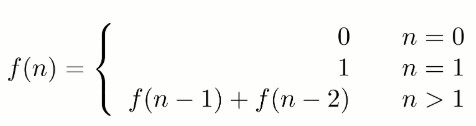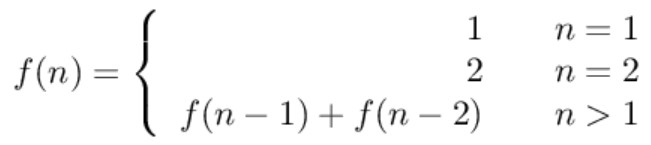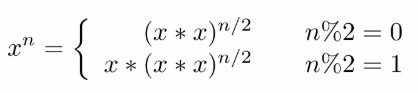diff --git a/notes/43. 从 1 到 n 整数中 1 出现的次数.md b/notes/43. 从 1 到 n 整数中 1 出现的次数.md
index f2b5ea96..89323cc8 100644
--- a/notes/43. 从 1 到 n 整数中 1 出现的次数.md
+++ b/notes/43. 从 1 到 n 整数中 1 出现的次数.md
@@ -15,4 +15,4 @@ public int NumberOf1Between1AndN_Solution(int n) {
}
```
-\> [Leetcode : 233. Number of Digit One](https://leetcode.com/problems/number-of-digit-one/discuss/64381/4+-lines-O(log-n)-C++JavaPython)
+> [Leetcode : 233. Number of Digit One](https://leetcode.com/problems/number-of-digit-one/discuss/64381/4+-lines-O(log-n)-C++JavaPython)
diff --git a/notes/Docker.md b/notes/Docker.md
index 26521d11..ecebdfc3 100644
--- a/notes/Docker.md
+++ b/notes/Docker.md
@@ -1,6 +1,12 @@
# Docker
* [Docker](#docker)
+ * [一、解决的问题](#一解决的问题)
+ * [二、与虚拟机的比较](#二与虚拟机的比较)
+ * [三、优势](#三优势)
+ * [四、使用场景](#四使用场景)
+ * [五、镜像与容器](#五镜像与容器)
+ * [参考资料](#参考资料)
diff --git a/notes/HTTP.md b/notes/HTTP.md
index 384094a7..f41f474b 100644
--- a/notes/HTTP.md
+++ b/notes/HTTP.md
@@ -2,14 +2,58 @@
* [HTTP](#http)
* [一 、基础概念](#一-基础概念)
+ * [请求和响应报文](#请求和响应报文)
+ * [URL](#url)
* [二、HTTP 方法](#二http-方法)
+ * [GET](#get)
+ * [HEAD](#head)
+ * [POST](#post)
+ * [PUT](#put)
+ * [PATCH](#patch)
+ * [DELETE](#delete)
+ * [OPTIONS](#options)
+ * [CONNECT](#connect)
+ * [TRACE](#trace)
* [三、HTTP 状态码](#三http-状态码)
+ * [1XX 信息](#1xx-信息)
+ * [2XX 成功](#2xx-成功)
+ * [3XX 重定向](#3xx-重定向)
+ * [4XX 客户端错误](#4xx-客户端错误)
+ * [5XX 服务器错误](#5xx-服务器错误)
* [四、HTTP 首部](#四http-首部)
+ * [通用首部字段](#通用首部字段)
+ * [请求首部字段](#请求首部字段)
+ * [响应首部字段](#响应首部字段)
+ * [实体首部字段](#实体首部字段)
* [五、具体应用](#五具体应用)
+ * [连接管理](#连接管理)
+ * [Cookie](#cookie)
+ * [缓存](#缓存)
+ * [内容协商](#内容协商)
+ * [内容编码](#内容编码)
+ * [范围请求](#范围请求)
+ * [分块传输编码](#分块传输编码)
+ * [多部分对象集合](#多部分对象集合)
+ * [虚拟主机](#虚拟主机)
+ * [通信数据转发](#通信数据转发)
* [六、HTTPS](#六https)
+ * [加密](#加密)
+ * [认证](#认证)
+ * [完整性保护](#完整性保护)
+ * [HTTPS 的缺点](#https-的缺点)
* [七、HTTP/2.0](#七http20)
+ * [HTTP/1.x 缺陷](#http1x-缺陷)
+ * [二进制分帧层](#二进制分帧层)
+ * [服务端推送](#服务端推送)
+ * [首部压缩](#首部压缩)
* [八、HTTP/1.1 新特性](#八http11-新特性)
* [九、GET 和 POST 比较](#九get-和-post-比较)
+ * [作用](#作用)
+ * [参数](#参数)
+ * [安全](#安全)
+ * [幂等性](#幂等性)
+ * [可缓存](#可缓存)
+ * [XMLHttpRequest](#xmlhttprequest)
* [参考资料](#参考资料)
@@ -95,13 +139,13 @@ http 使用 URL( **U** niform **R**esource **L**ocator,统一资源定位符
### GET
-\> 获取资源
+> 获取资源
当前网络请求中,绝大部分使用的是 GET 方法。
### HEAD
-\> 获取报文首部
+> 获取报文首部
和 GET 方法类似,但是不返回报文实体主体部分。
@@ -109,7 +153,7 @@ http 使用 URL( **U** niform **R**esource **L**ocator,统一资源定位符
### POST
-\> 传输实体主体
+> 传输实体主体
POST 主要用来传输数据,而 GET 主要用来获取资源。
@@ -117,7 +161,7 @@ POST 主要用来传输数据,而 GET 主要用来获取资源。
### PUT
-\> 上传文件
+> 上传文件
由于自身不带验证机制,任何人都可以上传文件,因此存在安全性问题,一般不使用该方法。
@@ -132,7 +176,7 @@ Content-length: 16
### PATCH
-\> 对资源进行部分修改
+> 对资源进行部分修改
PUT 也可以用于修改资源,但是只能完全替代原始资源,PATCH 允许部分修改。
@@ -148,7 +192,7 @@ Content-Length: 100
### DELETE
-\> 删除文件
+> 删除文件
与 PUT 功能相反,并且同样不带验证机制。
@@ -158,7 +202,7 @@ DELETE /file.html HTTP/1.1
### OPTIONS
-\> 查询支持的方法
+> 查询支持的方法
查询指定的 URL 能够支持的方法。
@@ -166,7 +210,7 @@ DELETE /file.html HTTP/1.1
### CONNECT
-\> 要求在与代理服务器通信时建立隧道
+> 要求在与代理服务器通信时建立隧道
使用 SSL(Secure Sockets Layer,安全套接层)和 TLS(Transport Layer Security,传输层安全)协议把通信内容加密后经网络隧道传输。
@@ -178,7 +222,7 @@ CONNECT www.example.com:443 HTTP/1.1
### TRACE
-\> 追踪路径
+> 追踪路径
服务器会将通信路径返回给客户端。
@@ -863,7 +907,7 @@ DELETE /idX/delete HTTP/1.1 -> Returns 404
为了阐述 POST 和 GET 的另一个区别,需要先了解 XMLHttpRequest:
-\> XMLHttpRequest 是一个 API,它为客户端提供了在客户端和服务器之间传输数据的功能。它提供了一个通过 URL 来获取数据的简单方式,并且不会使整个页面刷新。这使得网页只更新一部分页面而不会打扰到用户。XMLHttpRequest 在 AJAX 中被大量使用。
+> XMLHttpRequest 是一个 API,它为客户端提供了在客户端和服务器之间传输数据的功能。它提供了一个通过 URL 来获取数据的简单方式,并且不会使整个页面刷新。这使得网页只更新一部分页面而不会打扰到用户。XMLHttpRequest 在 AJAX 中被大量使用。
- 在使用 XMLHttpRequest 的 POST 方法时,浏览器会先发送 Header 再发送 Data。但并不是所有浏览器会这么做,例如火狐就不会。
- 而 GET 方法 Header 和 Data 会一起发送。
diff --git a/notes/Java IO.md b/notes/Java IO.md
index 5a4e15f1..d95eee4f 100644
--- a/notes/Java IO.md
+++ b/notes/Java IO.md
@@ -4,10 +4,31 @@
* [一、概览](#一概览)
* [二、磁盘操作](#二磁盘操作)
* [三、字节操作](#三字节操作)
+ * [实现文件复制](#实现文件复制)
+ * [装饰者模式](#装饰者模式)
* [四、字符操作](#四字符操作)
+ * [编码与解码](#编码与解码)
+ * [String 的编码方式](#string-的编码方式)
+ * [Reader 与 Writer](#reader-与-writer)
+ * [实现逐行输出文本文件的内容](#实现逐行输出文本文件的内容)
* [五、对象操作](#五对象操作)
+ * [序列化](#序列化)
+ * [Serializable](#serializable)
+ * [transient](#transient)
* [六、网络操作](#六网络操作)
+ * [InetAddress](#inetaddress)
+ * [URL](#url)
+ * [Sockets](#sockets)
+ * [Datagram](#datagram)
* [七、NIO](#七nio)
+ * [流与块](#流与块)
+ * [通道与缓冲区](#通道与缓冲区)
+ * [缓冲区状态变量](#缓冲区状态变量)
+ * [文件 NIO 实例](#文件-nio-实例)
+ * [选择器](#选择器)
+ * [套接字 NIO 实例](#套接字-nio-实例)
+ * [内存映射文件](#内存映射文件)
+ * [对比](#对比)
* [八、参考资料](#八参考资料)
diff --git a/notes/Java 基础.md b/notes/Java 基础.md
index 5f31cec6..9a1dae8a 100644
--- a/notes/Java 基础.md
+++ b/notes/Java 基础.md
@@ -2,16 +2,42 @@
* [Java 基础](#java-基础)
* [一、数据类型](#一数据类型)
+ * [基本类型](#基本类型)
+ * [包装类型](#包装类型)
+ * [缓存池](#缓存池)
* [二、String](#二string)
+ * [概览](#概览)
+ * [不可变的好处](#不可变的好处)
+ * [String, StringBuffer and StringBuilder ](#string-stringbuffer-and-stringbuilder )
+ * [String Pool](#string-pool)
+ * [new String("abc")](#new-stringabc)
* [三、运算](#三运算)
+ * [参数传递](#参数传递)
+ * [float 与 double](#float-与-double)
+ * [隐式类型转换](#隐式类型转换)
+ * [switch](#switch)
* [四、关键字](#四关键字)
+ * [final](#final)
+ * [static](#static)
* [五、Object 通用方法](#五object-通用方法)
+ * [概览](#概览)
+ * [equals()](#equals)
+ * [hashCode()](#hashcode)
+ * [toString()](#tostring)
+ * [clone()](#clone)
* [六、继承](#六继承)
+ * [访问权限](#访问权限)
+ * [抽象类与接口](#抽象类与接口)
+ * [super](#super)
+ * [重写与重载](#重写与重载)
* [七、反射](#七反射)
* [八、异常](#八异常)
* [九、泛型](#九泛型)
* [十、注解](#十注解)
* [十一、特性](#十一特性)
+ * [Java 各版本的新特性](#java-各版本的新特性)
+ * [Java 与 C++ 的区别](#java-与-c-的区别)
+ * [JRE or JDK](#jre-or-jdk)
* [参考资料](#参考资料)
@@ -1328,26 +1354,25 @@ public static void main(String[] args) {
Class 和 java.lang.reflect 一起对反射提供了支持,java.lang.reflect 类库主要包含了以下三个类:
-- **Field** :可以使用 get() 和 set() 方法读取和修改 Field 对象关联的字段;
-- **Method** :可以使用 invoke() 方法调用与 Method 对象关联的方法;
-- **Constructor** :可以用 Constructor 的 newInstance() 创建新的对象。
+- **Field** :可以使用 get() 和 set() 方法读取和修改 Field 对象关联的字段;
+- **Method** :可以使用 invoke() 方法调用与 Method 对象关联的方法;
+- **Constructor** :可以用 Constructor 的 newInstance() 创建新的对象。
**反射的优点:**
-* **可扩展性** :应用程序可以利用全限定名创建可扩展对象的实例,来使用来自外部的用户自定义类。
-* **类浏览器和可视化开发环境** :一个类浏览器需要可以枚举类的成员。可视化开发环境(如 IDE)可以从利用反射中可用的类型信息中受益,以帮助程序员编写正确的代码。
-* **调试器和测试工具** : 调试器需要能够检查一个类里的私有成员。测试工具可以利用反射来自动地调用类里定义的可被发现的 API 定义,以确保一组测试中有较高的代码覆盖率。
+- **可扩展性** :应用程序可以利用全限定名创建可扩展对象的实例,来使用来自外部的用户自定义类。
+- **类浏览器和可视化开发环境** :一个类浏览器需要可以枚举类的成员。可视化开发环境(如 IDE)可以从利用反射中可用的类型信息中受益,以帮助程序员编写正确的代码。
+- **调试器和测试工具** : 调试器需要能够检查一个类里的私有成员。测试工具可以利用反射来自动地调用类里定义的可被发现的 API 定义,以确保一组测试中有较高的代码覆盖率。
**反射的缺点:**
尽管反射非常强大,但也不能滥用。如果一个功能可以不用反射完成,那么最好就不用。在我们使用反射技术时,下面几条内容应该牢记于心。
-* **性能开销** :反射涉及了动态类型的解析,所以 JVM 无法对这些代码进行优化。因此,反射操作的效率要比那些非反射操作低得多。我们应该避免在经常被执行的代码或对性能要求很高的程序中使用反射。
+- **性能开销** :反射涉及了动态类型的解析,所以 JVM 无法对这些代码进行优化。因此,反射操作的效率要比那些非反射操作低得多。我们应该避免在经常被执行的代码或对性能要求很高的程序中使用反射。
-* **安全限制** :使用反射技术要求程序必须在一个没有安全限制的环境中运行。如果一个程序必须在有安全限制的环境中运行,如 Applet,那么这就是个问题了。
-
-* **内部暴露** :由于反射允许代码执行一些在正常情况下不被允许的操作(比如访问私有的属性和方法),所以使用反射可能会导致意料之外的副作用,这可能导致代码功能失调并破坏可移植性。反射代码破坏了抽象性,因此当平台发生改变的时候,代码的行为就有可能也随着变化。
+- **安全限制** :使用反射技术要求程序必须在一个没有安全限制的环境中运行。如果一个程序必须在有安全限制的环境中运行,如 Applet,那么这就是个问题了。
+- **内部暴露** :由于反射允许代码执行一些在正常情况下不被允许的操作(比如访问私有的属性和方法),所以使用反射可能会导致意料之外的副作用,这可能导致代码功能失调并破坏可移植性。反射代码破坏了抽象性,因此当平台发生改变的时候,代码的行为就有可能也随着变化。
- [Trail: The Reflection API](https://docs.oracle.com/javase/tutorial/reflect/index.html)
- [深入解析 Java 反射(1)- 基础](http://www.sczyh30.com/posts/Java/java-reflection-1/)
diff --git a/notes/Java 容器.md b/notes/Java 容器.md
index 4f4deaf3..6782d65f 100644
--- a/notes/Java 容器.md
+++ b/notes/Java 容器.md
@@ -2,8 +2,20 @@
* [Java 容器](#java-容器)
* [一、概览](#一概览)
+ * [Collection](#collection)
+ * [Map](#map)
* [二、容器中的设计模式](#二容器中的设计模式)
+ * [迭代器模式](#迭代器模式)
+ * [适配器模式](#适配器模式)
* [三、源码分析](#三源码分析)
+ * [ArrayList](#arraylist)
+ * [Vector](#vector)
+ * [CopyOnWriteArrayList](#copyonwritearraylist)
+ * [LinkedList](#linkedlist)
+ * [HashMap](#hashmap)
+ * [ConcurrentHashMap](#concurrenthashmap)
+ * [LinkedHashMap](#linkedhashmap)
+ * [WeakHashMap](#weakhashmap)
* [参考资料](#参考资料)
diff --git a/notes/Java 并发.md b/notes/Java 并发.md
index 4a003a55..cb011950 100644
--- a/notes/Java 并发.md
+++ b/notes/Java 并发.md
@@ -2,17 +2,60 @@
* [Java 并发](#java-并发)
* [一、使用线程](#一使用线程)
+ * [实现 Runnable 接口](#实现-runnable-接口)
+ * [实现 Callable 接口](#实现-callable-接口)
+ * [继承 Thread 类](#继承-thread-类)
+ * [实现接口 VS 继承 Thread](#实现接口-vs-继承-thread)
* [二、基础线程机制](#二基础线程机制)
+ * [Executor](#executor)
+ * [Daemon](#daemon)
+ * [sleep()](#sleep)
+ * [yield()](#yield)
* [三、中断](#三中断)
+ * [InterruptedException](#interruptedexception)
+ * [interrupted()](#interrupted)
+ * [Executor 的中断操作](#executor-的中断操作)
* [四、互斥同步](#四互斥同步)
+ * [synchronized](#synchronized)
+ * [ReentrantLock](#reentrantlock)
+ * [比较](#比较)
+ * [使用选择](#使用选择)
* [五、线程之间的协作](#五线程之间的协作)
+ * [join()](#join)
+ * [wait() notify() notifyAll()](#wait-notify-notifyall)
+ * [await() signal() signalAll()](#await-signal-signalall)
* [六、线程状态](#六线程状态)
+ * [新建(NEW)](#新建new)
+ * [可运行(RUNABLE)](#可运行runable)
+ * [阻塞(BLOCKED)](#阻塞blocked)
+ * [无限期等待(WAITING)](#无限期等待waiting)
+ * [限期等待(TIMED_WAITING)](#限期等待timed_waiting)
+ * [死亡(TERMINATED)](#死亡terminated)
* [七、J.U.C - AQS](#七juc---aqs)
+ * [CountDownLatch](#countdownlatch)
+ * [CyclicBarrier](#cyclicbarrier)
+ * [Semaphore](#semaphore)
* [八、J.U.C - 其它组件](#八juc---其它组件)
+ * [FutureTask](#futuretask)
+ * [BlockingQueue](#blockingqueue)
+ * [ForkJoin](#forkjoin)
* [九、线程不安全示例](#九线程不安全示例)
* [十、Java 内存模型](#十java-内存模型)
+ * [主内存与工作内存](#主内存与工作内存)
+ * [内存间交互操作](#内存间交互操作)
+ * [内存模型三大特性](#内存模型三大特性)
+ * [先行发生原则](#先行发生原则)
* [十一、线程安全](#十一线程安全)
+ * [不可变](#不可变)
+ * [互斥同步](#互斥同步)
+ * [非阻塞同步](#非阻塞同步)
+ * [无同步方案](#无同步方案)
* [十二、锁优化](#十二锁优化)
+ * [自旋锁](#自旋锁)
+ * [锁消除](#锁消除)
+ * [锁粗化](#锁粗化)
+ * [轻量级锁](#轻量级锁)
+ * [偏向锁](#偏向锁)
* [十三、多线程开发良好的实践](#十三多线程开发良好的实践)
* [参考资料](#参考资料)
@@ -1177,7 +1220,7 @@ volatile 关键字通过添加内存屏障的方式来禁止指令重排,即
#### 1. 单一线程原则
-\> Single Thread rule
+> Single Thread rule
在一个线程内,在程序前面的操作先行发生于后面的操作。
@@ -1185,7 +1228,7 @@ volatile 关键字通过添加内存屏障的方式来禁止指令重排,即
#### 2. 管程锁定规则
-\> Monitor Lock Rule
+> Monitor Lock Rule
一个 unlock 操作先行发生于后面对同一个锁的 lock 操作。
@@ -1193,7 +1236,7 @@ volatile 关键字通过添加内存屏障的方式来禁止指令重排,即
#### 3. volatile 变量规则
-\> Volatile Variable Rule
+> Volatile Variable Rule
对一个 volatile 变量的写操作先行发生于后面对这个变量的读操作。
@@ -1201,7 +1244,7 @@ volatile 关键字通过添加内存屏障的方式来禁止指令重排,即
#### 4. 线程启动规则
-\> Thread Start Rule
+> Thread Start Rule
Thread 对象的 start() 方法调用先行发生于此线程的每一个动作。
@@ -1209,7 +1252,7 @@ Thread 对象的 start() 方法调用先行发生于此线程的每一个动作
#### 5. 线程加入规则
-\> Thread Join Rule
+> Thread Join Rule
Thread 对象的结束先行发生于 join() 方法返回。
@@ -1217,19 +1260,19 @@ Thread 对象的结束先行发生于 join() 方法返回。
#### 6. 线程中断规则
-\> Thread Interruption Rule
+> Thread Interruption Rule
对线程 interrupt() 方法的调用先行发生于被中断线程的代码检测到中断事件的发生,可以通过 interrupted() 方法检测到是否有中断发生。
#### 7. 对象终结规则
-\> Finalizer Rule
+> Finalizer Rule
一个对象的初始化完成(构造函数执行结束)先行发生于它的 finalize() 方法的开始。
#### 8. 传递性
-\> Transitivity
+> Transitivity
如果操作 A 先行发生于操作 B,操作 B 先行发生于操作 C,那么操作 A 先行发生于操作 C。
diff --git a/notes/Java 虚拟机.md b/notes/Java 虚拟机.md
index b617432d..01df1073 100644
--- a/notes/Java 虚拟机.md
+++ b/notes/Java 虚拟机.md
@@ -2,9 +2,30 @@
* [Java 虚拟机](#java-虚拟机)
* [一、运行时数据区域](#一运行时数据区域)
+ * [程序计数器](#程序计数器)
+ * [Java 虚拟机栈](#java-虚拟机栈)
+ * [本地方法栈](#本地方法栈)
+ * [堆](#堆)
+ * [方法区](#方法区)
+ * [运行时常量池](#运行时常量池)
+ * [直接内存](#直接内存)
* [二、垃圾收集](#二垃圾收集)
+ * [判断一个对象是否可被回收](#判断一个对象是否可被回收)
+ * [引用类型](#引用类型)
+ * [垃圾收集算法](#垃圾收集算法)
+ * [垃圾收集器](#垃圾收集器)
* [三、内存分配与回收策略](#三内存分配与回收策略)
+ * [Minor GC 和 Full GC](#minor-gc-和-full-gc)
+ * [内存分配策略](#内存分配策略)
+ * [Full GC 的触发条件](#full-gc-的触发条件)
* [四、类加载机制](#四类加载机制)
+ * [类的生命周期](#类的生命周期)
+ * [类加载过程](#类加载过程)
+ * [类初始化时机](#类初始化时机)
+ * [类与类加载器](#类与类加载器)
+ * [类加载器分类](#类加载器分类)
+ * [双亲委派模型](#双亲委派模型)
+ * [自定义类加载器实现](#自定义类加载器实现)
* [参考资料](#参考资料)
diff --git a/notes/Leetcode 题解 - 目录1.md b/notes/Leetcode 题解 - 目录1.md
deleted file mode 100644
index d93b96a2..00000000
--- a/notes/Leetcode 题解 - 目录1.md
+++ /dev/null
@@ -1,33 +0,0 @@
-本文从 Leetcode 中精选大概 200 左右的题目,去除了某些繁杂但是没有多少算法思想的题目,同时保留了面试中经常被问到的经典题目。
-
-# 算法思想
-
-- [双指针](notes/Leetcode%20题解%20-%20双指针.md)
-- [排序](notes/Leetcode%20题解%20-%20排序.md)
-- [贪心思想](notes/Leetcode%20题解%20-%20贪心思想.md)
-- [二分查找](notes/Leetcode%20题解%20-%20二分查找.md)
-- [分治](notes/Leetcode%20题解%20-%20分治.md)
-- [搜索](notes/Leetcode%20题解%20-%20搜索.md)
-- [动态规划](notes/Leetcode%20题解%20-%20动态规划.md)
-- [数学](notes/Leetcode%20题解%20-%20数学.md)
-
-# 数据结构相关
-
-- [链表](notes/Leetcode%20题解%20-%20链表.md)
-- [树](notes/Leetcode%20题解%20-%20树.md)
-- [栈和队列](notes/Leetcode%20题解%20-%20栈和队列.md)
-- [哈希表](notes/Leetcode%20题解%20-%20哈希表.md)
-- [字符串](notes/Leetcode%20题解%20-%20字符串.md)
-- [数组与矩阵](notes/Leetcode%20题解%20-%20数组与矩阵.md)
-- [图](notes/Leetcode%20题解%20-%20图.md)
-- [位运算](notes/Leetcode%20题解%20-%20位运算.md)
-
-# 参考资料
-
-
-- Leetcode
-- Weiss M A, 冯舜玺. 数据结构与算法分析——C 语言描述[J]. 2004.
-- Sedgewick R. Algorithms[M]. Pearson Education India, 1988.
-- 何海涛, 软件工程师. 剑指 Offer: 名企面试官精讲典型编程题[M]. 电子工业出版社, 2014.
-- 《编程之美》小组. 编程之美[M]. 电子工业出版社, 2008.
