Java 的内存编码使用双字节编码 UTF-16be,这不是指 Java 只支持这一种编码方式,而是说 char 这种类型使用 UTF-16be 进行编码。char 类型占 16 位,也就是两个字节,Java 使用这种双字节编码是为了让一个中文或者一个英文都能使用一个 char 来存储。
-
-## String 的编码方式
-
-String 可以看成一个字符序列,可以指定一个编码方式将它编码为字节序列,也可以指定一个编码方式将一个字节序列解码为 String。
-
-```java
-String str1 = "中文";
-byte[] bytes = str1.getBytes("UTF-8");
-String str2 = new String(bytes, "UTF-8");
-System.out.println(str2);
-```
-
-在调用无参数 getBytes() 方法时,默认的编码方式不是 UTF-16be。双字节编码的好处是可以使用一个 char 存储中文和英文,而将 String 转为 bytes[] 字节数组就不再需要这个好处,因此也就不再需要双字节编码。getBytes() 的默认编码方式与平台有关,一般为 UTF-8。
-
-```java
-byte[] bytes = str1.getBytes();
-```
-
-## Reader 与 Writer
-
-不管是磁盘还是网络传输,最小的存储单元都是字节,而不是字符。但是在程序中操作的通常是字符形式的数据,因此需要提供对字符进行操作的方法。
-
-- InputStreamReader 实现从字节流解码成字符流;
-- OutputStreamWriter 实现字符流编码成为字节流。
-
-## 实现逐行输出文本文件的内容
-
-```java
-public static void readFileContent(String filePath) throws IOException {
-
- FileReader fileReader = new FileReader(filePath);
- BufferedReader bufferedReader = new BufferedReader(fileReader);
-
- String line;
- while ((line = bufferedReader.readLine()) != null) {
- System.out.println(line);
- }
-
- // 装饰者模式使得 BufferedReader 组合了一个 Reader 对象
- // 在调用 BufferedReader 的 close() 方法时会去调用 Reader 的 close() 方法
- // 因此只要一个 close() 调用即可
- bufferedReader.close();
-}
-```
-
-# 五、对象操作
-
-## 序列化
-
-序列化就是将一个对象转换成字节序列,方便存储和传输。
-
-- 序列化:ObjectOutputStream.writeObject()
-- 反序列化:ObjectInputStream.readObject()
-
-不会对静态变量进行序列化,因为序列化只是保存对象的状态,静态变量属于类的状态。
-
-## Serializable
-
-序列化的类需要实现 Serializable 接口,它只是一个标准,没有任何方法需要实现,但是如果不去实现它的话而进行序列化,会抛出异常。
-
-```java
-public static void main(String[] args) throws IOException, ClassNotFoundException {
-
- A a1 = new A(123, "abc");
- String objectFile = "file/a1";
-
- ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream(objectFile));
- objectOutputStream.writeObject(a1);
- objectOutputStream.close();
-
- ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream(objectFile));
- A a2 = (A) objectInputStream.readObject();
- objectInputStream.close();
- System.out.println(a2);
-}
-
-private static class A implements Serializable {
-
- private int x;
- private String y;
-
- A(int x, String y) {
- this.x = x;
- this.y = y;
- }
-
- @Override
- public String toString() {
- return "x = " + x + " " + "y = " + y;
- }
-}
-```
-
-## transient
-
-transient 关键字可以使一些属性不会被序列化。
-
-ArrayList 中存储数据的数组 elementData 是用 transient 修饰的,因为这个数组是动态扩展的,并不是所有的空间都被使用,因此就不需要所有的内容都被序列化。通过重写序列化和反序列化方法,使得可以只序列化数组中有内容的那部分数据。
-
-```java
-private transient Object[] elementData;
-```
-
-# 六、网络操作
-
-Java 中的网络支持:
-
-- InetAddress:用于表示网络上的硬件资源,即 IP 地址;
-- URL:统一资源定位符;
-- Sockets:使用 TCP 协议实现网络通信;
-- Datagram:使用 UDP 协议实现网络通信。
-
-## InetAddress
-
-没有公有的构造函数,只能通过静态方法来创建实例。
-
-```java
-InetAddress.getByName(String host);
-InetAddress.getByAddress(byte[] address);
-```
-
-## URL
-
-可以直接从 URL 中读取字节流数据。
-
-```java
-public static void main(String[] args) throws IOException {
-
- URL url = new URL("http://www.baidu.com");
-
- /* 字节流 */
- InputStream is = url.openStream();
-
- /* 字符流 */
- InputStreamReader isr = new InputStreamReader(is, "utf-8");
-
- /* 提供缓存功能 */
- BufferedReader br = new BufferedReader(isr);
-
- String line;
- while ((line = br.readLine()) != null) {
- System.out.println(line);
- }
-
- br.close();
-}
-```
-
-## Sockets
-
-- ServerSocket:服务器端类
-- Socket:客户端类
-- 服务器和客户端通过 InputStream 和 OutputStream 进行输入输出。
-
- 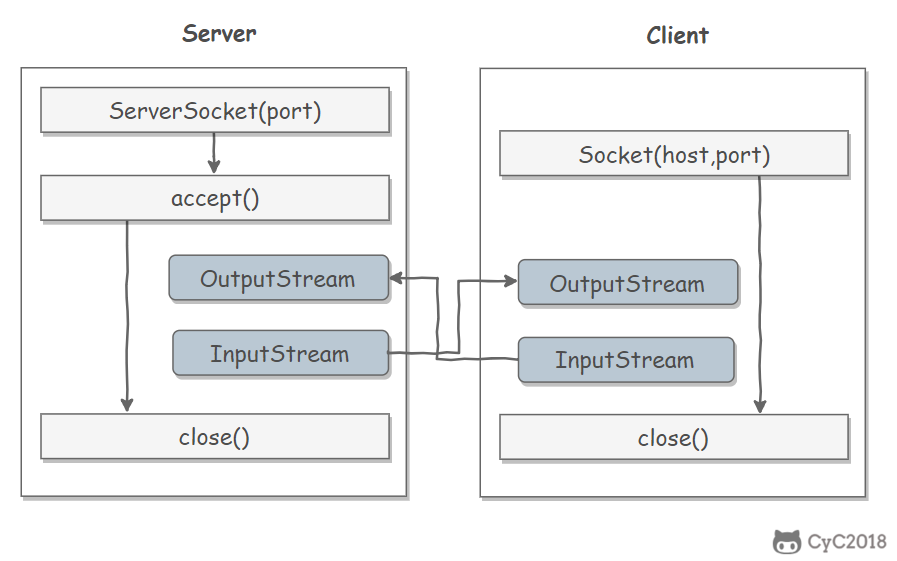
-
-## Datagram
-
-- DatagramSocket:通信类
-- DatagramPacket:数据包类
-
-# 七、NIO
-
-新的输入/输出 (NIO) 库是在 JDK 1.4 中引入的,弥补了原来的 I/O 的不足,提供了高速的、面向块的 I/O。
-
-## 流与块
-
-I/O 与 NIO 最重要的区别是数据打包和传输的方式,I/O 以流的方式处理数据,而 NIO 以块的方式处理数据。
-
-面向流的 I/O 一次处理一个字节数据:一个输入流产生一个字节数据,一个输出流消费一个字节数据。为流式数据创建过滤器非常容易,链接几个过滤器,以便每个过滤器只负责复杂处理机制的一部分。不利的一面是,面向流的 I/O 通常相当慢。
-
-面向块的 I/O 一次处理一个数据块,按块处理数据比按流处理数据要快得多。但是面向块的 I/O 缺少一些面向流的 I/O 所具有的优雅性和简单性。
-
-I/O 包和 NIO 已经很好地集成了,java.io.\* 已经以 NIO 为基础重新实现了,所以现在它可以利用 NIO 的一些特性。例如,java.io.\* 包中的一些类包含以块的形式读写数据的方法,这使得即使在面向流的系统中,处理速度也会更快。
-
-## 通道与缓冲区
-
-### 1. 通道
-
-通道 Channel 是对原 I/O 包中的流的模拟,可以通过它读取和写入数据。
-
-通道与流的不同之处在于,流只能在一个方向上移动(一个流必须是 InputStream 或者 OutputStream 的子类),而通道是双向的,可以用于读、写或者同时用于读写。
-
-通道包括以下类型:
-
-- FileChannel:从文件中读写数据;
-- DatagramChannel:通过 UDP 读写网络中数据;
-- SocketChannel:通过 TCP 读写网络中数据;
-- ServerSocketChannel:可以监听新进来的 TCP 连接,对每一个新进来的连接都会创建一个 SocketChannel。
-
-### 2. 缓冲区
-
-发送给一个通道的所有数据都必须首先放到缓冲区中,同样地,从通道中读取的任何数据都要先读到缓冲区中。也就是说,不会直接对通道进行读写数据,而是要先经过缓冲区。
-
-缓冲区实质上是一个数组,但它不仅仅是一个数组。缓冲区提供了对数据的结构化访问,而且还可以跟踪系统的读/写进程。
-
-缓冲区包括以下类型:
-
-- ByteBuffer
-- CharBuffer
-- ShortBuffer
-- IntBuffer
-- LongBuffer
-- FloatBuffer
-- DoubleBuffer
-
-## 缓冲区状态变量
-
-- capacity:最大容量;
-- position:当前已经读写的字节数;
-- limit:还可以读写的字节数。
-
-状态变量的改变过程举例:
-
-① 新建一个大小为 8 个字节的缓冲区,此时 position 为 0,而 limit = capacity = 8。capacity 变量不会改变,下面的讨论会忽略它。
-
- 
-
-② 从输入通道中读取 5 个字节数据写入缓冲区中,此时 position 为 5,limit 保持不变。
-
- 
-
-③ 在将缓冲区的数据写到输出通道之前,需要先调用 flip() 方法,这个方法将 limit 设置为当前 position,并将 position 设置为 0。
-
- 
-
-④ 从缓冲区中取 4 个字节到输出缓冲中,此时 position 设为 4。
-
- 
-
-⑤ 最后需要调用 clear() 方法来清空缓冲区,此时 position 和 limit 都被设置为最初位置。
-
- 
-
-## 文件 NIO 实例
-
-以下展示了使用 NIO 快速复制文件的实例:
-
-```java
-public static void fastCopy(String src, String dist) throws IOException {
-
- /* 获得源文件的输入字节流 */
- FileInputStream fin = new FileInputStream(src);
-
- /* 获取输入字节流的文件通道 */
- FileChannel fcin = fin.getChannel();
-
- /* 获取目标文件的输出字节流 */
- FileOutputStream fout = new FileOutputStream(dist);
-
- /* 获取输出字节流的文件通道 */
- FileChannel fcout = fout.getChannel();
-
- /* 为缓冲区分配 1024 个字节 */
- ByteBuffer buffer = ByteBuffer.allocateDirect(1024);
-
- while (true) {
-
- /* 从输入通道中读取数据到缓冲区中 */
- int r = fcin.read(buffer);
-
- /* read() 返回 -1 表示 EOF */
- if (r == -1) {
- break;
- }
-
- /* 切换读写 */
- buffer.flip();
-
- /* 把缓冲区的内容写入输出文件中 */
- fcout.write(buffer);
-
- /* 清空缓冲区 */
- buffer.clear();
- }
-}
-```
-
-## 选择器
-
-NIO 常常被叫做非阻塞 IO,主要是因为 NIO 在网络通信中的非阻塞特性被广泛使用。
-
-NIO 实现了 IO 多路复用中的 Reactor 模型,一个线程 Thread 使用一个选择器 Selector 通过轮询的方式去监听多个通道 Channel 上的事件,从而让一个线程就可以处理多个事件。
-
-通过配置监听的通道 Channel 为非阻塞,那么当 Channel 上的 IO 事件还未到达时,就不会进入阻塞状态一直等待,而是继续轮询其它 Channel,找到 IO 事件已经到达的 Channel 执行。
-
-因为创建和切换线程的开销很大,因此使用一个线程来处理多个事件而不是一个线程处理一个事件,对于 IO 密集型的应用具有很好地性能。
-
-应该注意的是,只有套接字 Channel 才能配置为非阻塞,而 FileChannel 不能,为 FileChannel 配置非阻塞也没有意义。
-
- 
-
-### 1. 创建选择器
-
-```java
-Selector selector = Selector.open();
-```
-
-### 2. 将通道注册到选择器上
-
-```java
-ServerSocketChannel ssChannel = ServerSocketChannel.open();
-ssChannel.configureBlocking(false);
-ssChannel.register(selector, SelectionKey.OP_ACCEPT);
-```
-
-通道必须配置为非阻塞模式,否则使用选择器就没有任何意义了,因为如果通道在某个事件上被阻塞,那么服务器就不能响应其它事件,必须等待这个事件处理完毕才能去处理其它事件,显然这和选择器的作用背道而驰。
-
-在将通道注册到选择器上时,还需要指定要注册的具体事件,主要有以下几类:
-
-- SelectionKey.OP_CONNECT
-- SelectionKey.OP_ACCEPT
-- SelectionKey.OP_READ
-- SelectionKey.OP_WRITE
-
-它们在 SelectionKey 的定义如下:
-
-```java
-public static final int OP_READ = 1 << 0;
-public static final int OP_WRITE = 1 << 2;
-public static final int OP_CONNECT = 1 << 3;
-public static final int OP_ACCEPT = 1 << 4;
-```
-
-可以看出每个事件可以被当成一个位域,从而组成事件集整数。例如:
-
-```java
-int interestSet = SelectionKey.OP_READ | SelectionKey.OP_WRITE;
-```
-
-### 3. 监听事件
-
-```java
-int num = selector.select();
-```
-
-使用 select() 来监听到达的事件,它会一直阻塞直到有至少一个事件到达。
-
-### 4. 获取到达的事件
-
-```java
-Set keys = selector.selectedKeys();
-Iterator keyIterator = keys.iterator();
-while (keyIterator.hasNext()) {
- SelectionKey key = keyIterator.next();
- if (key.isAcceptable()) {
- // ...