-- 左程云. 程序员代码面试指南[M]. 电子工业出版社, 2015.
diff --git a/notes/Leetcode-Database 题解.md b/notes/Leetcode-Database 题解.md
deleted file mode 100644
index a9a3a89b..00000000
--- a/notes/Leetcode-Database 题解.md
+++ /dev/null
@@ -1,1098 +0,0 @@
-
-* [595. Big Countries](#595-big-countries)
-* [627. Swap Salary](#627-swap-salary)
-* [620. Not Boring Movies](#620-not-boring-movies)
-* [596. Classes More Than 5 Students](#596-classes-more-than-5-students)
-* [182. Duplicate Emails](#182-duplicate-emails)
-* [196. Delete Duplicate Emails](#196-delete-duplicate-emails)
-* [175. Combine Two Tables](#175-combine-two-tables)
-* [181. Employees Earning More Than Their Managers](#181-employees-earning-more-than-their-managers)
-* [183. Customers Who Never Order](#183-customers-who-never-order)
-* [184. Department Highest Salary](#184-department-highest-salary)
-* [176. Second Highest Salary](#176-second-highest-salary)
-* [177. Nth Highest Salary](#177-nth-highest-salary)
-* [178. Rank Scores](#178-rank-scores)
-* [180. Consecutive Numbers](#180-consecutive-numbers)
-* [626. Exchange Seats](#626-exchange-seats)
-
-
-
-# 595. Big Countries
-
-https://leetcode.com/problems/big-countries/description/
-
-## Description
-
-```html
-+-----------------+------------+------------+--------------+---------------+
-| name | continent | area | population | gdp |
-+-----------------+------------+------------+--------------+---------------+
-| Afghanistan | Asia | 652230 | 25500100 | 20343000 |
-| Albania | Europe | 28748 | 2831741 | 12960000 |
-| Algeria | Africa | 2381741 | 37100000 | 188681000 |
-| Andorra | Europe | 468 | 78115 | 3712000 |
-| Angola | Africa | 1246700 | 20609294 | 100990000 |
-+-----------------+------------+------------+--------------+---------------+
-```
-
-查找面积超过 3,000,000 或者人口数超过 25,000,000 的国家。
-
-```html
-+--------------+-------------+--------------+
-| name | population | area |
-+--------------+-------------+--------------+
-| Afghanistan | 25500100 | 652230 |
-| Algeria | 37100000 | 2381741 |
-+--------------+-------------+--------------+
-```
-
-## Solution
-
-```sql
-SELECT name,
- population,
- area
-FROM
- World
-WHERE
- area > 3000000
- OR population > 25000000;
-```
-
-## SQL Schema
-
-SQL Schema 用于在本地环境下创建表结构并导入数据,从而方便在本地环境调试。
-
-```sql
-DROP TABLE
-IF
- EXISTS World;
-CREATE TABLE World ( NAME VARCHAR ( 255 ), continent VARCHAR ( 255 ), area INT, population INT, gdp INT );
-INSERT INTO World ( NAME, continent, area, population, gdp )
-VALUES
- ( 'Afghanistan', 'Asia', '652230', '25500100', '203430000' ),
- ( 'Albania', 'Europe', '28748', '2831741', '129600000' ),
- ( 'Algeria', 'Africa', '2381741', '37100000', '1886810000' ),
- ( 'Andorra', 'Europe', '468', '78115', '37120000' ),
- ( 'Angola', 'Africa', '1246700', '20609294', '1009900000' );
-```
-
-# 627. Swap Salary
-
-https://leetcode.com/problems/swap-salary/description/
-
-## Description
-
-```html
-| id | name | sex | salary |
-|----|------|-----|--------|
-| 1 | A | m | 2500 |
-| 2 | B | f | 1500 |
-| 3 | C | m | 5500 |
-| 4 | D | f | 500 |
-```
-
-只用一个 SQL 查询,将 sex 字段反转。
-
-```html
-| id | name | sex | salary |
-|----|------|-----|--------|
-| 1 | A | f | 2500 |
-| 2 | B | m | 1500 |
-| 3 | C | f | 5500 |
-| 4 | D | m | 500 |
-```
-
-## Solution
-
-两个相等的数异或的结果为 0,而 0 与任何一个数异或的结果为这个数。
-
-sex 字段只有两个取值:'f' 和 'm',并且有以下规律:
-
-```
-'f' ^ ('m' ^ 'f') = 'm' ^ ('f' ^ 'f') = 'm'
-'m' ^ ('m' ^ 'f') = 'f' ^ ('m' ^ 'm') = 'f'
-```
-
-因此将 sex 字段和 'm' ^ 'f' 进行异或操作,最后就能反转 sex 字段。
-
-```sql
-UPDATE salary
-SET sex = CHAR ( ASCII(sex) ^ ASCII( 'm' ) ^ ASCII( 'f' ) );
-```
-
-## SQL Schema
-
-```sql
-DROP TABLE
-IF
- EXISTS salary;
-CREATE TABLE salary ( id INT, NAME VARCHAR ( 100 ), sex CHAR ( 1 ), salary INT );
-INSERT INTO salary ( id, NAME, sex, salary )
-VALUES
- ( '1', 'A', 'm', '2500' ),
- ( '2', 'B', 'f', '1500' ),
- ( '3', 'C', 'm', '5500' ),
- ( '4', 'D', 'f', '500' );
-```
-
-# 620. Not Boring Movies
-
-https://leetcode.com/problems/not-boring-movies/description/
-
-## Description
-
-
-```html
-+---------+-----------+--------------+-----------+
-| id | movie | description | rating |
-+---------+-----------+--------------+-----------+
-| 1 | War | great 3D | 8.9 |
-| 2 | Science | fiction | 8.5 |
-| 3 | irish | boring | 6.2 |
-| 4 | Ice song | Fantacy | 8.6 |
-| 5 | House card| Interesting| 9.1 |
-+---------+-----------+--------------+-----------+
-```
-
-查找 id 为奇数,并且 description 不是 boring 的电影,按 rating 降序。
-
-```html
-+---------+-----------+--------------+-----------+
-| id | movie | description | rating |
-+---------+-----------+--------------+-----------+
-| 5 | House card| Interesting| 9.1 |
-| 1 | War | great 3D | 8.9 |
-+---------+-----------+--------------+-----------+
-```
-
-## Solution
-
-```sql
-SELECT
- *
-FROM
- cinema
-WHERE
- id % 2 = 1
- AND description != 'boring'
-ORDER BY
- rating DESC;
-```
-
-## SQL Schema
-
-```sql
-DROP TABLE
-IF
- EXISTS cinema;
-CREATE TABLE cinema ( id INT, movie VARCHAR ( 255 ), description VARCHAR ( 255 ), rating FLOAT ( 2, 1 ) );
-INSERT INTO cinema ( id, movie, description, rating )
-VALUES
- ( 1, 'War', 'great 3D', 8.9 ),
- ( 2, 'Science', 'fiction', 8.5 ),
- ( 3, 'irish', 'boring', 6.2 ),
- ( 4, 'Ice song', 'Fantacy', 8.6 ),
- ( 5, 'House card', 'Interesting', 9.1 );
-```
-
-# 596. Classes More Than 5 Students
-
-https://leetcode.com/problems/classes-more-than-5-students/description/
-
-## Description
-
-```html
-+---------+------------+
-| student | class |
-+---------+------------+
-| A | Math |
-| B | English |
-| C | Math |
-| D | Biology |
-| E | Math |
-| F | Computer |
-| G | Math |
-| H | Math |
-| I | Math |
-+---------+------------+
-```
-
-查找有五名及以上 student 的 class。
-
-```html
-+---------+
-| class |
-+---------+
-| Math |
-+---------+
-```
-
-## Solution
-
-对 class 列进行分组之后,再使用 count 汇总函数统计每个分组的记录个数,之后使用 HAVING 进行筛选。HAVING 针对分组进行筛选,而 WHERE 针对每个记录(行)进行筛选。
-
-```sql
-SELECT
- class
-FROM
- courses
-GROUP BY
- class
-HAVING
- count( DISTINCT student ) >= 5;
-```
-
-## SQL Schema
-
-```sql
-DROP TABLE
-IF
- EXISTS courses;
-CREATE TABLE courses ( student VARCHAR ( 255 ), class VARCHAR ( 255 ) );
-INSERT INTO courses ( student, class )
-VALUES
- ( 'A', 'Math' ),
- ( 'B', 'English' ),
- ( 'C', 'Math' ),
- ( 'D', 'Biology' ),
- ( 'E', 'Math' ),
- ( 'F', 'Computer' ),
- ( 'G', 'Math' ),
- ( 'H', 'Math' ),
- ( 'I', 'Math' );
-```
-
-# 182. Duplicate Emails
-
-https://leetcode.com/problems/duplicate-emails/description/
-
-## Description
-
-邮件地址表:
-
-```html
-+----+---------+
-| Id | Email |
-+----+---------+
-| 1 | a@b.com |
-| 2 | c@d.com |
-| 3 | a@b.com |
-+----+---------+
-```
-
-查找重复的邮件地址:
-
-```html
-+---------+
-| Email |
-+---------+
-| a@b.com |
-+---------+
-```
-
-## Solution
-
-对 Email 进行分组,如果并使用 COUNT 进行计数统计,结果大于等于 2 的表示 Email 重复。
-
-```sql
-SELECT
- Email
-FROM
- Person
-GROUP BY
- Email
-HAVING
- COUNT( * ) >= 2;
-```
-
-## SQL Schema
-
-```sql
-DROP TABLE
-IF
- EXISTS Person;
-CREATE TABLE Person ( Id INT, Email VARCHAR ( 255 ) );
-INSERT INTO Person ( Id, Email )
-VALUES
- ( 1, 'a@b.com' ),
- ( 2, 'c@d.com' ),
- ( 3, 'a@b.com' );
-```
-
-
-# 196. Delete Duplicate Emails
-
-https://leetcode.com/problems/delete-duplicate-emails/description/
-
-## Description
-
-邮件地址表:
-
-```html
-+----+---------+
-| Id | Email |
-+----+---------+
-| 1 | john@example.com |
-| 2 | bob@example.com |
-| 3 | john@example.com |
-+----+---------+
-```
-
-删除重复的邮件地址:
-
-```html
-+----+------------------+
-| Id | Email |
-+----+------------------+
-| 1 | john@example.com |
-| 2 | bob@example.com |
-+----+------------------+
-```
-
-## Solution
-
-只保留相同 Email 中 Id 最小的那一个,然后删除其它的。
-
-连接查询:
-
-```sql
-DELETE p1
-FROM
- Person p1,
- Person p2
-WHERE
- p1.Email = p2.Email
- AND p1.Id > p2.Id
-```
-
-子查询:
-
-```sql
-DELETE
-FROM
- Person
-WHERE
- id NOT IN (
- SELECT id
- FROM (
- SELECT min( id ) AS id
- FROM Person
- GROUP BY email
- ) AS m
- );
-```
-
-应该注意的是上述解法额外嵌套了一个 SELECT 语句,如果不这么做,会出现错误:You can't specify target table 'Person' for update in FROM clause。以下演示了这种错误解法。
-
-```sql
-DELETE
-FROM
- Person
-WHERE
- id NOT IN (
- SELECT min( id ) AS id
- FROM Person
- GROUP BY email
- );
-```
-
-参考:[pMySQL Error 1093 - Can't specify target table for update in FROM clause](https://stackoverflow.com/questions/45494/mysql-error-1093-cant-specify-target-table-for-update-in-from-clause)
-
-## SQL Schema
-
-与 182 相同。
-
-# 175. Combine Two Tables
-
-https://leetcode.com/problems/combine-two-tables/description/
-
-## Description
-
-Person 表:
-
-```html
-+-------------+---------+
-| Column Name | Type |
-+-------------+---------+
-| PersonId | int |
-| FirstName | varchar |
-| LastName | varchar |
-+-------------+---------+
-PersonId is the primary key column for this table.
-```
-
-Address 表:
-
-```html
-+-------------+---------+
-| Column Name | Type |
-+-------------+---------+
-| AddressId | int |
-| PersonId | int |
-| City | varchar |
-| State | varchar |
-+-------------+---------+
-AddressId is the primary key column for this table.
-```
-
-查找 FirstName, LastName, City, State 数据,而不管一个用户有没有填地址信息。
-
-## Solution
-
-涉及到 Person 和 Address 两个表,在对这两个表执行连接操作时,因为要保留 Person 表中的信息,即使在 Address 表中没有关联的信息也要保留。此时可以用左外连接,将 Person 表放在 LEFT JOIN 的左边。
-
-```sql
-SELECT
- FirstName,
- LastName,
- City,
- State
-FROM
- Person P
- LEFT JOIN Address A
- ON P.PersonId = A.PersonId;
-```
-
-## SQL Schema
-
-```sql
-DROP TABLE
-IF
- EXISTS Person;
-CREATE TABLE Person ( PersonId INT, FirstName VARCHAR ( 255 ), LastName VARCHAR ( 255 ) );
-DROP TABLE
-IF
- EXISTS Address;
-CREATE TABLE Address ( AddressId INT, PersonId INT, City VARCHAR ( 255 ), State VARCHAR ( 255 ) );
-INSERT INTO Person ( PersonId, LastName, FirstName )
-VALUES
- ( 1, 'Wang', 'Allen' );
-INSERT INTO Address ( AddressId, PersonId, City, State )
-VALUES
- ( 1, 2, 'New York City', 'New York' );
-```
-
-# 181. Employees Earning More Than Their Managers
-
-https://leetcode.com/problems/employees-earning-more-than-their-managers/description/
-
-## Description
-
-Employee 表:
-
-```html
-+----+-------+--------+-----------+
-| Id | Name | Salary | ManagerId |
-+----+-------+--------+-----------+
-| 1 | Joe | 70000 | 3 |
-| 2 | Henry | 80000 | 4 |
-| 3 | Sam | 60000 | NULL |
-| 4 | Max | 90000 | NULL |
-+----+-------+--------+-----------+
-```
-
-查找薪资大于其经理薪资的员工信息。
-
-## Solution
-
-```sql
-SELECT
- E1.NAME AS Employee
-FROM
- Employee E1
- INNER JOIN Employee E2
- ON E1.ManagerId = E2.Id
- AND E1.Salary > E2.Salary;
-```
-
-## SQL Schema
-
-```sql
-DROP TABLE
-IF
- EXISTS Employee;
-CREATE TABLE Employee ( Id INT, NAME VARCHAR ( 255 ), Salary INT, ManagerId INT );
-INSERT INTO Employee ( Id, NAME, Salary, ManagerId )
-VALUES
- ( 1, 'Joe', 70000, 3 ),
- ( 2, 'Henry', 80000, 4 ),
- ( 3, 'Sam', 60000, NULL ),
- ( 4, 'Max', 90000, NULL );
-```
-
-# 183. Customers Who Never Order
-
-https://leetcode.com/problems/customers-who-never-order/description/
-
-## Description
-
-Customers 表:
-
-```html
-+----+-------+
-| Id | Name |
-+----+-------+
-| 1 | Joe |
-| 2 | Henry |
-| 3 | Sam |
-| 4 | Max |
-+----+-------+
-```
-
-Orders 表:
-
-```html
-+----+------------+
-| Id | CustomerId |
-+----+------------+
-| 1 | 3 |
-| 2 | 1 |
-+----+------------+
-```
-
-查找没有订单的顾客信息:
-
-```html
-+-----------+
-| Customers |
-+-----------+
-| Henry |
-| Max |
-+-----------+
-```
-
-## Solution
-
-左外链接
-
-```sql
-SELECT
- C.Name AS Customers
-FROM
- Customers C
- LEFT JOIN Orders O
- ON C.Id = O.CustomerId
-WHERE
- O.CustomerId IS NULL;
-```
-
-子查询
-
-```sql
-SELECT
- Name AS Customers
-FROM
- Customers
-WHERE
- Id NOT IN (
- SELECT CustomerId
- FROM Orders
- );
-```
-
-## SQL Schema
-
-```sql
-DROP TABLE
-IF
- EXISTS Customers;
-CREATE TABLE Customers ( Id INT, NAME VARCHAR ( 255 ) );
-DROP TABLE
-IF
- EXISTS Orders;
-CREATE TABLE Orders ( Id INT, CustomerId INT );
-INSERT INTO Customers ( Id, NAME )
-VALUES
- ( 1, 'Joe' ),
- ( 2, 'Henry' ),
- ( 3, 'Sam' ),
- ( 4, 'Max' );
-INSERT INTO Orders ( Id, CustomerId )
-VALUES
- ( 1, 3 ),
- ( 2, 1 );
-```
-
-# 184. Department Highest Salary
-
-https://leetcode.com/problems/department-highest-salary/description/
-
-## Description
-
-Employee 表:
-
-```html
-+----+-------+--------+--------------+
-| Id | Name | Salary | DepartmentId |
-+----+-------+--------+--------------+
-| 1 | Joe | 70000 | 1 |
-| 2 | Henry | 80000 | 2 |
-| 3 | Sam | 60000 | 2 |
-| 4 | Max | 90000 | 1 |
-+----+-------+--------+--------------+
-```
-
-Department 表:
-
-```html
-+----+----------+
-| Id | Name |
-+----+----------+
-| 1 | IT |
-| 2 | Sales |
-+----+----------+
-```
-
-查找一个 Department 中收入最高者的信息:
-
-```html
-+------------+----------+--------+
-| Department | Employee | Salary |
-+------------+----------+--------+
-| IT | Max | 90000 |
-| Sales | Henry | 80000 |
-+------------+----------+--------+
-```
-
-## Solution
-
-创建一个临时表,包含了部门员工的最大薪资。可以对部门进行分组,然后使用 MAX() 汇总函数取得最大薪资。
-
-之后使用连接找到一个部门中薪资等于临时表中最大薪资的员工。
-
-```sql
-SELECT
- D.NAME Department,
- E.NAME Employee,
- E.Salary
-FROM
- Employee E,
- Department D,
- ( SELECT DepartmentId, MAX( Salary ) Salary
- FROM Employee
- GROUP BY DepartmentId ) M
-WHERE
- E.DepartmentId = D.Id
- AND E.DepartmentId = M.DepartmentId
- AND E.Salary = M.Salary;
-```
-
-## SQL Schema
-
-```sql
-DROP TABLE IF EXISTS Employee;
-CREATE TABLE Employee ( Id INT, NAME VARCHAR ( 255 ), Salary INT, DepartmentId INT );
-DROP TABLE IF EXISTS Department;
-CREATE TABLE Department ( Id INT, NAME VARCHAR ( 255 ) );
-INSERT INTO Employee ( Id, NAME, Salary, DepartmentId )
-VALUES
- ( 1, 'Joe', 70000, 1 ),
- ( 2, 'Henry', 80000, 2 ),
- ( 3, 'Sam', 60000, 2 ),
- ( 4, 'Max', 90000, 1 );
-INSERT INTO Department ( Id, NAME )
-VALUES
- ( 1, 'IT' ),
- ( 2, 'Sales' );
-```
-
-
-# 176. Second Highest Salary
-
-https://leetcode.com/problems/second-highest-salary/description/
-
-## Description
-
-```html
-+----+--------+
-| Id | Salary |
-+----+--------+
-| 1 | 100 |
-| 2 | 200 |
-| 3 | 300 |
-+----+--------+
-```
-
-查找工资第二高的员工。
-
-```html
-+---------------------+
-| SecondHighestSalary |
-+---------------------+
-| 200 |
-+---------------------+
-```
-
-没有找到返回 null 而不是不返回数据。
-
-## Solution
-
-为了在没有查找到数据时返回 null,需要在查询结果外面再套一层 SELECT。
-
-```sql
-SELECT
- ( SELECT DISTINCT Salary
- FROM Employee
- ORDER BY Salary DESC
- LIMIT 1, 1 ) SecondHighestSalary;
-```
-
-## SQL Schema
-
-```sql
-DROP TABLE
-IF
- EXISTS Employee;
-CREATE TABLE Employee ( Id INT, Salary INT );
-INSERT INTO Employee ( Id, Salary )
-VALUES
- ( 1, 100 ),
- ( 2, 200 ),
- ( 3, 300 );
-```
-
-# 177. Nth Highest Salary
-
-## Description
-
-查找工资第 N 高的员工。
-
-## Solution
-
-```sql
-CREATE FUNCTION getNthHighestSalary ( N INT ) RETURNS INT BEGIN
-
-SET N = N - 1;
-RETURN (
- SELECT (
- SELECT DISTINCT Salary
- FROM Employee
- ORDER BY Salary DESC
- LIMIT N, 1
- )
-);
-
-END
-```
-
-## SQL Schema
-
-同 176。
-
-
-# 178. Rank Scores
-
-https://leetcode.com/problems/rank-scores/description/
-
-## Description
-
-得分表:
-
-```html
-+----+-------+
-| Id | Score |
-+----+-------+
-| 1 | 3.50 |
-| 2 | 3.65 |
-| 3 | 4.00 |
-| 4 | 3.85 |
-| 5 | 4.00 |
-| 6 | 3.65 |
-+----+-------+
-```
-
-将得分排序,并统计排名。
-
-```html
-+-------+------+
-| Score | Rank |
-+-------+------+
-| 4.00 | 1 |
-| 4.00 | 1 |
-| 3.85 | 2 |
-| 3.65 | 3 |
-| 3.65 | 3 |
-| 3.50 | 4 |
-+-------+------+
-```
-
-## Solution
-
-要统计某个 score 的排名,只要统计大于等于该 score 的 score 数量。
-
-| Id | score | 大于等于该 score 的 score 数量 | 排名 |
-| :---: | :---: | :---: | :---: |
-| 1 | 4.1 | 3 | 3 |
-| 2 | 4.2 | 2 | 2 |
-| 3 | 4.3 | 1 | 1 |
-
-使用连接操作找到某个 score 对应的大于等于其值的记录:
-
-```sql
-SELECT
- *
-FROM
- Scores S1
- INNER JOIN Scores S2
- ON S1.score <= S2.score
-ORDER BY
- S1.score DESC, S1.Id;
-```
-
-| S1.Id | S1.score | S2.Id | S2.score |
-| :---: | :---: | :---: | :---: |
-|3| 4.3| 3 |4.3|
-|2| 4.2| 2| 4.2|
-|2| 4.2 |3 |4.3|
-|1| 4.1 |1| 4.1|
-|1| 4.1 |2| 4.2|
-|1| 4.1 |3| 4.3|
-
-可以看到每个 S1.score 都有对应好几条记录,我们再进行分组,并统计每个分组的数量作为 'Rank'
-
-```sql
-SELECT
- S1.score 'Score',
- COUNT(*) 'Rank'
-FROM
- Scores S1
- INNER JOIN Scores S2
- ON S1.score <= S2.score
-GROUP BY
- S1.id, S1.score
-ORDER BY
- S1.score DESC, S1.Id;
-```
-
-| score | Rank |
-| :---: | :---: |
-| 4.3 | 1 |
-| 4.2 | 2 |
-| 4.1 | 3 |
-
-上面的解法看似没问题,但是对于以下数据,它却得到了错误的结果:
-
-| Id | score |
-| :---: | :---: |
-| 1 | 4.1 |
-| 2 | 4.2 |
-| 3 | 4.2 |
-
-| score | Rank |
-| :---: | :--: |
-| 4.2 | 2 |
-| 4.2 | 2 |
-| 4.1 | 3 |
-
-而我们希望的结果为:
-
-| score | Rank |
-| :---: | :--: |
-| 4.2 | 1 |
-| 4.2 | 1 |
-| 4.1 | 2 |
-
-连接情况如下:
-
-| S1.Id | S1.score | S2.Id | S2.score |
-| :---: | :------: | :---: | :------: |
-| 2 | 4.2 | 3 | 4.2 |
-| 2 | 4.2 | 2 | 4.2 |
-| 3 | 4.2 | 3 | 4.2 |
-| 3 | 4.2 | 2 | 4.1 |
-| 1 | 4.1 | 3 | 4.2 |
-| 1 | 4.1 | 2 | 4.2 |
-| 1 | 4.1 | 1 | 4.1 |
-
-我们想要的结果是,把分数相同的放在同一个排名,并且相同分数只占一个位置,例如上面的分数,Id=2 和 Id=3 的记录都有相同的分数,并且最高,他们并列第一。而 Id=1 的记录应该排第二名,而不是第三名。所以在进行 COUNT 计数统计时,我们需要使用 COUNT( DISTINCT S2.score ) 从而只统计一次相同的分数。
-
-```sql
-SELECT
- S1.score 'Score',
- COUNT( DISTINCT S2.score ) 'Rank'
-FROM
- Scores S1
- INNER JOIN Scores S2
- ON S1.score <= S2.score
-GROUP BY
- S1.id, S1.score
-ORDER BY
- S1.score DESC;
-```
-
-## SQL Schema
-
-```sql
-DROP TABLE
-IF
- EXISTS Scores;
-CREATE TABLE Scores ( Id INT, Score DECIMAL ( 3, 2 ) );
-INSERT INTO Scores ( Id, Score )
-VALUES
- ( 1, 4.1 ),
- ( 2, 4.1 ),
- ( 3, 4.2 ),
- ( 4, 4.2 ),
- ( 5, 4.3 ),
- ( 6, 4.3 );
-```
-
-# 180. Consecutive Numbers
-
-https://leetcode.com/problems/consecutive-numbers/description/
-
-## Description
-
-数字表:
-
-```html
-+----+-----+
-| Id | Num |
-+----+-----+
-| 1 | 1 |
-| 2 | 1 |
-| 3 | 1 |
-| 4 | 2 |
-| 5 | 1 |
-| 6 | 2 |
-| 7 | 2 |
-+----+-----+
-```
-
-查找连续出现三次的数字。
-
-```html
-+-----------------+
-| ConsecutiveNums |
-+-----------------+
-| 1 |
-+-----------------+
-```
-
-## Solution
-
-```sql
-SELECT
- DISTINCT L1.num ConsecutiveNums
-FROM
- Logs L1,
- Logs L2,
- Logs L3
-WHERE L1.id = l2.id - 1
- AND L2.id = L3.id - 1
- AND L1.num = L2.num
- AND l2.num = l3.num;
-```
-
-## SQL Schema
-
-```sql
-DROP TABLE
-IF
- EXISTS LOGS;
-CREATE TABLE LOGS ( Id INT, Num INT );
-INSERT INTO LOGS ( Id, Num )
-VALUES
- ( 1, 1 ),
- ( 2, 1 ),
- ( 3, 1 ),
- ( 4, 2 ),
- ( 5, 1 ),
- ( 6, 2 ),
- ( 7, 2 );
-```
-
-# 626. Exchange Seats
-
-https://leetcode.com/problems/exchange-seats/description/
-
-## Description
-
-seat 表存储着座位对应的学生。
-
-```html
-+---------+---------+
-| id | student |
-+---------+---------+
-| 1 | Abbot |
-| 2 | Doris |
-| 3 | Emerson |
-| 4 | Green |
-| 5 | Jeames |
-+---------+---------+
-```
-
-要求交换相邻座位的两个学生,如果最后一个座位是奇数,那么不交换这个座位上的学生。
-
-```html
-+---------+---------+
-| id | student |
-+---------+---------+
-| 1 | Doris |
-| 2 | Abbot |
-| 3 | Green |
-| 4 | Emerson |
-| 5 | Jeames |
-+---------+---------+
-```
-
-## Solution
-
-使用多个 union。
-
-```sql
-# 处理偶数 id,让 id 减 1
-# 例如 2,4,6,... 变成 1,3,5,...
-SELECT
- s1.id - 1 AS id,
- s1.student
-FROM
- seat s1
-WHERE
- s1.id MOD 2 = 0 UNION
-# 处理奇数 id,让 id 加 1。但是如果最大的 id 为奇数,则不做处理
-# 例如 1,3,5,... 变成 2,4,6,...
-SELECT
- s2.id + 1 AS id,
- s2.student
-FROM
- seat s2
-WHERE
- s2.id MOD 2 = 1
- AND s2.id != ( SELECT max( s3.id ) FROM seat s3 ) UNION
-# 如果最大的 id 为奇数,单独取出这个数
-SELECT
- s4.id AS id,
- s4.student
-FROM
- seat s4
-WHERE
- s4.id MOD 2 = 1
- AND s4.id = ( SELECT max( s5.id ) FROM seat s5 )
-ORDER BY
- id;
-```
-
-## SQL Schema
-
-```sql
-DROP TABLE
-IF
- EXISTS seat;
-CREATE TABLE seat ( id INT, student VARCHAR ( 255 ) );
-INSERT INTO seat ( id, student )
-VALUES
- ( '1', 'Abbot' ),
- ( '2', 'Doris' ),
- ( '3', 'Emerson' ),
- ( '4', 'Green' ),
- ( '5', 'Jeames' );
-```
-
-
-
-
-
-
-
diff --git a/notes/Linux.md b/notes/Linux.md
index abf6f8f7..c31cccc9 100644
--- a/notes/Linux.md
+++ b/notes/Linux.md
@@ -3,15 +3,69 @@
* [Linux](#linux)
* [前言](#前言)
* [一、常用操作以及概念](#一常用操作以及概念)
+ * [快捷键](#快捷键)
+ * [求助](#求助)
+ * [关机](#关机)
+ * [PATH](#path)
+ * [sudo](#sudo)
+ * [包管理工具](#包管理工具)
+ * [发行版](#发行版)
+ * [VIM 三个模式](#vim-三个模式)
+ * [GNU](#gnu)
+ * [开源协议](#开源协议)
* [二、磁盘](#二磁盘)
+ * [磁盘接口](#磁盘接口)
+ * [磁盘的文件名](#磁盘的文件名)
* [三、分区](#三分区)
+ * [分区表](#分区表)
+ * [开机检测程序](#开机检测程序)
* [四、文件系统](#四文件系统)
+ * [分区与文件系统](#分区与文件系统)
+ * [组成](#组成)
+ * [文件读取](#文件读取)
+ * [磁盘碎片](#磁盘碎片)
+ * [block](#block)
+ * [inode](#inode)
+ * [目录](#目录)
+ * [日志](#日志)
+ * [挂载](#挂载)
+ * [目录配置](#目录配置)
* [五、文件](#五文件)
+ * [文件属性](#文件属性)
+ * [文件与目录的基本操作](#文件与目录的基本操作)
+ * [修改权限](#修改权限)
+ * [默认权限](#默认权限)
+ * [目录的权限](#目录的权限)
+ * [链接](#链接)
+ * [获取文件内容](#获取文件内容)
+ * [指令与文件搜索](#指令与文件搜索)
* [六、压缩与打包](#六压缩与打包)
+ * [压缩文件名](#压缩文件名)
+ * [压缩指令](#压缩指令)
+ * [打包](#打包)
* [七、Bash](#七bash)
+ * [特性](#特性)
+ * [变量操作](#变量操作)
+ * [指令搜索顺序](#指令搜索顺序)
+ * [数据流重定向](#数据流重定向)
* [八、管道指令](#八管道指令)
+ * [提取指令](#提取指令)
+ * [排序指令](#排序指令)
+ * [双向输出重定向](#双向输出重定向)
+ * [字符转换指令](#字符转换指令)
+ * [分区指令](#分区指令)
* [九、正则表达式](#九正则表达式)
+ * [grep](#grep)
+ * [printf](#printf)
+ * [awk](#awk)
* [十、进程管理](#十进程管理)
+ * [查看进程](#查看进程)
+ * [进程状态](#进程状态)
+ * [SIGCHLD](#sigchld)
+ * [wait()](#wait)
+ * [waitpid()](#waitpid)
+ * [孤儿进程](#孤儿进程)
+ * [僵尸进程](#僵尸进程)
* [参考资料](#参考资料)
diff --git a/notes/MySQL.md b/notes/MySQL.md
index c2614c2f..ddb601fb 100644
--- a/notes/MySQL.md
+++ b/notes/MySQL.md
@@ -2,11 +2,32 @@
* [MySQL](#mysql)
* [一、索引](#一索引)
+ * [B+ Tree 原理](#b-tree-原理)
+ * [MySQL 索引](#mysql-索引)
+ * [索引优化](#索引优化)
+ * [索引的优点](#索引的优点)
+ * [索引的使用条件](#索引的使用条件)
* [二、查询性能优化](#二查询性能优化)
+ * [使用 Explain 进行分析](#使用-explain-进行分析)
+ * [优化数据访问](#优化数据访问)
+ * [重构查询方式](#重构查询方式)
* [三、存储引擎](#三存储引擎)
+ * [InnoDB](#innodb)
+ * [MyISAM](#myisam)
+ * [比较](#比较)
* [四、数据类型](#四数据类型)
+ * [整型](#整型)
+ * [浮点数](#浮点数)
+ * [字符串](#字符串)
+ * [时间和日期](#时间和日期)
* [五、切分](#五切分)
+ * [水平切分](#水平切分)
+ * [垂直切分](#垂直切分)
+ * [Sharding 策略](#sharding-策略)
+ * [Sharding 存在的问题](#sharding-存在的问题)
* [六、复制](#六复制)
+ * [主从复制](#主从复制)
+ * [读写分离](#读写分离)
* [参考资料](#参考资料)
diff --git a/notes/Redis.md b/notes/Redis.md
index b2dd3b6c..b41f5d8c 100644
--- a/notes/Redis.md
+++ b/notes/Redis.md
@@ -3,18 +3,46 @@
* [Redis](#redis)
* [一、概述](#一概述)
* [二、数据类型](#二数据类型)
+ * [STRING](#string)
+ * [LIST](#list)
+ * [SET](#set)
+ * [HASH](#hash)
+ * [ZSET](#zset)
* [三、数据结构](#三数据结构)
+ * [字典](#字典)
+ * [跳跃表](#跳跃表)
* [四、使用场景](#四使用场景)
+ * [计数器](#计数器)
+ * [缓存](#缓存)
+ * [查找表](#查找表)
+ * [消息队列](#消息队列)
+ * [会话缓存](#会话缓存)
+ * [分布式锁实现](#分布式锁实现)
+ * [其它](#其它)
* [五、Redis 与 Memcached](#五redis-与-memcached)
+ * [数据类型](#数据类型)
+ * [数据持久化](#数据持久化)
+ * [分布式](#分布式)
+ * [内存管理机制](#内存管理机制)
* [六、键的过期时间](#六键的过期时间)
* [七、数据淘汰策略](#七数据淘汰策略)
* [八、持久化](#八持久化)
+ * [RDB 持久化](#rdb-持久化)
+ * [AOF 持久化](#aof-持久化)
* [九、事务](#九事务)
* [十、事件](#十事件)
+ * [文件事件](#文件事件)
+ * [时间事件](#时间事件)
+ * [事件的调度与执行](#事件的调度与执行)
* [十一、复制](#十一复制)
+ * [连接过程](#连接过程)
+ * [主从链](#主从链)
* [十二、Sentinel](#十二sentinel)
* [十三、分片](#十三分片)
* [十四、一个简单的论坛系统分析](#十四一个简单的论坛系统分析)
+ * [文章信息](#文章信息)
+ * [点赞功能](#点赞功能)
+ * [对文章进行排序](#对文章进行排序)
* [参考资料](#参考资料)
@@ -37,7 +65,7 @@ Redis 支持很多特性,例如将内存中的数据持久化到硬盘中,
| HASH | 包含键值对的无序散列表 | 添加、获取、移除单个键值对\ 获取所有键值对\ 检查某个键是否存在|
| ZSET | 有序集合 | 添加、获取、删除元素\ 根据分值范围或者成员来获取元素\ 计算一个键的排名 |
-\> [What Redis data structures look like](https://redislabs.com/ebook/part-1-getting-started/chapter-1-getting-to-know-redis/1-2-what-redis-data-structures-look-like/)
+> [What Redis data structures look like](https://redislabs.com/ebook/part-1-getting-started/chapter-1-getting-to-know-redis/1-2-what-redis-data-structures-look-like/)
### STRING
diff --git a/notes/SQL 练习.md b/notes/SQL 练习.md
index 6bc0d33a..97421e1d 100644
--- a/notes/SQL 练习.md
+++ b/notes/SQL 练习.md
@@ -1,6 +1,21 @@
# SQL 练习
* [SQL 练习](#sql-练习)
+ * [595. Big Countries](#595-big-countries)
+ * [627. Swap Salary](#627-swap-salary)
+ * [620. Not Boring Movies](#620-not-boring-movies)
+ * [596. Classes More Than 5 Students](#596-classes-more-than-5-students)
+ * [182. Duplicate Emails](#182-duplicate-emails)
+ * [196. Delete Duplicate Emails](#196-delete-duplicate-emails)
+ * [175. Combine Two Tables](#175-combine-two-tables)
+ * [181. Employees Earning More Than Their Managers](#181-employees-earning-more-than-their-managers)
+ * [183. Customers Who Never Order](#183-customers-who-never-order)
+ * [184. Department Highest Salary](#184-department-highest-salary)
+ * [176. Second Highest Salary](#176-second-highest-salary)
+ * [177. Nth Highest Salary](#177-nth-highest-salary)
+ * [178. Rank Scores](#178-rank-scores)
+ * [180. Consecutive Numbers](#180-consecutive-numbers)
+ * [626. Exchange Seats](#626-exchange-seats)
diff --git a/notes/SQL.md b/notes/SQL.md
index 3d029858..7e5f1636 100644
--- a/notes/SQL.md
+++ b/notes/SQL.md
@@ -6,14 +6,24 @@
* [五、更新](#五更新)
* [六、删除](#六删除)
* [七、查询](#七查询)
+ * [DISTINCT](#distinct)
+ * [LIMIT](#limit)
* [八、排序](#八排序)
* [九、过滤](#九过滤)
* [十、通配符](#十通配符)
* [十一、计算字段](#十一计算字段)
* [十二、函数](#十二函数)
+ * [汇总](#汇总)
+ * [文本处理](#文本处理)
+ * [日期和时间处理](#日期和时间处理)
+ * [数值处理](#数值处理)
* [十三、分组](#十三分组)
* [十四、子查询](#十四子查询)
* [十五、连接](#十五连接)
+ * [内连接](#内连接)
+ * [自连接](#自连接)
+ * [自然连接](#自然连接)
+ * [外连接](#外连接)
* [十六、组合查询](#十六组合查询)
* [十七、视图](#十七视图)
* [十八、存储过程](#十八存储过程)
diff --git a/notes/Socket.md b/notes/Socket.md
index afa27932..2348ebfa 100644
--- a/notes/Socket.md
+++ b/notes/Socket.md
@@ -2,7 +2,19 @@
* [Socket](#socket)
* [一、I/O 模型](#一io-模型)
+ * [阻塞式 I/O](#阻塞式-io)
+ * [非阻塞式 I/O](#非阻塞式-io)
+ * [I/O 复用](#io-复用)
+ * [信号驱动 I/O](#信号驱动-io)
+ * [异步 I/O](#异步-io)
+ * [五大 I/O 模型比较](#五大-io-模型比较)
* [二、I/O 复用](#二io-复用)
+ * [select](#select)
+ * [poll](#poll)
+ * [比较](#比较)
+ * [epoll](#epoll)
+ * [工作模式](#工作模式)
+ * [应用场景](#应用场景)
* [参考资料](#参考资料)
diff --git a/notes/分布式.md b/notes/分布式.md
index 63159197..318001b9 100644
--- a/notes/分布式.md
+++ b/notes/分布式.md
@@ -2,11 +2,29 @@
* [分布式](#分布式)
* [一、分布式锁](#一分布式锁)
+ * [数据库的唯一索引](#数据库的唯一索引)
+ * [Redis 的 SETNX 指令](#redis-的-setnx-指令)
+ * [Redis 的 RedLock 算法](#redis-的-redlock-算法)
+ * [Zookeeper 的有序节点](#zookeeper-的有序节点)
* [二、分布式事务](#二分布式事务)
+ * [2PC](#2pc)
+ * [本地消息表](#本地消息表)
* [三、CAP](#三cap)
+ * [一致性](#一致性)
+ * [可用性](#可用性)
+ * [分区容忍性](#分区容忍性)
+ * [权衡](#权衡)
* [四、BASE](#四base)
+ * [基本可用](#基本可用)
+ * [软状态](#软状态)
+ * [最终一致性](#最终一致性)
* [五、Paxos](#五paxos)
+ * [执行过程](#执行过程)
+ * [约束条件](#约束条件)
* [六、Raft](#六raft)
+ * [单个 Candidate 的竞选](#单个-candidate-的竞选)
+ * [多个 Candidate 竞选](#多个-candidate-竞选)
+ * [数据同步](#数据同步)
* [参考](#参考)
diff --git a/notes/剑指 Offer 题解 - 10~19.md b/notes/剑指 Offer 题解 - 10~19.md
deleted file mode 100644
index 1be8c6c6..00000000
--- a/notes/剑指 Offer 题解 - 10~19.md
+++ /dev/null
@@ -1,692 +0,0 @@
-
-* [10.1 斐波那契数列](#101-斐波那契数列)
-* [10.2 矩形覆盖](#102-矩形覆盖)
-* [10.3 跳台阶](#103-跳台阶)
-* [10.4 变态跳台阶](#104-变态跳台阶)
-* [11. 旋转数组的最小数字](#11-旋转数组的最小数字)
-* [12. 矩阵中的路径](#12-矩阵中的路径)
-* [13. 机器人的运动范围](#13-机器人的运动范围)
-* [14. 剪绳子](#14-剪绳子)
-* [15. 二进制中 1 的个数](#15-二进制中-1-的个数)
-* [16. 数值的整数次方](#16-数值的整数次方)
-* [17. 打印从 1 到最大的 n 位数](#17-打印从-1-到最大的-n-位数)
-* [18.1 在 O(1) 时间内删除链表节点](#181-在-o1-时间内删除链表节点)
-* [18.2 删除链表中重复的结点](#182-删除链表中重复的结点)
-* [19. 正则表达式匹配](#19-正则表达式匹配)
-
-
-
-# 10.1 斐波那契数列
-
-[NowCoder](https://www.nowcoder.com/practice/c6c7742f5ba7442aada113136ddea0c3?tpId=13&tqId=11160&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-求斐波那契数列的第 n 项,n \<= 39。
-
-
-
-
-
-## 解题思路
-
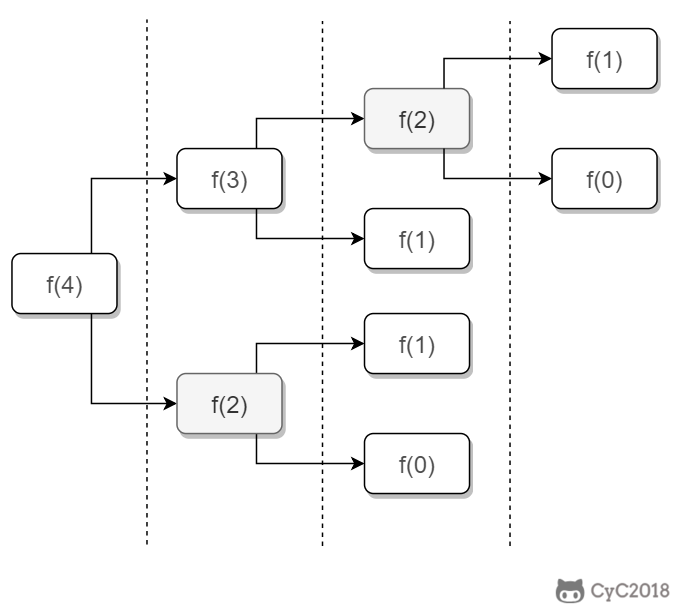
-如果使用递归求解,会重复计算一些子问题。例如,计算 f(4) 需要计算 f(3) 和 f(2),计算 f(3) 需要计算 f(2) 和 f(1),可以看到 f(2) 被重复计算了。
-
-
-
-递归是将一个问题划分成多个子问题求解,动态规划也是如此,但是动态规划会把子问题的解缓存起来,从而避免重复求解子问题。
-
-```java
-public int Fibonacci(int n) {
- if (n <= 1)
- return n;
- int[] fib = new int[n + 1];
- fib[1] = 1;
- for (int i = 2; i <= n; i++)
- fib[i] = fib[i - 1] + fib[i - 2];
- return fib[n];
-}
-```
-
-考虑到第 i 项只与第 i-1 和第 i-2 项有关,因此只需要存储前两项的值就能求解第 i 项,从而将空间复杂度由 O(N) 降低为 O(1)。
-
-```java
-public int Fibonacci(int n) {
- if (n <= 1)
- return n;
- int pre2 = 0, pre1 = 1;
- int fib = 0;
- for (int i = 2; i <= n; i++) {
- fib = pre2 + pre1;
- pre2 = pre1;
- pre1 = fib;
- }
- return fib;
-}
-```
-
-由于待求解的 n 小于 40,因此可以将前 40 项的结果先进行计算,之后就能以 O(1) 时间复杂度得到第 n 项的值。
-
-```java
-public class Solution {
-
- private int[] fib = new int[40];
-
- public Solution() {
- fib[1] = 1;
- for (int i = 2; i < fib.length; i++)
- fib[i] = fib[i - 1] + fib[i - 2];
- }
-
- public int Fibonacci(int n) {
- return fib[n];
- }
-}
-```
-
-# 10.2 矩形覆盖
-
-[NowCoder](https://www.nowcoder.com/practice/72a5a919508a4251859fb2cfb987a0e6?tpId=13&tqId=11163&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-我们可以用 2\*1 的小矩形横着或者竖着去覆盖更大的矩形。请问用 n 个 2\*1 的小矩形无重叠地覆盖一个 2\*n 的大矩形,总共有多少种方法?
-
-
-
-## 解题思路
-
-当 n 为 1 时,只有一种覆盖方法:
-
-
-
-当 n 为 2 时,有两种覆盖方法:
-
-
-
-要覆盖 2\*n 的大矩形,可以先覆盖 2\*1 的矩形,再覆盖 2\*(n-1) 的矩形;或者先覆盖 2\*2 的矩形,再覆盖 2\*(n-2) 的矩形。而覆盖 2\*(n-1) 和 2\*(n-2) 的矩形可以看成子问题。该问题的递推公式如下:
-
-
-
-
-
-```java
-public int RectCover(int n) {
- if (n <= 2)
- return n;
- int pre2 = 1, pre1 = 2;
- int result = 0;
- for (int i = 3; i <= n; i++) {
- result = pre2 + pre1;
- pre2 = pre1;
- pre1 = result;
- }
- return result;
-}
-```
-
-# 10.3 跳台阶
-
-[NowCoder](https://www.nowcoder.com/practice/8c82a5b80378478f9484d87d1c5f12a4?tpId=13&tqId=11161&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-一只青蛙一次可以跳上 1 级台阶,也可以跳上 2 级。求该青蛙跳上一个 n 级的台阶总共有多少种跳法。
-
-
-
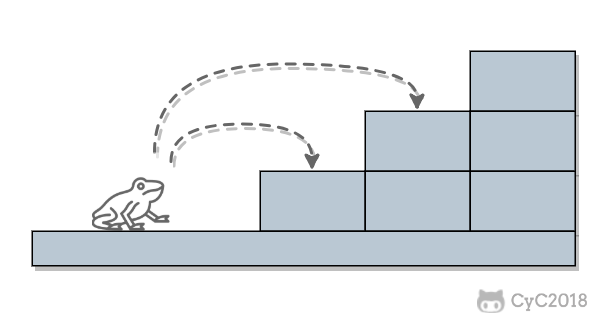
-## 解题思路
-
-当 n = 1 时,只有一种跳法:
-
-
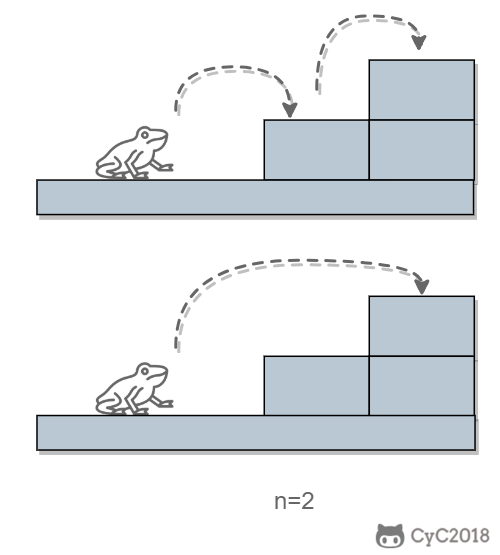
-
-当 n = 2 时,有两种跳法:
-
-
-
-跳 n 阶台阶,可以先跳 1 阶台阶,再跳 n-1 阶台阶;或者先跳 2 阶台阶,再跳 n-2 阶台阶。而 n-1 和 n-2 阶台阶的跳法可以看成子问题,该问题的递推公式为:
-
-
-
-```java
-public int JumpFloor(int n) {
- if (n <= 2)
- return n;
- int pre2 = 1, pre1 = 2;
- int result = 0;
- for (int i = 2; i < n; i++) {
- result = pre2 + pre1;
- pre2 = pre1;
- pre1 = result;
- }
- return result;
-}
-```
-
-# 10.4 变态跳台阶
-
-[NowCoder](https://www.nowcoder.com/practice/22243d016f6b47f2a6928b4313c85387?tpId=13&tqId=11162&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-一只青蛙一次可以跳上 1 级台阶,也可以跳上 2 级... 它也可以跳上 n 级。求该青蛙跳上一个 n 级的台阶总共有多少种跳法。
-
-
-
-## 解题思路
-
-### 动态规划
-
-```java
-public int JumpFloorII(int target) {
- int[] dp = new int[target];
- Arrays.fill(dp, 1);
- for (int i = 1; i < target; i++)
- for (int j = 0; j < i; j++)
- dp[i] += dp[j];
- return dp[target - 1];
-}
-```
-
-### 数学推导
-
-跳上 n-1 级台阶,可以从 n-2 级跳 1 级上去,也可以从 n-3 级跳 2 级上去...,那么
-
-```
-f(n-1) = f(n-2) + f(n-3) + ... + f(0)
-```
-
-同样,跳上 n 级台阶,可以从 n-1 级跳 1 级上去,也可以从 n-2 级跳 2 级上去... ,那么
-
-```
-f(n) = f(n-1) + f(n-2) + ... + f(0)
-```
-
-综上可得
-
-```
-f(n) - f(n-1) = f(n-1)
-```
-
-即
-
-```
-f(n) = 2*f(n-1)
-```
-
-所以 f(n) 是一个等比数列
-
-```source-java
-public int JumpFloorII(int target) {
- return (int) Math.pow(2, target - 1);
-}
-```
-
-
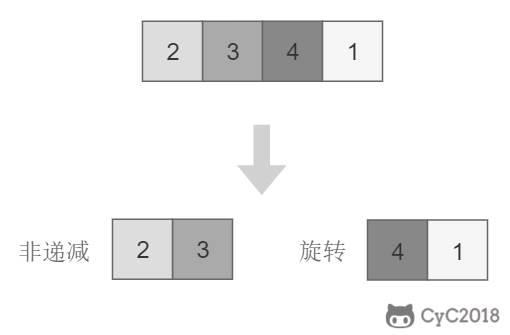
-# 11. 旋转数组的最小数字
-
-[NowCoder](https://www.nowcoder.com/practice/9f3231a991af4f55b95579b44b7a01ba?tpId=13&tqId=11159&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-把一个数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转。输入一个非递减排序的数组的一个旋转,输出旋转数组的最小元素。
-
-
-
-## 解题思路
-
-将旋转数组对半分可以得到一个包含最小元素的新旋转数组,以及一个非递减排序的数组。新的旋转数组的数组元素是原数组的一半,从而将问题规模减少了一半,这种折半性质的算法的时间复杂度为 O(logN)(为了方便,这里将 log2N 写为 logN)。
-
-
-
-此时问题的关键在于确定对半分得到的两个数组哪一个是旋转数组,哪一个是非递减数组。我们很容易知道非递减数组的第一个元素一定小于等于最后一个元素。
-
-通过修改二分查找算法进行求解(l 代表 low,m 代表 mid,h 代表 high):
-
-- 当 nums[m] \<= nums[h] 时,表示 [m, h] 区间内的数组是非递减数组,[l, m] 区间内的数组是旋转数组,此时令 h = m;
-- 否则 [m + 1, h] 区间内的数组是旋转数组,令 l = m + 1。
-
-```java
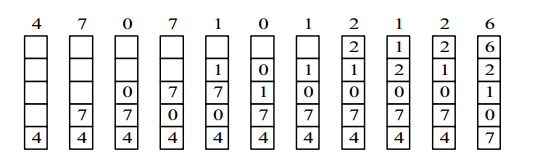
-public int minNumberInRotateArray(int[] nums) {
- if (nums.length == 0)
- return 0;
- int l = 0, h = nums.length - 1;
- while (l < h) {
- int m = l + (h - l) / 2;
- if (nums[m] <= nums[h])
- h = m;
- else
- l = m + 1;
- }
- return nums[l];
-}
-```
-
-如果数组元素允许重复,会出现一个特殊的情况:nums[l] == nums[m] == nums[h],此时无法确定解在哪个区间,需要切换到顺序查找。例如对于数组 {1,1,1,0,1},l、m 和 h 指向的数都为 1,此时无法知道最小数字 0 在哪个区间。
-
-```java
-public int minNumberInRotateArray(int[] nums) {
- if (nums.length == 0)
- return 0;
- int l = 0, h = nums.length - 1;
- while (l < h) {
- int m = l + (h - l) / 2;
- if (nums[l] == nums[m] && nums[m] == nums[h])
- return minNumber(nums, l, h);
- else if (nums[m] <= nums[h])
- h = m;
- else
- l = m + 1;
- }
- return nums[l];
-}
-
-private int minNumber(int[] nums, int l, int h) {
- for (int i = l; i < h; i++)
- if (nums[i] > nums[i + 1])
- return nums[i + 1];
- return nums[l];
-}
-```
-
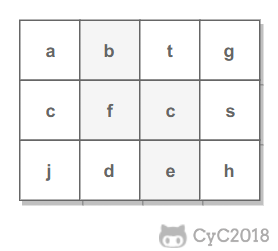
-# 12. 矩阵中的路径
-
-[NowCoder](https://www.nowcoder.com/practice/c61c6999eecb4b8f88a98f66b273a3cc?tpId=13&tqId=11218&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-判断在一个矩阵中是否存在一条包含某字符串所有字符的路径。路径可以从矩阵中的任意一个格子开始,每一步可以在矩阵中向上下左右移动一个格子。如果一条路径经过了矩阵中的某一个格子,则该路径不能再进入该格子。
-
-例如下面的矩阵包含了一条 bfce 路径。
-
-
-
-## 解题思路
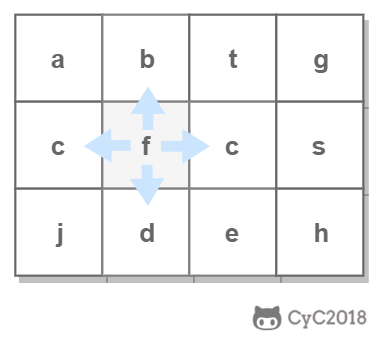
-
-使用回溯法(backtracking)进行求解,它是一种暴力搜索方法,通过搜索所有可能的结果来求解问题。回溯法在一次搜索结束时需要进行回溯(回退),将这一次搜索过程中设置的状态进行清除,从而开始一次新的搜索过程。例如下图示例中,从 f 开始,下一步有 4 种搜索可能,如果先搜索 b,需要将 b 标记为已经使用,防止重复使用。在这一次搜索结束之后,需要将 b 的已经使用状态清除,并搜索 c。
-
-
-
-本题的输入是数组而不是矩阵(二维数组),因此需要先将数组转换成矩阵。
-
-```java
-private final static int[][] next = {{0, -1}, {0, 1}, {-1, 0}, {1, 0}};
-private int rows;
-private int cols;
-
-public boolean hasPath(char[] array, int rows, int cols, char[] str) {
- if (rows == 0 || cols == 0) return false;
- this.rows = rows;
- this.cols = cols;
- boolean[][] marked = new boolean[rows][cols];
- char[][] matrix = buildMatrix(array);
- for (int i = 0; i < rows; i++)
- for (int j = 0; j < cols; j++)
- if (backtracking(matrix, str, marked, 0, i, j))
- return true;
-
- return false;
-}
-
-private boolean backtracking(char[][] matrix, char[] str,
- boolean[][] marked, int pathLen, int r, int c) {
-
- if (pathLen == str.length) return true;
- if (r < 0 || r >= rows || c < 0 || c >= cols
- || matrix[r][c] != str[pathLen] || marked[r][c]) {
-
- return false;
- }
- marked[r][c] = true;
- for (int[] n : next)
- if (backtracking(matrix, str, marked, pathLen + 1, r + n[0], c + n[1]))
- return true;
- marked[r][c] = false;
- return false;
-}
-
-private char[][] buildMatrix(char[] array) {
- char[][] matrix = new char[rows][cols];
- for (int r = 0, idx = 0; r < rows; r++)
- for (int c = 0; c < cols; c++)
- matrix[r][c] = array[idx++];
- return matrix;
-}
-```
-
-# 13. 机器人的运动范围
-
-[NowCoder](https://www.nowcoder.com/practice/6e5207314b5241fb83f2329e89fdecc8?tpId=13&tqId=11219&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-地上有一个 m 行和 n 列的方格。一个机器人从坐标 (0, 0) 的格子开始移动,每一次只能向左右上下四个方向移动一格,但是不能进入行坐标和列坐标的数位之和大于 k 的格子。
-
-例如,当 k 为 18 时,机器人能够进入方格 (35,37),因为 3+5+3+7=18。但是,它不能进入方格 (35,38),因为 3+5+3+8=19。请问该机器人能够达到多少个格子?