- } else if (key.isReadable()) {
- // ...
- }
- keyIterator.remove();
-}
-```
-
-### 5. 事件循环
-
-因为一次 select() 调用不能处理完所有的事件,并且服务器端有可能需要一直监听事件,因此服务器端处理事件的代码一般会放在一个死循环内。
-
-```java
-while (true) {
- int num = selector.select();
- Set keys = selector.selectedKeys();
- Iterator keyIterator = keys.iterator();
- while (keyIterator.hasNext()) {
- SelectionKey key = keyIterator.next();
- if (key.isAcceptable()) {
- // ...
- } else if (key.isReadable()) {
- // ...
- }
- keyIterator.remove();
- }
-}
-```
-
-## 套接字 NIO 实例
-
-```java
-public class NIOServer {
-
- public static void main(String[] args) throws IOException {
-
- Selector selector = Selector.open();
-
- ServerSocketChannel ssChannel = ServerSocketChannel.open();
- ssChannel.configureBlocking(false);
- ssChannel.register(selector, SelectionKey.OP_ACCEPT);
-
- ServerSocket serverSocket = ssChannel.socket();
- InetSocketAddress address = new InetSocketAddress("127.0.0.1", 8888);
- serverSocket.bind(address);
-
- while (true) {
-
- selector.select();
- Set keys = selector.selectedKeys();
- Iterator keyIterator = keys.iterator();
-
- while (keyIterator.hasNext()) {
-
- SelectionKey key = keyIterator.next();
-
- if (key.isAcceptable()) {
-
- ServerSocketChannel ssChannel1 = (ServerSocketChannel) key.channel();
-
- // 服务器会为每个新连接创建一个 SocketChannel
- SocketChannel sChannel = ssChannel1.accept();
- sChannel.configureBlocking(false);
-
- // 这个新连接主要用于从客户端读取数据
- sChannel.register(selector, SelectionKey.OP_READ);
-
- } else if (key.isReadable()) {
-
- SocketChannel sChannel = (SocketChannel) key.channel();
- System.out.println(readDataFromSocketChannel(sChannel));
- sChannel.close();
- }
-
- keyIterator.remove();
- }
- }
- }
-
- private static String readDataFromSocketChannel(SocketChannel sChannel) throws IOException {
-
- ByteBuffer buffer = ByteBuffer.allocate(1024);
- StringBuilder data = new StringBuilder();
-
- while (true) {
-
- buffer.clear();
- int n = sChannel.read(buffer);
- if (n == -1) {
- break;
- }
- buffer.flip();
- int limit = buffer.limit();
- char[] dst = new char[limit];
- for (int i = 0; i < limit; i++) {
- dst[i] = (char) buffer.get(i);
- }
- data.append(dst);
- buffer.clear();
- }
- return data.toString();
- }
-}
-```
-
-```java
-public class NIOClient {
-
- public static void main(String[] args) throws IOException {
- Socket socket = new Socket("127.0.0.1", 8888);
- OutputStream out = socket.getOutputStream();
- String s = "hello world";
- out.write(s.getBytes());
- out.close();
- }
-}
-```
-
-## 内存映射文件
-
-内存映射文件 I/O 是一种读和写文件数据的方法,它可以比常规的基于流或者基于通道的 I/O 快得多。
-
-向内存映射文件写入可能是危险的,只是改变数组的单个元素这样的简单操作,就可能会直接修改磁盘上的文件。修改数据与将数据保存到磁盘是没有分开的。
-
-下面代码行将文件的前 1024 个字节映射到内存中,map() 方法返回一个 MappedByteBuffer,它是 ByteBuffer 的子类。因此,可以像使用其他任何 ByteBuffer 一样使用新映射的缓冲区,操作系统会在需要时负责执行映射。
-
-```java
-MappedByteBuffer mbb = fc.map(FileChannel.MapMode.READ_WRITE, 0, 1024);
-```
-
-## 对比
-
-NIO 与普通 I/O 的区别主要有以下两点:
-
-- NIO 是非阻塞的;
-- NIO 面向块,I/O 面向流。
-
-# 八、参考资料
-
-- Eckel B, 埃克尔, 昊鹏, 等. Java 编程思想 [M]. 机械工业出版社, 2002.
-- [IBM: NIO 入门](https://www.ibm.com/developerworks/cn/education/java/j-nio/j-nio.html)
-- [Java NIO Tutorial](http://tutorials.jenkov.com/java-nio/index.html)
-- [Java NIO 浅析](https://tech.meituan.com/nio.html)
-- [IBM: 深入分析 Java I/O 的工作机制](https://www.ibm.com/developerworks/cn/java/j-lo-javaio/index.html)
-- [IBM: 深入分析 Java 中的中文编码问题](https://www.ibm.com/developerworks/cn/java/j-lo-chinesecoding/index.html)
-- [IBM: Java 序列化的高级认识](https://www.ibm.com/developerworks/cn/java/j-lo-serial/index.html)
-- [NIO 与传统 IO 的区别](http://blog.csdn.net/shimiso/article/details/24990499)
-- [Decorator Design Pattern](http://stg-tud.github.io/sedc/Lecture/ws13-14/5.3-Decorator.html#mode=document)
-- [Socket Multicast](http://labojava.blogspot.com/2012/12/socket-multicast.html)
-
-
-
-
-
-
- 
-
-**3. 安全性**
-
-String 经常作为参数,String 不可变性可以保证参数不可变。例如在作为网络连接参数的情况下如果 String 是可变的,那么在网络连接过程中,String 被改变,改变 String 的那一方以为现在连接的是其它主机,而实际情况却不一定是。
-
-**4. 线程安全**
-
-String 不可变性天生具备线程安全,可以在多个线程中安全地使用。
-
-[Program Creek : Why String is immutable in Java?](https://www.programcreek.com/2013/04/why-string-is-immutable-in-java/)
-
-## String, StringBuffer and StringBuilder
-
-**1. 可变性**
-
-- String 不可变
-- StringBuffer 和 StringBuilder 可变
-
-**2. 线程安全**
-
-- String 不可变,因此是线程安全的
-- StringBuilder 不是线程安全的
-- StringBuffer 是线程安全的,内部使用 synchronized 进行同步
-
-[StackOverflow : String, StringBuffer, and StringBuilder](https://stackoverflow.com/questions/2971315/string-stringbuffer-and-stringbuilder)
-
-## String Pool
-
-字符串常量池(String Pool)保存着所有字符串字面量(literal strings),这些字面量在编译时期就确定。不仅如此,还可以使用 String 的 intern() 方法在运行过程将字符串添加到 String Pool 中。
-
-当一个字符串调用 intern() 方法时,如果 String Pool 中已经存在一个字符串和该字符串值相等(使用 equals() 方法进行确定),那么就会返回 String Pool 中字符串的引用;否则,就会在 String Pool 中添加一个新的字符串,并返回这个新字符串的引用。
-
-下面示例中,s1 和 s2 采用 new String() 的方式新建了两个不同字符串,而 s3 和 s4 是通过 s1.intern() 和 s2.intern() 方法取得同一个字符串引用。intern() 首先把 "aaa" 放到 String Pool 中,然后返回这个字符串引用,因此 s3 和 s4 引用的是同一个字符串。
-
-```java
-String s1 = new String("aaa");
-String s2 = new String("aaa");
-System.out.println(s1 == s2); // false
-String s3 = s1.intern();
-String s4 = s2.intern();
-System.out.println(s3 == s4); // true
-```
-
-如果是采用 "bbb" 这种字面量的形式创建字符串,会自动地将字符串放入 String Pool 中。
-
-```java
-String s5 = "bbb";
-String s6 = "bbb";
-System.out.println(s5 == s6); // true
-```
-
-在 Java 7 之前,String Pool 被放在运行时常量池中,它属于永久代。而在 Java 7,String Pool 被移到堆中。这是因为永久代的空间有限,在大量使用字符串的场景下会导致 OutOfMemoryError 错误。
-
-- [StackOverflow : What is String interning?](https://stackoverflow.com/questions/10578984/what-is-string-interning)
-- [深入解析 String#intern](https://tech.meituan.com/in_depth_understanding_string_intern.html)
-
-## new String("abc")
-
-使用这种方式一共会创建两个字符串对象(前提是 String Pool 中还没有 "abc" 字符串对象)。
-
-- "abc" 属于字符串字面量,因此编译时期会在 String Pool 中创建一个字符串对象,指向这个 "abc" 字符串字面量;
-- 而使用 new 的方式会在堆中创建一个字符串对象。
-
-创建一个测试类,其 main 方法中使用这种方式来创建字符串对象。
-
-```java
-public class NewStringTest {
- public static void main(String[] args) {
- String s = new String("abc");
- }
-}
-```
-
-使用 javap -verbose 进行反编译,得到以下内容:
-
-```java
-// ...
-Constant pool:
-// ...
- #2 = Class #18 // java/lang/String
- #3 = String #19 // abc
-// ...
- #18 = Utf8 java/lang/String
- #19 = Utf8 abc
-// ...
-
- public static void main(java.lang.String[]);
- descriptor: ([Ljava/lang/String;)V
- flags: ACC_PUBLIC, ACC_STATIC
- Code:
- stack=3, locals=2, args_size=1
- 0: new #2 // class java/lang/String
- 3: dup
- 4: ldc #3 // String abc
- 6: invokespecial #4 // Method java/lang/String."":(Ljava/lang/String;)V
- 9: astore_1
-// ...
-```
-
-在 Constant Pool 中,#19 存储这字符串字面量 "abc",#3 是 String Pool 的字符串对象,它指向 #19 这个字符串字面量。在 main 方法中,0: 行使用 new #2 在堆中创建一个字符串对象,并且使用 ldc #3 将 String Pool 中的字符串对象作为 String 构造函数的参数。
-
-以下是 String 构造函数的源码,可以看到,在将一个字符串对象作为另一个字符串对象的构造函数参数时,并不会完全复制 value 数组内容,而是都会指向同一个 value 数组。
-
-```java
-public String(String original) {
- this.value = original.value;
- this.hash = original.hash;
-}
-```
-
-# 三、运算
-
-## 参数传递
-
-Java 的参数是以值传递的形式传入方法中,而不是引用传递。
-
-以下代码中 Dog dog 的 dog 是一个指针,存储的是对象的地址。在将一个参数传入一个方法时,本质上是将对象的地址以值的方式传递到形参中。
-
-```java
-public class Dog {
-
- String name;
-
- Dog(String name) {
- this.name = name;
- }
-
- String getName() {
- return this.name;
- }
-
- void setName(String name) {
- this.name = name;
- }
-
- String getObjectAddress() {
- return super.toString();
- }
-}
-```
-
-在方法中改变对象的字段值会改变原对象该字段值,因为引用的是同一个对象。
-
-```java
-class PassByValueExample {
- public static void main(String[] args) {
- Dog dog = new Dog("A");
- func(dog);
- System.out.println(dog.getName()); // B
- }
-
- private static void func(Dog dog) {
- dog.setName("B");
- }
-}
-```
-
-但是在方法中将指针引用了其它对象,那么此时方法里和方法外的两个指针指向了不同的对象,在一个指针改变其所指向对象的内容对另一个指针所指向的对象没有影响。
-
-```java
-public class PassByValueExample {
- public static void main(String[] args) {
- Dog dog = new Dog("A");
- System.out.println(dog.getObjectAddress()); // Dog@4554617c
- func(dog);
- System.out.println(dog.getObjectAddress()); // Dog@4554617c
- System.out.println(dog.getName()); // A
- }
-
- private static void func(Dog dog) {
- System.out.println(dog.getObjectAddress()); // Dog@4554617c
- dog = new Dog("B");
- System.out.println(dog.getObjectAddress()); // Dog@74a14482
- System.out.println(dog.getName()); // B
- }
-}
-```
-
-[StackOverflow: Is Java “pass-by-reference” or “pass-by-value”?](https://stackoverflow.com/questions/40480/is-java-pass-by-reference-or-pass-by-value)
-
-## float 与 double
-
-Java 不能隐式执行向下转型,因为这会使得精度降低。
-
-1.1 字面量属于 double 类型,不能直接将 1.1 直接赋值给 float 变量,因为这是向下转型。
-
-```java
-// float f = 1.1;
-```
-
-1.1f 字面量才是 float 类型。
-
-```java
-float f = 1.1f;
-```
-
-## 隐式类型转换
-
-因为字面量 1 是 int 类型,它比 short 类型精度要高,因此不能隐式地将 int 类型向下转型为 short 类型。
-
-```java
-short s1 = 1;
-// s1 = s1 + 1;
-```
-
-但是使用 += 或者 ++ 运算符会执行隐式类型转换。
-
-```java
-s1 += 1;
-s1++;
-```
-
-上面的语句相当于将 s1 + 1 的计算结果进行了向下转型:
-
-```java
-s1 = (short) (s1 + 1);
-```
-
-[StackOverflow : Why don't Java's +=, -=, *=, /= compound assignment operators require casting?](https://stackoverflow.com/questions/8710619/why-dont-javas-compound-assignment-operators-require-casting)
-
-## switch
-
-从 Java 7 开始,可以在 switch 条件判断语句中使用 String 对象。
-
-```java
-String s = "a";
-switch (s) {
- case "a":
- System.out.println("aaa");
- break;
- case "b":
- System.out.println("bbb");
- break;
-}
-```
-
-switch 不支持 long,是因为 switch 的设计初衷是对那些只有少数几个值的类型进行等值判断,如果值过于复杂,那么还是用 if 比较合适。
-
-```java
-// long x = 111;
-// switch (x) { // Incompatible types. Found: 'long', required: 'char, byte, short, int, Character, Byte, Short, Integer, String, or an enum'
-// case 111:
-// System.out.println(111);
-// break;
-// case 222:
-// System.out.println(222);
-// break;
-// }
-```
-
-[StackOverflow : Why can't your switch statement data type be long, Java?](https://stackoverflow.com/questions/2676210/why-cant-your-switch-statement-data-type-be-long-java)
-
-
-# 四、关键字
-
-## final
-
-**1. 数据**
-
-声明数据为常量,可以是编译时常量,也可以是在运行时被初始化后不能被改变的常量。
-
-- 对于基本类型,final 使数值不变;
-- 对于引用类型,final 使引用不变,也就不能引用其它对象,但是被引用的对象本身是可以修改的。
-
-```java
-final int x = 1;
-// x = 2; // cannot assign value to final variable 'x'
-final A y = new A();
-y.a = 1;
-```
-
-**2. 方法**
-
-声明方法不能被子类重写。
-
-private 方法隐式地被指定为 final,如果在子类中定义的方法和基类中的一个 private 方法签名相同,此时子类的方法不是重写基类方法,而是在子类中定义了一个新的方法。
-
-**3. 类**
-
-声明类不允许被继承。
-
-## static
-
-**1. 静态变量**
-
-- 静态变量:又称为类变量,也就是说这个变量属于类的,类所有的实例都共享静态变量,可以直接通过类名来访问它。静态变量在内存中只存在一份。
-- 实例变量:每创建一个实例就会产生一个实例变量,它与该实例同生共死。
-
-```java
-public class A {
-
- private int x; // 实例变量
- private static int y; // 静态变量
-
- public static void main(String[] args) {
- // int x = A.x; // Non-static field 'x' cannot be referenced from a static context
- A a = new A();
- int x = a.x;
- int y = A.y;
- }
-}
-```
-
-**2. 静态方法**
-
-静态方法在类加载的时候就存在了,它不依赖于任何实例。所以静态方法必须有实现,也就是说它不能是抽象方法。
-
-```java
-public abstract class A {
- public static void func1(){
- }
- // public abstract static void func2(); // Illegal combination of modifiers: 'abstract' and 'static'
-}
-```
-
-只能访问所属类的静态字段和静态方法,方法中不能有 this 和 super 关键字,因此这两个关键字与具体对象关联。
-
-```java
-public class A {
-
- private static int x;
- private int y;
-
- public static void func1(){
- int a = x;
- // int b = y; // Non-static field 'y' cannot be referenced from a static context
- // int b = this.y; // 'A.this' cannot be referenced from a static context
- }
-}
-```
-
-**3. 静态语句块**
-
-静态语句块在类初始化时运行一次。
-
-```java
-public class A {
- static {
- System.out.println("123");
- }
-
- public static void main(String[] args) {
- A a1 = new A();
- A a2 = new A();
- }
-}
-```
-
-```html
-123
-```
-
-**4. 静态内部类**
-
-非静态内部类依赖于外部类的实例,也就是说需要先创建外部类实例,才能用这个实例去创建非静态内部类。而静态内部类不需要。
-
-```java
-public class OuterClass {
-
- class InnerClass {
- }
-
- static class StaticInnerClass {
- }
-
- public static void main(String[] args) {
- // InnerClass innerClass = new InnerClass(); // 'OuterClass.this' cannot be referenced from a static context
- OuterClass outerClass = new OuterClass();
- InnerClass innerClass = outerClass.new InnerClass();
- StaticInnerClass staticInnerClass = new StaticInnerClass();
- }
-}
-```
-
-静态内部类不能访问外部类的非静态的变量和方法。
-
-**5. 静态导包**
-
-在使用静态变量和方法时不用再指明 ClassName,从而简化代码,但可读性大大降低。
-
-```java
-import static com.xxx.ClassName.*
-```
-
-**6. 初始化顺序**
-
-静态变量和静态语句块优先于实例变量和普通语句块,静态变量和静态语句块的初始化顺序取决于它们在代码中的顺序。
-
-```java
-public static String staticField = "静态变量";
-```
-
-```java
-static {
- System.out.println("静态语句块");
-}
-```
-
-```java
-public String field = "实例变量";
-```
-
-```java
-{
- System.out.println("普通语句块");
-}
-```
-
-最后才是构造函数的初始化。
-
-```java
-public InitialOrderTest() {
- System.out.println("构造函数");
-}
-```
-
-存在继承的情况下,初始化顺序为:
-
-- 父类(静态变量、静态语句块)
-- 子类(静态变量、静态语句块)
-- 父类(实例变量、普通语句块)
-- 父类(构造函数)
-- 子类(实例变量、普通语句块)
-- 子类(构造函数)
-
-# 五、Object 通用方法
-
-## 概览
-
-```java
-
-public native int hashCode()
-
-public boolean equals(Object obj)
-
-protected native Object clone() throws CloneNotSupportedException
-
-public String toString()
-
-public final native Class getClass()
-
-protected void finalize() throws Throwable {}
-
-public final native void notify()
-
-public final native void notifyAll()
-
-public final native void wait(long timeout) throws InterruptedException
-
-public final void wait(long timeout, int nanos) throws InterruptedException
-
-public final void wait() throws InterruptedException
-```
-
-## equals()
-
-**1. 等价关系**
-
-两个对象具有等价关系,需要满足以下五个条件:
-
-Ⅰ 自反性
-
-```java
-x.equals(x); // true
-```
-
-Ⅱ 对称性
-
-```java
-x.equals(y) == y.equals(x); // true
-```
-
-Ⅲ 传递性
-
-```java
-if (x.equals(y) && y.equals(z))
- x.equals(z); // true;
-```
-
-Ⅳ 一致性
-
-多次调用 equals() 方法结果不变
-
-```java
-x.equals(y) == x.equals(y); // true
-```
-
-Ⅴ 与 null 的比较
-
-对任何不是 null 的对象 x 调用 x.equals(null) 结果都为 false
-
-```java
-x.equals(null); // false;
-```
-
-**2. 等价与相等**
-
-- 对于基本类型,== 判断两个值是否相等,基本类型没有 equals() 方法。
-- 对于引用类型,== 判断两个变量是否引用同一个对象,而 equals() 判断引用的对象是否等价。
-
-```java
-Integer x = new Integer(1);
-Integer y = new Integer(1);
-System.out.println(x.equals(y)); // true
-System.out.println(x == y); // false
-```
-
-**3. 实现**
-
-- 检查是否为同一个对象的引用,如果是直接返回 true;
-- 检查是否是同一个类型,如果不是,直接返回 false;
-- 将 Object 对象进行转型;
-- 判断每个关键域是否相等。
-
-```java
-public class EqualExample {
-
- private int x;
- private int y;
- private int z;
-