-
-## 解题思路
-
-使用深度优先搜索(Depth First Search,DFS)方法进行求解。回溯是深度优先搜索的一种特例,它在一次搜索过程中需要设置一些本次搜索过程的局部状态,并在本次搜索结束之后清除状态。而普通的深度优先搜索并不需要使用这些局部状态,虽然还是有可能设置一些全局状态。
-
-```java
-private static final int[][] next = {{0, -1}, {0, 1}, {-1, 0}, {1, 0}};
-private int cnt = 0;
-private int rows;
-private int cols;
-private int threshold;
-private int[][] digitSum;
-
-public int movingCount(int threshold, int rows, int cols) {
- this.rows = rows;
- this.cols = cols;
- this.threshold = threshold;
- initDigitSum();
- boolean[][] marked = new boolean[rows][cols];
- dfs(marked, 0, 0);
- return cnt;
-}
-
-private void dfs(boolean[][] marked, int r, int c) {
- if (r < 0 || r >= rows || c < 0 || c >= cols || marked[r][c])
- return;
- marked[r][c] = true;
- if (this.digitSum[r][c] > this.threshold)
- return;
- cnt++;
- for (int[] n : next)
- dfs(marked, r + n[0], c + n[1]);
-}
-
-private void initDigitSum() {
- int[] digitSumOne = new int[Math.max(rows, cols)];
- for (int i = 0; i < digitSumOne.length; i++) {
- int n = i;
- while (n > 0) {
- digitSumOne[i] += n % 10;
- n /= 10;
- }
- }
- this.digitSum = new int[rows][cols];
- for (int i = 0; i < this.rows; i++)
- for (int j = 0; j < this.cols; j++)
- this.digitSum[i][j] = digitSumOne[i] + digitSumOne[j];
-}
-```
-
-# 14. 剪绳子
-
-[Leetcode](https://leetcode.com/problems/integer-break/description/)
-
-## 题目描述
-
-把一根绳子剪成多段,并且使得每段的长度乘积最大。
-
-```html
-n = 2
-return 1 (2 = 1 + 1)
-
-n = 10
-return 36 (10 = 3 + 3 + 4)
-```
-
-## 解题思路
-
-### 贪心
-
-尽可能多剪长度为 3 的绳子,并且不允许有长度为 1 的绳子出现。如果出现了,就从已经切好长度为 3 的绳子中拿出一段与长度为 1 的绳子重新组合,把它们切成两段长度为 2 的绳子。
-
-证明:当 n \>= 5 时,3(n - 3) - n = 2n - 9 \> 0,且 2(n - 2) - n = n - 4 \> 0。因此在 n \>= 5 的情况下,将绳子剪成一段为 2 或者 3,得到的乘积会更大。又因为 3(n - 3) - 2(n - 2) = n - 5 \>= 0,所以剪成一段长度为 3 比长度为 2 得到的乘积更大。
-
-```java
-public int integerBreak(int n) {
- if (n < 2)
- return 0;
- if (n == 2)
- return 1;
- if (n == 3)
- return 2;
- int timesOf3 = n / 3;
- if (n - timesOf3 * 3 == 1)
- timesOf3--;
- int timesOf2 = (n - timesOf3 * 3) / 2;
- return (int) (Math.pow(3, timesOf3)) * (int) (Math.pow(2, timesOf2));
-}
-```
-
-### 动态规划
-
-```java
-public int integerBreak(int n) {
- int[] dp = new int[n + 1];
- dp[1] = 1;
- for (int i = 2; i <= n; i++)
- for (int j = 1; j < i; j++)
- dp[i] = Math.max(dp[i], Math.max(j * (i - j), dp[j] * (i - j)));
- return dp[n];
-}
-```
-
-# 15. 二进制中 1 的个数
-
-[NowCoder](https://www.nowcoder.com/practice/8ee967e43c2c4ec193b040ea7fbb10b8?tpId=13&tqId=11164&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-输入一个整数,输出该数二进制表示中 1 的个数。
-
-### n&(n-1)
-
-该位运算去除 n 的位级表示中最低的那一位。
-
-```
-n : 10110100
-n-1 : 10110011
-n&(n-1) : 10110000
-```
-
-时间复杂度:O(M),其中 M 表示 1 的个数。
-
-
-```java
-public int NumberOf1(int n) {
- int cnt = 0;
- while (n != 0) {
- cnt++;
- n &= (n - 1);
- }
- return cnt;
-}
-```
-
-
-### Integer.bitCount()
-
-```java
-public int NumberOf1(int n) {
- return Integer.bitCount(n);
-}
-```
-
-# 16. 数值的整数次方
-
-[NowCoder](https://www.nowcoder.com/practice/1a834e5e3e1a4b7ba251417554e07c00?tpId=13&tqId=11165&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-给定一个 double 类型的浮点数 base 和 int 类型的整数 exponent,求 base 的 exponent 次方。
-
-## 解题思路
-
-下面的讨论中 x 代表 base,n 代表 exponent。
-
-
-
-
-
-
-因为 (x\*x)n/2 可以通过递归求解,并且每次递归 n 都减小一半,因此整个算法的时间复杂度为 O(logN)。
-
-```java
-public double Power(double base, int exponent) {
- if (exponent == 0)
- return 1;
- if (exponent == 1)
- return base;
- boolean isNegative = false;
- if (exponent < 0) {
- exponent = -exponent;
- isNegative = true;
- }
- double pow = Power(base * base, exponent / 2);
- if (exponent % 2 != 0)
- pow = pow * base;
- return isNegative ? 1 / pow : pow;
-}
-```
-
-# 17. 打印从 1 到最大的 n 位数
-
-## 题目描述
-
-输入数字 n,按顺序打印出从 1 到最大的 n 位十进制数。比如输入 3,则打印出 1、2、3 一直到最大的 3 位数即 999。
-
-## 解题思路
-
-由于 n 可能会非常大,因此不能直接用 int 表示数字,而是用 char 数组进行存储。
-
-使用回溯法得到所有的数。
-
-```java
-public void print1ToMaxOfNDigits(int n) {
- if (n <= 0)
- return;
- char[] number = new char[n];
- print1ToMaxOfNDigits(number, 0);
-}
-
-private void print1ToMaxOfNDigits(char[] number, int digit) {
- if (digit == number.length) {
- printNumber(number);
- return;
- }
- for (int i = 0; i < 10; i++) {
- number[digit] = (char) (i + '0');
- print1ToMaxOfNDigits(number, digit + 1);
- }
-}
-
-private void printNumber(char[] number) {
- int index = 0;
- while (index < number.length && number[index] == '0')
- index++;
- while (index < number.length)
- System.out.print(number[index++]);
- System.out.println();
-}
-```
-
-# 18.1 在 O(1) 时间内删除链表节点
-
-## 解题思路
-
-① 如果该节点不是尾节点,那么可以直接将下一个节点的值赋给该节点,然后令该节点指向下下个节点,再删除下一个节点,时间复杂度为 O(1)。
-
-
-
-② 否则,就需要先遍历链表,找到节点的前一个节点,然后让前一个节点指向 null,时间复杂度为 O(N)。
-
-
-
-综上,如果进行 N 次操作,那么大约需要操作节点的次数为 N-1+N=2N-1,其中 N-1 表示 N-1 个不是尾节点的每个节点以 O(1) 的时间复杂度操作节点的总次数,N 表示 1 个尾节点以 O(N) 的时间复杂度操作节点的总次数。(2N-1)/N \~ 2,因此该算法的平均时间复杂度为 O(1)。
-
-```java
-public ListNode deleteNode(ListNode head, ListNode tobeDelete) {
- if (head == null || tobeDelete == null)
- return null;
- if (tobeDelete.next != null) {
- // 要删除的节点不是尾节点
- ListNode next = tobeDelete.next;
- tobeDelete.val = next.val;
- tobeDelete.next = next.next;
- } else {
- if (head == tobeDelete)
- // 只有一个节点
- head = null;
- else {
- ListNode cur = head;
- while (cur.next != tobeDelete)
- cur = cur.next;
- cur.next = null;
- }
- }
- return head;
-}
-```
-
-# 18.2 删除链表中重复的结点
-
-[NowCoder](https://www.nowcoder.com/practice/fc533c45b73a41b0b44ccba763f866ef?tpId=13&tqId=11209&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-
-
-## 解题描述
-
-```java
-public ListNode deleteDuplication(ListNode pHead) {
- if (pHead == null || pHead.next == null)
- return pHead;
- ListNode next = pHead.next;
- if (pHead.val == next.val) {
- while (next != null && pHead.val == next.val)
- next = next.next;
- return deleteDuplication(next);
- } else {
- pHead.next = deleteDuplication(pHead.next);
- return pHead;
- }
-}
-```
-
-# 19. 正则表达式匹配
-
-[NowCoder](https://www.nowcoder.com/practice/45327ae22b7b413ea21df13ee7d6429c?tpId=13&tqId=11205&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-请实现一个函数用来匹配包括 '.' 和 '\*' 的正则表达式。模式中的字符 '.' 表示任意一个字符,而 '\*' 表示它前面的字符可以出现任意次(包含 0 次)。
-
-在本题中,匹配是指字符串的所有字符匹配整个模式。例如,字符串 "aaa" 与模式 "a.a" 和 "ab\*ac\*a" 匹配,但是与 "aa.a" 和 "ab\*a" 均不匹配。
-
-## 解题思路
-
-应该注意到,'.' 是用来当做一个任意字符,而 '\*' 是用来重复前面的字符。这两个的作用不同,不能把 '.' 的作用和 '\*' 进行类比,从而把它当成重复前面字符一次。
-
-```java
-public boolean match(char[] str, char[] pattern) {
-
- int m = str.length, n = pattern.length;
- boolean[][] dp = new boolean[m + 1][n + 1];
-
- dp[0][0] = true;
- for (int i = 1; i <= n; i++)
- if (pattern[i - 1] == '*')
- dp[0][i] = dp[0][i - 2];
-
- for (int i = 1; i <= m; i++)
- for (int j = 1; j <= n; j++)
- if (str[i - 1] == pattern[j - 1] || pattern[j - 1] == '.')
- dp[i][j] = dp[i - 1][j - 1];
- else if (pattern[j - 1] == '*')
- if (pattern[j - 2] == str[i - 1] || pattern[j - 2] == '.') {
- dp[i][j] |= dp[i][j - 1]; // a* counts as single a
- dp[i][j] |= dp[i - 1][j]; // a* counts as multiple a
- dp[i][j] |= dp[i][j - 2]; // a* counts as empty
- } else
- dp[i][j] = dp[i][j - 2]; // a* only counts as empty
-
- return dp[m][n];
-}
-```
diff --git a/notes/剑指 Offer 题解 - 20~29.md b/notes/剑指 Offer 题解 - 20~29.md
deleted file mode 100644
index 8271b75a..00000000
--- a/notes/剑指 Offer 题解 - 20~29.md
+++ /dev/null
@@ -1,390 +0,0 @@
-
-* [20. 表示数值的字符串](#20-表示数值的字符串)
-* [21. 调整数组顺序使奇数位于偶数前面](#21-调整数组顺序使奇数位于偶数前面)
-* [22. 链表中倒数第 K 个结点](#22-链表中倒数第-k-个结点)
-* [23. 链表中环的入口结点](#23-链表中环的入口结点)
-* [24. 反转链表](#24-反转链表)
-* [25. 合并两个排序的链表](#25-合并两个排序的链表)
-* [26. 树的子结构](#26-树的子结构)
-* [27. 二叉树的镜像](#27-二叉树的镜像)
-* [28 对称的二叉树](#28-对称的二叉树)
-* [29. 顺时针打印矩阵](#29-顺时针打印矩阵)
-
-
-
-# 20. 表示数值的字符串
-
-[NowCoder](https://www.nowcoder.com/practice/6f8c901d091949a5837e24bb82a731f2?tpId=13&tqId=11206&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-```
-true
-
-"+100"
-"5e2"
-"-123"
-"3.1416"
-"-1E-16"
-```
-
-```
-false
-
-"12e"
-"1a3.14"
-"1.2.3"
-"+-5"
-"12e+4.3"
-```
-
-
-## 解题思路
-
-使用正则表达式进行匹配。
-
-```html
-[] : 字符集合
-() : 分组
-? : 重复 0 ~ 1 次
-+ : 重复 1 ~ n 次
-* : 重复 0 ~ n 次
-. : 任意字符
-\\. : 转义后的 .
-\\d : 数字
-```
-
-```java
-public boolean isNumeric(char[] str) {
- if (str == null || str.length == 0)
- return false;
- return new String(str).matches("[+-]?\\d*(\\.\\d+)?([eE][+-]?\\d+)?");
-}
-```
-
-# 21. 调整数组顺序使奇数位于偶数前面
-
-[NowCoder](https://www.nowcoder.com/practice/beb5aa231adc45b2a5dcc5b62c93f593?tpId=13&tqId=11166&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-需要保证奇数和奇数,偶数和偶数之间的相对位置不变,这和书本不太一样。
-
-
-
-## 解题思路
-
-方法一:创建一个新数组,时间复杂度 O(N),空间复杂度 O(N)。
-
-```java
-public void reOrderArray(int[] nums) {
- // 奇数个数
- int oddCnt = 0;
- for (int x : nums)
- if (!isEven(x))
- oddCnt++;
- int[] copy = nums.clone();
- int i = 0, j = oddCnt;
- for (int num : copy) {
- if (num % 2 == 1)
- nums[i++] = num;
- else
- nums[j++] = num;
- }
-}
-
-private boolean isEven(int x) {
- return x % 2 == 0;
-}
-```
-
-方法二:使用冒泡思想,每次都当前偶数上浮到当前最右边。时间复杂度 O(N2),空间复杂度 O(1),时间换空间。
-
-```java
-public void reOrderArray(int[] nums) {
- int N = nums.length;
- for (int i = N - 1; i > 0; i--) {
- for (int j = 0; j < i; j++) {
- if (isEven(nums[j]) && !isEven(nums[j + 1])) {
- swap(nums, j, j + 1);
- }
- }
- }
-}
-
-private boolean isEven(int x) {
- return x % 2 == 0;
-}
-
-private void swap(int[] nums, int i, int j) {
- int t = nums[i];
- nums[i] = nums[j];
- nums[j] = t;
-}
-```
-
-# 22. 链表中倒数第 K 个结点
-
-[NowCoder](https://www.nowcoder.com/practice/529d3ae5a407492994ad2a246518148a?tpId=13&tqId=11167&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
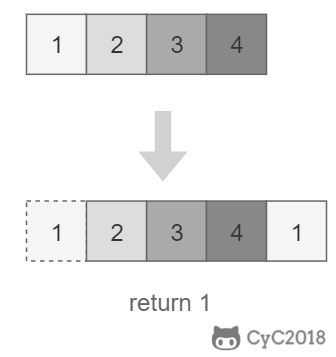
-
-## 解题思路
-
-设链表的长度为 N。设置两个指针 P1 和 P2,先让 P1 移动 K 个节点,则还有 N - K 个节点可以移动。此时让 P1 和 P2 同时移动,可以知道当 P1 移动到链表结尾时,P2 移动到第 N - K 个节点处,该位置就是倒数第 K 个节点。
-
- 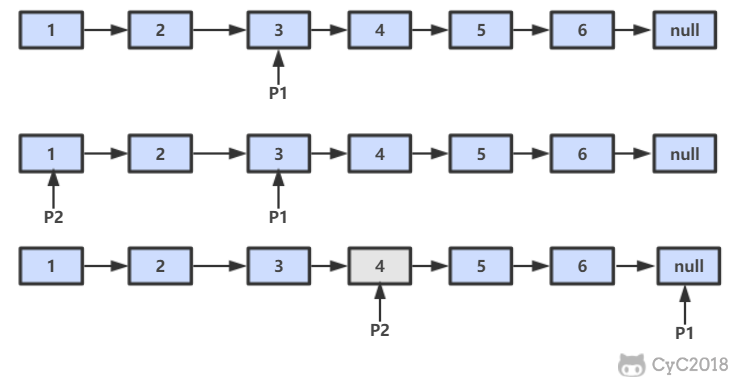
-
-```java
-public ListNode FindKthToTail(ListNode head, int k) {
- if (head == null)
- return null;
- ListNode P1 = head;
- while (P1 != null && k-- > 0)
- P1 = P1.next;
- if (k > 0)
- return null;
- ListNode P2 = head;
- while (P1 != null) {
- P1 = P1.next;
- P2 = P2.next;
- }
- return P2;
-}
-```
-
-# 23. 链表中环的入口结点
-
-[NowCoder](https://www.nowcoder.com/practice/253d2c59ec3e4bc68da16833f79a38e4?tpId=13&tqId=11208&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-一个链表中包含环,请找出该链表的环的入口结点。要求不能使用额外的空间。
-
-## 解题思路
-
-使用双指针,一个指针 fast 每次移动两个节点,一个指针 slow 每次移动一个节点。因为存在环,所以两个指针必定相遇在环中的某个节点上。假设相遇点在下图的 z1 位置,此时 fast 移动的节点数为 x+2y+z,slow 为 x+y,由于 fast 速度比 slow 快一倍,因此 x+2y+z=2(x+y),得到 x=z。
-
-在相遇点,slow 要到环的入口点还需要移动 z 个节点,如果让 fast 重新从头开始移动,并且速度变为每次移动一个节点,那么它到环入口点还需要移动 x 个节点。在上面已经推导出 x=z,因此 fast 和 slow 将在环入口点相遇。
-
- 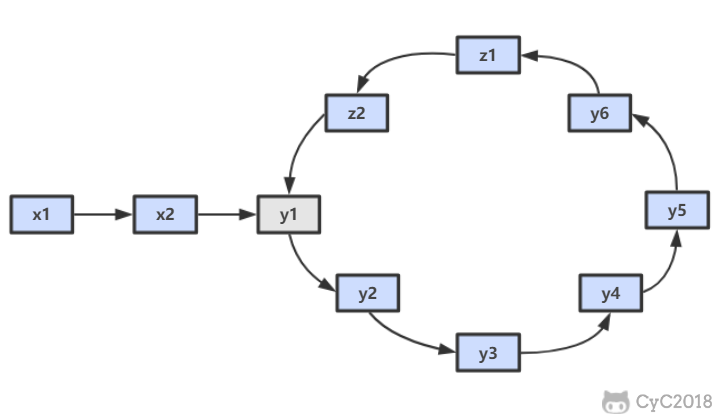
-
-```java
-public ListNode EntryNodeOfLoop(ListNode pHead) {
- if (pHead == null || pHead.next == null)
- return null;
- ListNode slow = pHead, fast = pHead;
- do {
- fast = fast.next.next;
- slow = slow.next;
- } while (slow != fast);
- fast = pHead;
- while (slow != fast) {
- slow = slow.next;
- fast = fast.next;
- }
- return slow;
-}
-```
-
-# 24. 反转链表
-
-[NowCoder](https://www.nowcoder.com/practice/75e878df47f24fdc9dc3e400ec6058ca?tpId=13&tqId=11168&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 解题思路
-
-### 递归
-
-```java
-public ListNode ReverseList(ListNode head) {
- if (head == null || head.next == null)
- return head;
- ListNode next = head.next;
- head.next = null;
- ListNode newHead = ReverseList(next);
- next.next = head;
- return newHead;
-}
-```
-
-### 迭代
-
-使用头插法。
-
-```java
-public ListNode ReverseList(ListNode head) {
- ListNode newList = new ListNode(-1);
- while (head != null) {
- ListNode next = head.next;
- head.next = newList.next;
- newList.next = head;
- head = next;
- }
- return newList.next;
-}
-```
-
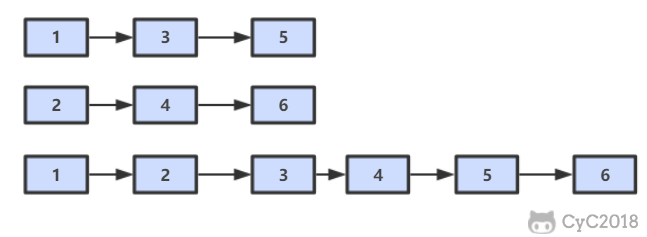
-# 25. 合并两个排序的链表
-
-[NowCoder](https://www.nowcoder.com/practice/d8b6b4358f774294a89de2a6ac4d9337?tpId=13&tqId=11169&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
- 
-
-## 解题思路
-
-### 递归
-
-```java
-public ListNode Merge(ListNode list1, ListNode list2) {
- if (list1 == null)
- return list2;
- if (list2 == null)
- return list1;
- if (list1.val <= list2.val) {
- list1.next = Merge(list1.next, list2);
- return list1;
- } else {
- list2.next = Merge(list1, list2.next);
- return list2;
- }
-}
-```
-
-### 迭代
-
-```java
-public ListNode Merge(ListNode list1, ListNode list2) {
- ListNode head = new ListNode(-1);
- ListNode cur = head;
- while (list1 != null && list2 != null) {
- if (list1.val <= list2.val) {
- cur.next = list1;
- list1 = list1.next;
- } else {
- cur.next = list2;
- list2 = list2.next;
- }
- cur = cur.next;
- }
- if (list1 != null)
- cur.next = list1;
- if (list2 != null)
- cur.next = list2;
- return head.next;
-}
-```
-
-# 26. 树的子结构
-
-[NowCoder](https://www.nowcoder.com/practice/6e196c44c7004d15b1610b9afca8bd88?tpId=13&tqId=11170&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
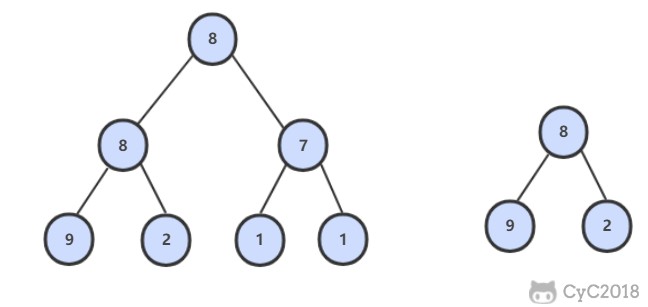
- 
-
-## 解题思路
-
-```java
-public boolean HasSubtree(TreeNode root1, TreeNode root2) {
- if (root1 == null || root2 == null)
- return false;
- return isSubtreeWithRoot(root1, root2) || HasSubtree(root1.left, root2) || HasSubtree(root1.right, root2);
-}
-
-private boolean isSubtreeWithRoot(TreeNode root1, TreeNode root2) {
- if (root2 == null)
- return true;
- if (root1 == null)
- return false;
- if (root1.val != root2.val)
- return false;
- return isSubtreeWithRoot(root1.left, root2.left) && isSubtreeWithRoot(root1.right, root2.right);
-}
-```
-
-# 27. 二叉树的镜像
-
-[NowCoder](https://www.nowcoder.com/practice/564f4c26aa584921bc75623e48ca3011?tpId=13&tqId=11171&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
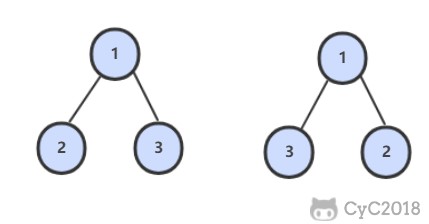
- 
-
-## 解题思路
-
-```java
-public void Mirror(TreeNode root) {
- if (root == null)
- return;
- swap(root);
- Mirror(root.left);
- Mirror(root.right);
-}
-
-private void swap(TreeNode root) {
- TreeNode t = root.left;
- root.left = root.right;
- root.right = t;
-}
-```
-
-# 28 对称的二叉树
-
-[NowCoder](https://www.nowcoder.com/practice/ff05d44dfdb04e1d83bdbdab320efbcb?tpId=13&tqId=11211&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-
-
-## 解题思路
-
-```java
-boolean isSymmetrical(TreeNode pRoot) {
- if (pRoot == null)
- return true;
- return isSymmetrical(pRoot.left, pRoot.right);
-}
-
-boolean isSymmetrical(TreeNode t1, TreeNode t2) {
- if (t1 == null && t2 == null)
- return true;
- if (t1 == null || t2 == null)
- return false;
- if (t1.val != t2.val)
- return false;
- return isSymmetrical(t1.left, t2.right) && isSymmetrical(t1.right, t2.left);
-}
-```
-
-# 29. 顺时针打印矩阵
-
-[NowCoder](https://www.nowcoder.com/practice/9b4c81a02cd34f76be2659fa0d54342a?tpId=13&tqId=11172&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-下图的矩阵顺时针打印结果为:1, 2, 3, 4, 8, 12, 16, 15, 14, 13, 9, 5, 6, 7, 11, 10
-
- 
-
-## 解题思路
-
-```java
-public ArrayList printMatrix(int[][] matrix) {
- ArrayList ret = new ArrayList<>();
- int r1 = 0, r2 = matrix.length - 1, c1 = 0, c2 = matrix[0].length - 1;
- while (r1 <= r2 && c1 <= c2) {
- for (int i = c1; i <= c2; i++)
- ret.add(matrix[r1][i]);
- for (int i = r1 + 1; i <= r2; i++)
- ret.add(matrix[i][c2]);
- if (r1 != r2)
- for (int i = c2 - 1; i >= c1; i--)
- ret.add(matrix[r2][i]);
- if (c1 != c2)
- for (int i = r2 - 1; i > r1; i--)
- ret.add(matrix[i][c1]);
- r1++; r2--; c1++; c2--;
- }
- return ret;
-}
-```
diff --git a/notes/剑指 Offer 题解 - 30~39.md b/notes/剑指 Offer 题解 - 30~39.md
deleted file mode 100644
index 83769157..00000000
--- a/notes/剑指 Offer 题解 - 30~39.md
+++ /dev/null
@@ -1,470 +0,0 @@
-
-* [30. 包含 min 函数的栈](#30-包含-min-函数的栈)
-* [31. 栈的压入、弹出序列](#31-栈的压入弹出序列)
-* [32.1 从上往下打印二叉树](#321-从上往下打印二叉树)
-* [32.2 把二叉树打印成多行](#322-把二叉树打印成多行)
-* [32.3 按之字形顺序打印二叉树](#323-按之字形顺序打印二叉树)
-* [33. 二叉搜索树的后序遍历序列](#33-二叉搜索树的后序遍历序列)
-* [34. 二叉树中和为某一值的路径](#34-二叉树中和为某一值的路径)
-* [35. 复杂链表的复制](#35-复杂链表的复制)
-* [36. 二叉搜索树与双向链表](#36-二叉搜索树与双向链表)
-* [37. 序列化二叉树](#37-序列化二叉树)
-* [38. 字符串的排列](#38-字符串的排列)
-* [39. 数组中出现次数超过一半的数字](#39-数组中出现次数超过一半的数字)
-
-
-
-# 30. 包含 min 函数的栈
-
-[NowCoder](https://www.nowcoder.com/practice/4c776177d2c04c2494f2555c9fcc1e49?tpId=13&tqId=11173&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-定义栈的数据结构,请在该类型中实现一个能够得到栈最小元素的 min 函数。
-
-## 解题思路
-
-```java
-private Stack dataStack = new Stack<>();
-private Stack minStack = new Stack<>();
-
-public void push(int node) {
- dataStack.push(node);
- minStack.push(minStack.isEmpty() ? node : Math.min(minStack.peek(), node));
-}
-
-public void pop() {
- dataStack.pop();
- minStack.pop();
-}
-
-public int top() {
- return dataStack.peek();
-}
-
-public int min() {
- return minStack.peek();
-}
-```
-
-# 31. 栈的压入、弹出序列
-
-[NowCoder](https://www.nowcoder.com/practice/d77d11405cc7470d82554cb392585106?tpId=13&tqId=11174&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-输入两个整数序列,第一个序列表示栈的压入顺序,请判断第二个序列是否为该栈的弹出顺序。假设压入栈的所有数字均不相等。
-
-例如序列 1,2,3,4,5 是某栈的压入顺序,序列 4,5,3,2,1 是该压栈序列对应的一个弹出序列,但 4,3,5,1,2 就不可能是该压栈序列的弹出序列。
-
-## 解题思路
-
-使用一个栈来模拟压入弹出操作。
-
-```java
-public boolean IsPopOrder(int[] pushSequence, int[] popSequence) {
- int n = pushSequence.length;
- Stack stack = new Stack<>();
- for (int pushIndex = 0, popIndex = 0; pushIndex < n; pushIndex++) {
- stack.push(pushSequence[pushIndex]);
- while (popIndex < n && !stack.isEmpty()
- && stack.peek() == popSequence[popIndex]) {
- stack.pop();
- popIndex++;
- }
- }
- return stack.isEmpty();
-}
-```
-
-# 32.1 从上往下打印二叉树
-
-[NowCoder](https://www.nowcoder.com/practice/7fe2212963db4790b57431d9ed259701?tpId=13&tqId=11175&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-从上往下打印出二叉树的每个节点,同层节点从左至右打印。
-
-例如,以下二叉树层次遍历的结果为:1,2,3,4,5,6,7
-
- 
-
-## 解题思路
-
-使用队列来进行层次遍历。
-
-不需要使用两个队列分别存储当前层的节点和下一层的节点,因为在开始遍历一层的节点时,当前队列中的节点数就是当前层的节点数,只要控制遍历这么多节点数,就能保证这次遍历的都是当前层的节点。
-
-```java
-public ArrayList PrintFromTopToBottom(TreeNode root) {
- Queue queue = new LinkedList<>();
- ArrayList ret = new ArrayList<>();
- queue.add(root);
- while (!queue.isEmpty()) {
- int cnt = queue.size();
- while (cnt-- > 0) {
- TreeNode t = queue.poll();
- if (t == null)
- continue;
- ret.add(t.val);
- queue.add(t.left);
- queue.add(t.right);
- }
- }
- return ret;
-}
-```
-
-# 32.2 把二叉树打印成多行
-
-[NowCoder](https://www.nowcoder.com/practice/445c44d982d04483b04a54f298796288?tpId=13&tqId=11213&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-和上题几乎一样。
-
-## 解题思路
-
-```java
-ArrayList> Print(TreeNode pRoot) {
- ArrayList> ret = new ArrayList<>();
- Queue queue = new LinkedList<>();
- queue.add(pRoot);
- while (!queue.isEmpty()) {
- ArrayList list = new ArrayList<>();
- int cnt = queue.size();
- while (cnt-- > 0) {
- TreeNode node = queue.poll();
- if (node == null)
- continue;
- list.add(node.val);
- queue.add(node.left);
- queue.add(node.right);
- }
- if (list.size() != 0)
- ret.add(list);
- }
- return ret;
-}
-```
-
-# 32.3 按之字形顺序打印二叉树
-
-[NowCoder](https://www.nowcoder.com/practice/91b69814117f4e8097390d107d2efbe0?tpId=13&tqId=11212&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-请实现一个函数按照之字形打印二叉树,即第一行按照从左到右的顺序打印,第二层按照从右至左的顺序打印,第三行按照从左到右的顺序打印,其他行以此类推。
-
-## 解题思路
-
-```java
-public ArrayList> Print(TreeNode pRoot) {
- ArrayList> ret = new ArrayList<>();
- Queue queue = new LinkedList<>();
- queue.add(pRoot);
- boolean reverse = false;
- while (!queue.isEmpty()) {
- ArrayList list = new ArrayList<>();
- int cnt = queue.size();
- while (cnt-- > 0) {
- TreeNode node = queue.poll();
- if (node == null)
- continue;
- list.add(node.val);
- queue.add(node.left);
- queue.add(node.right);
- }
- if (reverse)
- Collections.reverse(list);
- reverse = !reverse;
- if (list.size() != 0)
- ret.add(list);
- }
- return ret;
-}
-```
-
-# 33. 二叉搜索树的后序遍历序列
-
-[NowCoder](https://www.nowcoder.com/practice/a861533d45854474ac791d90e447bafd?tpId=13&tqId=11176&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-输入一个整数数组,判断该数组是不是某二叉搜索树的后序遍历的结果。假设输入的数组的任意两个数字都互不相同。
-
-例如,下图是后序遍历序列 1,3,2 所对应的二叉搜索树。
-
- 
-
-## 解题思路
-
-```java
-public boolean VerifySquenceOfBST(int[] sequence) {
- if (sequence == null || sequence.length == 0)
- return false;
- return verify(sequence, 0, sequence.length - 1);
-}
-
-private boolean verify(int[] sequence, int first, int last) {
- if (last - first <= 1)
- return true;
- int rootVal = sequence[last];
- int cutIndex = first;
- while (cutIndex < last && sequence[cutIndex] <= rootVal)
- cutIndex++;
- for (int i = cutIndex; i < last; i++)
- if (sequence[i] < rootVal)
- return false;
- return verify(sequence, first, cutIndex - 1) && verify(sequence, cutIndex, last - 1);
-}
-```
-
-# 34. 二叉树中和为某一值的路径
-
-[NowCoder](https://www.nowcoder.com/practice/b736e784e3e34731af99065031301bca?tpId=13&tqId=11177&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-输入一颗二叉树和一个整数,打印出二叉树中结点值的和为输入整数的所有路径。路径定义为从树的根结点开始往下一直到叶结点所经过的结点形成一条路径。
-
-下图的二叉树有两条和为 22 的路径:10, 5, 7 和 10, 12
-
- 
-
-## 解题思路
-
-```java
-private ArrayList> ret = new ArrayList<>();
-
-public ArrayList> FindPath(TreeNode root, int target) {
- backtracking(root, target, new ArrayList<>());
- return ret;
-}
-
-private void backtracking(TreeNode node, int target, ArrayList path) {
- if (node == null)
- return;
- path.add(node.val);
- target -= node.val;
- if (target == 0 && node.left == null && node.right == null) {
- ret.add(new ArrayList<>(path));
- } else {
- backtracking(node.left, target, path);
- backtracking(node.right, target, path);
- }
- path.remove(path.size() - 1);
-}
-```
-
-# 35. 复杂链表的复制
-
-[NowCoder](https://www.nowcoder.com/practice/f836b2c43afc4b35ad6adc41ec941dba?tpId=13&tqId=11178&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-输入一个复杂链表(每个节点中有节点值,以及两个指针,一个指向下一个节点,另一个特殊指针指向任意一个节点),返回结果为复制后复杂链表的 head。
-
-```java
-public class RandomListNode {
- int label;
- RandomListNode next = null;
- RandomListNode random = null;
-
- RandomListNode(int label) {
- this.label = label;
- }
-}
-```
-
- 
-
-## 解题思路
-
-第一步,在每个节点的后面插入复制的节点。
-
- 
-
-第二步,对复制节点的 random 链接进行赋值。
-
- 
-
-第三步,拆分。
-
- 
-
-```java
-public RandomListNode Clone(RandomListNode pHead) {
- if (pHead == null)
- return null;
- // 插入新节点
- RandomListNode cur = pHead;
- while (cur != null) {
- RandomListNode clone = new RandomListNode(cur.label);
- clone.next = cur.next;
- cur.next = clone;
- cur = clone.next;
- }
- // 建立 random 链接
- cur = pHead;
- while (cur != null) {
- RandomListNode clone = cur.next;
- if (cur.random != null)
- clone.random = cur.random.next;
- cur = clone.next;
- }
- // 拆分
- cur = pHead;
- RandomListNode pCloneHead = pHead.next;
- while (cur.next != null) {
- RandomListNode next = cur.next;
- cur.next = next.next;
- cur = next;
- }
- return pCloneHead;
-}
-```
-
-# 36. 二叉搜索树与双向链表
-
-[NowCoder](https://www.nowcoder.com/practice/947f6eb80d944a84850b0538bf0ec3a5?tpId=13&tqId=11179&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-输入一棵二叉搜索树,将该二叉搜索树转换成一个排序的双向链表。要求不能创建任何新的结点,只能调整树中结点指针的指向。
-
- 
-
-## 解题思路
-
-```java
-private TreeNode pre = null;
-private TreeNode head = null;
-
-public TreeNode Convert(TreeNode root) {
- inOrder(root);
- return head;
-}
-
-private void inOrder(TreeNode node) {
- if (node == null)
- return;
- inOrder(node.left);
- node.left = pre;
- if (pre != null)
- pre.right = node;
- pre = node;
- if (head == null)
- head = node;
- inOrder(node.right);
-}
-```
-
-# 37. 序列化二叉树
-
-[NowCoder](https://www.nowcoder.com/practice/cf7e25aa97c04cc1a68c8f040e71fb84?tpId=13&tqId=11214&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-请实现两个函数,分别用来序列化和反序列化二叉树。
-
-## 解题思路
-
-```java
-private String deserializeStr;
-
-public String Serialize(TreeNode root) {
- if (root == null)
- return "#";
- return root.val + " " + Serialize(root.left) + " " + Serialize(root.right);
-}
-
-public TreeNode Deserialize(String str) {
- deserializeStr = str;
- return Deserialize();
-}
-
-private TreeNode Deserialize() {
- if (deserializeStr.length() == 0)
- return null;
- int index = deserializeStr.indexOf(" ");
- String node = index == -1 ? deserializeStr : deserializeStr.substring(0, index);
- deserializeStr = index == -1 ? "" : deserializeStr.substring(index + 1);
- if (node.equals("#"))
- return null;
- int val = Integer.valueOf(node);
- TreeNode t = new TreeNode(val);
- t.left = Deserialize();
- t.right = Deserialize();
- return t;
-}
-```
-
-# 38. 字符串的排列
-
-[NowCoder](https://www.nowcoder.com/practice/fe6b651b66ae47d7acce78ffdd9a96c7?tpId=13&tqId=11180&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-输入一个字符串,按字典序打印出该字符串中字符的所有排列。例如输入字符串 abc,则打印出由字符 a, b, c 所能排列出来的所有字符串 abc, acb, bac, bca, cab 和 cba。
-
-## 解题思路
-
-```java
-private ArrayList ret = new ArrayList<>();
-
-public ArrayList Permutation(String str) {
- if (str.length() == 0)
- return ret;
- char[] chars = str.toCharArray();
- Arrays.sort(chars);
- backtracking(chars, new boolean[chars.length], new StringBuilder());
- return ret;
-}
-
-private void backtracking(char[] chars, boolean[] hasUsed, StringBuilder s) {
- if (s.length() == chars.length) {
- ret.add(s.toString());
- return;
- }
- for (int i = 0; i < chars.length; i++) {
- if (hasUsed[i])
- continue;
- if (i != 0 && chars[i] == chars[i - 1] && !hasUsed[i - 1]) /* 保证不重复 */
- continue;
- hasUsed[i] = true;
- s.append(chars[i]);
- backtracking(chars, hasUsed, s);
- s.deleteCharAt(s.length() - 1);
- hasUsed[i] = false;
- }
-}
-```
-
-# 39. 数组中出现次数超过一半的数字
-
-[NowCoder](https://www.nowcoder.com/practice/e8a1b01a2df14cb2b228b30ee6a92163?tpId=13&tqId=11181&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 解题思路
-
-多数投票问题,可以利用 Boyer-Moore Majority Vote Algorithm 来解决这个问题,使得时间复杂度为 O(N)。
-
-使用 cnt 来统计一个元素出现的次数,当遍历到的元素和统计元素相等时,令 cnt++,否则令 cnt--。如果前面查找了 i 个元素,且 cnt == 0,说明前 i 个元素没有 majority,或者有 majority,但是出现的次数少于 i / 2 ,因为如果多于 i / 2 的话 cnt 就一定不会为 0 。此时剩下的 n - i 个元素中,majority 的数目依然多于 (n - i) / 2,因此继续查找就能找出 majority。
-
-```java
-public int MoreThanHalfNum_Solution(int[] nums) {
- int majority = nums[0];
- for (int i = 1, cnt = 1; i < nums.length; i++) {
- cnt = nums[i] == majority ? cnt + 1 : cnt - 1;
- if (cnt == 0) {
- majority = nums[i];
- cnt = 1;
- }
- }
- int cnt = 0;
- for (int val : nums)
- if (val == majority)
- cnt++;
- return cnt > nums.length / 2 ? majority : 0;
-}
-```
diff --git a/notes/剑指 Offer 题解 - 3~9.md b/notes/剑指 Offer 题解 - 3~9.md
deleted file mode 100644
index bde21f8e..00000000
--- a/notes/剑指 Offer 题解 - 3~9.md
+++ /dev/null
@@ -1,361 +0,0 @@
-
-* [3. 数组中重复的数字](#3-数组中重复的数字)
-* [4. 二维数组中的查找](#4-二维数组中的查找)
-* [5. 替换空格](#5-替换空格)
-* [6. 从尾到头打印链表](#6-从尾到头打印链表)
-* [7. 重建二叉树](#7-重建二叉树)
-* [8. 二叉树的下一个结点](#8-二叉树的下一个结点)
-* [9. 用两个栈实现队列](#9-用两个栈实现队列)
-
-
-
-# 3. 数组中重复的数字
-
-[NowCoder](https://www.nowcoder.com/practice/623a5ac0ea5b4e5f95552655361ae0a8?tpId=13&tqId=11203&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-在一个长度为 n 的数组里的所有数字都在 0 到 n-1 的范围内。数组中某些数字是重复的,但不知道有几个数字是重复的,也不知道每个数字重复几次。请找出数组中任意一个重复的数字。
-
-```html
-Input:
-{2, 3, 1, 0, 2, 5}
-
-Output:
-2
-```
-
-## 解题思路
-
-要求时间复杂度 O(N),空间复杂度 O(1)。因此不能使用排序的方法,也不能使用额外的标记数组。
-
-对于这种数组元素在 [0, n-1] 范围内的问题,可以将值为 i 的元素调整到第 i 个位置上进行求解。
-
-以 (2, 3, 1, 0, 2, 5) 为例,遍历到位置 4 时,该位置上的数为 2,但是第 2 个位置上已经有一个 2 的值了,因此可以知道 2 重复:
-
- 
-
-
-```java
-public boolean duplicate(int[] nums, int length, int[] duplication) {
- if (nums == null || length <= 0)
- return false;
- for (int i = 0; i < length; i++) {
- while (nums[i] != i) {
- if (nums[i] == nums[nums[i]]) {
- duplication[0] = nums[i];
- return true;
- }
- swap(nums, i, nums[i]);
- }
- }
- return false;
-}
-
-private void swap(int[] nums, int i, int j) {
- int t = nums[i];
- nums[i] = nums[j];
- nums[j] = t;
-}
-```
-
-# 4. 二维数组中的查找
-
-[NowCoder](https://www.nowcoder.com/practice/abc3fe2ce8e146608e868a70efebf62e?tpId=13&tqId=11154&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-给定一个二维数组,其每一行从左到右递增排序,从上到下也是递增排序。给定一个数,判断这个数是否在该二维数组中。
-
-```html
-Consider the following matrix:
-[
- [1, 4, 7, 11, 15],
- [2, 5, 8, 12, 19],
- [3, 6, 9, 16, 22],
- [10, 13, 14, 17, 24],
- [18, 21, 23, 26, 30]
-]
-
-Given target = 5, return true.
-Given target = 20, return false.
-```
-
-## 解题思路
-
-要求时间复杂度 O(M + N),空间复杂度 O(1)。其中 M 为行数,N 为 列数。
-
-该二维数组中的一个数,小于它的数一定在其左边,大于它的数一定在其下边。因此,从右上角开始查找,就可以根据 target 和当前元素的大小关系来缩小查找区间,当前元素的查找区间为左下角的所有元素。
-
- 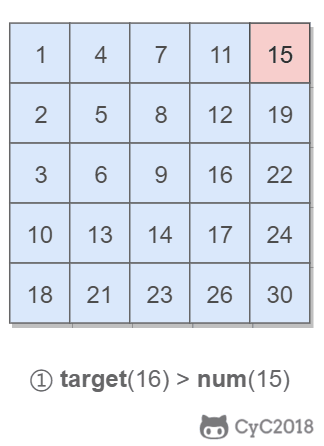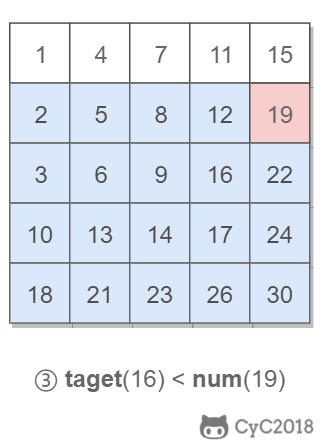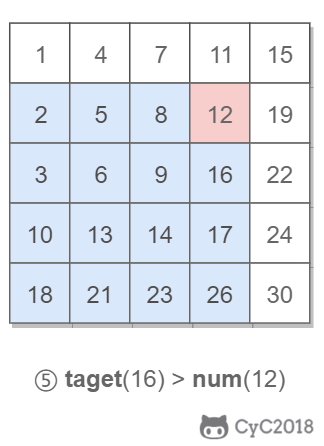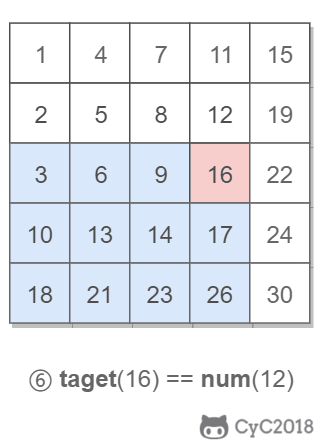
-
-```java
-public boolean Find(int target, int[][] matrix) {
- if (matrix == null || matrix.length == 0 || matrix[0].length == 0)
- return false;
- int rows = matrix.length, cols = matrix[0].length;
- int r = 0, c = cols - 1; // 从右上角开始
- while (r <= rows - 1 && c >= 0) {
- if (target == matrix[r][c])
- return true;
- else if (target > matrix[r][c])
- r++;
- else
- c--;
- }
- return false;
-}
-```
-
-# 5. 替换空格
-
-[NowCoder](https://www.nowcoder.com/practice/4060ac7e3e404ad1a894ef3e17650423?tpId=13&tqId=11155&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-
-将一个字符串中的空格替换成 "%20"。
-
-```text
-Input:
-"A B"
-
-Output:
-"A%20B"
-```
-
-## 解题思路
-
-在字符串尾部填充任意字符,使得字符串的长度等于替换之后的长度。因为一个空格要替换成三个字符(%20),因此当遍历到一个空格时,需要在尾部填充两个任意字符。
-
-令 P1 指向字符串原来的末尾位置,P2 指向字符串现在的末尾位置。P1 和 P2 从后向前遍历,当 P1 遍历到一个空格时,就需要令 P2 指向的位置依次填充 02%(注意是逆序的),否则就填充上 P1 指向字符的值。
-
-从后向前遍是为了在改变 P2 所指向的内容时,不会影响到 P1 遍历原来字符串的内容。
-
- 
-
-```java
-public String replaceSpace(StringBuffer str) {
- int P1 = str.length() - 1;
- for (int i = 0; i <= P1; i++)
- if (str.charAt(i) == ' ')
- str.append(" ");
-
- int P2 = str.length() - 1;
- while (P1 >= 0 && P2 > P1) {
- char c = str.charAt(P1--);
- if (c == ' ') {
- str.setCharAt(P2--, '0');
- str.setCharAt(P2--, '2');
- str.setCharAt(P2--, '%');
- } else {
- str.setCharAt(P2--, c);
- }
- }
- return str.toString();
-}
-```
-
-# 6. 从尾到头打印链表
-
-[NowCoder](https://www.nowcoder.com/practice/d0267f7f55b3412ba93bd35cfa8e8035?tpId=13&tqId=11156&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-从尾到头反过来打印出每个结点的值。
-
- 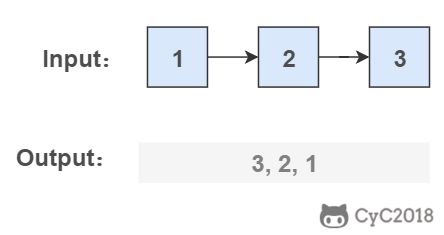
-
-## 解题思路
-
-### 使用递归
-
-要逆序打印链表 1-\>2-\>3(3,2,1),可以先逆序打印链表 2-\>3(3,2),最后再打印第一个节点 1。而链表 2-\>3 可以看成一个新的链表,要逆序打印该链表可以继续使用求解函数,也就是在求解函数中调用自己,这就是递归函数。
-
-```java
-public ArrayList printListFromTailToHead(ListNode listNode) {
- ArrayList ret = new ArrayList<>();
- if (listNode != null) {
- ret.addAll(printListFromTailToHead(listNode.next));
- ret.add(listNode.val);
- }
- return ret;
-}
-```
-
-### 使用头插法
-
-使用头插法可以得到一个逆序的链表。
-
-头结点和第一个节点的区别:
-
-- 头结点是在头插法中使用的一个额外节点,这个节点不存储值;
-- 第一个节点就是链表的第一个真正存储值的节点。
-
- 
-
-```java
-public ArrayList printListFromTailToHead(ListNode listNode) {
- // 头插法构建逆序链表
- ListNode head = new ListNode(-1);
- while (listNode != null) {
- ListNode memo = listNode.next;
- listNode.next = head.next;
- head.next = listNode;
- listNode = memo;
- }
- // 构建 ArrayList
- ArrayList ret = new ArrayList<>();
- head = head.next;
- while (head != null) {
- ret.add(head.val);
- head = head.next;
- }
- return ret;
-}
-```
-
-### 使用栈
-
-栈具有后进先出的特点,在遍历链表时将值按顺序放入栈中,最后出栈的顺序即为逆序。
-
- 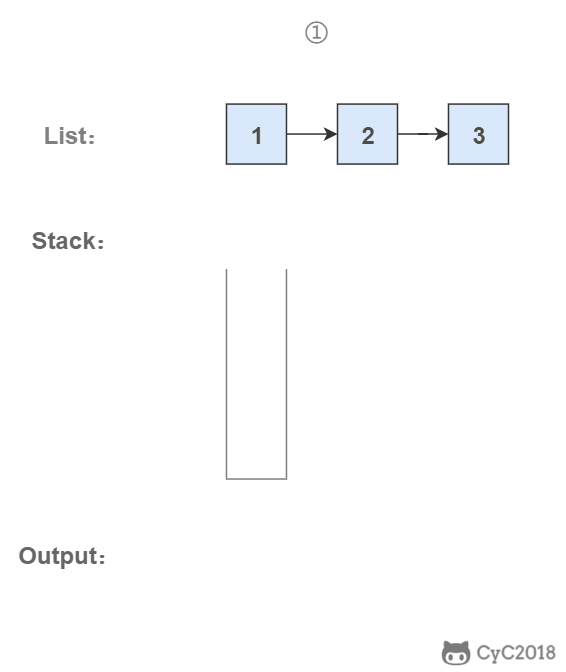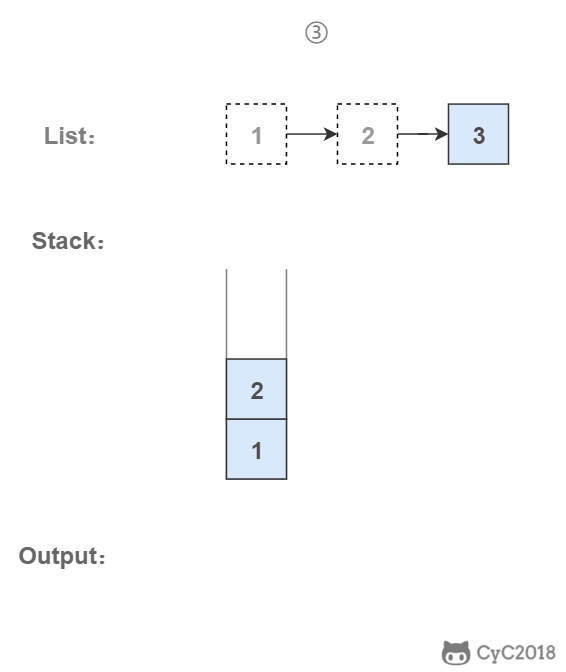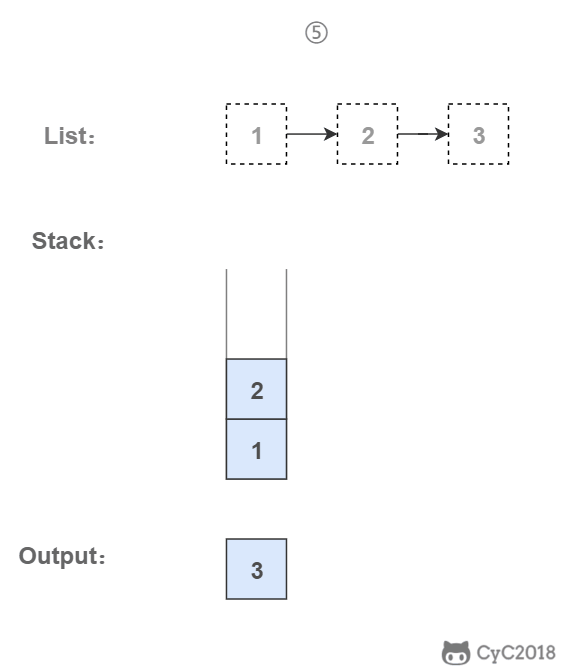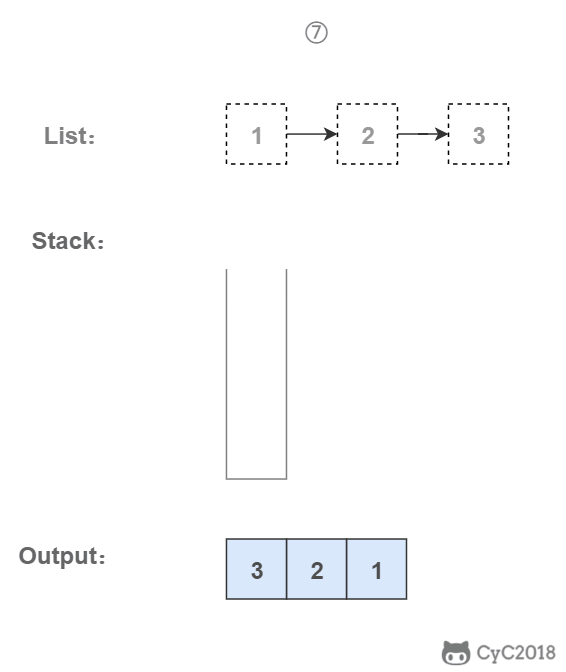
-
-```java
-public ArrayList printListFromTailToHead(ListNode listNode) {
- Stack stack = new Stack<>();
- while (listNode != null) {
- stack.add(listNode.val);
- listNode = listNode.next;
- }
- ArrayList ret = new ArrayList<>();
- while (!stack.isEmpty())
- ret.add(stack.pop());
- return ret;
-}
-```
-
-# 7. 重建二叉树
-
-[NowCoder](https://www.nowcoder.com/practice/8a19cbe657394eeaac2f6ea9b0f6fcf6?tpId=13&tqId=11157&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-根据二叉树的前序遍历和中序遍历的结果,重建出该二叉树。假设输入的前序遍历和中序遍历的结果中都不含重复的数字。
-
-
- 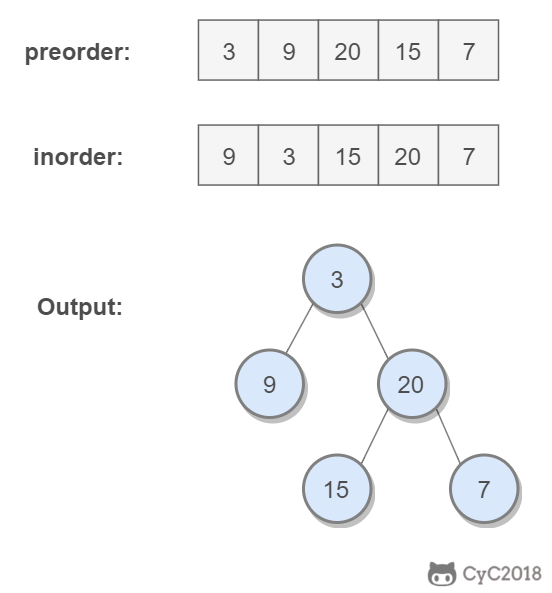
-
-## 解题思路
-
-前序遍历的第一个值为根节点的值,使用这个值将中序遍历结果分成两部分,左部分为树的左子树中序遍历结果,右部分为树的右子树中序遍历的结果。
-
- 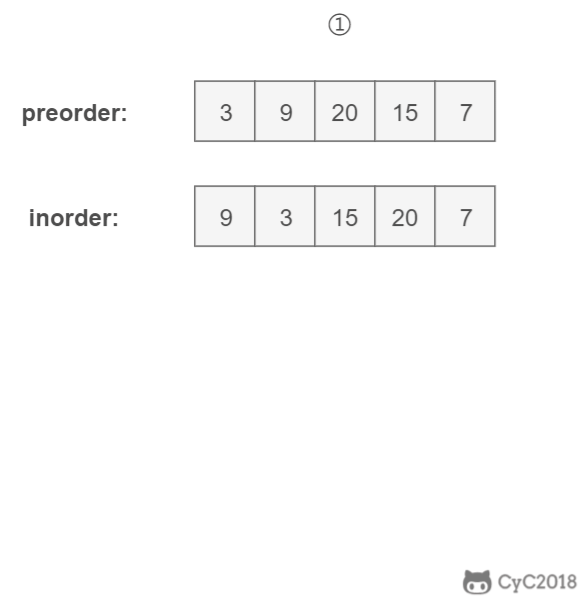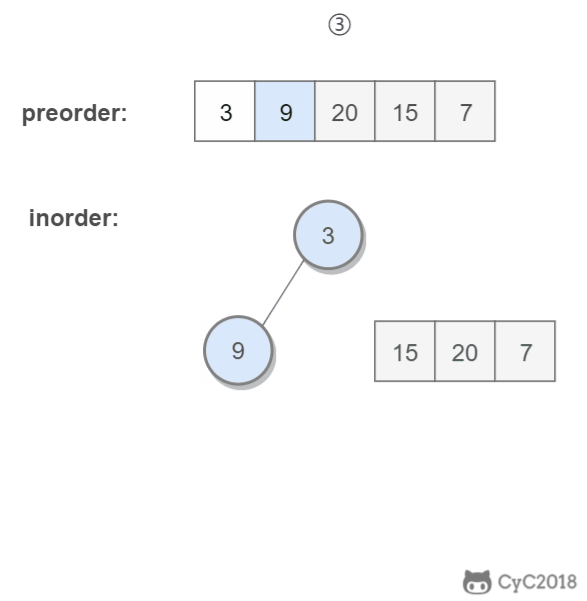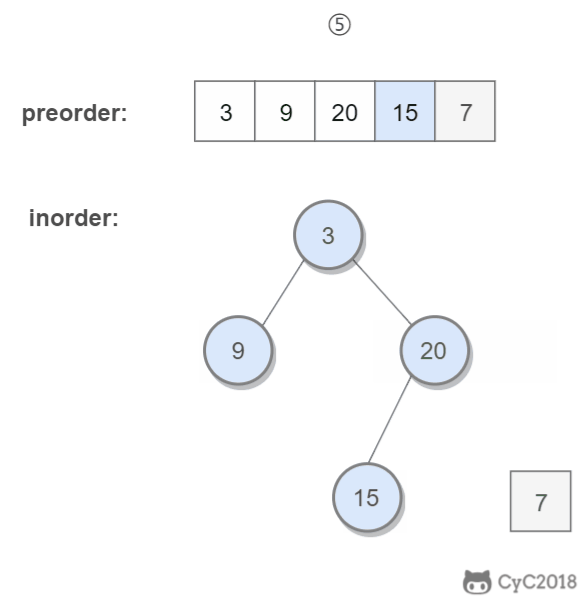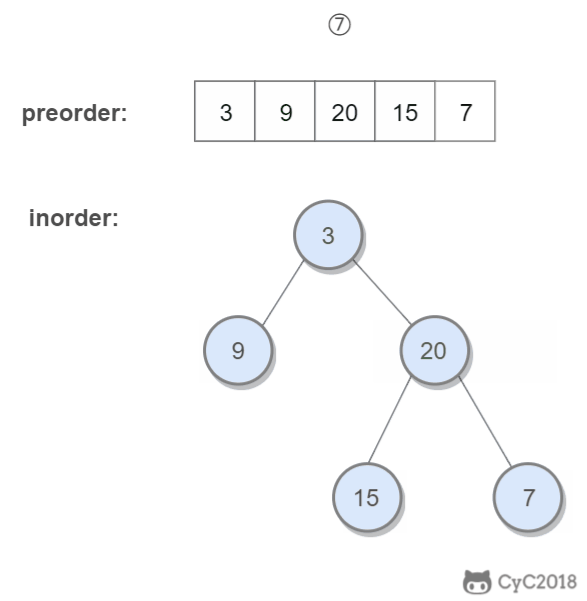
-
-```java
-// 缓存中序遍历数组每个值对应的索引
-private Map indexForInOrders = new HashMap<>();
-
-public TreeNode reConstructBinaryTree(int[] pre, int[] in) {
- for (int i = 0; i < in.length; i++)
- indexForInOrders.put(in[i], i);
- return reConstructBinaryTree(pre, 0, pre.length - 1, 0);
-}
-
-private TreeNode reConstructBinaryTree(int[] pre, int preL, int preR, int inL) {
- if (preL > preR)
- return null;
- TreeNode root = new TreeNode(pre[preL]);
- int inIndex = indexForInOrders.get(root.val);
- int leftTreeSize = inIndex - inL;
- root.left = reConstructBinaryTree(pre, preL + 1, preL + leftTreeSize, inL);
- root.right = reConstructBinaryTree(pre, preL + leftTreeSize + 1, preR, inL + leftTreeSize + 1);
- return root;
-}
-```
-
-# 8. 二叉树的下一个结点
-
-[NowCoder](https://www.nowcoder.com/practice/9023a0c988684a53960365b889ceaf5e?tpId=13&tqId=11210&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-给定一个二叉树和其中的一个结点,请找出中序遍历顺序的下一个结点并且返回。注意,树中的结点不仅包含左右子结点,同时包含指向父结点的指针。
-
-```java
-public class TreeLinkNode {
-
- int val;
- TreeLinkNode left = null;
- TreeLinkNode right = null;
- TreeLinkNode next = null;
-
- TreeLinkNode(int val) {
- this.val = val;
- }
-}
-```
-
-## 解题思路
-
-① 如果一个节点的右子树不为空,那么该节点的下一个节点是右子树的最左节点;
-
- 
-
-② 否则,向上找第一个左链接指向的树包含该节点的祖先节点。
-
- 
-
-```java
-public TreeLinkNode GetNext(TreeLinkNode pNode) {
- if (pNode.right != null) {
- TreeLinkNode node = pNode.right;
- while (node.left != null)
- node = node.left;
- return node;
- } else {
- while (pNode.next != null) {
- TreeLinkNode parent = pNode.next;
- if (parent.left == pNode)
- return parent;
- pNode = pNode.next;
- }
- }
- return null;
-}
-```
-
-# 9. 用两个栈实现队列
-
-[NowCoder](https://www.nowcoder.com/practice/54275ddae22f475981afa2244dd448c6?tpId=13&tqId=11158&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-用两个栈来实现一个队列,完成队列的 Push 和 Pop 操作。
-
-## 解题思路
-
-in 栈用来处理入栈(push)操作,out 栈用来处理出栈(pop)操作。一个元素进入 in 栈之后,出栈的顺序被反转。当元素要出栈时,需要先进入 out 栈,此时元素出栈顺序再一次被反转,因此出栈顺序就和最开始入栈顺序是相同的,先进入的元素先退出,这就是队列的顺序。
-
- 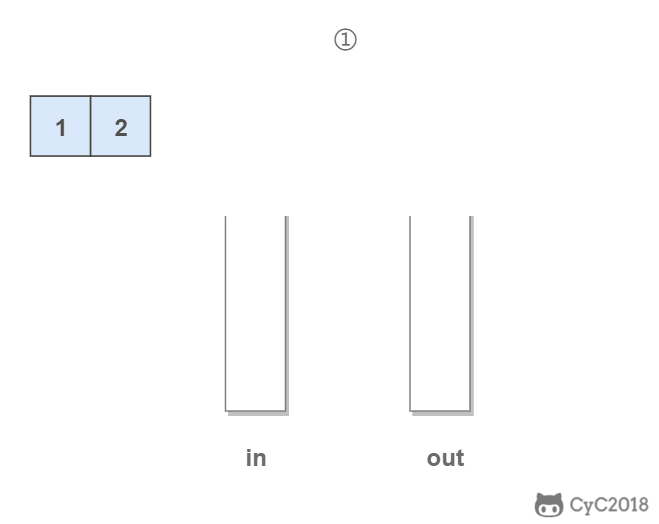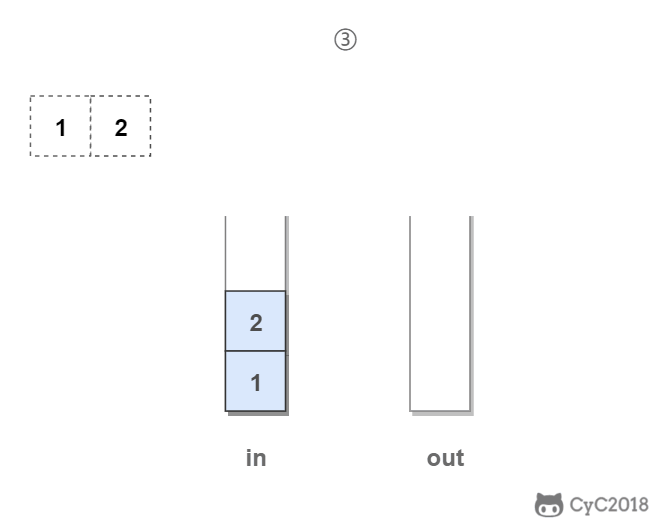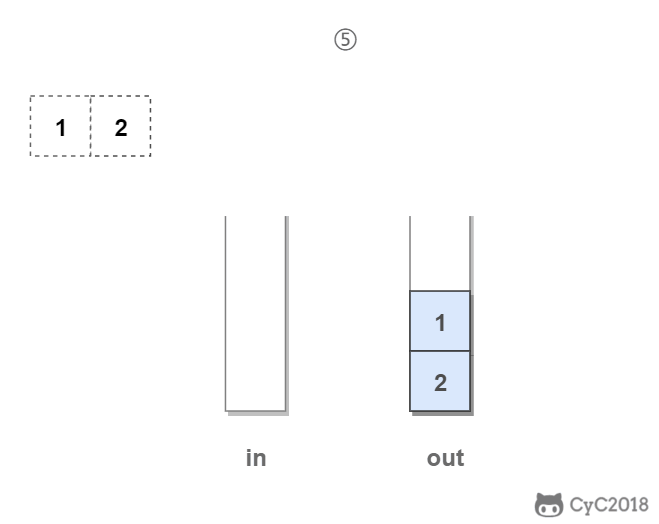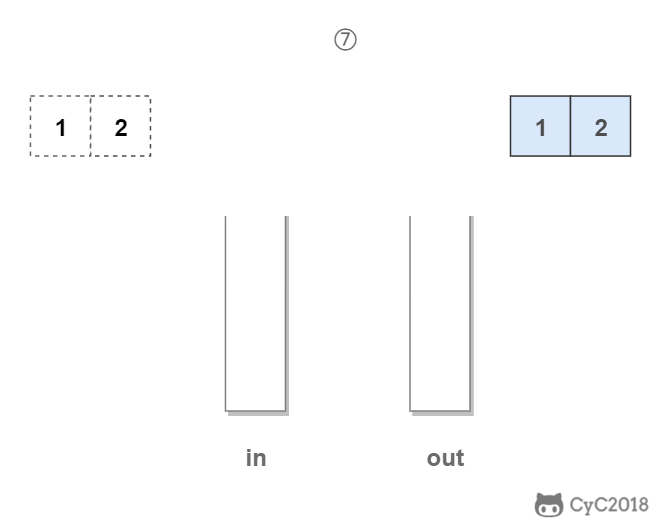
-
-```java
-Stack in = new Stack();
-Stack out = new Stack();
-
-public void push(int node) {
- in.push(node);
-}
-
-public int pop() throws Exception {
- if (out.isEmpty())
- while (!in.isEmpty())
- out.push(in.pop());
-
- if (out.isEmpty())
- throw new Exception("queue is empty");
-
- return out.pop();
-}
-```
-
diff --git a/notes/剑指 Offer 题解 - 40~49.md b/notes/剑指 Offer 题解 - 40~49.md
deleted file mode 100644
index c4694cae..00000000
--- a/notes/剑指 Offer 题解 - 40~49.md
+++ /dev/null
@@ -1,403 +0,0 @@
-# 40. 最小的 K 个数
-
-[NowCoder](https://www.nowcoder.com/practice/6a296eb82cf844ca8539b57c23e6e9bf?tpId=13&tqId=11182&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 解题思路