- public EqualExample(int x, int y, int z) {
- this.x = x;
- this.y = y;
- this.z = z;
- }
-
- @Override
- public boolean equals(Object o) {
- if (this == o) return true;
- if (o == null || getClass() != o.getClass()) return false;
-
- EqualExample that = (EqualExample) o;
-
- if (x != that.x) return false;
- if (y != that.y) return false;
- return z == that.z;
- }
-}
-```
-
-## hashCode()
-
-hashCode() 返回哈希值,而 equals() 是用来判断两个对象是否等价。等价的两个对象散列值一定相同,但是散列值相同的两个对象不一定等价,这是因为计算哈希值具有随机性,两个值不同的对象可能计算出相同的哈希值。
-
-在覆盖 equals() 方法时应当总是覆盖 hashCode() 方法,保证等价的两个对象哈希值也相等。
-
-HashSet 和 HashMap 等集合类使用了 hashCode() 方法来计算对象应该存储的位置,因此要将对象添加到这些集合类中,需要让对应的类实现 hashCode() 方法。
-
-下面的代码中,新建了两个等价的对象,并将它们添加到 HashSet 中。我们希望将这两个对象当成一样的,只在集合中添加一个对象。但是 EqualExample 没有实现 hashCode() 方法,因此这两个对象的哈希值是不同的,最终导致集合添加了两个等价的对象。
-
-```java
-EqualExample e1 = new EqualExample(1, 1, 1);
-EqualExample e2 = new EqualExample(1, 1, 1);
-System.out.println(e1.equals(e2)); // true
-HashSet set = new HashSet<>();
-set.add(e1);
-set.add(e2);
-System.out.println(set.size()); // 2
-```
-
-理想的哈希函数应当具有均匀性,即不相等的对象应当均匀分布到所有可能的哈希值上。这就要求了哈希函数要把所有域的值都考虑进来。可以将每个域都当成 R 进制的某一位,然后组成一个 R 进制的整数。
-
-R 一般取 31,因为它是一个奇素数,如果是偶数的话,当出现乘法溢出,信息就会丢失,因为与 2 相乘相当于向左移一位,最左边的位丢失。并且一个数与 31 相乘可以转换成移位和减法:`31*x == (x<<5)-x`,编译器会自动进行这个优化。
-
-```java
-@Override
-public int hashCode() {
- int result = 17;
- result = 31 * result + x;
- result = 31 * result + y;
- result = 31 * result + z;
- return result;
-}
-```
-
-## toString()
-
-默认返回 ToStringExample@4554617c 这种形式,其中 @ 后面的数值为散列码的无符号十六进制表示。
-
-```java
-public class ToStringExample {
-
- private int number;
-
- public ToStringExample(int number) {
- this.number = number;
- }
-}
-```
-
-```java
-ToStringExample example = new ToStringExample(123);
-System.out.println(example.toString());
-```
-
-```html
-ToStringExample@4554617c
-```
-
-## clone()
-
-**1. cloneable**
-
-clone() 是 Object 的 protected 方法,它不是 public,一个类不显式去重写 clone(),其它类就不能直接去调用该类实例的 clone() 方法。
-
-```java
-public class CloneExample {
- private int a;
- private int b;
-}
-```
-
-```java
-CloneExample e1 = new CloneExample();
-// CloneExample e2 = e1.clone(); // 'clone()' has protected access in 'java.lang.Object'
-```
-
-重写 clone() 得到以下实现:
-
-```java
-public class CloneExample {
- private int a;
- private int b;
-
- @Override
- public CloneExample clone() throws CloneNotSupportedException {
- return (CloneExample)super.clone();
- }
-}
-```
-
-```java
-CloneExample e1 = new CloneExample();
-try {
- CloneExample e2 = e1.clone();
-} catch (CloneNotSupportedException e) {
- e.printStackTrace();
-}
-```
-
-```html
-java.lang.CloneNotSupportedException: CloneExample
-```
-
-以上抛出了 CloneNotSupportedException,这是因为 CloneExample 没有实现 Cloneable 接口。
-
-应该注意的是,clone() 方法并不是 Cloneable 接口的方法,而是 Object 的一个 protected 方法。Cloneable 接口只是规定,如果一个类没有实现 Cloneable 接口又调用了 clone() 方法,就会抛出 CloneNotSupportedException。
-
-```java
-public class CloneExample implements Cloneable {
- private int a;
- private int b;
-
- @Override
- public Object clone() throws CloneNotSupportedException {
- return super.clone();
- }
-}
-```
-
-**2. 浅拷贝**
-
-拷贝对象和原始对象的引用类型引用同一个对象。
-
-```java
-public class ShallowCloneExample implements Cloneable {
-
- private int[] arr;
-
- public ShallowCloneExample() {
- arr = new int[10];
- for (int i = 0; i < arr.length; i++) {
- arr[i] = i;
- }
- }
-
- public void set(int index, int value) {
- arr[index] = value;
- }
-
- public int get(int index) {
- return arr[index];
- }
-
- @Override
- protected ShallowCloneExample clone() throws CloneNotSupportedException {
- return (ShallowCloneExample) super.clone();
- }
-}
-```
-
-```java
-ShallowCloneExample e1 = new ShallowCloneExample();
-ShallowCloneExample e2 = null;
-try {
- e2 = e1.clone();
-} catch (CloneNotSupportedException e) {
- e.printStackTrace();
-}
-e1.set(2, 222);
-System.out.println(e2.get(2)); // 222
-```
-
-**3. 深拷贝**
-
-拷贝对象和原始对象的引用类型引用不同对象。
-
-```java
-public class DeepCloneExample implements Cloneable {
-
- private int[] arr;
-
- public DeepCloneExample() {
- arr = new int[10];
- for (int i = 0; i < arr.length; i++) {
- arr[i] = i;
- }
- }
-
- public void set(int index, int value) {
- arr[index] = value;
- }
-
- public int get(int index) {
- return arr[index];
- }
-
- @Override
- protected DeepCloneExample clone() throws CloneNotSupportedException {
- DeepCloneExample result = (DeepCloneExample) super.clone();
- result.arr = new int[arr.length];
- for (int i = 0; i < arr.length; i++) {
- result.arr[i] = arr[i];
- }
- return result;
- }
-}
-```
-
-```java
-DeepCloneExample e1 = new DeepCloneExample();
-DeepCloneExample e2 = null;
-try {
- e2 = e1.clone();
-} catch (CloneNotSupportedException e) {
- e.printStackTrace();
-}
-e1.set(2, 222);
-System.out.println(e2.get(2)); // 2
-```
-
-**4. clone() 的替代方案**
-
-使用 clone() 方法来拷贝一个对象即复杂又有风险,它会抛出异常,并且还需要类型转换。Effective Java 书上讲到,最好不要去使用 clone(),可以使用拷贝构造函数或者拷贝工厂来拷贝一个对象。
-
-```java
-public class CloneConstructorExample {
-
- private int[] arr;
-
- public CloneConstructorExample() {
- arr = new int[10];
- for (int i = 0; i < arr.length; i++) {
- arr[i] = i;
- }
- }
-
- public CloneConstructorExample(CloneConstructorExample original) {
- arr = new int[original.arr.length];
- for (int i = 0; i < original.arr.length; i++) {
- arr[i] = original.arr[i];
- }
- }
-
- public void set(int index, int value) {
- arr[index] = value;
- }
-
- public int get(int index) {
- return arr[index];
- }
-}
-```
-
-```java
-CloneConstructorExample e1 = new CloneConstructorExample();
-CloneConstructorExample e2 = new CloneConstructorExample(e1);
-e1.set(2, 222);
-System.out.println(e2.get(2)); // 2
-```
-
-# 六、继承
-
-## 访问权限
-
-Java 中有三个访问权限修饰符:private、protected 以及 public,如果不加访问修饰符,表示包级可见。
-
-可以对类或类中的成员(字段和方法)加上访问修饰符。
-
-- 类可见表示其它类可以用这个类创建实例对象。
-- 成员可见表示其它类可以用这个类的实例对象访问到该成员;
-
-protected 用于修饰成员,表示在继承体系中成员对于子类可见,但是这个访问修饰符对于类没有意义。
-
-设计良好的模块会隐藏所有的实现细节,把它的 API 与它的实现清晰地隔离开来。模块之间只通过它们的 API 进行通信,一个模块不需要知道其他模块的内部工作情况,这个概念被称为信息隐藏或封装。因此访问权限应当尽可能地使每个类或者成员不被外界访问。
-
-如果子类的方法重写了父类的方法,那么子类中该方法的访问级别不允许低于父类的访问级别。这是为了确保可以使用父类实例的地方都可以使用子类实例去代替,也就是确保满足里氏替换原则。
-
-字段决不能是公有的,因为这么做的话就失去了对这个字段修改行为的控制,客户端可以对其随意修改。例如下面的例子中,AccessExample 拥有 id 公有字段,如果在某个时刻,我们想要使用 int 存储 id 字段,那么就需要修改所有的客户端代码。
-
-```java
-public class AccessExample {
- public String id;
-}
-```
-
-可以使用公有的 getter 和 setter 方法来替换公有字段,这样的话就可以控制对字段的修改行为。
-
-```java
-public class AccessExample {
-
- private int id;
-
- public String getId() {
- return id + "";
- }
-
- public void setId(String id) {
- this.id = Integer.valueOf(id);
- }
-}
-```
-
-但是也有例外,如果是包级私有的类或者私有的嵌套类,那么直接暴露成员不会有特别大的影响。
-
-```java
-public class AccessWithInnerClassExample {
-
- private class InnerClass {
- int x;
- }
-
- private InnerClass innerClass;
-
- public AccessWithInnerClassExample() {
- innerClass = new InnerClass();
- }
-
- public int getValue() {
- return innerClass.x; // 直接访问
- }
-}
-```
-
-## 抽象类与接口
-
-**1. 抽象类**
-
-抽象类和抽象方法都使用 abstract 关键字进行声明。如果一个类中包含抽象方法,那么这个类必须声明为抽象类。
-
-抽象类和普通类最大的区别是,抽象类不能被实例化,只能被继承。
-
-```java
-public abstract class AbstractClassExample {
-
- protected int x;
- private int y;
-
- public abstract void func1();
-