-
-### 快速选择
-
-- 复杂度:O(N) + O(1)
-- 只有当允许修改数组元素时才可以使用
-
-快速排序的 partition() 方法,会返回一个整数 j 使得 a[l..j-1] 小于等于 a[j],且 a[j+1..h] 大于等于 a[j],此时 a[j] 就是数组的第 j 大元素。可以利用这个特性找出数组的第 K 个元素,这种找第 K 个元素的算法称为快速选择算法。
-
-```java
-public ArrayList GetLeastNumbers_Solution(int[] nums, int k) {
- ArrayList ret = new ArrayList<>();
- if (k > nums.length || k <= 0)
- return ret;
- findKthSmallest(nums, k - 1);
- /* findKthSmallest 会改变数组,使得前 k 个数都是最小的 k 个数 */
- for (int i = 0; i < k; i++)
- ret.add(nums[i]);
- return ret;
-}
-
-public void findKthSmallest(int[] nums, int k) {
- int l = 0, h = nums.length - 1;
- while (l < h) {
- int j = partition(nums, l, h);
- if (j == k)
- break;
- if (j > k)
- h = j - 1;
- else
- l = j + 1;
- }
-}
-
-private int partition(int[] nums, int l, int h) {
- int p = nums[l]; /* 切分元素 */
- int i = l, j = h + 1;
- while (true) {
- while (i != h && nums[++i] < p) ;
- while (j != l && nums[--j] > p) ;
- if (i >= j)
- break;
- swap(nums, i, j);
- }
- swap(nums, l, j);
- return j;
-}
-
-private void swap(int[] nums, int i, int j) {
- int t = nums[i];
- nums[i] = nums[j];
- nums[j] = t;
-}
-```
-
-### 大小为 K 的最小堆
-
-- 复杂度:O(NlogK) + O(K)
-- 特别适合处理海量数据
-
-应该使用大顶堆来维护最小堆,而不能直接创建一个小顶堆并设置一个大小,企图让小顶堆中的元素都是最小元素。
-
-维护一个大小为 K 的最小堆过程如下:在添加一个元素之后,如果大顶堆的大小大于 K,那么需要将大顶堆的堆顶元素去除。
-
-```java
-public ArrayList GetLeastNumbers_Solution(int[] nums, int k) {
- if (k > nums.length || k <= 0)
- return new ArrayList<>();
- PriorityQueue maxHeap = new PriorityQueue<>((o1, o2) -> o2 - o1);
- for (int num : nums) {
- maxHeap.add(num);
- if (maxHeap.size() > k)
- maxHeap.poll();
- }
- return new ArrayList<>(maxHeap);
-}
-```
-
-# 41.1 数据流中的中位数
-
-[NowCoder](https://www.nowcoder.com/practice/9be0172896bd43948f8a32fb954e1be1?tpId=13&tqId=11216&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-如何得到一个数据流中的中位数?如果从数据流中读出奇数个数值,那么中位数就是所有数值排序之后位于中间的数值。如果从数据流中读出偶数个数值,那么中位数就是所有数值排序之后中间两个数的平均值。
-
-## 解题思路
-
-```java
-/* 大顶堆,存储左半边元素 */
-private PriorityQueue left = new PriorityQueue<>((o1, o2) -> o2 - o1);
-/* 小顶堆,存储右半边元素,并且右半边元素都大于左半边 */
-private PriorityQueue right = new PriorityQueue<>();
-/* 当前数据流读入的元素个数 */
-private int N = 0;
-
-public void Insert(Integer val) {
- /* 插入要保证两个堆存于平衡状态 */
- if (N % 2 == 0) {
- /* N 为偶数的情况下插入到右半边。
- * 因为右半边元素都要大于左半边,但是新插入的元素不一定比左半边元素来的大,
- * 因此需要先将元素插入左半边,然后利用左半边为大顶堆的特点,取出堆顶元素即为最大元素,此时插入右半边 */
- left.add(val);
- right.add(left.poll());
- } else {
- right.add(val);
- left.add(right.poll());
- }
- N++;
-}
-
-public Double GetMedian() {
- if (N % 2 == 0)
- return (left.peek() + right.peek()) / 2.0;
- else
- return (double) right.peek();
-}
-```
-
-# 41.2 字符流中第一个不重复的字符
-
-[NowCoder](https://www.nowcoder.com/practice/00de97733b8e4f97a3fb5c680ee10720?tpId=13&tqId=11207&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-请实现一个函数用来找出字符流中第一个只出现一次的字符。例如,当从字符流中只读出前两个字符 "go" 时,第一个只出现一次的字符是 "g"。当从该字符流中读出前六个字符“google" 时,第一个只出现一次的字符是 "l"。
-
-## 解题思路
-
-```java
-private int[] cnts = new int[256];
-private Queue queue = new LinkedList<>();
-
-public void Insert(char ch) {
- cnts[ch]++;
- queue.add(ch);
- while (!queue.isEmpty() && cnts[queue.peek()] > 1)
- queue.poll();
-}
-
-public char FirstAppearingOnce() {
- return queue.isEmpty() ? '#' : queue.peek();
-}
-```
-
-# 42. 连续子数组的最大和
-
-[NowCoder](https://www.nowcoder.com/practice/459bd355da1549fa8a49e350bf3df484?tpId=13&tqId=11183&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-{6, -3, -2, 7, -15, 1, 2, 2},连续子数组的最大和为 8(从第 0 个开始,到第 3 个为止)。
-
-## 解题思路
-
-```java
-public int FindGreatestSumOfSubArray(int[] nums) {
- if (nums == null || nums.length == 0)
- return 0;
- int greatestSum = Integer.MIN_VALUE;
- int sum = 0;
- for (int val : nums) {
- sum = sum <= 0 ? val : sum + val;
- greatestSum = Math.max(greatestSum, sum);
- }
- return greatestSum;
-}
-```
-
-# 43. 从 1 到 n 整数中 1 出现的次数
-
-[NowCoder](https://www.nowcoder.com/practice/bd7f978302044eee894445e244c7eee6?tpId=13&tqId=11184&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 解题思路
-
-```java
-public int NumberOf1Between1AndN_Solution(int n) {
- int cnt = 0;
- for (int m = 1; m <= n; m *= 10) {
- int a = n / m, b = n % m;
- cnt += (a + 8) / 10 * m + (a % 10 == 1 ? b + 1 : 0);
- }
- return cnt;
-}
-```
-
-\> [Leetcode : 233. Number of Digit One](https://leetcode.com/problems/number-of-digit-one/discuss/64381/4+-lines-O(log-n)-C++JavaPython)
-
-# 44. 数字序列中的某一位数字
-
-## 题目描述
-
-数字以 0123456789101112131415... 的格式序列化到一个字符串中,求这个字符串的第 index 位。
-
-## 解题思路
-
-```java
-public int getDigitAtIndex(int index) {
- if (index < 0)
- return -1;
- int place = 1; // 1 表示个位,2 表示 十位...
- while (true) {
- int amount = getAmountOfPlace(place);
- int totalAmount = amount * place;
- if (index < totalAmount)
- return getDigitAtIndex(index, place);
- index -= totalAmount;
- place++;
- }
-}
-
-/**
- * place 位数的数字组成的字符串长度
- * 10, 90, 900, ...
- */
-private int getAmountOfPlace(int place) {
- if (place == 1)
- return 10;
- return (int) Math.pow(10, place - 1) * 9;
-}
-
-/**
- * place 位数的起始数字
- * 0, 10, 100, ...
- */
-private int getBeginNumberOfPlace(int place) {
- if (place == 1)
- return 0;
- return (int) Math.pow(10, place - 1);
-}
-
-/**
- * 在 place 位数组成的字符串中,第 index 个数
- */
-private int getDigitAtIndex(int index, int place) {
- int beginNumber = getBeginNumberOfPlace(place);
- int shiftNumber = index / place;
- String number = (beginNumber + shiftNumber) + "";
- int count = index % place;
- return number.charAt(count) - '0';
-}
-```
-
-# 45. 把数组排成最小的数
-
-[NowCoder](https://www.nowcoder.com/practice/8fecd3f8ba334add803bf2a06af1b993?tpId=13&tqId=11185&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-输入一个正整数数组,把数组里所有数字拼接起来排成一个数,打印能拼接出的所有数字中最小的一个。例如输入数组 {3,32,321},则打印出这三个数字能排成的最小数字为 321323。
-
-## 解题思路
-
-可以看成是一个排序问题,在比较两个字符串 S1 和 S2 的大小时,应该比较的是 S1+S2 和 S2+S1 的大小,如果 S1+S2 \< S2+S1,那么应该把 S1 排在前面,否则应该把 S2 排在前面。
-
-```java
-public String PrintMinNumber(int[] numbers) {
- if (numbers == null || numbers.length == 0)
- return "";
- int n = numbers.length;
- String[] nums = new String[n];
- for (int i = 0; i < n; i++)
- nums[i] = numbers[i] + "";
- Arrays.sort(nums, (s1, s2) -> (s1 + s2).compareTo(s2 + s1));
- String ret = "";
- for (String str : nums)
- ret += str;
- return ret;
-}
-```
-
-# 46. 把数字翻译成字符串
-
-[Leetcode](https://leetcode.com/problems/decode-ways/description/)
-
-## 题目描述
-
-给定一个数字,按照如下规则翻译成字符串:1 翻译成“a”,2 翻译成“b”... 26 翻译成“z”。一个数字有多种翻译可能,例如 12258 一共有 5 种,分别是 abbeh,lbeh,aveh,abyh,lyh。实现一个函数,用来计算一个数字有多少种不同的翻译方法。
-
-## 解题思路
-
-```java
-public int numDecodings(String s) {
- if (s == null || s.length() == 0)
- return 0;
- int n = s.length();
- int[] dp = new int[n + 1];
- dp[0] = 1;
- dp[1] = s.charAt(0) == '0' ? 0 : 1;
- for (int i = 2; i <= n; i++) {
- int one = Integer.valueOf(s.substring(i - 1, i));
- if (one != 0)
- dp[i] += dp[i - 1];
- if (s.charAt(i - 2) == '0')
- continue;
- int two = Integer.valueOf(s.substring(i - 2, i));
- if (two <= 26)
- dp[i] += dp[i - 2];
- }
- return dp[n];
-}
-```
-
-# 47. 礼物的最大价值
-
-[NowCoder](https://www.nowcoder.com/questionTerminal/72a99e28381a407991f2c96d8cb238ab)
-
-## 题目描述
-
-在一个 m\*n 的棋盘的每一个格都放有一个礼物,每个礼物都有一定价值(大于 0)。从左上角开始拿礼物,每次向右或向下移动一格,直到右下角结束。给定一个棋盘,求拿到礼物的最大价值。例如,对于如下棋盘
-
-```
-1 10 3 8
-12 2 9 6
-5 7 4 11
-3 7 16 5
-```
-
-礼物的最大价值为 1+12+5+7+7+16+5=53。
-
-## 解题思路
-
-应该用动态规划求解,而不是深度优先搜索,深度优先搜索过于复杂,不是最优解。
-
-```java
-public int getMost(int[][] values) {
- if (values == null || values.length == 0 || values[0].length == 0)
- return 0;
- int n = values[0].length;
- int[] dp = new int[n];
- for (int[] value : values) {
- dp[0] += value[0];
- for (int i = 1; i < n; i++)
- dp[i] = Math.max(dp[i], dp[i - 1]) + value[i];
- }
- return dp[n - 1];
-}
-```
-
-# 48. 最长不含重复字符的子字符串
-
-## 题目描述
-
-输入一个字符串(只包含 a\~z 的字符),求其最长不含重复字符的子字符串的长度。例如对于 arabcacfr,最长不含重复字符的子字符串为 acfr,长度为 4。
-
-## 解题思路
-
-```java
-public int longestSubStringWithoutDuplication(String str) {
- int curLen = 0;
- int maxLen = 0;
- int[] preIndexs = new int[26];
- Arrays.fill(preIndexs, -1);
- for (int curI = 0; curI < str.length(); curI++) {
- int c = str.charAt(curI) - 'a';
- int preI = preIndexs[c];
- if (preI == -1 || curI - preI > curLen) {
- curLen++;
- } else {
- maxLen = Math.max(maxLen, curLen);
- curLen = curI - preI;
- }
- preIndexs[c] = curI;
- }
- maxLen = Math.max(maxLen, curLen);
- return maxLen;
-}
-```
-
-# 49. 丑数
-
-[NowCoder](https://www.nowcoder.com/practice/6aa9e04fc3794f68acf8778237ba065b?tpId=13&tqId=11186&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-把只包含因子 2、3 和 5 的数称作丑数(Ugly Number)。例如 6、8 都是丑数,但 14 不是,因为它包含因子 7。习惯上我们把 1 当做是第一个丑数。求按从小到大的顺序的第 N 个丑数。
-
-## 解题思路
-
-```java
-public int GetUglyNumber_Solution(int N) {
- if (N <= 6)
- return N;
- int i2 = 0, i3 = 0, i5 = 0;
- int[] dp = new int[N];
- dp[0] = 1;
- for (int i = 1; i < N; i++) {
- int next2 = dp[i2] * 2, next3 = dp[i3] * 3, next5 = dp[i5] * 5;
- dp[i] = Math.min(next2, Math.min(next3, next5));
- if (dp[i] == next2)
- i2++;
- if (dp[i] == next3)
- i3++;
- if (dp[i] == next5)
- i5++;
- }
- return dp[N - 1];
-}
-```
diff --git a/notes/剑指 Offer 题解 - 50~59.md b/notes/剑指 Offer 题解 - 50~59.md
deleted file mode 100644
index 49d0c146..00000000
--- a/notes/剑指 Offer 题解 - 50~59.md
+++ /dev/null
@@ -1,479 +0,0 @@
-
-* [50. 第一个只出现一次的字符位置](#50-第一个只出现一次的字符位置)
-* [51. 数组中的逆序对](#51-数组中的逆序对)
-* [52. 两个链表的第一个公共结点](#52-两个链表的第一个公共结点)
-* [53. 数字在排序数组中出现的次数](#53-数字在排序数组中出现的次数)
-* [54. 二叉查找树的第 K 个结点](#54-二叉查找树的第-k-个结点)
-* [55.1 二叉树的深度](#551-二叉树的深度)
-* [55.2 平衡二叉树](#552-平衡二叉树)
-* [56. 数组中只出现一次的数字](#56-数组中只出现一次的数字)
-* [57.1 和为 S 的两个数字](#571-和为-s-的两个数字)
-* [57.2 和为 S 的连续正数序列](#572-和为-s-的连续正数序列)
-* [58.1 翻转单词顺序列](#581-翻转单词顺序列)
-* [58.2 左旋转字符串](#582-左旋转字符串)
-* [59. 滑动窗口的最大值](#59-滑动窗口的最大值)
-
-
-
-# 50. 第一个只出现一次的字符位置
-
-[NowCoder](https://www.nowcoder.com/practice/1c82e8cf713b4bbeb2a5b31cf5b0417c?tpId=13&tqId=11187&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-在一个字符串中找到第一个只出现一次的字符,并返回它的位置。
-
-```
-Input: abacc
-Output: b
-```
-
-## 解题思路
-
-最直观的解法是使用 HashMap 对出现次数进行统计,但是考虑到要统计的字符范围有限,因此可以使用整型数组代替 HashMap,从而将空间复杂度由 O(N) 降低为 O(1)。
-
-```java
-public int FirstNotRepeatingChar(String str) {
- int[] cnts = new int[256];
- for (int i = 0; i < str.length(); i++)
- cnts[str.charAt(i)]++;
- for (int i = 0; i < str.length(); i++)
- if (cnts[str.charAt(i)] == 1)
- return i;
- return -1;
-}
-```
-
-以上实现的空间复杂度还不是最优的。考虑到只需要找到只出现一次的字符,那么需要统计的次数信息只有 0,1,更大,使用两个比特位就能存储这些信息。
-
-```java
-public int FirstNotRepeatingChar2(String str) {
- BitSet bs1 = new BitSet(256);
- BitSet bs2 = new BitSet(256);
- for (char c : str.toCharArray()) {
- if (!bs1.get(c) && !bs2.get(c))
- bs1.set(c); // 0 0 -> 0 1
- else if (bs1.get(c) && !bs2.get(c))
- bs2.set(c); // 0 1 -> 1 1
- }
- for (int i = 0; i < str.length(); i++) {
- char c = str.charAt(i);
- if (bs1.get(c) && !bs2.get(c)) // 0 1
- return i;
- }
- return -1;
-}
-```
-
-# 51. 数组中的逆序对
-
-[NowCoder](https://www.nowcoder.com/practice/96bd6684e04a44eb80e6a68efc0ec6c5?tpId=13&tqId=11188&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-在数组中的两个数字,如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对。输入一个数组,求出这个数组中的逆序对的总数。
-
-## 解题思路
-
-```java
-private long cnt = 0;
-private int[] tmp; // 在这里声明辅助数组,而不是在 merge() 递归函数中声明
-
-public int InversePairs(int[] nums) {
- tmp = new int[nums.length];
- mergeSort(nums, 0, nums.length - 1);
- return (int) (cnt % 1000000007);
-}
-
-private void mergeSort(int[] nums, int l, int h) {
- if (h - l < 1)
- return;
- int m = l + (h - l) / 2;
- mergeSort(nums, l, m);
- mergeSort(nums, m + 1, h);
- merge(nums, l, m, h);
-}
-
-private void merge(int[] nums, int l, int m, int h) {
- int i = l, j = m + 1, k = l;
- while (i <= m || j <= h) {
- if (i > m)
- tmp[k] = nums[j++];
- else if (j > h)
- tmp[k] = nums[i++];
- else if (nums[i] <= nums[j])
- tmp[k] = nums[i++];
- else {
- tmp[k] = nums[j++];
- this.cnt += m - i + 1; // nums[i] > nums[j],说明 nums[i...mid] 都大于 nums[j]
- }
- k++;
- }
- for (k = l; k <= h; k++)
- nums[k] = tmp[k];
-}
-```
-
-# 52. 两个链表的第一个公共结点
-
-[NowCoder](https://www.nowcoder.com/practice/6ab1d9a29e88450685099d45c9e31e46?tpId=13&tqId=11189&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
- 
-
-## 解题思路
-
-设 A 的长度为 a + c,B 的长度为 b + c,其中 c 为尾部公共部分长度,可知 a + c + b = b + c + a。
-
-当访问链表 A 的指针访问到链表尾部时,令它从链表 B 的头部重新开始访问链表 B;同样地,当访问链表 B 的指针访问到链表尾部时,令它从链表 A 的头部重新开始访问链表 A。这样就能控制访问 A 和 B 两个链表的指针能同时访问到交点。
-
-```java
-public ListNode FindFirstCommonNode(ListNode pHead1, ListNode pHead2) {
- ListNode l1 = pHead1, l2 = pHead2;
- while (l1 != l2) {
- l1 = (l1 == null) ? pHead2 : l1.next;
- l2 = (l2 == null) ? pHead1 : l2.next;
- }
- return l1;
-}
-```
-
-# 53. 数字在排序数组中出现的次数
-
-[NowCoder](https://www.nowcoder.com/practice/70610bf967994b22bb1c26f9ae901fa2?tpId=13&tqId=11190&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-```html
-Input:
-nums = 1, 2, 3, 3, 3, 3, 4, 6
-K = 3
-
-Output:
-4
-```
-
-## 解题思路
-
-```java
-public int GetNumberOfK(int[] nums, int K) {
- int first = binarySearch(nums, K);
- int last = binarySearch(nums, K + 1);
- return (first == nums.length || nums[first] != K) ? 0 : last - first;
-}
-
-private int binarySearch(int[] nums, int K) {
- int l = 0, h = nums.length;
- while (l < h) {
- int m = l + (h - l) / 2;
- if (nums[m] >= K)
- h = m;
- else
- l = m + 1;
- }
- return l;
-}
-```
-
-# 54. 二叉查找树的第 K 个结点
-
-[NowCoder](https://www.nowcoder.com/practice/ef068f602dde4d28aab2b210e859150a?tpId=13&tqId=11215&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 解题思路
-
-利用二叉查找树中序遍历有序的特点。
-
-```java
-private TreeNode ret;
-private int cnt = 0;
-
-public TreeNode KthNode(TreeNode pRoot, int k) {
- inOrder(pRoot, k);
- return ret;
-}
-
-private void inOrder(TreeNode root, int k) {
- if (root == null || cnt >= k)
- return;
- inOrder(root.left, k);
- cnt++;
- if (cnt == k)
- ret = root;
- inOrder(root.right, k);
-}
-```
-
-# 55.1 二叉树的深度
-
-[NowCoder](https://www.nowcoder.com/practice/435fb86331474282a3499955f0a41e8b?tpId=13&tqId=11191&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-从根结点到叶结点依次经过的结点(含根、叶结点)形成树的一条路径,最长路径的长度为树的深度。
-
- 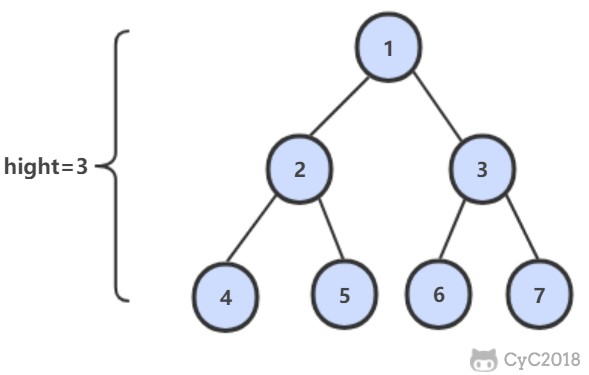
-
-## 解题思路
-
-```java
-public int TreeDepth(TreeNode root) {
- return root == null ? 0 : 1 + Math.max(TreeDepth(root.left), TreeDepth(root.right));
-}
-```
-
-# 55.2 平衡二叉树
-
-[NowCoder](https://www.nowcoder.com/practice/8b3b95850edb4115918ecebdf1b4d222?tpId=13&tqId=11192&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-平衡二叉树左右子树高度差不超过 1。
-
- 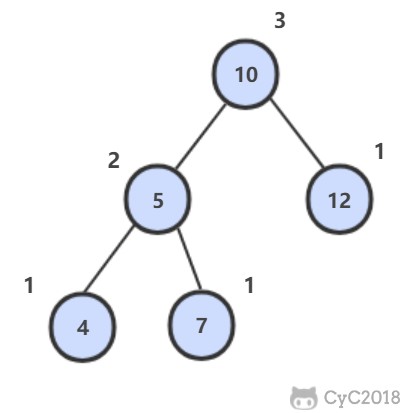
-
-## 解题思路
-
-```java
-private boolean isBalanced = true;
-
-public boolean IsBalanced_Solution(TreeNode root) {
- height(root);
- return isBalanced;
-}
-
-private int height(TreeNode root) {
- if (root == null || !isBalanced)
- return 0;
- int left = height(root.left);
- int right = height(root.right);
- if (Math.abs(left - right) > 1)
- isBalanced = false;
- return 1 + Math.max(left, right);
-}
-```
-
-# 56. 数组中只出现一次的数字
-
-[NowCoder](https://www.nowcoder.com/practice/e02fdb54d7524710a7d664d082bb7811?tpId=13&tqId=11193&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-一个整型数组里除了两个数字之外,其他的数字都出现了两次,找出这两个数。
-
-## 解题思路
-
-两个不相等的元素在位级表示上必定会有一位存在不同,将数组的所有元素异或得到的结果为不存在重复的两个元素异或的结果。
-
-diff &= -diff 得到出 diff 最右侧不为 0 的位,也就是不存在重复的两个元素在位级表示上最右侧不同的那一位,利用这一位就可以将两个元素区分开来。
-
-```java
-public void FindNumsAppearOnce(int[] nums, int num1[], int num2[]) {
- int diff = 0;
- for (int num : nums)
- diff ^= num;
- diff &= -diff;
- for (int num : nums) {
- if ((num & diff) == 0)
- num1[0] ^= num;
- else
- num2[0] ^= num;
- }
-}
-```
-
-# 57.1 和为 S 的两个数字
-
-[NowCoder](https://www.nowcoder.com/practice/390da4f7a00f44bea7c2f3d19491311b?tpId=13&tqId=11195&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-输入一个递增排序的数组和一个数字 S,在数组中查找两个数,使得他们的和正好是 S。如果有多对数字的和等于 S,输出两个数的乘积最小的。
-
-## 解题思路
-
-使用双指针,一个指针指向元素较小的值,一个指针指向元素较大的值。指向较小元素的指针从头向尾遍历,指向较大元素的指针从尾向头遍历。
-
-- 如果两个指针指向元素的和 sum == target,那么得到要求的结果;
-- 如果 sum \> target,移动较大的元素,使 sum 变小一些;
-- 如果 sum \< target,移动较小的元素,使 sum 变大一些。
-
-```java
-public ArrayList FindNumbersWithSum(int[] array, int sum) {
- int i = 0, j = array.length - 1;
- while (i < j) {
- int cur = array[i] + array[j];
- if (cur == sum)
- return new ArrayList<>(Arrays.asList(array[i], array[j]));
- if (cur < sum)
- i++;
- else
- j--;
- }
- return new ArrayList<>();
-}
-```
-
-# 57.2 和为 S 的连续正数序列
-
-[NowCoder](https://www.nowcoder.com/practice/c451a3fd84b64cb19485dad758a55ebe?tpId=13&tqId=11194&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-输出所有和为 S 的连续正数序列。
-
-例如和为 100 的连续序列有:
-
-```
-[9, 10, 11, 12, 13, 14, 15, 16]
-[18, 19, 20, 21, 22]。
-```
-
-## 解题思路
-
-```java
-public ArrayList> FindContinuousSequence(int sum) {
- ArrayList> ret = new ArrayList<>();
- int start = 1, end = 2;
- int curSum = 3;
- while (end < sum) {
- if (curSum > sum) {
- curSum -= start;
- start++;
- } else if (curSum < sum) {
- end++;
- curSum += end;
- } else {
- ArrayList list = new ArrayList<>();
- for (int i = start; i <= end; i++)
- list.add(i);
- ret.add(list);
- curSum -= start;
- start++;
- end++;
- curSum += end;
- }
- }
- return ret;
-}
-```
-
-# 58.1 翻转单词顺序列
-
-[NowCoder](https://www.nowcoder.com/practice/3194a4f4cf814f63919d0790578d51f3?tpId=13&tqId=11197&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-```html
-Input:
-"I am a student."