- public void func2() {
- System.out.println("func2");
- }
-}
-```
-
-```java
-public class AbstractExtendClassExample extends AbstractClassExample {
- @Override
- public void func1() {
- System.out.println("func1");
- }
-}
-```
-
-```java
-// AbstractClassExample ac1 = new AbstractClassExample(); // 'AbstractClassExample' is abstract; cannot be instantiated
-AbstractClassExample ac2 = new AbstractExtendClassExample();
-ac2.func1();
-```
-
-**2. 接口**
-
-接口是抽象类的延伸,在 Java 8 之前,它可以看成是一个完全抽象的类,也就是说它不能有任何的方法实现。
-
-从 Java 8 开始,接口也可以拥有默认的方法实现,这是因为不支持默认方法的接口的维护成本太高了。在 Java 8 之前,如果一个接口想要添加新的方法,那么要修改所有实现了该接口的类,让它们都实现新增的方法。
-
-接口的成员(字段 + 方法)默认都是 public 的,并且不允许定义为 private 或者 protected。从 Java 9 开始,允许将方法定义为 private,这样就能定义某些复用的代码又不会把方法暴露出去。
-
-接口的字段默认都是 static 和 final 的。
-
-```java
-public interface InterfaceExample {
-
- void func1();
-
- default void func2(){
- System.out.println("func2");
- }
-
- int x = 123;
- // int y; // Variable 'y' might not have been initialized
- public int z = 0; // Modifier 'public' is redundant for interface fields
- // private int k = 0; // Modifier 'private' not allowed here
- // protected int l = 0; // Modifier 'protected' not allowed here
- // private void fun3(); // Modifier 'private' not allowed here
-}
-```
-
-```java
-public class InterfaceImplementExample implements InterfaceExample {
- @Override
- public void func1() {
- System.out.println("func1");
- }
-}
-```
-
-```java
-// InterfaceExample ie1 = new InterfaceExample(); // 'InterfaceExample' is abstract; cannot be instantiated
-InterfaceExample ie2 = new InterfaceImplementExample();
-ie2.func1();
-System.out.println(InterfaceExample.x);
-```
-
-**3. 比较**
-
-- 从设计层面上看,抽象类提供了一种 IS-A 关系,需要满足里式替换原则,即子类对象必须能够替换掉所有父类对象。而接口更像是一种 LIKE-A 关系,它只是提供一种方法实现契约,并不要求接口和实现接口的类具有 IS-A 关系。
-- 从使用上来看,一个类可以实现多个接口,但是不能继承多个抽象类。
-- 接口的字段只能是 static 和 final 类型的,而抽象类的字段没有这种限制。
-- 接口的成员只能是 public 的,而抽象类的成员可以有多种访问权限。
-
-**4. 使用选择**
-
-使用接口:
-
-- 需要让不相关的类都实现一个方法,例如不相关的类都可以实现 Comparable 接口中的 compareTo() 方法;
-- 需要使用多重继承。
-
-使用抽象类:
-
-- 需要在几个相关的类中共享代码。
-- 需要能控制继承来的成员的访问权限,而不是都为 public。
-- 需要继承非静态和非常量字段。
-
-在很多情况下,接口优先于抽象类。因为接口没有抽象类严格的类层次结构要求,可以灵活地为一个类添加行为。并且从 Java 8 开始,接口也可以有默认的方法实现,使得修改接口的成本也变的很低。
-
-- [Abstract Methods and Classes](https://docs.oracle.com/javase/tutorial/java/IandI/abstract.html)
-- [深入理解 abstract class 和 interface](https://www.ibm.com/developerworks/cn/java/l-javainterface-abstract/)
-- [When to Use Abstract Class and Interface](https://dzone.com/articles/when-to-use-abstract-class-and-intreface)
-- [Java 9 Private Methods in Interfaces](https://www.journaldev.com/12850/java-9-private-methods-interfaces)
-
-
-## super
-
-- 访问父类的构造函数:可以使用 super() 函数访问父类的构造函数,从而委托父类完成一些初始化的工作。应该注意到,子类一定会调用父类的构造函数来完成初始化工作,一般是调用父类的默认构造函数,如果子类需要调用父类其它构造函数,那么就可以使用 super() 函数。
-- 访问父类的成员:如果子类重写了父类的某个方法,可以通过使用 super 关键字来引用父类的方法实现。
-
-```java
-public class SuperExample {
-
- protected int x;
- protected int y;
-
- public SuperExample(int x, int y) {
- this.x = x;
- this.y = y;
- }
-
- public void func() {
- System.out.println("SuperExample.func()");
- }
-}
-```
-
-```java
-public class SuperExtendExample extends SuperExample {
-
- private int z;
-
- public SuperExtendExample(int x, int y, int z) {
- super(x, y);
- this.z = z;
- }
-
- @Override
- public void func() {
- super.func();
- System.out.println("SuperExtendExample.func()");
- }
-}
-```
-
-```java
-SuperExample e = new SuperExtendExample(1, 2, 3);
-e.func();
-```
-
-```html
-SuperExample.func()
-SuperExtendExample.func()
-```
-
-[Using the Keyword super](https://docs.oracle.com/javase/tutorial/java/IandI/super.html)
-
-## 重写与重载
-
-**1. 重写(Override)**
-
-存在于继承体系中,指子类实现了一个与父类在方法声明上完全相同的一个方法。
-
-为了满足里式替换原则,重写有以下三个限制:
-
-- 子类方法的访问权限必须大于等于父类方法;
-- 子类方法的返回类型必须是父类方法返回类型或为其子类型。
-- 子类方法抛出的异常类型必须是父类抛出异常类型或为其子类型。
-
-使用 @Override 注解,可以让编译器帮忙检查是否满足上面的三个限制条件。
-
-下面的示例中,SubClass 为 SuperClass 的子类,SubClass 重写了 SuperClass 的 func() 方法。其中:
-
-- 子类方法访问权限为 public,大于父类的 protected。
-- 子类的返回类型为 ArrayList,是父类返回类型 List 的子类。
-- 子类抛出的异常类型为 Exception,是父类抛出异常 Throwable 的子类。
-- 子类重写方法使用 @Override 注解,从而让编译器自动检查是否满足限制条件。
-
-```java
-class SuperClass {
- protected List func() throws Throwable {
- return new ArrayList<>();
- }
-}
-
-class SubClass extends SuperClass {
- @Override
- public ArrayList func() throws Exception {
- return new ArrayList<>();
- }
-}
-```
-
-在调用一个方法时,先从本类中查找看是否有对应的方法,如果没有再到父类中查看,看是否从父类继承来。否则就要对参数进行转型,转成父类之后看是否有对应的方法。总的来说,方法调用的优先级为:
-
-- this.func(this)
-- super.func(this)
-- this.func(super)
-- super.func(super)
-
-
-```java
-/*
- A
- |
- B
- |
- C
- |
- D
- */
-
-
-class A {
-
- public void show(A obj) {
- System.out.println("A.show(A)");
- }
-
- public void show(C obj) {
- System.out.println("A.show(C)");
- }
-}
-
-class B extends A {
-
- @Override
- public void show(A obj) {
- System.out.println("B.show(A)");
- }
-}
-
-class C extends B {
-}
-
-class D extends C {
-}
-```
-
-```java
-public static void main(String[] args) {
-
- A a = new A();
- B b = new B();
- C c = new C();
- D d = new D();
-
- // 在 A 中存在 show(A obj),直接调用
- a.show(a); // A.show(A)
- // 在 A 中不存在 show(B obj),将 B 转型成其父类 A
- a.show(b); // A.show(A)
- // 在 B 中存在从 A 继承来的 show(C obj),直接调用
- b.show(c); // A.show(C)
- // 在 B 中不存在 show(D obj),但是存在从 A 继承来的 show(C obj),将 D 转型成其父类 C
- b.show(d); // A.show(C)
-
- // 引用的还是 B 对象,所以 ba 和 b 的调用结果一样
- A ba = new B();
- ba.show(c); // A.show(C)
- ba.show(d); // A.show(C)
-}
-```
-
-**2. 重载(Overload)**
-
-存在于同一个类中,指一个方法与已经存在的方法名称上相同,但是参数类型、个数、顺序至少有一个不同。
-
-应该注意的是,返回值不同,其它都相同不算是重载。
-
-```java
-class OverloadingExample {
- public void show(int x) {
- System.out.println(x);
- }
-
- public void show(int x, String y) {
- System.out.println(x + " " + y);
- }
-}
-```
-
-```java
-public static void main(String[] args) {
- OverloadingExample example = new OverloadingExample();
- example.show(1);
- example.show(1, "2");
-}
-```
-
-# 七、反射
-
-每个类都有一个 **Class** 对象,包含了与类有关的信息。当编译一个新类时,会产生一个同名的 .class 文件,该文件内容保存着 Class 对象。
-
-类加载相当于 Class 对象的加载,类在第一次使用时才动态加载到 JVM 中。也可以使用 `Class.forName("com.mysql.jdbc.Driver")` 这种方式来控制类的加载,该方法会返回一个 Class 对象。
-
-反射可以提供运行时的类信息,并且这个类可以在运行时才加载进来,甚至在编译时期该类的 .class 不存在也可以加载进来。
-
-Class 和 java.lang.reflect 一起对反射提供了支持,java.lang.reflect 类库主要包含了以下三个类:
-
-- **Field** :可以使用 get() 和 set() 方法读取和修改 Field 对象关联的字段;
-- **Method** :可以使用 invoke() 方法调用与 Method 对象关联的方法;
-- **Constructor** :可以用 Constructor 的 newInstance() 创建新的对象。
-
-**反射的优点:**
-
-* **可扩展性** :应用程序可以利用全限定名创建可扩展对象的实例,来使用来自外部的用户自定义类。
-* **类浏览器和可视化开发环境** :一个类浏览器需要可以枚举类的成员。可视化开发环境(如 IDE)可以从利用反射中可用的类型信息中受益,以帮助程序员编写正确的代码。
-* **调试器和测试工具** : 调试器需要能够检查一个类里的私有成员。测试工具可以利用反射来自动地调用类里定义的可被发现的 API 定义,以确保一组测试中有较高的代码覆盖率。
-
-**反射的缺点:**
-
-尽管反射非常强大,但也不能滥用。如果一个功能可以不用反射完成,那么最好就不用。在我们使用反射技术时,下面几条内容应该牢记于心。
-
-* **性能开销** :反射涉及了动态类型的解析,所以 JVM 无法对这些代码进行优化。因此,反射操作的效率要比那些非反射操作低得多。我们应该避免在经常被执行的代码或对性能要求很高的程序中使用反射。
-
-* **安全限制** :使用反射技术要求程序必须在一个没有安全限制的环境中运行。如果一个程序必须在有安全限制的环境中运行,如 Applet,那么这就是个问题了。
-
-* **内部暴露** :由于反射允许代码执行一些在正常情况下不被允许的操作(比如访问私有的属性和方法),所以使用反射可能会导致意料之外的副作用,这可能导致代码功能失调并破坏可移植性。反射代码破坏了抽象性,因此当平台发生改变的时候,代码的行为就有可能也随着变化。
-
-
-- [Trail: The Reflection API](https://docs.oracle.com/javase/tutorial/reflect/index.html)
-- [深入解析 Java 反射(1)- 基础](http://www.sczyh30.com/posts/Java/java-reflection-1/)
-
-# 八、异常
-
-Throwable 可以用来表示任何可以作为异常抛出的类,分为两种: **Error** 和 **Exception**。其中 Error 用来表示 JVM 无法处理的错误,Exception 分为两种:
-
-- **受检异常** :需要用 try...catch... 语句捕获并进行处理,并且可以从异常中恢复;
-- **非受检异常** :是程序运行时错误,例如除 0 会引发 Arithmetic Exception,此时程序崩溃并且无法恢复。
-
- 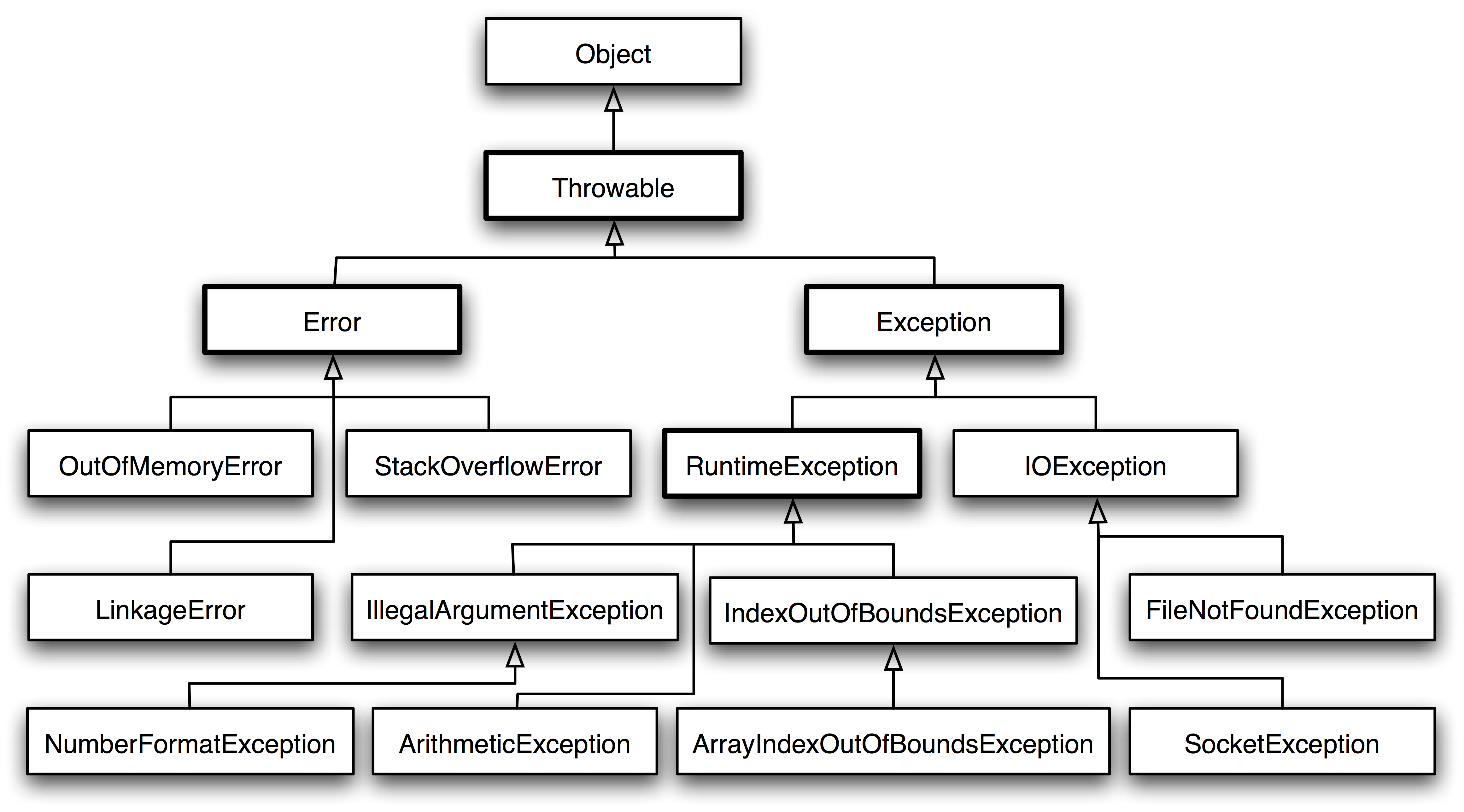
-
-- [Java 入门之异常处理](https://www.cnblogs.com/Blue-Keroro/p/8875898.html)
-- [Java Exception Interview Questions and Answers](https://www.journaldev.com/2167/java-exception-interview-questions-and-answersl)
-
-# 九、泛型
-
-```java
-public class Box {
- // T stands for "Type"
- private T t;
- public void set(T t) { this.t = t; }
- public T get() { return t; }
-}
-```
-
-- [Java 泛型详解](http://www.importnew.com/24029.html)
-- [10 道 Java 泛型面试题](https://cloud.tencent.com/developer/article/1033693)
-
-# 十、注解
-
-Java 注解是附加在代码中的一些元信息,用于一些工具在编译、运行时进行解析和使用,起到说明、配置的功能。注解不会也不能影响代码的实际逻辑,仅仅起到辅助性的作用。
-
-[注解 Annotation 实现原理与自定义注解例子](https://www.cnblogs.com/acm-bingzi/p/javaAnnotation.html)
-
-# 十一、特性
-
-## Java 各版本的新特性
-
-**New highlights in Java SE 8**
-
-1. Lambda Expressions
-2. Pipelines and Streams
-3. Date and Time API
-4. Default Methods
-5. Type Annotations
-6. Nashhorn JavaScript Engine
-7. Concurrent Accumulators
-8. Parallel operations
-9. PermGen Error Removed
-
-**New highlights in Java SE 7**
-
-1. Strings in Switch Statement
-2. Type Inference for Generic Instance Creation
-3. Multiple Exception Handling
-4. Support for Dynamic Languages
-5. Try with Resources
-6. Java nio Package
-7. Binary Literals, Underscore in literals
-8. Diamond Syntax
-
-- [Difference between Java 1.8 and Java 1.7?](http://www.selfgrowth.com/articles/difference-between-java-18-and-java-17)
-- [Java 8 特性](http://www.importnew.com/19345.html)
-
-## Java 与 C++ 的区别
-
-- Java 是纯粹的面向对象语言,所有的对象都继承自 java.lang.Object,C++ 为了兼容 C 即支持面向对象也支持面向过程。
-- Java 通过虚拟机从而实现跨平台特性,但是 C++ 依赖于特定的平台。
-- Java 没有指针,它的引用可以理解为安全指针,而 C++ 具有和 C 一样的指针。
-- Java 支持自动垃圾回收,而 C++ 需要手动回收。
-- Java 不支持多重继承,只能通过实现多个接口来达到相同目的,而 C++ 支持多重继承。
-- Java 不支持操作符重载,虽然可以对两个 String 对象执行加法运算,但是这是语言内置支持的操作,不属于操作符重载,而 C++ 可以。
-- Java 的 goto 是保留字,但是不可用,C++ 可以使用 goto。
-
-[What are the main differences between Java and C++?](http://cs-fundamentals.com/tech-interview/java/differences-between-java-and-cpp.php)
-
-## JRE or JDK
-
-- JRE:Java Runtime Environment,Java 运行环境的简称,为 Java 的运行提供了所需的环境。它是一个 JVM 程序,主要包括了 JVM 的标准实现和一些 Java 基本类库。
-- JDK:Java Development Kit,Java 开发工具包,提供了 Java 的开发及运行环境。JDK 是 Java 开发的核心,集成了 JRE 以及一些其它的工具,比如编译 Java 源码的编译器 javac 等。
-
-# 参考资料
-
-- Eckel B. Java 编程思想[M]. 机械工业出版社, 2002.
-- Bloch J. Effective java[M]. Addison-Wesley Professional, 2017.
-
-
-
-
-
-
- 
-
-### 1. Set
-
-- TreeSet:基于红黑树实现,支持有序性操作,例如根据一个范围查找元素的操作。但是查找效率不如 HashSet,HashSet 查找的时间复杂度为 O(1),TreeSet 则为 O(logN)。
-
-- HashSet:基于哈希表实现,支持快速查找,但不支持有序性操作。并且失去了元素的插入顺序信息,也就是说使用 Iterator 遍历 HashSet 得到的结果是不确定的。
-
-- LinkedHashSet:具有 HashSet 的查找效率,并且内部使用双向链表维护元素的插入顺序。
-
-### 2. List
-
-- ArrayList:基于动态数组实现,支持随机访问。
-
-- Vector:和 ArrayList 类似,但它是线程安全的。
-
-- LinkedList:基于双向链表实现,只能顺序访问,但是可以快速地在链表中间插入和删除元素。不仅如此,LinkedList 还可以用作栈、队列和双向队列。
-
-### 3. Queue
-
-- LinkedList:可以用它来实现双向队列。
-
-- PriorityQueue:基于堆结构实现,可以用它来实现优先队列。
-
-## Map
-
- 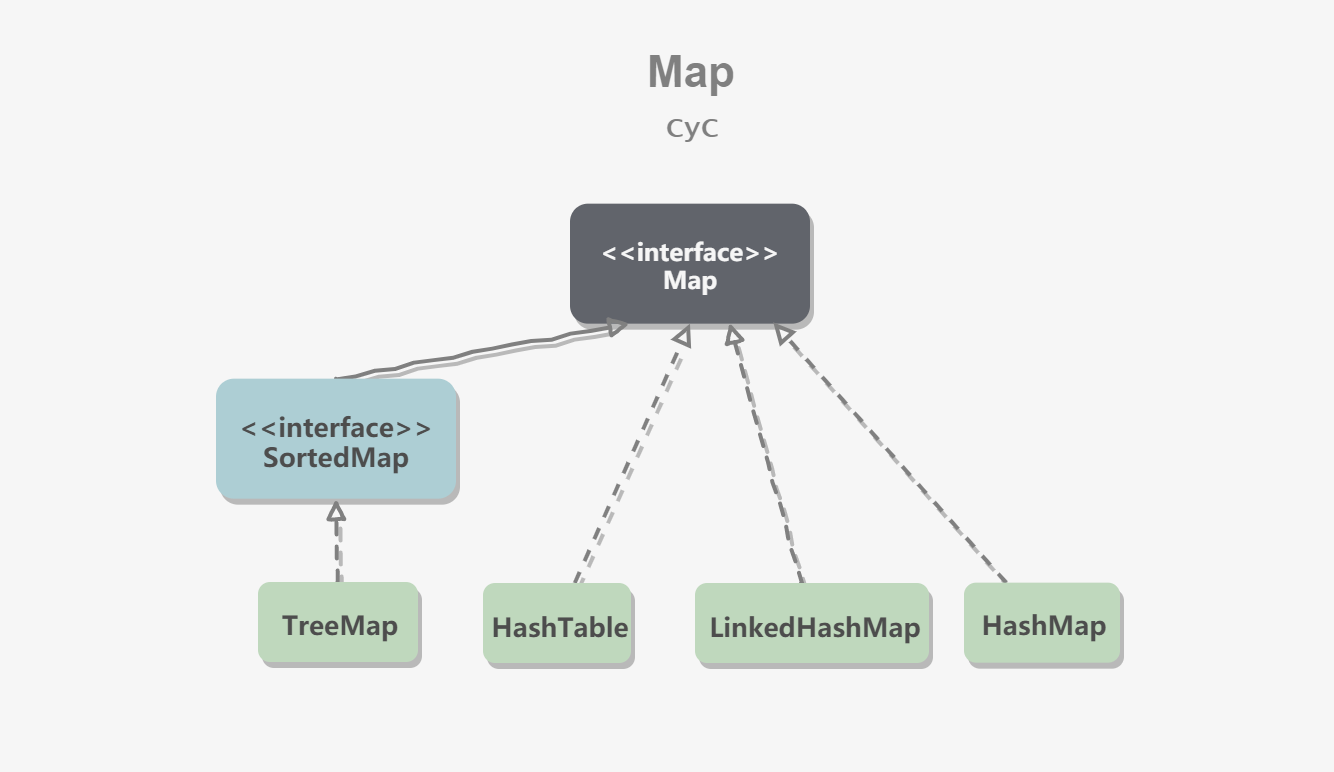
-
-- TreeMap:基于红黑树实现。
-
-- HashMap:基于哈希表实现。
-
-- HashTable:和 HashMap 类似,但它是线程安全的,这意味着同一时刻多个线程同时写入 HashTable 不会导致数据不一致。它是遗留类,不应该去使用它,而是使用 ConcurrentHashMap 来支持线程安全,ConcurrentHashMap 的效率会更高,因为 ConcurrentHashMap 引入了分段锁。
-
-- LinkedHashMap:使用双向链表来维护元素的顺序,顺序为插入顺序或者最近最少使用(LRU)顺序。
-
-
-# 二、容器中的设计模式
-
-## 迭代器模式
-
- 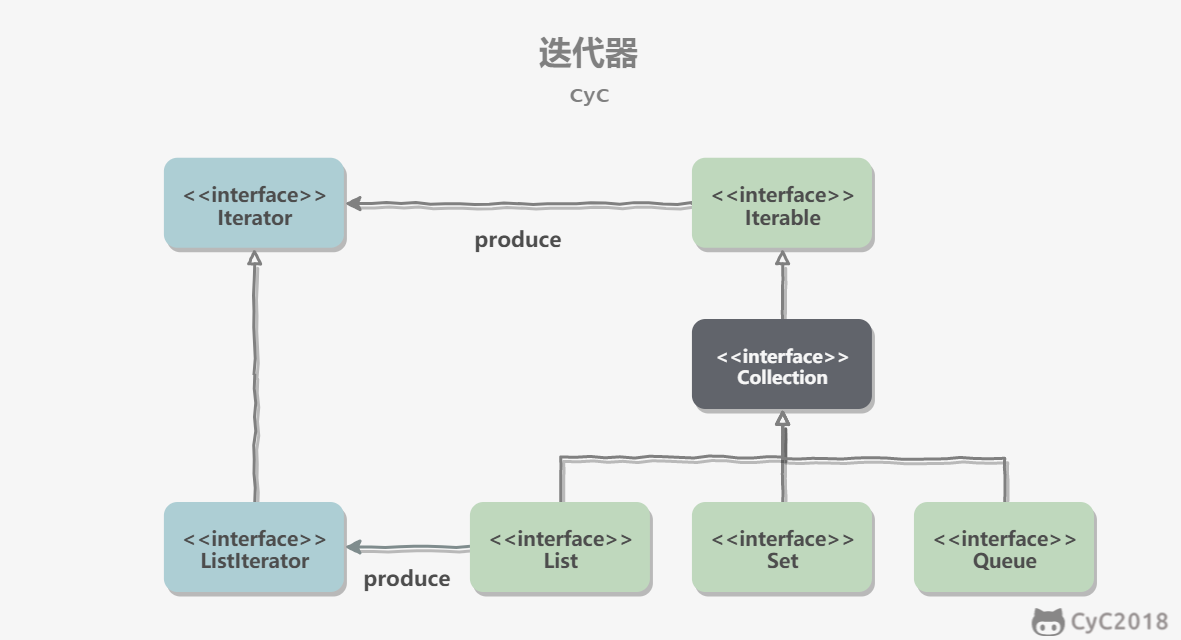
-
-Collection 继承了 Iterable 接口,其中的 iterator() 方法能够产生一个 Iterator 对象,通过这个对象就可以迭代遍历 Collection 中的元素。
-
-从 JDK 1.5 之后可以使用 foreach 方法来遍历实现了 Iterable 接口的聚合对象。
-
-```java
-List list = new ArrayList<>();
-list.add("a");
-list.add("b");
-for (String item : list) {
- System.out.println(item);
-}
-```
-
-## 适配器模式
-
-java.util.Arrays#asList() 可以把数组类型转换为 List 类型。
-
-```java
-@SafeVarargs
-public static List asList(T... a)
-```
-
-应该注意的是 asList() 的参数为泛型的变长参数,不能使用基本类型数组作为参数,只能使用相应的包装类型数组。
-
-```java
-Integer[] arr = {1, 2, 3};
-List list = Arrays.asList(arr);
-```
-
-也可以使用以下方式调用 asList():
-
-```java
-List list = Arrays.asList(1, 2, 3);
-```
-
-# 三、源码分析
-
-如果没有特别说明,以下源码分析基于 JDK 1.8。
-
-在 IDEA 中 double shift 调出 Search EveryWhere,查找源码文件,找到之后就可以阅读源码。
-
-## ArrayList
-
-
-### 1. 概览
-
-因为 ArrayList 是基于数组实现的,所以支持快速随机访问。RandomAccess 接口标识着该类支持快速随机访问。
-
-```java
-public class ArrayList extends AbstractList
- implements List, RandomAccess, Cloneable, java.io.Serializable
-```
-
-数组的默认大小为 10。
-
-```java
-private static final int DEFAULT_CAPACITY = 10;
-```
-
- 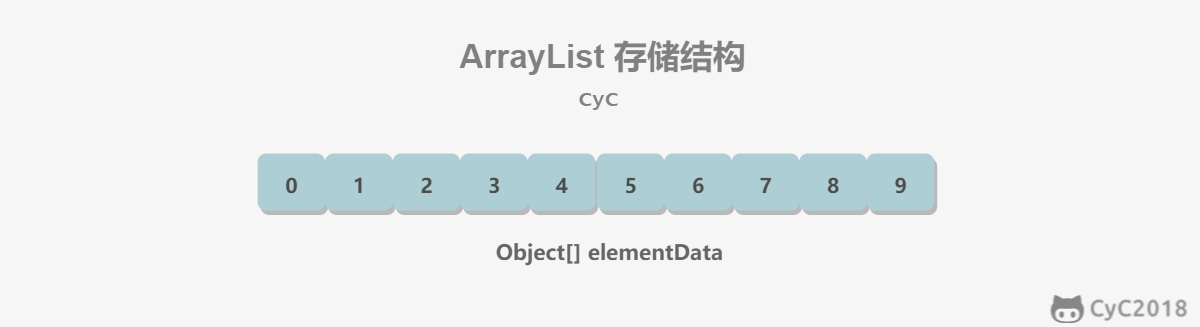
-
-### 2. 扩容
-
-添加元素时使用 ensureCapacityInternal() 方法来保证容量足够,如果不够时,需要使用 grow() 方法进行扩容,新容量的大小为 `oldCapacity + (oldCapacity >> 1)`,也就是旧容量的 1.5 倍。
-
-扩容操作需要调用 `Arrays.copyOf()` 把原数组整个复制到新数组中,这个操作代价很高,因此最好在创建 ArrayList 对象时就指定大概的容量大小,减少扩容操作的次数。
-
-```java
-public boolean add(E e) {
- ensureCapacityInternal(size + 1); // Increments modCount!!
- elementData[size++] = e;
- return true;
-}
-
-private void ensureCapacityInternal(int minCapacity) {
- if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
- minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
- }
- ensureExplicitCapacity(minCapacity);
-}
-
-private void ensureExplicitCapacity(int minCapacity) {
- modCount++;
- // overflow-conscious code
- if (minCapacity - elementData.length > 0)
- grow(minCapacity);
-}
-
-private void grow(int minCapacity) {
- // overflow-conscious code
- int oldCapacity = elementData.length;
- int newCapacity = oldCapacity + (oldCapacity >> 1);
- if (newCapacity - minCapacity < 0)
- newCapacity = minCapacity;
- if (newCapacity - MAX_ARRAY_SIZE > 0)
- newCapacity = hugeCapacity(minCapacity);
- // minCapacity is usually close to size, so this is a win:
- elementData = Arrays.copyOf(elementData, newCapacity);
-}
-```
-
-### 3. 删除元素
-
-需要调用 System.arraycopy() 将 index+1 后面的元素都复制到 index 位置上,该操作的时间复杂度为 O(N),可以看到 ArrayList 删除元素的代价是非常高的。
-
-```java
-public E remove(int index) {
- rangeCheck(index);
- modCount++;
- E oldValue = elementData(index);
- int numMoved = size - index - 1;
- if (numMoved > 0)
- System.arraycopy(elementData, index+1, elementData, index, numMoved);
- elementData[--size] = null; // clear to let GC do its work
- return oldValue;
-}
-```
-
-### 4. 序列化
-
-ArrayList 基于数组实现,并且具有动态扩容特性,因此保存元素的数组不一定都会被使用,那么就没必要全部进行序列化。
-
-保存元素的数组 elementData 使用 transient 修饰,该关键字声明数组默认不会被序列化。
-
-```java
-transient Object[] elementData; // non-private to simplify nested class access
-```
-
-ArrayList 实现了 writeObject() 和 readObject() 来控制只序列化数组中有元素填充那部分内容。
-
-```java
-private void readObject(java.io.ObjectInputStream s)
- throws java.io.IOException, ClassNotFoundException {
- elementData = EMPTY_ELEMENTDATA;
-
- // Read in size, and any hidden stuff
- s.defaultReadObject();
-
- // Read in capacity
- s.readInt(); // ignored
-
- if (size > 0) {
- // be like clone(), allocate array based upon size not capacity
- ensureCapacityInternal(size);