-
-Output:
-"student. a am I"
-```
-
-## 解题思路
-
-题目应该有一个隐含条件,就是不能用额外的空间。虽然 Java 的题目输入参数为 String 类型,需要先创建一个字符数组使得空间复杂度为 O(N),但是正确的参数类型应该和原书一样,为字符数组,并且只能使用该字符数组的空间。任何使用了额外空间的解法在面试时都会大打折扣,包括递归解法。
-
-正确的解法应该是和书上一样,先旋转每个单词,再旋转整个字符串。
-
-```java
-public String ReverseSentence(String str) {
- int n = str.length();
- char[] chars = str.toCharArray();
- int i = 0, j = 0;
- while (j <= n) {
- if (j == n || chars[j] == ' ') {
- reverse(chars, i, j - 1);
- i = j + 1;
- }
- j++;
- }
- reverse(chars, 0, n - 1);
- return new String(chars);
-}
-
-private void reverse(char[] c, int i, int j) {
- while (i < j)
- swap(c, i++, j--);
-}
-
-private void swap(char[] c, int i, int j) {
- char t = c[i];
- c[i] = c[j];
- c[j] = t;
-}
-```
-
-# 58.2 左旋转字符串
-
-[NowCoder](https://www.nowcoder.com/practice/12d959b108cb42b1ab72cef4d36af5ec?tpId=13&tqId=11196&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-```html
-Input:
-S="abcXYZdef"
-K=3
-
-Output:
-"XYZdefabc"
-```
-
-## 解题思路
-
-先将 "abc" 和 "XYZdef" 分别翻转,得到 "cbafedZYX",然后再把整个字符串翻转得到 "XYZdefabc"。
-
-```java
-public String LeftRotateString(String str, int n) {
- if (n >= str.length())
- return str;
- char[] chars = str.toCharArray();
- reverse(chars, 0, n - 1);
- reverse(chars, n, chars.length - 1);
- reverse(chars, 0, chars.length - 1);
- return new String(chars);
-}
-
-private void reverse(char[] chars, int i, int j) {
- while (i < j)
- swap(chars, i++, j--);
-}
-
-private void swap(char[] chars, int i, int j) {
- char t = chars[i];
- chars[i] = chars[j];
- chars[j] = t;
-}
-```
-
-# 59. 滑动窗口的最大值
-
-[NowCoder](https://www.nowcoder.com/practice/1624bc35a45c42c0bc17d17fa0cba788?tpId=13&tqId=11217&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-给定一个数组和滑动窗口的大小,找出所有滑动窗口里数值的最大值。
-
-例如,如果输入数组 {2, 3, 4, 2, 6, 2, 5, 1} 及滑动窗口的大小 3,那么一共存在 6 个滑动窗口,他们的最大值分别为 {4, 4, 6, 6, 6, 5}。
-
-## 解题思路
-
-```java
-public ArrayList maxInWindows(int[] num, int size) {
- ArrayList ret = new ArrayList<>();
- if (size > num.length || size < 1)
- return ret;
- PriorityQueue heap = new PriorityQueue<>((o1, o2) -> o2 - o1); /* 大顶堆 */
- for (int i = 0; i < size; i++)
- heap.add(num[i]);
- ret.add(heap.peek());
- for (int i = 0, j = i + size; j < num.length; i++, j++) { /* 维护一个大小为 size 的大顶堆 */
- heap.remove(num[i]);
- heap.add(num[j]);
- ret.add(heap.peek());
- }
- return ret;
-}
-```
diff --git a/notes/剑指 Offer 题解 - 60~68.md b/notes/剑指 Offer 题解 - 60~68.md
deleted file mode 100644
index cc32cf3a..00000000
--- a/notes/剑指 Offer 题解 - 60~68.md
+++ /dev/null
@@ -1,322 +0,0 @@
-
-* [60. n 个骰子的点数](#60-n-个骰子的点数)
-* [61. 扑克牌顺子](#61-扑克牌顺子)
-* [62. 圆圈中最后剩下的数](#62-圆圈中最后剩下的数)
-* [63. 股票的最大利润](#63-股票的最大利润)
-* [64. 求 1+2+3+...+n](#64-求-123n)
-* [65. 不用加减乘除做加法](#65-不用加减乘除做加法)
-* [66. 构建乘积数组](#66-构建乘积数组)
-* [67. 把字符串转换成整数](#67-把字符串转换成整数)
-* [68. 树中两个节点的最低公共祖先](#68-树中两个节点的最低公共祖先)
-
-
-
-# 60. n 个骰子的点数
-
-[Lintcode](https://www.lintcode.com/en/problem/dices-sum/)
-
-## 题目描述
-
-把 n 个骰子扔在地上,求点数和为 s 的概率。
-
-
-
-## 解题思路
-
-### 动态规划
-
-使用一个二维数组 dp 存储点数出现的次数,其中 dp[i][j] 表示前 i 个骰子产生点数 j 的次数。
-
-空间复杂度:O(N2)
-
-```java
-public List> dicesSum(int n) {
- final int face = 6;
- final int pointNum = face * n;
- long[][] dp = new long[n + 1][pointNum + 1];
-
- for (int i = 1; i <= face; i++)
- dp[1][i] = 1;
-
- for (int i = 2; i <= n; i++)
- for (int j = i; j <= pointNum; j++) /* 使用 i 个骰子最小点数为 i */
- for (int k = 1; k <= face && k <= j; k++)
- dp[i][j] += dp[i - 1][j - k];
-
- final double totalNum = Math.pow(6, n);
- List> ret = new ArrayList<>();
- for (int i = n; i <= pointNum; i++)
- ret.add(new AbstractMap.SimpleEntry<>(i, dp[n][i] / totalNum));
-
- return ret;
-}
-```
-
-### 动态规划 + 旋转数组
-
-空间复杂度:O(N)
-
-```java
-public List> dicesSum(int n) {
- final int face = 6;
- final int pointNum = face * n;
- long[][] dp = new long[2][pointNum + 1];
-
- for (int i = 1; i <= face; i++)
- dp[0][i] = 1;
-
- int flag = 1; /* 旋转标记 */
- for (int i = 2; i <= n; i++, flag = 1 - flag) {
- for (int j = 0; j <= pointNum; j++)
- dp[flag][j] = 0; /* 旋转数组清零 */
-
- for (int j = i; j <= pointNum; j++)
- for (int k = 1; k <= face && k <= j; k++)
- dp[flag][j] += dp[1 - flag][j - k];
- }
-
- final double totalNum = Math.pow(6, n);
- List> ret = new ArrayList<>();
- for (int i = n; i <= pointNum; i++)
- ret.add(new AbstractMap.SimpleEntry<>(i, dp[1 - flag][i] / totalNum));
-
- return ret;
-}
-```
-
-# 61. 扑克牌顺子
-
-[NowCoder](https://www.nowcoder.com/practice/762836f4d43d43ca9deb273b3de8e1f4?tpId=13&tqId=11198&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-五张牌,其中大小鬼为癞子,牌面为 0。判断这五张牌是否能组成顺子。
-
-
-
-
-## 解题思路
-
-```java
-public boolean isContinuous(int[] nums) {
-
- if (nums.length < 5)
- return false;
-
- Arrays.sort(nums);
-
- // 统计癞子数量
- int cnt = 0;
- for (int num : nums)
- if (num == 0)
- cnt++;
-
- // 使用癞子去补全不连续的顺子
- for (int i = cnt; i < nums.length - 1; i++) {
- if (nums[i + 1] == nums[i])
- return false;
- cnt -= nums[i + 1] - nums[i] - 1;
- }
-
- return cnt >= 0;
-}
-```
-
-# 62. 圆圈中最后剩下的数
-
-[NowCoder](https://www.nowcoder.com/practice/f78a359491e64a50bce2d89cff857eb6?tpId=13&tqId=11199&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-让小朋友们围成一个大圈。然后,随机指定一个数 m,让编号为 0 的小朋友开始报数。每次喊到 m-1 的那个小朋友要出列唱首歌,然后可以在礼品箱中任意的挑选礼物,并且不再回到圈中,从他的下一个小朋友开始,继续 0...m-1 报数 .... 这样下去 .... 直到剩下最后一个小朋友,可以不用表演。
-
-## 解题思路
-
-约瑟夫环,圆圈长度为 n 的解可以看成长度为 n-1 的解再加上报数的长度 m。因为是圆圈,所以最后需要对 n 取余。
-
-```java
-public int LastRemaining_Solution(int n, int m) {
- if (n == 0) /* 特殊输入的处理 */
- return -1;
- if (n == 1) /* 递归返回条件 */
- return 0;
- return (LastRemaining_Solution(n - 1, m) + m) % n;
-}
-```
-
-# 63. 股票的最大利润
-
-[Leetcode](https://leetcode.com/problems/best-time-to-buy-and-sell-stock/description/)
-
-## 题目描述
-
-可以有一次买入和一次卖出,买入必须在前。求最大收益。
-
-
-
-## 解题思路
-
-使用贪心策略,假设第 i 轮进行卖出操作,买入操作价格应该在 i 之前并且价格最低。
-
-```java
-public int maxProfit(int[] prices) {
- if (prices == null || prices.length == 0)
- return 0;
- int soFarMin = prices[0];
- int maxProfit = 0;
- for (int i = 1; i < prices.length; i++) {
- soFarMin = Math.min(soFarMin, prices[i]);
- maxProfit = Math.max(maxProfit, prices[i] - soFarMin);
- }
- return maxProfit;
-}
-```
-
-# 64. 求 1+2+3+...+n
-
-[NowCoder](https://www.nowcoder.com/practice/7a0da8fc483247ff8800059e12d7caf1?tpId=13&tqId=11200&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-要求不能使用乘除法、for、while、if、else、switch、case 等关键字及条件判断语句 A ? B : C。
-
-## 解题思路
-
-使用递归解法最重要的是指定返回条件,但是本题无法直接使用 if 语句来指定返回条件。
-
-条件与 && 具有短路原则,即在第一个条件语句为 false 的情况下不会去执行第二个条件语句。利用这一特性,将递归的返回条件取非然后作为 && 的第一个条件语句,递归的主体转换为第二个条件语句,那么当递归的返回条件为 true 的情况下就不会执行递归的主体部分,递归返回。
-
-本题的递归返回条件为 n \<= 0,取非后就是 n \> 0;递归的主体部分为 sum += Sum_Solution(n - 1),转换为条件语句后就是 (sum += Sum_Solution(n - 1)) \> 0。
-
-```java
-public int Sum_Solution(int n) {
- int sum = n;
- boolean b = (n > 0) && ((sum += Sum_Solution(n - 1)) > 0);
- return sum;
-}
-```
-
-# 65. 不用加减乘除做加法
-
-[NowCoder](https://www.nowcoder.com/practice/59ac416b4b944300b617d4f7f111b215?tpId=13&tqId=11201&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-写一个函数,求两个整数之和,要求不得使用 +、-、\*、/ 四则运算符号。
-
-## 解题思路
-
-a ^ b 表示没有考虑进位的情况下两数的和,(a & b) \<\< 1 就是进位。
-
-递归会终止的原因是 (a & b) \<\< 1 最右边会多一个 0,那么继续递归,进位最右边的 0 会慢慢增多,最后进位会变为 0,递归终止。
-
-```java
-public int Add(int a, int b) {
- return b == 0 ? a : Add(a ^ b, (a & b) << 1);
-}
-```
-
-# 66. 构建乘积数组
-
-[NowCoder](https://www.nowcoder.com/practice/94a4d381a68b47b7a8bed86f2975db46?tpId=13&tqId=11204&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-给定一个数组 A[0, 1,..., n-1],请构建一个数组 B[0, 1,..., n-1],其中 B 中的元素 B[i]=A[0]\*A[1]\*...\*A[i-1]\*A[i+1]\*...\*A[n-1]。要求不能使用除法。
-
-
-
-
-## 解题思路
-
-```java
-public int[] multiply(int[] A) {
- int n = A.length;
- int[] B = new int[n];
- for (int i = 0, product = 1; i < n; product *= A[i], i++) /* 从左往右累乘 */
- B[i] = product;
- for (int i = n - 1, product = 1; i >= 0; product *= A[i], i--) /* 从右往左累乘 */
- B[i] *= product;
- return B;
-}
-```
-
-# 67. 把字符串转换成整数
-
-[NowCoder](https://www.nowcoder.com/practice/1277c681251b4372bdef344468e4f26e?tpId=13&tqId=11202&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
-
-## 题目描述
-
-将一个字符串转换成一个整数,字符串不是一个合法的数值则返回 0,要求不能使用字符串转换整数的库函数。
-
-```html
-Iuput:
-+2147483647
-1a33
-
-Output:
-2147483647
-0
-```
-
-## 解题思路
-
-```java
-public int StrToInt(String str) {
- if (str == null || str.length() == 0)
- return 0;
- boolean isNegative = str.charAt(0) == '-';
- int ret = 0;
- for (int i = 0; i < str.length(); i++) {
- char c = str.charAt(i);
- if (i == 0 && (c == '+' || c == '-')) /* 符号判定 */
- continue;
- if (c < '0' || c > '9') /* 非法输入 */
- return 0;
- ret = ret * 10 + (c - '0');
- }
- return isNegative ? -ret : ret;
-}
-```
-
-# 68. 树中两个节点的最低公共祖先
-
-## 解题思路
-
-### 二叉查找树
-
-[Leetcode : 235. Lowest Common Ancestor of a Binary Search Tree](https://leetcode.com/problems/lowest-common-ancestor-of-a-binary-search-tree/description/)
-
-二叉查找树中,两个节点 p, q 的公共祖先 root 满足 root.val \>= p.val && root.val \<= q.val。
-
-
-
-```java
-public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
- if (root == null)
- return root;
- if (root.val > p.val && root.val > q.val)
- return lowestCommonAncestor(root.left, p, q);
- if (root.val < p.val && root.val < q.val)
- return lowestCommonAncestor(root.right, p, q);
- return root;
-}
-```
-
-### 普通二叉树
-
-[Leetcode : 236. Lowest Common Ancestor of a Binary Tree](https://leetcode.com/problems/lowest-common-ancestor-of-a-binary-tree/description/)
-
-在左右子树中查找是否存在 p 或者 q,如果 p 和 q 分别在两个子树中,那么就说明根节点就是最低公共祖先。
-
-
-
-```java
-public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
- if (root == null || root == p || root == q)
- return root;
- TreeNode left = lowestCommonAncestor(root.left, p, q);
- TreeNode right = lowestCommonAncestor(root.right, p, q);
- return left == null ? right : right == null ? left : root;
-}
-```
diff --git a/notes/剑指 Offer 题解 - 目录1.md b/notes/剑指 Offer 题解 - 目录1.md
deleted file mode 100644
index 11e35e73..00000000
--- a/notes/剑指 Offer 题解 - 目录1.md
+++ /dev/null
@@ -1,90 +0,0 @@
-# 目录
-
-- [3. 数组中重复的数字](notes/3.%20数组中重复的数字.md)
-- [4. 二维数组中的查找](notes/4.%20二维数组中的查找.md)
-- [5. 替换空格](notes/5.%20替换空格.md)
-- [6. 从尾到头打印链表](notes/6.%20从尾到头打印链表.md)
-- [7. 重建二叉树](notes/7.%20重建二叉树.md)
-- [8. 二叉树的下一个结点](notes/8.%20二叉树的下一个结点.md)
-- [9. 用两个栈实现队列](notes/9.%20用两个栈实现队列.md)
-- [10.1 斐波那契数列](notes/10.1%20斐波那契数列.md)
-- [10.2 矩形覆盖](notes/10.2%20矩形覆盖.md)
-- [10.3 跳台阶](notes/10.3%20跳台阶.md)
-- [10.4 变态跳台阶](notes/10.4%20变态跳台阶.md)
-- [11. 旋转数组的最小数字](notes/11.%20旋转数组的最小数字.md)
-- [12. 矩阵中的路径](notes/12.%20矩阵中的路径.md)
-- [13. 机器人的运动范围](notes/13.%20机器人的运动范围.md)
-- [14. 剪绳子](notes/14.%20剪绳子.md)
-- [15. 二进制中 1 的个数](notes/15.%20二进制中%201%20的个数.md)
-- [16. 数值的整数次方](notes/16.%20数值的整数次方.md)
-- [17. 打印从 1 到最大的 n 位数](notes/17.%20打印从%201%20到最大的%20n%20位数.md)
-- [18.1 在 O(1) 时间内删除链表节点](notes/18.1%20在%20O(1)%20时间内删除链表节点.md)
-- [18.2 删除链表中重复的结点](notes/18.2%20删除链表中重复的结点.md)
-- [19. 正则表达式匹配](notes/19.%20正则表达式匹配.md)
-- [20. 表示数值的字符串](notes/20.%20表示数值的字符串.md)
-- [21. 调整数组顺序使奇数位于偶数前面](notes/21.%20调整数组顺序使奇数位于偶数前面.md)
-- [22. 链表中倒数第 K 个结点](notes/22.%20链表中倒数第%20K%20个结点.md)
-- [23. 链表中环的入口结点](notes/23.%20链表中环的入口结点.md)
-- [24. 反转链表](notes/24.%20反转链表.md)
-- [25. 合并两个排序的链表](notes/25.%20合并两个排序的链表.md)
-- [26. 树的子结构](notes/26.%20树的子结构.md)
-- [27. 二叉树的镜像](notes/27.%20二叉树的镜像.md)
-- [28. 对称的二叉树](notes/28.%20对称的二叉树.md)
-- [29. 顺时针打印矩阵](notes/29.%20顺时针打印矩阵.md)
-- [30. 包含 min 函数的栈](notes/30.%20包含%20min%20函数的栈.md)
-- [31. 栈的压入、弹出序列](notes/31.%20栈的压入、弹出序列.md)
-- [32.1 从上往下打印二叉树](notes/32.1%20从上往下打印二叉树.md)
-- [32.2 把二叉树打印成多行](notes/32.2%20把二叉树打印成多行.md)
-- [32.3 按之字形顺序打印二叉树](notes/32.3%20按之字形顺序打印二叉树.md)
-- [33. 二叉搜索树的后序遍历序列](notes/33.%20二叉搜索树的后序遍历序列.md)
-- [34. 二叉树中和为某一值的路径](notes/34.%20二叉树中和为某一值的路径.md)
-- [35. 复杂链表的复制](notes/35.%20复杂链表的复制.md)
-- [36. 二叉搜索树与双向链表](notes/36.%20二叉搜索树与双向链表.md)
-- [37. 序列化二叉树](notes/37.%20序列化二叉树.md)
-- [38. 字符串的排列](notes/38.%20字符串的排列.md)
-- [39. 数组中出现次数超过一半的数字](notes/39.%20数组中出现次数超过一半的数字.md)
-- [40. 最小的 K 个数](notes/40.%20最小的%20K%20个数.md)
-- [41.1 数据流中的中位数](notes/41.1%20数据流中的中位数.md)
-- [41.2 字符流中第一个不重复的字符](notes/41.2%20字符流中第一个不重复的字符.md)
-- [42. 连续子数组的最大和](notes/42.%20连续子数组的最大和.md)
-- [43. 从 1 到 n 整数中 1 出现的次数](notes/43.%20从%201%20到%20n%20整数中%201%20出现的次数.md)
-- [44. 数字序列中的某一位数字](notes/44.%20数字序列中的某一位数字.md)
-- [45. 把数组排成最小的数](notes/45.%20把数组排成最小的数.md)
-- [46. 把数字翻译成字符串](notes/46.%20把数字翻译成字符串.md)
-- [47. 礼物的最大价值](notes/47.%20礼物的最大价值.md)
-- [48. 最长不含重复字符的子字符串](notes/48.%20最长不含重复字符的子字符串.md)
-- [49. 丑数](notes/49.%20丑数.md)
-- [50. 第一个只出现一次的字符位置](notes/50.%20第一个只出现一次的字符位置.md)
-- [51. 数组中的逆序对](notes/51.%20数组中的逆序对.md)
-- [52. 两个链表的第一个公共结点](notes/52.%20两个链表的第一个公共结点.md)
-- [53. 数字在排序数组中出现的次数](notes/53.%20数字在排序数组中出现的次数.md)
-- [54. 二叉查找树的第 K 个结点](notes/54.%20二叉查找树的第%20K%20个结点.md)
-- [55.1 二叉树的深度](notes/55.1%20二叉树的深度.md)
-- [55.2 平衡二叉树](notes/55.2%20平衡二叉树.md)
-- [56. 数组中只出现一次的数字](notes/56.%20数组中只出现一次的数字.md)
-- [57.1 和为 S 的两个数字](notes/57.1%20和为%20S%20的两个数字.md)
-- [57.2 和为 S 的连续正数序列](notes/57.2%20和为%20S%20的连续正数序列.md)
-- [58.1 翻转单词顺序列](notes/58.1%20翻转单词顺序列.md)
-- [58.2 左旋转字符串](notes/58.2%20左旋转字符串.md)
-- [59. 滑动窗口的最大值](notes/59.%20滑动窗口的最大值.md)
-- [60. n 个骰子的点数](notes/60.%20n%20个骰子的点数.md)
-- [61. 扑克牌顺子](notes/61.%20扑克牌顺子.md)
-- [62. 圆圈中最后剩下的数](notes/62.%20圆圈中最后剩下的数.md)
-- [63. 股票的最大利润](notes/63.%20股票的最大利润.md)
-- [64. 求 1+2+3+...+n](notes/64.%20求%201+2+3+...+n.md)
-- [65. 不用加减乘除做加法](notes/65.%20不用加减乘除做加法.md)
-- [66. 构建乘积数组](notes/66.%20构建乘积数组.md)
-- [67. 把字符串转换成整数](notes/67.%20把字符串转换成整数.md)
-- [68. 树中两个节点的最低公共祖先](notes/68.%20树中两个节点的最低公共祖先.md)
-
-
-# 参考文献
-
-何海涛. 剑指 Offer[M]. 电子工业出版社, 2012.