-
- Object[] a = elementData;
- // Read in all elements in the proper order.
- for (int i=0; i= elementCount)
- throw new ArrayIndexOutOfBoundsException(index);
-
- return elementData(index);
-}
-```
-
-### 2. 扩容
-
-Vector 的构造函数可以传入 capacityIncrement 参数,它的作用是在扩容时使容量 capacity 增长 capacityIncrement。如果这个参数的值小于等于 0,扩容时每次都令 capacity 为原来的两倍。
-
-```java
-public Vector(int initialCapacity, int capacityIncrement) {
- super();
- if (initialCapacity < 0)
- throw new IllegalArgumentException("Illegal Capacity: "+
- initialCapacity);
- this.elementData = new Object[initialCapacity];
- this.capacityIncrement = capacityIncrement;
-}
-```
-
-```java
-private void grow(int minCapacity) {
- // overflow-conscious code
- int oldCapacity = elementData.length;
- int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
- capacityIncrement : oldCapacity);
- if (newCapacity - minCapacity < 0)
- newCapacity = minCapacity;
- if (newCapacity - MAX_ARRAY_SIZE > 0)
- newCapacity = hugeCapacity(minCapacity);
- elementData = Arrays.copyOf(elementData, newCapacity);
-}
-```
-
-调用没有 capacityIncrement 的构造函数时,capacityIncrement 值被设置为 0,也就是说默认情况下 Vector 每次扩容时容量都会翻倍。
-
-```java
-public Vector(int initialCapacity) {
- this(initialCapacity, 0);
-}
-
-public Vector() {
- this(10);
-}
-```
-
-### 3. 与 ArrayList 的比较
-
-- Vector 是同步的,因此开销就比 ArrayList 要大,访问速度更慢。最好使用 ArrayList 而不是 Vector,因为同步操作完全可以由程序员自己来控制;
-- Vector 每次扩容请求其大小的 2 倍(也可以通过构造函数设置增长的容量),而 ArrayList 是 1.5 倍。
-
-### 4. 替代方案
-
-可以使用 `Collections.synchronizedList();` 得到一个线程安全的 ArrayList。
-
-```java
-List list = new ArrayList<>();
-List synList = Collections.synchronizedList(list);
-```
-
-也可以使用 concurrent 并发包下的 CopyOnWriteArrayList 类。
-
-```java
-List list = new CopyOnWriteArrayList<>();
-```
-
-## CopyOnWriteArrayList
-
-### 1. 读写分离
-
-写操作在一个复制的数组上进行,读操作还是在原始数组中进行,读写分离,互不影响。
-
-写操作需要加锁,防止并发写入时导致写入数据丢失。
-
-写操作结束之后需要把原始数组指向新的复制数组。
-
-```java
-public boolean add(E e) {
- final ReentrantLock lock = this.lock;
- lock.lock();
- try {
- Object[] elements = getArray();
- int len = elements.length;
- Object[] newElements = Arrays.copyOf(elements, len + 1);
- newElements[len] = e;
- setArray(newElements);
- return true;
- } finally {
- lock.unlock();
- }
-}
-
-final void setArray(Object[] a) {
- array = a;
-}
-```
-
-```java
-@SuppressWarnings("unchecked")
-private E get(Object[] a, int index) {
- return (E) a[index];
-}
-```
-
-### 2. 适用场景
-
-CopyOnWriteArrayList 在写操作的同时允许读操作,大大提高了读操作的性能,因此很适合读多写少的应用场景。
-
-但是 CopyOnWriteArrayList 有其缺陷:
-
-- 内存占用:在写操作时需要复制一个新的数组,使得内存占用为原来的两倍左右;
-- 数据不一致:读操作不能读取实时性的数据,因为部分写操作的数据还未同步到读数组中。
-
-所以 CopyOnWriteArrayList 不适合内存敏感以及对实时性要求很高的场景。
-
-## LinkedList
-
-### 1. 概览
-
-基于双向链表实现,使用 Node 存储链表节点信息。
-
-```java
-private static class Node {
- E item;
- Node next;
- Node prev;
-}
-```
-
-每个链表存储了 first 和 last 指针:
-
-```java
-transient Node first;
-transient Node last;
-```
-
- 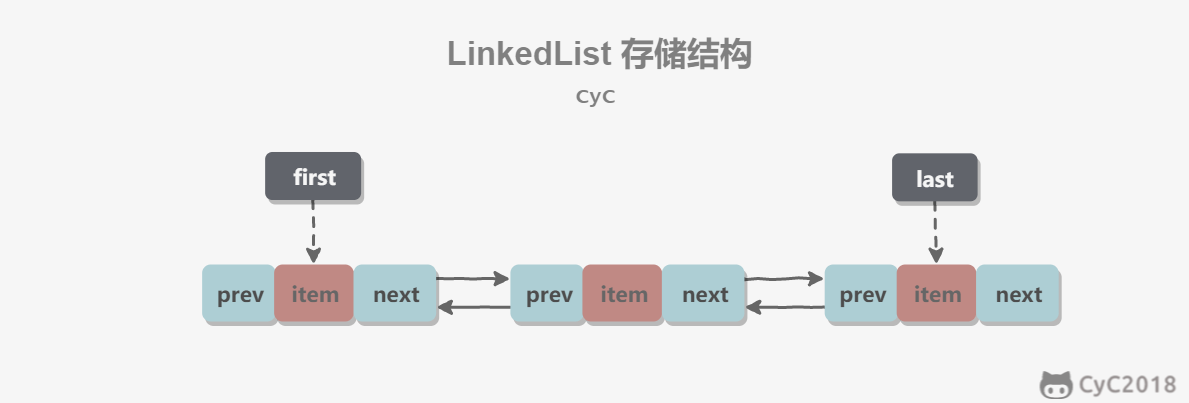
-
-### 2. 与 ArrayList 的比较
-
-ArrayList 基于动态数组实现,LinkedList 基于双向链表实现。ArrayList 和 LinkedList 的区别可以归结为数组和链表的区别:
-
-- 数组支持随机访问,但插入删除的代价很高,需要移动大量元素;
-- 链表不支持随机访问,但插入删除只需要改变指针。
-
-## HashMap
-
-为了便于理解,以下源码分析以 JDK 1.7 为主。
-
-### 1. 存储结构
-
-内部包含了一个 Entry 类型的数组 table。Entry 存储着键值对。它包含了四个字段,从 next 字段我们可以看出 Entry 是一个链表。即数组中的每个位置被当成一个桶,一个桶存放一个链表。HashMap 使用拉链法来解决冲突,同一个链表中存放哈希值和散列桶取模运算结果相同的 Entry。
-
- 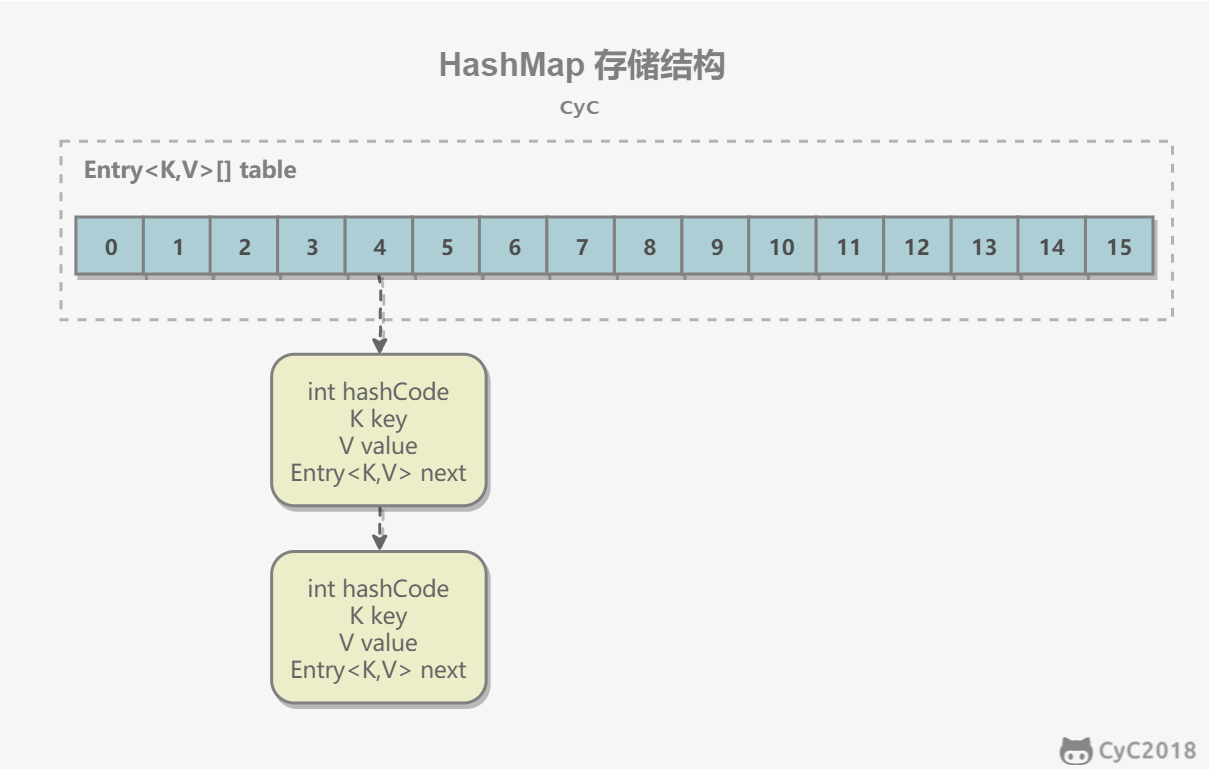
-
-```java
-transient Entry[] table;
-```
-
-```java
-static class Entry implements Map.Entry {
- final K key;
- V value;
- Entry next;
- int hash;
-
- Entry(int h, K k, V v, Entry n) {
- value = v;
- next = n;
- key = k;
- hash = h;
- }
-
- public final K getKey() {
- return key;
- }
-
- public final V getValue() {
- return value;
- }
-
- public final V setValue(V newValue) {
- V oldValue = value;
- value = newValue;
- return oldValue;
- }
-
- public final boolean equals(Object o) {
- if (!(o instanceof Map.Entry))
- return false;
- Map.Entry e = (Map.Entry)o;
- Object k1 = getKey();
- Object k2 = e.getKey();
- if (k1 == k2 || (k1 != null && k1.equals(k2))) {
- Object v1 = getValue();
- Object v2 = e.getValue();
- if (v1 == v2 || (v1 != null && v1.equals(v2)))
- return true;
- }
- return false;
- }
-
- public final int hashCode() {
- return Objects.hashCode(getKey()) ^ Objects.hashCode(getValue());
- }
-
- public final String toString() {
- return getKey() + "=" + getValue();
- }
-}
-```
-
-### 2. 拉链法的工作原理
-
-```java
-HashMap map = new HashMap<>();
-map.put("K1", "V1");
-map.put("K2", "V2");
-map.put("K3", "V3");
-```
-
-- 新建一个 HashMap,默认大小为 16;
-- 插入 <K1,V1> 键值对,先计算 K1 的 hashCode 为 115,使用除留余数法得到所在的桶下标 115%16=3。
-- 插入 <K2,V2> 键值对,先计算 K2 的 hashCode 为 118,使用除留余数法得到所在的桶下标 118%16=6。
-- 插入 <K3,V3> 键值对,先计算 K3 的 hashCode 为 118,使用除留余数法得到所在的桶下标 118%16=6,插在 <K2,V2> 前面。
-
-应该注意到链表的插入是以头插法方式进行的,例如上面的 <K3,V3> 不是插在 <K2,V2> 后面,而是插入在链表头部。
-
-查找需要分成两步进行:
-
-- 计算键值对所在的桶;
-- 在链表上顺序查找,时间复杂度显然和链表的长度成正比。
-
- 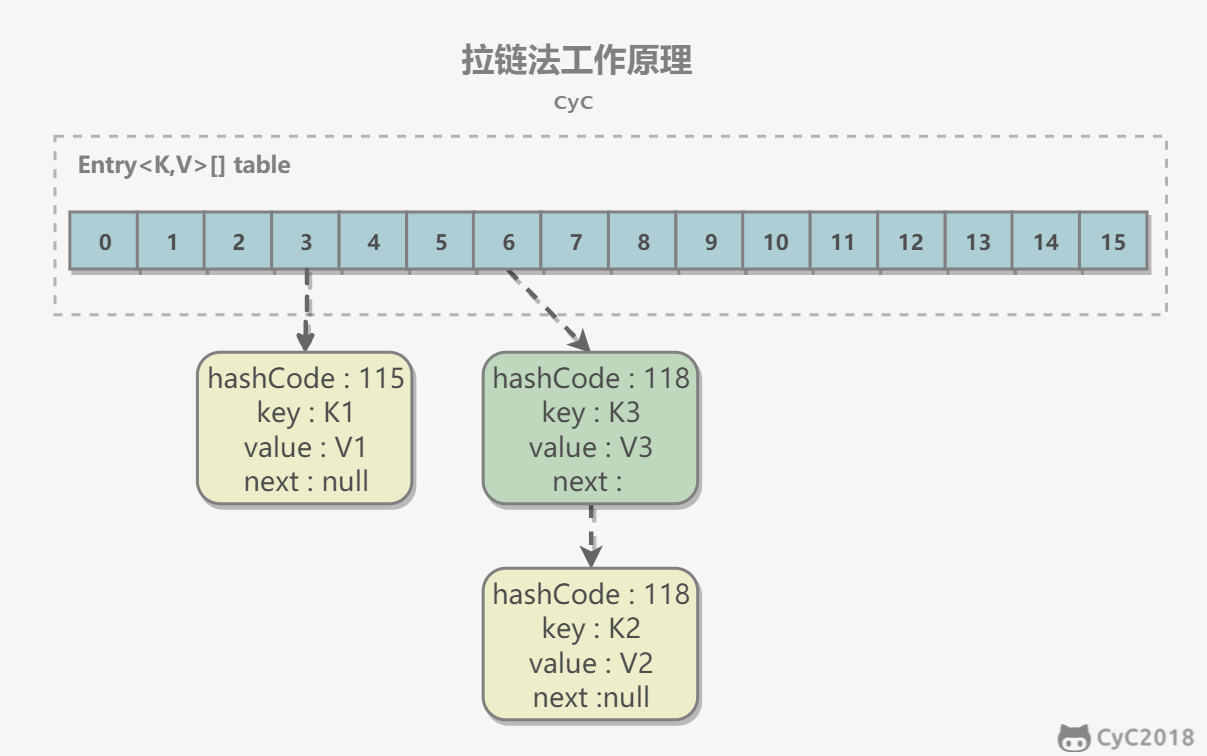
-
-### 3. put 操作
-
-```java
-public V put(K key, V value) {
- if (table == EMPTY_TABLE) {
- inflateTable(threshold);
- }
- // 键为 null 单独处理
- if (key == null)
- return putForNullKey(value);
- int hash = hash(key);
- // 确定桶下标
- int i = indexFor(hash, table.length);
- // 先找出是否已经存在键为 key 的键值对,如果存在的话就更新这个键值对的值为 value
- for (Entry e = table[i]; e != null; e = e.next) {
- Object k;
- if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
- V oldValue = e.value;
- e.value = value;
- e.recordAccess(this);
- return oldValue;
- }
- }
-
- modCount++;
- // 插入新键值对
- addEntry(hash, key, value, i);
- return null;
-}
-```
-
-HashMap 允许插入键为 null 的键值对。但是因为无法调用 null 的 hashCode() 方法,也就无法确定该键值对的桶下标,只能通过强制指定一个桶下标来存放。HashMap 使用第 0 个桶存放键为 null 的键值对。
-
-```java
-private V putForNullKey(V value) {
- for (Entry e = table[0]; e != null; e = e.next) {
- if (e.key == null) {
- V oldValue = e.value;
- e.value = value;
- e.recordAccess(this);
- return oldValue;
- }
- }
- modCount++;
- addEntry(0, null, value, 0);
- return null;
-}
-```
-
-使用链表的头插法,也就是新的键值对插在链表的头部,而不是链表的尾部。
-
-```java
-void addEntry(int hash, K key, V value, int bucketIndex) {
- if ((size >= threshold) && (null != table[bucketIndex])) {
- resize(2 * table.length);
- hash = (null != key) ? hash(key) : 0;
- bucketIndex = indexFor(hash, table.length);
- }
-
- createEntry(hash, key, value, bucketIndex);
-}
-
-void createEntry(int hash, K key, V value, int bucketIndex) {
- Entry e = table[bucketIndex];
- // 头插法,链表头部指向新的键值对
- table[bucketIndex] = new Entry<>(hash, key, value, e);
- size++;
-}
-```
-
-```java
-Entry(int h, K k, V v, Entry n) {
- value = v;
- next = n;
- key = k;
- hash = h;
-}
-```
-
-### 4. 确定桶下标
-
-很多操作都需要先确定一个键值对所在的桶下标。
-
-```java
-int hash = hash(key);
-int i = indexFor(hash, table.length);
-```
-
-**4.1 计算 hash 值**
-
-```java
-final int hash(Object k) {
- int h = hashSeed;
- if (0 != h && k instanceof String) {
- return sun.misc.Hashing.stringHash32((String) k);
- }
-
- h ^= k.hashCode();
-
- // This function ensures that hashCodes that differ only by
- // constant multiples at each bit position have a bounded
- // number of collisions (approximately 8 at default load factor).
- h ^= (h >>> 20) ^ (h >>> 12);
- return h ^ (h >>> 7) ^ (h >>> 4);
-}
-```
-
-```java
-public final int hashCode() {
- return Objects.hashCode(key) ^ Objects.hashCode(value);
-}
-```
-
-**4.2 取模**
-
-令 x = 1<<4,即 x 为 2 的 4 次方,它具有以下性质:
-
-```
-x : 00010000
-x-1 : 00001111
-```
-
-令一个数 y 与 x-1 做与运算,可以去除 y 位级表示的第 4 位以上数:
-
-```
-y : 10110010
-x-1 : 00001111
-y&(x-1) : 00000010
-```
-
-这个性质和 y 对 x 取模效果是一样的:
-
-```
-y : 10110010
-x : 00010000
-y%x : 00000010
-```
-
-我们知道,位运算的代价比求模运算小的多,因此在进行这种计算时用位运算的话能带来更高的性能。
-
-确定桶下标的最后一步是将 key 的 hash 值对桶个数取模:hash%capacity,如果能保证 capacity 为 2 的 n 次方,那么就可以将这个操作转换为位运算。
-
-```java
-static int indexFor(int h, int length) {
- return h & (length-1);
-}
-```
-
-### 5. 扩容-基本原理
-
-设 HashMap 的 table 长度为 M,需要存储的键值对数量为 N,如果哈希函数满足均匀性的要求,那么每条链表的长度大约为 N/M,因此查找的复杂度为 O(N/M)。
-
-为了让查找的成本降低,应该使 N/M 尽可能小,因此需要保证 M 尽可能大,也就是说 table 要尽可能大。HashMap 采用动态扩容来根据当前的 N 值来调整 M 值,使得空间效率和时间效率都能得到保证。
-
-和扩容相关的参数主要有:capacity、size、threshold 和 load_factor。
-
-| 参数 | 含义 |
-| :--: | :-- |
-| capacity | table 的容量大小,默认为 16。需要注意的是 capacity 必须保证为 2 的 n 次方。|
-| size | 键值对数量。 |
-| threshold | size 的临界值,当 size 大于等于 threshold 就必须进行扩容操作。 |
-| loadFactor | 装载因子,table 能够使用的比例,threshold = (int)(capacity* loadFactor)。 |
-
-```java
-static final int DEFAULT_INITIAL_CAPACITY = 16;
-
-static final int MAXIMUM_CAPACITY = 1 << 30;
-
-static final float DEFAULT_LOAD_FACTOR = 0.75f;
-
-transient Entry[] table;
-
-transient int size;
-
-int threshold;
-
-final float loadFactor;
-
-transient int modCount;
-```
-
-从下面的添加元素代码中可以看出,当需要扩容时,令 capacity 为原来的两倍。
-
-```java
-void addEntry(int hash, K key, V value, int bucketIndex) {
- Entry e = table[bucketIndex];
- table[bucketIndex] = new Entry<>(hash, key, value, e);
- if (size++ >= threshold)
- resize(2 * table.length);
-}
-```
-
-扩容使用 resize() 实现,需要注意的是,扩容操作同样需要把 oldTable 的所有键值对重新插入 newTable 中,因此这一步是很费时的。
-
-```java
-void resize(int newCapacity) {
- Entry[] oldTable = table;
- int oldCapacity = oldTable.length;
- if (oldCapacity == MAXIMUM_CAPACITY) {
- threshold = Integer.MAX_VALUE;
- return;
- }
- Entry[] newTable = new Entry[newCapacity];
- transfer(newTable);
- table = newTable;
- threshold = (int)(newCapacity * loadFactor);
-}
-
-void transfer(Entry[] newTable) {
- Entry[] src = table;
- int newCapacity = newTable.length;
- for (int j = 0; j < src.length; j++) {
- Entry e = src[j];
- if (e != null) {
- src[j] = null;
- do {
- Entry next = e.next;
- int i = indexFor(e.hash, newCapacity);
- e.next = newTable[i];
- newTable[i] = e;
- e = next;
- } while (e != null);
- }
- }
-}
-```
-
-### 6. 扩容-重新计算桶下标
-
-在进行扩容时,需要把键值对重新计算桶下标,从而放到对应的桶上。在前面提到,HashMap 使用 hash%capacity 来确定桶下标。HashMap capacity 为 2 的 n 次方这一特点能够极大降低重新计算桶下标操作的复杂度。
-
-假设原数组长度 capacity 为 16,扩容之后 new capacity 为 32:
-
-```html
-capacity : 00010000
-new capacity : 00100000
-```
-
-对于一个 Key,它的哈希值 hash 在第 5 位:
-
-- 为 0,那么 hash%00010000 = hash%00100000,桶位置和原来一致;
-- 为 1,hash%00010000 = hash%00100000 + 16,桶位置是原位置 + 16。
-
-### 7. 计算数组容量
-
-HashMap 构造函数允许用户传入的容量不是 2 的 n 次方,因为它可以自动地将传入的容量转换为 2 的 n 次方。
-
-先考虑如何求一个数的掩码,对于 10010000,它的掩码为 11111111,可以使用以下方法得到:
-
-```
-mask |= mask >> 1 11011000
-mask |= mask >> 2 11111110
-mask |= mask >> 4 11111111
-```
-
-mask+1 是大于原始数字的最小的 2 的 n 次方。
-
-```
-num 10010000
-mask+1 100000000
-```
-
-以下是 HashMap 中计算数组容量的代码:
-
-```java
-static final int tableSizeFor(int cap) {
- int n = cap - 1;
- n |= n >>> 1;
- n |= n >>> 2;
- n |= n >>> 4;
- n |= n >>> 8;
- n |= n >>> 16;
- return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
-}
-```
-
-### 8. 链表转红黑树
-
-从 JDK 1.8 开始,一个桶存储的链表长度大于等于 8 时会将链表转换为红黑树。
-
-### 9. 与 Hashtable 的比较
-
-- Hashtable 使用 synchronized 来进行同步。
-- HashMap 可以插入键为 null 的 Entry。
-- HashMap 的迭代器是 fail-fast 迭代器。
-- HashMap 不能保证随着时间的推移 Map 中的元素次序是不变的。
-
-## ConcurrentHashMap
-
-### 1. 存储结构
-
- 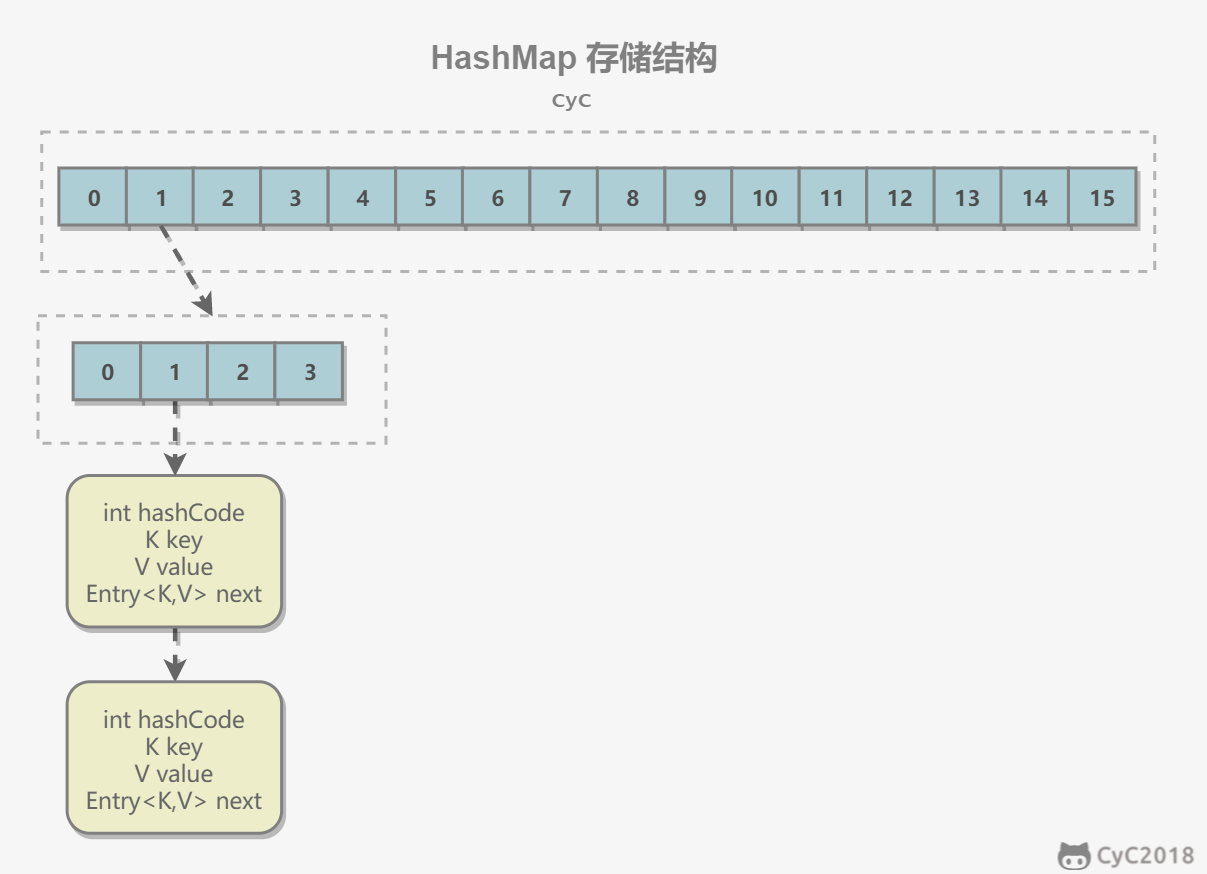
-
-```java
-static final class HashEntry {
- final int hash;
- final K key;
- volatile V value;
- volatile HashEntry next;
-}
-```
-
-ConcurrentHashMap 和 HashMap 实现上类似,最主要的差别是 ConcurrentHashMap 采用了分段锁(Segment),每个分段锁维护着几个桶(HashEntry),多个线程可以同时访问不同分段锁上的桶,从而使其并发度更高(并发度就是 Segment 的个数)。
-
-Segment 继承自 ReentrantLock。
-
-```java
-static final class Segment extends ReentrantLock implements Serializable {
-
- private static final long serialVersionUID = 2249069246763182397L;
-
- static final int MAX_SCAN_RETRIES =
- Runtime.getRuntime().availableProcessors() > 1 ? 64 : 1;
-
- transient volatile HashEntry[] table;
-
- transient int count;
-
- transient int modCount;
-
- transient int threshold;
-
- final float loadFactor;
-}
-```
-
-```java
-final Segment[] segments;
-```
-
-默认的并发级别为 16,也就是说默认创建 16 个 Segment。
-
-```java
-static final int DEFAULT_CONCURRENCY_LEVEL = 16;
-```
-
-### 2. size 操作
-
-每个 Segment 维护了一个 count 变量来统计该 Segment 中的键值对个数。
-
-```java
-/**
- * The number of elements. Accessed only either within locks
- * or among other volatile reads that maintain visibility.
- */
-transient int count;
-```
-
-在执行 size 操作时,需要遍历所有 Segment 然后把 count 累计起来。
-
-ConcurrentHashMap 在执行 size 操作时先尝试不加锁,如果连续两次不加锁操作得到的结果一致,那么可以认为这个结果是正确的。
-
-尝试次数使用 RETRIES_BEFORE_LOCK 定义,该值为 2,retries 初始值为 -1,因此尝试次数为 3。
-
-如果尝试的次数超过 3 次,就需要对每个 Segment 加锁。
-
-```java
-
-/**
- * Number of unsynchronized retries in size and containsValue
- * methods before resorting to locking. This is used to avoid
- * unbounded retries if tables undergo continuous modification
- * which would make it impossible to obtain an accurate result.
- */
-static final int RETRIES_BEFORE_LOCK = 2;
-
-public int size() {
- // Try a few times to get accurate count. On failure due to
- // continuous async changes in table, resort to locking.
- final Segment[] segments = this.segments;
- int size;
- boolean overflow; // true if size overflows 32 bits
- long sum; // sum of modCounts
- long last = 0L; // previous sum
- int retries = -1; // first iteration isn't retry
- try {
- for (;;) {
- // 超过尝试次数,则对每个 Segment 加锁
- if (retries++ == RETRIES_BEFORE_LOCK) {
- for (int j = 0; j < segments.length; ++j)
- ensureSegment(j).lock(); // force creation
- }
- sum = 0L;
- size = 0;
- overflow = false;
- for (int j = 0; j < segments.length; ++j) {
- Segment seg = segmentAt(segments, j);
- if (seg != null) {
- sum += seg.modCount;
- int c = seg.count;
- if (c < 0 || (size += c) < 0)
- overflow = true;
- }
- }
- // 连续两次得到的结果一致,则认为这个结果是正确的
- if (sum == last)
- break;
- last = sum;
- }
- } finally {
- if (retries > RETRIES_BEFORE_LOCK) {
- for (int j = 0; j < segments.length; ++j)
- segmentAt(segments, j).unlock();
- }
- }
- return overflow ? Integer.MAX_VALUE : size;
-}
-```
-
-### 3. JDK 1.8 的改动
-
-JDK 1.7 使用分段锁机制来实现并发更新操作,核心类为 Segment,它继承自重入锁 ReentrantLock,并发度与 Segment 数量相等。
-
-JDK 1.8 使用了 CAS 操作来支持更高的并发度,在 CAS 操作失败时使用内置锁 synchronized。
-
-并且 JDK 1.8 的实现也在链表过长时会转换为红黑树。
-
-## LinkedHashMap
-
-### 存储结构
-
-继承自 HashMap,因此具有和 HashMap 一样的快速查找特性。
-
-```java
-public class LinkedHashMap extends HashMap implements Map
-```
-
-内部维护了一个双向链表,用来维护插入顺序或者 LRU 顺序。
-
-```java
-/**
- * The head (eldest) of the doubly linked list.
- */
-transient LinkedHashMap.Entry head;
-
-/**
- * The tail (youngest) of the doubly linked list.
- */
-transient LinkedHashMap.Entry tail;
-```
-
-accessOrder 决定了顺序,默认为 false,此时维护的是插入顺序。
-
-```java
-final boolean accessOrder;
-```
-
-LinkedHashMap 最重要的是以下用于维护顺序的函数,它们会在 put、get 等方法中调用。
-
-```java
-void afterNodeAccess(Node p) { }
-void afterNodeInsertion(boolean evict) { }
-```
-
-### afterNodeAccess()
-
-当一个节点被访问时,如果 accessOrder 为 true,则会将该节点移到链表尾部。也就是说指定为 LRU 顺序之后,在每次访问一个节点时,会将这个节点移到链表尾部,保证链表尾部是最近访问的节点,那么链表首部就是最近最久未使用的节点。
-
-```java
-void afterNodeAccess(Node e) { // move node to last
- LinkedHashMap.Entry last;
- if (accessOrder && (last = tail) != e) {
- LinkedHashMap.Entry p =
- (LinkedHashMap.Entry)e, b = p.before, a = p.after;
- p.after = null;
- if (b == null)
- head = a;
- else
- b.after = a;
- if (a != null)
- a.before = b;
- else
- last = b;
- if (last == null)
- head = p;
- else {
- p.before = last;
- last.after = p;
- }
- tail = p;
- ++modCount;
- }
-}
-```
-
-### afterNodeInsertion()
-
-在 put 等操作之后执行,当 removeEldestEntry() 方法返回 true 时会移除最晚的节点,也就是链表首部节点 first。
-
-evict 只有在构建 Map 的时候才为 false,在这里为 true。
-
-```java
-void afterNodeInsertion(boolean evict) { // possibly remove eldest
- LinkedHashMap.Entry first;
- if (evict && (first = head) != null && removeEldestEntry(first)) {
- K key = first.key;
- removeNode(hash(key), key, null, false, true);
- }
-}
-```
-
-removeEldestEntry() 默认为 false,如果需要让它为 true,需要继承 LinkedHashMap 并且覆盖这个方法的实现,这在实现 LRU 的缓存中特别有用,通过移除最近最久未使用的节点,从而保证缓存空间足够,并且缓存的数据都是热点数据。
-
-```java
-protected boolean removeEldestEntry(Map.Entry eldest) {
- return false;
-}
-```
-
-### LRU 缓存
-
-以下是使用 LinkedHashMap 实现的一个 LRU 缓存:
-
-- 设定最大缓存空间 MAX_ENTRIES 为 3;
-- 使用 LinkedHashMap 的构造函数将 accessOrder 设置为 true,开启 LRU 顺序;
-- 覆盖 removeEldestEntry() 方法实现,在节点多于 MAX_ENTRIES 就会将最近最久未使用的数据移除。
-
-```java
-class LRUCache extends LinkedHashMap {
- private static final int MAX_ENTRIES = 3;
-
- protected boolean removeEldestEntry(Map.Entry eldest) {
- return size() > MAX_ENTRIES;
- }
-
- LRUCache() {
- super(MAX_ENTRIES, 0.75f, true);
- }
-}
-```
-
-```java
-public static void main(String[] args) {
- LRUCache cache = new LRUCache<>();
- cache.put(1, "a");
- cache.put(2, "b");
- cache.put(3, "c");
- cache.get(1);
- cache.put(4, "d");
- System.out.println(cache.keySet());
-}
-```
-
-```html
-[3, 1, 4]
-```
-
-## WeakHashMap
-
-### 存储结构
-
-WeakHashMap 的 Entry 继承自 WeakReference,被 WeakReference 关联的对象在下一次垃圾回收时会被回收。
-
-WeakHashMap 主要用来实现缓存,通过使用 WeakHashMap 来引用缓存对象,由 JVM 对这部分缓存进行回收。
-
-```java
-private static class Entry extends WeakReference