-
-
-
-
-
-
-
diff --git a/notes/剑指 Offer 题解 - 目录2.md b/notes/剑指 Offer 题解 - 目录2.md
deleted file mode 100644
index a7488895..00000000
--- a/notes/剑指 Offer 题解 - 目录2.md
+++ /dev/null
@@ -1,124 +0,0 @@
-# 前言
-
-题目来自《何海涛. 剑指 Offer[M]. 电子工业出版社, 2012.》,刷题网站推荐:
-
-- [牛客网](https://www.nowcoder.com/ta/coding-interviews?from=cyc_github)
-- [Leetcode](https://leetcode-cn.com/problemset/lcof/)
-
-# 数组与矩阵
-
-- [3. 数组中重复的数字](notes/3.%20数组中重复的数字.md)
-- [4. 二维数组中的查找](notes/4.%20二维数组中的查找.md)
-- [5. 替换空格](notes/5.%20替换空格.md)
-- [29. 顺时针打印矩阵](notes/29.%20顺时针打印矩阵.md)
-- [50. 第一个只出现一次的字符位置](notes/50.%20第一个只出现一次的字符位置.md)
-
-# 栈队列堆
-
-- [9. 用两个栈实现队列](notes/9.%20用两个栈实现队列.md)
-- [30. 包含 min 函数的栈](notes/30.%20包含%20min%20函数的栈.md)
-- [31. 栈的压入、弹出序列](notes/31.%20栈的压入、弹出序列.md)
-- [40. 最小的 K 个数](notes/40.%20最小的%20K%20个数.md)
-- [41.1 数据流中的中位数](notes/41.1%20数据流中的中位数.md)
-- [41.2 字符流中第一个不重复的字符](notes/41.2%20字符流中第一个不重复的字符.md)
-- [59. 滑动窗口的最大值](notes/59.%20滑动窗口的最大值.md)
-
-# 双指针
-
-- [57.1 和为 S 的两个数字](notes/57.1%20和为%20S%20的两个数字.md)
-- [57.2 和为 S 的连续正数序列](notes/57.2%20和为%20S%20的连续正数序列.md)
-- [58.1 翻转单词顺序列](notes/58.1%20翻转单词顺序列.md)
-- [58.2 左旋转字符串](notes/58.2%20左旋转字符串.md)
-
-# 链表
-
-- [6. 从尾到头打印链表](notes/6.%20从尾到头打印链表.md)
-- [18.1 在 O(1) 时间内删除链表节点](notes/18.1%20在%20O(1)%20时间内删除链表节点.md)
-- [18.2 删除链表中重复的结点](notes/18.2%20删除链表中重复的结点.md)
-- [22. 链表中倒数第 K 个结点](notes/22.%20链表中倒数第%20K%20个结点.md)
-- [23. 链表中环的入口结点](notes/23.%20链表中环的入口结点.md)
-- [24. 反转链表](notes/24.%20反转链表.md)
-- [25. 合并两个排序的链表](notes/25.%20合并两个排序的链表.md)
-- [35. 复杂链表的复制](notes/35.%20复杂链表的复制.md)
-- [52. 两个链表的第一个公共结点](notes/52.%20两个链表的第一个公共结点.md)
-
-# 树
-
-- [7. 重建二叉树](notes/7.%20重建二叉树.md)
-- [8. 二叉树的下一个结点](notes/8.%20二叉树的下一个结点.md)
-- [26. 树的子结构](notes/26.%20树的子结构.md)
-- [27. 二叉树的镜像](notes/27.%20二叉树的镜像.md)
-- [28. 对称的二叉树](notes/28.%20对称的二叉树.md)
-- [32.1 从上往下打印二叉树](notes/32.1%20从上往下打印二叉树.md)
-- [32.2 把二叉树打印成多行](notes/32.2%20把二叉树打印成多行.md)
-- [32.3 按之字形顺序打印二叉树](notes/32.3%20按之字形顺序打印二叉树.md)
-- [33. 二叉搜索树的后序遍历序列](notes/33.%20二叉搜索树的后序遍历序列.md)
-- [34. 二叉树中和为某一值的路径](notes/34.%20二叉树中和为某一值的路径.md)
-- [36. 二叉搜索树与双向链表](notes/36.%20二叉搜索树与双向链表.md)
-- [37. 序列化二叉树](notes/37.%20序列化二叉树.md)
-- [54. 二叉查找树的第 K 个结点](notes/54.%20二叉查找树的第%20K%20个结点.md)
-- [55.1 二叉树的深度](notes/55.1%20二叉树的深度.md)
-- [55.2 平衡二叉树](notes/55.2%20平衡二叉树.md)
-- [68. 树中两个节点的最低公共祖先](notes/68.%20树中两个节点的最低公共祖先.md)
-
-# 贪心思想
-
-- [14. 剪绳子](notes/14.%20剪绳子.md)
-- [48. 最长不含重复字符的子字符串](notes/48.%20最长不含重复字符的子字符串.md)
-- [63. 股票的最大利润](notes/63.%20股票的最大利润.md)
-
-# 二分查找
-
-- [11. 旋转数组的最小数字](notes/11.%20旋转数组的最小数字.md)
-- [53. 数字在排序数组中出现的次数](notes/53.%20数字在排序数组中出现的次数.md)
-
-# 分治
-
-- [16. 数值的整数次方](notes/16.%20数值的整数次方.md)
-
-# 搜索
-
-- [12. 矩阵中的路径](notes/12.%20矩阵中的路径.md)
-- [13. 机器人的运动范围](notes/13.%20机器人的运动范围.md)
-- [38. 字符串的排列](notes/38.%20字符串的排列.md)
-
-# 排序
-
-- [21. 调整数组顺序使奇数位于偶数前面](notes/21.%20调整数组顺序使奇数位于偶数前面.md)
-- [45. 把数组排成最小的数](notes/45.%20把数组排成最小的数.md)
-- [51. 数组中的逆序对](notes/51.%20数组中的逆序对.md)
-
-# 动态规划
-
-- [10.1 斐波那契数列](notes/10.1%20斐波那契数列.md)
-- [10.2 矩形覆盖](notes/10.2%20矩形覆盖.md)
-- [10.3 跳台阶](notes/10.3%20跳台阶.md)
-- [10.4 变态跳台阶](notes/10.4%20变态跳台阶.md)
-- [42. 连续子数组的最大和](notes/42.%20连续子数组的最大和.md)
-- [47. 礼物的最大价值](notes/47.%20礼物的最大价值.md)
-- [49. 丑数](notes/49.%20丑数.md)
-- [60. n 个骰子的点数](notes/60.%20n%20个骰子的点数.md)
-- [66. 构建乘积数组](notes/66.%20构建乘积数组.md)
-
-# 数学
-
-- [39. 数组中出现次数超过一半的数字](notes/39.%20数组中出现次数超过一半的数字.md)
-- [62. 圆圈中最后剩下的数](notes/62.%20圆圈中最后剩下的数.md)
-- [43. 从 1 到 n 整数中 1 出现的次数](notes/43.%20从%201%20到%20n%20整数中%201%20出现的次数.md)
-
-# 位运算
-
-- [15. 二进制中 1 的个数](notes/15.%20二进制中%201%20的个数.md)
-- [56. 数组中只出现一次的数字](notes/56.%20数组中只出现一次的数字.md)
-
-# 其它
-
-- [17. 打印从 1 到最大的 n 位数](notes/17.%20打印从%201%20到最大的%20n%20位数.md)
-- [19. 正则表达式匹配](notes/19.%20正则表达式匹配.md)
-- [20. 表示数值的字符串](notes/20.%20表示数值的字符串.md)
-- [44. 数字序列中的某一位数字](notes/44.%20数字序列中的某一位数字.md)
-- [46. 把数字翻译成字符串](notes/46.%20把数字翻译成字符串.md)
-- [61. 扑克牌顺子](notes/61.%20扑克牌顺子.md)
-- [64. 求 1+2+3+...+n](notes/64.%20求%201+2+3+...+n.md)
-- [65. 不用加减乘除做加法](notes/65.%20不用加减乘除做加法.md)
-- [67. 把字符串转换成整数](notes/67.%20把字符串转换成整数.md)
diff --git a/notes/攻击技术.md b/notes/攻击技术.md
index a624f56f..f08a4e48 100644
--- a/notes/攻击技术.md
+++ b/notes/攻击技术.md
@@ -1,6 +1,11 @@
# 攻击技术
* [攻击技术](#攻击技术)
+ * [一、跨站脚本攻击](#一跨站脚本攻击)
+ * [二、跨站请求伪造](#二跨站请求伪造)
+ * [三、SQL 注入攻击](#三sql-注入攻击)
+ * [四、拒绝服务攻击](#四拒绝服务攻击)
+ * [参考资料](#参考资料)
@@ -80,7 +85,7 @@ alert(/xss/);
</script>
```
-\> [XSS 过滤在线测试](http://jsxss.com/zh/try.html)
+> [XSS 过滤在线测试](http://jsxss.com/zh/try.html)
## 二、跨站请求伪造
diff --git a/notes/数据库系统原理.md b/notes/数据库系统原理.md
index 7ceedf3f..8ef8e6d4 100644
--- a/notes/数据库系统原理.md
+++ b/notes/数据库系统原理.md
@@ -2,13 +2,43 @@
* [数据库系统原理](#数据库系统原理)
* [一、事务](#一事务)
+ * [概念](#概念)
+ * [ACID](#acid)
+ * [AUTOCOMMIT](#autocommit)
* [二、并发一致性问题](#二并发一致性问题)
+ * [丢失修改](#丢失修改)
+ * [读脏数据](#读脏数据)
+ * [不可重复读](#不可重复读)
+ * [幻影读](#幻影读)
* [三、封锁](#三封锁)
+ * [封锁粒度](#封锁粒度)
+ * [封锁类型](#封锁类型)
+ * [封锁协议](#封锁协议)
+ * [MySQL 隐式与显示锁定](#mysql-隐式与显示锁定)
* [四、隔离级别](#四隔离级别)
+ * [未提交读(READ UNCOMMITTED)](#未提交读read-uncommitted)
+ * [提交读(READ COMMITTED)](#提交读read-committed)
+ * [可重复读(REPEATABLE READ)](#可重复读repeatable-read)
+ * [可串行化(SERIALIZABLE)](#可串行化serializable)
* [五、多版本并发控制](#五多版本并发控制)
+ * [基本思想](#基本思想)
+ * [版本号](#版本号)
+ * [Undo 日志](#undo-日志)
+ * [ReadView](#readview)
+ * [快照读与当前读](#快照读与当前读)
* [六、Next-Key Locks](#六next-key-locks)
+ * [Record Locks](#record-locks)
+ * [Gap Locks](#gap-locks)
+ * [Next-Key Locks](#next-key-locks)
* [七、关系数据库设计理论](#七关系数据库设计理论)
+ * [函数依赖](#函数依赖)
+ * [异常](#异常)
+ * [范式](#范式)
* [八、ER 图](#八er-图)
+ * [实体的三种联系](#实体的三种联系)
+ * [表示出现多次的关系](#表示出现多次的关系)
+ * [联系的多向性](#联系的多向性)
+ * [表示子类](#表示子类)
* [参考资料](#参考资料)
diff --git a/notes/构建工具.md b/notes/构建工具.md
index 61978898..dbc70bc6 100644
--- a/notes/构建工具.md
+++ b/notes/构建工具.md
@@ -1,6 +1,10 @@
# 构建工具
* [构建工具](#构建工具)
+ * [一、构建工具的作用](#一构建工具的作用)
+ * [二、Java 主流构建工具](#二java-主流构建工具)
+ * [三、Maven](#三maven)
+ * [参考资料](#参考资料)
diff --git a/notes/正则表达式.md b/notes/正则表达式.md
index f1efa18e..fba48021 100644
--- a/notes/正则表达式.md
+++ b/notes/正则表达式.md
@@ -1,6 +1,17 @@
# 正则表达式
* [正则表达式](#正则表达式)
+ * [一、概述](#一概述)
+ * [二、匹配单个字符](#二匹配单个字符)
+ * [三、匹配一组字符](#三匹配一组字符)
+ * [四、使用元字符](#四使用元字符)
+ * [五、重复匹配](#五重复匹配)
+ * [六、位置匹配](#六位置匹配)
+ * [七、使用子表达式](#七使用子表达式)
+ * [八、回溯引用](#八回溯引用)
+ * [九、前后查找](#九前后查找)
+ * [十、嵌入条件](#十嵌入条件)
+ * [参考资料](#参考资料)
diff --git a/notes/消息队列.md b/notes/消息队列.md
index cd30815c..60507bc9 100644
--- a/notes/消息队列.md
+++ b/notes/消息队列.md
@@ -2,8 +2,15 @@
* [消息队列](#消息队列)
* [一、消息模型](#一消息模型)
+ * [点对点](#点对点)
+ * [发布/订阅](#发布订阅)
* [二、使用场景](#二使用场景)
+ * [异步处理](#异步处理)
+ * [流量削锋](#流量削锋)
+ * [应用解耦](#应用解耦)
* [三、可靠性](#三可靠性)
+ * [发送端的可靠性](#发送端的可靠性)
+ * [接收端的可靠性](#接收端的可靠性)
* [参考资料](#参考资料)
diff --git a/notes/算法 - 目录1.md b/notes/算法 - 目录1.md
deleted file mode 100644
index aa982d16..00000000
--- a/notes/算法 - 目录1.md
+++ /dev/null
@@ -1,12 +0,0 @@
-# 目录
-
-- [算法分析](notes/算法%20-%20算法分析.md)
-- [排序](notes/算法%20-%20排序.md)
-- [并查集](notes/算法%20-%20并查集.md)
-- [栈和队列](notes/算法%20-%20栈和队列.md)
-- [符号表](notes/算法%20-%20符号表.md)
-- [其它](notes/算法%20-%20其它.md)
-
-# 参考资料
-
-- Sedgewick, Robert, and Kevin Wayne. _Algorithms_. Addison-Wesley Professional, 2011.
diff --git a/notes/系统设计基础.md b/notes/系统设计基础.md
index 933a13c8..02ffa567 100644
--- a/notes/系统设计基础.md
+++ b/notes/系统设计基础.md
@@ -1,6 +1,12 @@
# 系统设计基础
* [系统设计基础](#系统设计基础)
+ * [一、性能](#一性能)
+ * [二、伸缩性](#二伸缩性)
+ * [三、扩展性](#三扩展性)
+ * [四、可用性](#四可用性)
+ * [五、安全性](#五安全性)
+ * [参考资料](#参考资料)
diff --git a/notes/缓存.md b/notes/缓存.md
index 9839d4a9..f20d1dd5 100644
--- a/notes/缓存.md
+++ b/notes/缓存.md
@@ -1,6 +1,14 @@
# 缓存
* [缓存](#缓存)
+ * [一、缓存特征](#一缓存特征)
+ * [二、缓存位置](#二缓存位置)
+ * [三、CDN](#三cdn)
+ * [四、缓存问题](#四缓存问题)
+ * [五、数据分布](#五数据分布)
+ * [六、一致性哈希](#六一致性哈希)
+ * [七、LRU](#七lru)
+ * [参考资料](#参考资料)
diff --git a/notes/计算机操作系统 - 内存管理.md b/notes/计算机操作系统 - 内存管理.md
index b7cbff62..9b0b78be 100644
--- a/notes/计算机操作系统 - 内存管理.md
+++ b/notes/计算机操作系统 - 内存管理.md
@@ -46,7 +46,7 @@
### 1. 最佳
-\> OPT, Optimal replacement algorithm
+> OPT, Optimal replacement algorithm
所选择的被换出的页面将是最长时间内不再被访问,通常可以保证获得最低的缺页率。
@@ -62,7 +62,7 @@
### 2. 最近最久未使用
-\> LRU, Least Recently Used
+> LRU, Least Recently Used
虽然无法知道将来要使用的页面情况,但是可以知道过去使用页面的情况。LRU 将最近最久未使用的页面换出。
@@ -77,7 +77,7 @@
### 3. 最近未使用
-\> NRU, Not Recently Used
+> NRU, Not Recently Used
每个页面都有两个状态位:R 与 M,当页面被访问时设置页面的 R=1,当页面被修改时设置 M=1。其中 R 位会定时被清零。可以将页面分成以下四类:
@@ -92,7 +92,7 @@ NRU 优先换出已经被修改的脏页面(R=0,M=1),而不是被频繁
### 4. 先进先出
-\> FIFO, First In First Out
+> FIFO, First In First Out
选择换出的页面是最先进入的页面。
@@ -108,7 +108,7 @@ FIFO 算法可能会把经常使用的页面置换出去,为了避免这一问
### 6. 时钟
-\> Clock
+> Clock
第二次机会算法需要在链表中移动页面,降低了效率。时钟算法使用环形链表将页面连接起来,再使用一个指针指向最老的页面。
diff --git a/notes/计算机操作系统 - 目录1.md b/notes/计算机操作系统 - 目录1.md
deleted file mode 100644
index e4895e72..00000000
--- a/notes/计算机操作系统 - 目录1.md
+++ /dev/null
@@ -1,20 +0,0 @@
-# 目录
-
-- [概述](notes/计算机操作系统%20-%20概述.md)
-- [进程管理](notes/计算机操作系统%20-%20进程管理.md)
-- [死锁](notes/计算机操作系统%20-%20死锁.md)
-- [内存管理](notes/计算机操作系统%20-%20内存管理.md)
-- [设备管理](notes/计算机操作系统%20-%20设备管理.md)
-- [链接](notes/计算机操作系统%20-%20链接.md)
-
-# 参考资料
-
-- Tanenbaum A S, Bos H. Modern operating systems[M]. Prentice Hall Press, 2014.
-- 汤子瀛, 哲凤屏, 汤小丹. 计算机操作系统[M]. 西安电子科技大学出版社, 2001.
-- Bryant, R. E., & O’Hallaron, D. R. (2004). 深入理解计算机系统.
-- 史蒂文斯. UNIX 环境高级编程 [M]. 人民邮电出版社, 2014.
-- [Operating System Notes](https://applied-programming.github.io/Operating-Systems-Notes/)
-- [Operating-System Structures](https://www.cs.uic.edu/\~jbell/CourseNotes/OperatingSystems/2_Structures.html)
-- [Processes](http://cse.csusb.edu/tongyu/courses/cs460/notes/process.php)
-- [Inter Process Communication Presentation[1]](https://www.slideshare.net/rkolahalam/inter-process-communication-presentation1)
-- [Decoding UCS Invicta – Part 1](https://blogs.cisco.com/datacenter/decoding-ucs-invicta-part-1)
diff --git a/notes/计算机操作系统 - 设备管理.md b/notes/计算机操作系统 - 设备管理.md
index faf67c97..95c7924d 100644
--- a/notes/计算机操作系统 - 设备管理.md
+++ b/notes/计算机操作系统 - 设备管理.md
@@ -32,7 +32,7 @@
### 1. 先来先服务
-\> FCFS, First Come First Served
+> FCFS, First Come First Served
按照磁盘请求的顺序进行调度。
@@ -40,7 +40,7 @@
### 2. 最短寻道时间优先
-\> SSTF, Shortest Seek Time First
+> SSTF, Shortest Seek Time First
优先调度与当前磁头所在磁道距离最近的磁道。
@@ -50,7 +50,7 @@
### 3. 电梯算法
-\> SCAN
+> SCAN
电梯总是保持一个方向运行,直到该方向没有请求为止,然后改变运行方向。
diff --git a/notes/计算机网络 - 目录1.md b/notes/计算机网络 - 目录1.md
deleted file mode 100644
index 6bf3f786..00000000
--- a/notes/计算机网络 - 目录1.md
+++ /dev/null
@@ -1,27 +0,0 @@
-# 目录
-
-- [概述](notes/计算机网络%20-%20概述.md)
-- [物理层](notes/计算机网络%20-%20物理层.md)
-- [链路层](notes/计算机网络%20-%20链路层.md)
-- [网络层](notes/计算机网络%20-%20网络层.md)
-- [传输层](notes/计算机网络%20-%20传输层.md)
-- [应用层](notes/计算机网络%20-%20应用层.md)
-
-# 参考链接
-
-- 计算机网络, 谢希仁
-- JamesF.Kurose, KeithW.Ross, 库罗斯, 等. 计算机网络: 自顶向下方法 [M]. 机械工业出版社, 2014.
-- W.RichardStevens. TCP/IP 详解. 卷 1, 协议 [M]. 机械工业出版社, 2006.
-- [Active vs Passive FTP Mode: Which One is More Secure?](https://securitywing.com/active-vs-passive-ftp-mode/)
-- [Active and Passive FTP Transfers Defined - KB Article #1138](http://www.serv-u.com/kb/1138/active-and-passive-ftp-transfers-defined)
-- [Traceroute](https://zh.wikipedia.org/wiki/Traceroute)
-- [ping](https://zh.wikipedia.org/wiki/Ping)
-- [How DHCP works and DHCP Interview Questions and Answers](http://webcache.googleusercontent.com/search?q=cache:http://anandgiria.blogspot.com/2013/09/windows-dhcp-interview-questions-and.html)
-- [What is process of DORA in DHCP?](https://www.quora.com/What-is-process-of-DORA-in-DHCP)
-- [What is DHCP Server ?](https://tecadmin.net/what-is-dhcp-server/)
-- [Tackling emissions targets in Tokyo](http://www.climatechangenews.com/2011/html/university-tokyo.html)
-- [What does my ISP know when I use Tor?](http://www.climatechangenews.com/2011/html/university-tokyo.html)
-- [Technology-Computer Networking[1]-Computer Networks and the Internet](http://www.linyibin.cn/2017/02/12/technology-ComputerNetworking-Internet/)
-- [P2P 网络概述.](http://slidesplayer.com/slide/11616167/)
-- [Circuit Switching (a) Circuit switching. (b) Packet switching.](http://slideplayer.com/slide/5115386/)
-
diff --git a/notes/设计模式.md b/notes/设计模式.md
index 2cc0be4a..fe1002a2 100644
--- a/notes/设计模式.md
+++ b/notes/设计模式.md
@@ -2,32 +2,132 @@
* [一、概述](#一概述)
* [二、创建型](#二创建型)
* [1. 单例(Singleton)](#1-单例singleton)
+ * [Intent](#intent)
+ * [Class Diagram](#class-diagram)
+ * [Implementation](#implementation)
+ * [Examples](#examples)
+ * [JDK](#jdk)
* [2. 简单工厂(Simple Factory)](#2-简单工厂simple-factory)
+ * [Intent](#intent)
+ * [Class Diagram](#class-diagram)
+ * [Implementation](#implementation)
* [3. 工厂方法(Factory Method)](#3-工厂方法factory-method)
+ * [Intent](#intent)
+ * [Class Diagram](#class-diagram)
+ * [Implementation](#implementation)
+ * [JDK](#jdk)
* [4. 抽象工厂(Abstract Factory)](#4-抽象工厂abstract-factory)
+ * [Intent](#intent)
+ * [Class Diagram](#class-diagram)
+ * [Implementation](#implementation)
+ * [JDK](#jdk)
* [5. 生成器(Builder)](#5-生成器builder)
+ * [Intent](#intent)
+ * [Class Diagram](#class-diagram)
+ * [Implementation](#implementation)
+ * [JDK](#jdk)
* [6. 原型模式(Prototype)](#6-原型模式prototype)
+ * [Intent](#intent)
+ * [Class Diagram](#class-diagram)
+ * [Implementation](#implementation)
+ * [JDK](#jdk)
* [三、行为型](#三行为型)
* [1. 责任链(Chain Of Responsibility)](#1-责任链chain-of-responsibility)
+ * [Intent](#intent)
+ * [Class Diagram](#class-diagram)
+ * [Implementation](#implementation)
+ * [JDK](#jdk)
* [2. 命令(Command)](#2-命令command)
+ * [Intent](#intent)
+ * [Class Diagram](#class-diagram)
+ * [Implementation](#implementation)
+ * [JDK](#jdk)
* [3. 解释器(Interpreter)](#3-解释器interpreter)
+ * [Intent](#intent)
+ * [Class Diagram](#class-diagram)
+ * [Implementation](#implementation)
+ * [JDK](#jdk)
* [4. 迭代器(Iterator)](#4-迭代器iterator)
+ * [Intent](#intent)
+ * [Class Diagram](#class-diagram)
+ * [Implementation](#implementation)
+ * [JDK](#jdk)
* [5. 中介者(Mediator)](#5-中介者mediator)
+ * [Intent](#intent)
+ * [Class Diagram](#class-diagram)
+ * [Implementation](#implementation)
+ * [JDK](#jdk)
* [6. 备忘录(Memento)](#6-备忘录memento)
+ * [Intent](#intent)
+ * [Class Diagram](#class-diagram)
+ * [Implementation](#implementation)
+ * [JDK](#jdk)
* [7. 观察者(Observer)](#7-观察者observer)
+ * [Intent](#intent)
+ * [Class Diagram](#class-diagram)
+ * [Implementation](#implementation)
+ * [JDK](#jdk)
* [8. 状态(State)](#8-状态state)
+ * [Intent](#intent)
+ * [Class Diagram](#class-diagram)
+ * [Implementation](#implementation)
* [9. 策略(Strategy)](#9-策略strategy)
+ * [Intent](#intent)
+ * [Class Diagram](#class-diagram)
+ * [与状态模式的比较](#与状态模式的比较)
+ * [Implementation](#implementation)
+ * [JDK](#jdk)
* [10. 模板方法(Template Method)](#10-模板方法template-method)
+ * [Intent](#intent)
+ * [Class Diagram](#class-diagram)
+ * [Implementation](#implementation)
+ * [JDK](#jdk)
* [11. 访问者(Visitor)](#11-访问者visitor)
+ * [Intent](#intent)
+ * [Class Diagram](#class-diagram)
+ * [Implementation](#implementation)
+ * [JDK](#jdk)
* [12. 空对象(Null)](#12-空对象null)
+ * [Intent](#intent)
+ * [Class Diagram](#class-diagram)
+ * [Implementation](#implementation)
* [四、结构型](#四结构型)
* [1. 适配器(Adapter)](#1-适配器adapter)
+ * [Intent](#intent)
+ * [Class Diagram](#class-diagram)
+ * [Implementation](#implementation)
+ * [JDK](#jdk)
* [2. 桥接(Bridge)](#2-桥接bridge)
+ * [Intent](#intent)
+ * [Class Diagram](#class-diagram)
+ * [Implementation](#implementation)
+ * [JDK](#jdk)
* [3. 组合(Composite)](#3-组合composite)
+ * [Intent](#intent)
+ * [Class Diagram](#class-diagram)
+ * [Implementation](#implementation)
+ * [JDK](#jdk)
* [4. 装饰(Decorator)](#4-装饰decorator)
+ * [Intent](#intent)
+ * [Class Diagram](#class-diagram)
+ * [Implementation](#implementation)
+ * [设计原则](#设计原则)
+ * [JDK](#jdk)
* [5. 外观(Facade)](#5-外观facade)
+ * [Intent](#intent)
+ * [Class Diagram](#class-diagram)
+ * [Implementation](#implementation)
+ * [设计原则](#设计原则)
* [6. 享元(Flyweight)](#6-享元flyweight)
+ * [Intent](#intent)
+ * [Class Diagram](#class-diagram)
+ * [Implementation](#implementation)
+ * [JDK](#jdk)
* [7. 代理(Proxy)](#7-代理proxy)
+ * [Intent](#intent)
+ * [Class Diagram](#class-diagram)
+ * [Implementation](#implementation)
+ * [JDK](#jdk)
* [参考资料](#参考资料)
diff --git a/notes/集群.md b/notes/集群.md
index 6c87ae6c..2cc3a7c8 100644
--- a/notes/集群.md
+++ b/notes/集群.md
@@ -2,7 +2,23 @@
* [集群](#集群)
* [一、负载均衡](#一负载均衡)
+ * [负载均衡算法](#负载均衡算法)
+ * [1. 轮询(Round Robin)](#1-轮询round-robin)
+ * [2. 加权轮询(Weighted Round Robbin)](#2-加权轮询weighted-round-robbin)
+ * [3. 最少连接(least Connections)](#3-最少连接least-connections)
+ * [4. 加权最少连接(Weighted Least Connection)](#4-加权最少连接weighted-least-connection)
+ * [5. 随机算法(Random)](#5-随机算法random)
+ * [6. 源地址哈希法 (IP Hash)](#6-源地址哈希法-ip-hash)
+ * [转发实现](#转发实现)
+ * [1. HTTP 重定向](#1-http-重定向)
+ * [2. DNS 域名解析](#2-dns-域名解析)
+ * [3. 反向代理服务器](#3-反向代理服务器)
+ * [4. 网络层](#4-网络层)
+ * [5. 链路层](#5-链路层)
* [二、集群下的 Session 管理](#二集群下的-session-管理)
+ * [Sticky Session](#sticky-session)
+ * [Session Replication](#session-replication)
+ * [Session Server](#session-server)
diff --git a/notes/面向对象思想.md b/notes/面向对象思想.md
index f2ef9776..d5ba57d9 100644
--- a/notes/面向对象思想.md
+++ b/notes/面向对象思想.md
@@ -2,8 +2,19 @@
* [面向对象思想](#面向对象思想)
* [一、三大特性](#一三大特性)
+ * [封装](#封装)
+ * [继承](#继承)
+ * [多态](#多态)
* [二、类图](#二类图)
+ * [泛化关系 (Generalization)](#泛化关系-generalization)
+ * [实现关系 (Realization)](#实现关系-realization)
+ * [聚合关系 (Aggregation)](#聚合关系-aggregation)
+ * [组合关系 (Composition)](#组合关系-composition)
+ * [关联关系 (Association)](#关联关系-association)
+ * [依赖关系 (Dependency)](#依赖关系-dependency)
* [三、设计原则](#三设计原则)
+ * [S.O.L.I.D](#solid)
+ * [其他常见原则](#其他常见原则)
* [参考资料](#参考资料)
@@ -279,7 +290,7 @@ Vihicle .. N
#### 1. 单一责任原则
-\> 修改一个类的原因应该只有一个。
+> 修改一个类的原因应该只有一个。
换句话说就是让一个类只负责一件事,当这个类需要做过多事情的时候,就需要分解这个类。
@@ -287,7 +298,7 @@ Vihicle .. N
#### 2. 开放封闭原则
-\> 类应该对扩展开放,对修改关闭。
+> 类应该对扩展开放,对修改关闭。
扩展就是添加新功能的意思,因此该原则要求在添加新功能时不需要修改代码。
@@ -295,7 +306,7 @@ Vihicle .. N
#### 3. 里氏替换原则
-\> 子类对象必须能够替换掉所有父类对象。
+> 子类对象必须能够替换掉所有父类对象。
继承是一种 IS-A 关系,子类需要能够当成父类来使用,并且需要比父类更特殊。
@@ -303,13 +314,13 @@ Vihicle .. N
#### 4. 接口分离原则
-\> 不应该强迫客户依赖于它们不用的方法。
+> 不应该强迫客户依赖于它们不用的方法。
因此使用多个专门的接口比使用单一的总接口要好。
#### 5. 依赖倒置原则
-\> 高层模块不应该依赖于低层模块,二者都应该依赖于抽象;\抽象不应该依赖于细节,细节应该依赖于抽象。
+> 高层模块不应该依赖于低层模块,二者都应该依赖于抽象;抽象不应该依赖于细节,细节应该依赖于抽象。
高层模块包含一个应用程序中重要的策略选择和业务模块,如果高层模块依赖于低层模块,那么低层模块的改动就会直接影响到高层模块,从而迫使高层模块也需要改动。